Rochester Institute of Technology
RIT Scholar Works
Theses
Thesis/Dissertation Collections
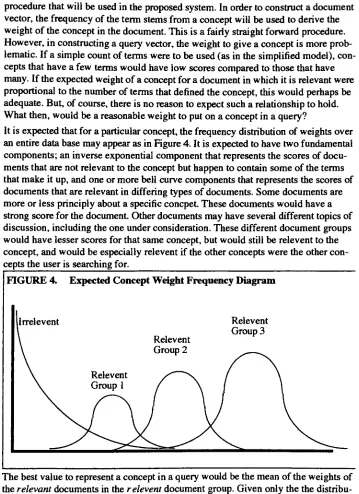
1994
Knowledge based text indexing and retrieval
utilizing case based reasoning
Alan Mick
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion
in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact
Recommended Citation
ROCHESTER
INSTITUTE
OF TECHNOLOGY
This
volumeis the
property
ofthe
Institute,
but the
literary
rightsofthe
author mustbe
respected.Please
referto
permission statementin this
volumefor denial
orpermission,
by
author, to
reproduce.In
addition,
if the
readerobtainsany
assistancefrom
this volume,
he
must give proper creditin his
ownwork.This
thesis
has been
usedby
the
following
persons,
whose signatures attestto their
acceptance ofthe
above restrictions.Name
Address
Date
Acknowledgments
I
wouldlike
to
acknowledgethe
support receivedfrom my RTT
thesis
committee,
especially Feredoun Kazemian
andWalter Wolf.
I
wouldalsolike
to
acknowledgethe
kind
support receivedfrom
the
Inspec bibliographic
service which provided
bibliographic data
essentialto
the
completionofthe project,
andespecially Jim
Ashling,
Director
ofthe
US Inspec
office,
who arrangedit
for
me.I dedicate
this thesis to
Rosemary
Grace
Mick,
neZimmermann,
my
mother,
whoselast
wish was
that
it be finished.
Key
Words
and
Phrases
Information Search
andRetrieval
Knowledge Based Information Systems
Case Based
Reasoning
Computing
Review
Subject Codes
Using
the
computing
classificationcodes establishedby
the
ACM,
the
primary
classification
is H.33
-Information Search
andAbstract
Information
retrieval systemsfor documents normally rely
onthe
useofkeywords
that
describe
the
text
in
somefashion
oranother,
or are containedin
the
text
itself,
for
indexing
and searching.These
keywords
may be
associatedwithstandardboolean
operators,
where presenceorabsencein
the text
ortext
description
is
used asthe truth value,
or other oper atorsindicating
their
proximity
to
one anotherin
the text.
Another
emerging
approachis
the
use of content orknowledge
based
indexing
and retrieval.In
this
approachthe text
is
not represented ortreated
as a collectionkeywords,
ratherits meaning
or semantic contentis
abstracted andthe
meaning is
usedto
searchfor
the text
desired.
This
approachmay have
severaladvantagesoverthe
standardkeyword
approach.Both
precision andrecall ofthe
searchmay be
improved,
increasing
the
likelihood
that
relevanttexts
willbe
found
whiledecreasing
the
probability
offinding
irrelevant
ones.The knowl
edgebased
approachmay
also allow more sophisticatedquery
techniques,
for instance
queriesbased
onthe
purposefor
whichthe text
willbe
used.Table
of
Contents
1.0
Introduction
and
Background
1
1
.1
Problem Statement
7
1.2
Previous Work
9
13
Theoretical
andConceptual Development
18
1.4
Glossary
27
2.0
Software Project Description
28
2.1
Functional Specification
31
2.1.1
System
Objects,
Inputs,
Outputs
andFiles
32
2.1.2
Functions Performed
33
2.1.3
Limitations
andRestrictions
35
2.2
Verification
andValidation
:36
2.2. 1
Single Concept Search Test
36
2.2.2
Multi-Concept Search
37
2.2.3
Conceptualization
andQuery
Refinement
38
3.0
Conclusions
41
3.1
Problems Encountered
andSolved
41
3.2
Discrepancies
andShortcomings
ofthe
System
41
33
Lessons
Learned
42
3.3.1
Improvements
andAlternative Approaches
42
33.2
Suggestions For Further Work
42
1.0
introduction
and
Background
In
contrastto typical
database
systems,
information
retrieval systemsdeal
withthe
storage and retrieval ofrelatively
large
unitsof unstructuredinformation. For
instance,
aninfor
mation retrieval systemmay
index
and storejournal
articlesthai
consist ofthousands
of words oftext
on avariety
oftopics,
writtenin
avariety
ofstyles,
andevenin
different
lan
guages.The internal
structure ofthe
articlesmay
be
generally
similar,
but
variance wouldbe
quitecommon,
andit
wouldbe
hard
to
define in
arigorous
enoughway
to
make simple useofduring
processing.A
retrievalitem in
atypical database
system,
however,
might consist of no morethan
five information
fields,
wouldhave
avery
restrictivecontent(such
asname,
socialsecurity
numberoraddress)
andwouldhave
awelldefined
relationship
to
all otherinformation in
the
database.
Keyword Retrieval
Information
systemsfor document
storageandretrievalnormally rely
onthe
use ofkey
wordsthat
describe
the text
in
somefashion
oranother,
or are containedin
the text
itself,
for
indexing
and searching.In searching for
information,
these
keywords may be
usedin
conjunction with standardboolean
operators,
wherepresenceor absencein
the
text
ortext
description is
usedasthe truth value,
or withotheroperatorsindicating
their
orderandproximity
to
one anotherin
the text.
Keywords
mostoftendescribe
adocument's
content,
but may be
usedto
describe
other attributes such asits title,
author,
andpublisher,
or even whattype
ofdocument it
is
andin
whatway it
treats
its
subject.A keyword query
canbe
quitesimple,
orvery
complex.The
simplestis
alisting
ofkey
words which select adocument if
alltest true.
For
instance,
the
query "Information
Retrieval
,Natural
Language
,Case Based
Reasoning"
would retrieve
any document
that
pertainedto
information
retrievalutilizing
naturallanguage
processing
and casebased
reasoning,
but
would not retrieve adocument
that
consideredthe
useful ness of naturallanguage processing in
aninformation
retrieval system without referenceto
casebased
reasoning.A
more complex search allowsthe
addition ofboolean
operatorsto
expandthe
differentia
tion
powerof a query.For
instance,
the
query "Information
Retrieval
AND
(Natural
Language
OR Case
Based
Reasoning
)"would retrieve all
docu
mentsthat the
previous examplewould,
but
would also retrieveany documents
aboutinformation
retrievalthat
consideredonly
naturallanguage processing
oronly
casebased
reasoning,
withoutrequiring both
topics to
be
covered.If
the
keywords do
notjust
describe
the
content ofthe
document but
areactually
words containedin
the
document
instead,
then
proximity
operatorsmay be
usedin
additionto
boolean
operators.The Computer Select
system allows operatorsthat
selectTwo
wordsappearing in
the
same sentence or paragraphTwo
wordsappearing
within a specified number ofwordswithinthe
same sentence
or paragraphThese
operators arcusedto
searchfor documents
that
discuss
the
relationship
oftwo
top
ics.
