Rochester Institute of Technology
RIT Scholar Works
Theses
Thesis/Dissertation Collections
1993
Word hypothesis from undifferentiated, errorful
phonetic strings
R. Thomas Sellman
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion
in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact
.
Recommended Citation
Rochester Institute of Technology
School of Computer Science and Technology
Word Hypothesis From Undifferentiated. Errorful
Phonetic Strings
by
R.
Thomas Sellman
A thesis. submitted
to
The Faculty of the School of Computer Science and Technology.
in
partial
ful1illinent of the requirements for the
degree
of Master of Science
in
Computer Science.
Approved
by :
Professor John A. Biles
(Chairman)
Dr. James M. Hillenbrand
R·I·T
SAMPLE statements to reproduce an RIT thesis:
PERMISSION
GRANTED
Title of thesis
U';,C,RD
fo·d
Pc
114
GS,S
Fi2DM
ei~
..
(?.[J,rcri.AL
Plvto
N
Eric
sTfCl
tJ(.tS
Rochester Institute of Technology
\Vallace Library
Post Office Box 9887
Rochester, New York 14623-0887
716-475-2562
Fax 716-475-6490
Signature of Author:
I
J ..
11t.t>VVlA-S
SGL.L-I\,1,4-I\}
hereby grant permission to the
Wallace Memorial Library of the Rochester Institute of Technology to reproduce my
thesis in whole or in part. Any reproduction will not be for commercial use or profit.
Date:
(, /22
/Cf_3
PERMISSION FROM AUTHOR REQUIRED
Title of thesis
_
I
prefer to be contacted each time a
request for reproduction is made. I can be reached at the following address:
PHONE:
Date:
Signature of Author:
PERMISSION
DENIED
TITle of thesis
_
I
hereby deny permission to the Wallace
Abstract
This
thesis
investigates
adynamic programming
approachto
wordhypothesis
in
the
context of aspeaker
independent,
large
vocabulary,
continuous speech recognition system.Using
amethodknown
as
Dynamic
Time
Warping,
an undifferentiated phoneticstring (one
withoutwordboundaries)
is
parsedto
produce allpossible
wordscontained
in
adomain
specificlexicon.
Dynamic
Time
Warping
is
acommon method of
sequence
comparison usedin matching
the
acousticfeature
vectorsrepresenting
anunknown
input
utterance and some referenceutterance.The
cumulativeleast
costpath,
whencomparedwith some
threshold
canbe
used as adecision
criterionfor
recognition.This
thesis
attemptsto
extendthe
DTW
technique
using
strings of phoneticsymbols,
instead.
Three
variablesthat
werefound
to
affectthe
parsing
processinclude:
(1)
minimumdistance
thres
hold,
(2)
the
number of word candidates accepted atany
given phoneticindex,
and(3)
the
lexical
search space used
for
reference pattern comparisons.The
performance ofthis
parser as afunction
ofthese
variablesis discussed. Also discussed is
the
performance ofthe
parser at avariety
ofinput
errorAcknowledgements
I
wouldlike
to
extendmy
sincere
thanks
and appreciationto
Dr. Jim Hillenbrand for coaching
methorough
this
long
and arduous endeavor.His
experience and expertisein
the
field
of speech recognitionwas
invaluable.
I
amindebted
to
Dr. Hillenbrand
ashis
encouragement,
assistance and experttutelage
was
indispensable
in
keeping
this thesis
focused.
I
must also extendmany
thanks to
Al Biles for
allhis
suggestions andinput into
the
research.In
a multi-functional role as
RIT
advisor,
professorfor
severalcourses,
and committee,chairman.
I
amappreciative of
bis
analysis
and guidance.The
following
peopledeserve
thanks
for
their
roles as part-timeadvisors, consultants,
andreviewers:
Rob
Gayvert,
Harvey
Rhody,
Betsy
Richards
andTom Ridely. I
wouldbe
terribly
remissif
I
did
notinclude
thanks
to
my
wifeConnie for her
endless patience and supportduring
the
many late
nights andweekends
during
this
period.This
research wasin
part supportedby
Rome Air Development Center (Griffiss
AFB,
New
York)
and
done in
cooperation withthe
Rochester Institute
ofTechnology
Research
Corporation
(Rochester,
TABLE
OF
CONTENTS
1
Introduction
1
2
Speech
Understanding
3
2.1
Concepts
ofSpeech
3
12
Automatic Speech
Understanding
Systems
4
2.2.1
Difficulties in ASU
4
2.2.2
Extensibility
. ___..._.5
2.2.3
Previous Systems
6
2.2.4
Current System Architecture
7
23
Lexical Access
9
23.1
Error
Conditions
_ _10
232
Approaches To
String
Comparison
13
2.3.2.1
Hidden
Markov
Models
13
2.3.2.2
Dynamic Time
Warping
14
2.3.2.3
Comparison
ofHHM
andDTW
16
3
Experimental Method
..18
3.1
Software Tools
18
32
Hardware Tools
.. _18
3.3
Distance
andConfusion Matrices
. ~19
3.4
Lexicon
Construction
24
3.5
Test Data Creation
25
3.6
Dynamic Time
Warping
Process
26
3.6.1
Constraints
andConsiderations for DTW
26
3.7
Recognition Technique
29
3.7.1
Sentence
Parsing
29
4
Results
34
4.1
Initial
Empirical Findings
34
4.2
Test Series 1
37
4.3
Test
Series 2
49
5
Conclusions
58
Appendicies
61
Appendix A: Distance Matrix
61
Appendix B: Confusion
Matrix
63
Appendix C: Phonetic Symbols
65
Appendix D: Test Phrases
66
Appendix E: Lexicon
69
CHAPTER
1
INTRODUCTION
Spoken language is
one ofthe
mentalfaculties
that
mostidentifies
us ashuman
[WINS84],
andthereby
becomes
a prime area of considerationfor
artificialintelligence
research.George White
identified
speech communication research as a"major
force"in
man-machineinteraction,
justified
by
that
fact
that
"speech
remains unrivaled asthe
fastest
and most convenientway for
human
beings
to
communicate interactively"
[WHTnol.
Martin's study
[MART87]
ofthe
utility
of speechinput in
user-computer
interfaces found
evidenceto support two
claims:(1)
speech provides a more efficientresponse channel
than typed
input,
and(2)
speech supplies an addedresponsechannelincreasing
userproductivity,
particularly in
situations where paralleltasks
aredistributed
across multiple mentalresources.
Martin
alsosuggested
that
continued
researchin
speech recognitiontechnologies
was warranted
by
the
future utility
of speechinput
This
thesis
is
a part of anongoing
project atRochester Institute
ofTechnology
Research
Corpora
tion. The
project's
aimis
to
conduct researchin
the
development
of aspeaker-independent,
large
vocabulary,
continuous speechunderstanding
system,
applying
techniques
ofartificialintelligence in
additionto
otherdisciplines.
As
willbe
explainedin
the
following
sections,
some speech recognition methods provide asequence
of phoneticsymbols
that
are representative of some utterance.The
sequenceis
searched
for
conceptually larger
forms
(words)
that
are consistent with adictionary
(lexicon).
