Rochester Institute of Technology
RIT Scholar Works
Theses
Thesis/Dissertation Collections
2002
Simultaneous multithreading: Operating system
perspective
Vyacheslav Rubinfine
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion
in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact
Recommended Citation
Simultaneous Multithreading:
Operating System Perspective
By
Vyacheslav Rubinfine
A Thesis Submitted
In
Partial Fulfillment of the
Requirements for the Degree of
MASTERS OF SCIENCE
In
Computer Engineering
Approved by:
Committee Principle:
Date:
(1-
5 -
'20
GZ GZ GZ GZ GZ GZ GZ GZ GZ GZ GZ GZ GZ GZ GZ GZ GZ GZ GZ GZ
-Dr. Muhammad Shaaban
Committee Member:
Date:
hv.cJ€
2b0
c..-Dr. Roy S. Czemikowski
Committee Member:
Date:
J,/bv-
S-:..-?
t*71.
Dr. Hans-Peter Bischof
Department of Computer Engineering
College of Engineering
THESIS RELEASE PERMISSION FORM
Rochester Institute of Technology
Simultaneous Multithreading:
Operating System Perspective
I, Vyacheslav Rubinfine, hereby grant perrmSSlOn to any individual or organization to
reproduce this thesis in whole or in part for non-commercial and non-profit purposes only.
Abstract
Developing
CPU
architecture
is
avery
complicated,
iterative
processthat
requiressignificant
time
andmoney
investments.
The
motivationfor
this
workis
to
find
waysto
decreases
the
amount oftime
andmoney
neededfor
the
development
ofhardware
architectures.
The
main problemis
that
it is
very
difficult
to
determine
the
performance ofthe
architecture,
sinceit is impossible
to take
any
performance measurements untill uponcompletion of
the
development
process.Consecutively,
it is
impossible
to
improve
the
performance of
the
product orto
predictthe
influence
ofdifferent
partsofthe
architectureon
the
architecture's overall performance.Another
problemis
that
this
type
ofdevelopment does
not allowfor
the
developed
systemto
be
reconfigured or alteredwithout complete re-development. .
The
solutionto the
problems mentioned aboveis
the
software simulatorsthat
allowresearching
the
architecturebefore
evenstarting
to
cutthe
silicon..Simultaneous
multithreading
(SMT)
is
amodernapproachto
CPU
design. This
technique
increases
the
system
throughput
by decreasing
both
total
instruction
delay
and stalltimes
ofthe
CPU.
The
gainin
performance of atypical
SMT
processoris
achievedby
allowing
the
instructions from
severalthreads to
be
fetched
by
anoperating
systeminto
the
CPU
simultaneously.
In
orderto
function successfully
the
CPU
needs software support.In
modern computer systemsthe
influence
of anoperating
system on overall systemperformancecan no
longer be ignored. It
is important
to
understandthat the
union ofthe
CPU
andthe
supporting operating
system andtheir
interdependency
determines
the
overall performance of
any
computer system.In
the
systemthat
has been
implemented
on
hardware
level
such analysisis
impossible,
sincethe
hardware
systemis
neitherflexible
nor configurable.However,
in
the
SMT
architecture, the
systemis
capable ofperforming
some useful work evenif
atask
has
generated an error.A
wide range ofsimulators
is
described
in
the
literature,
and alot
ofthem
arepublicly
accessible.The
main goal ofthis
workis
to
modify
anexisting
SEVIOS/Topsy
simulatorto
process of
the
SMT
MIPS,
as well asscheduling
aspects ofthe
CPU
andthe
operating
system
integrated
environment..This
work covers abroad
range ofaspects,
among
which are:1)
Completion
ofSMT
MIPS
andSMT
Topsy
specifications;
2)
Integration
ofMXS
into
SIMOS/Topsy;
3)
Modifications
to the
fetching
unit ofMXS
that
allowto
supportSMT;
4)
Addition
ofSMT
supportto
Topsy;;
This
work usesTopsy/R4000
simulatordeveloped
atSwiss
Federal Institute
ofTechnology,
andthe
MXS
(R10000)
part ofthe
SimOS
simulatordeveloped
atStanford
University.
Development
process utilizesC
high-level
language,
Intel
andMIPS
assembly
languages.
The
result ofthis
workis
adevelopment
of a complete computer system softwaresimulator.
The
simulator allowstaking
performance measurements andreconfigurationofSMT
Topsy
andthe
fetching
unit ofthe
SMT MXS.
The
simulatoris
modular:that
is
any
ofits
parts canbe
substituted with otherpartsthat
perform similarfunctionality.
It
also means
that the
whole simulator canbe
integrated into
alarger
scale simulationproject.
The development
ofthis
simulatorsignificantly decreases
the
amount oftime
andmoney
neededfor
the
development
ofhardware
architectures and providesnewwaysin
researching
the
influence
of anoperating
system onthe
performance ofthe
computerAcknowledgements
This
workis dedicated
to
my
family
that
has
supported andinspired
meduring
the
difficult
time
I
have
spent at school.I
am gratefulto
my
wifeElena for spending
countlesshours
doing
proofreading
and other paperwork.
Thanks
goto
my friend Slava Rozman for his
help
in
completion of successful
installation
and compilation ofthe
software.I
am gratefulto
Professor Muhammad E. Shaaban
atthe
Computer
Engineering
department
ofthe
Rochester Institute
ofTechnology
for raising my interest in
to
the topic
andpatiently answering
allmy
questions relatedto
various computerarchitectures and
operating
systems.I
wishto thank
him for giving
methe
opportunity
to
work onthis
project andshaping my
learning
withhis
valuableTrademarks
This
workis
based
onthe
following
software:SimOS
Trademark
ofStanford
University
Table
of
Contents
List
ofFigures
3
List
ofTables
5
Glossary
ofTerms
6
Chapter 1. Introduction
8
1.1. Basic
architectures andtechniques
8
1.2. Pipeline
andhazards
10
1.3.
Superscalar
architecture andSMT
15
1.4. Overview
ofsubsequentchapters16
Chapter 2.
Developing
SMT
SimOS/Topsy
environment17
2.1. Basic
SimOS/Topsy
environment17
2.2.
Switching
to
SMT
SimOS/Topsy
environment18
2.2.1. Problems
associatedwithbasic
SimOS/Topsy
environment19
2.2.2. SMT
SimOS/Topsy
environment19
2.2.3.
Work
cycle ofthe
SMT
SimOS/Topsy
environment21
2.3. Annotations
vs.Performance Counters
23
Chapter 3.
Developing
SMT MXS CPU
model26
3.1. General
Description
27
3.2.
Instruction
Set
29
3.3.
Pipeline
34
3.4.
Caches
38
3.4.1.
Primary
Instruction Cache
38
3.4.2.
Primary
Data
Cache
38
3.4.3.
Secondary
Cache
39
3.4.4.
Cache
Algorithms
39
3.4.5.
Virtual
Address
Translation
andPages
40
3.5.
