JOURNALOFVIROLOGY, Jan. 1982,p. 51-65
0022-538X/82/010051-15$02.0O/0 Vol.41,No. 1
Nucleotide
Sequence of a Cloned Woodchuck
Hepatitis Virus
Genome:
Comparison with the Hepatitis B Virus Sequence
FRANCISGALIBERT,* TSIEN NANCHEN,tANDELISABETH MANDARTLaboratoired'HMmatologieExptrimentale, Centre Hayem, Hopital Saint-Louis, 7S475ParisC&dex10, France
Received 1 June 1981/Accepted 14 July 1981
The complete nucleotide sequence of a woodchuck hepatitis virus genome clonedin Escherichia coli was determined by the method of Maxam and Gilbert. This sequence was found to be 3,308 nucleotides long. Potential ATG initiator triplets and nonsense codons were identified and used to locate regions with a substantial coding capacity. A striking similarity was observed between the organizationof human hepatitis B virus and woodchuck hepatitis virus. Nucleo-tidesequences of these open regions in the woodchuck virus were compared with correspondingregions present in hepatitis B virus. This allowed the location of fourviral genes on the L strand and indicated the absence of protein coded by the Sstrand. Evolution rates of the various parts of the genome aswell as of the four differentproteins coded by hepatitis B virus and woodchuck hepatitis virus were compared. These results indicated that: (i) the core protein has evolved slightly lessrapidly than the other proteins; and (ii) when a region of DNA codes for two differentproteins, there is less freedom for the DNA to evolve and, moreover, one ofthe proteinscan evolve morerapidly than the other. A hairpin structure, very well conserved in the two genomes, was located in the only region devoid of coding function, suggesting the location of the origin of replication of the viral DNA.
Biologicalstudyofhepatitis B virus (HBV) is drasticallylimited due to its restricted host range and failure to infect tissue culture. However, with development of recombinant DNA technol-ogy,itwaspossibletoclone the HBV genome in Escherichiacoli (2, 7, 16) and produce substan-tial amounts ofDNA; this, inturn, allowed its complete primary structure to be analyzed (8, 14, 20). Although genes cannot be identified from a DNA sequence alone because of the possibility of splicingevents abletoeliminatea
closed reading frame from a putative mRNA transcript, the location ofopen reading frames could be a useful step toward gene identifica-tion. On the HBV genome (subtype ayw), we
wereable tolocateseveral openreadingframes with substantial coding capacity (8). Among
otherconsiderations,twoofthem werefoundto
correspond to two viral
proteins:
polypeptide Iand its glycosylated derivative,
polypeptide
II, the main components of the viralenvelope,
calledthehepatitis B surface
antigen
(HBsAg),
and thehepatitisBcoreantigen
(HBcAg) (4,
8,
19).
Recently three
hepatitis
virusesinfecting,
re-tPresent address: Genetic Institute of the Academy of SciencesofChina,Peking,China.
spectively, woodchucks, squirrels, and Peking ducks, were isolated (11, 18; J. Summers, W. T. London, T.T.Sun, and B. S. Blumberg, manu-scriptinpreparation).These viruses have many characteristics in common with human HBV, and some areunique to this novel class. Of these characteristics, ultrastructure, antigenic make-up, DNA size andstructure (the smallestknown DNAgenome, made of apartially single-strand-ed andnoncovalently closedcircularDNA),and features ofpersistent infection shouldbe noted (6, 12, 21).
Because these HBV-like viruses share all of these properties, we felt that a
comparison
of their genomes at the nucleotide level might provideananswertoseveralquestions concern-ingthe number and locationof the viral genes, theserologicalrelationshipbetween thevarious viralproteins, andtheevolution ofthegenomes of theseviruses, whicharelocalized in different ecological niches.Recently we were able to locate within the whole cloned DNAgenome ofwoodchuck
hepa-titis virus (WHV) the gene
coding
for the WHsAg proteinandtocompare theamino acid sequences of the surfaceantigens
from humanandwoodchuck
hepatitis
viruses(F.
Galibert,
E. Mandart,and S.N.Chen,Proc.Natl. Acad. Sci. 51on November 10, 2019 by guest
http://jvi.asm.org/
U.S.A.,in press). We report here the complete nucleotide sequence of the genome of WHV and compare its primary structure with that of the
human HBV genome(8).
MATERIALS ANDMETHODS
Enzymes and chemicals. Restriction endonucleases came from New England Biolabs andwere used as recommendedby the manufacturer. DNApolymerase I came from Boehringer Mannheim, and bacterial alkalinephosphatase andpolynucleotide kinasewere from P. L. Biochemicals.
A
A
T
T
C T C T
G3
A
A
c T G
T
T (3
T
T G3
A T C*
_~~~~_
- (
_~~~( A
..eW~~~~~~~~~~~~(
T
G A
--_~~~~~
_ _.
- C
A..e
::...A
wl0ps.~~ ~ ~
: 3
A ....
I
a
Chemicals used for the nucleotide sequenceanalysis were as described (10). [y-32P]ATP(specific activity, >2,500 Ci/mmol) and a-32P-labeled nucleotide triphos-phate (specific activity, >3,000 Ci/mmol) were from NewEngland Biolabs.
PreparationofEcoVHV DNA. A X-WHV recombi-nant wasconstructedby Cumming et al., using Xgt XB WES bacteriophage as the cloning vector (6). The cloned DNA was referred to as Eco WHV DNA. Propagation and purification of the recombinant as well as preparation of the Eco WHV DNA were performed as previously described (4, 8,10).
A'A ....
, T. f
"A3 4
: .
PI A-
i-4
1k
C
_~~~~
-WF! A
1A
A
A
C
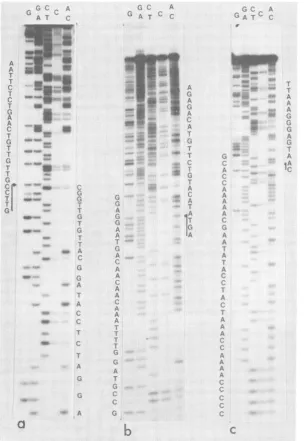
FIG. 1. Autoradiogramof 16% acrylamide sequencinggelshowingthesequenceofchainL fromnucleotide 208 (a), 714(b), and889 (c). Five chemical reactions specific forG-AG-CT-C and AC were performed on all
sequencedfragments.
on November 10, 2019 by guest
http://jvi.asm.org/
[image:2.504.110.415.204.645.2]WHV GENOME NUCLEOTIDE SEQUENCE 53
Containnt. Containment conditionswere as rec-ommendedby the French National Control Commit-tee. The culture of recombinant bacteriophage was doneunderL3B1 conditions.
DNA nudeotide sequence. Sequence analyseswere determined by the Maxam and Gilbert method (13). Usually, about 10pmol of Eco WHV DNA(20,ug)was fully digested each time with a givenrestriction en-zyme. Fragments weredephosphorylated and labeled with [-y-32P]ATP and polynucleotide kinase as de-scribed(10). Tosegregatethe two labeled ends, frag-ments were denatured by heating to 92°C in the presence of30%o dimethyl sulfoxideandfractionated byelectrophoresis inacrylamidegel (13). Fragments largerthan 600 base pairs were hydrolyzedwith anoth-er restriction enzyme. Under some circumstances, fragmentswith arecessed3'endwere labeled with a a-32P-labeled nucleotide triphosphate of choice and DNApolymeraseIasdescribedby Hartley and Donel-son (9).
RESULTS ANDDISCUSSION
Wedetermined by the methodofMaxamand Gilbert (Fig. 1) the complete nucleotide
se-quenceof the WHV DNA genome cloned in E. coli.Thesequence wasdetermined fromalarge number of fragments obtained with various re-striction enzymes. Both DNA strands were in-dependently analyzed except between nucleo-tides 1,110 and 1,174, which wereanalyzed on one strand only, but several times and from differentrestrictionsites(Fig. 2). All restriction sites used asstarting points were also analyzed
as internal points of overlapping fragments in order to detectpotentially verysmallfragments produced by closed identical restriction sites. From the relative positions ofthe EcoRl and SacI enzymes on the viral DNA (6) and the position ofthe Sacl restriction site on the
se-quencedDNA, itwaspossibletoorientthe Eco WHV DNA. As for HBV, we
designate
the DNAstrandofthe Eco WHV DNAhomologous1 c:=j - I
tothe longest viral DNA strand as the L strand and the other strand as the S strand. The L strandstarts with the sequence CCAGG, and the S strand starts with thesequenceAATTCGGG. Thesequence shown in Fig. 3 is complementary to the L strand. It is 3,308 nucleotides long, compared with the 3,182 nucleotides of the HBV Lstrand.
