Rochester Institute of Technology
RIT Scholar Works
Theses
Thesis/Dissertation Collections
1987
A simulation of a distributed file system
Alan Stanley
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion
in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact
ritscholarworks@rit.edu.
Recommended Citation
Rochester Institute of Technology
School of Computer Science and Technology
A Simulation of a Distributed File System
by
Alan L. Stanley
A thesis, submitted to
the faculty of the School of Computer Science and Tecnology,
in partial fulfillment of the requirements for the degree of
Master of Science in Computer Science
Approvedby: ____________
~~~--~--~~~~~
Professor James E. Heliotis
Professor Andrew Ki tchen
A Simulation
of
a
Distributed
File System
Alan
L.
Stanley
Abstract
This
thesis
presents a simulation of a
distributed
file
system.
It is
a simplified
version of
the
distributed
file
system
found
in
the
LOCUS
distributed
operating
system.
The
simulation
models
a
network
of multiuser
computers
of
any
configuration.
The
number of sites
in
the
network can
range
from
a minimum of
three
sites
to
a maximum of
twenty.
A
simple
database
management system
is
supported
that
allows
the
creation
of an
indexed
database for
reading
and
updating
records.
The
distributed
file
system supports a
transaction mechanism,
record
level
locking,
file
replication
and
update
propagation,
and
network
transparency.
To
test the
effect of
site
failures
and network
partitioning
on
the
Computing
Review
Subject Codes
File
Systems
Management
/ Distributed
File Systems
(CR
D.4.3)
Table
of
Contents
1. Introduction
1
1.1.
Distributed
File
System Definition
1
1.2.
Overview
ofDissertation
1
2. Overview
ofthe
LOCUS
Operating
System's Distributed File System
2
3.
Project Description
5
3.1.
Program Design
6
3.1.1. Network
andSite Specification
6
3.1.2.
Site
Communication
andMessage
Forwarding
8
3.1.3.
File Replication
andDistribution
12
3.1.4.
File
andRecord
Locking
15
3.1.5. Transaction Mechanism
1
8
3.1.6. User Site Program
20
3.1.7.
Storage Site Program
23
3.1.8.
Current
Synchronization
Site Program
24
3.2. Network
Testing Facility
26
3.2.1. Demo User Site
Specification
26
3.2.2.
Site
Crashing
Mechanism
28
3.2.3.
Site
Rebooting
Mechanism
29
4. Project
Testing
29
4.
1
.Test Plan
andProcedures
29
4.2.
Problems Encountered
andSystem Limitations
31
4.3.
Project
Test Results
34
5. Conclusions
36
Appendix
37
A. User's Guide
38
B. Test Plan
48
C.
Simulation
vs.LOCUS
56
1.
Introduction
The
proliferation
ofminicomputers, microcomputers,
and personal workstationsthat
have
replaced
the
large
mainframes, along
withthe many
large databases
aroundthe
nation,
has
required
the
development
ofdistributed file
systems.Early
attempts atdeveloping
suchsystems resulted
in slow,
inefficient,
andvery
userunfriendly
systems.Information
waspassed
between
processors,
each withits
ownoperating
system.Today
there
areonly
ahandful
ofcommercially
availabledistributed file
systems,
while others are stillin
the
development
stages.1.1.
Distributed File System Definition
A
distributed file
system provides users withthe ability to
accessfiles
andthe
individual
recordswithin
the
files
exclusively, atomically,
andtransparently.
Exclusive
accessto
oneormore records within a
file
is
typically
achievedby
alocking
mechanism with recordlevel
granularity.
Files
canbe locked
either witha sharedlock,
whichallows multiple readers andblocks
writers,
or with anexclusivelock,
whichblocks
all other readers and writers.Atomicity
is
typically
achievedby
the
use ofatransaction
mechanism.All
updates performedwithina
transaction
are guaranteedto
be
applied or none ofthem
are.For
example,
if
asitefailure in
the
network causes atransaction to
be
interrupted,
all previous updates arediscarded.
Updates
areonly
guaranteedto
be
applied when atransaction
commitacknowledgement
is
received.Updates
can alsobe
forcibly
discarded
by
an abort command.The
networkis
transparent
to the
usersbecause
the
distributed
file
systemdoes
allthe
work.Users
do
not needto
know
wherein
the
systemafile is located. Users
only
become
awareofthe
system when a sitefailure interrupts
their
processing.1.2. Overview
of
Dissertation
The distributed
file
system simulationdescribed
in
this
paperis
based
onthe
distributed file
system
utility
ofthe
LOCUS distributed
operating
system.An
overview ofthe
distributed file
system
utility
ofLOCUS is
presentedin
chapter2.
Chapter 3 describes
the
programdesign
2.
Overview
of
the
LOCUS
Operating
System's Distributed File
System
The LOCUS
operating system,
a superset ofUNIXTMt
Wasdeveloped
atthe
University
ofCalifornia
atLos Angeles [POPEK
81],
[WALKER
83],
[WEINSTEIN
86].
LOCUS is
designed
to
operate on ahigh band
width,
low
delay,
local
area network.A
token ring
network,
with acirculating
token
supportedby hardware,
is
usedto
control accessto the
transmission
mechanism.For
performance
reasons,
LOCUS
is
notbased
onthe
ISO
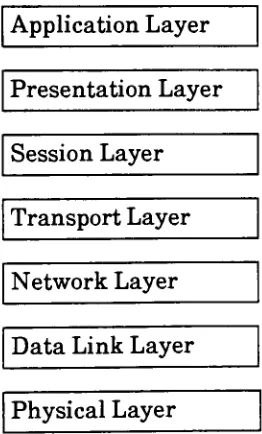
model oflayers for
networksoftware.
The
ISO
model wouldhave
the
network softwareimplemented in
the
applicationlayer
[TANENBAUM
81],
shownin
figure
2.1.
But,
sinceit
has been
observedto
costup to
5,000
executedinstructions
just to
moveasmall collection ofdata from
one user programto
the network, the
LOCUS
softwaresupportis
located
withinthe operating
systematthe
lower
network
layer level [POPEK 81].
