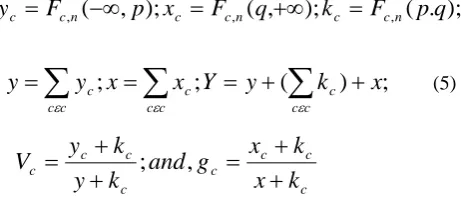International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8, Issue- 6S4, April 2019
Abstract— Ordinary desire tree classifiers artwork with recognized and specific information esteems. In late data amassing strategies, apparent diploma of developments are unsure. The unsure characteristics, in nearly all programs, have greater results on the informational index on records grouping and desire tree develops. Vulnerability want to be dealt with correctly. Vulnerability occurs due to facts staleness, some silly estimations, estimation and quantization errors. Vulnerability of an statistics factor is spoken to as some distance as one of a kind capabilities. typically unsure records are disconnected via the usage of measurable subsidiaries (eg., suggest, present day deviation, center and so forth.,). complete statistics of the information element improves the exactness of choice tree classifier (e.g., possibility Density feature (PDF)).
In this paper, the proposed work is made to enhance the pruning of desire tree classifier calculation by means of grouping with separation limits and dividing of questionable danger move esteems. Bunching methods increment the rate of desire tree improvement and restriction the pruning time to more noteworthy degree. Separation limit grouping system, works based on the criteria of lower and upper bounds distances of the uncertain attributes values.
Partitioning is done with objective function introduced on probability distribution based on the density levels. Objective function introduced evaluates the discrete value of the uncertain data item. Experiments are planned to conduct performance evaluation of heart disease diagnosis and prediction from UCI repository data sets.
Keywords — Objective Function, Decision Tree Classifiers, Cluster Interface, Uncertainty
1. INTRODUCTION
Arrangement assumes an crucial interest in the regions of facts mining and AI. The technique of grouping is finished with the aid of giving affiliation of getting equipped data tuples to the classifier, in which information tuple is associated with a category call and meant through way of an indicator vector. The purpose of arrangement is to algorithmically expand a model, which predicts the shrouded test tuple magnificence mark depending on the tuple's trademark vector.
One of the famous order fashions is the selection tree model, which is seen to be realistic and easy to understand. The grouping necessities can likewise be mined from preference wood correctly. a few calculations are created to shape desire wooden and the absolute best models are ID3 and C4.five. the choice tree primarily based completely calculations are applicable in severa non-forestall programs,
Revised Manuscript Received on April 12, 2019.
S. Chidambaranathan, Department of MCA, ) Palaymkottai 627007. Tamil Nadu, India.
St. Xavier’s College(Autonomous) Palaymkottai 627007. Tamil Nadu, India. (E-mail: [email protected])
for instance, item acknowledgment, restorative assessment, score of credit score score applicants, logical packages, safety based totally absolutely packages and goal advertising.
Information vulnerability takes location truely in some programs due to an series of reasons. The massive 3 classifications are estimation errors, statistics staleness and tedious estimations. Estimation errors happen even as the records accomplishment is finished from estimations yielded through physical devices, which activates incorrectness due to estimation blunders. data staleness takes place whilst the records esteems exchange constantly and the show information is normally stale. for example, this situation is primary in area based following framework.
At very last, stupid estimations are the maximum recognizable wellspring of vulnerability, which takes vicinity from redundant estimations. for instance, a frame temperature of a affected individual may be observed on various occasions at some point of multi day and an anemometer can record wind pace as soon as in constantly.
In preference tree affiliation, a issue 'o' of an records tuple can either be excessive pleasant or measurable. In a while later, a unique and accurate thing truly well worth is regularly understood. however, facts vulnerability is unavoidable in the considerable majority of the normal packages. The hugeness of every aspect is selected no longer with the aid of the unmistakable factor however rather by using a assembly of qualities as for opportunity conveyance.
This paper audits the emergency of making preference tree classifiers for records with uncertain actual highlights. The dreams of this artwork are to build up a calculation to set up preference bushes over questionable facts with the aid of using bunching with separation limits and dividing of uncertain possibility conveyance esteems, to explore apportioning with goal paintings, to create Distance restrict grouping gadget depending on the standards of decrease and better limits separations and to actualize a theoretical base via which the pruning strategies are eliminated for enhancing the choice classifier calculation.
