Rochester Institute of Technology
RIT Scholar Works
Theses
Thesis/Dissertation Collections
5-1-2002
Automatic indoor/outdoor scene classification
Navid Serrano
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion in Theses by an authorized administrator of RIT Scholar Works. For more information, please [email protected].
Recommended Citation
AUTOMATIC INDOOR/ OUTDOOR
SCENE CLASSIFICATION
by
Navid Serrano
A Thesis Submitted
In
Partial Fulfillment
of the
Requirements for the Degree of
MASTER OF SCIENCE
In
Electrical Engineering
Approved by:
Prof. Andreas E. Savakis, Thesis Advisor
Prof. Sohail
A.
Dianat. Thesis Committee
Prof. Raghuveer M. Rao, Thesis Committee
Dr. Jiebo Luo, Thesis Committee
Prof. Robert J. Bowman, Department Head
DEPARTMENT OF ELECTRICAL ENGINEERING
COLLEGE OF ENGINEERING
ROCHESTER INSTITUTE OF TECHNOLOGY
ROCHESTER, NEW YORK
AUTOMATIC INDOOR/OUTDOOR
SCENE CLASSIFICATION
I, Navid Serrano, hereby grant permission to the Wallace Library of the Rochester
Institute of Technology to reproduce my thesis in whole or in part. Any reproduction will
not be for commercial use or profit.
RochesterInstituteof
Technology
Thesis Abstract
AUTOMATIC
INDOOR/OUTDOOR
SCENE
CLASSIFICATION
By
Navid SerranoProf.Andreas E.
Savakis,
Chairperson oftheSupervisory
CommitteeDepartmentofElectrical
Engineering
The advent and wide acceptance of digital
imaging
technology
has motivated an upsurge in research focused on managing the ever-growing number ofdigital images. Current research inimage manipulation represents a general shift in the field of computer vision from traditional image analysis based on low-level features (e.g. color and texture) to semantic scene
understanding based on high-level features (e.g. grass and sky). One particular area of investigation is scene categorization, where the organization of a large number of images is
treated as a classification problem.
Generally,
the classification involves mapping a set oftraditional low-level features to semantically meaningful categories, such as indoor and outdoor
scenes,usinga classifier engine. Successful indoor/outdoor scenecategorizationisbeneficialtoa number of image manipulation applications, as indoor and outdoor scenes represent among the
most general scene types. In content-based image retrieval, for example, a query for a scene
containing a sunsetcanbe restricted to images in thedatabase pre-categorized as outdoor scenes.
Also,
inimageenhancement, categorizationof a scene as indoorvs. outdoor can leadtoimprovedcolor
balancing
andtonereproduction.Prior research in scene classification has shown that high-level information can, in
fact,
beinferred from low-level image features. Classification rates ofroughly 90% have been reported
using low-level features to predict indoor scenes vs. outdoor scenes.
However,
the highclassification rates are often achieved
by
using computationally expensive, high-dimensional feature sets, thuslimiting
thepractical implementation ofsuchsystems. To addressthisproblem,a lowcomplexity, low-dimensionalfeature set was extracted in avariety ofconfigurations in the
work presented here. Due to their excellent generalization performance, Support Vector Machines
(SVMs)
were used to manage the tradeoff between reduceddimensionality
andincreased classification accuracy. It was determined that features extracted from image
subblocks, as opposed to the full
image,
can yield betterclassification rates when combined in a second stage. In particular, applying SVMs in two stages led toan indoor/outdoor classificationaccuracy of90.2% on alarge database of consumer photographs provided
by
Kodak.Finally,
itTABLE
OF CONTENTS
1. INTRODUCTION 1
1.1 TheSceneClassificationProblem 1
1.2 Background 2
1.2.1 Scene ClassificationResearch 2
1.2.2 Indoor/OutdoorSceneClassification 3
1.2.3 FeatureExtraction 3
1.2.4 FeatureClassification 4
1.2.5 Feature Integration 4
1.3 ThesisContribution 6
1.4 Thesis Outline 6
2. LOW-LEVEL FEATURE EXTRACTION 7
2.1 ColorFeatures 7
2.1.1 LST Co/or Space 8
2. 1.2 LS7 Color Histograms 8
2.2 Wavelet Texture Features 9
2.2.1 Wavelet Transform 10
2.2.2 Wave/ef Basw Selection 13
2.2.3 Wave/e? Texture Feature Extraction 15
2.3 Edge Direction Features 16
2.3.1 Edge Detection 17
2.3.2 Edge MagnitudeandDirection 18
2.3.3 DominantEdge Selection 20
2.3.4 fi(ge Direction Histograms 20
3. LOW-LEVEL FEATURE CLASSIFICATION 21
3.1 Support Vector Machines 2 1
3.1.1 SVM
Training
213.2 Low-Level Feature SVM Training 24
3.2.1 Low-Level Features Extracted FromtheFullImage 24
3.2.2 Low-Level Features ExtractedFroma2x2 Tessellation 25 3.2.3 Low-LevelFeatures Extracted Froma4x4 Tessellation 26
3.3 InferringIndoor/OutdoorClassification From Subblocks 26
3.3.1
Majority
Classification 273.3.2 SynthesisofSubblockSVM Distances 29
3.3.3 Second Stage SVM 30
4. SEMANTIC FEATURE EXTRACTION 32
5. FEATUREINTEGRATION 34
5.1 Bayesian Networks 34
5.2 Indoor/Outdoor Feature Integration 37
6. RESULTS ANDDISCUSSION 39
6.1 ImageDatabase 39
6.2 Low-Level Feature Classification 39
6.2.1 Low-LevelFeaturesExtractedFromtheFull Image 39
6.2.3 Low-LevelFeatures Extracted Froma4x4Tessellation
4J
6.3 Inferring Indoor/OutdoorClassificationFromSubblocks 42 6.3.1
Majority
Classification6.3.2 SynthesisofSubblockSVM Distances 6.3.3 Second Stage SVM
6.4 Feature IntegrationUsingaBayesian Network 4
6.4. 1 Bayesian Network FeatureIntegration
Using
Second Stage SVMresults 466.4.2 Full Bayesian Network FeatureIntegration 6.5 Computational Efficiency
42 44
45
7. CONCLUSIONS
8. REFERENCES
APPENDIX
50
51
52
1.
INTRODUCTION
1.1
The Scene Classification
Problem
The number ofdigital images to be processed, transmitted, and archived is
increasing
rapidly asthe quality and variety ofdigital capture
technology
grow.Consequently,
the need forefficientdigital imagemanagement
technology
hasalsorisenin importance. Aconcerted efforttodevelop
technology
capable ofinterpreting
the content of digitalimagery
has also gained momentum.Successful interpretation of scene content i.e. image understanding has been and remains a
very challenging problem in computer vision. It can be said that modern research in image
understandingevolvedfrom prior researchin imageanalysis [1].
However,
image understandingdeals primarily with high-level
(semantic)
scene informationincluding
people,buildings,
andnatural scenery, for example, while image analysis has
traditionally
focused on low-level imagecontent such as color andtexture.
Thus,
the challenge in image understanding has been to movefrom low-level scenedescription tomoremeaningfulsemanticinterpretation.
An important area of research in image understanding is sceneclassification. The goal in scene
classification is to organize images categorically. Scene classification has been investigated
primarily for image database management applications.
Yet,
any areainvolving
image manipulation, such as digital photofinishing, stands to benefit from successful scene classification. Knowledge of the scene canhelp
improve the performance of such digitalphotofinishingoperationsas colorbalanceandtone reproduction, for instance.
The inference of semantic scene content from low-level features has
traditionally
beenaccomplished through statistical learning. Although this approach has been shown to be
successful, it does have limitations. The limitations rest, in particular, on the reliance on classifier engines to infer the semantic content from low-level features. High classification
accuracy can be achieved ifthere is consistency between the images in the
training
set.This,
however,
implies that theclassification will be less accurateforimages outside thetraining
setespecially those with different scene characteristics. On the other
hand,
when large and diverse image sets are used to train the classifier engines, the classification accuracy also decreasesthis is a pervading challenge in the pattern recognition field in general, there are encouraging
signs.