Fetching
Unit
ofSMT
MXS CPU
model41
3.5.1
Basic
MXS
Fetching
Unit
41
3.5.2
SMT
MXS
Fetching
Unit
42
3.5.3
Enhanced
SMT
MXS
Fetching
Unit
43
3.6. Register
Renaming
Unit
andSpecial
Techniques
47
3.6.1.
Operating
System
Support
for
Register
Renaming
49
3.6.2.
Compiler
Support for
Register
Renaming
51
3.6.3. SMT
MXS Support
for
Register
Renaming
53
3.7.
SMT
Issue
Queues
55
3.7.1
Integer
Queue
55
3.7.2 Floating-point
Queue
56
3.7.3. Address
Queue
56
3.8.
Branch Prediction Policies
57
3.9.
Branch Prediction
Unit
ofSMT
SimOS
65
3.10. WRITE
Branch Prediction
Policy
72
3.11.
Exception
Handling
in
SMT
MXS
72
3.1 1.1.
Cold
Reset Exception
74
3.11.2.
Soft
Reset Exception
75
3.11.4.
TLB
Exception
76
3.11.5. System Call Exception
78
3.12. SMT MXS Coprocessor 0
79
Chapter 4.
Developing
SMT
Topsy
83
4.1. Slow Interrupts
83
4.2. OS:
loading
executablefiles
88
4.3. Topsy:
current architecture89
4.4.
Switching
to
SMT:
Bootstrapping
process90
4.5. SMT startup
anddynamic
loading
92
4.6. SMT Threads Module
93
4.7. Demand
Paging
in SMT
Topsy
101
4.8.
SMT
Memory
Management Module
103
4.9.
SMT Scheduler
106
4.9.1. Basic
Topsy
Scheduler
106
4.9.2. SMT
Topsy
Schedule
107
4.9.3. SMT
Topsy
Scheduler Interface
1
10
4.10.
Exception
Handling
1 1 1
4.11. SMT
Topsy
Shell
112
Chapter
5.
Simulation
Results
1 14
5.1.
SMT
fetching
unit performance114
5.2.
SMT
Topsy
schedulerperformance119
Chapter
6.
SMT MXS
SimOS/Topsy
Installation
andConfiguration
124
6.1.
Binary
Utilities
installation instructions
124
6.2.
MIPS
Cross-compiler installation instructions
125
6.3.
SMT
SimOS/Topsy
integrated
environmentinstallation instructions
125
6.4. SMT
MXS
SimOS/Topsy
Configuration
127
Chapter
7.
Conclusion
130
List
of
Figures
Figure 1. Basic
SimOS/Topsy
environment.Page
17.
Figure 2. SMT
SimOS/Topsy
environment.Page
19.
Figure
3.
Work
cycleof
SMT
SimOS/Topsy
environment.Page 21.
Figure
4.
Viewing
data
withRIT
Viewer
application.Page 24.
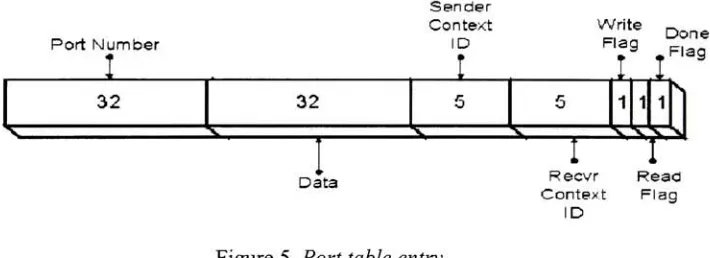
Figure 5.
Port
table
entry.Courtesy
ofDominik
Madoh,
Eduardo
Sanchez,
Stefan
Monnier,
Computer Science
Department,
Yale
University.
Page 32.
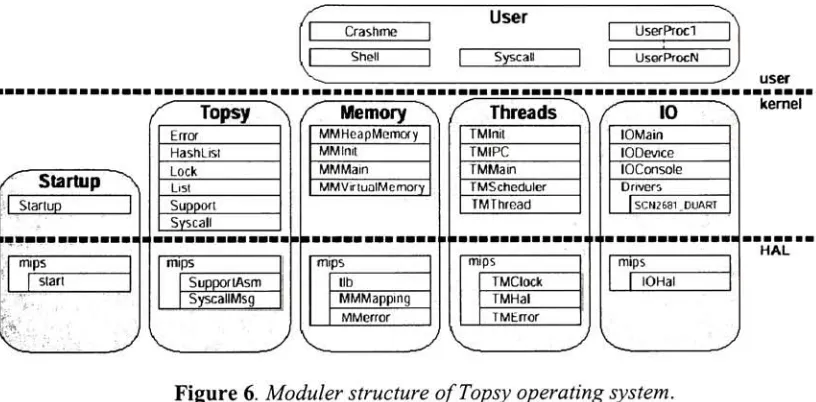
Figure 6.
Modular
structureof
Topsy
operating
system.Courtesy
ofGeorge
Fankhauser,
Christian
Conrad,
Eckart
Zitzler,
Bernhard
Partner,
Computer
Engineering
andNetworks
Laboratory,
ETH Zurich. Page
89.
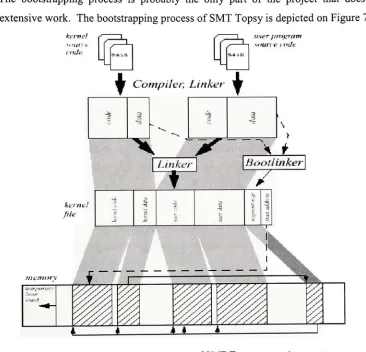
Figure
7.
Bootstrapping
processof SMT
Topsy
operating
system.Courtesy
ofGeorge
Fankhauser,
Christian
Conrad,
Eckart
Zitzler,
Bernhard
Partner,
Computer
Engineering
andNetworks
Laboratory,
ETH Zurich. Page 90.
Figure 8. Kernel
thread
messages queue organizationof
Topsy
operating
system.Courtesy
ofGeorge
Fankhauser,
Christian
Conrad,
Eckart
Zitzler,
Bernhard
Partner,
Computer
Engineering
andNetworks
Laboratory,
ETH Zurich.
Page 97.
Figure
9. Kernel
threadmessages queue organizationofSMT
Topsy
operating
system.Page 98.
Figure
10.
SMT MXS
fetching
process.Page 106.
Figure 12. BasicMXS
Fetching
Unit
performance.Page 114.
Figure 13. SMT MXS
Fetching
Unit
performance:2
contexts.Page 115.
Figure 14. SMT MXS
Fetching
Unit
performance:4
contexts.Page 116.
Figure 15. SMT
MXS
Fetching
Unit
performance:8
contexts.Page 1
17.
Figure 16.
Comparing
none-SMTandSMT
MXS
Fetching
Units. Page 117.
Figure
17.
Comparing
none-SMTandSMT
MXS
Fetching
Units. Page 118.