Application Layer
Presentation
Layer
Session Layer
Transport Layer
Network Layer
Data Link Layer
[image:7.521.185.316.316.533.2]Physical
Layer
Figure 2.1
ISO/OSI
Network Model
LOCUS has
provento
be
highly
reliable[POPEK
81]
andit
supports networktransparency
ofto
communicate
withforeign
sites.LOCUS
also supportstransparent
replication offiles,
record
level
locking,
andtransaction
mechanisms
suchascommit, abort,
and recovery.These
attributes of
LOCUS
arefound
in
its distributed file
system andother attributespertaining to
the
LOCUS
operating
system such asremote
process creation and execution are notconsidered
here.
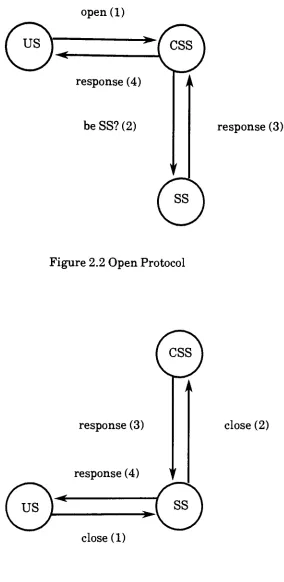
Accessing
afile
in
LOCUS
involves the
interaction
ofthree logical
sites:the
user site(US),
the
storage site(SS),
andthe
current synchronization site(CSS).
The US is
the
siterequesting
afile,
the
SS
is
the
sitewithacopy
ofthe
file
andis
selectedby
the
CSS
to supply
it
to the
US. The
CSS
alsoenforcesaglobal accesspolicy.When the
CSS
receives arequestfrom
the
US
to
open afile,
the
CSS
choosesthe
site withthe
most up-to-date
copy
to
be the SS.
Subsequent
file
requestsby
the
US
arehandled
by
the
SS.
When the US
requeststhe closing
ofafile,
the
SS
sendsthis
requestto the
CSS
whichclosesthe
file
andsends aresponseto the
SS,
whichthen
passesit
onto the
US. Figures
2.2
and2.3
show
the
LOCUS
open and close protocols.The
transaction
mechanisms ofLOCUS
[WEINSTEIN
86]
arefully
implemented
onthe
originalbase
system asdescribed in [POPEK
81]
and[WALKER 83].
Transactions in LOCUS
are simple-nested.The fully-nested
transaction
mechanism of[MUELLER
83]
is
notimplemented
because
ofits high
implementation
and performance costs.A
simple-nestedtransaction
is
encompassedby
aBeginTrans,
EndTrans
call pair.All
file
operations
by
the
processbetween
this
pairbecome
permanent unless anAbortTrans
callis
sent or
the
SS fails;
in
which case all updates arediscarded.
But if
the
SS fails
afterthe
commit signal
has been
sentto the
US
by
anEndTrans
call, the
changes are saved untilthe
site
(SS)
comesback
online,
at whichtime
they
are committedto the transaction
file.
A
file
locking
mechanismis
providedby
LOCUS
with a recordlevel
locking
granularity.LOCUS
enforcesatwo
phaselocking
mechanism.Records
may
be locked
with either asharedor an exclusive
lock.
Shared locks
allow multiple readers and exclude writers.Exclusive
locks
arerequiredfor
writing
and providethe
lock holder
with exclusive accessto the
locked
open
(1)
response
(4)
be
SS? (2)
response
(3)
Figure
2.2
Open
Protocol
response
(3)
response
(4)
^ '?'
closed)
close
(2)
[image:9.521.127.411.43.625.2] [image:9.521.132.331.373.593.2]Other distributed
operating
systemdesigns
as supersets ofUNIX
include
the
Newcastle
Connection [BROWNBRIDGE
82],
developed
atthe
University
ofNewcastle-upon-Tyne,
England,
COCANET
UNIX,
developed
atthe
University
ofCalifornia
atBerkeley
[ROWE
81],
S/F-UNIXTM(
developed
atBell
Labs [LUDERER
81],
andthe
Berkeley
Remote Mount
currently in
development
atthe
University
ofCalifornia
atBerkeley
[HUNTER
85].
3.
Project Description
This
projectis
asimulationof adistributed file
system(dfs)
residing
onalocal
area network.The
program was writtenin
the
C
programming language in
aSystem V
UNIXenvironment on a
Pyramid
90X
computer.The
network sites are simulated as processeswhich are
forked
from the
demo
programaccording
to the
specifications ofthe
networkconfiguration
file.
Each
site processis
asynchronousand runsconcurrently
withthe
othersites
in
the
network.Communication between
the
sitesis
achievedby
the
use ofUNIXFIFOs (named
pipes).The
LOCUS
open and close protocols areimplemented
as well as otherdatabase
operationsusing the
US, SS,
CSS
logical
site concept.As
withLOCUS,
the
user needs noknowledge
offile
location
orfile
replication.Also,
the
integrity
ofthe
systemis
maintainedby
the
use ofrecord
level file
locking
andby
atransaction
mechanism.Transaction
nesting,
however,
is
not
implemented in
the
simulation.Recovery
from
sitefailures is
providedin
the
simulation.Alternate
communication paths areused
to
reroute messagesthat
areinterrupted
by
sitefailures. A
sitefailure
at a sitethat
is
the
CSS
resultsin
the
drafting
of another siteto
become
the
newCSS
whenthe
failure
is
discovered.
Under
mostcircumstances,
the
file
replication mechanism allowsthe
systemto
accessalternate storage sites
for
aparticularfile group
whenone or more ofits
file
images is
lost because
ofa sitefailure (s).
If
asitefailure
causesthe
networkto
become
partitionedinto
two
or moresubnets, those
sitesthat
cannotaccessthe
CSS
will stillbe
allowed read accessto
files in
their
subnet.Each
ofallows
files
to
openedfor
reading only
andonly
sharedlocks
are allowedonthe
records withinthe
file.
A
testing
facility
is
also providedto
evaluate
the
performanceofthe
simulation andto study
the
effect of sitefailures
onthe
simulated
distributed file
system.LOCUS
providedthe
protocols andmechanisms
usedin the
simulation.The
protocols andmechanismswere usedas guidelines
in
the
implementaion
sincemany
ofthe implementation
details
were not providedby
the
literature
onLOCUS.
The
networktesting
facility
wasdesigned for
the
simulationandis
nota part ofLOCUS.
Refer
to
Appendix
C for
a completesummary
ofthe
differences between LOCUS
andthe
simulation.
3.1. Program
Design
3.1.1.