Specifically,
theincorporationofhigh-level scene informationtogether with thetraditionallow-level image featuresseems a promisingapproachto sceneclassification.
1.2
Background
1.2.1
Scene
Classification
Research
Research in scene classification has been
largely
drivenby
applicationsinvolving
themanipulation of alarge volume of
imagery
[2].Many
image database management systems have beenproposed overtheyearsincluding
QBIC[3],
Photobook[4],
VisualSEEk[5],
NeTra[6],
and MARS [7]. Most ofthese systems are example-based systems in thatthelow-level features of anexample query image are used to find images in the database with similar features. These
low-level features generally include some formof color and texture image analysis.
However,
it iswell known that images with entirely different semantic scene content can possess similar
low-level features. For example, it is entirely possible for a scene containing a school bus to be
confused with a sunset scene using color
features,
such as a color histogram.Thus,
scene interpretation using low-level featuresaloneis usually ineffective. It is forthis reason thathigher level features have been investigated as a means ofimproving
content-based image retrieval and imageunderstanding, ingeneral.Theneedforautomaticsemantic sceneinterpretationand subsequent
indexing
in imagedatabaseswerenotedin [4]. In
[8],
aparadigmfortextureannotation wasproposed, where a texturemodel derived from an image (or image region) is linked to a semanticdescriptor,
e.g. water. The inclusionof, forinstance,
shapeand sketch, as well astheirlocation and size was proposed in [3-7].Yet,
image primitivesincluding
color, texture, and shape, to name afew,
alone cannotfully
bridge the gap to semantic scene understanding. In[6],
text annotations were used to describescene content. Although textannotationscan describesemantic scene content, thecontent canbe
varied, complex, andthus, subjecttointerpretation.
Furthermore,
the semantic description is notautomatic; it depends on human action. These
limitations,
as well as the growing number ofresearch, where images are organized
according to semantically meaningful categories. Scene
classification maybesupervised or unsupervised. In theunsupervisedcase, clusteringtechniques are usedtogroup images accordingto theirsemantic scene content [9,10]. Inthe supervised case, scenes are classified usingpre-defined semanticcategories, e.g. indoorscenes vs. outdoor scenes.
1.2.2
Indoor/
Outdoor Scene Classification
Because,
in general, scene classification is challenging, the problem can be simplifiedby
considering broad scene categories, such as indoor scenes vs. outdoor scenes.
Clearly,
other semantic categories could beexplored and, infact,
categorization according tohuman preferencehas been investigated [11].
However,
indoor/outdoor classification has received significantattention partially because of its importance in image enhancement, as discussed earlier. Szummer andPicardfirstexploredindoor/outdoorsceneclassification andshowed thathigh-level image content could be deduced through statistical classification of low-level image attributes [12]. Laterresearchaddressing indoor/outdoorclassification includesthework ofPaeketal
[13],
Vailaya et al
[11,14],
Savakis and Luo[15],
and Guerin-Dugue and Oliva[16],
toname a few.Althoughtheseapproachesvaryinmanyrespects, some generaltrendscan be discerned.
1.2.3
Feature Extraction
Almost all documented indoor/outdoor scene classification work involves some degree of
low-level feature extraction. In general, indoor/outdoor classification approaches employ color,
texture, and to a lesserextent, spatial
frequency
low-level features. These features aretypically
computed oneither theentire image orimage subblocks. The most common colorfeaturesused for indoor/outdoor classification include colorhistograms[12,13,15]
and color moments [11,14]. In terms of texturefeatures,
the Multiresolution Simultaneous Auto-Regressive(MSAR)
modelwas explored in
[11,12,14,15],
edge direction histograms were considered in[11,13,14],
and Local Dominant Orientation(LDO)
distributions were used in [16]. Spectralfeatures,
such as discrete cosine transform(DCT)
coefficients, have alsobeeninvestigated,
thoughthey
have beenimage,
whereas the other approaches in[11-14]
extract the features from image subblocks.Finally,
in[13],
textual features are derived from text annotations and combined withimage-based featuresfor
indoor/outdoor
classification.1.2.4
Feature Classification
It can be said that there are two
dominating
paradigms for the classification of low-levelindoor/outdoor image features:
1)
featureextraction andclassificationfrom image subblocks,and2)
feature extraction and classification from the full image. If the first approach is used, thesubblock features can be concatenated in order to obtain a feature vector representing the full
image,
as in [11,14,17]. Classification oftheconcatenatedfeature vectorthenyields afull imageindoor/outdoor label.
Alternatively,
the subblock features can be classifiedindependently
[12].This implies that the resulting indoor/outdoor classification foreach subblock must somehow be
combined toproduce an indoor/outdoor label corresponding to the full image. The second, less
common, approach, as in
[15,16],
involves low-level feature extraction and subsequent featureextraction fromthewhole image.
In terms of specific classifier engines, the ^-nearest neighbor
(&-NN)
classifier has beenfrequently
used and shown to produce favorable results for indoor/outdoor classification[12,15,16]. The main
drawback, however,
is that &-NN classifiers are generally slow. A moreefficient Bayesian classification approach was used in
[11,14]
to classify concatenated subblockfeatures.
However,
concatenatedfeature vectors canbe very high dimensional. Not surprisingly,the concatenated feature vectors used in
[11,14]
had on the order of 600 dimensions. Highfeature
dimensionality
can beproblematicandistypically
avoided.1
.2.5Feature Integration
The indoor/outdoor classification methods described in
[11,14,16]
construct a feature vectorcorrespondingto theentire image. The final indoor/outdoorassignment is produced
by
statisticalrelationship between the
low-level
features and the semantic scene content. Approaches ofthis type havetypically
achieved indoor/outdoor classification rates slightly lower than 90%.Specifically,
in[11,14],
indoor/outdoor
classification rates of88.2% and88.7% werereportedfortwo independent image test sets. The work described in
[16]
included two other classes {openandclosedscenes) in additionto theindoorand outdoor classesresulting inanoverall recognition
rate of88.7%.
Many
oftheother referenced approaches involveadditional feature integration (orinterpretation)
before making a final indoor/outdoorcategory assignment. In
[12],
two distinct classifiers were trained for color and texture features extracted from a 4 x 4 image tessellation.Consequently,
two indoor/outdoor labels are assigned to each image subblock one resulting from the color classifier and another from the texture classifier. The final indoor/outdoor classification was decided
by
majority vote. Afinal indoor/outdoor classification rate of90.3% was reported on adatabaseof 1324 images provided
by
Kodak.However,
in[13]
this method was evaluatedon adistinct image database of 1300 news images and the indoor/outdoor classification rate dropped to74.7% significantly lowerthan 90.3%. This
drop
couldbe dueto thefactthatKodak's image database contains a large number of images with duplicate scene content that might inflate theclassification rates. This issue isrevisited insection6.1.
Otherapproaches have integrated the low-level image features described in the previous section with higher level features. For
instance,
Paeket al[13]
proposed a unique approach tointegrate low-level color and texture features computed over image subblocks together with textualinformationaboutthecontent ofthescene.
Using
this technique, anindoor/outdoorclassification rate of86% was reportedon adatabase ofapproximately 1300news images.In
[15],
SavakisandLuo computed colorand texture features analogous to [12]. As in[12],
ak-NN classifier was trained for both the color and texture features.