The
searchinvolves
selection of
phonetic
reference patternsfrom
the
lexicon,
then their
comparison againstthe phonetic
representation of
the
input
utterance.Based
on a measure ofsimilarity (to be defined in later
sections),
the
presence ofreference
wordsin
the
input
utteranceis hypothesized
or rejected.The
collection ofthese
proceduresis known
asthe
process oflexical
access.in
adomain-specific
lexicon.
This
requiredthe
establishment ofknowledge
sources,
determining
theirrepresentations,
andthe
provision ofsome search procedureto
progressthroughthe
unknownutteranceto
producehypotheses
of words contained withinthe
utterance.The
search procedure used wasbased
on
the concept
ofdynamic
programming,
whichis
described
asfollows.
When searching
from
anini
tial
stateto
a goalstate,
all pathsfrom
the
initial
state through anintermediate
state canbe
ignored
except
the
least-cost
pathto that
intermediate
state.Therefore,
the
useofdynamic programming
prunesaway
non-vitalpaths,
reducing
the
time
and computational resourcesfor
the
search.Details
ofthis
search concept are presented
in Chapters 2
and3.
Chapter 2 is
a
discussion
ofissues in
the
field
ofspeechunderstanding.Some
previous systemsare
overviewed,
followed
by
a presentation ofthe
architecture ofthe
R.LT. Research
Corporation
Speech
Understanding
project.Approaches
to
string
comparisonarecoveredwith an explanation ofthe
principal methods
currently in
use.Chapter 3
coversthe
experimental methods ofthe
thesis
projectitself.
Topics
include
the
knowledge
sources used andtheir
preparation,
recognitiontechniques,
algorithm constraints and conditions,
evaluationcriteria,
andthe
software/hardwaretools
used.Chapter 4
presents adiscussion
ofthe
results obtainedduring
experimentation.
Conclusions
andCHAPTER 2
SPEECH
UNDERSTANDING
2.L
Concepts
ofSpeech
Speech is
a
process usedfor
messagetransfer
from
oneindividual
to
another,
involving
the
generation and reception of complex acoustical signals.
The
processmay be
thought
of as acoding
anddecoding
operation over ahierarchy
oflevels [HYDE72].
At
the
highest level
wehave
the
formation
offundamental concepts,
orthoughts,
which areencoded as words on
the
linguistic level.
These
words are encoded onsuccessively lower
levels,
involving
neuralprocessing
andarticulatory
movements1,
until wereachthe
lowest level
-the
acoustic
signal.
Speech understanding is
the
reverseprocess,
trying
to take the
acousticlevel information
andwork
back up
the
hierarchy
to
some meaningfulinterpretation.
These hierarchical levels in
effectdescribe
some ofthe
basic knowledge
sources availablefor
the
task
of speechunderstanding,
including
semantic, syntactic, prosodic,
and acousticknowledge
sourcesrWHn76,
REDD76].
Semantic
knowledge includes
wordmeanings andtheir
relationships,
whilesyntactic
knowledge
refersto the
structural aspects ofthe
language (e.g.
wordorder).Prosodic
sources arespeech
features like
stress,
intonation,
and rhythm.Acoustic
signal characteristicslike energy
level,
fundamental
andformant
frequencies,
andzero-crossing
ratesform
yetanother source ofknowledge.
Although
the
speechlevels
and events canbe
described,
it is
often unclearhow
the
knowledge from
one
level is
transformed
into
the type
ofinformation
used on a successivelevel
Not
knowing
these
transformation
methodsis
aninherent
difficulty
in
developing
anAutomatic
Speech
Understanding
Sys
tem
(ASU)
|WHn76].
The degree
ofdifficulty
depends
on whattype
of speechunderstanding
systemis desired
or required.1ArticuUionare structures
in
the22. Automatic Speech
Understanding
Systems
2^.1.
Difficulties in
ASU
Three primary factors
controlthe
level
ofdifficulty
ofthe
automatic speechunderstanding problem,
andin
effect categorizethe types
of systemsthat
have
been,
and continueto
be
investigated[REDD76.
PARS86].
The first factor
concerns whetherthe
systemis
designed to
recognizespeech produced
by
one,
ormorethan
onespeaker(speaker
dependent
vs. speakerindependent).
Speech
signalscontain talker-dependent
information
which resultsin
alarge
disparity
between
acoustic patternsrepresenting
the
same utterance when spokenby
different individuals
[PARS86].
This
(hspanty
between
individuals
is primarily
causedby
differences
in
characteristicslike
vocaltract
size andconfiguration,
voicepitch,
anddialect
Single
speaker recognition systemsdo
nothave
to
accountfor
these
differences
to the
samedegree
as multiple speaker systems.The
variations are minorby
comparison and can
be
compensatedfor
by
effectivetraining
techniques.
The
secondfactor is
whetherthe
systemis intended
to
recognizeisolated
words(discrete)
orcontinuous
speech.Words in
isolation
providethe
easiestopportunity
to
identify
the
start and end of aword
in
an acousticalpattern[PARS86]. When
peopletalk
in
a continuousfashion,
boundaries between
words
become blurred
exceptin
ahigh level
cognitive sense.In
addition,
wordsarestrongly influenced
by,
and canthemselves
influence surrounding
words.This
is due
to
coarticulation and phonologicalrecoding
[KLAT75.
OSKI75, REDD76, SMTT80.
ZUE80,
WnT82]. Words in isolation
tend
to
be
pro nounced morecarefully,
suggesting
a more consistentacoustic
pattern[PARS86].
The
third
factor
concernsthe
issue
of small orlarge
vocabularies.
Small
vocabularieslimit
the
amount of
confusibility
[REDD76].
As
the
vocabulary
sizeincreases,
the
degree
ofsimilarity between
words
grows,
sothe
ability
to
distinguish
smalldifferences
needs
to
be
increased.
Computational
requirementsofsearch
procedures
also grow asthe
vocabulary
sizeexpands.
Finally,
asthe
size ofthe
222.
Extensibility
The
techniques
for
singlespeaker,
smallvocabulary,
isolated
word recognition systems are wellunderstood
[TTAK75, MART75,
WHTT75].
However
these techniques
are notlikely
to
workwell withlarge
vocabulary,
multiplespeaker,
continuous wordunderstanding
systems[REDD76].
Speaker depen
dent
isolated
word recognition systems with small vocabularies use templatematching
methods oflow-level
acousticpatterns,
wherethe
unit of recognitionis
aword,
or short utterance[REDD76,
ZUE80,
LEVI83,
PARS86].
An
unknown wordis
analyzedto
its
representative acousticpattern,
andthen
comparedto
patterns storedin
alexicon.
These
reference patterns are a result ofthe
speakerrepeating
the
vocabulary
one or moretimes
andstoring
the
acousticpattern,
in
effecttraining
the
system.
It
is
significantto
notethat there
is
adirect mapping
between
the
input
utteranceandthe
lexicon.
