Unsupervised Multi-Label Text Classification
Using a World Knowledge Ontology
Xiaohui Tao1, Yuefeng Li2, Raymond Y. K. Lau3, and Hua Wang1
1Centre for Systems Biology, University of Southern Queensland, Australia 2
Science and Engineering Faculty, Queensland University of Technology, Australia 3
Department of Information Systems, City University of Hong Kong, Hong Kong 1{xtao, hua.wang}@usq.edu.au, 2
[email protected], [email protected]
Abstract. The development of text classification techniques has been largely promoted in the past decade due to the increasing availability and widespread use of digital documents. Usually, the performance of text classification relies on the quality of categories and the accuracy of classifiers learned from samples. When training samples are unavailable or categories are unqualified, text classification performance would be degraded. In this paper, we propose an unsupervised multi-label text classification method to classify documents using a large set of categories stored in a world ontology. The approach has been promisingly evaluated by compared with typical text classification methods, using a real-world document collection and based on the ground truth encoded by human experts.
1
Introduction
The increasing availability of documents in the past decades has greatly pro-moted the development of information retrieval and organising systems, such as search engines and digital libraries. The widespread use of digital documents has also increased these systems’ accessibility to textual information. A fundamen-tal theory supporting these information retrieval and organising systems is that information can be associated with semantically meaningful categories. Such a theory supports also ontology learning, text categorisation, information filtering, text mining, and text analysis, etc. Text classification aims at associating tex-tual documents with semantically meaningful categorises, and has been studied in the past decades, along with the development of information retrieval and organising systems [11].
stream of documents; the descriptive and discriminative capacity of categorisa-tion reduces noise in classificacategorisa-tion, which is caused by sense ambiguities, sparsity, and high dimensionality of the documents [7]. Text classification performance is also affected by the topic coverage of categories. An inadequate category may be assigned to a document if an in-comprehensive set of categories is employed, because non-adequate categories can be found. The performance of text classifi-cation relies upon the descriptive and discriminative capacity of categories and the accuracy of classifiers learned from training sets.
However, there exist situations that a qualified training document set may not be available (e.g., the “cold start” problem in recommender systems); a set of categories with in-comprehensive topic coverage may be used for classifica-tion; sometimes although a set of categories with comprehensive topic coverage is available, the large number of classes would easily introduce noise in classifi-cation results [5]. Traditionally, text classificlassifi-cation models are designed to handle only single-label problems. However, in some circumstances (e.g., categorizing documents in library catalogue into multiple subjects), multi-label text clas-sification is required and automatic clasclas-sification is necessary, especially when classifying a very large volume of documents [15]. To deal with these prob-lems, in this paper we propose an automatic unsupervised text classification approach to classify documents into multiple classes, without the requirement of pre-classified sample documents for training classifiers. The approach consists of three modules; pattern mining for document feature extraction; feature-subject mapping for initial classification; knowledge generalisation for optimal classifica-tion. The method incorporates comprehensive world knowledge stored in a large ontology and classifies documents into the classes in the ontology without any pre-classified training samples available. The world ontology is built from Library of Congress Subject Headings (LCSH), which represents the natural growth and distribution of human intellectual work [4]. The subject classes and semantic relationships in the ontology are investigated and exploited to improve the clas-sification results. The proposed method was experimentally evaluated using a large library catalogue, by compared with typical text classification approaches. The presented work makes three-fold contributions:
– An unsupervised text classification method that classifies documents into multiple classes;
– A knowledge generalisation method to optimise text classification by analysing the semantic relations of categories;
– An exploration of using the LCSH as a world knowledge to facilitate text classification.
2
Related Work
Unsupervised text classification aims to classify documents into the classes with absence of any labelled training documents. In many occasions the target classes may not have any labelled training documents available. One particular example is the “cold start” problem in recommender systems and social tagging. Unsu-pervised classification can automatically learn an annotation model to make recommendations or label the tags when the products or tags are rare and do not have any useful information associated. Unsupervised classification has been studied by many groups and many successful models have been proposed. With-out associated training samples, Yang et al. [16] built a classification model for a target class by analysing the correlating auxiliary classes. Though as similar as theirs in investigating correlating classes, our work is different by exploiting a hi-erarchical world knowledge ontology for classification, instead of only auxiliary classes. Also exploiting a world knowledge base, Yan et al. [14] examined un-supervised relation extraction from Wikipedia articles and integrated linguistic analysis with web frequency information to improve unsupervised classification performance. However, our work has different aims from theirs; ours aims to exploit a world knowledge ontology to help unsupervised classification, whereas Yan et al. [14] aims to extract semantic relations for Wikipedia concepts by using unsupervised classification techniques. Cai et al. [2] and Houle and Grira [6] pro-posed unsupervised approaches to evaluate and improve the quality of selecting features. Given a set of data, their work is to find a subset containing the most informative, discriminative features. Though the work presented in this paper also relies on features selected from documents, the features are further investi-gated with their referring-to ontological concepts to improve the performance of classification.