However,
the features were computed over the entireimage,
rather than image subblocks.Using
this approach,indoor/outdoor classification rates of74.2% and 82.2% were obtained for the color and texture
features,
respectively, on the Kodak image database (minus 15 ambiguous scenes) used in [12].They
also proposed a paradigm for the integration of the low-level color and texture featuresBayes net was used to
integrate
the indoor/outdoor beliefs obtained using color and texturefeaturestogetherwithsemantic
information
thatdistinguishes outdoor scenes fromindoorscenes,such as the presence of grass and/or sky regions in an image. This approach yielded a final
indoor/outdoor
classification rate of 90.1% using grass and sky ground truth and 84.7% usingcomputed grass and skyfeatures.
1.3
Thesis Contribution
The work presented in this thesis proposes an improved approach to indoor/outdoor scene
classification. The
key
contributions ofthis thesisare thefollowing:1)
Lowdimensional,
low complexity featureset2)
Application ofSupport Vector Machines(SVMs)
tolow-level featureclassification3)
ApplicationofSVMstointerpretsubblockbeliefs ina second classification stage4)
Increased overall indoor/outdoor classificationby integrating
low-level and semanticfeaturesusingaBayesiannetwork
1.4
Thesis
Outline
The thesis is organized as follows. Section 2 introduces the low-level feature set tobe used for
indoor/outdoor classification: color
histograms,
wavelet coefficients, and edge direction histograms. Section 3 discusses low-level feature classification using SVMs. In addition, avariety of configurations for feature extraction and classification are proposed. Section 4 describes the use of semantic feature detectors for indoor/outdoor classification. Section 5
presents an introduction to Bayesian beliefnetworks and a paradigm for the integration of
low-level and semantic features for indoor/outdoor classification. Section 6 delineates the results
fromeach approach and compares the classification accuracy oftheproposed systemto existing
2.
LOW-LEVEL
FEATURE EXTRACTION
This sectiondescribes a series oflow-level features for indoor/outdoor classification. Color and
texture attributes constitute the most common low-level features in scene classification.
Many
color and texture analysis techniques exist, and a number of these have been proposed for
indoor/outdoor classification. Popular color features include color moments
[11,14,17],
colorhistograms
[12,15],
color coherence vectors[11,14,17],
and color correlograms [18]. Populartexture
features
include MSAR features[11,13,14,15,17],
edge direction histograms[11,14,17],
edgedirectioncoherence vectors
[11,14,17],
andLDO distributions [16]. Althoughthesefeatureshave been shown tobe effective for indoor/outdoor classification, prior research has focused on
successful resolution of the indoor/outdoor classification problem
first,
andtractability
second.Hence,
the low-level features considered here were assessed not only in terms of theireffectivenessfor indoor/outdoorclassificationbut also in terms oftheircomputationalefficiency.
Three different low-levelfeatures were evaluated: color
histograms,
wavelettexturefeatures,
andedge-directionhistograms.
2.1
Color Features
It is well known that the spectral characteristics of natural and artificial illuminants can vary
considerably [19].
Moreover,
the primary light source in a scene will impact the colorreproductionin aphotograph, be it digital or analog.
Thus,
illuminant differences are among themost important scene characteristics that distinguish indoor scenes from outdoor scenes.
Reconstruction of the spectral characteristics of the illumination source in a scene remains a
difficultproblem
[20]
andtherefore, beyondthescope ofsceneclassification.Instead,
thegoal inindoor/outdoorclassification is to capture coarse scene illumination differences
by
using simple,well-established color features. Color histograms were used in the indoor/outdoor classification
system proposed here because of their simplicity. Based on prior use of color histograms for
indoor/outdoorclassification
[12,15],
theprecision ofthe histograms was reducedby
afactorof2inordertoimprove efficiency. Thechoice of color spaceis of prime
importance
andis addressed2.1.1
LST Color Sp,
aceMany
factors impact the selection of a color space. These factors may include the statistical distribution of color signals, the effect of noise in color coordinates, the effect of light sourcevariations, and theeffect of reflectance variations. Basedon these considerations, the LSTcolor
space, also knownasthe Ohta color space orT-space
[21],
isa goodchoice. The LSTcolorspacehas beenshown tobeusefulinimageprocessingapplications
[22]
andis detailed below:Foran8-bit
image,
oris givenby:L= -^=-(R+G+
B)
(1)
V3
S=-^=.(R-B)
(2)
V2
T=-%=(R-2G
+B)
(3)
V6
255
d=
? r
(4)
Max{R,G,B
}
The three LST components are orthogonal and have unit length. The LST color space is a
luminance-chrominance representation and the color components are thus, approximately
decorrelated. The ST
(chrominance)
components areintensity-invariant,
meaningthey
do notvary with light source
intensity
changes.Furthermore,
the S component ofthe LSTcolor spacerepresents daylight to tungsten illuminant variations.
Finally,
LSTcolor channels represent theprincipalcomponents of a largeselectionof naturalRGBimages.
2. 1
.2LST Color Histograms
Having
transformedaninput RGB image to theLSTcolorspace, colorhistograms foreach oftheL, S,
andT channels, respectively.Where,
b=l,2,...,nc
representsthegray level
bins,
andnc isthetotal number ofbinsper colorhistogram. Theconcatenated
L,
S,
and Thistograms constitutethecolorfeature vector xc:
xc =
[hL(l), hL(2),...,
hL(nc), hs(l), hs(2),..., hs(nc), h^l), M2),...,
h-fa)]
(5)
This color feature approach is analogous to that of
[12,15]
(including
the choice ofcolor space).The
dimensionality
ofthe colorhistogram feature vectoris equalto 2>nc. Thenumber ofbins percolor histogram was set to c=16 for a feature
dimensionality
of 48. In[12,15],
32 bins perhistogram were used for a feature
dimensionality
of96.Therefore,
the color features proposedherehave halfthe
dimensionality
oftheanalogousfeatures usedin [12,15].2.2
Wavelet Texture Features
Texture has
long
been an area of research in image analysis. The numerous texture featuresproposed over the years can be divided into five categories [23]: statistical, geometrical,
structural, model-based, and signal processing features.
Early
approaches to texture analysisrelied mostly on statistical features [24,25]. It has since been shown,
however,
that statisticalmethods do not adequately describe both local and global textural information [26]. Attention
has thus concentrated on signal processing approaches, and in particular, multiresolution
methods, which better preserve both local and global information [27,28]. Ofparticular note is
theaforementionedMSAR model introduced
by
MaoandJain [29]. As noted earlier, theMSARmodel has been used considerably for indoor/outdoor classification [11,12,14,15,17]. Despite
their popularity, MSAR texturefeatures are computationally intensive. A more computationally
efficient alternativeis thewavelettransform[30].
The last
decade,
especially, has produced a host of work on the wavelet transform and itsapplications. Not originallyenvisagedas atool fortextureanalysisperse, theapplicabilityofthe
wavelet transform to texture analysis was first proposed in the pioneering work of Mallat [31].
Wavelet packets (or tree-structured wavelet
transform)
[32],
and waveletframes
(orwavelet
features
performedfavorably
compared to other signal processing texturefeatures,
including
MSARfeatures,
in a recent evaluation [34]. Beyond texture analysis, the use of thewavelettransformhas beenextendedtohigh-level sceneanalysis,as surveyed in [35].
Finally,
it is worth noting that the wavelet transform has also been shown to exist in biological visualsystems [36]. Due to their comparative computational efficiency and positive performance in
texture analysis, waveletfeaturesare consideredhere.
2.2.1
Wavelet
Transform
Multiresolution analysis
(MRA)
refers to theprocess ofdecomposing
a signal intoahierarchy
ofapproximation and detail coefficients. Fundamental to MRA is the fact that the original signal
can be reconstructed perfectly from the approximation and detail functions if the proper
methodology is employed. Simple scaling alone is notfeasible because
frequency
information islost,
thusmaking it impossible toreconstruct theoriginal signal exactly.However,
ifthe scalingis preceded
by
afiltering
stageusing alow-pass(LP)
filterh0(n)
and a high-pass(HP)
filterhx(n),
the original signal can bereconstructedperfectly
by
scalingthe analyzed signal andthenfiltering
itwitha LPfilterg0(n)and a HPfilterg\(n). Thedecompositioncan be done multiple times thus
producingmultiple scaled versions oftheoriginalsignal the aforementionedhierarchy.