They
may
alsobe
usedto
construct"complex
keywords"
In
additionto
keywords
that
describe
the
content of adocument,
searchescanbe
conducted
on other attributes of adocument.
Frequently
the title
is
treated
as separatefrom
the
contents and searchesmay be
usedthat
operateonly
onit. Other
commonattributes usedin searching
arethe
document
type
andtreatment
ofthe
subject matter.For
instance,
the
INSPEC
system allows asearchonsubjecttreatment
that
includes keywords
suchas "experimental,""practical,"and
"theoretical/mathematical."
Knowledge Based Retrieval
Another emerging
approachis
the
useof content orknowledge based
indexing
and retrieval.In
this
approachthe text
is
notrepresented ortreated
as a collectionofkeywords,
ratherits
meaning
or semantic contentis
abstracted andthe
meaning is
usedto
searchfor
the text
desired.
This
approachhas
several advantagesoverthe
standardkeyword
approach.Both
precision and recallofthe
searchmay be
improved,
increasing
the
likelihood
that
relevanttexts
willbe
found
whiledecreasing
the
probability
ofretrieving
irrelevant
texts.
The knowledge
based
approach also allowsfor
moresophisticatedquery techniques,
such as queriesbased
on an example or sampledocuments.
It
can alsobe
usedto
link
the text
search and retrievalprocessinto
more sophisticatedexpertsystems,
such as onedesigned
to
help
for
mulatelitigation
strategiesin
the
domain
oflaw,
wheretext
searchand retrievalmay be
usedto
discover
precedence,
akey
elementin litigation
strategy.A
key
component ofany knowledge based
systemis
the
data
structures andprocessing
techniques
usedto
representknowledge
andto
reasonbased
onit. The
major varieties ofknowledge
representation andreasoning
techniques
nowbeing
employedin
expert systems
arethe
rule-basedapproach,
patternrecognition,
neural networksand case-based rea soning.A
rule-basedsystem stores rulesthat
allowit
to
recognize orformulate
a goodplan,
strategy
orsolutionto
a problembased
on aninput
specification.The initial
specificationis
usedto
match againstany
rulesthat
are applicable.When
a ruleis
applied(or
"fired"in
the
terminology
of rule-basedsystems), the
state ofthe
systemis
altered suchthat
other rulesmay
nowbe
applicable,
andthey
then
arefired in
turn.
This
process of"chaining" continues until a solution
is
arrived at.The
systemmay
also askfor further information
based
onits inferences in
orderto
clarify
some aspect ofthe
problem and allowit
to
continue
its inference
process.Pattern
recognitionis
atechnique
usedto
classify
complexinstances into
useful categories. In many
cases,
classification alone candetermine
a plan or course ofaction,
but
clas sificationitself may be
a complexproblem.For
instance,
once apatient'
s
disease has been
identified,
the
treatment
may be
wellknown
and straightforward,
but
identifying
from
avariety
of symptomsexactly
whatthe
disease
is may be
quitedifficult. Pattern
recognition uses alarge
number of examples and counter examples and analysesthem
mathematically
to
create aclassificationfunction. The
most popular analysestechniques
arelinear
and quadraticdiscriminants
andBayes
classifiers.Once aformula has been developed it may
be
appliedin
asystemthat
processesthe
inputs in
astraightforward
manner andchoosesa solutionbased
onthe
resulting
classification.Neural
networksrely
ondata
structuresthat
mathematically
modelthe
information
processing feaftires
ofbiological
nervoussystems,
such asthe
human brain [26]. The
networkdefines
connectionsbetween
"neurons",
which,
whensufficiently
stimulated,
"fire,"send
ing
a messageto those
neuronsto
whichit is
connected.Connections
canbe excitory
orinhibitory,
and are added and subtractedto
form
a weighted sum which must exceed athreshold
valuefor
the
neuronto
fireThe
inputs
to
the
networkconstitutethe
initial
stimulus,
andthe
outputs arethe
outputs of some subset ofthe
network's nodes.The
weights at each connectionandthe threshold
valuescanbe
alteredto
affectthe
behavior
ofthe
network,
andby
systematically providing
the
networkwithinputs
andadjusting
the
weightstoachieve
the
desired
outputthe
networkis
"trained"to
respondto
avariety
ofinputs
withthe
appropriateoutput.Although
each ofthese techniques
has its
ownstrengths,
each alsohas
some weaknesses.Some
ofthe
weaknesses ofthese
techniqueshave
been
explainedby
Ralph
Rarletta in his
introduction
to
case-basedreasoning [2]. The
rulebased
approachis
time
consuming
andlabor
intensive
to
usebecause
the
rulesthat
governdecisions
in
adomain
mustbe
discov
ered
through
aninterview
process with an expert.Experts generally do
notconsciously
think
in
a"rule
like"manner outside of
the
simpler problemsthey
encounter.They
thus
have
adifficult
time
explaining
the
"rules
ofthe
game"
and
the
process ofdefining
them
may
be
as much a process ofdiscovery
for
the
expert asit is for
the
knowledge
engineer.Rule-based
systemsalso are noteasy
to
maintain.Since
rules areinherently
dependent
on a wholecomplex of other rulesto
workproperly,
they
cannotbe
added piecemeal oradhoc
as needed.An understanding
ofthe
entire rule setis
neededin
orderto
effectively
keep
it up
to
date.
Pattern
recognitiontechniques that
use mathematicaltechniques
such aslinear
and quadratic
discriminants
canonly be
appliedto those
problemsthat
are opento
numericaldescription.
Many
domains have important features
that
arenon-numeric,
such as medicine,
where avariety
of subjectivedescriptive
information
mustbe
usedto
make afinal
judgement. Bayes
classifiers require a completeprobability
estimatefor
eachdependent
variable
in
the
exampleset.whichis difficult
to
do
in
most real-worddomains.
Neural
networks requirethe
feature
of a problemto
be defined in
terms
of a vector of eitherBoolean
or numeric values.As in
the
case of patternmatching, this
limits
their
applicationsto
problemsthat
canbe defined in
this
way.Many
problems aredefined
through
complexinternal
relationshipsandthe
neuralnetworkis best
suitedto
a simplelist
offeatures. Neural
networks also require alot
of computational resourcesto
arrive at an adequate network configuration.In
complexcases, this
can meanusing
weeksofCPU
time
to train
a single network.In
addition,
nomethodology
existsfor
the
process ofdefin
ing
a networksothat
it is
atbest
anart and at worst atrial-and-error
process.Since it
takes
so much computertime to
performthe
trials,
the
errors canbe excessively
expensive.A knowledge
representationthat
currently
is generating interest is
the
case-based reasoning
technique.