Figure
18.
Basic
Topsy
scheduler.Page
118.
Figure 19. SMT
Topsy
scheduler.Page 1 19.
Figure 20. Basic
Topsy
scheduling
process.Page 120.
Figure 21.
SMT
Topsy
scheduling
process.Page
121.
Figure
22.
SMT
Topsy
scheduling
process.Page 122.
Figure
23.
Comparing
SMT
Topsy
scheduling
processes,List
of
Tables
Table 1.
Main
configuration parametersofSMT
SimOS/Topsy
environment.Page 20.
Table
2.
Viewing
data
withRIT
Viewer
application.Page
24.
Table 3. General
specificationof
SMT
microprocessor.Page
28.
Table
4. Instructions
compatibility in SMT
microprocessor.Page 37.
Table 5.
Operational
modesofSMT
MIPS
microprocessor.Page
40.
Table
6. SMT Coprocessor 0
instructions.
Page 79.
Table 7. Number
andtypes
of
registersin SMT MXS
CPU
model.Page
127.
Table
8. Parameters
relatedto
registerrenaming
andload/store
operationsin SMT MXS
simulator.
Page
128.
Table 9. Bandwidth
parametersof SMT MXS
simulator.Page 128.
Table
10.
Branch
prediction parametersofSMT MXS
simulator.Page 129.
Table
11.
Latencies of
the
various operationsof
thefunctional
Glossary
of
Terms
Superscalar
-CPU
architecture
that
canfetch,
execute and complete morethat
oneinstruction in
parallel.ANDES
-Architecture
with
Non-sequential Dynamic
Execution
Scheduling
Dynamic instruction scheduling
-CPU issues
an
instruction
as soon as allits
operands
become
availableandthe
required execution unitis
notbusy.
Out-of-order
execution-in Superscalar CPU -instructions
canbe
executed notin
program order..
Speculative
branching
-the
CPU
executesthe
branch
based
onthe
previoushistory
ofthe
branch
orbased
onits
ownfetching
policy,
sincethere
is
not enoughtime
for
the
CPU
to
calculatethe
realbranch
addressdue
to the
CPU fetch bandwidth.
Non-blocking
cache-type
ofcache,
in
which cache missesdo
not stallthe
CPU.
Wrong-path instructions
-instructions
that
werefetched
asthe
result ofbranch
misprediction.
Pipeline
-the
process ofdividing
of eachinstruction into
a sequence of simplersuboperations
(stages),
each of whichis
performedby
a separatehardware
unit.Pipeline
latency
-the
number of cycles
between
the time
aninstruction
is issued
andthe time
the
dependent
instruction
(the instruction
which usesits
resultas anoperand)
can
be issued.
Precise
exceptionhandling
-technique that
allowshandling
of an exception atthe
moment
it
occurs.A
typical
processordesign implements
precise exceptionsby:
1)
identifying
the
instruction,
which causedthe exception;
2)
preventing
the
exception-causing instruction
from
graduating;
3)
aborting
all subsequentinstructions.
Strong
ordering
-in-order
instruction
graduationmaintained, though the
instructions
may
be issued
and executed out-of-order.Register renaming
-logical
registers specifiedin
the
operands are mappedto
Forwarding
logic
-hardware
that
makesthe
result of aninstruction
availablefor
subsequentinstructions before
the
instruction
graduates.Dead-register distance
-the
number ofcycles passedbetween
a register'slast
use andits
redefinition.HAL
-hardware
abstractionlayer.
SMT
-simultaneous multithreading.
The
SMT-capable
CPU
can processinstructions from
several processes simultaneously.The SMT-capable operating
system can
have
several processesin running
state simultaneously.SIMOS
-complete machine simulator environment
developed
atStanford
University.
SMT
SIMOS
-completemachine simulator environment
that
supportsSMT.
Topsy
-simple
Teachable
Operating
System
developed
atSwiss
Federal Institute
ofTechnology.
SMT
Topsy
-Topsy
that
supportsSMT.
MIPS
-CPU
type.
Can be
referred
to
in
conjuntion withR3000, R4000, R10000,
orR12000
processors.SMT MIPS
-MIPS
processor model
that
supportsSMT.
SIMOS/Topsy
-integrated
environment
that
includes
both
SEVIOS
andTOPSY.
SMT
SIMOS/Topsy
-SIMOS/Topsy
that
supportsSMT.
MXS
-part of
SEVIOS
that
implements
R10000
CPU.
SMT MXS
-MXS
that
Chapter
1.
Introduction
Section
1.1
illustrates
basic
architectures andtechniques that
are usedin CPU
design.
Section 1.2 describes
the
issues
relatedto
pipelining
and problems associated withthis
technique.
Section 1.3
represents superscalarandSMT CPU
architectures.Section 1.4
providesan overview ofthe
subsequent chapters.7. 7.
Basic
architectures and
techniques
During
the
secondhalf
oflast
century
computertechnology
has
madeincredible
progress.The
microprocessorperformance growthimproved
atthe
rateofroughly
35%
per year[1].
Any
modern computer architecturehas
to
satisfy
variousrequirements,
such as:1)
Instruction
set architecture should referto
the
actual visible user set ofassembly
instructions.
At
the
sametoken, it has
to
be
minimal,
yetflexible
enough, to
allowthe
userto
manipulate all aspects of
the
contemporary
CPU.
2)
Modern memory
hierarchy
should notonly
include
physicalimplementation
of allthe
levels
ofcaches,
but
alsoeffectivememory
management strategies.These
strategiesimply,
but
notlimited
to
increasing
the
hit/miss
cacheratio,
memory consistency
and access andmanaging
persistentmedia.3)
Performance
shouldinclude
such aspects asinstructions
scheduling
andexecution;
hardware
interrupts.
4) Operating
systems specifics shouldinclude
processesscheduling,
processmemory
management,
softwareinterrupts,
file
systems andother aspects.In
light
ofthe
complicatedtasks
mentionedabove, and,
in
particular,
ofthe
CPU
performance
requirements, this
work addressesthe
following
issues:
1)
General definition
ofthe
main principals ofhigh
performanceCPUs.
2)
Formulation
ofthe
hardware
and software requirementsfor
the
CPU
modelalong
with3)
Determination
ofthe
factors
that
allow most efficientinteraction between
aUNIX-type
operating
systemandthe
high
performanceCPU.
4)
Identification
andimplementation
of a set ofchangesto the
operating
systemthat
allows reliable use ofSMT
features.
5)
Foundation
for future
research anddevelopment in
the
area of computerengineering
consistent withthe
findings
presentedin
this
work.The
formula
presentedbelow is
usedto
calculateperformance ofany
CPU:
P
=IC
*CPI
*T;
Where: IC
-instruction
counter,
indicates
the total
numberofinstructions in
aprogram;
CPI
-cycles per
instruction,
indicates
the
number of machine(command)
cycles perinstruction;
T
-clock cycle
time that
is
individually
measuredfor
eachtype
ofCPU.