The wavelet transform is a specialized formof
MRA,
where the signal is decomposed into a setoffunctions i/fm,n(t) defined by:
Vm,n(t)=
2m/2y/(2mt-n)
(6)
The
family
of functions ofEq.(5)
is generatedby
translating
anddilating
the mother wavelety/(f). The mother wavelet satisfies
\yAf)dt=Q,
and is constructed from a scaling function (fit)accordingto:
V(0=
^h\(kM2t-k)
(8)
k=-Where,
h0(k)
andhx{k)
are the coefficients of the aforementioned LP and HP decompositionfilters,
respectively. If a discrete wavelet transform(DWT)
is used, the filter coefficientsthemselves can be used instead ofthe continuous functions yAt) and <p(J). Biorthogonal wavelet
filter banks are a special class of DWT. In a biorthogonal wavelet representation, the
decomposition filters
h0(n)
andhx{n)
satisfyand are relatedby:5>o()
=i(9)
n
2(-l)"-1/z1(n)
=2(10)
n
hl(n)
=(-l)nh0(l-n)
(11)
Thereconstruction filtersg0(n) andgi(n)are relatedto
ho(n)
andh^n)
accordingto:g0(n)=
(.-iyhl(l-n)
(12)
g1(n)=
(-l)n-1ft0(l-)
(13)
The biorthogonal denomination stems fromthefact that
h0(n)
andg\(n) are mutuallyorthogonalas are
h{(n)
andgo(n). Inaddition,biorthogonal filter banks are symmetric (i.e. have linear phase)and areapproximately decorrelated.
The 2-D DWT is an extension of the 1-D case. In
fact,
a separable 2-D DWT can be easilyimplemented
by
applying the 1-D filters (described above) along the twodimensions
of thesignal. For a given image
f\x,y),
a one-level, 2-D separable DWT decomposition can beimplemented
by
convolving therows and columns ofJ\x,y)
with combinations ofh0(n)
andhx(n),
oo oo
LLX
(x,
v)=X S
/(*.
J)K
d
-i*)h
U
-2y)
(=-;LHl(x,y)=
J
JJf(i,j)h0(i-2x)hxU-2y)
HLl(x,y)=^^jf(i,j)hl(i-2x)h0U-2y)
i=-~j=-////1(^y)=XS/0".M0-2^O'-2y)
(14)
(15)
(16)
(17)
Where, LL,
LH,
HL andHH stand forlow-low, low-high, high-low,
andhigh-high,
respectively.Specifically, LLx{x,y)
represent the approximation coefficients andLH:(x,y), HL\(x,y),
andHHi(x,y)
representthedetail coefficients. The subscriptdenotes the decompositionlevel (in thiscase 1). Figure 1 showsthe2-DseparableDWT implementationgraphically.
M/2xN/2
MxN
rows
TJ-^N^)
columns^TT-(jg)-
LL!
ft!
4-2
HL,
aTT-(^2)
columns>
/fa
H4-2LH,
[image:18.613.108.496.399.590.2]>
A?
-H4-2HH,
Figure 1. 2-DseparableDWT implementation.
Wavelet coefficients are
typically
depicted using the pyramid structure shown in Figure 2. Ascan be seen from Figure
2,
for each level ofdecomposition,
it is thelow-frequency
coefficientsthat are furtherdecomposed. This implies that the final decomposition at level Kwill consistof
one coarse approximation (the final
low-frequency
coefficients) and K sets of detail (highLL2
LH2
LH!
HL2
HH2
[image:19.613.230.389.90.253.2]HL!
HHi
Figure 2. Two-levelpyramidDWTstructure.
2.2.2
Wavelet Basis Selection
Animportantpoint ofconsideration whenemployingthe DWTis theselection of a wavelet basis
(i.e. filter bank).
Many
wavelet filter banks exist, each possessing distinct properties.Biorthogonal wavelets(discussed intheprevious section)have been shown tobe useful for image
compression
[37]
andwill be used in the newJPEG2000compression standard [38]. In the areaof texture analysis,
however,
no formal evaluation of wavelet filter banks had been conducteduntil recently.
Daubechies'
filter banks have
traditionally
been a popular choice for wavelettexture analysis [32,39,40,41].
Yet,
the selection of a wavelet basis for texture analysis haslargely
been subjective or arbitrary. In[42],
Mojsilovic et al, attempt to define an optimalwavelet basis for texture characterization. Their study showed,
first,
that the selection ofdecomposition filters notably impacts texture characterization.
Second,
in comparing 19orthogonal and biorthogonal wavelet
filters,
they
found that biorthogonal filters outperformedorthogonal filters. A simple study described below provides further motivation for the use of
biorthogonal,
as opposedto, orthogonalfilters.A simple test imagewith edges oriented in four directions
(0, 45,
90,
and 135degrees)
is shownin Figure 3. The edges in the image have a width of one pixel. The simple test involves a
waveletdecompositionofthe testimage using
Daubechies'
popular
4-tap
orthonormalfilter(db4)
andthe5/3 biorthogonal filter(bior5/3). The
LHX
andHLX
waveletcoefficients corresponding tocorresponding
to thebior5/3 decomposition
are shownin Figure4b. As canbe seen fromFigure4a,
aninteresting
artifact appearswhen using the db4 filter.
Namely,
the db4 filter is unable toproperly extract the edges oriented at 135 degrees (the first quadrant inthe test
image),
whereasthe
bior5/3
filters does. This is relatedto thefrequency
response ofthedb4 filterand is clearly,anundesirableresult.
Figure3. Edgepattern usedforwaveletfilterevaluation.
[image:20.614.250.399.215.367.2](a)
(b)
Figure 4.
LHX
andHLX
coefficientsusingthedb4 filter(a)
andthebior5/3 filter(b).Another consideration is computational efficiency. Shorter filter lengths
are, obviously, more
computationally efficient as
they
requirefewernumerical operationsper pixel.Considering
bothcomputational
tractability
and optimal texture characterization, thebior5/3
wavelet filters wereselectedfortheproposedindoor/outdoorclassification system.
Finally,
thebior5/3
filter is one of [image:20.614.87.562.469.600.2]filter may provide
further
efficiency gains when the indoor/outdoor classification system isimplemented
in conjunction with the JPEG2000 codec. The bior5/3 decomposition filtersh0(n)
and
hi(n)
are shown in Eq.(18)
and (19). In this casethey
are not shown in normalized form inorderto
illustrate
thefactthatthey
areintegercoefficients.h0(n)
=[-l
2 62-1]
hx(n)
=[l -21]
(18)
(19)
2.2.3
Wavelet
Texture Feature Extraction
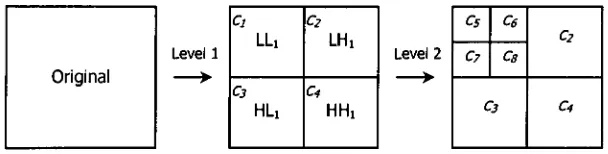
Let c2, cs, c4, c5, c6, c7, and cs represent the subband coefficients of the two-level wavelet
decompositionas shownin Figure 5.
Level 1 Ci
LL! LHi
Cs
HLi
C, HHi
Level2
CS C6 C2 c? Cs
[image:21.613.151.455.381.458.2]c3 c*
Figure 5. Coefficient labels forwavelettexturefeatureextraction.
