Theses
Thesis/Dissertation Collections
1989
The introduction, demonstration and evaluation of
a new typeface identification system
J. Ames Parsons
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion
in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact
Recommended Citation
by
Ames Parsons
A
thesis
submittedin
partialfulfillment
ofthe
requirements
for
the
degree
ofMaster
ofScience
in
the
School
ofPrinting
Management
andSciences
in
the
College
ofGraphic Arts
andPhotography
ofthe
Rochester Institute
ofTechnology
May
1989
Thesis Advisor:
Accordingly
I
wishto thank the
following
for
their
help:
Professor
Archibald
Provan
for acting
asmy primary
thesis
advisor,
for
allowing
meto
virtually
monopolize(for
months)
the
Xerox
Star
system,
for
providing
the
fundamentals
uponwhich
this
thesis
is
based,
andfor providing
copious goodcheer, patience,
andsupport;
Professor Frank
Cost for
acting
asmy
researchadvisor,
andfor
designing
andtesting
the
TYPE-ID
computerprogram;
Mr. Paul
Swift,
Director
ofthe
Graphic
Arts Division
ofthe
RIT
Research
Corporation,
for sponsoring
this
project,
andfor
acting
asmy
thesis
advisor;
Mr. David
Pankow,
Curator
ofthe
Cary
Library,
for providing
me with
innumerable
referencesources;
Professor
Emery
Schneider
for allowing
me andmy
helpers
to
use
the
typesetting
equipmentin
the
Phototypesetting
Lab;
Professor Marie Freckleton
for
keeping
the
lab
open;
Ms. Helga
Birth,
Librarian
ofthe
Technical
andEducation Center
for
the
Graphic
Arts,
for her
help
andsupport;
Mr. John
Winslow,
President
ofBirdlow
Associates,
Inc.
(Maplewood,
NJ)
andJeff Wasilko
for
their
typesetting
help;
Tim & Maude
Kent,
Rob
Kent,
Mom
andDad,
James
Hamilton,
Mary
Lou
Bulger,
Sean
McElveney,
Jason
Rosenberg,
and variousprinting
graduate studentsfor
their
help
in
testing
the
various generations of
the
TYPE-ID system;
Rick
Schmidle
andMark DuPre
and"the
gang"
at
the
T&E
Center
for
their
unbridledhumor
andwit;
andLIST
OF TABLES
viABSTRACT
1
CHAPTERS
1. Introduction
1
Notes
3
2. Literature Search
4
Notes
8
3. Theoretical Basis
ofStudy
9
The Panose
Problem
9
The Pass Option
10
The Null Digit
11
4. Hypothesis
13
5. Definitions
14
6.
Methodology
16
Conclusion 3
20
Conclusion 4
21
Conclusion 5
24
Conclusion 6
25
Conclusion 7
27
Conclusion 8
28
Conclusion 9
28
Conclusion 10
29
Conclusion 11
29
Conclusion 12
29
8.
Summary
31
9.
Suggestions for
Further Research
33
Suggestion
1
33
Suggestion 2
33
Suggestion 3
36
Suggestion 4
39
Notes
40
BIBLIOGRAPHY
41
APPENDICES
A.
The Panose
Number
Generator
44
B.
The Panose
Classification Index
60
C. Samples
ofPanose Specimen Pages
64
D. TYPE-ID Profile
Generator
71
E.
Typeface
Specimens
149
G.
Typeface
Nomenclature
216
Notes
223
H. Typeface Classification
Systems
224
Theodore
Low De Vinne
(1900)
225
F. Thibaudeau
(1903)
225
Legros &
Grant
(1922)
226
Beatrice Warde
(1935)
227
Johnson &
Berry
(1953)
227
Maximilien Vox
(1954)
228
Deutsche Industrie Norman
(DIN)
System
(1959)
. .228
ATypI
(1961)
230
The British Standards System
(1965)
231
Alexander
Lawson
(1971)
231
Marshall
Lee
(1979)
232
Rookledge & Perfect
(1983)
232
Martin
Solomon
(1986)
234
Archibald Provan
(1989)
234
Notes
240
I.
Typeface Identification
Systems
241
The
galMethod
242
Rookledge's Earmark Tables
244
The 100-ems Method
246
The Panose System
248
Notes
249
TABLE 1
Collected Data
202
TABLE 2
Average
Search
Yield
andProbability
ofSuccess for
Each
Sequence
211
TABLE 3
Average Search Yield
andProbability
ofSuccess for
Any
Search Based
onOne
Sequence
212
TABLE 4
Probability
ofSuccess for
Searches Based
onOne
orMore
Sequences
213
TABLE 5
Average Search Yields
for
Searches Based
onOne
orMore
Sequences
214
TABLE 6
Average Number
ofSequences Needed
to
Narrow
the
List
to
One
andthe
Probability
ofSuccess
withTYPE-ID
215
Graphic
communicators,
including
typographers,
designers,
anddescriptive
bibliographers,
are often called uponto
identify
typefaces.
Since
there
arethousands
oftypefaces
availablein
the
marketplacetoday,
it is
unlikely
that
any
onedesigner,
typographer
orbibliographer
can namethem
all at sight.Accordingly,
there
is
a needfor
atypeface
identification
system.The
purpose of
this
paperis
to
introduce,
demonstrate
and evaluate such asystem.
An
identification
system calledTYPE-ID
wasdeveloped
andtested.
Two
newprinciples
the "pass
option"and
the
"null
digit" wereintroduced. A
sequence of questions was written
for
a number ofdifferent
characters.An
index
or"database"
of
50
typefaces
was created.The
sequences anddatabase
wereincorporated
into
a computer program.Subjects
tested the
system
1000
times.
Based
onthe results,
it
appearsthat the
system works.For
searches ofthe
Graphic
communicators are often called uponto
"identify"(ie.,
determine
the
specific commercial nameof)
typefaces.
To
wit:(1)
the
typesetter
whohas
been
instructed
by
his
clientto
"match" a particular specimen oftype
must
first determine
the
name ofthe typeface
in
whichthe
specimen wasset;
(2)
the
designer
whohas happened
upon a sample of a new orunfamiliar
typeface
(while
perusing
aperiodical,
perhaps)
mustfirst
determine,
before
he
can usethe
typeface
in
his
nextlayout,
the
name ofthe typeface
in
whichthe
sample wasset;
or(3)
the
descriptive
bibliographer! who wishesto
describe
the type
of a particularbook,
must,
among
otherthings,
determine
the
name ofthe typeface
in
whichthe
book
was set.
There
arethousands
oftypefaces
availablein
the
marketplacetoday.