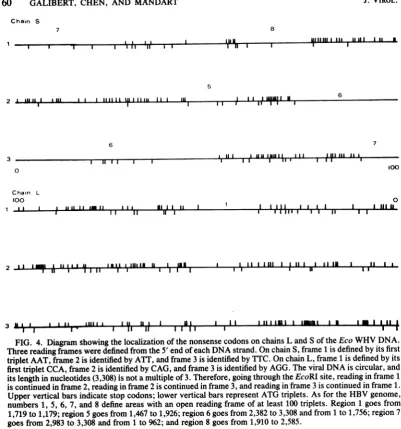
Location of the open reading frame. A comput-er program (17) was used to search for stop codons and ATG triplets on both DNA strands (Fig. 4), In chain L, which had a sequence identical to thepotential transcripts of chain S, there was a large number of stop codons (44, 64 and 60, respectively) located in the three phases. Moreover, the distribution of these stop codons all along the molecule left only one region in phase 1 betweennucleotides 1,719 and 1,179 with a coding capacity arbitrarily chosen above 100 amino acids.
On the other strand, the number of stop codons in the various phases was smaller (33, 50 and 30,respectively), and their uneven distri-bution created several large open reading frames. The locations of these open reading frames on the WHV circular genome are shown and comparedwith those of the HBV genome in Fig.5. Fromthiscomparison, astriking similar-ityin the number, size, and location of the open readingframes, relative to each other and to the nickofthe Lstrand, emerged between the two genomes. The fact that there was one open reading frame in chain L of the WHV genome butfour in chain L of the HBV genome was the onlydifference. Wepreviously noted (8) that, in the open reading frames 1 to 4 ofthe HBV L chain, the first ATG encountered and able to play an initiator role was located well inside these open readingframes,largelyreducingtheir coding capacity. The lack of open reading frames homologousto
regions
2, 3,and4in the_ * ZJZ
2 t
.r]F
Z'
_-J
4 1
5 6 7 8
-J .
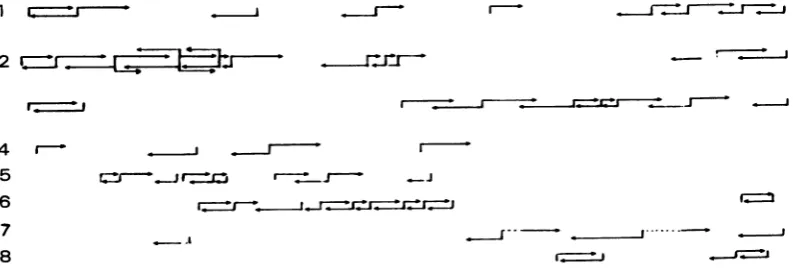
[image:3.504.58.455.512.646.2]I_..-I-J FIG. 2. DiagramofanalyzedDNAfragmnents. Vertical barscorrespondtothepositionof the labeled ends ofrestrictionfragmentsused.Lengthof thearrowsis relativetothe number ofanalyzednucleotides. Most of the fragmentswere5'labeled.Hinflfragmentswerelabeledatthe 5' and 3' ends.(1)BstEII;(2)Hinfl;(3)HaeIII;(4) BamHI, BglII,andHindIll;(5)AluI; (6) Sau3a; (7) RsaI; (8)DdeI.
VOL.41, 1982
a
I 0
on November 10, 2019 by guest
http://jvi.asm.org/
IleArgAspIleProArgGlyLeuValProPrcGlnThrProThrAsnArgAspGlnGlyArgLysProThrPro
AsnSerGlyHisThrThrTrpPheSerSerAlaSerAsnSerAsnLysSerArgSerArgGluLysAlaTyrSer
1
AATTCGGGACATACCACGTGGTTTAGTTCCGCCTCAAACTCCAACAAATCGAGATCAAGGGAGAAAGCCTACTCC
.0..*..*. . .. *. ..** . .
3081 CCAGCAAAT CCGCCTCCTGCCTCCACCAATCGCCAGTCAGGAAGGCAGCCTACCCC
AlaSerLys o o o CysLeuHisGln o ProVal o LysAla o o Pro
o AlaAsn o o ProAlaSer o o o GlnSer o o Gln o o o
ProThrProProLeuArgAspThrHisProHisLeuThrMetLysAsnGlnThrPheHisLeuGInGlyPheVal
SerAsnSerThrSerLysArgTyrSerProProLeuAsnTyrGluLysSerAspPheSerSerPraGlyValArg
76 TCCAACTCCACCTCTAAGAGATACTCACCCCCACTTAACTATG AAAAATCAGA CT TTCGT
... 0.0 ... ..
3137 GCTGTCTCCACCTTTGAGAAACACTCATCCTCAGGCC ATGCAGTGGAATTC CACAACCTTCCA AlaVal o o PheGluLysHis o SerSerGly HisAlaValGluPhe HisAsnLeuPro
LeuSer o o o o Asn o o o GlnAla o GlnThrAsnSer ThrThr o His
AspGlyLeuArgAspLeuThrThrThrGluArgGlnHisAsnAlaTyrGlyAspProPheThrThrLeuSerPro
GlyArgI1eLysArgLeuAspAsnAsnGlyThrProThrGlnCysLeuTrpArgSerPheTyrAspThrLysPro
151 GGACGGA'ITAAGAGACTTGACAACAACGGAACGCCAACACAATGCCTATGGAGATCCTTTTACGACACTAAGCCC 18
CCAAACTCTGCAAGATCCCAGAGTGAGAGGCCTGTATTTCCCTGCTGGTGGCTCCAGTTCAGGAACAGTAAACCC
ProAsnSerAla o SerGlnSerGluArgProValPhePro o Trp o LeuGIn o ArgAsnSer o oGlnThrLeuGlnAspProArgValArgGlyLeuTyrPhePro o Gly o SerSerSerGly o ValAsn o WHs
ValValProThrValSerThrI1eLeuSerProProSerThrThrGlyAspProAlaGlnSerPrcGluMet
CysGlySerTyrCysIleHisHisileValSerSerl1eAspAspTrpGlyPrcCysThrValThrGlyAsp
226
TGTGGTTCCTACTGTATCCACCATATTGTCTCCTCCATCGACGACTGGGGACCCTGCACAGTCACCGGAGA'G
93
TGTTCTGACTACTGCCTCTCCCTTATCGTCAATCTTCTCGAGGATTGGGGACCCTGCGCTGAAC
ATGGAGo SerAsp o o LeuSerLeu o o AsnLeuLeuGlu o o o o o AlaGlu HisGly
o LeuThr o Ala o ProLeuSer o IlePhe o Arglle o o o o LeuAsn o Glu
SerProSerSerLeuLeuGlyLeuLeuAlaGlyLeuGlnValValTyrPheLeuTrpThrLysIeLeuThr
ValThrlIeLysSerProArgThrProArgArgIleThrGlyGlyValPheLeuValAspLysAsnProAsn
299
TCACCATCAAGTCTCCTAGGACTCCTCGCAGGATTACAGGTGGTGTATTTCTTGTGGACAAAAATCCTAACA
163
AACATCACATCAGGATTCCTAGGACCCCTTCTCGTGTTACAGGCGGGGTTTTTCTTGTTGACAAGAATCCTCACA
GluHisHis o Arglle o o o o Ser o Val o o o o o o o o o o o His
AsnlleThr o GlyPhe o o Pro o LeuVal o o
AlaGlyPhe
o o Leu oArg
o o oIleAlaGlnAsnLeuAspTrpTrpTrpThrSerLeuSerPhePrcGlyGlyllePrdGluCysThrGlyGlnAsn
AsnSerSerGluSerArgLeuValValAspPheSerGlnPheSerArgGlyHisThrArgValHisTrpProLys
371
ATAGCTCAGAATCTAGATTGGTGGTGGACTTCTCTCAGTTTTCCAGGGGGCATACCAGAGTGCACTGGCCAAAAT
*C * *v.o -*-* * ***.-. ....@-*@**- *o.*@@@@@*.o. * . ...*@-..