Extending
the
above approachto
large
vocabulary,
multiple speaker systems presents problems.The
principle problemis
that the
search space(using
acousticaltemplate
knowledge sources)
growstoo
large for
reasonableefficiency [REDD76].
An
acoustic patternrepresenting
one word requires560
bytes for
storage
(TTAK75].
A
2000
wordvocabulary
would require over one megabyte ofstoragespace.
As
the
vocabulary
grows,
the
lexicon
sizebecomes
cumbersome.Adding
duplicate
patternsfor
all
vocabulary
wordsto
accountfor
the
variability between
multiple speakerswould expandthe
searchspace
to
an unmanageable size.Additionally,
wordsin
continuous speechare affectedby
the
contextualinfluences
ofsurrounding
words,
sothe
lexicon
wouldhave
to
store all potential reference patternsreflecting
these
influences. It
would
take
10
million reference patternsto
accountfor
all possible7
digit
sequencesin
a10
wordvocabulary
[REDD76].
At 560
bytes/pattem
from
the
earlierexample,
overfive
gigabytes of storagewould
be
required.This is
unsuitableboth computationally
and
from
astorage
organizationstandpoint
It has been
suggested[WINS84,
WHrT76]
that
many
search problemsmay be
reducedby
using
abetter knowledge
representation.This
canbe
accomplishedby
noticing
that
spoken words are perceived as
a
successionofelementalsound unitscalledphonemes[WATE86,
SHOU80]. Categorized
asvowels,
liquids,
glides, stops,
fricatives,
affricates andnasals, there
areapproximately
40 in
the
English
represen-tation, ehminating
extraneousinformation
whflepreserving
that
whichis
important
[HYD
J.
mcewords average
10
phonemes[WHn76]
and require onebyte
ofstorage, a2000
wordlexicon
could
be
reduced
to
approximately
20
Kbytes.
A
phonetic representation providesa knowledge
source
that
isover an order of magnitude smaller
than
the
acoustic representation.Also,
if
onedesigns
a
talker-independent
phoneticanalyzer,
many
speakervariability
problems goaway
(not
dialect
problems,though).
223.
Previous
Systems
Speech understanding
systemsall useahypothesize-and-test
paradigmfor
the
recognitionproblem[WHn76.
SMTT80]. The
general processcanbe
guidedin
eithera top-downor predictivefashion
(as
was
typical
in early systems)
[WOLF77. LOWE80],
abottom-up
ordata
driven
approach,
or a mixtureof
both [LESS75]. The
top-down
approach usespragmatic,
semanticandsyntacticknowledge
sourcesto
guide
the
hypothesization
ofwords;
phrases andsentences,
based
ontask-dependent
knowledge
andgrammatical constraints.
Bottom-up
or"data-driven"
hypothesization
attemptsto
deduce
wordsbased
on acoustical representations
in
the
utterance.Both
predictive anddata-driven
methodshave
their
draw
backs.
As
task
domains,
vocabularies and acceptable grammaticalforms
increase,
the
predictivemethods can
become
overwhelmed with potential choices.On
the
otherhand,
if
the
acousticdata
become
morecorrupt
the
data-driven
approachwillhypothesize incorrect
words withoutbeing
able
to
recover.
Of
the
continuous word recognition systemsdeveloped in
conjunction withthe
ARPA
researcheffort
[KLAT76],
Harpy [LOWE80]
performed
best
(Le.,
meeting
the
ARPA
criteria).
All knowledge
sources
(semantic,
syntactic,
lexical,
phonetic,
andacoustic)
werecompiled
into
a15,000-state
transition
network.
A beam
searchtraversed
the
network(bottom-up)
looking
for
optimalsequences
ascompared
to the
utterance.A
major problem withthis
representation
wasits
rigidity.
Changes
to
any
knowledge
source as a result of
expanded constraints
(changes
in vocabulary
size,
number ofspeakers,
task
domain
and
grammar)
required a13 hour
re-compilation
ofthe
state
transition
network.One
shouldnotethat
Hearsay-n
[LESS75],
also
developed
atCarnegie-Mellon,
attemptedto
take
advantageof potentialparallelism
by
using asynchronous,
independent knowledge
sources(semantic,
syntactic,
lexical,
phonetic,
and
acoustic)
communicating
via a globaldata
structure calleda
blackboard.
Predictive
hypotheses
from
semantic and syntactic
constraintscould
be
usedto
verify
hypotheses
from data-driven
knowledge
sources,
and visa versa.At any
giventime
aknowledge
sourcemay
presentinformation
to
the
blackboard,
providing
anopportunity for
otherknowledge
sourcesto
be
activated.22.4.
Current System Architecture
This
thesis
is
part
ofa
speakerindependent
large
vocabulary,
continuous speechunderstanding
system under
development
atRXT. Research Corporation.
The
systemis primarily
data-driven
andis
void ofcomplex control structures such as
the
blackboard
approach ofHearsay-n.
The belief is
that
given accurate phonetic
transcriptions,
abottom-up
paradigmis
sufficientThis
viewis
sharedby
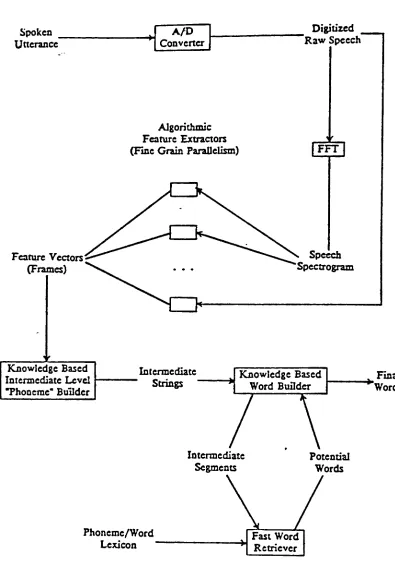
Figure 1
RTTRC
Speech Project
Software
Architecture
Spoken
Utterance
A/D
Converter
Digitized
"Raw
Speech
Algorithmic
Feature
Extractors
(Fine Grain
Parallelism)
(FFT]
Feature Vectors
(Frames)
Speech
Spectrogram
Knowledge
Based
Intermediate
Level
"Phoneme"Builder
Intermediate
Strings
Knowledge Based
Word
Buflder
Final
"Words
Intermediate
Segments
Potential
Words
Phoneme/Word
Lexicon
Figure 1
showsthe software architecture
ofthe
entirespeechprojectAn input
utteranceis
processed
to
produce
a speechspectrogram,
whichis
amapping
ofinput
signalfrequency
andintensity
over
time.
These
spectrograms preserve
all speakerdependent
information
in
additionto the
phoneticcharacteristics of
the
utterance[SMTT80].
Then
a set ofparallelfeature
extractorsbuild frames
offeature
vectorsconsisting
ofinformation
such asformant
frequencies,
pitch, total
energy
andzerocrossing
counts.The
purpose ofthis
data
compressionis
to
preserveinformation
that
is
mostclosely
associated with phonetic
content
These
feature frames
are subjectedto
aknowledge based
phonemebuilder
to
producestrings of undifferentiated phonemes(strings
withno wordboundary
markers).Through
the
process of
lexical
access,
words arehypothesized from
the
undifferentiated phonemestring using
the
string
comparisontechnique
ofDynamic Time Warping.