It is
unlikely
that
any
onedesigner,
typographer
orbibliographer
canidentify
them
all.Indeed,
Geoffrey
Dowding
writesin The
History
ofPrinting
Types:2It
is,
ofcourse,
no part ofthe typographer's
job
to
recognizeand name at sight
any
specimen oftypeface
placedbefore him.
Such
is
animpossible
task
and wouldonly
be
demanded
by
oneignorant
ofthe
subject.3Because
it is
an"impossible
task"to
identify
every
specimen oftype
at sightany
type
is
Accordingly,
the
purpose ofthis
paperis
to
introduce,
demonstrate,
andevaluate
the
first step
in
the
development
of a newtypeface
identification
1.
G. Thomas
Tanselle
suggestsin
his
article entitled"The
Identification
ofType Faces in Bibliographic
Description"(The
Journal
ofTypographic
Research,
October
1967,
p.428)
that
a"precise
description
ofthe type
usedin
abook
is
a proper part ofthe total
bibliographic description
oftnat
book."
Should
this
become
the
prevailing
view,
there
wouldbe
a greatdemand
for
atypeface
identification
system.Particularly
from
those
selectedto
identify
the
type
in
allthe
books
in
the
Library
ofCongress.
2.
Geoffrey
Dowding,
The
History
ofPrinting
Types. (London: Wace &
Co.,
1961).
xxiv.The
typeface
identification
systemthat
has
been
developed
in
conjunctionwith
this thesis
is
based,
in part,
onthe
"Panose
System" as presentedby
Benjamin Bauermeister in The Panose System: A Manual
ofComparative
Typography2
The
specifics ofThe
Panose System
arediscussed
below.3
In
orderfor
the
user ofthe
Panose System
to
identify
atypeface, he
mustdetermine
its
"seven-digit
classificationnumber."
This is
accomplishedby
using
the the
supplied"number
generator."The
number generatoris
essentially
a series of7
questions.Each
question"generates"
one
digit.
The
first digit
ofthe
seven-digit numberthe
user must generate correspondsto
serif style.Accordingly,
question1
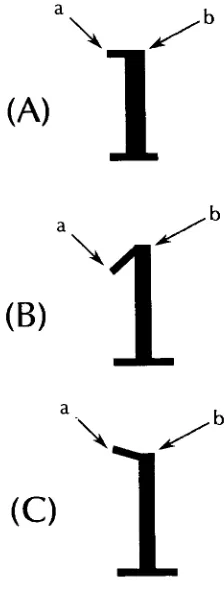
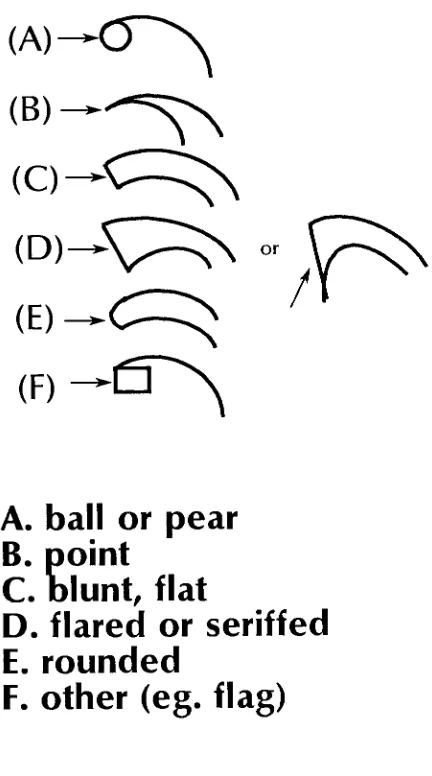
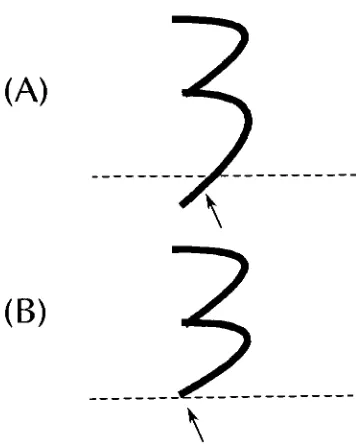
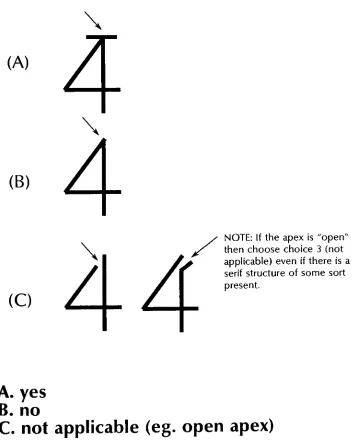
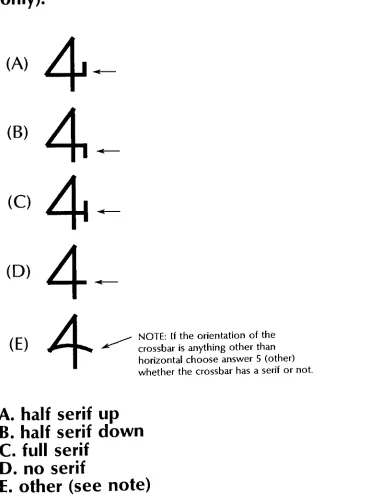
asks:QUESTION
#1:
What
kind
of serif structuredoes
yourtypeface
have?
1.
cove serif2.
square serif3.
square cove serif4.
thin-line
serif5.
exaggerated serif6.
triangle
serif7.
square normal-end sans-serif8.
square perpendicular-end sans-serifAppendix
A)
that
his
unidentifiedtypeface
has
"cove
(answer 1
above),
then the
first digit
ofhis
seven-digit numberis
"1."If
the
usershould
determine
that
his
unidentifiedtypeface
has
"square
serifs"(answer
2)
then the
first digit
ofhis
seven-digit numberis
"2."In
short, the
numbercorresponding
to the
answer selectedbecomes
the
first
digit
ofthe
seven-digit
number.The
seconddigit
the
user must generate correspondsto
"proportion."Accordingly,
question2
asks:QUESTION #2:
What
kind
of proportiondoes
yourtypeface
have?
1.
old style2.
modern3.
even width4.
expanded5.
condensed6.
monospacedIf
the
user shoulddetermine
that
his
unidentifiedtypeface
has
"old
style"proportion
(answer
1)
then
the
seconddigit
ofthe
seven-digit numberis
"1."If
the
user shoulddetermine
that
his
unidentifiedtypeface
has
"monospaced"
seven-selected
is
the
seconddigit
ofthe
seven-digit number.This
number-generating
procedureis
continued until all sevendigits
aregenerated.