2. RELATED ARTWORK
Doubtful information the executives is one of the top notch exam pastimes in most cutting-edge years. facts vulnerability for the most element characterised into
Cluster Interfaced Objective Function for
Decision Tree Classifiers for Mining Data
with Uncertainty
existential and esteem vulnerability. Existential vulnerability takes place when vulnerability happens as for a piece of writing or an statistics tuple. for instance, an information tuple being to be had in a social database is related to a opportunity that speaks to the understanding of the occasion [1]. certain probabilistic databases are worried closer to semi-organized data and eXtensible Markup Language (XML) [2]. worth vulnerability is the aftereffect of the high-quality information tuples yet now not its specific features. An information tuple critiques esteem vulnerability is typically indicated with the resource of a chance Density feature (PDF) over a limited and restricted regions of promising qualities [3].
In [4], the widely known ok-implies bunching calculation is stepped forward as uk-implies calculation, which is meant to accumulate unsure information. facts vulnerability is specially stuck with the aid of manner of PDFs that are commonly indicated through gatherings of test esteems [5]. anyways, dubious facts is tough to cope with for removing statistics, because it consists of computational in view of statistics explosion. The exhibition of united kingdom-implies is advanced by using the use of making use of pruning techniques is [6].
The doubtful data association is tested over all the time and a day regarding missing traits [7]. missing traits rise while no longer many trait esteems don't exist each records amassed works or due to the mistake occasion for the duration of information affirmation [8]. The present day methodologies encompass approximating missing qualities with the mass absolutely well worth or looking forward to the missing truly worth registered through using a classifier on the trait (e.g., requested feature tree [11] and probabilistic assets tree [9]). The lacking developments of the train data are figured with the aid of partial tuples [13] in C4.5 [10] and probabilistic desire timber [12]. In mild of the inside the past mentioned strategies, a strategy called "filling in" the missing ascribes can be used to address the ignored characteristics [14], via using thinking about the functionality of overseeing abnormal PDFs in the proposed approach. This paintings thinks approximately the PDF of the belongings, that's poor over the tuples with features. proper right here PDF is carried out as a "surmise" dispersion of the trait's an incentive inside the lacking information tuples, trailed via using which the selection tree is advanced.
3. Bunch interfaced target artwork for desire tree classifiers for mining information with vulnerability
Under our vulnerability model, Cluster Interfaced purpose feature, each detail is indicated thru a PDF and now not with the assistance of a solitary really worth. For all intents and features, this paintings assume that PDF is to be nonzero inner a confined intervening time on my own. A PDF custom designed diagnostically within the occasion that it's miles signified in shut shape. at the terrible side, it's miles very expensive to system an extensive range of take a look at focuses. This work endeavors to enhance the precision charges by means of manner of thinking about the vulnerability facts. furthermore, the proposed choice tree classifier calculation is pruned as a manner to limit the computational intricacy.
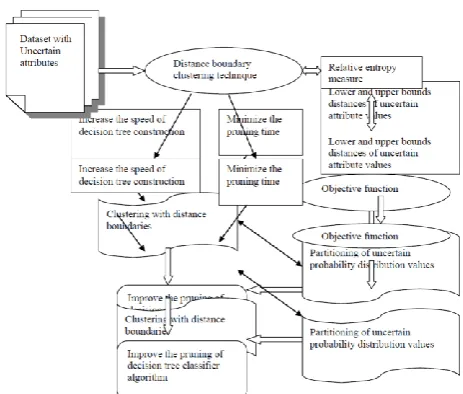
[image:2.595.309.541.124.321.2]A choice tree worked via the proposed vulnerability version is like the aspect data model and the principle impromptu introduction right here is that a preference tree is used for arranging many of the lacking check tuples, as in [17].
Figure 1: Cluster interfaced objective function for decision tree classifiers
Choice classifier calculation created by bunching with separation limits and parceling of dubious likelihood conveyance esteems. Bunching system parts the information focuses into k parcel, where each segment speaks to a group. The parcel is done dependent on certain goal work. One such measure capacities is limiting square mistake foundation which is registered as,
E = Σ Σ || p – mi || 2
(1)
where p is the point in a cluster and mi is the mean of the cluster. The cluster should exhibit two properties, they are (1) each group must contain at least one object (2) each object must belong to exactly one group.