This formula determines
that
the
CPU
executiontime
is
equally
dependent
on all ofthethree
parameters:IC,
CPI
andT.
Since
T
is
a constanthardware
characteristic of eachparticulartype
ofCPU
anddoes
not changedepending
on process parameters andorganization, this
workis
mostly
dedicated
to the
othertwo
component ofthe
equation:IC
andCPI.
The
stack-basedCPU
designs
suggested a goodIC
*CPI
ratio
by
allowing
all operationsto
utilizethe
stack.In
that case, the
CPU
waswaiting
onthe
first
operandto
be
pushed ontothe stack, then
for
the
second operandto
be
enteredlikewise,
the
operationto
occupy
the
top
ofthe stack, and,
atlast,
for
executionto take
place.The
accumulator-based architectures employedslightly
different
approach.One
operand wasloaded into
a special purposeregister,
also calledaccumulator,
andthe
other operand was accesseddirectly
from
memory
orloaded into
anothertemporary
location
and accessedfrom
there.
Those
two
instruction
set architectureswere named register-register andregister-memory
architectures accordingly.They
both
presentedadvantages,
as well asdisadvantages:
disadvantage
ofthe
register-register architectureis
that
instructions
cannotdirectly
referto
memory;
the
IC
for
this
architectureis higher
than
for
the
register-memory
architecture.2)
The
advantage ofthe
register-memory
architecture presents good codedensity,
whichyields
the
goodIC.
Because
the
instructions
containdirect memory
references,
data
canbe
accessedwithout
loading
first. One
ofthe
disadvantages
ofthe
register-memory
architectureis
that
eventhough the
CPI
parameterfor
this
architectureis lower
than
for
the
register-register
architecture,
the
operandsare not equalin
size.Another
disadvantage
ofthe
register-memory
architectureis
that
encoding
a register number and amemory
addressin
eachinstruction
may
restrictthe
number ofregisters.The
listed
above architectures presented a significantfreedom
to
computer engineersand
designers.
However,
neither ofthe
architectures could produce a significantboost in
the
CPU
performance.The
reasonfor
that
wasthat the
CPU
executed allthe
instructions (no
matter
from
wherethey
weretaken)
sequentially.Therefore,
the total
executiontime
depended
linearly
onthe
number ofthe
instructions introduced
by
a particular process.On
the
otherhand,
analysis of processes showedthat
atypical
processhad
alarge
number of independentinstructions. The CPU designers faced
a great challengein
developing
technique
that
allows multipleinstructions
to
be
simultaneously
issued
to the
CPU.
1.2. Pipeline
and
hazards
The
basic idea
ofpipelining
(the
new andpromising
way
ofissuing
multipleinstructions
to
the
CPU)
is
simple: similarto
anassembly
line,
aninstruction
executionis
broken
up
into
several steps.Different
stages complete particular parts of variousinstructions in
parallel.Each
ofthese
stepsis
named either a pipe stage or a pipe segment.This instruction
executiontime
canbe
calculated as a product ofthe
number of pipelinestages
(the
pipelinedepth)
andthe
length
ofthe
slowest pipelinestage,
assuming
that there
are no problems
during
the
executionthat
may
postponethe
execution ofthe
instruction.
Such
time
is
requiredto
measurethe
ideal
performanceofthe
pipeline.In
reallife, however,
the
executiontime
of aninstruction in
the
pipelineis significantly different from its ideal
due
to
a number offactors.
These
factors
are calledhazards
and categorizedinto
severalgroups,
depending
ontheir
nature.The
following
paragraphs provide moredetails
onthe
pipelinehazards.
Any
hazard
preventsthe
nextinstruction in
the
instruction
streamfrom
executing
during
its designated
clock cycle.There
arethree
classesofhazards [1]:1)
structuralhazards
that
arosefrom
resource conflicts whenthe
hardware
could not provide so called"support
orthogonality".In
other words structuralhazards
occurred when not all possible combinations ofinstruction
couldbe
supportedby
the
hardware.
2)
data hazards
that
arose whenthe
instruction depends
onthe
results ofthe
previousinstruction in
away
that
was exposedby
overlapping
ofinstructions in
the
pipeline.3)
controlhazards
causedby
branches
and otherinstructions
that
changedthe
PC.
The
following
is
a moredetailed discussion
onthe
structuralhazards.
The
most commoninstances
of structuralhazards
occurred whensomefunctional
unitswere not
fully
pipelined.In
technical terms
it
meantthat
a particularfunctional
unit orthe
number offunctional
units could not executethe
instructions
atthe
rate of one per clock cycle.According
to
[1],
whenthe
sequence ofinstructions
encounteredthis
hazard,
the
pipeline stalled one ofthe
instructions
untilthe
required unitbecame
available.Some
pipelines contained mixedinstruction
anddata
streams,
whichincreasedthe
average number of pipeline stalls.As
the result, the
majority
of modem machineshave
separateinstruction
anddata
pipelines.Another
solutionin
preventing
structuralhazards is
the
duplication
ofhardware
units.For
moredetails
on structuralhazards
please referto
[1].
The
next and more serioustype
ofhazards
is
the
data hazard.
There
aremany
situations when a particularinstruction
got awrong
operandasthe
result of non-finished execution ofits
predecessor,
or an operation notbeing
overwrittenbefore
the
instruction
waiting
for
this
resulthad
a chanceto
readit. Data hazards
canbe described
as one ofthe three
types,
depending
onthe order,
in
which read and write accesses occurresin
the
instructions.
For
two
instructions
A
andB,
withA occurring before
B,
the
possibledata hazards
are:1)
RAW
(read
afterwrite)
-B
attemptedto
read a sourcebefore
A
wroteit,
2)
WAW
(write
afterwrite)
-B
tried to
write an operandbefore it
was writtenby
A,
and3)
WAR
(write
afterread)
-B
proceeded withtechniques
willbe
mentionedfurther down
as a part ofpresenting
instruction-level
parallelism
in
pipelining.As
it is
shownin
[1],
the
data hazards
caused a greatdeal
of performanceloss in
the
pipeline.However,
controlhazards
are always consideredto
be
the
main sourceofthe
loss
ofthe
CPU
performance.The
simplestway
to
deal
withthe
controlhazards is
to
stallthe
pipeline as soon asthe
hazard
wasdetected. In
otherwords,
the
pipelinehad
to
be
stalled untillthe
new value ofPC
wascalculated.
However,
in
orderto
really
solvethe
problem,
the
CPU designers had
to
find
answersto the
following
questions:1)
how
to
determine
whetherthe
branch
wastaken
or nottaken
earlierin
the
pipeline and2)
how
to
computethe taken
PC
(i.e.,
the
address ofthe
branch
target)
earlier.The
length
ofthe
controlhazard
was called abranch delay.
In
general,
the
deeper
pipeline,
the
worsethe
branch
penalty
wasin
clock cycles.Here
several choices ofreducing
pipelinebranch delays
willbe
considered.As
it
was presentedabove,
the
simplest schemeto
handle branches is
to
stallthe
pipeline.
