Rochester Institute of Technology
RIT Scholar Works
Theses
Thesis/Dissertation Collections
9-1-1999
Guaranteed bandwidth implementation of message
passing interface on workstation clusters
Ali Atalay
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion
in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact
Recommended Citation
Approved by:
GUARANTEED BANDWIDTH
IMPLEMENTATION
OF MESSAGE PASSING INTERFACE
ON WORKSTATION CLUSTERS
By
Ali S. Atalay
A Thesis Submitted
in
Partial Fulfillment of the
Requirements for the Degree of
MASTER OF SCIENCE
in
Computer Engineering
Graduate Advisor - Muhammad E. Shaaban, Assistant Professor
Roy Czemikowski, Professor
Tony
R
Chang, Professor
Department of Computer Engineering
Kate Gleason College of Engineering
Rochester Institute of Technology
Rochester, New York
3
/lo[_~_~
_ _
Thesis Release Permission Form
Rochester Institute of Technology
College of Engineering
Title: Guaranteed Bandwidth hnplementation of Message Passing Interface On
Workstation Clusters.
I, Ali Serdar Atalay, hereby grant permission to the Wallace Memorial Library to
reproduce my thesis in whole or in part for non-commercial uses.
Signature:
_
ABSTRACT
Due
to theirwideavailability,networksofworkstations(NOW)
are an attractive platformfor
parallel processing.Parallel programming
environments such asParallel
VirtualMachine
(PVM),
andMessage
Passing
Interface
(MPI)
offertheusera convenientway
toexpressparallel
computing
andcommunicationfor
a network of workstations.Currently,
a number of
MPI implementations
are available that offerlow (average
)
latency
andhigh bandwidth
environments to usersby
utilizing
an efficientMPI
library
specificationand
high
speed networks.In
addition tohigh bandwidth
andlow
averagelatency
requirements, mission criticaldistributed
applications, audio/video communications require acompletely different
typeof service, guaranteed
bandwidth
and worst casedelays (worst
caselatency)
tobe
guaranteed
by
underlying
protocol.The hypothesis
presentedin
this paperis
thatit is
possible to provide an application a
low
level
reliable transport protocol withperformanceand guaranteed
bandwidth
as closeto thehardware
on whichit is
executing.The
hypothesis is
provenby designing
andimplementing
a reliablehigh
performancemessage
passing
protocolinterface
which also providestheguaranteedbandwidth
toMPI
andto mission critical
distributed MPI
applications.This
protocolinterface
works withthe
Fiber
DistributedData Interface
(FDDI)
driver
whichhas been designed
andimplemented for Performance
Technology
Inc.
commercialhigh
performanceFDDI
product, the
Station
ManagementSoftware
7.3,
andtheADI / MPICH (Argonne National
Laboratory
and MississippiState
University's
free
MPI
implementation).
Inthisthesis,the
latency
referstoaveragetimeittakes to transfera messagefromthemomentthesendoperation startstothetimewhenthereceiverreceivesthepacket.Worstcase
latency
isthelongesttimeAcknowledgements
I
amindebted
toProfessor,
Roy
Czernikowksi,
whohelped
mefinishing
writing
ofmy
thesis andthe paper.
I
am gratefulfor his
support.He
reviewedmy
thesismany times,
and corrected
my
grammatical errors.I
wouldlike
to thank tomy
advisor,Professor
Shaaban,
who was always available withhis
valuable comments and support.Special
thanks to other thesis committee member,Professor
Chang
for reading my
thesis.The
coursesI
tookfrom him helped
meduring
thedevelopment
ofthis thesis.I
owe a greatdepth
tomy
previousboss,
my forever
friend,
John
Grana
who assigned meall the toughest
device driver
projectsin my junior
years atPerformance Technologies
Inc.
whereI learned
theUNIX
device driver
development,
protocolinternals
withhands
onassignments.
I
am grateful tomy beloved
girlfriendElcin. She
was sokind
and understanding.She
visited me so
many
times whileI
can not affordto visither
even onceduring
this thesiswrite-up.