As can be seen from Figure
5,
c2=LHl(x,y), c3=//L1(x,y), cA=HHx{x,y), c5=LL2(x,y), c6=LH2(x,y),c7=HL2(x,y),andc&=HH2(x,y). Coefficientsetc5 isa
low-frequency
approximation ofthe originalsignal. The other coefficients provide
directionally
correlated measures of thehigh-frequency
signal content. Because natural textures contain mostly mid to high
frequency
information,
thelow-frequency
coefficients are notinherently
useful for texture description.Thus,
rather thanusing the raw
LLiix,y)
wavelet coefficients, set c5 is redefinedby filtering
LL2(x,y)
with theLaplacian filter:
M N
c5=YjYj LL2
G'
Ml
(*~
,y~
J)
.=1 ;=1Where,
MandNarethedimensions
ofLL^y)
andhL{x,y)
istheLaplacian filter:hL(x,y)
=-1 -1 -f -1 8 -1 -1 -1 -1
(21)
Because the Laplacian filter provides an isotropic measure of the
high-frequency
signalinformation,
the filtered coefficient set c5 can be regarded as a measure ofnon-directional highfrequency
energy in the image.Ultimately,
the texture features are obtainedby
computing thesubband energy for all wavelet coefficients
(including
the Laplacian filtered c5 coefficients)accordingto the
following
general expression:M N
ek
1 M _"_
= k=2,X..AK
(22)
Where,
M and N are the image dimensions of coefficient ck, and K is the number of decomposition levels (in this case 2).Therefore,
seven wavelet texture features are obtained. This represents a reductionby
a factor of 2 compared to the 15 MSAR features used in[11,12,14,15,17]. Thewavelet texturefeature vectorx,is definedas:
\,=
[e2,e3,...,e8]
(23)
2.3
Edge Direction Features
It has been observed that many types of scenes have directional edge signatures. For
instance,
scenes containing man-made structures (e.g. city scenes) tend to have edges with dominant orientations. On the other
hand,
images with a predominance of natural scenery (e.g. landscapescenes) tend to havemorerandomlyoriented edge content.
Hence,
it is reasonabletoassume thatdirectional edge features might be strong discriminators between certain types of scenes. Not
for
indoor/outdoor
classification in [9,12,13]. Otherdirectionally
sensitive features have alsobeen used for
indoor/outdoor
classification,including
the LDO distributions introduced in [16].In
keeping
with the goal of computational efficiency, edge direction histograms are consideredhere.
The process involves four basic steps:
1)
edgedetection,
2)
computation of the edge magnitudeand
direction,
and3)
selection of dominant edges, and4)
construction of the edge directionhistogram. The method of Lee and Cok
[43],
which provides a framework fordetecting
boundaries in color images and estimating their magnitude and
direction,
is adopted here andsummarizedbelow.
2.3.1
Edge Detection
Given an image
j\x,y)
with three color attributes(R,G,B),
the individual color planes can bedefinedas:
r(x,y)=fix,y) e R
(24)
g(x,y)=fix,y) e G
(25)
b(x,y)
=f{x,y) G B(26)
The horizontal edges can be obtained
by
convolving each of the above color planes with aderivative filter
hx(x,y),
thusyieldingthepartialderivatives:-\ M N
^-
=yYr(i,j)hx(x-i,y-j)
(27)
MM
-\ M N
7T
=EE
*<'*<*-'>-./)
(28)
dx /=1 ;=1
M N
Where,
M and Ndenote
the row and column dimensions ofJ\x,y).Similarly,
the vertical edgesare obtained
by
convolving
the color planes with aderivative filter hy(x,y):^_ m N
,
=J\Y,r(i,j)h
(x-i,y-j)
M N
-r-=
y,J\
s(*.
My
(*-*.y
-J)
y
ri%
db M N
V=
EE
W*
My
(x
-i,y-j)
y mm
(30)
(31)
(32)
The filters
hx(x,y)
andhy{x,y)
can be any derivative filters. The well-known Prewitt filters wereused
here,
where:hx(x,y)
-1 -1
0 0 0
1 1 1
(33)
K(x,y)
=-1 0 1
"
-1 0 1
-1 0 1
(34)
Finally,
itshould be noted that theimagef\x,y)
wasfirst smoothed usinga Gaussian filter beforeapplying filters
(33)
and(34)
inordertosuppresstheeffect of spurious edges.2.3.2
Edge Magnitude
andDirection
Having
estimatedthehorizontal and vertical edges, a matrixD composed ofthepartial derivative~dr
dx
oyog
dg
dx
oydb
db
dx
oy\
D= Z*. ^
(35)
The edge magnitude and direction can be obtained from principal component analysis of the
matrix product
DTD,
where the largest eigenvalue corresponds to the edge magnitude. Thelargesteigenvalue
X
andthustheedge magnitudeis givenby:X
= 2La+b+yl(a+
b)2
-4(ab-c2)
(36)
Where,
+
fdg}2 fdb^2
\0XJ
+
KdXj
/3^2
/aV /a^^2
b=
dr_
+dg_
oy)
+ db
_
dr dr
dg dg
db db
dx
dy
dx
dy
dx
dy
(37)
(38)
(39)
The eigenvector corresponding to the largest eigenvalue
X
provides the edgedirection,
which inturn can be used to compute the edge angle. The partial derivatives
dr/dx, dr/dx, db/dx, drldy,
dgldy,
anddbldy
havevalues associated with all points in f{x,y).Thus,
each pixel location inthe2.3.3
Dominant Edge
Selection
It is not meaningful to construct an edge direction histogram without first analyzing the edge
magnitude and
determining
whether or not it is a dominant (i.e. significant) edge.Canny'
s
popular edge detector
[44]
can be used for this purpose. Candidate points are those that arethelocal edge magnitude maxima along the corresponding edge direction. A candidate point is
regarded as an edgeifits edge magnitudeisgreaterthanalowthreshold
T,
and isconnectedtoatleastone pointthathasan edge magnitude greaterthanahighthreshold T2. Thethresholds
Tj
andT2
aretypically
determined empiricallydepending
onthedesired degreeof edge selectivity.2.3.4
Edge Direction
Histograms
An edge direction histogram is accumulatedonly for those points that were marked as dominant
edges according to thecriteria ofsection2.3.3. Let
he{b)
be theedge directionhistogram,
where,b-l,2,...,ne
represents theedge direction bin element, andne is the totalnumber ofbins per edgedirection histogram. In other words, ne defines the number of edge angles to include in the
histogramhe. Theedgedirection featurevector\eisgiven by:
xe=
[he(l),he(2),...,he(ne),MN-^he(b)]
(40)
bThe last element in the feature vector (which is not part of the edge direction
histogram)
representsthenumberofnon-edgepoints, whereMandNarethe row and columndimensions of
the imageor imagesubblock. The
dimensionality
oftheedgedirection histogram isne + 1. Thenumberofbins per edgedirection histogramwas setto ne=36, forafeature
dimensionality
of37.Thisis roughly halfthe
dimensionality
ofthe analogous edge direction histograms of[11,14,17],
where 5
3.
LOW-LEVEL FEATURE CLASSIFICATION
3.1
Support
Vector Machines
The Support Vector Machine
(SVM) [45,46]
is a new method of parameterization offunctions,
and therefore has application outside the realm of predictive learning. It has been called a
universal
learning
procedure because it can be used to learn various representations such asneural networks, radial basis functions
(RBF),
polynomial estimators, etc. In the patternrecognition context, SVMs have been used for
handwriting
recognition[47],
text categorization[48],
and face detection [49]. SVMs have been shown tohave equivalent or significantly bettererror rates than comparative classification methods [45]. One characteristic, in particular,
separates SVMs fromother classification paradigms optimization ofthe separating hyperplane.
This optimization (discussed in the
following
section) results in better generalization beyondthetraining
dataset. Forthesereasons, SVMswere usedin the indoor/outdoorclassification schemeproposedhere.
3.1.1
S
VTS/L
Training
In preceding sections, a colorfeature vectorxc, a wavelettexture featurex,, andanedge direction
feature vector xe were introduced. A general feature vector x will be used in this section for
discussion purposes only. It should be noted that the discussion applies equally to the feature
vectorsxc, x andxe.