Text classification models are originally designed to handle only single-label problems, where each document is classified into only one class. However, in many circumstances single-label text classification cannot satisfy the demand, for example, in social network multiple labels may need to be suggested for a tag [8]. Comparing with the work done by Katakis et al. [8], our work relies on the semantic content of documents, rather than the meta-data of documents used in [8]. As similar as the work conducted by Yang et al. [15], our work also targets on multi-label text classification. However, Yang et al. [15]’ work is different in adopting active learning algorithms for multi-label classification, whereas ours exploits concepts and their structure in world knowledge ontologies.
considers the semantic relations existing in the ontological concepts. However, their work focuses on only the medical domain, whereas our approach works on general areas because exploiting the LCSH, a superior world knowledge ontol-ogy. Another world ontology commonly used in text classification is Wikipedia. Wang and Domeniconi [13] and Hu et al. [7] derived background knowledge from Wikipedia to represent documents and attempted to deal with the sparsity and high dimensionality problems in text classification. Instead of Wikipedia with free-contributed entries, our work uses the superior LCSH ontology, which has been under continuous development for a hundred years by knowledge engineers. Many works utilise pattern mining techniques to help build classification models, which is similar as the strategy employed in our work. Malik and Kender [10] proposed the “Democratic Classifier”, which is a pattern-based classification al-gorithm using short patterns. Different from our work, their democratic classifier relies on the quality of training samples and cannot deal with the “no training set available” problem. Bekkerman and Matan [1] argued that most of informa-tion on documents can be captured in phrases and proposed a text classificainforma-tion method that employs lazy learning from labelled phrases. The phrases in their work are in fact a special form of sequential patterns that are used in our work for feature extraction of documents.
3
Unsupervised Multi-label Text Classification
Let D= {di ∈D, i= 1, . . . , m} be a set of text documents;S ={s1, . . . , sK}
be a large set of classes, where K is the number of classes. If there is available a training set Dt ={dj ∈D, j =m+ 1, . . . , n} with yjk ={0,1}, k = 1, . . . , K
provided for describing the likelihood of dj belonging to classsk, it is easy to
learn a binary prediction functionp(yk|d) and use it to classifyd
i∈ D. However,
our objective is to learn a prediction functionp(yk|d) to classifyd
iinto{sk} ⊂ S
without Dt available. We refer to this problem as unsupervised multi-label text
classification.
The proposed classification method consists of three steps: feature extraction, initial classification, and optimising classification, using a world ontology.
3.1 World Ontology
The world knowledge ontology is constructed from the Library of Congress Sub-ject Headings (LCSH), which is a knowledge system developed for organising information in large library collections. It has been under continuous develop-ment for over a hundred years to describe and classify human knowledge. Because of the endeavours dedicated by the knowledge engineers from generation to gen-eration, the LCSH has become a de facto standard for concept cataloguing and indexing, superior to other knowledge bases. Tao et al. [12] once compared the LCSH with the Library of Congress Classification, the Dewey Decimal Classifica-tion, and Yahoo! categorisaClassifica-tion, and reported that the LCSH has broader topic coverage, more meaningful structure, and more accurate semantic relations. The LCSH has been widely used as a means for many knowledge engineering and management works [4]. In this work, the class set S ={s1, . . . , sK} is encoded
Definition 1. (SUBJECT) Let S be the set of subjects, an element s∈ S is a 4-tuple s:=hlabel, neighbour, ancestor, descendanti, where
– label is a set of sequential terms describings;lable(s) ={t1, t2, . . . , tn};
– neighbour refers to the set of subjects in the LCSH that directly link to s,
neighbour(s)⊂ S;
– ancestor refers to the set of subjects directly and indirectly link to s and locating at more abstractive level thansin the LCSH, ancestor(s)⊂ S; – descendantrefers to the set of subjects directly and indirectly link to sand
locating at more specific level thans in the LCSH, descendant(s)⊂ S.