Most
of all,I
wouldlike
todedicate
this thesis to thememory
ofmy
father,
"CengizTable
ofContents
TABLE OF CONTENTS I
ListofFigures m
ListofTables rv
Glossary v
1. INTRODUCTION 1
l.l General 1
1.2 Motivation 4
1.3 Deliverables 8
1.4 Methodology 8
1.5 Results 9
1.6 Thesis Overview 10
2. BACKGROUND 12
2.1 NetworkofWorkstations
(NOW)
122.2 Fiber Distributed Data Interface
(FDDI)
and its intereace toMPIGB 142.3 ParallelDevelopment Tools 19
2.3.1 PVM 19
2.3.2 MPI 21
2.3.2.1 MPICH 23
2.3.2.2 LAM 26
2.4 MPI-GBandRelatedwork 27
2.4.1 Hardware Based Solutions 28
2.4.2 SoftwareBased Solutions 28
FastSockets[34]: 29
FM[8]: 30
U-Net[33]: 31
NCS[12]: 32
fbufs[31]: 33
3. MPI-GB DESIGN 34
3.1 MPI-GB Design Methodology 34
3.2 MPI-GB PacketStructures:
MPI,
GB Packet Header. IEEE 802.3 Encapsulation 343.2.1 NotationalConventions 34
3.2.2 MPI-GBPacketandFDDIEncapsulation 36
3.3 MPI-GBProtocol Description 40
3.3.1 Initialization 40
MPI-GBJNTT 40
MPI-GB_COMMTT(GB_resource_struct*) 42
3.3.2 GB ProcessesandComponents 43
3.3.3 MPI-GBADI 46
3.3.4 Buffers,PacketsandMessagesandMessage Queues 54
3.3.5 Synchronous Bandwidth AllocationandBandwidth Reservation 56
3.3.6 Message Prioritizationand
Scheduling
for Synch/Asynchronous Traffic 593.3.7 Flow/RateandError Detection 61
3.3.8
Multicasting
633.3.9
Mmap
vsStreams 633.3.10 MPI-GB ADI Primitives 66
3.3.11 Three MPI-GB Solutions 69
3.3.11.1 Streams Raw Fast IP Socket Interface Model 69
3.3.1 1.2 Streams DLPI Raw Interface Model 72
4. PERFORMANCE ANALYSIS OF MPI-GB 78
4.1 Test ConditionsandMeasurementmodel 78
4.2 Performance Metrics 80
4.3 PointtoPoint Benchmarkprograms 83
4.3.1
Roundtrip
(Ping-Pong) Delay
measurements 834.3.2 Bandwidth Measurements 86
4.3.3 Percentage of missing deadlinespackets 88
4.4 Collective Communication
(Broadcast)
Measurements 904.5 Real World Example: Distributed Ray Tracing 91
5. CONCLUSIONS 92
5.1 AccomplishmentsandSummaryofStudy 92
5.2 Future Work 97
REFERENCES 99
APPENDIX 103
mpi-gb adiinterface header file 103
Performance Analysis Testcodes 107
Roundtrip
Latency
107Bandwidth 113
Percentage of missing deadlinespackets 118
Sender 118
List
ofFigures
FIGURE 1: MPI-GB MODEL 4
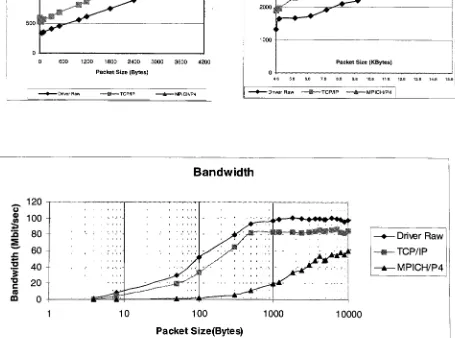
FIGURE 2: PING- PONG LATENCY FOR RA
W, TCP/IPAND MPI APP. 5
FIGURE 3: BANDWIDTH FOR RAW,TCP/IP AND MPI APPS. 5
FIGURE 4: TCP/IP BANDWIDTH FOR SBUS AND PCI WORKSTATION PAIRS 13
FIGURE 5: TCP/IP LATENCY FOR SBUS AND PCI WORKSTATION PAIRS 1 3
FIGURE 6: TYPICAL FDDI TOPOLOGY 1 4
FIGURE 7: OSI AND FDDI MODEL 1 5
FIGURE 8: BUFFER MANAGEMENT IN FDDI DEVICE DRIVER 17
FIGURE 9: FDDI DEVICE DRIVER SOFTWARE LAYERS 18