This
technique
is
the
focus
ofthe
thesis
andwill
be described in
greaterdetail
later.
In
the
final
stage,
syntactic and semanticknowledge
sources(natural language
analysis,
semanticnetworks)
usethe
hypothesized
wordsin
anattemptto
form
a syntactically
correct utterance and ascertainits
meaning.23.
Lexical
Access
The
proposedlexical
access processwill parse a sequence of phonemesrepresenting
an unknownutterance,
hypothesizing
all wordsin
the
utterancethat
are consistent
withthe
lexicon.
This
canbe
accomplished
by
comparing
reference patternsin
a phonemiclexicon
withthe
unknownsequence.However,
there
arethree
areas ofcomplexity
which preventthe
lexical
access procedurefrom
being
a simplelexicon
lookup.
Front
enderrors,
andthe
effects of phonologicalrecoding,
aretwo
areaswhichalter
the
symbolic representation ofan utterance.Ambiguity
that
resultsin
multiple pars23.1.
Error Conditions
The
front-end2of a speech
understanding
system will attimes
exhibit aninability
to distinguish
between
similarsounding
phonemes[PARS86].
As
a
result ofthis
confusibitity,the
string
ofphonemesrepresenting
the
unknown utterance will contain errors.Not
only does
this
create a major problemwhen
trying
to
match referencepatterns,
but any
speech segmentmay
representthree
different
types
oferrors
including:
insertion,
deletion,
or substitution errors.Finding
a methodthat
manages all threeerror
types
is
notsimple.Shown
below
areexamples ofthe three
errortypes.Insertion
Error
- chauffeur :Jofr-Jolfr
Deletion
Error
-hallway
:
lOIwe
-IOwe
Substitution Error
-tell
:
t e
1
-k
e
1
In
continuousspeech, there
are rulegoverned variationsin
pronunciation,
especially
acrosswordboundaries
[REDD76,
KLAT75,
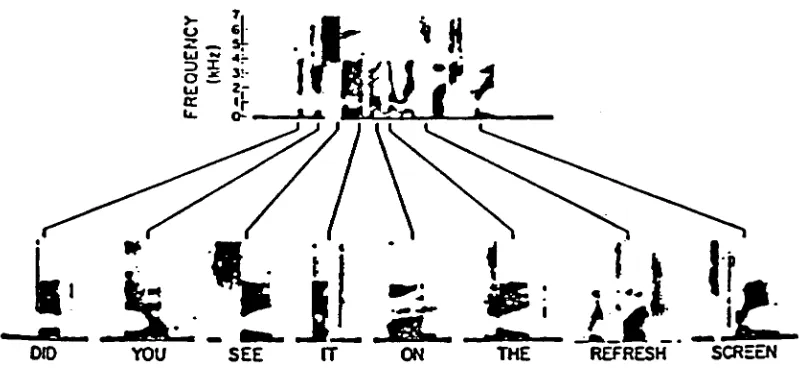
OSKT75]. Figure
2a
contains spectrograms ofthe
utterance"Did
yousee
it
onthe
refreshscreen?",
spokenboth
in
continuousspeech,
andasisolated
words.The
enlargedview
in figure 2b
showsthe significant
difference in
acoustic patterns when wordsare spokenin isola
tion
vscontinuous speech.These
variations are notrandomand canbe described
by
a set ofphonolog
ical
rules[KLAT75, OSKT75, COHE75],
following
the
generalform: W
->X
/
Y_Z,
meaning
that
W
becomes X in
the
environment
whereit is
precededby
Y,
and
followed
by
Z.
An
system componentsor modulesfrom initial
utteranceto theknowledge based
phonemebuilder
areknown
collectivelyasthe
"front
end"Figure 2a
Spectrograms
ofContinuous
vsIsolated Speech
i
'i
U 2."
ins
[image:17.511.43.464.409.613.2]ti^IiJELiMi
0J0
YOU
SEE
IT
ON
THE
REFRESH
SCREEN
Figure 2b Continuous
vsIsolated Speech
(enlarged)
Continuous
Isolated
Finding
lexical
search methodsthat
compensatefor
phonologicalreceding
has
notproven
to
be
asimple matter.
The
following
exampleshowsthe
condition whereaphonological ruleapplies withina
word
boundary.
Specifically,
the
"t"is
deleted
whenin
the
context of an "n"followed
by
anunstressed voweL
Phonological
rulesthat
apply
withinawordboundary
canbe
bandied
by
creating
analternative
base
forms in
the
lexicon.
identify
-*idenify
rule:
t
->0
: n_VA
moredifficult
problem arises whenworking
with phonological rulesthat
apply
across wordboundaries. The
phrase-Did
youseeit?,
illustrates
when an obstruent phonemeis
followed
by
a
palatal
phoneme,
the
actual realizationis
reducedto
a single anddifferent
palatal.Adding
anotherbaseform
to the
lexicon
for
the
word "you"(starting
withthe
palatal"j"),
could providefor
anerroneousrecognitionof
"you",
whenthe
utterancemay in fact be
"judge".
representation when spoken
in isolation
:did
yu siit
V
representationwhen spokencontinuously
:dldjdsidt
rules :
[dy]
-J
and[u4]
-9
Even
withthis
potentialproblem,
many
recognition systemshave built lexicons
where each wordmay
have
alternative representations generatedby
application ofphonological rulesto
its
dictionary
base
form
representation[WOLF77,
LOWE80.
LESS75, RUDN87,
WOOD75].
Lasdy,
one needsto
considerthe
potential problem of a single phoneticstring
with multipleinterpretations
as a sentence.Ambiguous
parsings canmap
a single phoneme sequenceinto different
strings of words.
The
nexttwo sentences
have nearly identical
phoneticrepresentations,
yetmap
ontotwo
entirely different
word sequences[COLE80].
Remember,
a spoken sentence often containsmany
wordsthatwere notintended
tobe heard.
Ream
ember, us poke cancenttenseoff
in
containsmenknee
wordsthatwereknot in
tenddid
tubebee
herd.
Matching
against entriesin
the
lexicon
willnot contribute
to
solving
this
problem.
There
is
aneed
for
syntax and
semantic
knowledge
to
differentiate
meanings[REDD76]. Incorporation
of syntaxand
232. Approaches To
String
Comparison
The
two
basic
approaches
to
string
comparisonin isolated
speechrecognitionareHidden Markov
Models
(HMM)
[LEVI83]
andDynamic
Time
Warping (DTW)
[1TAK75].
Both
methods operate onthe
generalprinciple ofdynamic programming (search for
optimalpaths)
[LEVI85,
KRUS83,
WATB81].
Although
both
approacheshave been
extendedinto
the
domain
of continuous word recognitionrWOLF77.
LOWE80, LOWE80,
BAKE75. MYER81, NEY84, LEVI87.
WATA86], it is
notcertainif
they
are extensibleto
large
vocabulary,
speakerindependent
continuous speechunderstanding
systems.232.1.