--238
ATACCGCAGAGTCTAGACTCGTGGTGGACTTCTCTCAATTTTCTAGGGGGAACTACCG,I.irI
ii.,uOCAAAATo Thr o o o o o o o o o o o o o o o AsnTyr o o Ser o o o
o Pro o Ser o o Ser o o o o o Asn o Leu o o ThrThrVal o Leu o o o
SerGlnPheGlnThrCysLysHisLeuProThrSerCysProProThrCysAsnGlyPheArgTrpMetTyrLeu
PheAlaValProAsnLeuGlnThrLeuAlaAsnLeuLeuSerThrAspLeuGlnTrpLeuSerLeuAspValSer
446 TCGCAGTTCCAAACTTGCAAACACTTGCCAACCTCCTGTCCACCGACTTGCAATGGCTTTCGTTGGATGTATCTG
313 TCGATCAjCTCTATACCTTGCTAATGCTGATGCTGGATGTGTCTG
o o o o o o o Ser o Thr o o o o SerAsn o Ser o o o o o o o o o SerPro o SerAsn o Ser o o o o o o o o Pro o Tyr o o o Cys o FIG. 3. Comparison of the WHV and HBV DNA sequences. The top line corresponds to the WHV sequence (Sstrand); thesecond linecorresponds to the HBV sequence (8). Identical nucleotides are marked with a dot. Identical amino acids are indicated by an open circle. In both cases,sequences are numbered from theirEcoRI site.
on November 10, 2019 by guest
http://jvi.asm.org/
WHV GENOME NUCLEOTIDE SEQUENCE 55
ArgArgPheIlelieTyrLeuLeuValLeuLeuLeuCysLeuIlePheLeuLeuValLeuLeuAspTrpLysGly
5lAlaAlaPheTyrHisIleProIleSerProAlaAlaValProHiisLeuLeuValGlySerProGlyLeuGluArg
521 CTACTTGTGTCCTGCG^AG
388
CGciGT'rrT
TTTCCTCTfCA.CDCTGO
lGCT.CATGCCTCATCTTCTTGT.TGGTTCTTCTGGA.CTATCAAGGT
o o o o o Leu o LeuHis o o o Met o o o o o o o Ser o o Ser o
o o o o o Phe o Phe o o o o o o o o o o o o o o
TyrGIn
oLeulieProValCysProlleGInProThrThrGluThrThrValAsn
CysArgGInCysThrlIeSerPheAsnThrCysLeuSerTyrSerThrHisAsnArgAsnAspSerGln
LeuGlnThrMetHisAsnLeu 596TTAATAI~CcLXCTGTCTEIATCAACCCACAACAGAXACGACAGTCAA
TTGCAGACAATGCACAATCTCT00000.0.0o..0 0. .0. 00
000~~~~~ ~
. .463 ATGT
TyrValAlaArg o o SerAsnSerArglIeLeu o AsnGInHisGlyThrMetProAspLeu o AspTyr
MetLeu o o o o Leulle o GlySerSer o o SerThrGlyPro o o Thr o o ThrThr
VaIGInAspMetTyrThrProProTyrCysCysCysLeuLysProThrAlaGlyAsnCysThrCysTrpProIle
CysThrArgHisValTyrSerSerLeuLeuLeuLeuPheLysThrTyrGlyArgLysLeuHisLeuLeuAlaHis
'665
TAAACCTACGGCAGGCAATTGCACTTGCTGGCCCATC
.
..0.0.0 0 . 0 O. 0 . . . .0 0
538 CTCAAGGAA ATTGCTGTATTCCCATC
CysSer o AsnLeu o Val o o o o o TyrGIn o Phe o o o o o o TyrSer o Ala o GlyThrSerMetTyr o Ser o o o Thr o o SerAsp o o o o o Ile o o
ProSerSerTrpAlaLeuGlyAsnTyrLeuTrpGluTrpAlaLeuAlaArgPheSerTrpLeuAsnLeuLeuVal
ProPhelleMetGlyPheArgLysLeuPrdMetGlyValGlyLeuSerProPheLeuLeuAlaGlnPheThrSer
740 CGGAGTGGGCC
613
CCATCATCTmMAArrCCTATGGGA
CAGTTTACTAGTGo Ile o Leu o o a o Ile o o o o o o o o o o o o o o o o
o o o o Phe o LysPhe o o o o Ser o a o o ooSer o o o
ProLeuLeuGlnTrpLeuGlyGlylieSerLeulleAlaTrpPheLeuLeuleTrpMetIleTrpPheTrpGly
AlaLeuAlaSerMetValArgArgAsnPheProHisCysValValPheAlaTyrMetAspAspLeuValLeuGly
815
CCCTTGCTTCAATGGTTAGGTGGAATCTCA
1ox.111R,CTTATATGGATGATTTGGTTTTGGGGG
688
CCATTTGTTCA.GTGGTTCGTAGGGCTTTCCCCCACTGTTTGGCTTTCAGTTATATGGATGATGTGGTATTGGGGG
o IleCys o Val o o o Ala o o o o LeuAla o Ser o o o o Val o o o o PheVal o o o Val o Leu o ProThrVal o LeuSerVal o o o Met Tyr o o
End of region 7
ProAlaLeuLeuSerIleLeuProProPhelleProliePheValLeuPhePheLeulieTrpValTyrlle_
AlaArgThrSerGluHisLeuThrAlaIleTyrThrHisIleCysSerValPheLeuAspLeuGlyIleHiisLeu
890
CCCGCACTTlCTGACAITCTTACCGCATTTATACCCATATTTGTTCTGTTTTTCTTGATTTGGGTATAATTTRAA
763
CTTIACCGCTGTTACCAATTTTCITGTCTTTGGGTATACAT1-AA
o LysSerValGln o o GluSerLeuPhe o AlaValThrAsnPheLeu o Ser o o o o o o Ser o Tyr o o o Ser o o Leu LeuLeuProlle o o CysLeu o o o ao
AsnValAsnLysThrLysTrpTrpGlyAsnHisLeuHisPheMetGlyTyrVailIeThrSerSerGlyValLeu
965
ATGTTAATAAAACAAAATGGTGGGXCAATCATTTACATTrTIATGc^ASTATAATTACTAGTTCAGGTGTATTG
838ACCCTAACAAAACAAAGAGATGGGGTT.ACTCTCTAAATTTTATGG3TTATGTCATTGGATGTTATGGGTCCTTG
o Pro o o a o Arg o o TyrSer o Asn o o o o o GlyCysTyr o Ser oFIG. 3-continued
VOL.41,1982
on November 10, 2019 by guest
http://jvi.asm.org/
ProGInAspLysHisValLysLysLeuSerArgTyrLeuArgSerValProValAsnGInProLeuAspTyrLys
1039CCACAAGACAAACATGTTAAGAAACTTTCCCGTTATTTACGCTCTGTCCTTATAACCTCTGGATTACAA
o o GluHis o IleGln o lIeLysGluCysPhe o LysLeu o Ile o Arg o Ile o Trp o IleCysGIuArgLeuThrAspIleLeuAsnTyrValAlaProPheThrLeuCysGlyTyrAlaAlaLeuMetPro
**T**-** * * * * * * *- * .- ... * ...*. ... O*- M *@ ...@
987 GTATGTCAACGAATTGTGGGCITGCCCTTTTACACAATGITIGTATCCTGCGTTGATGCCT
Val o Gln o IleValGlyLeu o GlyPheAla o o o o Gln o o o Pro o o o o
LeuTyrHisAlaIleAlaSerArgThrAlaPheValPheSerSerLeuTyrLysSerTrpLeuLeuSerLeuTyr 1189
CTGTATCATGCTATTGCTTCCCGTACGGCTTTCGTTITCTCCTCCTFGTATAAATCCGGTTGCTGTCTCTTTAT
1062
TG.CAATAC
o o AlaCys o Gln o LysGIn o o Thr o o ProThr o o AlaPhe o CysLysGln o
GluGluLeuTrpProValValArgGlnArgGlyValValCysSerValPheAlaAspAlaThrProThrGlyTrp
1137
CTGAACCTTTACCCCGTTGCCCGGCAACGGCCAGGTCTGTGCCAAGTGTTGCTGACGCAACCCCCACTGGCTG
LeuAsn o Tyr o o Ala o o o ProGlyLeu o Gln o o o o o o o o o o
GlylleAlaThrThrCysGInLeuLeuSerGlyThrPheAlaPheProLeuProlleAlaThrAlaGluLeulle
1339 GAACTCATC
*G-~~~~~~*G * *@ .0 @.0 *- .* D.*- ... *- *-. *---..