Case based reasoning
representsknowledge
as cases orexamples,
and reahave
their
own strengthsandweaknesses,
case-basedreasoning has many
advantagesoverthe
othertechniques.
Case-Based
Reasoning
When
anexpertmakes a recommendationbased
onthe
facts
of a particularcase,
he rarely
reasons
from "first
principles"to
solvethe
problems.More
often,
he
recalls pastinstances
where similarconditions prevailedandeither uses
the
solutionthat
workedthen
or modifies it
to
fit
the
new circumstances.When he does
arrive at aparticularly
goodsolutionto
aunique
problem,
orwhenhe
finds
a newway
to
approachanoldone,
it
is
rememberedand serves asthe
bases for solving future
problems.This is
the
basic
modelfor
case-based reasoning.
A
case-basedexpert system consists of a store of past problems and solutions and a meansto
look
for
those that
are similarto the
problemathand.
Given
asufficiently
diverse
store,
there
is
aprobability
that
an exact match canbe
found
andthe
problem canbe
solvedsimply
by
retrieving
the
stored solution.When
an exact matchis
notavailable,
asolutionto
a similar problemis
retrieved andthen
must
be
used asthe
bases
for
deriving
a new solution.This is known
as case adaptation.While
the
reasoning
process usedto
derive
a newsolutionfrom
the
oldmay be
similarto
that
usedin
othertechniques, it has
astarting
pointmuchfurther along in
the
processthan
does
the
"blank
slate"approach
that
would generate solutionsfrom "first
principles."The
adapted case
is
then
storedin
memory
for future
use,
eitherdirectly
whenthe
same problem
arises,
or as abasis for
further
adaptation when a new problems arises.In
designing
a case-basedsystem,
severaldesign
considerations mustbe
taken
into
account.
These include
caserepresentation,
caseindexing,
case storage andretrieval,
case adaptation andthe
system's overalllearning
and generalization strategies[2].
Case Representation: A
case representationis
the
data
structurethat
storesthe
informa
tion
about each casein
the
system.Simple
structures would consist of alist
offeatures
from
the
description
ofthe
problemthe
system solves andthe
solutionthat
fits
each case.An
example,
from
an actual system[43],
is
the
description
of a part andthe
associatedmanufacturing
stepsalong
withtheir
costs.Such
a system canbe
usedto
bid
onthe
manufacture
of new partsby
finding
similar partsthat
have
been bid in
the
past andusing
the
historical
data
to
determine
whatthe
new part will costto
manufacture.More
complicatedstructures might consist of a related set of
subcases,
eachcorresponding
to
some part ofthe
complete problemsolving
task.
More
important
that
just
the
data
structureitself,
however,
is
the
exactfeatures
that
shouldbe
usedin characterizing
the
problem.This is
one ofthe
mostimportant design
tasks
ofthe system,
sincethe
feature list
willdetermine
in exactly
whatterms the
problemwillbe
statedto the
system.Discovering
andvalidating
the
relevantfeatures
ofthe
domain is
the
chieftask
ofthe
knowledge
engineer.In
the
case-basedsystem, the
knowledge
engineerinterviews
the
expertto
understandanddefine
the
domain's
terminology
andto
gathercaseswhichcan
then
be
usedin
the
system.Case Indexing:
Case
indexing
providesthe
ability
to
retrievethe
appropriatecasesfrom
casememory quickly
andefficiently
giventhe
problemdescription
providedby
the
user.There
arethree
primary
techniques
in
generaluse:the
nearestneighbor,
inductive,
andknowledge-guided
approaches.The
nearestneighbor approachuses aweighted sumoffeatures in
the input
casethat
match, to
somedegree,
the
values offeatures in
astored caseto
determine
if
that
case shouldbe
retrieved.For
eachfeature in
the
case, the
valuein
the
input
casemuchmatchthe
valuein
the
stored caseto
somedegree,
andthe
degree
ofthe
matchmay be
usedin
the
overall
judgement
of a case'sapplicability
to
a problem.The
required matchmay
be
perfect,
ortheir
may be
somedegree
oftolerance
for less
than
exactmatches.For
instance,
in
one case-basedsystemfor bid
preparation[43],
the
shape ofa partis
onefeature
used.The
shapecould
have
one of10
possiblevaluesandfor
a matchto
occur onthis
feature
the
valueshave
to
matchexactly.But in
the
samesystem amatch occurs onthe
material of a partif
the
input
material'snameis
asubstring
ofthe
stored case's material.With
numeri calvalues,
rangesrepresenting
degrees
ofsimilarity may be
established.In
additionto
the
degree
ofmatchbetween
features,
somefeatures may be
moreimportant
than
others.Thus features
themselves
may have
aweightandthis
weightis
appliedto the
degree
of matchin
determining
the
overall score.For
instance,
in
the
bid
example, the
salient
feature
mightbe
part shape.If
this
wereso,
the
shapefeature
wouldhave
alarge
weighting
factor
to
bias
the
selectionprocesstowards
casesthat
have
a match onit.
How
ever, the
significance of a particularfeature in
aparticularcase mighthave
a complexrelation to
all otherfeatures in
the
caseandtheir
values.In
orderto
accountfor
suchcomplexity,
ratherthan
giving
eachfeature
a uniform weightin every
case,
anindividual
weight mightbe
providedin
each case.The
difficulty
ofutilizing
nearest neighbor schemeslies in understanding
the
problemdomain
to
the
degree necessary
to
createcomplexsimilarity
andweighting
schemes.If
there
are enough good examples which relateto
a set of welldefined
outcomes or solutions, induction may be
usedto
determine
those
features
whichbest discriminate
the
cases andthe
indexing
schememay be
organized aroundthem.
Once
the
inductive
analyseshas
been
accomplished,
casesmay be
organizedin
ahierarchical fashion
that
allows retrievalon
the
order ofthe
log
ofthe
numberof cases stored.Not only does induction
allowthe
selection ofthose
features
whichobjectively best describe
the
domain,
but
alsoallows retrievalin less
than the
linear
time
requiredto
calculate aweightedsumfor
each case stored.In knowledge-based
indexing,
existing
knowledge is
usedto
determine
whichfeatures,
for
each
individual
case,
arethe
important
ones andto
matchthose
againstthe
input
case.This is
the
best
approachwhensuchknowledge
exists and canbe
codified.However,
oftensuch
knowledge is hard
to
obtain and representfor
a wide range ofinputs. Thus
this
methodis
oftenused as a supplementto
the
othertechniques,
helping
to
makeafinal
determination
afteraninitial
selectionhas been
made.efficientstructureandaccessmethods must
be
supplied.Storage
retrievalcanbe purely
associative,
withvery
minimalto
no relationalinformation
between
casesand a search methodthat
individually
considerseachone;
it may be
highly
organizedinto
a stricthier
archical structurethat
provides accessto
a particular case with minimalsearching;
orsome
intermediary
degree
ofstructurebetween
these two
extremesmay be
appropriate.The
nearestneighborindexing
schemelends
itself
wellto
purely
associativestorage andretrieval,
whereasthe
inductive
technique
providesthe
information
neededto
create an efficienthierarchical
structure.Discrimination
netscanprovide anintermediary
level
of organizationbetween
the two.