A
higher
performance,
but
somewhat morecomplex,
scheme wasto
predictthe
branch
as nottaken,
simply
allowing
the
pipelineto
proceed asif
the
branch
were neverexecuted.
An
alternative schemeis
to
predictthe
branch
astaken
and always continuethe
execution atthe
branch
target
instruction
address.Yet
another scheme wasdeveloped
that
was calleddelayed branch.
This
scheme placedthe
sequential successors ofthe
branch in
the
branch-delay
slots.These instructions
were executed whether or notthe
branch
wastaken.
The
modem andthe
most practical use ofthis
schemeis
that
branches have
a singleinstruction
delay
slot.There
weremany
othertechniques the
computer engineersintroduced
to
prevent controlhazards.
For
moredetails
on prevention of controlhazards
please referto
The
listed
above explainedhow
pipelining
couldoverlap
the
execution ofinstructions
when
the
instruction
wereindependent
ofone another.Several
techniques
wereintroduced
to
extendthe
pipelining
ideas
by increasing
the
amount of parallelismintroduced
by
many
instructions.
Consider
the
case withthree
instructions
A, B,
C
wherethe
instruction C did
notdepend
on eitherA
orB,
than the
execution ofC
was postponed untilit
commitsthe
resultspresenceofstructural and
data
hazards,
the
instruction had
to
waitfor its
operandsto
become
ready.Only
afterboth
operandshad been
present wasthe
instruction ready
to
moveto the
execution stage.It clearly
showedthat
in
somecases aninstruction had
to
occupy CPU
unitsfor
significanttime;
the
whole pipelinehad
to
be
stalled while someinstructions
wereactually
ableto
execute.The logical
solutionto this
problem wasto
splitthe
decode
stageinto
two:
issue
and read operands stages.If
there
were no structuralhazards,
the
instruction
would
be
checked againstthe
readiness ofits
operands,
andif
any
operand were notready
due
to the
data
hazard,
the
instruction
would notbe issued
to
an appropriateCPU
unit,
but
into
the
queue.Moreover,
sincethe
execution phase might span afew CPU
cycles, the
CPU
designers distinguished between begin
and complete execution phases.The
technique
ofintroducing
multipleinstructions
to
CPU
execution units was named"dynamic
scheduling" andbecame extremely
popularin
avery
shorttime.
The
following
subsectionsbriefly
describe different
techniques
for dynamic
scheduling,
their
advantages anddisadvantages,
as well asinability
to
solve certain problemsthat
arosefor
the
computer engineers atthat time.
Scoreboarding [1]
was usedin
those
cases whenthe
CPU
executesinstructions in
an out-of-order mannerin
the
presence of sufficienthardware
resources and absence ofdata
hazards.
As
described in
[1],
every instruction
wentthrough the scoreboard,
wherea record of alldata dependencies
was constructed.This
actionimplied
WAW
hazard
checking,
as well asthe
availability
ofthe
appropriatefunctional
units.Only
if
no otherinstruction
wantedto
writethe
resultto the
outputregister,
andthe
unit wasfree,
wasthe
instruction
issued.
Then
the
scoreboarddetermined
whenthe
instruction
could readits
operands andbegin
execution.The instruction
wasexecuted,
andthe
scoreboard was notified uponits
completion.
If
noWAR
hazards
weredetected,
the
scoreboardthen
wrotethe
resultin
memory
[1].
The
disadvantages
ofscoreboarding
were:1)
scoreboarding did
not allowforwarding,
sinceit
couldonly apply
operands afterboth
ofthem
had been
placedinto its
registers;
2)
scoreboarding
wasgetting
allthe
information from
communication withfunctional
units,
which waslimited
by
the
number of available operands/resultbuses in
a registerfile.
Perhaps,
the
most significantlimitations
ofscoreboarding,
according
to
[1],
werethe
that
couldbe
found),
andthe
number of scoreboard entries(scoreboard
window,
i.e.
the
number ofinstructions
that
couldbe actually
placedfor
execution atany
time).
Because
dynamically
scheduled pipelineintroduced
moredata
dependencies,
anothertechnique,
known
asregisterrenaming,
orthe
Tomasulo
Approach,
wasintroduced.
Tomasulo Approach
was usedprimarily in
those architectures;
wherethe
number offunctional
units was notsignificant,
though the
unitsthemselves
were pipelined.Instead
of compiler registerrenaming,
the
WAW
/
WAR
dependencies
elimination was achievedby
use ofreservation stations.The
reservation stationsbuffered
the
operands ofinstructions
that
werewaiting
to
be issued
by
the
issuing
logic [1].
First,
the
reservation station savedthe
operandeliminating
the
needto
getit from
the
register.Second,
any
pending
instructions
could use reservations stations astheir
input.
Finally,
the
WAW
hazards
could nothappen
due
to the
fact
that
only
the
last
write operationto the
reservation stationactually
causedthe
register update.As
specifiedby
[1],
there
weretwo
significant advantagesin
the
organization ofTomasulo's
schema:1)
hazards detection
and execution control weredistributed,
sincethe
reservation station atevery
functional
unitdecided
when an appropriateinstruction
could execute atthe unit;
2)
the
results were passedfrom
the
reservation stationsdirectly,
eliminating
the
need of use of registers and associateddata
hazards.
As
the
result of allthe
aspects mentionedabove, the
Tomasulo's
technique
was usefulon single-issue pipelines withlimited
number ofregisters.Even
though
a number of othertechniques
were alsodeveloped
to
improve CPU
performance,
none ofthem
couldincrease
the
numberof executedinstructions
per cycleto
1.3. Superscalar
architecture
and
SMT
Consistent
withthe
definition
of abase
scalar processor[2],
simple operation andinstruction latencies
were all equalto
one,
the
Superscalar
processorissued
multipleinstructions
and generated multiple results per cycle.A
vector processor executed vectorinstructions
onthe
arrays ofdata
suchthat
eachinstruction invoked
astring
of paralleloperations.
This
wasideal for
pipelined architecture with one result per cycle.In
theory,
according
to
[3],
aSuperscalar
processormay
reachthe
same performance as a machine with vectorhardware.
If
aSuperscalar
machinecouldissue
afixed-point,
floating-point,
load
andbranch,
allin
onecycle,
the
effect wouldbe
the
same asfrom
the
use of vectorload
chained with vector add machine.A
typical
VLIW
(very long
instruction
word)
[2]
machinehad
instruction
wordshundreds
ofbits in length.
Like
in
aSuperscalar
processor,
multiplefunctional
units were used concurrently.All
unitssharedthe
common registerfile.