1212 GGCG GGG
GGS
VTCTGCCGATCCATACTGCGGAACTCCTAo LeuValMetGlyHis o ArgMetArg o o o SerAla o o o o His o o o o Leu
AlaAlaCysLeuAlaArgCysTrpThrGlyAlaArgLeuLeuGlyThrAspAsnSerValValLeuSerGlyLys
1414
GGGGCTC
GTCGGGGAAG
1287
GCCGGTTGCT.CGCA)CAGGTCTGGAGCAAACATTATCGGGACTGATAACTCTGTTGTCCTATCCCGCAAA
o o o Phe o o SerArgSer o o Asnllelle o o o o o o o o o Arg o
Gene 5
MetAlaAlaArgLeuCysCysGlnLeuAspProAlaArgAspValLeuLeuLeuArgPro
LeuThrSerPheProTrpLeuLeuAlaCysValAlaAsnTrplIeLeuArgGlyThrSerPhecysTyrValPro
1489 TCCGCGGQGCGTCTTTGCACGCCC
1362 T AIACATGTTTCCATGCTGCTGGCLGTGCGCCLACTGGATCCTGCGCGGGACGTCCTTGTflACGTCCCG
Tyr o o o o o o oGly o Ala o o o o o o o o o o Val o o o o o o o o o o o o o o o o o o o0Cyso o o
PheGlySerGInSerSerGlyProProPheProArgProSerAlaGlySerAlaAlaSerProAlaSerSerLeu
SerALaLeuAsnProAlaAspLeuProSerArgGlyLeuLeuProValLeuArgProLeuProArgLeuArgPhe
15646G4CCACAGGACCCTCGAGCTTC
~J
14371437TCGGCGCGAA.TCcCCTTC
CG~GGGTCrCC
. CGTCIrrCGT
0.. 0o o o o o o o Asp o o o o Arg o GlyLeuSer o o o Leu o o Pro o Val o AlaGlu o Cys o Arg o o SerGlySerLeuGlyThrLeuSerSerProSerPro o AlaVal
FIG. 3-continued
on November 10, 2019 by guest
http://jvi.asm.org/
WHV GENOME NUCLEOTIDE SEQUENCE 57
SerAlaSerAspGluSerAspLeuProLeuGlyArgLeuProAlaCysPheAlaSerAlaSerGlyProCysCys
ArgProProThrSerArgI1eSerLeuTrpAlaAlaSerProProValSerProArgArgProValArgValAla
1639 CGTCCTCCGACGAGTCGGATCTCCCTTrGGGCCGCCTCCCCGCCTTTCGCCTCGGCGCCGTCCGTGTTGC
Ow* * .O-* . O. ..- O... O* O.@.... - *---.. *...@-
*--1512 CGACCGACCATTCTGCCGGACCGTGTGCAC
o o Thr o Gly o Thr o o Tyr o Asp o o Ser o ProSerHisLeu o Asp o o His
ProThrAspHisGlyAlaHis o Ser o ArgGly o o Val o AlaPhe o SerAla o o o Ala
LeuValValThrCysAlaGluLeuArgThrMetAspSerThrValAsnPheValSerTrpHisAla TrpSerSerProValGlnAsnCysGluProTrplIeProProi End of region 6 1714 TGGTCGTCACCTGTGCAGAATTGCCATGGATTCACCGTGAACTTTGTCTCCTGGCATGCA
O * ** .**pOO*-OO ** **@ @ @ @
1587 TTCGCTTCACCTCTGCAC GTCGCATGGAGACCACCGTGAACGCCCACCAAATATTGCCCAAGGTCTTA
PheAla o o LeuHis ValALa o Arg o o
-o ArgPhe o Ser o o Arg o GluThr o o o AlaHisGlnlleLeuProLysValLeu
AsnArgGlnLeuGly MetProSerLysAspLeuTrpTrpProTyrIleArgAspGlnLeuLeu
1779 AATCGTCAACTTGGC ATGCCAAGCAAG.GACCTTTGGACTCCTTATATAAGAGATCAATTATTA
*. *O @@s *0 O *O. -.- O O .0 ** * O..**
1655 CATAAGAGGACTCTTGGACTCTCAGCAATGTCAACGACCGACCTTGAGGCA TACTTCAAAGACTGTTTGTTT HisLys o Thr o o LeuSerAla o SerThrThr o o GluAla o PheLys o Cys o Phe
ThrLys TrpGluGlu GlySer IleAspProArgLeuSerlIePheValLeuGlyGlyCysArgHis 1842 ACTAAA TGGGAGGAG GGCAGC ATTGATCCTAGATTATCAATATTTGTATTAGGAGGCTGTAGGCAT
1727 AAAGACTGGGAGGAGTTGGGGGAGGAGATT AGGTTAAAGGTCTTTGTACTAGGAGGCTGTAGGCAT
o Asp o o o Leu o GluGlu o o o LysValo o o o o o o o
LysCysMetArgLeuProm End of region 5
1908 AAATGCATGCGACTTCCGTAACCATGTATCTTTTTCACCTGTGCCTTGTTITTGCCTGTGTTCCATGTCCTACTGT 1793 AAATTGGTCTGCGCACCAGCACCATGCAACTTTTTCACCTCTGCCTAATCATCTCTrGT TCATGTCCTACTGT
o LeuValCysAla o AlaPrcCysAsnPhePheThrSerAla _ Region 8 - WHc
MetAsp11eAspProTyrLysGluPheGlySerSerTyr 1984 TCAAGCCTCCAAGCTGTGCCTTGGATIATGGACATAGATcCTTATAAAGAATTTGGTTCATCTTAT
1866 TCAAGCCTCCAAGCTG TGT TTGGACATCGACCCflATAAAGAATAGCTACTGTG
o o o o o o o o o o AlaThrVal
GlnLeuLeuAsnPheLeuProLeuAspPhePheProAspLeuAsnAlaLeuValAspThrAlaThrAlaLeuTyr
2060 CAGTTGTTGAATTTTCTTCCTTGGACTTCTTTCCTGATCTAATGC XGACACTGCTACTGCCTlAT
1942 GAGTTACTCTCGTTCl CTTCTGACTTC
AGTCAGCTCTGTAT
Glu o o Ser o o o Ser o o o o SerValArgAsp o Leu o o o Ser o o o
GluGluGluLeuThrGlyArgGluHi sCysSerProHisHi sThrAla 11eArgGlnAlaLeuValCysTrpAsp 2135 GAAGAAGAACTACAGGTAGGGACATGCTCCGCACCATACAGCTATTAGACAACTTAGTATGCTAT,.00
* .0 *.@@. .- . O .. * * 00 *-OO * O *-.0-..