Adaptation:
After
a casethat
nearly
matchesthe
problemstatement andits
relatedsolution
has been
retrieved, the
solution needsto
be
adaptedto
fit
the
input
problem specifically.
There
are several general approachesto
caseadaptation,
but
the
processis
moredomain
specificthan
is
storage and retrieval.One
approachis
to
usedomain
specific rule-basedreasoning
to
workfrom
the
retrievedcases
to
a new solution.The
normaltechniques
ofrule-basedexpertsystems anddomain
modeling may be
used,
but in
a case-basedcontext, two
differences
resultFirst,
the
reasoning
processdoes
not startfrom
scratch,
but
proceedsfrom
one or moreexisting
solutions.
Thus
the
rule structuremay
be
simpler andthe
processfaster.
Second,
the
new solutionmay
be
storedsothat
future
adaptation canbuild
uponit,
increasing
the
knowl
edgeofthe
systemandits
effectiveness.Another
approachis
to
combine parts ofthe
various casesthat
existto
achieve a new solution.
This
may
workbest
where a complex case structure existsthat
has
subcases with welldefined
relationsbetween
them.
An
expert systemfor
designing
electronic circuits mightbe
ableto
combine subsystemsfrom
several pastdesigns
for
a new overall purpose.The
problem of case adaptationis
not yetto the
point where severaldifferent
genericapproaches exist
for
the
systembuilder
to
choosefrom. It is generally
approachedin
an adhoc
fashion,
andin
some systemsit is
not used at all.The
mere retrieval of several past casesfor
the
userto
startfrom
has
enough valueto
justify
construction ofmany
systems.For
instance,
the
SQUAD
system,
built
by
Hiroaki Kitano
for NEC Corporation
[23],
is
designed
to
index,
store and retrieveinstances
of softwaredefects
andtheir
cause,
solution and preventionfor
the
purpose of organizationalsharing of
experience,
as opposedto
an expert system whichactually
suppliessolutionsto
a problem.Learning
andGeneralization: Once
anew problemhas been
solvedthe
potentialexistsfor expanding
the
knowledge
ofthe
system andincreasing
its
potential andefficiency in
solving
other unique problems.How does
the
systemincorporate
newcaseknowledge in
orderto
expandits knowledge
base?
The
simplestapproachis
to
addthe
newcaseto
the
casememory
by
indexing
it in
the
way
that the
original cases were.With
an associativesearchstrategy utilizing
nearestneighbor,
this
is
straightforward.
However,
asthe
casememory
grows opportunitiesexistto
apply
more sophisticatedtechniques.
For
instance,
the
newcasesmay be
analyzed andthe
information
usedto
improve
the
efficiency
andreliability
ofthe
index
and retrieval process.Inductive
and explanation-basedindexes
couldimprove
their
feature
analysisovertime
andrestructurememory
to take
advantage of
the
knowledge
gained.Another possibility is
to
perform case generalization thatwoulddevelop
prototypicalcasesfrom many existing
cases.When
a new caseis
suffi-ciendy
the
same asthe
prototype,
it is
stored withit;
but
when a newtype
of caseis
encountered, the
potentialexiststo
create a new prototype and perhaps organizeexisting
casesthat
did
not quitefit
the
existing
prototypes underit.
Thus
memory
could undergo a radicalreorganization thatmight add a significantquantum tothe
system'seffectiveness,
as opposedto
asimple gradualincrease
withdiminishing
returns.Case based reasoning has
severalstrong
advantagesover other expert systemtechniques.It
structuresthe
knowledge engineering
processesin
away
that
fits
the
expert's ownapproach
to
problemsolving,
making
it
easierto
establisha system.It
is
easierto
maintain a systemby
adding
new casesthan
it is
by
adding
new rules.Case-based
techniques
arebetter
ableto
explainthe
solutionsthey
derive
than
arethe
rulebased
andotherapproaches.
Case-based
techniques
workbest
wherethere
already
exists alarge
store of casesto
draw
upon.
In
some situationsthey
do
notexist,
but
mustbe
createdthrough
interviewing
andobserving
the
domain
expert.This
canbe
acomplicatedandlengthily
task.
However,
in
someinstances
aready
made storeofknowledge
existsthat
canbe
exploited,
such asin
the
case of abiding
systemthat
made extensiveuseofaccounting
and contractinforma
tion thatcould
be readily
computerized.1.1
Problem Statement
Typical keyword
search systemsfor information
retrievalhave
severallimitations
and
draw
backs
that
may be improved
through
theuse of case-based reasoning.The
majorlimitation is in
retrievaleffectiveness as measuredby
the
performancefactors
of recall and precision.When
a searchis
made on aninformation
system'sdatabase,
the
user wishesto
obtain all relevant
documents
available,
anddoes
not wantextraneous,
irrelevant
documents
to
be
retrieved.In
responseto
aquery
for information
on a specifictopic,
the typical
systemwill notfind
all ofthe
relevantdocuments in
the collection,
andwill
inevitably
retrieve somethat
do
not pertainto the topic.
Given
the
subset ofdoc
umentsin
a collectionthat
actually
are relevantto the query, the
proportion ofthis
set retrievedby
the
query is
the
system's recall andthe
proportionofthose
retrievedthat
are relevantis
the
system's precision.In Blair
andMaron's
study
ofthe
STAIRS
retrievalsystem,
wordbased
retrieval systems
werefound
to
have
poor performance as measuredby
the
recall and precisionmetrics
[5j. Recall
wastypically
only
atthe
20
percentlevel,
when usedby
lawyers
in
their
area of expertise[6]. Users
were often unaware ofthis
poorperformance.The lawyers
in
this
study believed
that
die
recall ratewasaround75
percent.Their
for
usersto
foresee
the
exact words and phrasesthat
willbe
usedin
those
documents
they
willfind
useful,
andonly
in
those
documents."There
aretwo
linguistic
characteristicsof wordsthat
contributeto
this
problem:polysemy
and synonymy.Polysemy
is
the trait
ofonewordhaving
multiplemeanings,
such asthe
word"stringer,"whichin
the
context ofnewspaperreporting
refersto
anemployee,
whilein carpentry it
refersto the
supportfor
a stairway.Synonymy
is
the
trait
ofhaving
multiple words or phrasesto
expressthe
same concept ormeaning,such as
the
words"canine"and"dog."Polysemy
tends to
degrade
precisionbecause
the
wordsthat
may correctly
retrieve a relevantdocument
will also retrievethose
that
are notSynonymy
tends to
degrade
recallbecause
the
useofawordthat
correctly
refersto
a conceptin
the
query may
notbe
the
word usedby
the
authorin
the
soughtaftertext.