Once
the
seven-digit numberhas
been
generated, the
"classification
index"(see Appendix
B)
comesinto
play.If,
for
examplethe
userhas
generatedthe
number
1133122,
he
willfind,
in
the
numerically
ordered classificationindex
that
1133122
correspondsto
"Baskerville."Therefore,
the
usermay
conclude,
if
he
has
usedthe
number generatorcorrectly,
that the
name ofhis previously
unidentifiedtypeface
is
"Baskerville."To
test the
Panose
system, two
subjects were askedto
try
to
identify
5
typefaces
each.Both
subjects concludedthat the
systemis
useless and gaveup
in
frustration.
The
principal problem withthe
systemis
that the
questions usedto
generate
the
seven-digit number aredifficult
to
answer.Indeed,
somequestions are impossible4
to
answer withcertainty
for
some typefaces.For example,
the
following
problems werereported,
among
others,
by
test
subjects
attempting
to
answerthe
first
question5:(1)
the
typeface"Baskerville,"
which
according
to the
classificationindex
has
"cove
serifs"
appeared
to the
usersto
have
"thin-line"or
"triangular"
typeface; (3)
the
typeface
"Bernhard
whichaccording
to the
classification
index
is
a "thin-line"serif,
appearedto
have
"triangular serifs";
The
typeface
"Goudy
Old
Style"has,
according
to the
classificationindex,
"cove
serifs,"but
"Schneidler,"whose serifs resemble
Goudy's,
is
saidto
have
"exaggerated serifs";
and(5)
the typeface
"Letter
Gothic,"which
appears
to
be
a sans serifface,
is classified,
inexplicably,
as a "thin-line"serif
face.
Similar
difficulties
were encountered with eachPanose
question.None
couldNOTES
1.
See
Appendix I
for
discussion
of othertypeface
identification
systems.None
ofthese
systemsis
particularly
releventto this
discussion, however,
and none of
them
work.2. Benjamin
Bauermeister,
A Manual
ofComparative
Typography: The Panose
System (New York: Van
Nostrand Reinhold
Co.,
1988).
3.
See
Appendices
A,
B
andC
for full
description
ofthe
Panose System.
Appendix A
containsthe
Panose
Number
Generator,
Appendix
B
containsthe
Panose
Classification
Index,
andAppendix
C
contains samplePanose
specimen pages.
4. This
statementthat
"some
questions"of
the
Panose
system are"impossible
to
answer with certainty"is impossible
to
prove(and
indeed,
any
statement which saysthat
something
is
"impossible"is itself impossible
to
proveincluding
this
statement).Accordingly,
the
authoris
hesitant
to
support
his
troublesome
statement with even a single examplebecause any
such example would not
disprove
the existence,
or possibleexistence,
ofsomeone who can answer
the
Panose
questions with certainty.Perhaps
the
phrase
"the
questions areimpossible
to
answer"should
be
replaced withthe
phrase"in
ouropinion,
after exhaustivetesting
andresearch, the
questions are
extremely difficult
to
answer withcertainty for
eventhe
mostexperienced
typographers."
However,
in
the
interest
of wordeconomy,
the
word
"impossible"
will continue
to
be
usedindiscriminately,
and perhaps abit
recklessly, throughout the text.
5. The
specific problemsthat
are mentionedbelow
need notbe
understood substantively.The important
thing
is
that there
were problems.However,
those
wishing
a more substantiveunderstanding
oftne
Panose
questionsand answers
may
referto Appendix A
where aFull
description
ofthe
Panose
Number Generator is
presented. Appendix
B
wherethe
Panose Classification
Index
is
presented,
andAppendix
C
where some samplePanose
typeface
specimens pages are presented.
Furthermore,
a number ofthe
basic
The
newtypeface identification
systemthat
has been developed
in
conjunction with
this thesis
is
based
onthe
Panose System
(discussed in
Chapter
2) but has
someimportant
modifications.Below is
adiscussion
ofthese
modifications.The Panose Problem
The
problem withthe
Panose
system as reportedin Chapter 2 is
that:
The
questions and answers usedto
generatethe
seven-digit classification number aredifficult
to
answer.Indeed,
some questions arenearly
impossible
to
answer withcertainty for
sometypefaces.
At
first
glance,
one mightthink
that the
solutionto this
problemis
to
changethe
questions sothat
they
canbe
answered with certainty.After
investi
gation,
however,
it
was concludedthat
this
is prohibitively
difficult
to
do.
Typographic
details
are so subtle and variedthat
it is
difficult,
if
notimpos
sible,
to
design
a set ofquestions,
or even a singlequestion,
that
is
applicable
to,
and answerablefor,
every existing
typeface.
Further,
whatmay
be
a"perfect"
question
today
may
notbe
a perfect questiontomorrow
since newdesigns
areconstantly
being
produced(many
of which willundoubtedly
be
The
solutionto the
Panose
problem,
therefore,
is
notnecessarily
to
drop
oralter
imperfect
questions(although
each question shouldbe
made asperfect as
possible)
but
ratherto
make provisionsfor imperfect
questions.The Pass
Option
A
system whichincorporates
the
"pass
option"is
one which allowsthe
userto
"pass,"(ie.,
not answer) questionshe
cannot answer with certainty.The Panose
systemdoes
nothave
a"pass
option"its
useris
requiredto
answer
every
question.If
he
answers "incorrectly"(ie.,
differently
from
the
compiler of
the
classificationindex),
his
search ofthe
classificationindex
will endin
failure.
For
example, the
user ofPanose
whohas
generatedthe
number2331221
for
Typeface
"A"may have had
difficulty
in
answering
the
first
question.Therefore,
the
first
digit,
a2,
may
nothave
been
generated with certainty.If
the
compiler ofthe
index
had
previously
generated a "3"for
the
first
digit,
Typeface A
wouldbe listed
in
the
classificationindex
as:3331221. In
this
case,
the
user's search ofthe
classificationindex
would yield either(1)
notypefaces,
or(2)
alist
of one or moretypefaces
whichdoes
notinclude
the
If,
onthe
otherhand,
the
user were allowedto
pass on question1,
he
would generate
the
following
seven-digit numberfor Typeface
A:
P331221,
where "?" equals
"pass".
Now,
if
the
classificationindex
is
storedin
acomputer,
the
user can performa "search" of
the
index
for
the
list
oftypefaces that
have
the
samelast
sixdigits
ashis
unidentifiedtypeface.
The
first digit
(where
the
userpassed)
would
be
ignored. Such
a search would generate alist
oftypefaces that
does
include
the
name ofthe
user's unidentifiedtypeface
despite
the
fact
that the
user was unableto
answerthe
first
question.The Null Digit
A
system whichincorporates
the "null
digit"is
one which allowsthe
compiler of
the
index
to
"pass" onthose
questionshe
is
unableto
answerwith certainty.