Network
and
Site Specification
The demo
programaccepts apreviously
formatted
network configurationfile
as an argumentwhen executed.
If
nofile is
specified,
a network configurationfile is
created.A
networkconfiguration
file
consists of structures oftype SITE
as shownin
figure 3.1. The
sitefield
ofthe
SITE
structure canhold
any
integer
from 0
to
99
as a namefor
the
site.The linknum
field
holds
the
number ofsiteslinked
to the
specified site.The
links
array
containsthe
nameofeach
linked
site.A
maximumoftwenty
sitesis
allowedin
a network and each sitemay
have
amaximum of nineteen siteslinked
to
it.
typedef
struct
{
int
site;
int
linknum;
intlinks[MAXLINKS];
}SITE;
Figure 3.1 SITE Data
Structure
After
the
networkconfigurationhas been
determined,
a new asynchronousprocessis
forked
any time
withouthaving
to
be
waitedfor.
A
process candie
withoutbeing
waitedfor only if
its
parent processhas
previously
died.
Since
the
demo
process needsto
continueexecuting
after
creating
asite
process,
anintermediate
processhas
to
be forked. The
only
purpose ofthe
intermediate
process
is
to
fork
a newprocess,
executethe
siteprogram,
andthen
die.
The
demo
process,
afterwaiting only
a shorttime
for the
intermediate
processto
die,
continuesexecuting,
whilethe
newsite processis
nowasynchronous
sinceits
parent,
nowdead,
wasthe
intermediate
process.Figure
3.2
showsthe
codefor
forking
anasynchronousprocess.switch
(fork())
{
case
-1:syserrCfork");
case
0:
switch
(forkO)
{
case
-1:syserr("fork");
case
0:
execlp("./site",
"site", "boot",
sstr,
demo,
ess,
file, NULL);
default:
exit(0);
}
}
wait(NULL);
Figure
3.2
Asynchronous Process Creation
Each
site process creates atleast
two
asynchronous processesbefore creating its FIFO for
receiving
messages.The forward
program,
described
morefully
in
the
nextsection,
is
forked
by
the
siteprocessto
pass messages onto the
nextsitein
the
communication pathfield
ofthe
message structure when
the
messageis
notintended for
this
particular site.The forward
process runs
concurrently
withthe
site process anddoes
notterminate
unlessthe
site crashes.The forward
programis
runasa separate processto
free
the
site programfrom processing
andforwarding
messages,
thereby
increasing
the
responsetime
ofthe
simulation.As
the
numberof processes and
the
numberofsitesin
the
networkincreases,
sodoes
the
number ofmessagesthat
have
to
be forwarded.
This
wouldgreatly
slowthe
systemdown if
the
forwarding
programwas not run as a separate process since
the
siteprocess performsmany
functions
for
The
otherasynchronous
processthat
is forked
is
the
storflist program.The
purpose ofthis
program
is
to
sendthe
names ofthe
files,
their
last
modificationtimes,
andtheir
permissionsto the
CSS. The
storflist processterminates
when allfile
nameshave
been
sentto the
CSS.
The
storflist
processwillbe
executed againwhenthis
sitediscovers
that
a newCSS
has been
elected
(due
to
a site crash).The demo
program promptsfor
the
nameofthe
siteto
be
usedfor
the
demonstration
andalsofor
a siteto
become
the
current synchronizationsite.If
a givensitehas been
chosento
be
the
demo
site and/orthe
CSS,
anotherasynchronous process(es) has
to
be
forked
and executedby
the
site.The
usersiteprogram,
uspgm(see
section3.1.6),
executesthe
interactive
utility that
is
usedto
accessthe
systemfiles.
The
current synchronization siteprogram,
csspgm(see
section
3.1.8),
executesthe utility that
synchronizesusersite(US)
systemfile
accesses.The final
phase ofthe
site programis
the
messagereceiving
loop.
The
site creates aFIFO
when
the
receivefunction is
executed.All FIFO
names aremadeup
ofthe
word "fifo"and a
long
integer key. Keys
associated with a particularsitecontainthe
site name.For
example,
the
sitereceiving
key
for
each siteis:
sitename+
100.
The
siteforwarding key
for
eachsiteis:
site name+
200.
Therefore,
site0
wouldhave
aareceiving
key
of100
and aforwarding
key
of200.
A further
explanation ofthe
keys
and messagepassing
is
found in
section3.1.2.
Operations
to
be
performedby
the
site are containedin
a switch statement.A
singlecharacter
found in
the
message structurefield,
cmd,
determines
the
sitecommand.When
the
sitefinishes
executing the command,
it
returnsto the
top
ofthe receiving
loop
and waits onthe receiving
endofthe
FIFO for
more commands.The
only
exceptionto this
is
whenthe
die
command
is
received("). The die
command causesthe
siteto
kill
any
activeprocessesthat
it
created and
then
exit.This
site command andthe
otheroptions aredescribed
whendiscussed
in
subsequent sections.3.1.2.
Site
Communication
and
Message
Forwarding
Site
processescommunicate with one another via aFIFO.
When
either a reader or writeropensa
FIFO,
it blocks
untilthe
otherend ofthe
FIFO
is
opened.This
allowsthe
reader anddesired,
the
FIFO
canbe
setto
notblock
when opened.This
causesthe
processto
returnimmediately
if
nootherprocesshas
openedthe
other endofthe
FIFO.
A
modified version of animplementation
of messagepassing
using
FIFOs found in
[ROCHKIND
85]
is
used.Rochkind
creates alogical
device
whichhe
callsaqueue, to
describe
the
placeto
whichmessages are sent.The
queueis
openedto deposit
and retrievedata
by
along
integer
calledthe
key. Data
to
be
addedto the
queueis
addedto
the
back
ofthe
queuewhile
data
to
be
readfrom
the
queueis
taken
from the front.
Thus,
the
oldestdata
onthe
queueis
readfirst.
Two primitives,
send andreceive,
are usedby
Rochkind
to
describe
message passing.If
the
queue
fills
up, the
send primitiveblocks
untilthe
queuehas
enough roomfor
the
message.The
number ofbytes
readfrom
or writtento
the
queueis
found in
the
nbytesfield
ofthe
message primitives.
Any
left
overbytes
areleft
onthe
queue ordiscarded.
Therefore,
the
sender andthe
receiverusethe
same size messageonany
given queue.The headers for
the
send andreceive primitivesare shown
in
figure
3.3.