In
additionto the
impotence
ofwordbased
information
retrieval,
another problem with such systemsis
their
userinterface. The
usermusteither acceptthe
straightfor
wardlisting
ofwords,
each ofwhich mustbe
withinthe
document,
or mustlearn
how
to
create parenthesized expressionsusing
the
system'slogical
and positional operators.Due
to the
needto
deal
withpolysemy
andsynonymy,
search expressionsmay
become
very
long
and complex.In
orderto
reducethe
effectsofsynonymy,
many
terms
relating
to
the
same concept arestrung
together
withthe
OR
operator.If
multi pletopics
arebeing
searchedfor,
each concept mustbe
defined
in
this
fashion. If
documents
withseveraldifferent
combinations ofthe
sametopics
arcdesired,
these
combinationsmay have
to
be
repeated overwithinthe
same expression.For
instance,
considerthe
case where a useris interested in
topics
A,
B
andC,
and wantsany document
relevantto
A for background
information,
anddocuments
that
are relevantto
both
A
andB
aswell asdocuments
relatedto
A
andC,
but is
notinter
estedin B
andC
alone orin
combination.The
expressionhe
woulduse wouldbe A
OR
(A AND
B)
OR
(A
AND C
),
whereA,
B
andC
arelong
disjunctions
ofterms
relatedto their
respective concepts.In
orderto
reducethe
effect ofpolysemy, the
usermay
conjointhe
basic
conceptterms
withthose
of more general conceptsin
orderto
establishthe
context ofthe
conceptbeing
searchedfor. In
orderto
usethe term
"stringer"in
the
sense relevantto
carpentry,
as opposedto
its
usein
the
context of a newspaperorganization,
one couldconstructan expression such as<
STRINGER AND CARPENTRY AND
NOT
NEWSPAPER)
.Such
expressionswouldthen
have
to
be strung
together
withOR's
to
handle synonymy
andfactored
out wherethe
generalterms
are repeatedjust
to
makethe
expressionsmanageable.Of
course, there
is
no guaranteethat the
more generaltopic
is
mentionedin
a relevantdocument,
andin
such casesthe
document
wouldbe
excluded.The
userinterfaces
of mostkeyword based
systems presents aclumsy
searchdialog
and
does
not supporteasy
query
refinement.The way in
whichdocuments
ofinterest
aredescribed,
andthe
interaction
that
musttake
placeto
refinethe
description
is
ically
inefficient.
They
typically
giveonly
the
numberoffound
documents
and shortdescriptions
such astides, usually in
somearbitrary,
non-problemrelatedorder, to
the
user whois
then
onhis
ownto
refinethe
searchfurther. The way in
which a usergenerally interacts
with such a systemhas been investigated
by
Blair
[6]. A
user will enter aninitial keyword
and useit
to
conductapreliminary
search.This
willusually
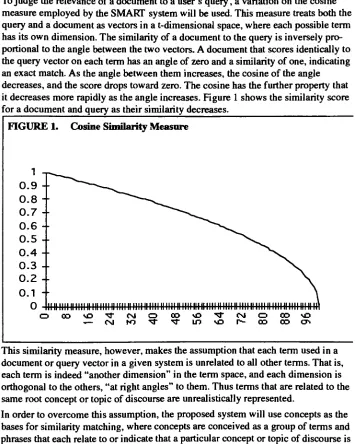
resultin
alarge
number ofdocument
descriptions
retrieved,
presentedin
ahodge
podge order.The
userthen
addsterms to
his query simply
to
reducethe
number ofdocuments
that
areretrieved,
and repeatsthis
processuntilthe
numberofdocuments
seems sufficient
for his
purpose and notunmanageably large. Thus
the
query
refine ment processis directed
towards
quickly reducing
the
numberofdocuments
retrieved,
ratherthan towards the
best
formulation for
finding
the
neededdocuments.
1.2
Previons Work
Case based reasoning has formed
the
basis
for
several recentinformation
retrievalsystems,
andthere
have
been
afew
theoretical
discussions
ofthe
applicability
ofthis
technique to
severaldomains
withinthe
information
retrievalfield.
CreANIMate
Daniel C. Edelson
[13]
has
done
work onthe
utilizationof case-basedreasoning in
teaching
systems.His
system,
calledCreANIMate,
uses storiestohelp
teach the
bio
logical
principles of animalmorphology
to
elementary
school students.The
systemengages
the
studentin
adialogue
aboutanimals,
andis
remindedof storiesby
cuestaken
from
the
interaction.
The
"stories"are
actually
video clipsillustrating
the
functions
of various animalfeatures.
In
mostknowledge based
tutoring
systems, the
system mustknow
as much abouttheinstructional
material asthestudentis
to
learn. Tn
thissystem,
however,
much ofthe
lesson
comesfrom
multimedia presentationsthe
content of which wouldbe very dif
ficult
to
capturein full. Case-based reasoning is
usedin
ordertoselect appropriatestories
for
the
studentwithouthaving
to
have
afull understanding
ofthe
stories' content
A
full
description
ofthe
contents of alibrary
of video clips wouldbe
very
large,
if
at allpossible,
and wouldtax
the
computational resourcesthat
are availablefor
apractical
implementation.
But
sincethe
case-based system'sknowledge
representation
is computationally
manageable,
more"expressive"
information,
such as videoclips,
canbe
presentedthan
is usually found in
such systems.The
kinds
ofreminding
that the
system supports arebased
on common pedagogicalcategories; the
systemis
reminded ofexamples,
ofsimilarities,
and of expectation violations.Examples
are usedto
explain somefeature
that
an animalhas in
terms
ofthe
capability it
givesthe
animal andthe
survival value or purpose ofthe
capability.Similarities
are usedto
present examples of other animals withdifferent features
andcapabilities
that
servethe
samepurpose,
in
orderto
lead
the
studentto
generalizethe
lesson learned
from
one case.Expectation
violations are usedto
challengethe
student
withmore exactknowledge,
and arethought to
have
intrinsic
valuein
them
The
case structurethat
supportsthis
systemis
composed ofanindex
ofvideoclips.Each clip
is
relatedto
ananimalthat
appearsin
it,
afeature
ofthe
animalillustrated,
the
capability
the
feature
givesthe animal,
andthe
survival valueofthe
capability.In
addition,
a more general expressionofthe
capability
andthe
survival valueofit
is
alsorepresented.
Thus
a videoclip
of a cheetahpursuing prey
wouldbe indexed
thus:
Specific Animal:
Cheetah
Specific Feature:
Long
Legs
Specific Capability: Run Fast
Specific Survival Value: Pursue
Prey
Generalized Capability: Move Fast
Generalized Survival Value:
Hunting
During
the
dialogue,
mention oflegs,
running
fast,
or pursuit ofprey
will remindthe
system ofthe
clip
andit
canbe
presentedto
the
student.This
is
a case of"example
reminding".
