A machine learning approach to map tropical selective logging
Full text
Figure
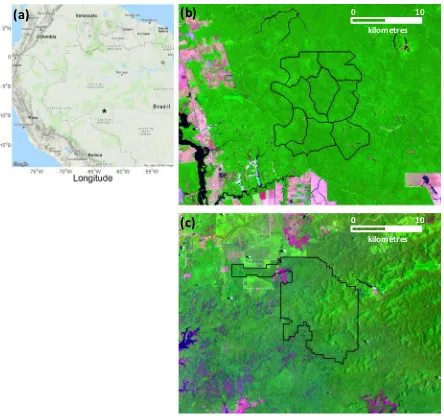

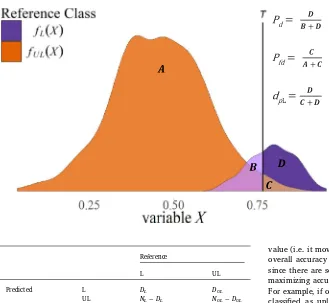
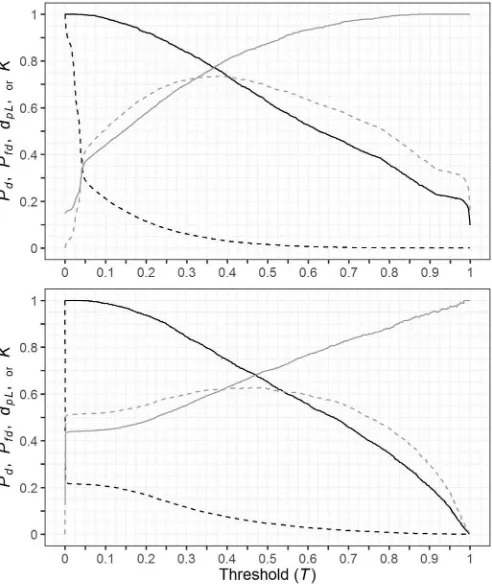
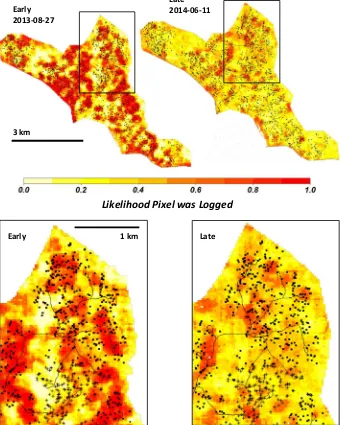


Related documents
Central Hypothesis: We hypothesized that consumption of two eggs per day as compared to one packet of oatmeal for breakfast will not negatively impact plasma lipids
İçimizdeki bu coşku -onun için önemli, benim için ikinci derecede olan- Saint- Michel-de Seze'de biraz daha artmıştı.. Bunun sebebi okulda Katolik eğitim verilmesi değildi
The data sets in scope for the AIHW support and evaluation project are the National Hospital Morbidity Database, National Perinatal Data Collection, National Community Mental
Christopher was recently named an “Analyst Superstar” by HRO Today magazine for his work in the contingent workforce management industry, and was also recognized by
The notion of using infrastructural sensors to infer individ- ualized context in a multi-inhabitant smart environment was first studied by Wilson [19], which uses a particle
This section describes how to plan the parameters of the external alarms and complete the data configuration according to the external alarm requirements, through an example...
Authentication of users/clients accessing the Hadoop cluster using Kerberos Protocol Authorization for accessing data residing.. over the HDFS (by granting and
For the poorest farmers in eastern India, then, the benefits of groundwater irrigation have come through three routes: in large part, through purchased pump irrigation and, in a