Objective function: Defines the objective function ( F) for varied data type
)
,
(
1 x y
K
x
V
d
c
F
(2)where distance of data dx from the closest center cy
2. Selection: Calculates the probability distribution function (Pf) using the fitness value F(Sf).
)
(
)
(
1 f
F
f f f
S
F
S
F
P
(3)where Sf denotes the solution.
3. Mutation: Mutation is performed to achieve global optimum using the probability distribution function Pn.
Kk n n k
k n m
n
C
X
d
X
d
C
X
d
X
d
P
1 max
max
5
.
0
)
,
(
)
(
5
.
1
(
5
.
0
)
,
(
)
(
5
.
1
(4)
Lower and upper bounds distances of uncertain attribute values
Partitioning of uncertain probability distribution values
Objective function
Lower and upper bounds distances of uncertain attribute values Relative entropy measure
Objective function
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8, Issue- 6S4, April 2019
where d(Xn, Ck) is the Euclidean distance between pattern Xn and the centroid Ck, represents the maximum distance for the pattern Xn
3. FINALLY CONVERGENCE IS OBTAINED BY
APPLYING K-MEANS OPERATOR. Steady with the dialog, the amazing trait alongside the cut up aspect for a hub are recognized thru the Cluster Interfaced objective feature, which needs to assess the split focuses for the hubs, in which n and k mean the complete amount of homes and variety of data tuples separately. each such up-and-comer homes and cut up thing f, an entropy E must be determined.
Entropy estimation is a calculation focused a part of Cluster Interfaced aim feature. This work actualizes capable calculation for showing better strategies, if you want to prune up-and-comer break up focuses and entropy computations. This artwork prunes away up-and-comer break up focuses alone, which give tough entropy esteems. After the end of pruning, the correct break up focuses are identified. ultimately, the pruning calculations don't have any impact over the choice tree improvement, which might be tested by way of our analyses. The imperfect up-and-comers from notion are disposed of and this quickens the machine of tree building.
Nextly, our Cluster Interfaced goal function for choice Tree Classifiers plans to prune heterogeneous interims by way of methods for a jumping manner. at first, the entropy for all of the end focuses is decided. subsequent, for every heterogeneous 09e2341fd293cc323cfb97bbbbaf957d, we take a look at in a lower certain, Ln, over all of the up-and-comer split focuses, the whole interim is pruned.
It's miles seen that the all out range of end focuses is tremendously negligible than absolutely the huge kind of up-and-comer cut up focuses. therefore, even as more and more heterogeneous interims are pruned thru along those lines, the tally of entropy estimations may be constrained. therefore, the belief here is to distinguish a decrease sure, this is something however difficult to manipulate but makes the way in the route of pruning proficient. This idea is inferred with a positive Ln as exhibited in the accompanying
element. previous to that, a couple of photographs are acquainted with accomplish the declaration of the certain in an unmistakable and recognizable association:
);
.
(
);
,
(
);
,
(
, ,,
p
x
F
q
k
F
p
q
F
y
c
cn
c
cn
c
cn;
)
(
;
;
x
x
Y
y
k
x
y
y
c c
c c
c c c
c
c
(5)
c c c c c
c c c
k
x
k
x
g
and
k
y
k
y
V
;
,
where p,q denotes bounded interval variables, c is a class label and Fc,x is a tuple count. By using the Equation (5)
lower bound value is computed in equation (6) which is given below.
})] , (max{ log log
log [ 1
2 2
2 c c c c c c
c c
c
n y V x g k V g
Y
L
(6)
The lower bound calculation is intently connected with the count of the entropy. Both these systems are equivalent to the count of entropy over a split point. Consolidating this heterogeneous interim pruning strategy with the invalid and homogeneous interims, brings about an effective Local Pruning calculation of Cluster Interfaced Objective Function.
4. PERFORMANCE EVALUATION ON CLUSTER
INTERFACED OBJECTIVE FUNCTION FOR DECISION TREE CLASSIFIERS
[image:3.595.312.543.96.201.2]The exhibition of accomplishing better grouping exactness by considering information vulnerability is examined with the proposed Cluster Interfaced Objective Function and connected them to coronary illness conclusion and expectation taken from the UCI Machine Learning Repository. A dataset with numerical qualities is picked for mimicking the proposed work. The investigations are done by setting up classifiers dependent on the numerical traits and their related "mark" characteristics. The characteristics of the dataset utilized are given in the table 1.