The semantic relationships of subjects are encoded from the references de-fined in the LCSH for subject headings, includingBroader Term,Used for, and
Related to. The ancestor(s) in Definition 1 returns theBroader Term subjects ofs; the descendant(s) is the reversed function ofancestor(s), with additional subjectsUsed for s; theneighbour(s) returns the subjectsRelated to s.
With Definition 1, the world knowledge ontology is defined:
Definition 2. (ONTOLOGY) Let O be a world ontology. O contains a set of subjects linked by their semantic relations in a hierarchical structure. O is a 3-tuple O:=hS,R,HS
Ri, where
– S is the set of subjects defined in Definition 1; – Ris the set of relations linking any pair of subjects; – HS
R is the hierarchical structure ofOconstructed byS × R.
3.2 Document Features
Various representations have been studied to formally describe text documents. The lexicon-based representation is based on the statistic of occurring terms. Such a representation is easy to understand by users and systems. However, along with meaningful, representative features, some noisy terms are also extracted, caused by sense ambiguity of terms. To deal with this problem, pattern-based representation is studied, which uses frequent sequential patterns (phrases) to represent document contents [9]. The pattern-based representation is superior to lexicon-based, as the context of terms co-occurred in phrases is considered. However, the pattern-based presentation suffers from a limitation caused by the length of patterns. Though a long pattern is wealthy with information and so more discriminative, it usually has low frequency and as a result, becomes inapplicable. To overcome the problem, we represent the content of documents by a set of weighted closed frequent sequential patterns discovered by pattern mining techniques.
Definition 3. (FEATURES) Given a document d = {t1, t2, . . . , tn} as a
se-quential set of repeatable terms, the feature set, denoted as F(d), is a set of weighted phrase patterns, {hp, w(p)i}, extracted from dthat satisfies the follow-ing constraints:
– ∀p∈ F(d), p⊆d.
– ∀p1, p2∈ F(d)(p16=p2), p16⊂p2∧p26⊂p1.
3.3 Initial Classification
The initial classification ofdtosk ∈ Sis done through accessing a term-subject
matrix created by the subjects and their labels. Adopting the features discovered previously, we use a feature-subject mapping approach to initially assign subject classes to the document.
Definition 4. (TERM-SUBJECT MATRIX)LetT be the term space ofS,T =
{t∈S
s∈Slabel(s)},hS,T iis the matrix coordinated by T andS, where a
map-ping exists:
µ:T →2S, µ(t) ={s∈ S|t∈label(s)}
and its reverse mapping also exists:
µ−1:S →2T, µ−1(s) ={t∈ T |s∈µ(t)}
Adopting Definition 3 and 4, we can initially classify di ∈ D into a set of
subjects using the following prediction:
b
yki =I(sk∈h◦g◦f(di)), i= 1, . . . , m (1)
whereI(z) is an indicator function that outputs 1 ifzis true and zero, otherwise;
f(d) ={p|hp, w(p)i ∈F(d)}; g(ρ) ={t∈ ∪p∈ρp};h(τ) ={s∈ ∪t∈τµ(t)}.
3.4 Generalised Classification
The initial classification process easily generates noisy subjects because of direct feature-subject mapping. Against the problem, we introduce a method to gener-alise the initial subjects to optimise the classification. We observed that in initial classification some subjects extracted from the ontology are overlapping in their semantic space. Thus, we can optimise the classification result by keeping only the dominating subjects and pruning away those being dominated. This can be done by investigating the semantic relations existing between subjects. Let s1 and s2 be two subjects and s1 ∈ancestor(s2) (s2 ∈descendant(s1)).s1 refers to an broader semantic space thans2 and thus, is more general. Vice versa,s2 is more specific and focused than s1. Hence, if some subjects are covered by a common ancestor, they can be replaced by the common ancestor without infor-mation loss. The common ancestor is unnecessary to be chosen from the initial classification result, as choosing an external common ancestor also satisfies the above rule. After generalising the initial classification result, we have a smaller set of subject classes, with no information lost but some focus. (The handling of focus problem is presented in next section.)
Definition 5. (GENERALISED CLASSIFICATION)Given a document dand its initial classification result, a subject set denoted by SI(d), the generalised classification result, denoted asSG(d), is the set of subjects satisfying:
1. ∀s∈SI(d),∃s0 ∈SG(d), s6=s0, s∈descendants(s0).
input :d={t1, t2, . . . , tn}wheren=|d|, a thresholdϑ. output: The feature setF(d) ={hp, w(p)i}.