2017 CGGGMGCCTTAGAGTCTCCTGAGCATTGTTCACCTCACCATACTGCACTCAGGCAGCTGG
Arg o Ala o GluSerPro o o o o o o o o o Leu o o o IleLeuo o Gly
FIG. 3-continued VOL.-41, 1982
on November 10, 2019 by guest
http://jvi.asm.org/
GluLeu ThrLysLeulleAla TrpMetSerSerAsnleThrSerGluGlnValArgThrllelleVal
2210 GAATTA ACTAAATTGATAGCT TGGATGAGCTCTAACATAACTTCTGAACAAGTAAGAACAATCATTGTA
2092 GAACTAATGACT CTA GCTACCTGGGTGGGTGTTAATTTGGAAGATCCAGCGTCTAGAGACCTAGTAGTC
o o Met o 0 o Thr o ValGlyVal o LeuGluAspProAlaSer o AspLeuVal o AsnHisValAsnAspThr TrpGlyLeuLysValArgGlnSerLeuTrpPheHisLeuSerCysLeuThrPhe
2279 AATCATGTCAATGATACC TGGGGACTTAAGGTGAGACAAAGTTTATGGTTTCATTTGTCATGTCTCACTTTC 2160 AGTTATGTCAAC ACTAATATGGGCCTAAAGTTCAGGCAACTCTTGTGGTTTCACATTTCTTGTCTCACTTTT
SerTyr o o 0 Met o o o Phe o o Leu o o 0 o Ile o o o o o
GlyGlnHisThrValGlnGluPheLeuValSerPheGlyValTrpIleArgThrProAlaPro TyrArgPro
2351 GGACAACATACAGTTCAAGAATTTTTAGTAAGTTTTGGAGTATGGATCAGGACTCCAGCTCCA TATAGACCT
*. **. ...** @ ** *
2233 GGAAGAGAAACAGTTATAGAGTATTTGGTGTCTTTCGGAGTGTGGATTCGCACTCCT CCAGCTTATAGACCA
o ArgGlu o o Ile o Tyro 0 0 0 o 0 0 0 o o o o Ala o o o
Gene 6
MetHisProPheSerArgLeuPheArgAsnIleGlnSerLeuGlyGluGluGluValGlnGluLeuLeuGly
ProAsnAlaProl1eLeuSerThrLeuPrcGluHisThrVaIlleArgArgArgGlyGlyAlaArgAlaSerArg
2423 CCTAATGCACCCATTCTCTCGACTCTAGG
2305 CCAAATGCCCCTATCCTATCAACACTTCCGGAGACTACTGTTGTTAGACGACGAGGC AGG
o o o o o o o o o o o Thr o o Val o o o o 0
o ProLeuSerTyrGlnHis o o ArgLeuLeuLeuLeuAspAsp o Ala o
ProPrcGluAspAlaLeuProLeuLeuAlaGlyGluAspLeuAsnHisArgValAlaAspAlawLeuAsnLeuHis
SerProArgArgArgThrProSerProArgArgArgArgSerGlnSerProArgArgArgArgSerGlnSerPro
2498
TCCCCCAGAAGACGCACTCCCTCTCCTCGCAGGAGAAGATCTCAATCACCGCGTCGCAGACGCTCTCAATCTCCA
. . * .**O.X * X X**... **** ... ...- *@@@@@2365 TCCCCTAGAAGAAGAACTCCCTCGCCTCGCAGACGAAGGTCTCAATCGCCGCGTCGCAGAAGATCTCAATCTCGG
° ° o o o oo o o o o o o o o o o o o o o o o o Arg
o Leu o GluGlu o o Arg o o Asp o Gly o o Arg o o o GluAsp o o o Gly
LeuProThrAlaAspLeuGlnTrpValHisLysThrAsnAlaIleThrGlyLeuTyrSerAsnGlnAlaAlaGln
SerAlaAsnCys_ End region 82573
TCTGCCAACTIGCTGTTAAGACATAAAACTAATGCTATTACAGGTCTTTACTCTAACCAAGCTGCTCAG
2440 GAATCTCAATGTTAGTATTCCTTGGACT AGGTC AACTTTACGCTTATTCTACTGTACCTGTCAsn o Gln o0
Asn o AsnValSerlIePro o Thr o o ValGlyAsnPhe o o o o o SerThrValProVal
PheAsnProHisTrpIeGlnPrcGluPhePrcGluLeuHisLeuHisAsnGluLeuIleLysLysLeuGInGIn
2649 TTTAATCCGCATTGGATTCAACCTGAGTTTCCTGAGC ACACAATG
MTTTTTCTAMAG
0...0~ ~~~~..
2516 TUTCCCTGAAAACACCATCT
TTTCCTAATACATTACAMATATG'EAACAG
0 o o o o LysThr o Ser o o Asnlle o o o GlnAsplle o o o CysGlu o
TyrPheGlyProLeuThrIleAsnGluLysArgLysLeuGlnLeuAsnPheProAlaArgPhePheProLysAla
2724TAT
IAGAAAATTGCAATTAAATTTTCCTGCAAGATTTTTCAAAGCC
2591
AGATGAGGAA
AGAGATTGAATAGATTGATATTGATTATTGCCAGG
TTTTATCCAAAGTT
PheVal o o 0 o Val o o o o Arg o o 0 IleMet o o o o Tyr o o Val
FIG. 3-continued
on November 10, 2019 by guest
http://jvi.asm.org/
WHVGENOME NUCLEOTIDE SEQUENCE 59
ThrLysTyrPheProLeulleLysGlylleLysAsnAsnTyrProAsnPheAlaLeuGluHisPhePheAlaThr 2799
AC.AAA
ATTTCTTAAMAGCATAAM
AACAATTATCCTMTGCTrAGAA C GACC2666 ACCAAATATATTA CTTCCAAACT
o o o Leu o o Asp o o o o ProTyr o o GluHisLeuValAsn o Tyr o Gln o AlaAsnTyrLeuTrpThrLeuTrpGluAlaGlylleLeuTyrLeuArgLysAsnGInThrThrLeuThrPheLys
2874 GG _GMC TGA AA
2741 ACATACGGGTCCTCATTTG
ArgHis o o His o o o Lys o o o o o Lys o GluThrThrHisSerAlaSer o Cys Gene 7 - pre S region
MetGlyAsnAsnlleLysValThrPheAsn
GlyLysProTyrSerTrpGluHisArg
GInLeuValGlnHisAsnGlyGlnGInHisLysSerHisLeuGln2949 GGTAAACCATATTC A AAACATA GA
2741
AGGTCACCATATC
MCAAGATCTACAGGGCAGAATCTTTCC ACCAGCAAo Ser o o o o o GInAspLeu o His o AlaGluSerPhe o Gln o
o o Gln o LeuSer o Ser o
ProAspLyslleAlaAlaTrpTrpProAlaValGlyThrTyrTyrThrThrThrTyrProGlnAsnGlnSerVaI SerArgGInAsnSerSerValValAlaCysSerGlyHisLeuLeuHisAsnHisLeuProSerGluProValSer
3021 A AG CG
AAGCCAGTCAGT
2876 TCC T C TGGG ATT CTTTCCC GACCAC CAG
o Ser o lie LeuPro Arg o Pro
o Leu o Phe PhePro AspHis Gln
PheGInPrcGlylleTyrGlnThrThrSerLeuValAsnProLysThrGInGInGluLeuAspSerValLeulle ValSerThrArgAsnLeuSerAsnAsnllePheGlyLysSerGInAsnSerThrArgThrGlyLeuCysSerHis
3096 GTTTCAACCAGGAATTTATA AA ACAAGAACTGGClCG TCAT
2904 TT GG ATCCAG CCTTCAGAGC AAA CAC C G C
o Gly SerSer LeuGInSer Lys His Arg
Leu AspPro AlaPheArgAla Asn Thr Ala
AsnArgTyrLysGinIleAspTrpAsnThrTrpGlnGlyPheProValAspGlnLysLeuProLeuValAsnArg
LysGlnIeGInThrAspArgLeuGluHisLeuAlaArglieSerCysArgSerLysThrThrIleGlyGInGln3171 CAAAAACTACCATTGCAACAG
2933 AAA T C C AGATTGGGAC TT CAA
TCCC
nucieotide
'GGC CAGO Ser o o GLy Ser Gln o
2957
and3b55
has o Ser0Pro 0 0 0
L~~~~~~no
homology
atall
AlaGlAspProProProLysSerAla GlnThrPheGlulleLysPrdilyProllelleValPrcGly GlySerSerProLyslIeSer SerAsnPheArgAsnGlnThrTrpAlaTyrAsnSerSerTrp 3246 GGATCCTCCCCCAAAATCAGCT CAMCTTTCGAAATCMACCTGGGCCTATMTAGTTCCTGG 3063 GG C AT A CTACAACTTT G
o His ThrThr o o
Gly lie Leu o o Leu
FIG. 3-continued VOL.41,1982
on November 10, 2019 by guest
http://jvi.asm.org/
Chain S
7 8
I. I 1llIll I IIIla IIII II
IIIIIIhiloIIVI I I 1 1 I
5
I Ia IailailI I
I IlIlI IalS II II IIu.111, , l_. _
I I I r Ir Il
6
0
Chain L
100
1 _L I I 1111u 11 lo 11 I Al1a11 I
a II II n r
( lulI I 111111 R I --I I I I I I II I
.. I I. I...a ... .1I I L I
I- Iaa
II----1 1 1I II 1I I I
I I I I11 I I I I I
I I II 11111 I 1 11 1aI
II I I
a II I11I1IaEl I1 a im Ia a
FIG. 4. Diagramshowingthe localizationofthenonsensecodonsonchains Land Sof the EcoWHV DNA. Threereading framesweredefined from the 5' end of each DNAstrand. OnchainS,frame 1 isdefinedby its first triplet AAT, frame 2is identifiedby ATT,and frame 3isidentifiedbyTTC. On chainL,frame1isdefinedbyits firsttriplet CCA,frame 2 isidentifiedbyCAG,andframe3isidentifiedbyAGG. Theviral DNAiscircular,and itslength in nucleotides(3,308)isnotamultipleof 3.Therefore,going throughtheEcoRIsite,reading in frame1 iscontinued in frame 2, readingin frame 2 is continuedinframe3,andreading in frame 3 is continued in frame 1. Upper vertical bars indicatestopcodons;lower vertical barsrepresentATGtriplets.AsfortheHBVgenome, numbers1, 5, 6, 7, and8defineareaswithanopenreadingframeofatleast 100triplets. Region1 goesfrom 1,719to1,179; region 5goesfrom1,467to1,926; region6goesfrom2,382to3,308and from1to1,756; region7
goesfrom2,983to3,308 and from 1to962;andregion8goesfrom1,910to2,585. WHVLchainmight therefore indicate that they
existby chance in the HBVgenomeand do not
correspondtoaparticular viralgene. Itis harder to estimate the significance of region 1. In the WHVgenome,the firstin-phase ATGwas
locat-edonlyafewresiduesahead ofstopcodon TAA 1,182 closing the open region 1, and no GUG
(which could beanalternateinitiator codon)was
present upstream. The absence of a potential
initiator codon indicates that region 1 cannot codeby itself foraviral protein but would have
tobe splicedtoa5'leader segment.