Table 1: Sample dataset of heart disease diagnosis
age sex cp trest
bps
chol fbs restecg thalach exang oldpeak slope ca thal num
63 male typ_angina 145 233 t left_vent_hyper 150 no 2.3 down 0 fixed_defect '<50'
67 male asympt 160 286 f left_vent_hyper 108 yes 1.5 flat 3 normal '>50_1'
67 male asympt 120 229 f left_vent_hyper 129 yes 2.6 flat 2 reversable_defect '>50_1'
37 male non_anginal 130 250 f normal 187 no 3.5 down 0 normal '<50'
41 female atyp_angina 130 204 f left_vent_hyper 172 no 1.4 up 0 normal '<50'
56 male atyp_angina 120 236 f normal 178 no 0.8 up 0 normal '<50'
62 female asympt 140 268 f left_vent_hyper 160 no 3.6 down 2 normal '>50_1'
57 female asympt 120 354 f normal 163 yes 0.6 up 0 normal '<50'
63 male asympt 130 254 f left_vent_hyper 147 no 1.4 flat 1 reversable_defect '>50_1'
53 male asympt 140 203 t left_vent_hyper 155 yes 3.1 down 0 reversable_defect '>50_1'
56 female atyp_angina 140 294 f left_vent_hyper 153 no 1.3 flat 0 normal '<50'
56 male non_anginal 130 256 t left_vent_hyper 142 yes 0.6 flat 1 fixed_defect '>50_1'
44 male atyp_angina 120 263 f normal 173 no 0 up 0 reversable_defect '<50'
52 male non_anginal 172 199 t normal 162 no 0.5 up 0 reversable_defect '<50'
57 male non_anginal 150 168 f normal 174 no 1.6 up 0 normal '<50'
48 male atyp_angina 110 229 f normal 168 no 1 down 0 reversable_defect '>50_1'
54 male asympt 140 239 f normal 160 no 1.2 up 0 normal '<50'
48 female non_anginal 130 275 f normal 139 no 0.2 up 0 normal '<50'
49 male atyp_angina 130 266 f normal 171 no 0.6 up 0 normal '<50'
In our experiment, we use 14 attributes which are described below.
1. Age: age in years
2. Sex: sex (1 = male; 0 = female) 3. Cp: chest pain type
-- Value 1: typical angina -- Value 2: atypical angina -- Value 3: non-anginal pain -- Value 4: asymptomatic
4. Trestbps: resting blood pressure (in mm Hg on admission to the hospital)
5. Chol: serum cholestoral in mg/dl
6. Fbs: (fasting blood sugar > 120 mg/dl) (1 = true; 0 = false)
7. Restecg: resting electrocardiographic results -- Value 0: normal
-- Value 1: having ST-T wave abnormality (T wave inversions and/or ST
elevation or depression of > 0.05 mV)
-- Value 2: showing probable or definite left ventricular hypertrophy
by Estes' criteria
8. Thalach: maximum heart rate achieved
9. Exang: exercise induced angina (1 = yes; 0 = no) 10. Oldpeak = ST depression induced by exercise relative to rest
11. Slope: the slope of the peak exercise ST segment -- Value 1: upsloping
-- Value 2: flat
-- Value 3: downsloping
12. Ca: number of major vessels (0-3) colored by flourosopy
13. Thal: 3 = normal; 6 = fixed defect; 7 = reversable defect
14. Num: diagnosis of heart disease (angiographic disease status)
-- Value 0: < 50% diameter narrowing -- Value 1: > 50% diameter narrowing
The above provided table 4.1 is taken from [16]. A preference tree is normal built recursively in a pinnacle-down way (from root) for uncertain statistics via combining numerical and categorical attributes. all of the viable attributes each in phrases of numerical or specific values are taken into account for each node. The entropy price of the cut up node is computed and the characteristic that yields the greatest statistics benefit is chosen. The node is allocated with that precise characteristic and break up factor, in case of numerical attribute and the facts tuples are transmitted to the child
nodes. all of the little one nodes are processed in a recursive mode.
The entropy of a categorical characteristic is analyzed thru splitting the tuples into a collection of buckets. Tuple is copied as a trendy tuple in which the PDFs are inherited, besides for attribute. The entropy value for the break up on attributes is computed through buckets. a specific characteristic which has achieved the assignment of splitting an ancestor node can't be utilized, because it cannot offer any facts gain, even as the tuples are break up with recognize to the specific express characteristic again.