FIGURE 10: MPICH LAYERS. 22
FIGURE 11: CHANNEL INTERFACE 24
FIGURE 12: LATENCY FOR MPICH AND LAM 26
FIGURE 13: CLASSIFICATION OF HIGH PERFORMANCE MESSAGE-PASSING SCHEMES 28
FIGURE 14: DATA TRANSFER VIA RECEIVE POSTING (TRUE ZERO COPY DATA
TRANSFER)
30FIGURE 15: DATA TRANSFER IN FAST SOCKETS. 30
FIGURE 16: TOP LEVEL MPI-GB DESIGN BLOCKS 34
FIGURE 1 7: TOP LEVEL MPI-GB DESIGN BLOCKS 37
FIGURE 18: LLC AND SNAP HEADER USED IN MPI-GB 37
FIGURE 19: MPI HEADER 38
FIGURE 20: GB HEADER 39
FIGURE 21: INWARD ARCHITECTURE OF GB 43
FIGURE 22: GB STATES 46
FIGURE23: MPI TO GB SEND FLOW 47
FIGURE24: MPI TO GB RECEIVE FLOW FOR BLOCKING RECEIVE 5 1
FIGURE 25: SBA STATE MACHINE DIAGRAM 57
FIGURE26: SBA -ESS RELATION
5 8
FIGURE 27: UNIX SYSTEM V STREAMS INTERFACE 64
FIGURE 28: RAW IP SOCKET IMPLEMENTATION OF MPI-GB 1 1
FIGURE29: STREAMS DLPI INTERFACE MODEL IMPLEMENTATION 74
FIGURE30: MMAP MODEL OF MPI-GB 11
FIGURE 31: ROUND TRIP LATENCY OF MPI-GB FOR SHORT AND LONG PACKETS 84
FIGURE 32:ROUNDTRIPLATENCY FOR MPICH-P4 AND MPI-GB DURING 20MBIT/SEC TTCP
LOAD GENERATED AT THEWORKSTATIONS. 85
FIGURE 33: WORST CASE LATENCY/AVERAGE LATENCY RATIO DURING 20 MBIT/SEC TRAFFIC
86 FIGURE34: MPI-GB,
TCP/IP,
MPI-CHP4 BANDWIDTH FOR DIFFERENT PACKET SIZES. 88List
ofTables
TABLE 1: ADI CORE ROUTINES 23
TABLE2: CHANNEL INTERFACE ROUTINES 24
TABLE3: MPI HEADER FIELDS 38
TABLE 4:
REQ
UEST INFORMATION FIELDS 48TABLE 5: NON-BLOCKING SEND WITH MPI-GB 50
TABLE 6: NON-BLOCKING RECEIVE WITH MPI-GB 52
TABLE 7: NON-BLOCKING RECEIVE IS POSTEDAFTERTHE MESSAGE ARRIVES TOMPI-GB 55
TABLE8: PAYLOAD SYNCHRONOUS UNIT CORRELATION 58
TABLE 9: MPI-GB API 67
TABLE 10: GB API 68
TABLE 11:"PTI"
TEST BED WORKSTATIONS USED IN THISTHESIS- 78
TABLE12: "BENCH"
Glossary
ADI[20]
:Abstract Device Interface.
ATM[
1
9]
:Asynchronous Transfer Mode.
DLPI[
1
6]
:Unix
Systems Laboratories Data Link Provider Interface
specification.DMA:
Direct
Memory
Access.
ESS:
End Station Service: Client
toSBA.
FDDI[6]
:Fiber Distributed Data
Interface.IETF[37]
:Internet
Engineering
Task Force.
IP[35]:
Internet Protocol.
LAN:
Local Area Network.
LAM[
1
7]
:Ohio
Supercomputing
Center MPI implementation.
LLC:
Logical Link Control.
MAC:
Media
Access Control Sublayer.
MMAP:
Memory
mapping.MPI:
Message
Passing
Interface.
MPI-CH[2]
:Argonne MPI implementation.
MPI-FM[8]:
University
ofIllinois,
Fast
Messages implementation
ofMPI
MPI-GB
:Guaranteed
bandwidth implementation
ofMPI.MPI-RT[4]
: RealTime
MessagePassing
Interface
Specification.
MPP:
Massively
Parallel
Processor.
MTU[3
7]
: Maximmum TransmissionUnit
NOW[34]
:Network
ofWorkstations.
NIC:
Network Interface Card.