The
concept of microcoding,
as statedby
[2],
implied
the
use ofdifferent
fields
ofthe
long
instruction
wordto
carry
the
operation codesin
the
orderto
be dispatched
to
different
functional
units.Indeed,
the
code writtenin
conventional shortinstructions had
to
be
combinedto
usein
VLIW
computers.However,
the
vector machines arebeyond
the
scope ofthis
work,
andfor
this reason, this
work willfocus
onSuperscalar
architecture only.The
issue
utilizationin
the
superscalararchitecture,
i.e.
the
percentage ofissue
slotsthat
werefilled
eachcycle, along
withthe
causefor
every empty
slot was measuredusing
the
SPEC benchmark.
If
the
nextinstruction
could notbe
assignedduring
the
same cycle asthe
current
instruction,
then
the
remaining
issue
slots atthis
cycle,
as well asissue
slots ofidle
cyclesduring
the
execution ofthe
currentinstruction,
were assignedto the
causes ofthe
delay.
In
case of overlappedcauses, the
longest
delay
wasassigned.The
results showedthat
the
functional
unitswerehighly
underutilized.On
average,
according
to
[2],
the
architecture reachedonly
1
.5instructions
percycle,
withafull
8-way
issuing
schema.Also,
it
was clearthat there
was noany dominant
source of wastedissue bandwidth.
Although
there
weredominant items in
individual benchmarked
applications, the
dominant
cause wasdifferent in
each case.All
abovelisted
majortechniques
ofreducing
the
waste were applied.None
ofthem,
though,
produced asatisfactory increase
in
performance,
sincethey
only
attackedwas notcapable ofcomplete elimination ofeithervertical waste
(completely
idle
cycles)
orhorizontal
waste(unused issue
slotsin
a non-idle cycle).1.4. Overview
of subsequent chapters
Chapter
2,
Developing SimOS/Topsy
Environment,
providesbasic
information
aboutthe
initial integrated
modelfor
the
development.
The
chapterdescribes necessary
modifications
to
convertthe
initial
integrated
environmentto
the
SMT MXS
integrated
environment.Chapter
3,
Developing
SMT
CPU Model
introduces
theoretical
foundation
and a setof requirements
for SMT CPU.
The
chapterincludes
severalimplementation
issues,
along
withthe
results ofinstruction
fetching by
the
SMT MXS
fetching
unit.Chapter
4,
Developing
SMT
Topsy
describes
a set of changesto the
modernoperating
system
(Topsy)
to
accommodatethe
SMT
scheduling.This
chapter also provides particularimplementation
details
ofthe
SMT MXS
scheduler.Chapter
5,
SMT
MXS
SimOS/Topsy
Installation,
describes
the
process ofinstallation
of
the
SMT
MXS
SimOS/Topsy
integrated
environment on a user'sPC (Linux
platform).Chapter
6,
SMT
MXS
SimOS/Topsy
Configuration,
describes
the
process ofChapter 2.
Developing
SMT
SimOS/Topsy
environment
Section 2. 1 discusses
the
basic
SimOS/Topsy
integrated
environment andits
workcycle.
Section 2.2
introduces
afew
problemsassociatedwiththe
basic
environment.Section 2.3 illustrates
advantagesofthe
SMT
SimOS/Topsy
anddescribes its
working
cycle.
Section 2.4 demonstrates
a newPerformance Counters
conceptthat
is
usedto
monitorthe
work cycle ofthe
SMT
SimOS/Topsy
integrated
environment.2.1.
Basic
SimOSITopsy
environment
This
section provides an overview ofthe
basic integrated
environment,
whichstructure
is
shownin Figure
1
.*
Startup
parameters^J
Compilation
^jj^-and linking
K
sprocess ,1 topsy.ecoff
R4000 CPU
[image:24.527.123.403.392.531.2]Configuration parameters
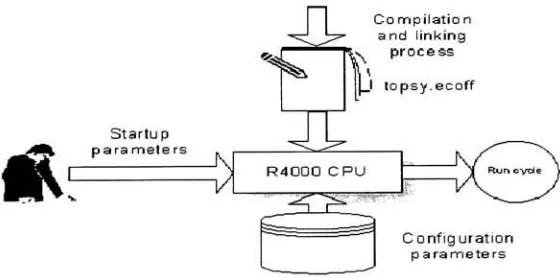
Figure I.Basic
SimOS/Topsy
environmentIn
orderto
be
executedby
the
SimOS
simulator,
Topsy
has
to
be
compiled andlinked
using
MIPS
cross-compiler.The
outputfile,
topsy.ecoff, is
then
loaded
into
the
SimOS
secondary
caches,
as well asthe
implementation
ofthe
virtual machines andCPU
vectorization,
aredisabled.
2.2.
Switching
to
SMT
SimOSITopsy
environment
As
indicated in
[3],
SMT is
alatency-tolerant CPU
architecturethat
is
ableto
executemultiple
instructions
from
multiplethreads
during
each cycle.This
ability
to
issue
instructions from different
threads
providesfor
abetter
utilization ofexecutionresourcesby
converting
thread-level
parallelisminto instruction-level
parallelism.A
number of previousstudies
have
establishedthat
SMT
is
an effectiveinstrument for
increasing
performance onavariety
ofworkloads, and,
atthe
sametime, it
provides good performancefor
single-threadedapplications.
As
it
was shownin
[1],
atthe
hardware
level,
SMT usually
serves as an extensionto
any
out-of-order superscalar.A
good example ofthis
wouldbe
the
fact
that the
SimOS
usesAlpha
21264
asthe
bases
for
SMT
features
implementation.
However,
the
Alpha
architecture, though
very
wellsuitedto
work onany IRLX/MIPS
based
system,
is
noteasy
to
acquire andaccommodate.
For
this
reasonimplementation
ofSMT
onthe
MIPS R10000
has
been
chosen.In
additionto the
difficulties
withAlpha 21264
mentionedabove, the
decision
to
implement
SMT
onthe
MIPS R10000
wasbased
uponotherreasons,
such as:1)
Comparably
large
selection ofdocumentation
materials availablefor
R10000;
2)
Compatibility
ofRl
0000
withTopsy;
3)
A
discovery
ofavery
well-structuredR4000/Topsy
simulator(see
previoussection);
Even considering
allthe
advances ofSMT,
there
are still someimprovements
to the
underlying hardware
neededto
be
addedin
orderfor
SMT
to
be implemented
on a singleCPU
architecture.These improvements
wereasfollows:
1)
Duplication
ofthe
registerfile,
programcounter,
subroutine stack andinternal
processor registers of a superscalar so
that the
state of multiplethreads
(contexts)
canbe
held;
2)
Implementation
ofthe
per-context mechanismsfor
pipelineflushing,
instruction
2.2.1. Problems
associated
with
basic
SimOS/Topsy
environment
There is
the
number of problemsthat
needto
be
resolvedin
orderto
switchfrom
the
basic
SimOS/Topsy
environmentto the
SMT
SimOS/Topsy
environment:1)
Initial MXS CPU
modelis in
non-working
state2)
The MXS CPU
modelis
notintegrated
into
the
basic
SimOS/Topsy
environment3)
The basic
SimOS/Topsy
environmentdoes
not providefull
supportfor instruction
and
data
caches:the
instruction
anddata
caches cannotbe
loaded
withthe
appropriate segmentsof
Topsy
kernel
4)
The
Topsy
kernel
requiresinstallation
ofbinary
utilitiesandMIPS
cross-compiler2.2.2. SMT
SimOS/Topsy
environment
Figure
2
showsthe
modifiedSimOS/Topsy
integrated
environment.~L
Cornp ilation and
linking
ijv process^
Startup
parameters
Configuration pa ra meters
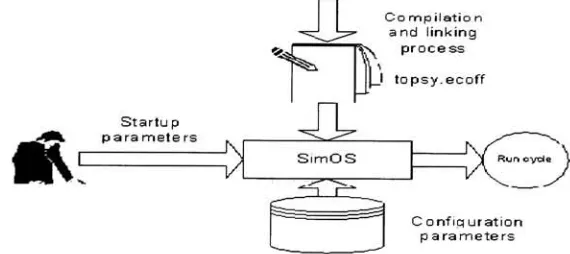
Figure
2. SMT
SimOS/Topsy
environmentUpon
completion ofthe
compilation andlinking
processes,
the
outputfile,
topsy.ecoff,
is
placedin
the
rootSimOS
directory.