5. CONSEQUENCES AND DISCUSSIONS
RESULTS
[image:4.595.7.596.49.166.2]Amazing experiments are performed to reveal that the proposed classifiers show better accuracy charges than the ones which can be based on average values with the assist of statistical derivatives. Processing opportunity density functions are computationally highly-priced while in assessment to unmarried cost processing (e.g., averages), choice tree formation for uncertain information consumes maximum CPU time. Pruning techniques are tailored to decorate production performance.
Table 2: Pruning effectiveness Number Of
Entropy Calculation
Pruning Effectiveness (%)
UDT-ES Cluster
Interfaced Objective Function
100 69 99
200 68 98
300 60 96
400 64 97
500 67 84
600 62 85
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8, Issue- 6S4, April 2019
Fig 2 : Pruning effectiveness
[image:5.595.41.288.487.773.2]This a part of evaluation has validated the pruning effectiveness of the Cluster Interfaced purpose function. Fig. 2 depicts the number of entropy calculations completed with the aid of Cluster Interfaced goal function and UDT-ES. As stated earlier, the computation time of the lower positive of an c program languageperiod is more or much less much like that of the computing entropy. for this reason, for Cluster Interfaced intention function, the entire depend variety of entropy calculations consists of the quantity of calculated lower bounds. The figure 2 illustrates that the proposed pruning technique indicates better performance. On evaluating the techniques in resultant graph against that for Cluster Interfaced objective function, it's miles recognized that numerous entropy calculations are removed with the aid of the proposed bounding techniques. via pruning forestall points, Cluster Interfaced intention feature minimizes the quantity of entropy calculations and increasing the pruning performance. sooner or later, pruning effectiveness is finished that ranges from 83 % to 99 %. because of the fact, the entropy price calculations impact over the execution time of Cluster Interfaced goal characteristic, the time intake for constructing tree is substantially decreased.
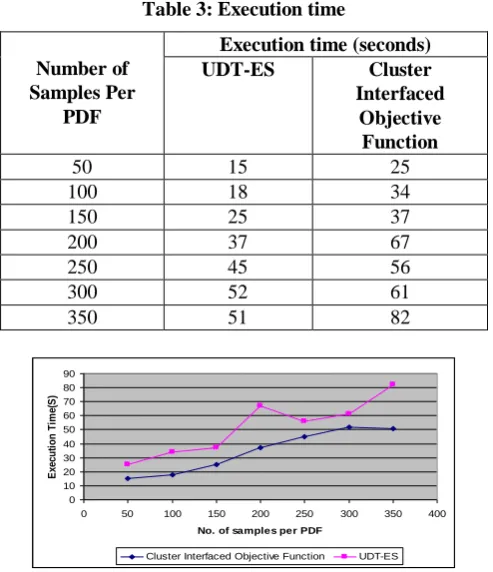
Table 3: Execution time
Number of Samples Per
Execution time (seconds)
UDT-ES Cluster
Interfaced Objective
Function
50 15 25
100 18 34
150 25 37
200 37 67
250 45 56
300 52 61
350 51 82
Fig 3: Execution time
We've given the execution time of Cluster Interfaced purpose characteristic. be aware that Cluster Interfaced purpose characteristic assembles diverse preference timber via Distance limit bunching system and intention paintings. within the investigation, every PDF is confirmed through the use of one hundred example focuses. For the informational series coronary infection end and forecast, the proposed pruning strategies are talented, which brings down the execution time of Cluster Interfaced objective function lesser than 1.7 sports of that of UDT-ES, while project higher characterization precision.
6. CONCLUSION
In this paper we've exhibited the Cluster Interfaced goal characteristic for preference Tree Classifiers for Mining Uncertainty information. Pruning of desire tree classifier calculation has been progressed thru bunching with separation limits and dividing of doubtful probability drift esteems. Grouping is executed thru Distance restriction bunching machine, in mild of the standards of decrease and higher limits separations of the dubious houses esteems. Parceling and evaluating the discrete estimation of uncertain information is finished with the aid of the use of aim potential. Relative entropy degree is made at the decrease and better constrained separations on the ascribe characteristics identified with other assurance trends in the informational index. check consequences completed with the measurements as Pruning Effectiveness, amount of entropy figurings and Execution time which accomplish a remarkable deal better arrangement exactness.