If
the
compilerhas
generatedthe
following
numberfor
Typeface
"B":
3331221,
but had
difficulty
in answering
the
secondquestion,
the
seconddigit,
a3,
may
nothave
been determined
with certainty.If
the
user shouldassign a "2"
to the
seconddigit,
his
search ofthe
index
would yield either(1)
no typefaces or(2)
alist
oftypefaces
whichdoes
notinclude
his
If the
compiler wereinstead
to
enter a"null
digit" asthe
seconddigit,
the
profile of
Typeface
B
as enteredin
the
computerdatabase
wouldbe:
3#31221,
where "#" equals"null
digit."The
nulldigit
is
essentially
an"all
of
the
above"response,
ie.,
it
matchesany
numberinput
by
the
userfor
that
digit.
Therefore any
ofthe
following
seven-digit numbersinput
by
the
user will
be
consideredto
matchTypeface B:
3131221
3431221
3731221
3031221
3231221
3531221
3831221
3P31221
3331221
3631221
3931221
PPPPPPP
The
location
ofthese
nulldigits
canbe determined
by
testing.
For
example,
each question
for every
typeface to
be
enteredinto
the
index
couldbe
answered
by
a number of compilers.Where
the
compilers agree on ananswer, the
answeris
enteredinto
the
index. Where
they
disagree,
a nulldigit
is
entered.In
this way,
allthe
questionsthat
arelikely
to
"cause
trouble"
Chapter 4
HYPOTHESIS
Statement
ofHypothesis: The
prototype ofthe typeface
identification
systemthat
has
been
developed
in
conjunction withthis thesis
will enableits
userto
generate alist
ofthe
specific commercial names of one or moretypefaces
which
includes
the
name ofthe
user's unidentifiedtypeface
providedthat
the
unidentifiedtypeface is
one ofthe
50
typefaces
listed
anddisplayed
in
Chapter
5
DEFINITIONS
TYPE-ID
The
name ofthe
prototype ofthe
newtypeface identification
system presented
in
this
paper.FULL PROFILE
-The 76-digit
description
of a
typeface
whichis
determined
by
answering
allthe
questions ofthe
76-question
profile generator.PROFILE GENERATOR
The 76
questions usedto
generatethe
profile of atypeface.
These
are presentedin
printedform in
Appendix
A
and are alsoentered
into
the
computer program.These
questions aredivided
into
sequences.
SEQUENCE
-A
related
"series"
of questions.
Sequences
have
been
writtenfor
the
following
characters: capsA, C,
G,
J, L, M, P, Q, R,
T
andW;
lowercase
a, e,
f
andg;
figures
1, 2,
3
and4;
andthe
period punctuationmark.
SEQUENCE
PROFILE
-The
numericaldescription
of atypefaces
whichis
determined
by
answering
the
questionsfor
a specific sequence and whichis
"n"
digits
in length (where
n =the
number of questionsin
the
sequence).SEARCH
ARGUMENT
--The
series of one or more sequence profiles uponSEARCH
To
comparethe
search argument of an unidentifiedtypeface
to
the
profiles of allthe typefaces
in
the
database.
DATABASE
~The
portion ofthe
computer program where
the
full
profiles ofspecific
typefaces
are stored.LIST
The list
oftypefaces
found
by
a search which satisfiesthe
searchargument of
the
unidentifiedtypeface.
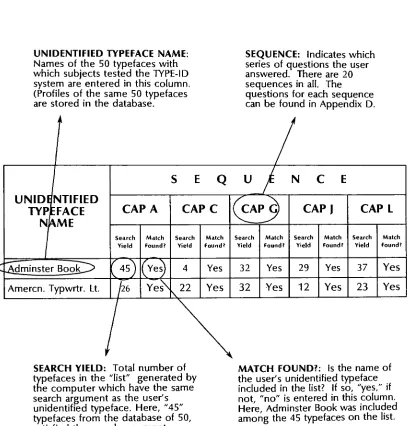
SEARCH YIELD
-The
number oftypefaces
in
the
list.
MATCH
-A
match
has been found
whenthe
name ofthe
user'sunidentified
typeface
appears onthe
list.
SUCCESS
--Synonym
of"match."
USER
--Person
who attempts
to
identify
atypeface
using
the
TYPE-ID
system.
COMPILER(S)
--Person(s)
who createthe
TYPE-ID
database.
COMPUTER
PROGRAM
-The
softwarein
whichthe
TYPE-ID
systemis
Chapter
6
METHODOLOGY
In
orderto
test
the
hypothesis
presentedin
Chapter
4,
the
following
stepswere
taken:
(1)
A
sequence of questions was writtenfor
each ofthe
following
characters:caps
A,
C, G,
J, L, M, P,
Q,
R,
T,
W;
lowercase
a, e,
f,
g;
figures
1, 2, 3, 4;
andthe
period punctuation mark.The
questions canbe found
in Appendix A.
These
questions servethe
samefunction
asthe
Panose
number-generating
questions as each
is
designed
to
generate onedigit
ofthe
"profile" of atypeface;
(2)
An
index
or"database"
of
50
typefaces
was created.This
database
servesthe
samefunction
asthe
Panose
classificationindex.
Here,
however,
eachdigit
for
eachtypeface
enteredinto
the
database
wasdetermined
by
three
compilers.
Where
they
agreed on adigit,
the
digit
was enteredinto
the
database.
Where
they
disagreed,
a nulldigit
was enteredinto
the
database;
(3)
The
sequences andthe
database
wereincorporated into
a computer program which allows
the identification
processto
be
completed with expediency.
Specifically,
the
computer program allowsthe
userto:
(a)
select asequence
(the
user cannot accessindividual questions,
he
must access anentire
sequence);
(b)
generate a sequence profile(which is
"n"digits
in
length
where "n"the
sequenceprofile,
including
passes,
into
a"search argument";
(d)
searchthe
database
for
the
"list" oftypefaces
that
satisfy
the
searchargument;
and(e)
repeatthe
process with another sequence(or
sequences)
andimmediately
cross-referencebetween
them;
(4)
Subjects
tested the
system1000
times.