Nucleotide and amino acid sequence
compari-son. Usingthe computerprogram NSEQFITN,
developed by Staden (17), the nucleotide
se-quences of the HBV and WHV genomes were
compared. The twosequences were largely
ho-mologous, in therangeof 62to70%allalong the
genome, except in two regions: one centered
aroundthe EcoRI site, wheremostof the
differ-ences inlength were encountered, and one
be-tweenregions 6 and 8,correspondingtoapartof region5(Fig. 3). Although therewerenoamino
acid dataonthe WHVproteins (which could be
used) to locate the genes as has been done for
HBsAg, the very similar open reading frames
and the large degree of homology sequence
sharedby thetwovirusesaresuitablearguments
forlocalizing thegeneforhomologous protein in ahomologousopenregion andcomparingthem
atthe nucleotide and amino acid levels. Region 7. The open reading frame of region 7
went from nucleotide 2,983 through the EcoRI siteuptoTAA 962 andmoreprobablygaverise
2
3
6
IaIfIIII III I I 1111 IIII alaII
100
2 11 AM I
I II
-3
0
a I Ill II
II-T
I I
I N I a am a
.9'
I I I I II I1I I 1
a I I.. . . _ . ... I .... . . . II oIIa.... II a II
I I
I 11I I Ian 1S1111 1I11
I 11 I I I I
. . .. Aaaa I . I 1A 11 a I
-- ' I 11 11 I I
on November 10, 2019 by guest
http://jvi.asm.org/
[image:10.504.54.456.64.494.2]WHV GENOME NUCLEOTIDE SEQUENCE 61
by translation from ATG 2% to the viral enve-lope protein (Galibert et al., in press) called the WHsAg protein. As in the case of the HBV genome, the ATGcorresponding to the N-termi-nal methionine was preceded by a large open readingframe, calledthe pre-Sregion, in which there were two ATG. Region 7 of WHV could then codefor proteins of 426 and/or 282 and 222 amino acids, and region 7 of HBV could code for proteins of 389 and/or 281 and 226 amino acids. This is more than a coincidence and suggests that the pre-S region codes for some proteins. Although a high degree of homology was found in nearly all parts of the two genomes, it is remarkable that one of the tworegions of large divergence started around nucleotide 2,980 (WHV) and went up to nucleotide 215, almost exactly corresponding to the pre-S region.
As a resultof this large difference at the DNA level, littlesequencehomology at the amino acid level was observed. However, both putative amino acid sequences revealed the presenceof the sequence Asn-X-Thr, known as the glycosy-lation site. What is moreinteresting, these se-quences occupiedasimilarposition.They were encounteredat-58fromthe WHsAg N methio-nineand at -52fromthe HBsAg Nmethionine. This putative glycosylation site was in both cases located very close to the second methio-nine of the pre-S region. Some other common featuresof thispre-Sregionaredepicted in Fig. 6, and more can be seen inFig.3.Translation of thepre-Sregionof the twovirusescouldgivea
proteinwith alargeamountofproline residues (26 for the WHV protein and 20 forthe HBV
protein) and no cysteine residue, which might indicate that this part of the protein could be more like a randomcoil with a low amount of secondary structure. The significance of the amino acid sequence coded by the pre-S region is not clear. Does it represent the extra sequence ofanenvelope protein precursor, or is it part of aminor component of the viral coat? Its poorly conserved status during evolution, whereas in the meantime the S region is well conserved (Galibertetal., in press), suggests that the pre-S region codes for the extra sequence of a precur-sormolecule (15).
Region
6. In both viruses, region 6 covered nearly 80% of the genome. From the first ATG (2,427) up to the stop codon TGA 1,756, a protein of 879 and 838 amino acids could be predicted forWHV and HBV. The use ofthe secondATG as an initiatortriplet is less proba-ble, since it would reduce the sizeoftheprotein to 371 and 400amino acids, respectively.Region6,like region 7, overlapped the EcoRI site. Therefore, the percentage of homology varied greatlyall along the DNA and amino acid sequences. From the first methionine up to
amino acid 23 of the WHV protein, the se-quencesof the twoproteinswerequite different. However, it is noticeable that the DNA
se-quences were better conserved than the amino acid sequences. Startingwith ATG 2,427, 37 of thefirst 54nucleotides were identical, whereas this was truefor only4of 18 amino acids. This divergence in the percentage of homology
be-tweenthe amino acid and nucleotide sequences probably indicatesthat theproteins codedbythe
6
5~~'
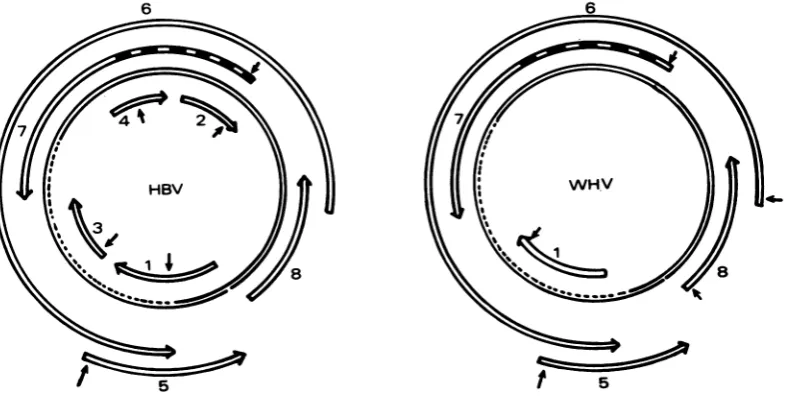
FIG. 5. Localization of the openreadingframesonthe viralgenome and comparison with the HBV genome (9).Thestrippedareainregion7correspondstothepre-Ssequence. Arrows indicated the position of the first ATG found withinanopenreadingframe.
VOL.41, 1982
on November 10, 2019 by guest
http://jvi.asm.org/
[image:11.504.65.459.448.647.2]1 87
W-V Met Gly Asn Asn Ile. . Thr . Asn Pro Pro Pro Pro-HBV Met Gly Gln Asn Leu . Thr . Asn Pro Pro Pro Pro
-1 81
99
Pro . Pro ... Pro Pro . Pro .. Pro Pro 94
145 164 205
Met . . Asn Gln Thr PheHis Thr Thr Thr et Hs Met . . Asn Ser Thr Phe His Ser Ser Ser Met HBs
[image:12.504.87.409.58.241.2]109 135 TU
FIG. 6. Some common characteristic features of theputativeproteins madefrom thepre-Sregionofboth
viruses.
overlappinggene 8 couldnotevolveasmuch as the protein coded by gene 6. It also indicates that, by virtue of the code degeneracy, a
se-quenceofnucleotideswhich codes intwo
differ-entframes fortwodifferentproteinscanevolve insuch a way that oneproteinis well conserved whereas the other is less so.