BOOLEAN
send
(dstkey,
buf,
nbytes)
/*send message
*/
long
dstkey;
/*destination
key
*/
char
*buf;
/*pointer
to
message
data
*/
int
nbytes;
/*number of
bytes
in
message
*/
/*
returns
TRUE
on success or
FALSE
on error
*/
BOOLEAN
receive
(srckey,
buf,
nbytes)
/*receive message
*/
long
srckey;
/*source
key
*/
char
*buf;
int
nbytes;
/*
returns
TRUE
on success or
FALSE
on error
*/
Figure 3.3 Message
Primitive Headers
The buf field
ofthe
message primitivesis
a pointerto
amessagedata
structure whosetype
may
vary,
sobuf is declared
as a character pointer.Two
messagetypes,
DMESSAGE
andSMESSAGE
are used.DMESSAGE
is
usedto
send messagesto the
demo
process,
whileSMESSAGE
is
usedby
the
sitesto
communicate with each other andby
the
demo
processto
typedef
struct
{
char
cmd;
/*demo
command
*/
int
site;
/*site name
*/
} DMESSAGE;
typedef
struct
{
char
cmd;
/*site
command
*/
char
data [MAXD
ATA]
;
/*message
*/
long
srckey;
/*key
name
of
message source
*/
long
dstkey;
/*key
name
of
message
destination */
int
src;
/*site
name of message source
*/
int
dst;
/*site
name
of
message
destination */
KEYS
fwd[MAXSITES];
/*network communication path
*/
} SMESSAGE;
typedef
struct
{
long
prev;
/*key
name of previous site
in
path
*/
long
next;
/*key
name of next site
in
path
*/
}
KEYS;
Figure
3.4
Message Data
Structures
The DMESSAGE
messagetype
is
usedto
"suspend"file
processing
in
orderto test the
effectasite
crash,
sitereboot,
oranewdemo
sitehas
onthe
network.The
sitefield
ofDMESSAGE
contains
the
name ofthe
sitethat
is
to
be
affectedby
the
action ofthe
suspend command.Section 3.2 describes
these
networktesting
features.
The SMESSAGE
messagetype
is
usedby
the
sitesto
sendmany
different
commandsanddata
to
one another.It
may
alsobe
usedby
a programrunning
atthe
siteto
retrieve networkrelated
information
suchascommunication pathsto
other sites.Most
ofthese
commandsarediscussed in later
sectionsofthis
paper.The SMESSAGE data
structureitself
and messageforwarding
is
whatis
emphasizedin
this
section.When
onesite wantsto
senda messageto
anothersitein
the network,
a communicationpathmust
be
constructed.The function
compathis
calledto
determine
the
shortest reachablepathto the
destination
site.This function is
recursiveandit
uses adepth
first
searchalgorithmto
[image:15.521.73.444.50.242.2]The function
compath,
whoseheader
is
shownin
figure
3.5,
requires sixinputs.
The
first,
network,
is
adata
structurethat
contains
every
sitein the
network andtheir
links. The
nextinput, dead,
is
alist
ofsitesin the
networkthat
have
"crashed"The
dead list is
checkedbefore
a new siteis
addedto the
path andif
found
to
be
"dead",
it is
notaddedto the
path.The
input,
start,
holds
the
sendersite,
whiledest,
holds
the receiving
site.The
nextinput,
srchpath,
holds
a candidatefor
the
shortest reachablepath,
whileshortpath,
holds
the
current shortest path.
void compath
(network,
dead,
start,
dest,
srchpath,
shortpath)
SITE
network[];
/*network site structure
*/
int
dead[];
/*dead
site
list
*/
int
start;
/*sender site
*/
int
dest;
/*receiver site
*/
char
*srchpath;
/*pointer
to
candidate path
*/
char
shortpath[];
/*current shortest path
*/
Figure 3.5 Communication
Path Function Header
The
search algorithmfor
finding
the
shortestreachablepathis
shown asfollows:
add
start
to
srchpath;
for
each
site
from
start
to
dest
{
call compath
function
for
eachlink
not
in
dead list
and not
visited;
add new site
to
srchpath;
if
srchpath
finished
and
(shortpath
is
empty
or srchpath
< shortpath)
copy
srchpathto
shortpath;
else
if
srchpath>
shortpathexit
from
this
compathcall;
}
If
a communication path canbe
determined,
it
mustbe
converted andloaded into
the
fwd
field
ofthe
SMESSAGE data
structure.The fwd field is
anarray
ofstructuresoftype
KEYS
The KEYS
structure containstwo
long
integer
fields,
prev andnext,
whichcontainthe
keys
loaded
with99,
to
indicate
the
beginning
andthe
end ofthe
communicationpath,
in
fwd[0].prev
andfwd[nsites].next
The
sitesin
between have keys
in
the
200
to
299
rangeto
indicate
that the
message
is
to
be
sentto the
forwarding
process of each sitein
the
communication
pathand notto the
site(site
receiving keys
rangefrom 100
to
199).
The forward
processfor
each site waits onits
queuefor
messagesto
pass along.When
amessage
is received,
the
forward
processfinds
its
key
(fwd[n])
in
the
fwd
pathlist
and sendsit to
the
'next'sitein the
fwd
path.Depending
onthe
valuein
the
cmdfield,
'next'may
meaneither
fwd[
+
+
n].nextorfwd[--n].prev.
Fwd[
+ +
n].nextis
the
nextsitefor
all commandsexcept
for the
crash command('!')
andthe
response commandC@'). The
response commandmessage
is
sentback
to the
source siteindicating
the
success orfailure
ofthe
originalmessagecommand.
So
the
forward
process sendsthe
response messageto
the
queue whosekey
is in
fwd[--n].prev.
The
crash commandindicates
that
a sitein
the
communication pathhas
crashed.The
forward
processtimes
outif it is blocked from
sending to the
fwd[+
+n].next
queue aftersomemaximum
tries.
When
asitecrashes,
all queues associated withit
are removed withthe
rmqueue
function. Rmqueue
removesthe
queue(FIFO)
whosekey
is
found in
the
input
key
variable.
The function
openfifo,
allowsaprocessto
have
up to
sevenFIFOs
openfor
reading
orwriting
and
keeps
track
of whichfile
descriptor is
associated with whatFIFO (queue key).