For
eachtest,
a subject selectedan unidentified
typeface
sample andthen:
(a)
selected a sequence andanswered
its
questions;
(b)
enteredthe
sequence profileinto
the
computerwhich
translated the
sequence profileinto
a searchargument;
(c)
initiated
asearch of
the
database;
(d)
countedthe
number oftypefaces
in
the
list
generated
by
the
computer(thus
determining
the
"search
yield");
and(e)
answered
the
question"was
the
name ofthe
unidentifiedtypeface
included
in
the
list?";
(5)
The
subjects recorded their results ondata
collection sheets similarthose
presented
in Table
1,
Appendix
F;
and(6)
From
the
data
collected, the
system was evaluatedboth mathematically
Chapter
7
RESULTS AND
CONCLUSIONS
The
results ofthe
experimentation performedin
conjunction withthis thesis
are presented
in Tables 1
through
6 in Appendix
F. The
conclusionspresented
below
arebased
onthese
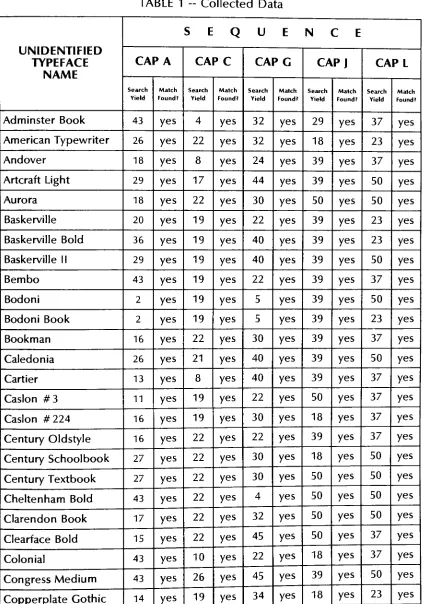
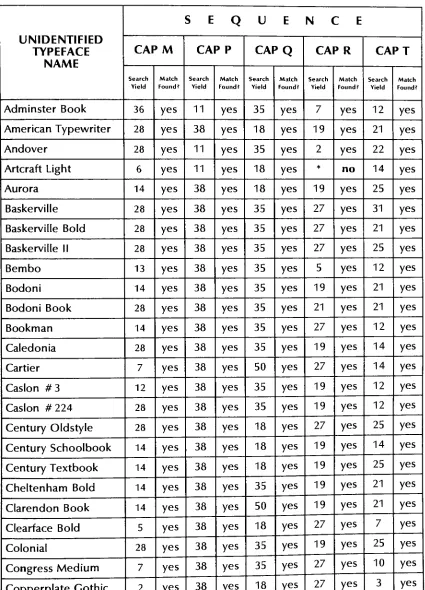
results.Conclusion 1
50
searches ofthe
database
were performed with each ofthe
20
sequencesof which
TYPE-ID
is currently
composed(the
rawdata
as collectedby
the
test
subjects canbe found
in Table 1).
For
each ofthe
20
sequences,
aprobability
of success(Pseq)
wasdetermined
which
is
equalto:
Pseq
=S/N
x100where "S"
is
the
number of successes recordedby
subjectsfor
the
specificsequence
in
question(these
valuesmay be found
in Table
2,
column5);
and"N"
is
the
number of searches performedfor
that
sequence(taken
from
Table
2,
column2).
For
example, the
probability
of success of a searchbased
onthe
cap
A
Pseq
=S/N
X100PcapA
=48/50x100
PcapA
=.96x100
PcapA
=96.
The
result,
"96,"indicates
that,
onaverage,
there
is
a96%
chancethat
the
user of
the
TYPE-ID
system willfind
the
name ofhis
unidentifiedtypeface
in
the
list
generatedby
the
computer providedthat the
searchis
based
ononly
the
cap
A
sequence.The
"PSeq" valuesfor
the
20
sequencestested
are presentedin
the
far
rightcolumn of
Table 2.
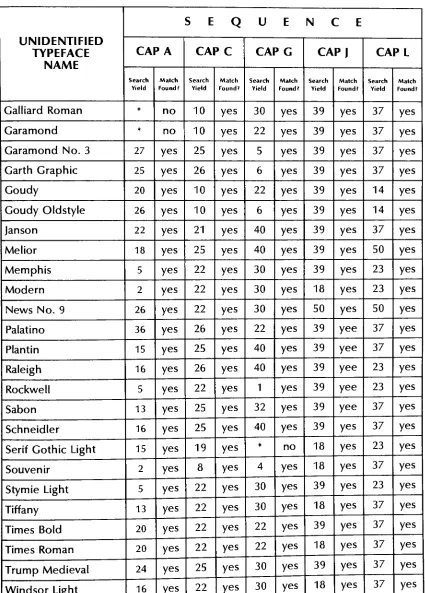
Conclusion 2
Since 50
searches were performed with each ofthe
20
sequences, there
were,
in
all,
(50
x20)
1000
searches performed.Of
these,
978
endedin
success.
There
is,
therefore,
onaverage,
a97.8% (978/1000
x100)
chancethat the
user ofthe
TYPE-ID
system willfind
the
name ofhis
unidentifiedtypeface
in
the
list
generatedby
the
computer providedthat the
searchis
based
ononly,
but
any,
one sequence.Or,
more succinctly:For
any
searchbased
on onesequence, there
is
a97.8%
probability
of success.This
canbe
Pt
=97.8
where "P-i" =
the
probability
of success withany
one-sequence search.This
value of97.8
is
encouraging
in that It
suggeststhat
the
system workswith near-perfect
accuracy for
searchesbased
on one sequence.But
anything
less
than
100%
accuracy
is
unacceptable sinceany
degree
of errorin
a searchbased
on one sequenceis
compoundedby
searchesbased
onmore
than
one sequence.To
illustrate,
if
the
probability
of success of asearch
based
on one sequenceis
97.8
then the
probability
of success of asearch
based
ontwo
is (.978
x .978) x100
whichis 95.6. With
a searchbased
on
three
sequencesthe
probability
of successdecreases further.
(This
is
discussed
further
in
conclusion4).
The
only way
to
solvethis
problemis
to
ensurethat the
probability
ofsuccess
for
any
searchbased
on one sequenceis 100%.
Conclusion 3
While
the
computeris
ableto
perform searches ofthe
database based
onthe
search arguments oftwo
or moresequences, this
feature
was nottested.
However,
the
probabilities of successfor
searchesbased
on morethan
onesequence can
be
determined mathematically
asfollows:
Pseqi,
seq2, . . seqn=
(Pseq/100
XPseq/I00
Xwhere "n"
is
the
number of sequencesin the
search.To
illustrate,
the
probability
of success of a searchbased
onthe
cap
A,
cap
C,
andfigure
2
sequences canbe determined
asfollows:
PcapA,
capC,fig2
=
(PCapA/100
X
PCapC/100
XPfig2/100
)
X100
PcapA,
capC,fig2
=(96/100
x100/100
x92/100
)
x100
PcapA,
capC,fig2
=(-96
x1.00
x .92)
x100
PcapA,
capC,fig2
=
(.88)x100
PcapA,
capC,fig2
=88
The result,
"88,"indicates
that,
onaverage,
there
is
an88%
chancethat the
name of
the
user's unidentifiedtypeface
will appearin
the
list
generatedby
the
computer providedthat the
searchis
based
ononly
the
cap
A,
cap C
and
figure
1
sequences.Conclusion 4
In
the
preceding
example, the
probability
of successfor
a specificcombination of
three
sequences wasdetermined.
