Evaluation corpus for restricted-domain question-answering systems for the holy Quran
Full text
Figure
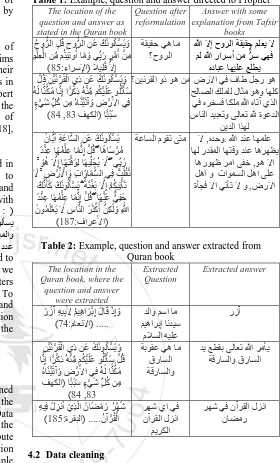
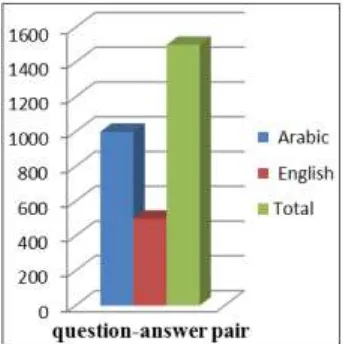

Related documents
Foxcroft et al BMC Pregnancy and Childbirth 2013, 13 3 http //www biomedcentral com/1471 2393/13/3 RESEARCH ARTICLE Open Access Development and validation of a pregnancy symptoms
This turn to history also demonstrates the strong association with the more important human-to-human encounters and is considered in order to situate the idea of
The use of Razor on a PTMAC structure has been tested at a post synthesis simulation level to study the effect and interactions of both energy reducing techniques on
Table 42: Rest of Europe Recent Past, Current & Future Analysis for Ambulance Services Analyzed with Annual Revenue Figures in US$ Million for Years 2014 through 2020
In this paper, we will introduce the concept of a continuous majority rule which generalizes the previous social welfare functions beyond the discrete values, and using new axioms,
If the formula is simply written in front of students with the expectation that they know the where it comes from and why it works, generally they have a harder time
In some national contexts, institutional ethics reviews are obligatory not only for medical research but also for social science research including qualitative research.. As
Based on the political economic findings about the effects of the composition of fiscal consolidation on budget deficit reduction (Alesina and Ardagna 2010 ; Alesina 2012