A
clockcounter
is incremented
every time
openfifois
called andis
stored with eachFIFO's file
descriptor
andkey
whenevera certainFIFO is
used.If
aneighthFIFO is
needed, the
FIFO's
file
descriptor
that
wasleast-recently-used
(the
one withthe
lowest
clocktime) is
closed andthe
newFIFO's
key
andfile descriptor
replacesthe
old one.The
number ofFIFOs
a processis
allowedto
have
open atany
onetime
is
limited
to
sevenbecause
the total
numberoffile descriptors
that
aUNIXprocessis
allowedto
have
open atany
onetime
is
twenty.
A
site withmany
links,
requiring
aFIFO
for
each,
could run out offile descriptors if
severalfiles
are openedfor
processing.The
number seven wasarbitrarily
picked and could
be
changedfor
efficiency
reasons.Seven
provedadequatefor
this
simulation3.1.3 File
Replication
and
Distribution
File
replicationin
a networkdecreases
the
effectofsite crashesonthe
system.As
the
numberof
file
replicates
increases,
file
accessing efficiency
increases.
Many
welldistributed
file
replicates
decreases
the
distance between
message source anddestination.
Communication
path
calculations
are shorter andthe
chancethat
the
communication path wouldhave
to
be
recalculated
due
to
a sitefailure
withinthe
pathdecreases
withashorter path.Therefore,
asfar
as network communicationis concerned,
file
accessing
wouldbe
most efficientif
every
sitehad
acopy
ofevery
file
in the
system.A
file
copy
atevery
sitewouldrequiretremendous
amountsofmemory
at each sitein
alarge
network with
many
files.
A lot
oftime
wouldbe
requiredofthe
current synchronizationsite(CSS)
to
propagate copies ofnewly
createdfiles
andto
propagatefile
transactions.
If file
copies are
distributed
to nearly every
site,
ratherthan
allsites,
alarge
amount ofmemory
would
be
needed onthe
CSS
to
store a sitefile list
table to
keep
track
offile locations.
Conversely,
too
few
file
copies causesinefficient file
accessing.Longer
communication pathsresult
in
a greater chancethat the
message willhave
to
be
rerouted orthat the
file
is
inaccessible. File
inaccessibility
willoccurif
all sites withthe
requiredfile
aredown
orif
sitefailures
causethe
networkto
be
partitionedinto
two
or more smaller networks.Too few
file
replicates could cause a sub-network
to
nothave
any
copies of somefiles.
No
attemptis
madein
this
simulationto
determine the
most efficientfile
replicationscheme.For every
file
that
is
created,
two
replicates are createdanddistributed in
the
networkfor
atotal
ofthree
file
images.
Three file images
are sufficientfor
this
simulation sincethe
numberofsites
in
the
network simulationis limited (see
the
subsection on problems encounteredin
the
conclusions section).Figure 3.6
shows a samplenetworkand somefiles
a,
b,
c,
d,
and e.Replicates
aredesignated,
for
example,
by
a'
and a".
File distribution in
this
simulationis determined
by
the
CSS
whenthe
newly
createdfile
is
requested
to
be
closedby
the
usersite(US)
through
the
storage site(SS)
asdescribed
by
the
close protocol.
The first
messagethat
the
CSS
receivesis
to
closethe
file
('c'command).
This
site
0
1
2
3
4
5
6
7
8
9
files
d
b,e
a,b',d'
c
a,e'
b",c'
a",c"
d",e"
[image:19.521.96.434.263.529.2]8
The CSS keeps
track
ofthe
numberoffiles
that
auserprocessona sitehas
openbecause
eachuser
process
in this
simulated
networkis
allowedto
have
only
five files
openatthe
sametime.
The CSS
sends a responseback to the
SS,
whichcausesthe
SS
to transmit the newly
createdfile
to
the
CSS.
When the
entirefile is
received,
the
CSS
picksthe
sitesto
hold
the two
file
copiesof
the
newfile.
Picking
the
sitesto
become
storage sitesinvolves
finding
the two
sitesin
the
network structure
that
arewithintwo
positionsplus andminusfrom
the
US. The CSS
propagates
the
newfile
copy
to
the
replicatesites and storesthe
newfile's
name andthe
sitesthat
storeacopy
ofit in
its file list
table
(see
section3.1.8. for
afurther
explanation).3.1.4.
File
and
Record
Locking
A
locking
mechanismis
supportedto
provideprotection offiles
during
file
accessing
andto
ensure
the
integrity
ofthe
distributed file
system.Before
any
file
canbe
accessed, the
recordor records needed must
be
locked
withthe
appropriatelock
at eachfile image location.
A
record
level
locking
granularity is
provided sothat any
number of recordsfrom
oneto
nrecordscan
be locked.
Two
types
oflocks
areprovidedto
makefile
accessing serializable,
ashared
lock
andanexclusivelock.
A
file
access(or transaction) is
serializableif
the
effect of several concurrentfile
accesseshas
the
sameeffect onthe
file
as wouldthe
samefile
accessesdone
one at atime
in
any
order.A
shared
lock
on a record or records within afile
allowsmultiple readers ofthe
same recordblock
andkeeps
all writersfrom
accessing
any
ofthe
records withinthe
locked block
ofrecords.
This
meansthat any
numberof sharedlocks
and no exclusivelocks
on all or part of ashared-lock record
block
canbe
acquiredby
other users.The
owner ofthe
sharedlock is
allowed
to
readthe
recordsbut
not update or add records.An
exclusivelock
on ablock
of recordsdoes
not allow other usersto
acquire either anexclusive
lock
or a sharedlock
onany
record or records withinthis
block.
An
exclusivelock
allows
the
userto
readthe
recordsin
the
recordblock
andto
updateand add records.Thus
exclusive access
to
an entirefile
canbe
achievedby
an exclusivelock
onevery
recordin
the
file.
An
unlock mechanismis
also providedto
remove shared and exclusivelocks from
recordsTo
acquire
alock
onapreviously
opened
file,
the
US
sends alock
requestto the
SS.
The
SS
calls
the
lockmgr
function,
whichdetermines
if the lock is to
be
allowed atthis
site.If
otherusers
have
alock
onthis copy that
would conflictwithany
part ofthe
requestedlock,
the
lock
request
is
denied.
If there
are noconflicting
locks,
the
SS
sendsthe
lock
requestto the
CSS.