Hidden
Markov Models
Hidden
Markov
Models
(HMM)
useprobabilistictechniques to
model astochasticprocess(Mar
kov
sources)
that
is
notdirecdy
observable,
but
canbe
examined through a sequence of output symbols[RABI86].
Conceptually,
the
underlying
processcanbe
modeledwith acollection ofstates connectedby
transitions; from
these
transitions,
afinite
set of symbolsis
produced.Through
empiricaltesting
andobservation,
distributions
canbe
calculatedfor
the
probability
ofall statetransitions,
and alsofor
the
probability
of symbol output given a particulartransition
[JELI74, JELI76, RABI86,
LEVI83].
During
the
recognitionprocess,
asystemis
presented a sequence of symbols.The
objectwhosemodelhas
the
highest probability
ofgenerating
the
observed sequenceis
the
one recognized.In
simplestterms,
phonemes and words canbe
thought
of asthe
observed outputdependent
onthe
probabilistic changes(transitions)
in
acoustic signalsand phonemes respectively.Through
the
useof
training
utterancesandempirical observationof a system'sfront-end
performance,
onecanmodelthe
process ofphonemeand word
generation,
taking
into
accountfront-end
errors,
speakervariation,
coarti-culatory
and phonologicalreceding
effects.Words
withinthe
unknown utterance wouldbe
hypothesized
asthose
whose modelshad
the
greatestprobability
ofgenerating
the
observed phonemes[LEVI83,
BAKE33].
This
statisticalmodeling
technique
wasthe
focus
of anextensive
study in
automatic recognition of continuous speech
by
Jelinek
et al[JELI76]
atIBM's
Speech
Processing
The Dragon
systemby
Baker
[BAKE75]
incorporated
the
concept ofchaining
Markov
processesin
ahierarchical
fashion,
notonly
atthe
wordlevel,
but
atthe
phraseand sentencelevel
as welLThe
result was a
finite
state network ofMarkov
sourcesin
whichthe
recognition procedurelooked
for
anoptimalpathof
transitions that
wouldmostlikely
accountfor
the
observedutterance.2322.
Dynamic Time
Warping
Dynamic Tune
Warping
(DTW)
is
amethod ofsequencecomparison,derived
from
a
time
sampling
of somequantity
that
is
subjectto
variations.DTW
has
been successfully
usedin isolated
rrrAK75.
WAIB81]
and connectedword recognition[MYER81, NEY84,
WATA86].
In
most commonapplications,
the
unknowninput
utterance and reference utterance arerepresented as
two
time
varying
sequences of acousticfeature
vectorsdefined
[TTAK75, PARS86,
WAD381, NEY84]
as:Unknown
:A
=alf
a^
a3^..xti,
au
Reference
:B
=blt 62 by^-bj,
bN
Each
sequencedefines
the
axisofa matrixmapping
the
feature
vectors(per
unittime)
against oneanother.
At
each coordinateC(ij)
is
a measure ofdistance
ordissimilarity d(ij)
between
the
acousticfeatures. The
goalis
to
find
apath
(with index
k)
from
C(l,l)
to
C(MJ>1)
whosedistance D
is
minimal.This
cumulativedistance
canthen
be
used as adecision
criterionfor
recognition.
K
D(A3)
=Minimum
dO(k)j(k))
*=il
Ney [NEY84]
applied
the concepts
ofdynamic
programming
to the
above minimizationproblem,
and
concluded
the
following:
If
thebest
path goesthrougha gridpoint...,
then thebest
pathincludes,
asa portion ofit,
thebest
partial pathtodie
grid point...Therefore,
to
obtainthe
best
path,
one
only has
to
select
the
predecessorwiththe
rninimumtotal
dis
Following
the
constraintsthat the
warping function is
monotonic and continuous, a recurrencerelation
minimizing
the
number of points considered atany
onetime follows
[KRUS83,
NEY84,
PARS86.
SAK078].
Dfa.6>)
=Min
/(a,_i.
bj)
+w(a,,
0)
deletion of
aj
^(a,-!,
>y_,)
+w(a,-,fr;)
substitutionof ai
by
bj
d(aitbj^i)
+w(0,
bj)
insertion
of
bj
Weighting
coefficients are addedto
penalizefor
deletions,
substitutions andinsertions.
However,
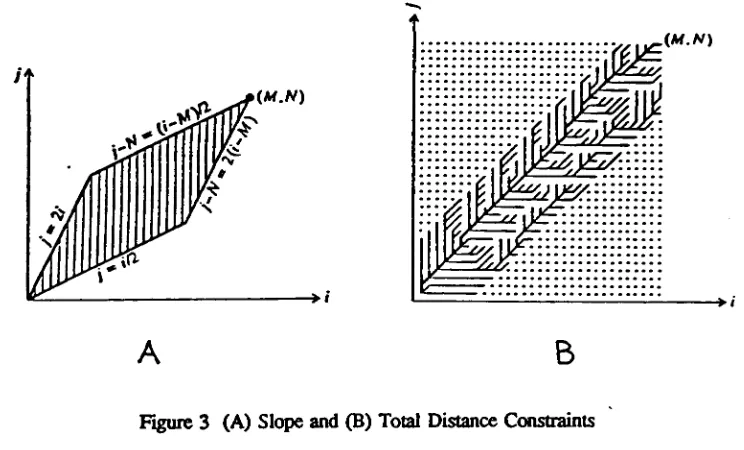
searching
allpossible pathsis computationally
expensive.Other
constraintsinclude
controlling
the
degree
ofslope allowed
in
the
warp,
andsetting
some maximum permissible pathdistance
help
to
controlthis.
As
shownin Figure
3
[PARS86],
both
constraints will prune pathsthat
would otherwise grow excessively large.
W.N)
(.M.N)
A
B
Figure
3
(A)
Slope
and(B)
Total Distance
Constraints
This
thesis
attemptsto
extendthe
aboveDTW
technique
using
strings of phonetic symbolsiphonemes)
to
representthe
unknownand reference utterancesinstead
ofacousticfeature
vectors.With
this
extension comestwo
basic
differences.
One is
that
although phoneme strings aretime
ordered,
each symbol
may
represent one or morearbitrary
units oftime.
Therefore
weare notstrictly warping
along
atime
axis.The
seconddifference
relatesto
acentral requirement ofthe
DTW
method:the
needfor
a measure ofdistance
ordissimilarity.
When
using
acousticfeatures,
these
distances
(commonly
a [image:21.511.73.445.286.511.2]straightforward.
This is
notthe
casewhenusing
phonetic strmgs.The
nitricthat
was usedfor
phoneticstring
matching
willbe discussed in
anupcoming
section.Once
this
measurehas been
determined,
the
proc^ofsequence compariswc^proceed.
There
is
no requirementfor
any
training
utterances(a
prioriknowledge) in
the
recognition process as with
Hidden Markov Models.