P(d) =∅,F(d) =∅, p=∅;
1
//Extracting sequential patterns;
2
for(i= 1;i <=n;i+ +)do 3
for(j=i;j <= (n−i);j+ +)do 4
p=p∪ {tj}; 5
end 6
ifp∈P(d)thenw(p) + + forhp, w(p)i ∈ F(d)elseP(d) =P(d)∪ {p},
7
F(d) =F(d)∪ {hp,1i};
end 8
//FilteringF(d)for closed, frequent patterns;
9
foreachhp, w(p)i ∈ F(d)do 10
ifw(p)< ϑthenF(d) =F(d)− {hp, w(p)i}else foreachhpk, w(pk)i ∈ F(d)do 11
ifp⊂pkandw(p)≤w(pk)thenF(d) =F(d)− {hp, w(p)i} 12
end 13
end 14
returnF(d).
15
Algorithm 1: Extracting Features from a Document
4
Implementation
In this section, we present the technical details for implementing the proposed approach of unsupervised multi-label text classification.
Algorithm 1 describes the process of extracting features to represent a docu-ment. The output isF(d), a set of closed frequent sequential patterns discovered fromd. Adopting the prediction in Eq. (1), withF(d) the initial set of subjects,
SI(d), can be assigned to classifyd. Taking into account the weights of feature
patterns, we can evaluatet∈d:
w(t) = X
p∈{p|t∈g◦f(d),p∈f(d)}
w(p)
Alls∈SI(d) can then be re-evaluated for their likelihood of being assigning to
d with consideration of term evaluation and term distribution ins∈ SI(d). A
prediction function can then be used to assess initial classification subjects for the second run of classification:
b
y0κ
i =I(
X
t∈µ−1(s
κ)
w(t)×log( |S
I(d i)|
sf(t, SI(d i))
)>θ), i= 1, . . . , m (2)
where I(z > θ) returns the value of z if z > θ is true and zero, otherwise;
κ= 1, ...,K and SI(d) = {s
1, . . . , sK} with |SI(d)|=K; θ is the threshold for filtering out noisy subjects. In experiments different values were tested for θ. The results revealed that settingθas the top fifthzin SI(d
i), a variable rather
input :Si={s1, s2, . . . , sj}(subject classes assigned todiafter Eq. (2)),O; output:S0
i={s1, s2, . . . , sk}(subject classes generalised for optimising classification).
S0i=∅, Stemp=∅, Sredundant=∅; 1
foreachs∈Sido
2
ExtractS(s) fromOwhereS(s) ={s0|s0∈ancestor(s), δ(s7→s0)≤3};foreach 3
sn∈Siwheresn6=sdo
ExtractS(sn) fromOlike Step 3; 4
ifS(s)∩S(sn)6=∅then 5
{bs=LCA(S(s)∪S(sn)), str(i,sb) =str(i, s) +str(i, sn);Stemp=Stemp∪ {bs};
Sredundant=Sredundant∪ {s, sn}} end
6
ifStemp6=∅then{S0i=S0i∪Stemp;Si=Si−Sredundant;Stemp=∅; 7
Sredundant=∅}elseS0i=S0i∪ {s} end
8
returnS0 i. 9
Algorithm 2: Generalising Subjects for Optimal Classification
ancestor (shortened by LCA) to replace its descendant subjects. The LCA is the common ancestor of a set of subjects, with the shortest distance to these subjects in the ontology structure. The LCA replaces descendant subjects with full information kept and minimised focus lost.
Algorithm 2 describes the process of generalising the initial subject classes to optimise classification. The functionstr(i, s) describes the likelihood of assign
s todi and returns the value ofI(z >θ) in Prediction function yb0
κ
i in Eq. (2).
The functionδ(s17→s2) returns a positive real number indicating the distance between two subjects. Such a distance is measured by counting the number of edges travelled through froms1 tos2 in HSR. The functionLCA(S(s1)∪S(s2)) returns sb, the LCA of s1 and s2. Note that δ(s1 7→ s2) ≤ 3, which restricts LCAs to three edges in distance. Subjects further than that in distance are too general; whereas using a highly-general subject for generalisation would severely jeopardise the focus of original subjects. (In the experiments, δ(s1 7→s2) ≤3 and≤5 were tested under the same environment in order to find a valid distance for tracking the competent LCA. The testing results revealed that as of three the distance was better.)