Next,
the
averageprobability
of successfor any
searchbased
onthree
sequences(P3)
is
(1)
the
average of allthe
specific probabilities of successfor
each ofthe
([20
x19
x18]
+[1x2x3]
=1140)
1140
combinations ofthree sequences,
that
is
P3
=(Pcombol
+Pcombo2
+
Pcombo3
+Pcombo1140)
"^1140
which means
"the
averageprobability
of success withany
combination of3
sequences
is
equalto the
sum ofthe
probabilities of all1140
possiblecombinations
divided
by
1140
(an
equation which wouldbe
time-consuming
to solve);
or(2)
the
following
equation:P3
=(P-|/100)3x
100
Where
"P3"is
the
averageprobability
of successbased
on "3"sequences;
and "P-i"
is
the
averageprobability
of successfor
one sequence.For
example,
any
search ofthe
database
that
uses3
sequenceswill,
onaverage,
have
the
following
probability
of success:P3
= (97.8/100)3 x100
P3
= (.978)3 x100
P3
=.93 x
100
This
meansthat,
onaverage,
there
is
a93%
chancethat
the
user ofthe
TYPE-ID
system willfind
the
name ofhis
unidentifiedtypeface
in
the
list
generated
by
the
computer providedthat the
searchis
based
onany,
but
only,
three
sequences.The
basic
form
ofthe
above equation canbe
usedto
calculatethe
averageprobability
of successfor any
searchbased
onany
number of sequences.Accordingly,
here
is
the
basic form:
Pn
= (P-|/100)n x100
where "Pn"
is
the
averageprobability
of successbased
on"n"
sequences;
"n"
is
the
number of sequencesin
the search;
and"Pi"
is
the
probability
ofsuccess
for
one sequence.For
example, the
averageprobability
of successfor any
searchbased
on5
sequences
is
equalto:
P5
= (97.8/100)5 x100
P5
= (.978)5 x100
P5
=.89 x
100
The
"Pn"values
for
each sequence are presentedin Table 4. Of
particularimportance is the
fact
that the
P
valuesdecrease
with each added sequence.In
otherwords,
a searchbased
on3
sequenceshas
a greaterprobability
ofsuccess,
andthus
a greaterP
value(93.54),
than
a searchbased
on4 (91.45).
The
reasonfor
this
canbe
explained asfollows: Since
the
probability
ofsuccess
for
a searchbased
on one sequence(Pi)
is
less
than
100%
(97.8)
and since
the
probability
of success with n sequencesis
equalto
Pi
/100
to
the
nthpower,
the
value ofPn
mustdecrease
asthe
value of nincreases.
Pn
is,
therefore,
indirectly
relatedto
n.Because
ofthis,
the
TYPE-ID
systembecomes
less
accurate with each added sequence.It
is
therefore
offundamental importance
to
improve TYPE-ID
to the
point wherePi
=100%.
Conclusion
5
The
average search yield(Yseq) for
each sequenceis
presentedin Table 2.
Each
Yseq
value wasdetermined
by
solving
the
following
equation:Yseq=
TSeq/Nseq
where
"Yseq"
is
the
average search yield of a givensequence;
"Tseq"is
the
total
yield of alltrials
of a givensequence;
and "Nseq"is
the total
number ofsearches made with
the
given sequence.YcapC
Tcapc/NcapC
Ycapc
=977/50
YcapC
=19.5
This
meansthat,
onaverage,
a search ofthe
database based
ononly
the
cap
C
sequence will yield alist
of19.5 typefaces.
Conclusion
6
The
average yieldfor any
searchbased
onany
one sequence canbe
determined
withthe
following
equation:Yi=
T1/N1
where "Y-|"
is
the
average search yieldfor any
searchbased
on onesequence,
"T-|"
is
the
sum ofthe
search yieldsfor
every
trial
made with onesequence;
and"Ni"
is
the total
number oftrials
made with one sequence.The
equationmay be
solved asfollows:
Yi=
T1/N1
For simplification,
the
average search yieldfor any
searchbased
on one sequenceshall,
hereafter,
be defined
as:Yi
=26.
This
meansthat,
onaverage,
the
list
oftypefaces
generatedby
the
computer afterits
search ofthe
database
containsthe
names of26
typefaces.
From
the
"Yi"
value a
"reduction
factor"may be
determined
asfollows:
R
=Y-i/B
where "R"
is
the
reductionfactor;
"Yy
is
the
"average
yieldfor any
searchbased
on onesequence"
and "B"
is
the
"total
number oftypefaces
in
the
database."The
equationmay be
solved asfollows:
R
=26/50
R
=.52
This
meansthat,
onaverage, the
list
generatedby
the
computer after asearch
based
on one sequence will contain52%
ofthe total
number oftypefaces
in
the
database. With
this
figure
the
yieldfor
a searchbased
onany
number of sequences canbe determined
asfollows:
where "Yn"
is
the
yieldfor
a searchbased
on "n"sequences.;
"R"is
the
reduction
factor,
"w"is
the total
number of sequences usedin
the
search,
and "B"
is
the total
number oftypefaces in
the
database.
For example, the
yield
for
a searchbased
on4
sequences canbe determined
asfollows:
Y4
= (.52)4 x50
Y4
=.073 x50Y4
=3.65
The answer,
"3.65,"means
that,
onaverage,
a search ofthe
database
with4
sequences will yield a
list
of3.65
typefaces.
The
calculated yieldsfrom
Yi
to
Y20
are presentedin Table 5.
Conclusion 7
The
following
is
takenfrom
Table
5:
Y6
=1.