The CSS looks
in
its
file list
table
for
the
sitesthat
storethe
othertwo
file
images.
The
CSS
then
sendsthe
lock
requestto these
other storage sites.Any
locks
ateither sitethat
conflictwith
the
lock
requestwillcausethe
lock
requestto
be
denied.
Otherwise,
the
CSS
grantsthe
lock
and sends a messageto the
SS,
whichsendsit
onto the
US.
Figure
3.7
shows a graphicaldepiction
ofthe lock
protocoldescribed here.
The lock
managerfunction, lockmgr,
implements
recordlocking
with atable
ofLOCK
structures
found
in
each record of afile.
The LOCK
structureis
madeup
ofthe
processid
(pid)
ofthe
owner ofthe
lock
andthe
type
oflock
(lock)
onthe record,
represented asthe
singlecharacter-'s'
(shared
lock),
V
(unlock),
or'x'(exclusive
lock).
A table
ofLOCK
structuresis
neededbecause
multiplereadersareallowedto
sharethe
samerecord
for
reading.Each
processthat
wishesto
sharelock
a recordhas its
pid number addedto the
LOCK
table
providedthere
is
no exclusivelock in
existence onthe
desired
record.When
a process unlocks arecord,
its
pid andlock
are removedfrom
the
LOCK
table.
An
exclusivelock
willbe
allowed onarecordif
there
are nolocks
withpidsthat
do
not matchthe
pid ofthe
processrequesting the
lock.
Only
one exclusivelock is
allowed per record andit
is
storedasthe
first
entry
into
the
LOCK
table.
An
existing
lock
onarecordmay
be
upgradedfrom
a sharelock
to
an exclusivelock if
the
pidof
the
process equalsthe
pid storedin
the
LOCK
table
andthis
process'slock is
the only
sharelock
onthe
record.Any
record withinthe
requested recordblock
with multiple readers willcausea
lock
upgradeto
be
denied.
The
unlocklock
request affectsonly those
records whoseLOCK
pid matchesthe
pid ofthe
process
requesting the
lock.
Therefore,
an unlock ofa wholefile
removesonly the
unlocking
lock
(1)
W
response
(3)
or
(9)
allow
lock?
(2)
allow
lock?
(3)
response
(8)
allow
lock?
(4)
response
(7)
Figure
3.7
Lock
Protocol
request
that
the
wholefile
be
unlockedevenif
the
processdoes
nothave
the
wholefile
locked.
This
relievesthe
user ofthe
choreofkeeping
track
of which recordsin
the
file
it has locked.
Since
there
are multiplefile
images in
the
distributed
file
system, the
lockmgr
setsthe
desired lock
onthe
local
copy
if it
is
allowed whileit
awaitsthe
outcome ofthe
lock
requestfrom
the
CSS.
This is done
to
preventsome otherprocess atthe
local
sitefrom acquiring
alocal lock
whilethis
SS
processis
waiting
for its
responsefrom
the
CSS. If
the
CSS denies
the
lock
request,
lockmgr
clearsthe
local
locks
and returnsto the calling process,
indicating
that
the
lock
wasdenied.
If
the
SS
receives a positive responsefrom
the
CSS,
lockmgr
sends a [image:22.521.77.440.44.425.2]The LOCK
table
in the
recorddata
structure
is
usedfor
a quicktest
to
seeif
the
userhas
the
appropriate
lock
for the
database
request.
A
requestto
readthe
next recordin
the
file
orto
read a record
by
index
requires
that
the
process
ownsasharelock in
the
record'sLOCK
table.
Deleting
orchanging
anexisting record,
requires
that
the
process ownsan exclusivelock in
the
record'sLOCK table.
Adding
a new recordto
afile
requiresthat
nootherprocesshas
the
entire
file locked.
If the
processdoes
notown anappropriatelock
onthe
desired
record, the
database
requestis
denied. Figure
3.8
showsthe
RECORD data
structure.typedef
struct
{
char
index[MAXLNDEX];
charrcd[MAXREC];
ch.3.roGlptp*
LOCK
netlocks[MAXLOCKS];
} RECORD;
typdef
struct
{
int
pid;
char
lock;
}LOCK
Figure
3.8 RECORD Data
Structure
3.1.5. Transaction
Mechanism
The
transaction
mechanism providedis
atomic.Therefore,
all changed recordsin
afile
withina
transaction
mustbe
guaranteedto
occur onevery
file image
or all changes mustbe
discarded.
There
canbe
nopartialtransaction
updates sincethis
wouldleave
the
file
in
aninconsistent
state.The
user must notbe left
guessing
asto
how
many
ofthe
updates wereactually
committedto
the
file.
To
startatransaction,
abegin
transaction
commandmustbe
sentto the
SS
that
has
the
file
to
be
updated(a
user canhave
up to
five files
openbut
only
onefile
at atime may
be
designated
the transaction
file). The
SS
createsatemporary file
to
containthe
changesto the
file
during
the
transaction.
The
changes willonly
become
permanentif
an endtransaction
commandis
received ata
later
date from
the
userandthe
commitis
successful.command.
The
abort commandis
sent
to the
SS,
which uponreceiving the command,
discards
the
temporary
file
that
held
the transaction
updates.The
useris
nowfree
to
send anotherbegin
transaction
commandto
the
sameSS
orgoonanddo
something
else.A
user's updatesmay
alsobe discarded
asthe
resultofa sitefailure
during
the processing
ofan end
transaction
command.When
aSS
receivesanendtransaction command, the
SS
sends acopy
ofthe transaction
file
with allthe
changesto the
CSS.
If the
CSS
does
not receivethe
entiretransaction
file
and respondto the
SS
due
to
a sitefailure,
the
SS
will abortthe
transaction
by
discarding
the
updates andnotifying
the
user ofthe
abortedtransaction.