OSI[37]:
Open
System Interconnection
P4[l
8]
:Parallel
Programming
System developed Argonne National
Laboratory
in
1990.
PHY[6]:
PhysicalLayer.
PMD[6]
:Physical Media Dependent.
PTI:
Performance
Technologies Inc.
RTP[37]
:Real Time Protocol.
QoS
[38]
:Quality
ofService.
SBA[6,7]:
Synchronous Bandwidth
Allocation.SNAP:
Sub-Network Access Protocol.
SMT[6]
:ANSI FDDI
Station Management
Software.SU[6,7]:
Synchronous Units
TCP[35]
:Transport Control
Protocol.TTCP[35]:
Benchmarking
tool,
used as aload injector in
this work.TLB:
TranslationLookaside
Buffer.UDP[37]
:User
DatagramProtocol
WAN:
Wide Area
Network.1.
Introduction
1.1
General
Workstation
clusters areincreasingly being
used as cost-effective parallel computingplatforms.
These
parallelprogramming
environments offer theuser a convenientway
toexpressparallel computationandcommunication.
A
number oflibraries
suchasPVM
[1],
MPI
[2]
arealready
availabletoprovide parallelcomputing
environments on a workstation clusters.MPI
[2]
is
alibrary
specificationfor
message passing, proposed as a standard
by
abroadly
based
committee of vendors,implementers
and users.This
standard andits
extensions,MPI II
andDraft
MPI/RT
[3-4],
feature
a range offunctionality,
including
point-to-point communication withsynchronous and asynchronous communication modes, and collective communication.
MPI
basically
is designed
to giveMPI implementers freedom in choosing exactly how
and when
data
is
movedfrom
one processto another.Among
MPI
implementations,
MPICH
[5],
developed
by
Argonne National
Laboratory,
stands out as portable, and allows
higher
performance than other availableimplementations.
MPICH
is built
on alower level
communicationlayer
calledAbstract
Data
Interface(ADI). ADI defines low-level
communication-relatedfunctions
that canbe
implemented
in different
ways ondifferent
machines.This interface is designed
tosupport multiple
devices
(e.g., TCP/IP,
andsharedmemory) in
asingleMPI
application.Abstract
Data
Interface(ADI)
contains routinesfor packetizing
the messages andattaching
theheader
information,
managing
multiplebuffering
policies,matching
postedof
MPICH handles
therest oftheMPI
standard,including
the managementofdata types,
and communicators, andthe
implementation
ofcollective operations with point-to-pointoperations.
(Figure 10). More information regarding MPICH
andADI
canbe found in
chapter
2. The device implementations
aretypically
built
ontop
oftheTCP/IP
protocolstack
because
ofits
wide usage.The
performance offeredby
TCP/IP
andconsequently delivered
to thelibraries
is
notacceptable since
both
the protocolitself
andits
traditionalimplementations
within theoperating
system weredesigned for
objectiveslike
tolerance tohigh
latency
andhigh
error rates rather than
low
latency
andhigh bandwidth. These
communication protocolsrequire anumber of servicesto work,
like timers, buffer
management, processprotection,andprocess notification.
Besides,
these protocol stacks come as a part oftheoperating
system, require a message
copy
anddo
not allow networkinterface
cards to performdirect memory
access(DMA)
into
theirbuffer
areas.An
efficientlow level messaging
protocol shouldbe designed
to provide alow-level
reliable transport protocol with point-to-point and multicast capabilities and with
performance asclose as possibleto the
hardware
onwhichit is running
on.It
has been
observed that the messagelayers incur
significant software overheads whenimplementing
"high
level"features
not providedby
hardware. These
software overheadsare
due
toboth
the networkhardware (no flow
control, nomulticast)
and to poorperforming device drivers (not
thread-safe, overmutexlocks,
nointerrupt-based
messageperformance are
very important
characteristicsfor
theunderlying
network to ensure anefficientmessage
passing among
workstationclusters.When
designing
today's mission critical communication protocols,it is
alsovery
important
to guarantee thedeadlines
of synchronous messages whilesustaining
ahigh
aggregatethroughput.
Synchronous FDDI
[6]
(Fiber Distributed Data
Interface)
providesguaranteed
bandwidth
and abounded
access timefor
synchronous messages andhigh
bandwidth (100
Mbit/sec)
to thenetworkinterface.