The
modifiedSimOS
simulatorincludes
the
implementation
ofprimary
andsecondary
caches andthe
implementation
ofthe
vector ofvirtual machines.
Each
ofthe
virtual machines can readinstructions
anddata from
instruction
anddata
caches.Both
the
instructions
anddata
canthen
be loaded into
the
vectorof
CPUs (maximum
number ofCPUs
associated with each machineis
32)
and executedby
each ofthe
CPUs. Both
cache andCPU
modelsare configurable.Even
though there
arefew
[image:26.527.118.403.329.456.2]CPU
model with addedSMT
capabilities and2Level
cache model ofthe
originalSimOS.
The
user specifiesthe
intended CPU
type
from
the
commandline.
The
type
andconfiguration of
the
instruction
cacheis
specifiedin
the
simulatorstartup
configurationfile,
initsimos. For
the
list
ofthe
mainconfigurationparameters referto
Table. The
completelist
of
the
configuration parameters canbe found in [31].
The
subsequent section provides more [image:27.527.47.488.205.321.2]details
onthe
workcycleofthe
simulator.Table 1. Main
configuration parametersof
SMT
SimOS/Topsy
environmentParameter
Value
Description
CPU.Count
1
Number
ofCPUs
supportedby
a singlevirtualmachineCPU.ISA
MIPS
Instruction
set architectureCPUModel
MIPSY
This
parameteridentifies
the type
of simulatorCACHE.Model
2Level
2Level
(primary,
secondary)
caches enabled.CACHE.2Level.ISize
1M
1stLevel Instruction
cachesizeCACHE.2Level.ILine
64
1stLevel Instruction
cacheline
size2.2.3.
Work
cycle of
the
SMT
SimOS/Topsy
environment
The
detailed
organizationofthe
SMT
SimOS/Topsy
integrated
environmentis
shownin Figure 3.
J\ T'jpuy.i.'Cjff 1
J
L
*
Fvrsmjrinn mnrtn <>imul>1.ir lyFiM,r.PI I type. i
4>
Loacffmage function
.text -J
U
J U
.data,.rdata lriNliui:liiiriCm-.hi: grr
Udtu Cuchu
cJl^ *n*
_3fei^g
Tl>
\r.^ flfl.11:turn: 1 IUlMi:liirn*y MHi:hirn:MV
t:
X
X
It
,_ Configuration parameters
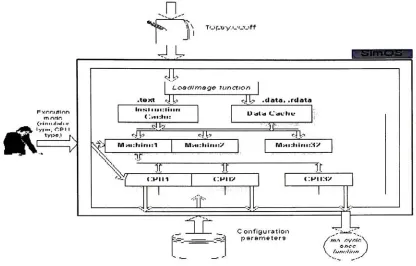
Figure
3.
fFor&
cyc/eofSMT
SimOS/Topsy
environmentThe
user starts simulatoronly
if
the
following
stepshave
been
completed:1
.SMT
Topsy
kernel
is built
using
the
MffSY
gcccross-compiler2.
SMT
MXS
SimOS/Topsy
integrated
environmentis built
using Intel
gcccompiler,
and
the
-DSMT optionis
presentin
the
Makefile
of cpus/mxssubdirectory
ofthe
simulator
[image:28.527.57.473.122.388.2]The
userthen
entersthe
following
commandline in
the
simos rootdirectory:
Jsimos
-Xwhere-Xoption
indicates
that the
simulatorutilizesthe
MXS CPU
model.Combined
withCPU.Model
option,
this
commendline
optioncompletely defines
the
simulated environment(MIPSY
simulator/SMTMXS CPU).
According
to
[32],
topsy.ecoff
file
containsthe
following
segments: .text-text
segment of
the
kernel
(instructions),
.data, .rdata-data
segments ofthe
kernel (variables
and constants).After main()
function
completesthe
initialization
ofthe simulator, the
simulator passesthe
controlto the
Loadlmage
function.
The Loadlmage
function is
responsiblefor:
1)
extraction ofthe
.text, .data, .rdata segmentsfrom
the topsy.ecoff
file;
2)
loading
the
instruction
cache withthe
.text segmentdata,
andthe
data
cache withthe
.data, .rdata
segments
data.
After
instruction
anddata
caches aresuccessfully
loaded
withthe
appropriatedata,
the
virtual machinethen
initializes
the
vector ofdefined CPU
models(in
this case, the
vector ofthe
SMT
MXS
CPUs)
and callsthe
mscycleoncefunction.
The
ms_cycle_oncefunction
implements
a single cycle of execution of a singleSMT MXS
CPU.
The
mscycleoncefunction
calls ms_fetchfunction,
whichimplements
the
SMT MXS
fetching
unitandis
one ofthe
main emphases ofthis
work.In
addition, the
"SMT
MXS
Fetching
Unit"section provides more
details
onthe
implementation
ofthe
fetching
unit andits
processing.The
"Results"
2.3. Annotations
vs.
Performance Counters
According
to
SimOS
documentation,
annotationsaremechanismsfor
running arbitrary
TCL
scriptsthroughout
the
execution ofthe
simulation.Annotations
are non-intrusivemechanisms.