Figure 4
showstwo
examplesofthe
optimumpam tracewhenusing
the
DTW
method
to
compare aninput
utteranceto
areference pattern.Figure
4a
demonstrates
aninsertion
errorwhile
figure 4b
showsasubstitutionerror.The
valuesateach coordinateindicate
ameasureof
dissimi-larity
between
the
represented phonemes.Reference
Inp
ot
utUtfc
n
trance
m
d
K.
7
7
10
n
7
N.
0^-2-N
10
[image:22.511.43.463.228.446.2]d
10
10
10
Os
Fig. 4a
Reference
Input
Utterance
d
I
j
ud
o\
9
3
9
\
I
9
<N
9
9
d
0
9
*
9
Fig.
4b
2323.
Comparison
ofHHM
andDTW
The
Hidden
Markov Model is
a recognition methodthat
requiresthe
collection of empirical statistics
that
describe
the
responseofthe
recognition system'sfront-end. The determination
ofstates,
transi
tions,
and associated probabilitiesis
a complex optimization problem[JELI76,
LEVI83].
DTW,
onthe
other
hand,
needsonly
receivethe
stringsfor
comparison andthe
provisionofsomedistance
metric.The
principaldrawback
ofDTW is
the
large
number ofdistance
calculationsthat
are required.It
has been
estimatedthat
HMM,
which uses a simplerlikelihood
evaluationfunction,
requires an order ofmagnitude
less
computation
time
than
DTW
[LEVI83].
Also
noted wasthat
both
systemsachieved
It has been
notedthat
with afull
naturallanguage
there
is
aninfinite
numberofwordordercombinations
andassociated contextual
influences
[COHE75]. This implies
that
asthe vocabulary
size andtask
domain
become
larger,
the
number ofHMM
states neededto
model multiple wordforms in
the
lexicon
grows.
Since
DTW
methods
represent each reference word witha
limited
number ofbase
CHAPTER
3
EXPERIMENTAL
METHOD
3.1. Software Tools
The
principle partofthis
study
wasimplemented
in
COMMON
LISP,
due
to the predetermining
fact
that
the
projectis
being
developed
on aLISP
machine.COMMON LISP
is
one ofbut many
dialects
ofLISP
(LISt
Programming).
LISP
is
afunctional programming
language,
orientedfor
the
manipulation
symbols,
andthus
afavorite in AI
applications.Using
LISP
in
aninterpreted
fashion
allowedrapid
prototyping,
giving
the
programmer quick confirmation ofthe
successorfailure
ofcode.As
alist processing
language,
it
was well suitedin
manipulating
sequences oftokens
(phonemes).
COMMON LISP
wasdeveloped in
an effortto
combinethe
features
ofthe
otherdialects in
an optimalway,
andto
promotethe
commonality
among
diverging
newdialects
[STEE84].
Several utility
programs were writtenin
C
onaSun
Microsystem
workstation.The
reasonfor
this
is
that the
initial base form
phonemic representations werederived from
the
output ofthe
DECtalk
synthesis system which was
physically
separatefrom
the
LISP
environmentSeveral
smallfilters
transformed that
outputinto
the
basic LISP forms for
usein
the
lexicon.
Another
program wascoded
to
provide aninteractive utility
usedduring
construction ofthe
confusion matrix.It
enabledthe
operator to
adjustthe
phonemedistance
matrix and viewthe
effect on phoneme confusionprobabilities
asdistances
are varied.32.
Hardware Tools
The
projecttook
place onboth Texas
Instruments
Explorer1I
andB LISP
machines.
The Explorer
is
amicroprogrammed,
dedicated
LISP workstation, providing
a
comprehensive
AI
environment
for fast
symbolic processing.
Additionally,
the
Explorer
contains
aTMS 32020 Signal
Processor
Board
that
allows
low-level
feature
extractionto
proceedin
parallelusing four
independent
signal processors.These
characteristics allowthe
integration
oflow-level processing
withthe
high
level
control mechanisms
typical
in AI
applications.The primary difference between
the
Explorer
1
andB
is
that the
LISP
microcode on
the
Explorer
I is distributed
over a series ofintegrated
circuits,
whereasonthe
Explorer
B
it is
reducedto
a
singlechip.
An increase in
performance ofapproximately
four
to
onewasobservedfor roughly
equivalenttests
during
this study.
33.
Distance
andConfusion Matrices
Implementation
ofthe
warping
procedurein DTW
requires some measure ofdistance between
phonemes.
Predictable confusibility
patterns are exhibitedby
the
acoustic-phonetic(Le.,
front-end)
modules ofspeech recognition systems.
Ideally,
a comprehensiveinter-phoneme distance
matrixwouldbe based
uponthe
system'sfront-end
response characteristicsin classifying
allphonemes;
however,
vowelclassification
is
the
only
portion ofthe
front-end for
whichdata
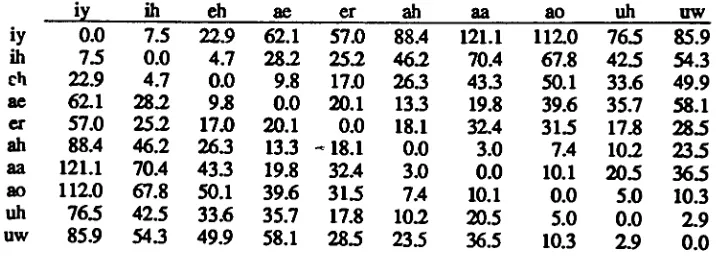
exists.Figure 5a
representsthe
responseof
the
vowel classification portionofthe
Research
Corporations front-end
[HILL87]
andFig
ure
5b
showsthe
corresponding
vowel vs voweldistances.
Distance data for
consonants were extractedfrom
studies ofhuman
confusibility
[SHEP80].
Studies
by
Miller
andNicely
[MTT.T.55]
demonstrated
that
humans
typically
confuse particular consonantsin
a consistentfashion.
In
the
Miller
andNicely
study,
listeners
were askedto
identify
stimulidrawn
from
a set of16 English
consonants.The
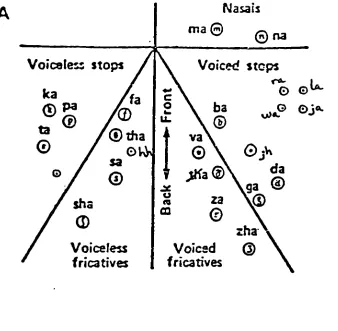
results(Figure
6a)
from Shepard's
[SHEP80]
multidimensionalscaling
analysis show clusters of consonantsthat
are similar andlikely
to
be
confused.Distances between
these
clusters were measured and areMVD
Output
iy
iy
ih
eh ae er ah aa ao uh uw95.8
4.2
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
ih
7.7
85.2
7.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
eh
0.0
12.0
85.9
2.1
0.0
0.0
0.0
0.0
0.0
0.0
Input
ae0.0
0.0
10.6
88.7
0.0
0.7
0.0
0.0
0.0
0.0
to
er0.0
1.4
1.4
0.7
94.4
1.4
0.0
0.0
0.0
0.7
MVD
ah0.0
0.0
0.0
0.0
0.7
88.7
7.7
2.8
0.0
0.0
aa
0.0
0.0
0.0
0.0
0.0
8.5
84.5
63
0.7
0.0
ao
0.0
0.0
0.0
0.0
0.0
0.7
7.0
85.9
42
2.1
uh
0.0
0.0
0.0
0.0
0.7
1.4
0.0
1.4
83.8
12.7
[image:26.511.92.454.70.200.2]uw
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.7
14.8
84.5
Figure 5a Vowel Classification
Response
-Confusion
matrixshowing
the
distribution
ofboth
correct andincorrect
choicesmadeby
the
MVD
recognitionalgorithmusing
parametersetconsisting
offormant's
FO,
Fl, F2,
F3.