5
Evaluation
The experiments were performed, using a large corpus collected from the cat-alogue of a library using the LCSH for information organising. The title and content of each catalogue item were used to form the content of a document. The subject headings associated with the catalogue items were manually assigned by specialist librarians who were trained to specify subjects for documents with-out bias [4]. The documents and subjects provided an ideal ground truth in the experiments to evaluate the effectiveness of the proposed classification method. This objective evaluation methodology assured the solidity and reliability of the experimental evaluation.
The testing set was crawled from the online catalogue of library of the Uni-versity of Melbourne1. General text pre-processing techniques, such as stopword
1
removal and word stemming (Porter stemming algorithm), were applied to the preparation of testing set for experiments. In the experiments, we used only doc-uments containing at least 30 terms, resulted in 31,902 docdoc-uments in the testing set. Documents shorter than that could hardly provided substantial frequent patterns for feature extraction, as revealed in the preliminary experiments.
Given that the LCSH ontology contains 394,070 subjects in our implemen-tation, the problem actually became aK-class text classification problem where
K = |S| = 394,070, a very large number. Hence, we chose two typical multi-class multi-classification approaches,Rocchio andkNN, as the baseline models in the experiments.
The performance of experimental models was measured by precision and recall, the modern evaluation methods in information retrieval and organising. In terms of text classification, precision was to measure the ability of a method to assign a document with only focusing subjects, and recall the ability to assign a document with all dealing subjects.
Taking into accountK=|S|= 394070, in respect with the testing document set and the ground truth featured by the LCSH, the classification performance was evaluated by:
precision=|F T(Stgt)∩ F T(Sgrt)|
|F T(Stgt)|
andrecall= |F T(Stgt)∩ F T(Sgrt)|
|F T(Sgrt)|
whereF T(S) =S
s∈Sµ−1(s) (see Definition 4);tgtreferred to the target model;
grtreferred to the ground truth subjects.
F1 Measure as another common method used in information organising sys-tems was also employed in evaluation. We usedmicro-F1, which evaluated each document’s classification result first and then averaged the results for the final
F1value. GreaterF1values indicate better performance.
6
Results and Discussions
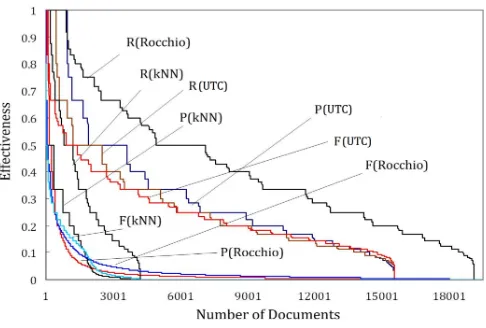
[image:9.612.233.378.632.678.2]Naming our proposed unsupervised classification approach as the UTC model, the experiments were to compare the effectiveness performance of the UTC model to the baselines, Rocchio and kNN models. Their effectiveness perfor-mances are depicted in Fig. 1 for the number of documents with valid effective-ness (>0), where the value axis indicates the effectiveness rate between 0 and 1; the category axis indicates the number of documents whose classification meets the respective accuracy rate. As shown in the figure, the effectiveness rates were measured by precision, recall, and F1 Measure, where P(x) refers to the preci-sion results of experimental model x, R(x) the recall results, and F(x) the F1 Measure results. Their overall average performances are shown in Table 1.
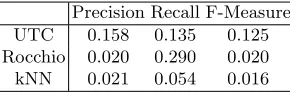
Table 1.Effectiveness Performance on Average
Fig. 1.Effectiveness Performance Results
F1Measure equally considers both precision and recall. Thus theF1Measure results can be deemed as an overall effectiveness performance. The average F1 Measure result shown in Table 1 reveals that the UTC model has achieved a much better overall performance (0.125) than other two models (0.020 and 0.016). Such a performance is also confirmed by the detailed results depicted in Fig. 1 - the
F(U T C) line is located at much higher bound level compared to theF(Rocchio) andF(kN N) lines.
Precision measures how accurate the classification is. In terms of this, the UTC model once again has outperformed the baseline models. The average pre-cision results shown in Table 1 demonstrates the achievement (UTC 0.158 vs. Rocchio 0.020 andkNN 0.021). The precision results depicted in Fig. 1 illustrate the same conclusion; the P(U T C) outperformed others.
Recall measures the performance of classification by considering all dealing classes. The recall performance in the experiments shows a slightly different result, compared with those from F1 Measure and precision performance. The
Rocchio model achieved the best recall performance (0.290 on average), com-pared to that of the UTC model (0.135) and thekNN model (0.054). The result is also illustrated in Fig. 1, whereR(U T C) lies in the middle ofR(Rocchio) and
R(kN N).