Supposethere are/observationsdescribed
by
a feature vectorx, sRd,
i=l,...,l and the associatedtruth y, e {-1,1 } Ifobservation icorresponds to an outdoor
image,
then y,=l, otherwise y,=-l.The objective is to find some way of separating the observations such that there is a clear
distinction betweenthetwoclassesy, (i.e. indoor vs. outdoor). Thereare
infinitely
many ways ofseparating the
data,
however,
the separation that yields the best generalization performance isdesired. To illustrate this
further,
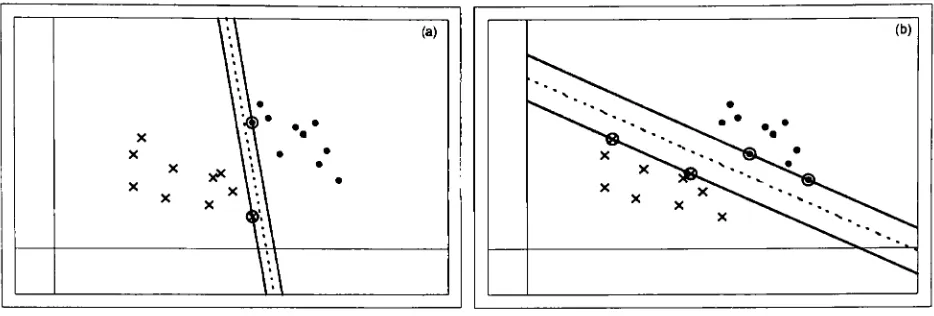
a simple linear classification is shown in Figure 6. Figure 6adepicts a successful separation ofthe
data,
with minimal margin, where themargin is the sum ofthe perpendicular distances from the closest point of each class to the separating hyperplane.
Intuitively,
the case in Figure 6b will have better generalization performance (lower [image:28.613.73.540.148.306.2]generalization error).
Figure 6. Successful SVM linearclassification with sub-optimal (a)andoptimal (b)margins.
Forthelinear-separablecase shownin Figure
6,
thehyperplane thatseparatesthedatasatisfiesw x+b=0
(41)
Where,
w is normal to thehyperplane,
and|b|/|w|
is the perpendicular distance from thehyperplane to the origin. The parameters, w and
b,
are determinedby
training
the SVM. Theoptimalhyperplaneis obtained
by
maximizingthe marginsubjectto theconstraintsXj- w + b> +1, fory,=+1
Xi w +b>-1,fory,=-1
(42)
(43)
which canbecombinedinto
y,(x, w +
b)
-1 >
0,
Vi(44)
All points that satisfy
(42)
lie on thehyperplane H,: x, w + b= 1.Points satisfying
(43)
lie onthe hyperplane H2: x,; w + b =-1. Hyperplanes
Hj
andH2
are shown in Figure6 as solid lines.are the points with an additional circle. The perpendicular distance from both
H,
andH2
to theshattering hyperplane
(41)
isl/||w||,
and thus,themargin issimply 2/||w||.As stated earlier, the goal is to maximize the margin
during
SVM training. This optimizationproblem canbesolved using Lagrangemultipliers. Thefullderivation is elegantly laidoutin
[43,
44]. Forthesake of
brevity,
onlythesolutionisnoted below:/(x)
=JA,7;xrx,.
+b(45)
i=\
Where,
A,
are the Lagrange multipliers. As can be seen, equation(45)
is a function of theobservation (or
feature)
vector, x, and can be interpreted as thedistance (in feature space) ofthepoint x fromthe separating
hyperplane,
ordecisionsurface(41).Up
tothis point, onlythelinear,
separable SVMcase has beentreated. A solution similarto(45)
can be obtained for a non-linear SVM using a kernelfunction K(x,Xi). The reader is again
referred to
[14,
19]
for full derivations. Thenon-linearSVMsolution is:f(x)
=^XiyiK(x,xi)
+b(46)
i=i
Clearly,
Eq.(46)
is similar in formto Eq.(45)
and infact,
can be said to encompass the linearcase, where
A"(x,x,)
= xTx,. Somecommon kernel functions fornon-linearclassification are listed [image:29.613.157.455.629.692.2]in Table 1.
Table 1. Possible SVM kernelfunctionsandtypeof classifier.
Kernel Function Classifier
/C(x,x,)
=exp(-|x-x,|2/a2) Gaussian RBFK(x,x.)
= (xTx,-+If
Polynomial ofdegreepK(x,Xi)
=tanh(v(x'x/) +a) NeuralNetworkAttention is now given to the non-separable data case. Most real life problems are of the
decision surface without some misclassification.
Furthermore,
when faced with the non-separable case, the above equations have no solution. To obtain a feasible solution forthe non-separable case and to manage the tradeoffbetween the margin and misclassification, constraints(42)
and(43)
(forthelinearcase),are relaxed asfollows:xrw + b>+1-4, fory,=+1
(47)
x, w+ b>
-l+, fory,=-1
(48)
&>0Vi
(49)
For an error to occur , must exceed unity and
hence, ,
is an upper bound on the number oftraining
errors. Acost parameter C is thenintroduced,
where C>0,
such that the function to beminimized changesfrom
||w||2/2
to||w||2/2
+CZ,. The optimizationproblemcan againbe solved withLagrange multipliers, where0<X,< C. Thecost parameter is determined beforetraining
by
the user; alarger Ccorrespondstoahigher penalty forerrors. A similarapproach is used forthe
non-linear SVM. For a more complete description of the solutions
incorporating
the cost parameterC,
thereaderis again referredto [45,46].3.2
Low-Level Feature SVM
Training
An RBF kernel (see Table
1)
was used to train the color, texture, and edge direction featuresseparately. The choice of kernel was arbitrary. The SVMs were trained using the "SVMfu"
algorithm developed at MIT's Artificial Intelligence Lab [50]. The SVMs were trained using low-level features extracted from the full
image,
as well as image subblocks from a 2 x 2tessellation and a 4 x 4 tessellation. In each case, the feature vectors were normalized to zero mean and unitvariancebeforetraining.
3.2.1
Low-Level Features Extracted From
theFull Image
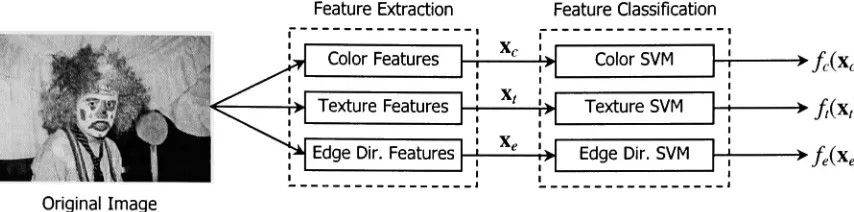
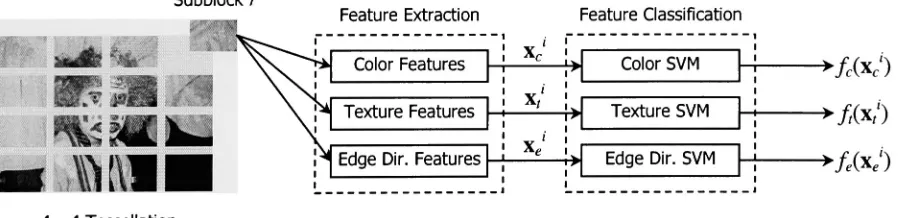
In this configuration, the color, texture, and edge direction feature vectors xc, x and xe
distance measures
/c(xc), /,(x,),
and/e(xe) respectively, which represent the indoor/outdoorbeliefsfortheimage in question. Theprocessisshown schematically in Figure 7.
FeatureExtraction Feature Classification
ColorFeatures
Texture Features
Edge Dir. Features
Color SVM
TextureSVM
Edge Dir. SVM
-?/c(xc)
+
ffa)
+M*e)
Original Image
Figure7. Low-level featureextraction and classificationfromthefull image.