iy
ih
eh ae er ah aa ao uh uwy
0.0
7.5
22.9
62.1
57.0
88.4
121.1
112.0
763
85.9
ih
73
0.0
4.7
28.2
252
46.2
70.4
67.8
423
54.3
ch
22.9
4.7
0.0
9.8
17.0
263
43.3
50.1
33.6
49.9
ae
62.1
28.2
9.8
0.0
20.1
133
19.8
39.6
35.7
S8.1
er
57.0
25.2
17.0
20.1
0.0
18.1
32.4
313
17.8
283
ah
88.4
46.2
263
133
-18.10.0
3.0
7.4
10.2
233
aa
121.1
70.4
433
19.8
32.4
3.0
0.0
10.1
203
363
ao112.0
67.8
50.1
39.6
313
7.4
10.1
0.0
5.0
10.3
uh
763
42.5
33.6
35.7
17.8
10.2
20.5
5.0
0.0
2.9
uw
85.9
543
49.9
58.1
283
233
36.5
10.3
2.9
0.0
Figure 5b. Vowel
Distances
-Measured
spectral
distances based
onformant's
[image:26.511.90.451.295.426.2]Figure
6a
Shepard's
Multidimensional
Scaling
(Masaij
Voiceless
stops
Voiced
steps
O
jo.
Voiceless
fricatives
m sh dh zfa
k
P
8.0
t
13.0
123
f
27XJ
20.0
31.0
-tfa
25.0
17.5
26.0
8.0
s
333
26.0
28.0
223
153
sh
41.0
35.5
293
403
323
19.0
V
553
473
55.5
30.0
303
31.0
48.0dh
643
563
63.0
393
39.0
363
513
10.0
i
z
70.0
62.0
66.0
483
46.0
383
48.0
23.0
15.0
zh
87.0
79.0
823
653
63.0
543
61.0
39.0
293
17.5
8
82.0
74.0
80.0
573
563
523
64.0
28.0
18.0
16.5
18.0d
86.0
78.5
85.0
603
61.0
583
71.0
31.0
22.0
25.0
25.5
9.0b
61.0
54.0
633
343
38.0
423
603
133
18.0
33.0
46.5
313
30.0
m
66.5
62.0
75.0
45.0
523
643
833
44.5
513
66.0
79.0
63.0
59.5
333
n
803
75.5
87.5
56.5
63.0
723
91.0
47.0
503
65.0
75.5
58.0
52J
34.0
163
Figure
6b. Consonant
Distances
-based
onShepard's MDS
of
Miller/Nicely's
[image:27.511.58.469.75.652.2] [image:27.511.96.434.85.416.2]The
reasonfor
using
distances from
the
aforementioned studies wasthat
algorithm performancecan
be
tested
andtuned
asdevelopment
proceeds withthe
rernaining
front-end
modules.Once
allmodules
arecomplete,
distance data
representing
actual system performance canbe incorporated in
the
distance
matrix.
One
problem encountered whenconstructing
the
distance
matrix wasthat
we weremissing
phonetic
distances:
(1)
relating
vowels andconsonants,
(2)
vowels notin
the
Research Corporation
study
and(3)
of consonants notin
the
Shepard
study.Based
ondiscussions
withDr.
Hillenbrand,
the
following
assumptions were madeto
accountfor
the
missing data:
Distance between
vowels and consonants(with
the
exception ofliquids
andglides)
was con sideredsufficiently large
to
assumea
confusionprobability
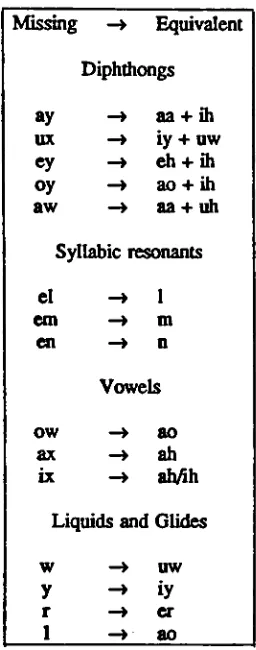
of zero.Diphthongs
canbe
thought
of astransitional
combinations ofsingular vowels(Figure 7).
Instead
ofapproximating
phoneticdistance
overthis
transition,
the
component vowelsof eachdiphthong
(for
whichdata
exists)
were substituted withinthe transcription
of a word eachtime
they
occurred.
Syllabic
resonants weretreated
similarly
to
diphthongs. Each
occurrence withina word was sub stitutedwitha similarconsonant
counterpart(Figure 7).
Distances for
singular vowels notin
the
Research
Corporation's
study
was providedusing ap
propriateadjustments
to
existing data for
similar
vowels(Figure
7).
Singular
consonants
notin
Shepard's
study
include
liquids,
glides,
flaps
andaffricates.
These
were
added
to suggested
locations
[HBX88]
in
Figure
6a,
andtheir
distances
approximated.
Liquids
and glides were uniquein
that
they
mapped
to
both
consonants and vowels(Figure 7).
Their
positions relativeto
otherconsonants
in Figure
6a,
andtheir
similarity
to specific
vowels,
Missing
-Equivalent
Diphthongs
ay
- aa +fli
ux
iy
+uwey
-> eh +ih
oy
- ao+ih
aw -* aa +uhSyllabic
resonantsel ->
1
em - m
en - n
Vowels
ow -+ ao
ax - ah
ix
-* ah/ihLiquids
andGlides
w > uw
y
-*y
r -* er
[image:29.511.204.332.47.372.2]1
aoFigure 7.
Mapping
ofMissing
Phonemes
to
Similar Phonemes based
onPerceptual
Confusion
In
additionto
simulating
the
front-end,
testing
requiresthat
errorsbe
simulatedin
away
that
approximates the
front-end
responsecharacteristics
from
whichthe
inter-phoneme distance
matrixis
derived.
Since
most ofthe
phonemedistance
data is based
on perceptual confusionbetween
phonemes,
there
is
a needfor probability data reflecting how
often aninput
phoneme
is
confused
with zero ormore
phonemes,
producing
insertion,
deletion
and substitution errors.Vowel
confusion probabilitieswere obtained
directly
from
the
vowel classificationstudy [HCLL87].