The
generalizedcapability
and survival value canthen
be
usedto
remind
the
systemof similar cases.For
instance,
another videoclip indexed
with"Move
Fast"and"Hunting"might
be
the
fishing
bat
that
flies in
orderto
pounce onits
prey.In
orderto
support exception remindings anotherindex
structureis
used.A
universalassertionabout a
kind
of animalforms
the expectation,
andit is
relatedto
video clipsillustrating
an exceptionto
it.
For instance,
the
expectationthat
allbirds
fly
to
flee
predatorswouldbe
representedthus:
Generalized Animal: Bird
Capability:
Fly
Survival Value: Flee Predator
Violation:
Capability.
Fly
Clip: Ostrich
Running
Fast
When any
animalclip
that
is
relatedto
birds
flying
to
flee is
activated, the
system canbe
reminded ofthe
exception and presentit
to the
studentin
anappropriate manner.
FERRET
The FERRET
systemdeveloped
by
Michael Mauldin
atthe
Center for Machine
Translation
atCamigie
Mellon
University
utilizesnaturallanguage processing
to
understandand
index
texts
and a caseframe
structure asits knowledge base [33].
The
systemhas been
usedto
experimentally
measurethe
increase in
recall andprecision
that
mightbe
gainedby
employing
conceptualinformation
retrieval.The
system consists of atext parser,
aquery
parser,
and a caseframe
matcher.The
text
parser readsthe
documents
to
be indexed
and creates caseframes
that
abstracttheir
semantic content.The
abstractsform
the
knowledge base for
the
system.A
query
parser accepts a naturallanguage
query
andconstructsa caseframe
patternfrom it. The
caseframe
matcherthen
searchesthe text
abstractsfor
relevanttexts,
whichare retrieved.The
system was usedto
experimentally
evaluatethe
increase in
precisionandrecallthat
canbe
expectedutilizing
conceptualinformation
retrieval overthe
standardboolean keyword
retrieval.22
sample user queriesthat
had been
expressedboth in
the
standardkeyword format
andin
naturallanguage
were usedfor
retrievalonthe
same collection ofoverathousand
astronomy
textsThe
resultswerethen
compared.Over
the
22
test
queries,
the
35%
ofthe
documents
retrievedby
the
keyword
search werejudged
to
be actually
relevant(precision),
whereas about46%
ofthe
docu
ments retrievedby
FERRET
werejudged
useful.The
meansofdeciding
adocu
mentsusefulnessgiventhe
goalofthe
query
were notdiscussed.
To
estimaterecall a searchwas madeby
hand
ofthe
entiredocument
base
for
alldocuments
relevantto
a random sample of5
ofthe
44
queries.The keyword
searchesfound
on average20%
ofthe
documents deemed
relevant,
whilethe
FERRET
system was ableto
find 52%
of
them.
The FERRET
systemis
notapractical,
fully functioning
system.It
wasimplemented
to test
the
relative performance of conceptualinformation
retrieval againstboolean
keyword
searching
techniques.
The
query
parser ofthe
systemis
notimplemented
and was simulatedfor
the
purposeofthe
study
by
using
the text
parser.Of 44
origi nal naturallanguage
queries,
22
could notbe
parsedat all and16
neededto
be
para phrasedby
the
authorbefore
successful parsing.Only
6
ofthe
original44
couldbe
parsed as
submitted,
and ofthe
44 only
22
were ableto
be
usedin
the
final
study.Although
the
authorcarefully
documents
the time
requiredto
index
documents,
no performancefigures
aregivenfor
retrieval, thus the
performance a user could expectis
unknown.Although
the
FERRET
systemuses caseframes
asits knowledge base
and casematching
asits
retrievalmechanism, the
authordid
not elaborateonthe techniques
usedto
determine
similarity
between
the
query
caseframe
patterns andthe text
abstractsThe
texts that
areindexed
are all narrative scriptsfrom
a radioshow,
cho senin
partbecause
the
narrativestructure makesthem
easy
to
parse comparedto
journal
articles,
whichmay
contain referencesto
otherarticles, charts,
figures,
etc.The
texts
are alsofairly
short,
only
about300
words each.The
systemrequires adomain description based
onasurvey
ofthe texts to
be
indexed,
andin extending it
from
the
limited domain description
adequateto
cover radio show scriptsto that
requiredfor
the
full
scienceofthe
astronomy
problemswouldlikely
be
encountered.The
proposed system willdiffer
from FERRET in many
ways.It
willbe
aworking
system with afully
functional
userinterface. It
willbase
querieson a"prototype"or "example"of
the
document
createdby
the
userin
a simple andstright-forwardway.document
index,
andthus
overtime
makeit
easierto
retrievedocuments
as well asimprove
the
system's precision and recall.Litigation Support Systems: Flexicon
Case based reasoning has been
frequently
appliedto the
area oflitigation,
sincereasoning from
precedent and past casesis fundamental
to the
legal
process.Although
there
aremany
novelknowledge based
systemsemerging,
in
mostpractical,
working
systems research
into
past casesis
fundamentally
treated
as atext
search andretrieval problem.
The legal
professionmakesuse of moreinformation
than
any
otherprofessional
group,
andlawyers
accesselectronicdatabases
that
encompasstens
of millions ofdocuments
on adaily
bases. A
text
retrieval systemin
the
legal
domain,
calledFlexicon,
that
incorporates
case-basedreasoning
techniques
has been
constructed
by
Daphne
Gelbart
andJ. C. Smith
[14].
This
system shares somefea
tures
withthe
proposed system.The
Flexicon
userinterface
avoidsthe
use ofthe typical
boolean
searchquery
andinstead
usesfour input lists
underthe
categoriesofconcepts,
cases,
statutes andfacts.
The
significance of eachentry
may be
specifiedashigh,
medium orlow. Legal
concepts or phrases are
keywords standing for
applicablelaw
andthe
resolutionsobtainedwhen
the
law
is
appliedto the
facts. Examples
giveninclude
"zoning,""duty
of care"and"negligence."
Case
citationslist
those
previous casesthat the
useralready knows
to
have
abearing
onthe
legal issues in
question.Statute
citationslist
those
laws
that the
userjudgesto
have
relevance.Facts
arekeywords
that
collectively
expressthe
relevantfactual
aspects of a particular case.The
example given of afact list includes
the
namesofthe
litigants,
geographicalinformation
such as citiesandstreet
names, types
ofbusinesses
andinstitutions
such as"restaurant,"
relation
ships
that
obtain withinthe
case such as"employee,"
and
legal features
that
are relevant suchas
"building
permit."