The two sequences then became muchmore
similar, and 90 amino acids of 162were identi-cal. After this, the sequences again diverged completelyat the DNA and amino acid levels. As previously noted, the difference in size be-tweenthe twovirus genomeswasmainlydueto
differences located in this region which could code for 183 and 140amino acids. Finally, the sequences again became similar atthe nucleo-tide and aminoacidlevels. Ofthe 515remaining aminoacids, 309 were identical.
Althoughthere is no direct argument indicat-ing that region 6 codes for a viral protein, the sizeof such a nucleotide sequence devoid in one readingframe of a stop codon leaves little doubt about the coding function of this region. In this respect, it has been suggested that the DNA polymerase found within the virion could be codedby gene 6 (8). If this istrue, the existence of a large piece of DNA centered around the EcoRI site and devoid of homology between the twoviruses ispuzzling. How is it that this piece of DNAhasevolved so rapidly in sequence and size withoutaffecting the biological property of thecorresponding protein? In the case of gene 7, because of its location, we have suggested that this piece of DNA could code for the extra sequence of a precursormolecule. Another ex-planation could be suggested for gene 6, namely, the existenceof an intron sequence eliminating a region which therefore can evolve more rapidly. However, no sequence resembling the consen-sussequence(often found at the border of many
intronsequences) can be found in the HBV and WHV sequences in support of this hypothesis (1, 3, 10).
Region 8. Region 8 was open from nucleotides 1,910 to2,585, and it corresponded in position, length, and sequence to region 8 of the HBV genome which codes for the HBc protein (8, 14). Several ATG were observed atthebeginning of this open reading frame, and thus the initiator triplet washardto locate. From the firstATG,
common to the two sequences and located at
positions1,931 and1,816,respectively,aprotein of 225 and 219 amino acids could be made.This isslightly above the value which can be calculat-edfrom the molecularweight of the HBc protein
asmeasuredby gelelectrophoresis. Translation from the second common ATG located at posi-tions 2,021 and 1,903 therefore seems more probable and would also agree with the results of Valenzuela et al. (20), who found a TGA stop codon instead ofaTGG twotripletsupstream of this secondATG.
Upon comparison, the nucleotide sequences downstream of ATG 2,021 and 1,903 and the predictable amino acid sequences were well preserved in the two viruses. This finding is in agreement with the results ofWerneret al. (21), who havedemonstrated by an immunodiffusion test thatHBc and WHc proteins have common antigenicdeterminants.
Table 1 shows characteristic features of the genes and their products. Due to the large amount ofsilent mutations, the homology ob-served between the two amino acid sequences washigher than that observed between the nu-cleotide sequences. An apposite result was ob-tained with geneS coding for the surface antigen (Galibertetal., in press). This wasprobably due tothefact that the sequence coding for the core protein does not code for another protein,
on November 10, 2019 by guest
http://jvi.asm.org/
WHV GENOME NUCLEOTIDE SEQUENCE 63 TABLE 1. Comparison of HBc and WHc genes and products
Residues Silent Length Amino acids
Gene Length No. %
Triplets
mutated: Deleted Insertedmuta-
of No. %triplets triplets tos poly- ie-Hml
iden- Homol- Once Twice Thrice peptide ticai omy
HBc 549 363 66 69 32 14 10 5 74 183 131 73
WHc 564 122 64 188
transversion 122 transition 64
Amino acids change within
Polar* NP Uncharged +Charged
9 15
whereas the sequence coding for the surface
proteincodesforanother protein, allowing less
freedom in the evolution of the latter DNA
sequence.
Aspreviously noted,thecoreprotein
exhibit-ed a particular structure at its carboxy end,
which is veryrich inproline and arginine
resi-dues (8). Eleven proline residues outof the last
60 residues and 16 arginine out of the last 34 residuescould be observed in theHBc and WHc
proteins. The repeat Ser-Pro-Arg-Arg-Arg-Arg-Ser-Gln previously noted at the carboxy endof the HBc proteinwasalsoobservedatthe
endof the WHcprotein.
Region5. Region5was openfrom nucleotide
1,467 up to stop codon TAA 1,926. The first
ATG was found at position 1,503, giving a
codingcapacity foraprotein of141amino acids.
Similarly, in the HBV genome, there was an
openreading frame fromnucleotide 1,340upto
TAA1,838 which could be translated from ATG 1,376 in aprotein of 154 amino acids.
Thereisat presentnodirectargument indicat-ing that region 5correspondstoaparticular viral
gene. However, several indirectarguments
sug-gest this quite strongly. (i) These two open
Basic Acid
2
reading frames occupied identical positions
withinthetwogenomeswithrespect tothe other
open regions and the nick of the L strand. (ii)
They could give rise totwo proteins of similar size. (iii) A third, more convincingargument is based on comparison of the amino acid
se-quenceswhich could be deduced from theDNA
sequences. Region 5 was read in frame 2 and was overlapped halfway down by region 6,
whichwasreadin frame3.Translationin frame
3 fromnucleotide 1,464tonucleotide 1,551gave anamino acidsequencesharingalarge degree of
homology with the correspondingHBVgenome:
11of13amino acidswereidenticalupstreamof
ATG 1,503, and 14 of16 were identical
down-streamof ATG. On thecontrary, translation in frame 2gave adifferent result:upstreamof ATG 1,503, only 1 of 12 amino acids was identical,
and16 of16wereidentical downstreamof ATG
1,503(Fig. 7). Thisdrastic change in the
conser-vation of the amino acidsequenceindicates that
another protein is made starting from ATG 1,503,in frame2. Italsoindicates,aspreviously
noted, that selective pressure on a particular gene does not greatly influence the coding
ca-pacity ofthevery samesequenceread inanother
Gene 5
Frame 2 Phe Arg Gly Val Val Gly Glu Ala Asp Val Leu Ser Met Ala Frame 3 Asn Ser Val Val Leu Ser Gly Lys Leu Thr Ser Phe Pro Trp Leu
TAATTCCGTGGTGTTGTCGGGGAAGCTGACGTCCTTTCCATGGCTG
~~~~~~~~~~~~~.
. . ... . ... . .*. ...*.*...*. TAAC TC TGTTGTCC TATC CCGC AAATATACATCGT T TCCATGGC TG
o o o o o o Arg o Tyr o o o o o o
Leu Cys Cys Pro Ile Pro Gln Ile Tyr Ile Val o o o
Ala Arg Leu Cys Cys Gln Leu Asp Pro Ala Arg Asp Val Leu Leu Ala Cys Val Ala Asn Trp Ile Leu Arg Gly Thr Ser Phe
CTGGCCTGTGTTGCCAACTGGATCCTGCGCGGGACGTCCTTC
. . . .
CTAGGCTGTGCTGCC AACTGGATCCTGCGCGGGACGTCCTTT
o Gly o Ala o o o o o o o o o. o
0 0 0 0 0 0 0 0 0 0 0 0 0 0
FIG. 7. Nucleotide sequence ofthe two virusesaround thefirst ATGofregion5. Translation inframes2 (region 5)and3(region 6)from the WHVsequence iscomparedwith thecorrespondingsequencesfound inthe HBV genome. Translation inframe 2 downstream of ATGgivesa proteinwhich resembles very much the homologous proteinmade from the HBV genome.
Identical group 21 VOL.41,1982
on November 10, 2019 by guest
http://jvi.asm.org/
[image:13.504.54.448.82.192.2] [image:13.504.53.451.497.634.2]WHV
2992
1756 2427
1503 1926
5
1376 1838
I
1623 a
I I -4
'2021 2585 8
1903 2452 2309
HBV
FIG. 8. Comparison of the organizationof thetwo genomesshowingthatonlyoneregionlocated between
regions5and 8 is devoid of coding function.
frame. Otherwise, the selective pressure made
on gene 6 upstream and downstream of ATG
1,503 could likewiseinfluence thetranslation in
frame 3upstreamand downstream ofthis ATG.
Comparison of the nucleotide sequence of
gene5and of itscorresponding protein showed
that they were less conserved than the se-quencesof othergenes.After the first stretch of
amino acids, which was identical in both pro-teins and was used as an argument to demon-strate theexistence ofgene5, the twoproteins became verydifferent, and several deletionsor
insertionsmustbepostulatedin the centralpart ofthe molecule to align43 amino acids outof
115. However, apotential identical secondary
structure could be predicted from the identical
HBV
positionsof several aminoacids suchasPro-Cys and Gly. Finally, near by the carboxylic end, which seemed to accumulate acid and basic
aminoacids,anidenticalnonapeptide
(Phe-Val-Leu-Gly-Gly-Cys-Arg-His-Lys) was
encoun-tered.