For
consonants,
however,
only
their
perceptualdistance
existed.IT
a relationbetween distance
and confusionprobability
could
be
found
to
approximatethe
vowelstudy
results, this
couldbe
appliedto the consonant
distances from
Shepard's
analysis[SHEP80]
ofMiller
andNicely's
consonant
confusiondata,
yielding
approximate
Examination
ofconfusion probabilities anddistances
from
the
vowel classificationstudy
yielded
an approximation
to
the
following
exponentialrelationship
(Base
=130):
.
base
Confusion
Probability
(
input
vsoutput)
=j-^
base*""" aOvowtbApplying
this
formulation
to
allphonemes,
it
wasdiscovered
that the
overallprobability
ofconfusionbetween
phonemes wastoo
low
anddid
not reflectwhatcouldbe
expectedin reality
[fflLL88].
Based
on
discussions
withDr.
Hillenbrand
andRobert
Gayvert
[fflLL88]
the
formula relating
phoneticdis
tance to
confusibility
wasmodified asfollows:
, . _ , . .
distance
Confusion
Probability (
input vs output)
=An
iterative
process ofadjusting inter-phousme distances
andrecalculating
the
confusion proba--bilities led
to the
creation of a second phoneme versusphonemematrix.The
confusion probabilitiesin
this
matrix werethen
usedin
error generationduring
test
data
creation.The final distance
andconfu
sion matricescan
be
found in
the
Appendix A
andAppendix
B,
respectively.3.4. Lexicon
Construction
The vocabulary for
this
study
wastaken
from
aUnited
States
Air Force
Cockpit
Natural
Language study [LEZ87].
The study
provides
avocabulary
of656
words,
their
frequency
ofoccurrence,
andthe
number oftimes
a wordis
preceded
orfollowed
by
other words.This information
may be
valuablein
determining
the
types
ofcontextual effects to expect
All
wordsfrom
the
Air Force study
wereinput into
atext-to-speech
synthesis
system(DECtalk2).
Output from
this
system
wasin
the
form
of asynthesized
utterance andphonetic
transcription
of eachword
using Digital
Equipment Corporation's
symbol
setWords
whose
auditory
output
did
not
lately
reflect agenerally
accepted
pronunciation werecorrected.
The
entire transcriptipn output wasreviewed
for
correctness,
with special attentionto those
wordsthat
were pronouncedincorrecdy.
The
transcriptions
werethen
converted
to the
Carnegie-Mellon
University
phoneticsymbolsetwhichis
usedin
conjunction with otherongoing
projects
atthe
RTT Research Corporation.
Appendix
C
showsa comparison of
the
symbols usedin both
the
DEC
andCMU
symbolsets.For
each wordtranscribed,
alexicon entry
wasconstructedcontaining
the
transcriptionlength,
the
transcription,
andthe
English
representation ofthe transcribed
word.These
entries(see
Appendix
E)
are grouped
based
on word-initialphoneme.
Placement
withinthe
group is in
descending
order ofphoneme
count
yielding
the
longest
reference patternfirst
whenany
particulargroup is
accessedduring
the
search procedure.The
significance
ofthis
willbe
explainedlater. Homonyms form
a singlelexical
entry
with multipleEnglish
representations.Words
withmultiple,
but generally
accepted pronunciations (eg. hostile:
hh
aa st
ay
I
vshh
aa st el),
aregivenalexical
entry for
eachpronunciation.33. Test Data Creation
The Air Force
Cockpit Natural Language study
[LIZZ87]
served asthe
source oftest
utterancesto
use asinput
stringsfor
the
DTW
process.A
setof42
test
phrases
was selectedfrom
the
study
that
combined a wide
variety
of words availablefrom
the
lexicon. The
averagelength
of phonetictranscrip
tion
overthe
42
phrases was26.
Test
phrases weretranslated
first
to their
phonemic representationswith no
errors,
allowing
somebenchmark
performancelevels
to
be determined.
After this,
anincreas
ingly
large
percentage of errors wasinduced into
the
input
strings.It is important
to
notethat
errorswere simulated
in
a mannerthat
accurately
reflectedthe
simulatedfront-end
responsecharacteristics.
Therefore,
a
key
componentin
the
errorgeneration process wasthe
phoneme confusion matrix.Using
this matrix,
the
following
method would generatethe three
different
errorstypes,
at some userdefined
percentage
level (for
eachtype),
and at sometotal
error rate.While
advancing
through
a phoneticinput
string,
andbased
onthe total
errorrate,
a randomnumber generator selected
the type
of error(substitution, deletion,
orinsertion)
to occur
at a givenone-to-one
into
the
output sequence.A
deletion
error resultsin
the
phoneme atthat
currentlocation
being
dropped from
the
output string.If
a substitution erroris
selected, the
phoneme atthe
currentinput string
location indexes
into
the
cifurionmatrix,
andbased
ontte
phoneme,
another phonemeis
chosenfor
inclusion
into
the
outputstring.Generation
of
insertion
errorswould also use
the
error matrix.The input
phoneme wouldindex
into
the matrix,
and
based
onit's
confusionprobabilities, aphoneme would
be
selectedfor
insertion
into
the
outputphoneme string.Error
types
were assumedindependent
sinceit
is
not clearhow,
orif
these
error
types
areinterre
lated.
Studies
atIBM
[JELI76]
showedthat
in
mostcases,
substitutions accountedfor
the
majority
(80%
to
90%)
oferrors,
followed
by
deletions
andinsertions.
Therefore,
this
study
concentratesonthe
successof
the
wordhypothesis
processusing
substitution errors primarily.Appendix
D
containsthe
setof
test
42
test
phrases with10%
substitutionerrorsinduced.
3.6.
Dynamic
Time
Warping
Process
3.6.1. Constraints
andConsiderations for
DTW
This study
usedthe
Dynamic Time
Warping
technique
for
the
hypothesis
procedure.As
previously
described,
DTW
provides a methodto
modela
warping function
that
mapstwo
speech patternsonto one another.
This mapping
or alignmentis
considered optimal whenthe
function
reachesa
minimum value.
This function
value canbe
usedas abasis for
recognition.Word
hypothesis
involves
comparing
phonemic representationsof wordsin
alexicon
to the
phonemic representation of an unknown
utterance,
looking
for
those
wordsthat
have
anoptimalalignment(minimum warping
function)
in
consecutive
time intervals
notto
exceed some giventhreshold.
A
majorfactor
that
affects system performanceduring
DTW
is
the
value ofthe
minimumdis
tance
threshold.
Too low
a value reducesthe
tolerance
for
errors andresults
in
the premature
rejectionof
a
potential reference-to-unknown match.Too high
a valuewillresult
in
the
acceptance
ofincorrect
matches and
the
increased
consumption of computationalresources.
A
benchmark
threshold
valuemust
first be
established witherror-free
input
patterns.Note
that
whencomparing
anerror-free
unknownto
a
- a
basis for rejecting
the
reference.
This
establishes aninitial
threshold
for testing
purposes.As
the
threshold
for
rejectionis
raised,
it is
expected that
beyond
somelimit
the
ratio ofincorrect
hypotheses
to
correct ones willincrease.
An
optimum valuefor
error-free patterns providesastarting
pointfrom
which
to
investigate
ths
effect of a minimumdistance
threshold
onDTW
performance(ratio
ofincorrect hypotheses