This
meansthat,
onaverage, the
yield of a search performed with6
sequences
is
one typeface.Therefore,
in
orderfor
the
user ofthe
TYPE-ID
system
to
narrowthe
list
to
onetypeface
he
mustperform,
onaverage,
aConclusion 8
If
it is
assumedthat
the
user will continueto
searchthe
database
untilhe
has
narrowedthe
list
to
one,
and sincethe
average number of searchesneeded
to
narrowthe
list
to
oneis
6,
the
overallprobability
of successis
equal
to:
^type-id
*Where
"P-^p^io-
is
the
overallprobability
of success ofTYPE-ID
andP6
is
the
probability
of success of a searchbased
on6
sequences.This
equationmay
be
solved asfollows:
^type-id
6p
=7 54
r
TYPE-ID u/ -J
This
figure,
87.54,
indicates
that,
onaverage, the
TYPE-ID
system,
in its
current
form,
is
87.54%
accurate(assuming
that
the
average search willbe
based
on6
sequences).Conclusion
9
Pi
=97.8. All
ofthe
otherP
values calculatedfor
this
discussion
arebased
on
P-|. It is
therefore
essentialto
improve
the
TYPE-ID
system suchthat
Pi
Conclusion
10
The
imperfect
probability
of success ratemay
be
attributableto
the
following: (1)
the
systemmay
not contain sufficient"null
digits"which
means
that the test
subjectsdisagreed
withthe
compilers ofthe
database
onthe
answersto
certainquestions;
(2)
the test
subjects made errors(such
aspushing
the
wrong
buttons,
answering
the
wrong
questions)
whileinputting
their
answersto their
profilegenerating
questions;
or(3)
the
compiler madeerrors while
inputting
the
database.
Conclusion
11
Any
sequence with aprobability
of success ofless
than
100
mustbe
investigated.
These
sequences canbe identified from Table
2. Each
questionfor
each ofthese
sequences mustbe
"recompiled,"that
is,
each questionmust
be
answeredby
a number of compilersto
see wherethey
agree anddisagree.
Since
the
number of compilers usedinitially
was3,
and sincethis
was
apparently
aninsufficient
numberto
determine
the
location
of allthe
null
digits,
the
recompilationprocess, should, perhaps,
be
carried out with5
or
10
compilers.Conclusion 12
experimental error
may
be
attributableto
test-subject
error.This is
notunlikely
asonly
two test
subjects generated allthe
data
(each
identified 500
typefaces!).
Test
subjectfatigue may
have
been
afactor.
Upon
retesting
the
system,
alarger
number oftest
subjects shouldbe
employedto
answer afewer
number of questions each.The resulting
data
wouldbe
a moreaccurate reflection of
the
TYPE-ID
system and muchless
a reflection oftest
subject endurance.
The
systemmay
in
fact be
more accuratethan the
Chapter
8
SUMMARY
The
first
order ofbusiness
ofthis
chapteris
to
answerthis
question:"is
the
hypothesis
presentedin
Chapter
4 true
or false?"The
answeris
"true
. . . sortof."
To review,
the
hypothesis
statementis:
The
prototype ofthe typeface
identification
systemthat
has
been
developed
in
conjunction withthis
thesis
will enableits
userto
generate alist
ofthe
specific commercial names of one or moretypefaces
whichincludes
the
name ofthe
user's unidentifiedtypeface
providedthat
the
unidentifiedtypeface
is
one ofthe
50
typefaces
listed
anddisplayed
in Appendix B
ofthis
paper.On
average,
97.8%
ofthe
searches performed with one sequence yielded alist
oftypefaces
whichdid
include
the
name ofthe
user's unidentifiedtypeface
(or,
numerically,
Pi
=97.8).
The
user who stopshis
search afterone sequence can
be
reasonably
certainthat the
name ofhis
unidentifiedtypeface
is included
onthe
list.
Therefore,
the
hypothesis
is
basically
true
for
searches
based
on one sequence.But,
as shownin Table 4
and explainedin
Chapter
6,
the
probability
of successdecreases
when more sequences areThe
solutionto
this
problem asdiscussed
in
chapter7,
may
be
two
fold:
(1)
more null
digits
mustbe
incorporated
into
the
system and(2)
the
procedurefor
testing
mustbe
improved.
While
the
systemis
notperfect, in its
currentstate,
it
is
a considerableimprovement
onthe
Panose system,
and oncethe
bugs
are workedout, it
Chapter 9
SUGGESTIONS
FOR
FURTHER
RESEARCH
The
prototype ofthe typeface
identification
systemdeveloped
in
conjunction
withthis thesis
is
not a comprehensive system.Its
database is
composed of
only
50 typefaces
and all ofthese
are members ofthe
samecategory
or "class" oftype
(Indeed,
they
may
allbe
classified as "seriffed"typefaces).
The
purpose ofthis
chapteris
suggest some ofthe
stepsthat
must
be
taken
to
develop
a comprehensivetypeface
identification
system.Suggestion
1
Once
the
"bugs"have been
worked out ofthe
TYPE-ID
prototype, the
database
canbe
expandedto
include
all seriffedtypefaces.
If
this
provessuccessful,
other profile generators anddatabases for
other categories oftype
may
be
developed. The
result:TYPE-ID,
in its
finished
form,
may
be
composed of severaldifferent
"branches"
each of which
functions
as a separate system and each of whichis
designed
to
identify
the typefaces
of a specificcategory
or"classification"
of
type.
Suggestion
2
If TYPE-ID is
to
be
divided into
classes,
one questionthat
mustbe
answeredIn Appendix H
ofthis
thesis
are presented a number oftypeface
classification systems.
From
studying
these
systemsthe
following
conclusionswere
drawn
(specific
examples aretaken
from
Appendix H
orfrom
the
sources cited
in Appendix H):
(1)
There is
generaldisagreement
asto
whatthe
major and minor categories oftypefaces
shouldbe.
For
example:Some
treat
"Italic"typefaces
as a separatecategory
while most othersdo
not;
One
systemdoes
notinclude
the
subclass"Slab
Serifs"under
the
broad
category
"Romans"while most others
do;
One
includes
"Blackletters"in
the
miscellaneousgrouping
"Decorative"while
many
otherhave
a separatecategory for
Blackletters;
Bold
faces
aretreated
separately
by
some and notby
others;
Display
faces
aredivided
into
subclassesby
somebut
notby
others;
and somehave
a separatecategory for
"Private
Press
Types" while most othersdo
not..(2)
There is
generaldisagreement
asto
whichtypefaces
belong
to
whichgroup; that
is,
agroup in
classification "A"may have
the
samelabel
as agroup
in
classification "B"but
their
elementsmay
notbe
the
same.For
example:Thibaudeau's
"Antique" class
contains sans serif
faces
whilethe
"Antique" ofDeVinne,
Legros
and
Grant,
andMartin
Solomon
containonly
seriffaces;
DeVinne's
"Gothic" class contains sans seriffaces
whileSolomon's
"Gothic" class containsblackletters.
(3)
There
is disagreement
asto
whatthe
base
oftypographical
classification should
be.
Some
believe
that
ahistorical
base
is
best;
otherbelieve
a morphologicalbase
is
best.
But
mostsystems are a mix of
the two.
The
ubiquitous"Roman"
category
is
historically
based
while such categories as"sans
serif,""slab
serif,"
and
"decorative"
are
morphologically
based.