3.2.2
Low-Level
Features
Extracted From
a2
x2
Tessellation
In this case, the image is divided into 4 subblocks. For a given M x Nresolution
image,
eachsubblocks willbe of sizeMI2 xN/2. Let i=l,2,...,4 denotethesubblocks of a source image. The
feature vectorsxc', xj, andxj are extractedfromeach subblocki and classified separately. SVM
distancemeasures
fc(xc'),f,(x,'),
and/e(x,')arethus,also obtainedforeach subblocki.Feature extraction from image subblocks can be expected to achieve less accuracy compared to
the full image
features,
as there are fewer and weaker signatures. Although less accurate,subblock classification offers further alternatives to
inferring
the final indoor/outdoorclassification. For
instance,
the subblock classification results can be combined in a variety ofways and, as shown in
[12],
improve the final indoor/outdoor classification. This is the majormotivation for exploring subblock classification alternatives. Feature extraction and
[image:31.614.93.520.154.260.2]Subblock/
2x2 Tessellation
Feature Extraction
Color Features
Texture Features
Edge Dir. Features
Feature Classification
Color SVM
Texture SVM
Edge Dir. SVM
-?/cOO
-?/,(x/)
+feM
Figure 8.Low-level featureextraction and classificationfroma2x2 imagetessellation.
3.2.3
Low-Level Features Extracted From
a4
x4Tessellation
A 4x4tessellationof anMxNimageresults in 16subblocks ofMIAxM4pixels. As
before,
thefeature vectors xc', x/, and xe\
i=l,2,...,16,
are extracted from each subblock and classifiedseparately. A further
drop
in classification rates can be expectedfromthe 4 x 4 as compared tothe 2 x 2 tessellation because the subblocks are smaller.
Again,
SVM distance measuresfc(xcl),
ft(x,'),
andfe(xe') areobtainedforeachimage subblock. Itshouldbenotedthat a4x4tessellationwas usedin [12].
Subblock /
i,
Ml
4x4 Tessellation
Feature Extraction
Color Features
Texture Features
Edge Dir. Features
Feature Classification
Color SVM
TextureSVM
Edge Dir. SVM
->/c(xc')
->//(x/)
[image:32.614.84.541.89.203.2]+feOO
Figure 9. Low-level featureextractionandclassificationfroma4x4 imagetessellation.
3.3
Inferring
Indoor/Outdoor
Classification
From
Subblocks
As intimated earlier, when low-level features are extracted from the full
image,
the classifier [image:32.614.84.533.477.586.2]shown in
[12]
that higherindoor/outdoor
classification rates could be achievedby
classifyingfeatures
extracted fromimage
subblocks and then combining the results in a second stage.Specifically,
the approach used in[12]
involved
classifying color and texture features extractedfrom image subblocks with a
fc-NN
classifier and then combining the subblock results usingmajorityclassification toobtain afinal indoor/outdoor label foragivenimage.
Given the aboveremarks, three approaches to synthesize subblock beliefs were evaluated for the
indoor/outdoor classification system proposed here. The first is the majority classification
scheme proposed in
[12],
which will serve as abenchmark.3.3.1
Majority
Classification
Assume color, texture, and edge direction feature vectorsxc', x/, and
xe'
are extractedfrom each
subblock i of a given image tessellation. The feature vectors are then classified using the
corresponding
SVM,
in turn producing the distance measures/c(xc'), //(x/),
and fe(xe'). Asdescribed in section
3.1.1,
these values measure the distance of a given feature vector from theseparating hyperplane the trained SVM decision
boundary
in feature space. A large positivevalue indicates the feature vector has strong outdoor scene cues.
Conversely,
a large negativevalueindicates thefeaturevectorhas strong indoor scene cues.
Thus,
hard indoor/outdoor labelsLc',
L,',
and Le'can be obtained for each subblock i using a hard limiter i.e.
thresholding
thedistance measuresatzero:
4=
r
fA<)>0co)
[0,
otherwiseI}-{1 /'(X;)>
(51)
[0,
otherwiseV,-\l- f->
A label equal to one
indicates
the subblock represents an outdoor scene. After computing theaboveequations, each subblockhas three
indoor/outdoor
labels,
one foreach feature type. Let Srepresentthesummation of
labels
Lj, L/,
andLj
over all subblocks:S =
4+4+4
(53)
/=i
Where,
B isthe total number of subblocks (e.g. 5=4fora2x 2tessellation). An indoor/outdoorlabelcanthusbeobtainedforthewholeimage accordingto:
L=
[1,
S>3B/20,
otherwise(54)
If,
forexample, color, texture, and edgedirection features are usedin a4 x4 image tessellation,there will be 35 subblock labels. The label L=l
(outdoor)
is assigned if the subblock labelsummation S is greater than halfthenumber oftotal subblocks; in thiscase 35/2=24.
However,
not all low-levelfeaturesneedbeused. For
instance,
onlytwoofthelow-level features mightbeextracted and classified. In this case,
25/2=16,
and therefore, the label L=l(outdoor)
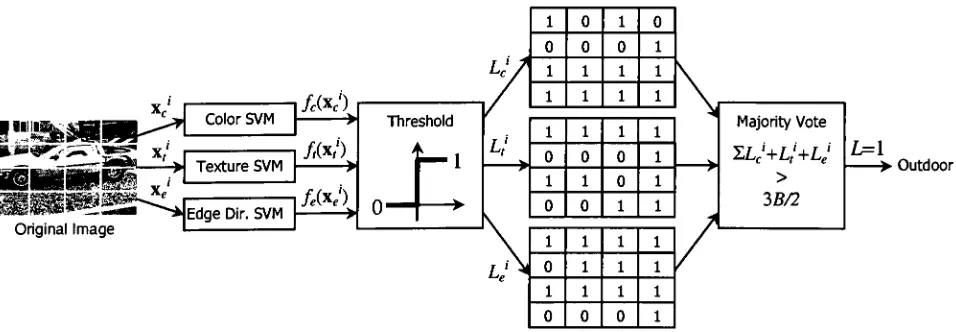
would beassigned if 5>16. The majorityclassifier is shown graphically for a 4 x4 tessellation in Figure
10.
1 0 1 0
0 0 0
1 1 1
\
fc(*J) 1 1 1
V
Xc
ColorSVM Threshold
\
MajorityVoteZLj+LJ+Lj
>3B/2
1 1 1
/,(*/) 0 0 0
Texture SVM
"^^lasffl*^
\
1 1 0
/
Original Imagefe(Xe')
Edge Dir. SVM > o
f
? 0 0 11 1 1
/
o 1 1
/
1 1 1
0 0 0
L=\
[image:34.613.85.563.518.684.2]Outdoor
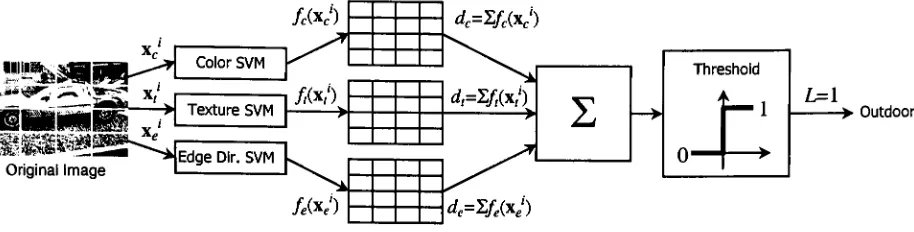
3.3.2
Synthesis
of
Subblock SVM Distances
This approach is very similar to majority classification except that the SVM distance measure is
exploited. In themajorityclassificationapproach, hard indoor/outdoorlabels
Lj, L/,
andLj
wereobtained
by
thresholding
/c(Xc'),
/,(x/),
and/e(xe').Doing
so,however,
is equivalent to quantizingthedistancemeasures, thus
incurring
alossofinformationandprecision. Given that/c(xc'),/,(x/),andfe(xe') aredistance measures corresponding toall subblocks,
they
can be summed to obtain aglobal distance measurefortheentireimage. Inother words, the subblockdistance measurescan
be synthesized to obtain a value that represents the indoor/outdoor belief for the full image.