It
meansthat
their
executiondoes
notnecessarily
needto
have any
affect onthe
behavior
ofthe
workloadandoperating
systemunder simulation.Annotations
aretriggered
by
any
number ofhardware
events,
including,
but
notlimited
to
execution of a specificaddress,
loads
or storesto
specificdata
locations,
device
interrupts,
and others.In
additionto
predefined annotation
types,
such asdiscussed
above,
it is
also possibleto
createuser-defined
types
ofannotations.These
aretypically
usedto
notify
scripts ofthe
execution ofsome
higher-level
event such asthe
creation of a newprocess,
entering
idle
loops,
orexecuting
a particular procedurein
an application.The
simulation usesthe
annotationcommand
in both instances:
to
set annotations andto
create new annotationtypes
for
othersto
use.Currently,
SimOS
supportsthe
following
annotationtypes:
Pc
-triggers
whenthe
PC
equals a certain value andfires
after all exceptionscaused
by
the
instruction's
execution and all cache misseshave
completed;
Load
-this
annotationtriggers
onloads
to
aparticularaddress;
Store
-triggers
on allstoresto
a particularaddress;
Cycle
-triggers
whenthe
cycle count reachesthe
predefinedvalue;
Exe
-triggers
on exception of aparticular
type;
Inst
-triggers
whenthe
instruction
of a particulartype
is
executed;
Simos
-triggers
on specificSimOS
events;
Scache
-triggers
on second
level
cache misses of a particulartype
orany
type
if
the
type
is
not specified.For
moredetails
onthe
format
of annotation command please referto
SimOS
documentation
[26].
The
annotations approachhas
its
advantages anddisadvantages.
Among
the
advantages,
annotations provideflexibility
andlow
executiontime
overhead.One
ofthe
disadvantages
ofusing
the
annotation approachis
anecessity
to
have
multiple scriptsto
address
the
different
types
ofannotations,
inclusion
ofTCL
libraries
into
the
simulationthe
annotation approachthere
areissues
relatedto
installation
andinitialization
ofthe
software related
to
the
specificTCL
problems and versionsincompatibilities,
andthe
necessity
to
providespecial support ofTCL
in
the
software.Taking
into
considerationthe
issues described
above,
adifferent
approachhas
been
taken,
namely
performance counters.The
performance countersimplemented in
this
worksomewhat mimic
the
Microsoft
approach.Every
function in
simmxsfolder
writesthe
data in
the
series of#
-delimited
rows,
whereevery
numberin
the
row represents a particular measured value of a particular matrix.For
example,
if
somedata
measurements werewrittenby
function X for data
seriesCl
andC2,
andthe
following
table
representsthe
actual [image:31.527.62.480.290.334.2]measured
data:
Table 2.
Viewing
data
withRIT Viewer
applicationSeries
Cl
Series C2
i
1
2
2
3
Then
the
file
createdby
the
function X
willlook
like follows:
12#
2 3#.
A
specialWindows
applicationRIT_viewer
wasdeveloped
to
visualizethe
data.
Figure 4 demonstrates how RIT_viewer
interprits
the
data from
the
listed
abovefile.
RIT
viewerdaLa
inLerpriLaLionIC2 C1
3.0
2.0
1.0
K1 K2
2.0
[image:31.527.67.467.475.641.2]The
idea is
that
the
function
returns somedata
that
is only
meaningfulto
the
interpreter.
That
allowshaving
a singledisplay
for any
number oftotally
different
events.Among
otheradvantages, this
approachintroduces
atruly
non-intrusivecoding
style; there
is
no need
to
supportany extra-libraries;
since counters areimplemented in
C,
any
environment(including,
but
notlimited to,
TCL)
may
be
usedfor display.
For
example, the
Windows
2000
performanceproxy
was usedto
monitorthe
simulationrunning
onthe
UNIX
box
Chapter
3.
Developing
SMT MXS CPU
model
Section 3. 1
contains general specificationofthe
SMT MXS CPU
model.Section
3.2
providesdetailed description
ofthe
SMT
MXS
instruction
set.Section 3.3
explainsthe
organization ofthe
SMT MXS
pipeline.Section
3.4
providesbrief discussion
ofthe
SMT
caches,
including
primary
instruction,
primary data
andsecondary
caches.This
section alsodescribes
cachealgorithms and virtual-to-physical address
translation
process.A brief discussion
ofthe
operating
modes ofthe
SMT MXS CPU
modelis
also providedin
this
section.Section 3.5
providesdetailed description
ofthe
fetching
unit ofthe
basic
MXS CPU
model;
it
then turns to
SMT
MXS
fetching
unit anddiscusses
afew
problems relatedto
SMT
fetching
process,
as well as possible enhancementsto the
SMT MXS
fetching
unit.
Section
3.6
introduces
the
concept of register renaming.The
section alsodemonstrates
afew
techniques
ofregisterrenaming
that
areimplemented
in
the
SMT
MXS CPU
model.Section
3. 7
explainsthe
organization ofthe
SMT MXS
issue
queues.Section 3.8
containsbackground
information
onbranch
predictionpolicies.Section
3.9 describes
the
SMP MXS branch
predictionunit.Section 3.10
introduces
a newdynamic branch
predictionpolicy.Section
3.11 illustrates
exceptionhandling
techniques
implemented
in
the
SMT MXS
CPU
model.3.
1.
General
Description
Taking
a closerlook
atthe
SMT
showsthat the
SMT MXS
architecture canbe
categorized as
MIPS
V
(provided
that
atypical
MIPS
architecturehas been
extendedfour
times
andthe
basic R 10000
architecturebelongs
to the
MIPS
IV
category).The
following
describes basic CPU
architectureinformation,
as well as specificSMT information.
The
detailed description
ofthe
basic
architectureis
containedin
[r
10000
us.Man].
The
specificSMT
information is
referencedaccording
to the
list
of sources.The
SMT
MIPS
processoris
asingle-chip
superscalar1
RISC
microprocessorthat
usesMIPS
ANDES2 architecture andhas
the
following
majorfeatures [5]:
1)
It specifically implements
the
64-bit
MIPS IV
instruction
set architecture(ISA);
2)
It
candecode
eightinstructions
each pipelinecycle,
appending
them to
one ofthree
32-entry
floating
point andinteger instruction
queues;
3)
It
has
ten
execution pipelines withthe
maximumdepth
of9
stages connectedto
separate6
integer
(including
4 Load/Store
and2 Synchronization units)
and4
floating
pointunits;
4)
It
usesdynamic instruction
scheduling3
andout-of-orderexecution4
;
5)
It
uses speculativeinstruction issue (also
termed
"speculative
branching"5);
6)
It
usesnon-blocking
caches6;
7)
It
has
separateon-chip 128-Kbyte primary instruction
anddata
caches;
8)
It
has
individually-optimized secondary
cache andSystem
interface
ports;
9)
It
has
aninternal
controllerfor
the
externalsecondary
cache;
10)
It has
aninternal System
interface
controller with multiprocessorsupport.The
table
below lists
the
parameters ofthe
SMT
processorandmemory
systemthat
areTable 3. General
specificationof
SMT
microprocessorParameter
Description
Pipeline
9
stagesFetch
Policy
8
instructions
percyclefrom
up
to
2
contexts(the
2,8
scheme of[6])
Functional
Units
6 integer
(including
4
load/store
and2
synchronizationunits),
4
floating
pointunitsInstruction Queues
32-entry
integer
andfloating
point queuesRenaming
Registers
10