The
pointhere
is
that
care mustbe
taken
in
the
selection of a classification system on whichto
base
the
TYPE-ID identification
system.The
system mustbe
sufficiently
clearthat the
user ofTYPE-ID
canquickly
andeasily
determine
to
which classhis
unidentifiedtypeface
belongs
--a
feat
whichdebating
the
subject oftypeface
classificationfor decades
(if
not centuries)and no system
has
yet gained universal support.The
beauty
ofthe
TYPE-ID identification
systemis its
provisionfor
uncertainty.
The
user or compiler whois
unableto
answer one of profilegenerating
questions withcertainty
may
"pass."Unfortunately,
the
user cannot pass on
the
classification question.For example, if
separate profile generators anddatabases
are createdfor
each of
the
following
"generic" classes oftype
Blackletter
Uncial
Serifs
Sans Serif
Scripts
Decorative,
the
first
thing
the
user mustdo,
before
he
canbegin using any
ofthe
profilegenerators,
is determine
to
which ofthe
above classeshis
unidentifiedtypeface
belongs.
If
his
unidentified typefaceis "Times Roman
Italic"
he may have difficulty.
Times Roman Italic
has
serifs and so mightbe
classified as a "serif"face.
But
face.
Furthermore,
depending
onits
use, it
may
also appearto
be
a"decorative"
face.
If
this
were a profilegenerating
question, the
user could pass.But
here,
he
must answerto
goany
further.
If
he
should answerincorrectly,
he may
spend
time
in
the
wrong branch
ofthe
systembefore he
realizeshis
error.This
problemis
not restrictedto
Times Roman Italic.
There
areprobably
hundreds,
if
notthousands,
oftypefaces that
couldbe similarly
misclassified(especially
by
typographical
novices).The
solutionto this
classificationproblem,
then,
is
notto
searchfor
perfect classnames,
but
to provide,
asthe
profile generatordoes,
for
uncertainty.This
mightbe
accomplishedin
one orboth
ofthe
following
ways:(1)
Typefaces
which arelikely
to
be
misclassifiedmay be
enteredinto
the
databases
of morethan
one class(for example,
Times Roman Italic
mightbe
included in
both
the
"serif" and"script"
databases)
and(2)
The
classificationquestion might
instead
be
a series of questions which couldhave
a profilegenerator and
database
ofits
own.The
user would usethe
classification profile generatorto
determine
whichidentification
profile generatorto
use.Suggestion
3
typefaces.
The
most obvious mistake a compiler could make wouldbe
to
label
profileA
as "Baskerville" whenit is
actually
"Bodoni."But,
there
areother,
more subtle mistakesthat
couldbe
made.The
commercial names oftypefaces
canbe confusing
and misleading.Indeed
problemshave
plaguedthe
naming
ofindividual
typeface
designs
since
the
incunabula
days
of printing.Geoffrey Dowding
addressesthis
problem
in "Typefaces: A Plea
for
aRational Terminology":
If
one can criticizethe
founders
for
failing
to
agreeamong
themselves
on aless muddling
system ofterminology
for
their
types,
individual
printershave
likewise,
withoutdouot,
further
confused matters
by
the
thoroughly
arbitrary
and reprehensible procedure ofinventing
namesfor
the types
in
their
cases.Were
these
invented
names confinedto the
printer's own works all mightbe
well,
but
as most printersissue
type
specimen sheetssooner or
later
these
new names arebroadcast
andhelp
to
perplex many.1
Dowding
gives whathe
calls a"flagrant
example"
of
this
name-changing
practice.
A
specimenbook
waspublished,
sometimebefore
World War II in
which was
listed
atypeface
called"Sun"
with
its
corresponding
"Sun
Italic."It
waslater
discovered
that the
specimens shownin
the
book
were piratedspecimens of
Monotype "Centaur
Roman"
and
Monotype "Arrighi
Italic."Not
only did
the
printer changethe names,
but he
alsojuxtaposed
a romanand
italic
face
that
were notdesigned
to
be
used together.2Today,
this name-changing
practicehas been
replacedby
a new menace.Alexander Lawson
andArchibald
Provan
alludeto this
in
their
article entitledWith
the
rapid expansion of photographic methodsin
typeset
ting,
there
has
also come an explosion of newtypefaces
readily
producedby
photographic means.A
greatmany
ofthese type
faces, however,
aresimply
adaptations ofthe
most preferredbasic
types,
alteredto
work with a specific equipment manufacturer's machinery
and marketed under a new name.The
resulting
proliferation oftypeface
nameshas
caused confusionamong designers
and editors.4There
aremany
examples oftypefaces that
have been slightly
altered andthen
sold under new names.Below
are some examples:"Baskerville"
has been
redesigned and sold under such names as"New
Baskerville," "Baskerline,"
and
"Beaumont."
"Helvetica"
has look-alikes
named"Claro," "Corvus," "Geneva," "Helios,"
"Megaron," "Newton,"
and
"Vega."
Hermann
Zapf's
"Palatino"has been
marketed as "Andover,""Elegante,"
"Palladium," "Pontiac,"
and
"Patina."
His
"Melior"has been
marketed as"Ballardvale," "Hanover," "Lyra," "Mallard," "Medallion," "Melier," "Uranus,"
and
"Ventura."
And,
his
"Optima"
has
been
marketed as "Chelmsford,""Musica," "Oracle," "Orleans," "Ursa,"
and
"Zenith."
There
are a veritable plethora of other such examples.It
should sufficeto
say,
however,
that the
commercial names of a greatmany
typefaces
arethe
sources of constant confusion
in
the typographic
industry,
andthat
the
Suggestion 4
The discussion
thus
far
has focused
onthe
"standard
equipment"of
the
TYPE-ID
system.There
is, however,
some"optional
equipment"that
might prove useful.For example,
afterthe
userhas
tentatively
determined
the
name ofhis
unidentifiedtypeface
he
mightlike
some otherinformation
as afinal
checksuch
as;
(1)
the
name ofthe
designer
ofthe
typeface, (2)
the
date
the
typeface
wasdesigned,
(3)
the
country
or countriesin
whichthe typeface
is,
or
was, marketed,
and(4)
alist
oftypefaces
which are similarin
design
or"substitutable"
for
the
unidentifiedtypeface.
Such information
couldeasily
Chapter 9
NOTES
1.
Geoffrey
Dowding,
"Typefaces: A Plea
for
aRational
Terminology,"Typographica
#4
(1926).
10.
2. Ibid. 11.
3. Alexander Lawson
andArchibald
Provan,
"Commonly
Used
Typeface
Names,"
appearing
in Janet
Field,
Sr.
Ed.
Graphic
Arts Manual (New York:
<