Define threenewdistance measurescorrespondingto theentire image:
dc=tfc)
<55>
;=i
*,=/,(*!)
(56)
1=1
de=f,fM)
(57)
i=i
Where,
5 again represents the total number of subblocks in the tessellation. Abinary
indoor/outdoor label can now obtained fromthe above synthesized distance measures according
to:
l=
|1,
dc+dt+de>0(5g)
0,
otherwiseAs
before,
a label L=l corresponds to an outdoor scene.Summing
the subblock distancemeasures before binarization reduces the impact of any borderline subblocks, as opposed to
forcing
ahard label. This approach can stillbe usedevenifoneor more ofthelow-level featuresis eliminated. If the edge direction features are excluded, for
instance,
the label L would beobtained
by
thresholding the sum ofdc
andd,
only. The subblock synthesis approach is shownal
>Outdoor
Original Image
/f(xe') de=Zfe(xJ)
Figure 11. Graphic illustrationofthesubblockSVMdistancesynthesis approach.
3.3.3
Second Stage SVM
In preceding sections, two approaches were proposed to combine low-level features extracted
from image subblocks. In each case, the SVM subblock classification results were combined in
distinct ways in order to deduce the indoor/outdoor classification for the full image. A third
approach is to use a classifier engine to generalize the subblock classification results andinfer a
final indoor/outdoorclassificationforthefull image.
In this approach, the subblockSVM distance measures
fc(xc'),f,(x,'),
andfe(xe') are synthesized asin section 3.3.2 in orderto obtain distance measures
dc, dt,
andde
using Eq.(55)
- (57). Thesedistance measures are then used to form a new color, texture, and edge direction feature vector
xcte.
Xc/e
-[dc-, dt, de\
(59)
A new RBF SVMis then trainedusingthe feature vector xcte. The output ofthis
SVM, fc,e(xcte),
thus represents an indoor/outdoor belief for the entire image. It can be said that the overall
process is atwo-stage approach. The firststage involvesextraction andclassification ofthe
low-levelsubblockfeaturesxj, x/,and xj. Thesecond stageinvolves synthesizingthe subblockSVM
distance measures
/c(xc'),/,(x/),
andfe(xj)
in ordertoobtainthefull imagecolor, texture,and edge [image:36.613.84.541.91.207.2]stage SVM in order to obtain the final indoor/outdoor classification. The two-stage SVM
approachis showngraphically fora4x4tessellationin Figure 12.
Original Image
d^ZfcxJ) SECONDSTAGE
4=2/,(x/) /(xJ Final
> Indoor/Outdoor Classification
[image:37.613.72.544.161.272.2]de=Xfe(xJ)
4.
SEMANTIC
FEATURE EXTRACTION
Althoughclassifier engines can beused toestablish a relationship between image primitivesand
semantic scene
understanding
(e.g. indoor vs.outdoor), the approach can be enriched
by
incorporating
additionalknowledge
that is pertinent to the semantic scene understanding in question. Inthis case, thesemantic scene understanding inquestion is whether or not aparticularscene is indoor vs. outdoor. Additional knowledge thatis pertinent tothis taskmightbe whether or notthe scene contains grass and/or sky regions, for example. Ifthe scene does contain grass and/or sky, then it canbe assertedthatit is an outdoor scene. Thisassertion isnot categorical, as thereare ambiguous cases such as photographstaken throughwindows.
However,
thesecases are infrequent and generally without resolutioninvolving
philosophical discourse.Hence,
it isreasonable to assume that additional knowledge ofthe scene might reinforce the indoor/outdoor
categorization obtained using low-level image analysis. Two inevitable questions arise. Can
additional knowledge ofthe scene be obtained reliably? And if so, how can this knowledge be
incorporated withtheaforementionedlow-level features?
Fortheapplication considered
here,
semantic scene content such as grass,sky,buildings,
cars andpeople can be said to represent mid-level scene information in that it is less general than the
indoor vs. outdoor labeling. Prior image understanding research has shown that such mid-level
scene content can be detected reliably. Some examples include vegetation detection
[51],
skydetection
[51,52],
and peopledetection [53].Furthermore,
models forprobabilisticintegration of sceneinformationalsoexist.Specifically,
the use ofBayesiannetworks for feature integration isdiscussed insection 5.
Not all mid-level scene information is useful in
determining
whether or not a given image is an indoorscene or anoutdoor scene. Forexample, peoplecan bepresent in both indoorand outdoorscenes.
However,
only on rare occasions can grass be found indoors (e.g. a domed stadium).Similarly,
sky regions are almost always present in outdoor scenes. Given this reasoning, theTo propose a scheme for the
detection
of grass and sky in images is beyond the scope ofthiswork.
Instead,
reliable grass and sky ground truth associated with animage databaseprovidedby
Kodak (see section
6.1)
was used. The sky ground truth is further qualified as blue sky, cloud,mixed sky, twilight, or other sky. The use of ground truth provides an upper bound on the
indoor/outdoor
classification accuracy. To ascertain how accurate the indoor/outdoorclassification might be with computed mid-level
information,
grass and sky detection schemesdeveloped
by
Kodakwere used. Kodak'sskydetection algorithmis asdescribed in [52]. Thoughundocumented, the grass detection algorithm employs color and texture information to detect
[image:39.614.91.531.296.441.2]grass regions. Anexampleimage andits associated grassground truthare shownin Figure 13.
5. FEATURE INTEGRATION
In this section, the process of
integrating
low-level features (as thosedescribed in section2)
andsemantic
features
(as thosedescribed
in section4)
for enhanced indoor/outdoor classification is discussed. An introduction to Bayesian networks probabilistic inference engines is firstprovided.
5.1
Bayesian
Networks
Bayesian networks, also known as belief networks, or simply Bayes nets, provide a powerful
framework for the description of complicated probabilistic systems through simple conditional
relationships [54].
They
have become an important tool in the field of artificialintelligence,
which is ruled
by
uncertainty.Bayes'
theorem is one of the celebrated results of probability
theory. It states that the posterior (or a posteriori) probability is described
by
the jointprobability, which in turn, is described
by
theconditional probability and the prior (orapriori) probability:Pvni!i.*5i*>.2\Em
(60)
1
P(E)
P{E)
The latterpart ofEq.
(60)
is the well-knowninversion formula. In words,it states thatthebeliefhypothesis H is true, based on new evidence E (posterior probability), can be expressed
by
theproduct oftheprevious belief H is true (priorprobability) with thelikelihood thatEwill occurif Histrue(conditionalprobability).
The importance of this result is that P(H
\
E),
atypically
difficult quantity to assess, can beobtainedfromquantities thatare notonly moreaccessible, but usually availablefromexperiential knowledge.
Yet,
often theevidenceE isnotasingle variablebutrather,a set ofvariables. As thenumberofevidence variables
increases,
computation ofthejoint probabilitybecomesintractable.Furthermore,
it has been observed that a purely mathematical description of probabilisticreasoning. Perhaps the most
striking limitation
of numerical approaches toprobability is the
assessment of
independence.
Using
the previous example, ifthe hypothesis His independent oftheevidence
E,
then,P(H, E)
=P(H) P(E)
(61)
And thus, theposteriorprobabilityis equalto thepriorprobability,
P(H\E)
=P(H,E)
=P(H)
(62)
P(E)
Inpractice, independence is gauged
by
computing theproductP(H)P(E)
anddetermining
whetheror not it is equal to the joint probability. Although more
formal,
it is impractical and againdeviates from human intuition. In
fact,
humans are quickly and confidently able to determineindependence without computing