Region 1. Region 1 lay on the other DNA strand and, as we observed previously in the
HBV sequence (8), was devoid of a potential
initiator codon. Comparison ofthe nucleotide
sequence ofregion1 of thetwoviruses showed
thattheywerecompletelydifferent. Asamatter offact,theywerenotlocatedexactlyatthesame
position within thetwo genomes butabout 200
nucleotides away.Therefore,itmaybe
conclud-ed thatthey exist by chance and do not
corre-WHV
G T G T
T G T G
c c c c
G-C G=C
A =T A=T
A=T A=T
C G C-G
C--G CmG
T-G T=AT
C-SG C §G
C-=G c-G
G-C G-C
A =T A=T
,G T T C A T T G G G, G T T C A T T G G G
FIG. 9. Twopossiblehairpin structureslocated in theonly region devoid of coding function.
7 962
6
6
2850 7 835
r---i
A I
on November 10, 2019 by guest
http://jvi.asm.org/
[image:14.504.81.450.112.273.2] [image:14.504.129.384.497.665.2]WHV GENOME NUCLEOTIDE SEQUENCE 65
spond to aparticular viral gene. It can also be inferred that there are only four viral genes, all located onthe L strand.
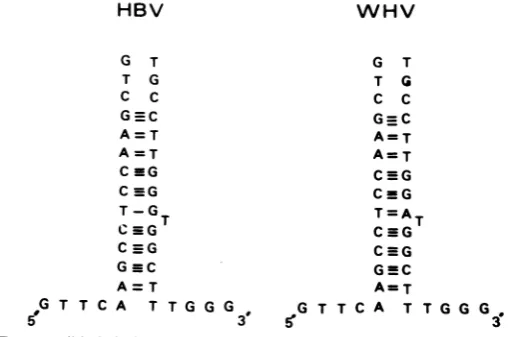
Location of the nick and the origin of replica-tion. Figure 8displays thevarious open reading frames from their putative initiator ATG triplets to their stop codons. As already noted, they overlapped each other without leaving any gap except between regions 5 and 8, where there was asmall sequence, devoid of coding function, in both viruses. Interestingly, comparison of these two nucleotide sequences indicated they were very well conserved even though they have no coding function. These nucleotide sequences also exhibited a palindromic structure able to form a hairpin structure with quite stable energy
(Fig.
9).
According to the location of the L-strand nick, as determined by gel electrophoresis (5, 6) for bothviruses, andthe length of the genome, one may calculate that the nick could be located in the HBV sequence around nucleotide 1,846 and in the WHV genome, around nucleotide 2,011, which means exactly within the only region devoid of coding function. These four results, i.e., absence of coding function, highly pre-served DNA sequence, hairpin structure, and position of the nick, are all consistent with the location of the origin ofreplication of the viral DNA inthisparticular sequence.
ACKNOWLEDGMENTS
Weare very muchgrateful to J. Summers, who gave us the EcoWHV cloned DNA.
Thiswork was supported by a grant from the Institut de la Santeetde la Recherche Medicale.
LITERATURECITED
1. Breathnack,R., C.Benoist, K.O'Hare,F.Gannon,andP. Chambon. 1978. Ovalbumingene: evidence foraleader sequence in mRNA and DNA sequences at the
exon-intronboundaries. Proc. Natl. Acad.Sci. U.S.A. 75:4853-4857.
2. Burrel, C. J., P. Mackay, P. J.Greenaway,P. H. Hof-schneider, and K.Murray. 1979.Expressionin Escheri-chia coli ofhepatitisB virusDNA cloned inplasmidpBR 322. Nature(London)279:43-47.
3. Catterall, J. F., W. 0. O'Malley,M. A. Robertson, R. Staden,R.Tanaka,andG. G.Brownlee. 1978. Nucleotide sequence homology at 12intron exonjunctions in the chick ovalbumingene. Nature(London)275:510-513. 4. Charnay, P., E. Mandart, A. Hampe, F. Fitoussi, P.
Tiollais, andF.Galibert. 1979. Localizationonthe viral genomeandnucleotidesequence ofthegenecodingfor
thetwo major polypeptides of the hepatitis B surface antigen (HBsAg). Nucleic Acids Res.7:335-346. 5. Charnay,P., C. Pourcel, A. Louise, A. Fritsch, and P.
Tiollais. 1979. Cloning in Escherichia coliandphysical structure of hepatitis B virion DNA. Proc. Natl. Acad. Sci. U.S.A. 76:2222-2226.
6. Cumming,I. W.,J.K.Browne, W. A. Salser, G. V.Tyler, R. L. Snyder, J. M. Smolec, and J. Summers. 1980. Isolation, characterization and comparison of recombi-nant DNAs derived from the human hepatitis B and woodchuck hepatitis virus genomes. Proc. Natl. Acad. Sci. U.S.A. 77:1842-1846.
7. Fritsch, A., C. Pourcel, P. Charnay, and P. Tioliais. 1978. Clonagedu virus del'hepatiteBdans Escherichia coli. C.R. Acad. Sci.287:1453-1546.
8. Galibert, F., E. Mandart, F. Fitoussi, P. Tiollais, and
P.Charnay.1979.Nucleotide sequence of thehepatitisB virus genome (subtype ayw)cloned in E. coli. Nature (London)281:646-650.
9. Hartley, J. L., and J. E. Donelson. 1980. Nucleotide sequence of the yeastplasmid. Nature (London) 286:860-864.
10. Herisse, J.,G.Courtois,andF.Galibert. 1980.Nucleotide sequence of the EcoRI D fragment of Adenovirus 2 genome. Nucleic Acids Res. 8:2173-2191.
11. Marion, P. L., L. S. Oshiro, D. C. Regnery, G. H. Scullard, and W. S. Robinson. 1980. A virus inBeechey ground squirrels that is related to hepatitis B virus of humans. Proc. Natl. Acad. Sci.U.S.A. 77:2941-2945. 12. Mason, S. W., G. Seal, and J. Summers. 1980. Virus of
Pekin ducks with structural andbiological relatednessto
human hepatitis B virus. J. Virol. 36:829-836.
13. Maxam, A., and W. Gilbert. 1980.Sequencing end labeled DNA with base specific chemical cleavage. Methods Enzymol.65:499-560.
14. Pasek, M., T. Golo, W. Gilbert, B. Zink, H. Schaller, P. McKay, G. Leadbetter, and K. Murray. 1979. Hepatitis B virus gene and theirexpression in E. coli. Nature 282:575-579.
15. Perler, F., A. Efstratiadis, P. Lomedico, W.Gilbert, R. Kolodner, and J. Dodgson. 1980.The evolution of genes: thechickenpreproinsulingene.Cell 20:555-566. 16. Sninski, J. J., A. Siddiqui, W. S. Robinson, and S. N.
Cohen. 1979. Cloning and endonucleasemapping of the hepatitis B viral genome. Nature (London) 279:346-348. 17. Staden, R. 1977. Sequence datahandling by computer.
Nucleic Acids Res.4:4037-4051.
18. Summers, J., J. M. Smolec, and R.Snyder.1978. Avirus similar to humanhepatitisB virus associated with hepati-tis andhepatoma in woodchucks. Proc. Natl. Acad. Sci. U.S.A.75:4533-4537.
19. Valenzuela, P., P. Gray, M.Quiroga, J.Zaldivar,H.M. Goodman,and W.J.Rutter. 1979.Ntucleotide sequence of the genecoding for the majorproteinofhepatitisBvirus surfaceantigen.Nature(London)280:815-819. 20. Valenzuela, P.,M.Quiroga,J.Zaldivar,P.Gray,and W.
J. Rutter. 1981. The nucleotide sequence of thehepatitisB viral genome and the identification of the majorviral genes. In B. Fields, R. Jalnisch, and C. F. Fox(ed.), Animal virusgenetics.AcademicPress, Inc.,New York. 21. Werner, B. G.,J. M.Smolec,R.Snyder,and J. Summers. 1979. Serological relationship of woodchuck hepatitis virusto humanhepatitis B virus. J. Virol. 32:314-322. VOL.41,1982
on November 10, 2019 by guest
http://jvi.asm.org/