There was a gap between the recall performance of the UTC and theRocchio
As a result, the classification became inaccurate though only the documents with the top cosine values were chosen to expand and only the subjects with the top similarity values were chosen to classify a document.
Table 2.Performance Comparison for Finding the LCA
Precision Recall F-Measure Level = 3 0.158 0.135 0.125 Level = 5 0.154 0.112 0.111
Different number of levels were tested in sensitivity study for choosing a right number of levels to find the lowest common ancestor when generalising subjects for optimal classification. Table 2 displays the testing results for finding such a right level number. In the same experimental environment, if tracing three levels to find a LCA the UTC model’s overall performance including F1 Measure, precision, and recall was better than that of tracing five levels. In addition, tracing three levels only would give us better complexity. Therefore, we chose three levels to restrict the extent of finding CLAs.
7
Conclusions
Text classification has been widely exploited to improve the performance in information retrieval, information organising, text categorisation, and knowl-edge engineering. Traditionally, text classification relies on the quality of target categorises and the accuracy of classifiers learned from training samples. Some-times qualified training samples may be unavailable; the set of categories used for classification may be with inadequate topic coverage. Sometimes documents may be classified into noisy classes because of large dimension of categories. Aiming to deal with these problems, in this paper we have introduced an un-supervised multi-label text classification method. Using a world ontology built from the LCSH, the method consists of three modules; closed frequent sequen-tial pattern mining for feature extraction; extracting subjects from the ontology for initial classification; and generalising subjects for optimal classification. The method has been promisingly evaluated by compared with typical text classi-fication methods, using a large real-world corpus, based on the ground truth encoded by human experts.
References
1. Ron Bekkerman and Matan Gavish. High-precision phrase-based document classifi-cation on a modern scale. InProceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining, KDD ’11, pages 231–239, 2011.
4. Lois Mai Chan. Library of Congress Subject Headings: Principle and Application. Libraries Unlimited, 2005.
5. Evgeniy Gabrilovich and Shaul Markovitch. Feature generation for text catego-rization using world knowledge. In Proceedings of The 19th International Joint Conference for Artificial Intelligence, pages 1048–1053, 2005.
6. Michael Edward Houle and Nizar Grira. A correlation-based model for unsuper-vised feature selection. InProceedings of the 16th ACM conference on Conference on information and knowledge management, CIKM ’07, pages 897–900, 2007. 7. Xiaohua Hu, Xiaodan Zhang, Caimei Lu, E. K. Park, and Xiaohua Zhou. Exploiting
wikipedia as external knowledge for document clustering. InKDD ’09: Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 389–396, 2009.
8. Ioannis Katakis, Grigorios Tsoumakas, and Ioannis Vlahavas. Multilabel text clas-sification for automated tag suggestion. InIn: Proceedings of the ECML/PKDD-08 Workshop on Discovery Challenge, 2008.
9. Yuefeng Li, Abdulmohsen Algarni, and Ning Zhong. Mining positive and negative patterns for relevance feature discovery. In Proceedings of 16th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 753–762, 2010. 10. Hassan H. Malik and John R. Kender. Classifying high-dimensional text and web
data using very short patterns. InProceedings of the 2008 8th IEEE International Conference on Data Mining, ICDM ’08, pages 923–928, 2008.
11. Leonardo Rocha, Fernando Mour˜ao, Adriano Pereira, Marcos Andr´e Gon¸calves, and Wagner Meira, Jr. Exploiting temporal contexts in text classification. In Pro-ceeding of the 17th ACM conference on Information and knowledge management, CIKM ’08, pages 243–252, 2008.
12. Xiaohui Tao, Yuefeng Li, and Ning Zhong. A personalized ontology model for web information gathering. IEEE Transactions on Knowledge and Data Engineering, IEEE computer Society Digital Library, 23(4):496–511, 2011.
13. Pu Wang and Carlotta Domeniconi. Building semantic kernels for text classification using wikipedia. InKDD ’08: Proceeding of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 713–721, 2008. 14. Yulan Yan, Naoaki Okazaki, Yutaka Matsuo, Zhenglu Yang, and Mitsuru Ishizuka.
Unsupervised relation extraction by mining wikipedia texts using information from the web. InProceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 2, ACL ’09, pages 1021–1029, 2009.
15. Bishan Yang, Jian-Tao Sun, Tengjiao Wang, and Zheng Chen. Effective multi-label active learning for text classification. InKDD ’09: Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 917–926, 2009.