The
goal ofthis thesisis
todesign
a reliablehigh
performance messagepassing
protocolabstract
data interface
which will provide the guaranteedbandwidth
toMPI
and to theQuality
ofService
(QoS)
requiredby
mission-criticaldistributed MPI
applications.The
intention is
tobring
the performance and guaranteedbandwidth
to user applications asmuch as possible.
MPI-GB (Guaranteed Bandwidth for
MPT)
runs ontop
oftheFDDI
driver designed
andimplemented for Performance Technology's Inc.
commercialhigh
performance
FDDI
product.This
product utilizes theSMT
7.3
standardSBA
[7]
(Synchronous
BandwidthAllocation)
anddelivers
predictable performance to thenetwork
interface.
The
protocol software(MPI-GB)
interfaces
withADI/MPICH
(Argonne
NationalLaboratory
andMississippi
State
University's
free
MPI
implementation)
(Figure
1)
and with theFDDI device driver
to provide this guaranteedFigure 1: MPI-GB
Model
MPI-CH
ik
ADI Abstract Device Interface
ik
MPI-GB
Guaranteed Bandwidth MPI messaging layer
ik V
ND Networkdevice Synchronous FDDI / Fast Ethernet
1.2
Motivation
In
theinitial
phase ofthisthesis,
various a number ofinterface
productsfor
severalcommercial and non-commercial
operating
systems arebenchmarked. The
benchmarking
suites
included
various tests to measure a combination of networklatency, bandwidth,
and contention.
The
performance results, given onthefollowing
pages, provide a goodinsight into
thebehavior
ofarchitectures,device
drivers,
and protocols underdifferent
load
conditions.Typically,
less
thanhalf
of the providedby
the networkinterface is
delivered
touser applications(MPI)
for
most packet sizes.The
resultsin
figures
2
and3
are recorded
using PCI
SPARC
workstations.(The
characteristics ofthese workstationand others used
in
this thesisis
givenin
Table
12.)
This
ratiodrops
evenlower
while*
running
at"Slow Host & Fast
Network"test setups.
(Please
refer to chapter2
and4 for
[image:16.583.74.523.149.480.2]more
information regarding
thediscussion regarding
thesebenchmarks).
Figure 2:
Ping
-Pong
latency
for
Raw,
TCP/IP
andMPI
APP.Latencyfor Short Messages
0 600 1200 1800 2400 3000 3600 4200 Packet Size(Bytes)
^ TCP/IP
LatencyforLongMessages
58 6.B 7.8 B.6 9.B 10.8 11 B 12.B 13.8 14.8 15.8 -DriverRaw gs TCP/IP A MPICH/P4
_ 120 u
(0 100 5s
A 80 5
.c
60 4>* o 40
i
o c 20 (0
m 0
Bandwidth
10 100
Packet
Size(Bytes)
1000
-?Driver Raw
--TCP/IP
-*MPICH/P4
[image:16.583.66.521.308.646.2]10000
But,
"Where does
thetimego?"as
Dr.Chien[ll]
askedfor MPPs.
To
find
where the timeis
wasted,different OSI
protocolsTCP/IP,
MPI level
protocolsthat
interfaces
with networkinterface
architecture throughthedevice driver
and our theraw
driver data
transferhave been benchmarked.
Carefully
analyzing
theresultshelped in
identifying
thefollowing
problems andbottlenecks in
software wherethis timeis lost:
Poor
networkdevice drivers
and architecturesNon
interrupt-based
messagedelivery
orinterrupting
more than necessary,lack
ofDMA
oroverusing
DMA
(ex. evenfor
small messages, notestablishing
abalance
withProcessorI/O
andDMA)
Not
threadsafedevice
drivers,
over mutexlocking.
Redundant
data moving
Non-streamlined,
non-optimized codeincreases instruction
cache misses.No
supportfor
synchronoustrafficand collision(Ethernet)
Slow I/O Buses
(Sbus)
Heavyweight,
over-reliable, slowtransportprotocolslike TCP/IP.
Designed
to achieve reliable and efficientnetworking
over slow, unreliablenetworks.
It
meetsits
goalby
timers,
buffers,
process protection,three-way
handshake
at the expense ofloosing
valuable time.Additional
processoverhead andextra
copying in
and outfrom
thecommunicationbuffers
needstoremoved.