Each list is
simplein
that
it does
not attemptto
express relations
between
elements.The
systemindexes
casesautomatically
according
to the
four input
categories.In
order
to
gleanlegal
concepts andfacts
ofinterest from
the
casetext,
anintelligent
text
parseris
usedthat
has
anability
to
recognize complexlegal
phrasesbased
onapproximateword matches and
orderings, without,
however,
doing
actual naturallanguage parsing
and understanding.The legal
concepts andfacts
are weighted pro portionalto the
frequency
withinthe
document
andinversely
proportionalto the
number of
documents
that
containthe word,
whichtends to
givelower
weightsto
those
wordswhichhave less ability
to
differentiate
anddefine
the
document's
content
Case
citationsare convertedto
a"canonical
form"and areweighted
according
to
frequency
withinthe
document. In
the
legal domain
case citations are goodindica
tors
ofdocument
content,
since each cited case serves as asuccinct expressionfor
aparticular
legal issue
orconcept, and,
unlike words orphrases,
do
nothave
synonymsor
homographs.
Statute
citations arealsoconvertedto
acanonicalform
andare also weightedproportional
to
their
document
frequency.
They
servemuchthe
sameusefulnessasdo
the
case citations.When
the
userenters aquery,
FLEXICON
searchesits
document
profiledatabase
and computes a
similarity
scorefor
eachdocument based
on a variation ofthe
cosineformula
givenby
G. S. Salton (discussed in
moredetail in
the
sectionbelow
onthe
SMART
system).Citation
cross referenceinformation is
usedin matching
on casesand statutes and a synonym
thesaurus
is
usedto
match onlegal
concepts andfactual
terms.
This
allowsthe
inclusion
ofdocuments
that
coverthe
sameor similarcases,
statutes,
concepts andfacts
regardlessof whetherthe
user'squery
containedthe
exactterminology
in
the
document
After concluding
asearch, the
system presentsthe
retrieved casesto the
userin
order oftheir
similarity
score,
andindicates
the
scorefor
each caseboth numerically
andin
the
form
ofabar
graph.All documents
over athreshold
valueofsimilarity
areshown,
but
sincethey
are stack rankedthe
userdoes
not perceivethe
numberofcases retrieved
to
be
aproblem, thus
avoiding
query
refinementbased solely
onthe
need
to
reducethe
numberofdocuments
to
avoid"information
overload."
There
are a number ofdifference between FLEXICON
andthe
proposed system.First
andforemost,
the
query
specification andindexing
techniques
used are specificto
the
legal domain.
The
proposed system willfunction in any
domain
as a generalpurpose
text
retrieval system.The FLEXICON
systemdoes
notlearn
from
the
userhow
better
to
evaluate andclassify documents. The
proposed system will providethe
user a means of
evaluating
the
relevanceofdocuments
and will notonly
usethis
information in
placeofquery
refinement,
but
alsoto
learn
aboutthe
documents' content
andthus
be
ableto
improve
performancefor
other users overtime.
Litigation
Support Systems: Purposive Search
One
class of case-basedreasoning
systemgenerally
starts with a problem statementthat
involves
the
specificationof a purpose or otherfunctional
description.
These
aresystem
that
areintended
to
help
engineersfind
and reusedesigns.
The designs
areindexed according
to the purpose,
orfunctionality
that
they implement,
as opposedto the
implementation
specifics.Case
matching
is
usedto
find designs for devices
orcomponents
that
serve similarfunctions
or purposesto the
onethe
engineeris
currently
trying
to
implements. Mital
[30]
has
appliedthe
purposive approachto text
retrievalin
the
legal domain.
In litigation
support systemsthe
documents
to
be indexed
and retrieved are allrelated
to
a specific casethat the
litigation
team
is working
on.Documents may
consist of
contracts, telephone
logs,
receipts,
and othervariety
of evidencethat
may be
used
to
support or contend againstthe
claimsbeing
madeis
aspecificcase.It is
not unusualfind
casesthat
involve 50,000
or moredocuments. The ability
to
find
the
right
document
atthe
right
time
may
makethe
difference in
a case.Rather
than
index
the
document
collection onthe
basis
ofits
contentsalone,
the
for in litigation. A
certaintype
oflegal
actionhas
certain specificlegal
andfactual
issues
that
arein
contention,
andthe
litigation
team's
purposeis
to
proveordisprove
them.
For
instance,
in
a caseinvolving
negligent misrepresentationby
afinancial
adviser
that
causeshis
clientto
sufferaloss
the
broad issues may
be defined
asWhether
the
clientpossessedinformation from
other sourcesWhether
the
client actedaccording
to
the
adviser's adviceWhether
or notthe
loss
wascausedby
reasons otherthan
just
taking
the
adviser'sadvice.
For
aparticularcase,
andindeed,
for
entire classesofcases, these
issues may be
welldefined
andmay be decomposed into
ahierarchy
ofissues.
However,
just
labeling
the
documents
withthe
issues
and sub-issuesis
too
imprecise
and coarse.The
usersshould
be
ableto
retrievethose
document's
that
relateto
a specificissue in
a particular
way,
andthere
areothertypes
of properties ofdocuments,
otherthan the
issues
they
relateto,
that
determine
their
usefulnessin
a court oflaw.
One
type
ofproperty
that
is
needto
be known
aboutdocuments is
the
kind
ofdocu
ments
they
are.But in
this case, the
classification systemis
peculiarto
the
legal field.
At
the
highest level
documents
may be
classifiedinto
those
of"disputable
provenance"
and
those
whose contentsmay be "assumed known
to
sender."For
instance,
a
telephone
log
is
ofdisputable
province sincethe
sender(caller)
does
not necessarily
know
whatis in
it,
or eventhat
it
exists.However
the
contentsof a postal com municationis
assumedknown
to
the
sender.In
the
caseof a postalcommunication,
the type
may be further
decomposed
into
those that
areregistered, those that
have
asigned
receipt,
etc.Another way
ofclassifying
the
documents
in
a caseis
by
the
situationalfacts
that
are coveredin
them.
Once
again, there
is
a specificlegal
interpretation
and classification,
typical to
eachtype
ofcase,
asto
what situationalfacts
are and are notimpor
tant.
In
the
example we startedwith,
loss due
to
bad
advice, the
rootfacts
arethe
sources of
"independent
knowledge"and
the
loss itself. Facts
underthe topic
ofindependent knowledge may be
relatedto
'Third
Party
Advisors"and eachtype
of suchadvisor,
such aslawyer
or accountant.Under
the
loss,
relevantfacts
arethe
"loss
accrued"and
"estimated
future
loss."In any
particulartype
oflitigation
the
fundamental facts
to
be
proved ordisproved
are a mater of previouslegal
precedent,
so a system of
this type
could start with much ofthe
higher level
categoriesalready
established.
The issues
adocument is
concernedwith, the type
ofdocument it
is,
andthe
facts
that
it
tends to
establish are all atomic properties ofthe
document itself. Other
types
of relational
information is
stored withthe
document. These
areexplanatory
links,
reference
links
and relevancefunctions.
An explanatory link
relates an atomicproperty
to
anotherin
the
document in
orderto
represent
the
extent ofthe
validity
ofthe
interpretation
the
atomicproperty
represents.
The
types
of relations are"Implied
By,"
"Alternative
Interpretation," and"Excludes."