REFERENCES
1. C.C. Aggarwal, "On Density based absolutely Transforms for unsure records Mining," Proc. Int'l Conf. statistics Eng. (ICDE), Apr. 2007, pp. 866-875.
2. A. Asuncion and D. Newman, UCI device gaining
knowledge of Repository,
http://www.ics.uci.edu/mlearn/MLRepository.html, 2007. 3. M. Chau, R. Cheng, B. Kao, and J. Ng, "Questionable
records Mining: An example in Clustering location information," Proc. Pacific-Asia Conf. mastering Discovery and data Mining (PAKDD), Apr. 2006, pp. 199-204.
4. J. Chen and R. Cheng, "effective evaluation of vague place-established Queries," Proc. Int'l Conf. facts Eng. (ICDE), Apr. 2007, pp. 586-595.
5. R. Cheng, D.V. Kalashnikov, and S. Prabhakar, "questioning vague facts in transferring object Environments," IEEE Trans. facts and information Eng., vol. 16, no. 9, Sept. 2004, pp. 1112-1127.
6. R. Cheng, Y. Xia, S. Prabhakar, R. Shah, and J.S. Vitter, "efficient Indexing strategies for Probabilistic Threshold Queries over unsure data," Proc. Int'l Conf. large statistics Bases (VLDB), Aug./Sept. 2004, pp. 876-887.
7. C.ok. Chui, B. Kao, and E. Hung, "Mining frequent Itemsets from unsure data," Proc. Pacific-Asia Conf. mastering Discovery and information Mining (PAKDD), may also 2007, pp. 47-fifty 8.
40 50 60 70 80 90 100 110
0 100 200 300 400 500 600 700 800
No. of entropy calculation
P
run
ing
e
ff
e
c
ti
v
e
ne
s
s
(
%
)
Cluster Interfaced Objective Function UDT-ES
0 10 20 30 40 50 60 70 80 90
0 50 100 150 200 250 300 350 400
No. of samples per PDF
E
x
e
c
ut
ion
Ti
m
e
(S
)
8. L. Hawarah, A. Simonet, and M. Simonet, "A Probabilistic method to classify Incomplete items using desire timber," Proc. Int'l Conf. Database and professional structures applications (DEXA), Aug./Sept. 2004, pp. 549-558. 9. E. Hung, L. Getoor, and V.S. Subrahmanian, "Probabilistic
c language XML," ACM Trans. Computational common sense (TOCL), vol. eight, no. four, 2007.
10. H.- P. Kriegel and M. Pfeifle, "Thickness based totally definitely Clustering of unsure information," Proc. Int'l Conf. gaining knowledge of Discovery and records Mining (KDD), Aug. 2005, pp. 672-677.
11. S.D. Lee, B. Kao, and R. Cheng, "Diminishing uk-approach to KMeans," Proc. First Workshop information Mining of uncertain records (DUNE), related to the 7th IEEE Int'l Conf. statistics Mining (ICDM), Oct. 2007. 12. W.good enough. Ngai, B. Kao, C.k. Chui, R. Cheng, M.
Chau, and k.Y. Howl, "productive Clustering of unsure statistics," Proc. Int'l Conf. information Mining (ICDM), Dec. 2006, pp. 436-445.
13. S. Tsang, B. Kao, k.Y. Howl, W.- S. Ho, and S.D. Lee, "preference timber for unsure records," Proc. Int'l Conf. information Eng. (ICDE), Mar./Apr. 2009, pp. 441-444. 14. Smith Tsang, Ben Kao, Kevin Y. Howl, Wai-Shing Ho,
and Sau Dan Lee, "preference wooden for uncertain data",
IEEE Transactions On
bdd5b54adb3c84011c7516ef3ab47e54 And facts Engineering, vol. 23, no. 1, 2011.
15. Xiaofeng Zhu, Shichao Zhang, Zhi Jin, Zili Zhang, and Zhuoming Xu, "lacking value Estimation for mixed-attribute records units", IEEE Transactions On know-how And information Engineering, vol. 23, no. 1, 2011. 16. Jaya, I. (2013). Analisis Seleksi Atribut Pada Algoritma
Naive Bayes Dalam Memprediksi Penyakit Jantung (hold close's proposition).