Otherwise,
the
updates are committed andthe
useris
senta commit message.A
sitefailure
may
also causethe
endtransaction
commandto
never reachthe
SS
orthe
SS
itself
may
crashbefore
it
canfinish
processing
the
endtransaction
command.When
the
CSS
receivesthe transaction
file
copy,
it
must propagatethe
changesto the
othertwo
file image
sites.If
oneorboth
ofthe
siteshave
notbeen designated
asfile image
storagesites, then
asite(s)
has
to
be
chosen.After
the
file has been
sentto the
otherfile
image
sites,
the
CSS
waitsfor
aresponse, containing that
file
image's
new modificationtime,
from
these
sites as anindication
that the transaction
file
wasreceived and stored.A
timeout
by
the
CSS
in
trying
to
sendto
afile
image
storage siteresultsin
the
modificationtime
ofthat
site's
file
image
to
be
setto
zeroin
the
CSS's file list
table
andthe transaction
file
that
the
CSS
receivedfrom
the
SS
to
be
retained.No
file image
willbe
ableto
be
accessed untilit has been
updated withthe
changesin
the
transaction
file.
When
the
sitethat
had
crashed comes
back
on-line, the
CSS
sendsthe transaction
file
to the
rebootedsite and waitsfor
the
file images's
new modificationtime to
be
returned.If
the
file
transfer
is
successful andall storage sites
have
afile
modificationtime
greaterthan
zero,
the transaction
file is
discarded.
Otherwise,
the
transaction
file
is
retained.The
transaction
file
retainedby
the
CSS
may
be
appendedbefore
the
CSS
is
ableto
propagatethe
file
to
a storage sitethat
has
not yet comeback
on-line.This is
allowed sincethe only
storage sitethat
wouldbe
allowedto
be
accessed wouldbe
the
onethat
is
up-to-date andhas
amodification
time
greaterthan
zero.This
site couldbe
eitherthe
SS
that
sentthe transaction
other
file images
ofafile
wouldbe
updated
withthe
transaction
file
changesas soonasthey
become
accessible
to the
CSS.
A
problemoccurs
if the
CSS
crashes.The
newCSS,
whichis
chosenby
finding
the
sitein
the
network
structure
that
is two
sitesaway,
willhave
noknowledge
ofthe
file
system untilthe
other sites
in the
network are made awarethat
anewCSS has
been
elected andhave
senttheir
file lists
to
the
CSS.
If the
CSS does
not receiveafile
list from
every
sitein
the
network,
the
CSS
willhave
anincomplete knowledge
ofthe
file
modificationtimes
of somefile
image
groups.
The
integrity
ofthe
file
systemcanbe
adversely
affectedif
an oldcopy
is
allowedto
be
updated
before
it
has
receivedthe
previoustransaction
updates.The
newCSS
wouldnothave
a
copy
ofthe transaction
file in
our example and cannot get oneif
the
site at whichthe
transaction
occurredhas
sincecrashed.Also,
the
most up-to-datecopy
cannotbe determined
ifone or
morefile
image
sitesaredown
when a newCSS
is
elected.Since
the
integrity
ofthe
file
system mustbe
ensured,
file
access mustbe
restrictedif
a newCSS
is
electedandthe
CSS
does
nothave
the
modificationtimes
for
eachfile
image.
Clearly,
this
is inefficient
since accesswillbe denied
to
somefiles
that
were neverchanged atany
ofthe
locations
if
one or more ofthe
storage sites aredown
when a newCSS is
elected.Normality
does
not returnto
the
system until allsitesof eachfile image
group
comeback
online.
All
recordlocks
that
are neededin
afile
mustbe
acquiredbefore
atransaction
canbegin.
Otherwise,
deadlock
can occurif
alock is
allowedto
be
acquired onthe transaction
file
afterthe
begin
transaction
commandhas been
executed.All locks
on afile
acquiredbefore
atransaction
remain afterthe
executionofthe
endtransaction
command.3.1.6. User Site
Program
The
usersiteprogram consistsmainly
of a userinterface
to the
distributed
file
systemandit
is
executedby
the
sitesin
the
network.Each
sitein
the
network allows multiple users andeach usersite program
that
is
executed returnsits
processid
to
its
home
site.The
home
sitestores
the
processid
ofa new user site programin
a processid
table.
the
process
id table.
This
key
is
sentto the
user siteprogram,
along
withthe
home
sitenumber,
whenit is
executed.
The
userinterface
accepts oneletter
commands
from the
userandthen
promptsthe
userfor
additional
information
asrequired.
A
questionmarkis
typed
by
the
userto
seea menu ofthe
available
commands
(see figure
3.9).
The
useris
promptedfor
moreinformation
whenit is
required
by
auserinterface
command.Upon
completionofthe
execution ofthe
command, the
user willreceiveat
least
oneofthe
following
replies:OK, NOTFOUND,
orERROR.
a
abort
transaction
b
begin
transaction
c
close
file
d
delete
record
e
end
transaction
1
lock file
or record
m
make
(create)
file
n
read next record
0
open
file
P
put record
q
quit
r
read record
by
index
s
suspend mode
t
rewind
to
top
of
file
Figure
3.9 User
Interface
Commands
The OK
reply
is
sentto the
user when a userinterface
commandexecutes successfully.A
NOTFOUND
reply
is
usually
returnedif
a requested record orfile
does
not exist.A
reply
ofFAILED
usually
meansthat
the
commandfailed
because
ofasitecrash orthe
userattemptedto
lock
atransaction
file,
acquire alock
on afile
whereexisting locks blocked
it,
or perform afile
update or read withoutthe
properlocks.
The NOTFOUND
andFAILED
repliesusually
are preceeded
by
a more specific error messageconcerning the
reasonfor
the
failure
ofthe
command.
Many
ofthese
commandshave
already
been discussed
and so will notbe dealt
withhere. The
quit and suspend mode commands are
only
coveredbriefly
here
and are explainedmorefully
in
section3.2. The
commandsthat
areleft,
recordreading
andupdating
commands and afile
[image:26.521.174.343.200.371.2]The
make or createfile
command allows a userto
openanewfile
locally. The
useris
promptedfor
the
nameofthe
file
and accesspermissions.
The
US
then
sendsarequestto
create anewfile
to
the
CSS.
As
long
asthe
CSS
canbe
reached, the
user process atthat
US has
notexceeded
the
five
openfile
limit,
and anotherfile
withthe
samenamedoes
notalready exist,
the
user receives anOK
reply.The
locking
mechanismis
notused noris it
neededfor
newly
createdfiles
sincethe
userhas
exclusive
accessto
anewfile
untilit is
closed.The
userinterface,
ordfs (distributed file
system),
promptsthe
userfor
the
recorddefinition
whenthe
makefile
commandis
invoked. The
useris
promptedfor
the
names ofthe
fields
in
a record andit
mustbe defined
withthe
first field
asthe
index
ofthe
record.A
maximum of elevenfields
may
be defined
(including
the
index
field)
andthe
length
ofthe
index
field
is
limited
to ten characters,
whilethe
restofthe
fields
may
containup to
fifteen
characters each.The
index field is
usedto
directly
access arecordwithinafile
for
reading
or updating.The
read next record andthe
read recordby
index
commands are usedto
viewthe
recordsin
an openedfile.