As
anexample,
adocument may
supportthe
situationalfact
that the
plaintiff
"attended
seminars ontrading
futures."But
if
the
indexer
thinks that the
document
canshowthat
he
did
sonotasa passivelistener,
but
intended
to
getpersonal advise
form
the
lecturer,
an alternativeinterpretation may be
"advised
by
third
parties."
The indexer includes
the
explanatory link
to
indicate
that the
atomicprop
erty "advised
by
third
parties"is
analternativeinterpretation
ofthe
moredirectly
supported
property "attended
seminars."
A
referencelink
relatesthe
document containing it
to
othersin
the
system.The
types
of relations are
"Refers
To,""Incorporates,"
and"Rebuts."
If
aletter
is
sentby
the
plaintiff
in reply
to
anaccusatory
letter
from
the
defendant,
it may
containinforma
tion
that
would gotowards
disproving
the
contentionsin
the accusal,
andthus
wouldbe
relatedby
the
"Rebuts"link.
A
relevancefunction
relatesone(and only
one)
of adocument's
relevantissues
to
one or moreof
the
otheratomic propertiesofthe
document. For
instance,
the
relevant
issue "Loss
by
Extraneous
Factors"may be
relatedto the
properties"Phone
Log,""Accountant,""Buy
Put
Options,"and
"Acceptance
ofAdvice."Remember
that the
atomicproperties existinside
oflegal domain hierarchies
suchas"Phone
Log"
being
aninstance
of adocument
withdisputable
providenceand"Accountant"being
a"Third
Party."This
givesthese
basic
qualities more significancethan
they
would
have
as simple phrases or qualities.While
there
is
no universaltheory
of relevance of conceptsto
issues
in
the
legal
domain,
it is
possible giventhe
facts
of a casefor
alawyer
or paralegalto
determine
that
adocument is
likely
to
be
relevantto
a particularissue
andfor
the
reasonthat
the
document
contains referencesto
certain concepts.The
referencefunctions apply
only inside
a specificdocument,
but it is
inevitable
that
many
ofthe
functions from
many
ofthe
documents
willbe
similar,
if
notexactly
the
same.The
referencefunc
tions
from
the
documents
may
be
organizedinto
a subsumptionhierarchy,
discrimi
nated
first
by
the
issue
andthen
by
the
other propertiesin
order ofimportance
asindicated
by
the
indexer.
In
orderto
retrievedocuments,
the
user specifies aquery
that
matches a referencefunction in
form,
that
is,
it
consistsofoneissue
and a set of other atomic properties.A document is
retrieved when atleast
one referencefunction in it
matchesthe
query.A query
can matchexactly
eithersimply
orthrough the
agency
of anexplanatory
function,
andit
can match partially.For
aquery
to
matchsimply, the
issue
andthe
atomic properties must eithermatchidentically
orbe closely
relatedin
the
varioushierarchies
to
whichthey
belong. A
query
can also matchif
anexplanatory link may be
usedto
alter areferencefunction
to
match.For
instance,
if
the
issue in
the
query is "Advised
by
Third
Party"and
in
the
referencefunction
the
issue
is "Loss
by
Extraneous
Factors,"a simple matchwill
not
be
made.But
if
a"Alternative
Interpretation"explanatory link
existsbetween
matches
but
notall other propertiesmatch.The
systemorders resultsby
degree
of matchfor easy
perusing.This
Mital's
systemis very different from
the
proposed system.In Mital's
systemadocument
is
retrievedaccording
to
its
purpose asdetermined
by,
andonly
by,
a spe cificlegal
contextcreatedby
a specificlegal
action.The
contextandthe
actionso constrainthe
useandinterpretation
ofthe
documents,
that the
purposesthat
adocu
mentmay
serveactually become
anintrinsic property
ofthe
document,
as much asany
other attribute wemightnormally
ascribeto one,
andthus
are ableto
be
usedin
indexing. In
contrast, the
purposesthat
documents
servein
the
contextof a general purposeliterature
searchsystem are extrinsicto
them,
and cannotbe
determined
a prioriby
anindexer. Certain
attributes of adocument
might makeit statistically
moreuseful
to
more researchers with acommonstatedpurpose,
andthis
information
may be
usedto
presentthe
resultsin
ausefulway
to the user,
but
the
purpose cannotbe
attachedto the
document
as aninherent
attribute ofit. The
extrinsic notion of pur pose wouldhave
to
be
usedin
a general purposelitereture
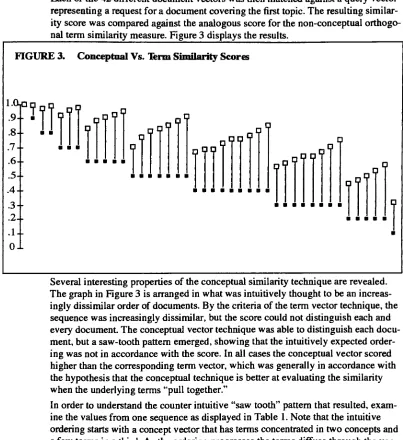
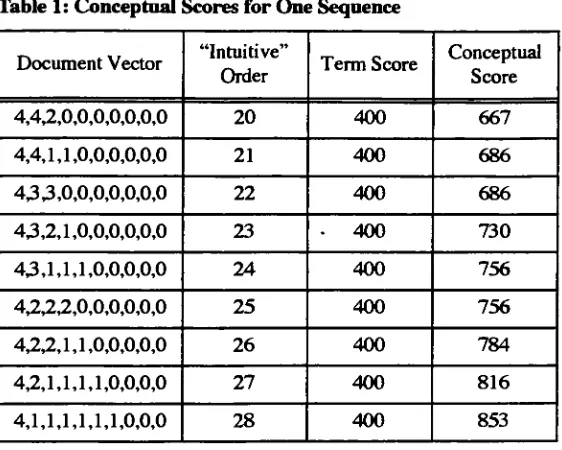
search system.The SMART System
The SMART
systemis
aninformation
retrievalsystemthat
pioneeredmany
ofthe
experimental retrieval
techniques
developed in
the
last
three
decades.
It
containsmany innovative features
that
distinguish it from
more conventional systems:fully
automaticindexing,
subjectclassindexing;
queriesbased
onsimilarity
matching
ratherthan
boolean
keywords
and automaticquery improvement based
on userfeed
back
[37].
Automatic
indexing
in
the
SMART
systemis
accomplishedby
using
words and phrasesextractedfrom
the text
using
fairly
simplelanguage processing
techniques.
The
individual
wordsin
atext
arefirst
parsed andfiltered using
astop list
of ordinary,
less

![FIGURE 8.REPRESENTATION OFA DOCUMENT PROTOTYPE|Q Information�][O](https://thumb-us.123doks.com/thumbv2/123dok_us/114874.10996/38.470.43.436.364.605/figure-representation-ofa-document-prototype-q-information-o.webp)