Only
those
records within afile
that
have been locked
withatleast
a sharelock
may be
read.The
read next record command readsthe
recordstarting
atthe
current position and changesthe
current position pointerto the
beginning
ofthe
nextrecordin
the
file. If
the
end of
the
file
is
reached, the
read next record command causesthe
file
to automatically
rewind
to the
top
ofthe
file
andthe
first
recordin
the
file is
read.The
file
can alsobe
rewoundmanually
by
calling the
rewindto
top
of
file
command.The
readrecordby
index
commandallows a userto
directly
acccess a recordif
the
userknows
the
index
ofthe
record.A NOTFOUND
reply
is
returnedto the
userif
the
index is incorrect
or
if the
recorddoes
not exist.The
put record commandis
usedto
adda new recordto
afile
orto
update anexisting
record.The
useris
promptedby
the
dfs for
the
index
andthe
fields
ofthe
recordto
be
added or updated.A
new recordis
appendedto
the
endofthe
file.
An
existing
record musthave
an exclusivelock
onit
and putsimply
over-writesthe
old record.The file is
checkedfor
the
The delete
recordcommand
alsorequires
that the
recordto
be deleted have
an exclusivelock
on
it.
The dfs
promptsthe
userfor
the
index
ofthe
record.If
successful,
the
recordis
markedfor deletion.
Actual
recorddeletion does
not occur untilthe
file
is
closed,
but
the
deleted
record
is treated
as notexisting
and cannotbe
accessed again.The dfs
removes markedrecords
by
rewriting only the
unmarked
recordsto
the
file.
If
norecord can
be
found
withthe
givenindex,
the
NOTFOUND
reply is
returned
to
the
user.The
quitcommand
is
usedto
exitfrom
the
demo
user siteprogram at a particular site.This
command also allows another site
to
be
specified asthe
demo
user site.The
suspend mode command allowsthe
userto
suspendrecordprocessing to
changethe
stateof
the
network.As
explainedin
section3.2,
any
sitein the
networkmay
be
"crashed",
"jumped
to"or"rebooted" while
in
suspend mode.When
this
commandhas
completed, the
useris
returnedto
the
userinterface.
3.1.7
Storage Site
Program
The
storage siteprogramis
executedby
a sitewhenthat
siteis
pickedto
be
the
SS
for
aUS
by
the
CSS.
The SS is
chosenbased
onthe
most up-to-datefile image
andthe reachability
ofthe
storagesites.
A
sitein
anetworkis
allowedto
execute multiple storage site programs.The
following
information is included in
the
argumentlist
sentto the
storage site program whenit is
executed:the
home
sitenumber, the
name ofthe
file
requestedby
the
US
andthe
key
for
the
storage siteprogram's message queue.Each
storagesite program returnsits
processid
to
the
home
site.The home
site storesthe
storage site program's processid in
a storage site pidtable.
The
home
site usesthe
offsetinto
this
table to
calculatethe
storage site's message queuekey
in
the
sameway
asthe
message queuekey
is determined for
each user siteprogram,
withthe
exception
that
astorage sitecode of10,000
is
usedinstead
ofaprocesscode.Once
aUS has
successfully
opened or createdafile,
the
US
nolonger
comunicates withthe
CSS
regarding this
file.
All
file
requests are now sentfrom
the
US
to the
SS.
Any
file
The
storage
site program runsuntilthe
US
sends a closefile
commandto
the
SS.
As
long
asthe
file
to
be
closedis
not atransaction
file,
the
SS
sendsthe
closefile
requestto
the
CSS
(transaction files
mustfirst be
endedwiththe
endtransaction
command).Whether
or notthe
SS is
ableto
sendthe
closecommand
andany
nontransactionchangesto the
CSS,
the
storagesite program exits after
returning
anERROR
messageto the
US
if
the
close could notbe
sentto
the
CSS
orafterreturning
anOK
message
to the
US
if
the
closewassuccessfully
sentto the
CSS
and anOK reply
wasreceivedfrom
the
CSS.
It
shouldbe
notedthat
nontransaction updates are notguaranteed andmay
leave
afile group
in
aninconsistent
state.3.1.8
Current Synchronization Site Program
The function
ofthe
CSS
is
to
synchronizefile
accesses on a network-widebasis,
enforce aglobal
locking
scheme,
andto
propagatenewfiles
andexisting file
updatesto the
sitesin
the
network.
The file
accessing
commandsthat the
CSS
handles,
asdescribed
earlier,
arethe
open
file,
the
makefile,
andthe
closefile
commands.File
and recordlocking
wasdescribed in
section
3.1.4.
andfile
propagation wasdiscussed in
section3.1.3.,
sothese topics
are notcovered
in
this
section.The initial
CSS
is
chosenatthe
beginning
ofthe
demo
program.Each
sitein
the
networkis
given,
as anargument, the
name ofthe
initial
CSS
whenthe
demo
createsthe
site process.The
sitewhose name matchesthe
designated
CSS,
executesthe
current synchronization siteprogramas an asynchronous process.
This
simulation allowsonly
oneCSS
in
the
network,
atany
giventime,
to
provideboth
readand write access
to
the
files in
the
network.However,
because
of networkpartitions andthe
need
to
provide read accessto those
sitesin
subnets without accessto the
CSS,
multiple readonly
CSSs
can occur.A
specialflag
is
setto
designate
aCSS
as read-only.This
flag
is
checkedeach
time
arequestis
receivedto
open or setlocks
on afile. As
long
asthis read-only
flag
is
set,
files
willonly
be
allowedto
be
openedfor
reading
andsharelocked.
A
read-only
CSS
canbecome
a"full
service"
CSS if
the
siteis
chosenlater
whenthe
networkreading
canbe
promotedto
updating
mode aslong
as exclusivelocks
canbe
acquired onthe
desired
record(s)
.The CSS initializes
and maintainstwo
tables;
a site statustable
and afile
location
table
(shown in
figures