Message passing interface
(MPI)
protocoloverheadsProtocol
overheadrelated withMPI
itself
andp4 abstractdata device.
Extra data copying from MPI7P4
toBSD
Socket interface.
Overheads
related with communicationbetween
thesedistinct layers.
Non-streamlined interfaces
anddistinct
layering
as a result ofthat the upperlayer's information is
not availabletolower layer
Redundant Context switching for
system calls and no real-time scheduling.After
determining
the problem areas, the nextstep is
todesign
a protocol that wouldeliminate these overheads, get
MPI
closer tohardware
andtry
tobring
the performanceandaverage
latency
to thelevel
providedby
hardware.
Anumberof research groups
have already
worked onimproving
communicationlatency
and
bandwidth
by
modifying
messagepassing
protocols tofacilitate
efficient systemimplementation.
Some
examplesinclude
theFast Message
[8]
projectby
Chien,
Shrimp
project
by
Li
[9],
andURTP
by
Bruck [10]. More detail
aboutthese others canbe found
in
chapter2.
New
communication technologies(ATM[19], FDDI[6],
Fiber channel[28])
bring
acompletely different kind
of service and guaranteedbandwidth
to the networkinterface.
FDDI
uses a separate synchronous channelotherthana regularasynchronous channelfor
stream-oriented traffic such as audio and video that require a
low
latency,
andhigh
bandwidth
pipe.Like
other newtechnologies, FDDI
provides guaranteedbandwidth
tocarefully designed
protocols.By
designing
andimplementing
MPI-GB
protocol we showthat
it is
possible to get the user applicationsbenefit from
thesefeatures
the networkinterface
provides,withoutloosing
muchin
reliability.1.3
Deliverables
The
purpose ofthis thesisis
to show thatit is
possible tobring
thefeatures
of a networkinterface like high
performance,low
average and worst-caselatency
and guaranteedbandwidth
to adistributed
user application.To
servethis purpose,existing programming
environments, standards, protocols and recent research are
investigated.
Upon
thisinvestigation,
MPI-GB
protocolis designed
andimplemented
to meet the requirementsneeds of mission-critical
distributed
applications.In
thedesign,
two main concepts areimplemented:
1) Being
given avery
reliableunderlying
network, extra errorchecking
should
be
removedfrom
the protocol to achieve a minimal protocol overhead.2)
Using
real-time schedulers,
priority
queuing, andremoving
extracopying, thegap between
theuser application and network
hardware
shouldbe
narrowed.These
two concepts aredemonstrated
by
theimplementation
of theMPI-GB
protocol.MPI-GB
is benchmarked
and comparedto otherprotocolsusing
average and worst-caselatency,
averageandguaranteedbandwidth.
1.4
Methodology
To
achievethegoals givenin
thisthesis,
variouslayers
ofthe software such as thedevice
driver,
networkinterface
API,
MPI
andits
abstractdata
interface
are studiedindividually
interface between
theselayers
on receive and transmit sites are removed. Special careis
given
for scheduling between layers
andpassing data between layers.
Finally
staticbuffering
andflow
controlis carefully integrated into MPI-GB for
areliable and efficientdata
transfer.For
exampleif
themaximumthreshold valueis
reachedon thereceive site,the receive site sends a control packet to the sender to slow
down.
Using
this negativeacknowledgement approach
helps
in
eliminating
the overhead causedby
acknowledgment packets .
Early
thresholdwarning
approach gives the senderapplication an option to take precautions such as
slowing down
thetransmission,
therefore
allowing
the receiver a chance to process andfree
morebuffers before
allreceive
buffers
aredepleted.
(Please
refer to section3.1
of this thesisfor
detailed
explanation of thedesign
methodology).
1.5
Results
During
high
andidle
asynchronousload,
MPI-GB
and otherMPI
implementations
areevaluated
based
on generic network evaluation metrics such asbandwidth,
Ping-Pong
(Roundtrip)
latency
and guaranteedbandwidth
metrics such as worst caseroundtrip
latency
toAverage
latency
ratioandpercentageofpacketsmissing
theirdeadlines.
Our
resultsindicate
thatMPI-GB
provides muchbetter roundtrip
latency
thanMPI-CHP4
during
idle load.
The roundtrip
latency
results ofMPI-GB
versions present anincremental
improvement
over the previous versions.All
threeimplementations
outperformthe
MPI-CHP4 implementation for
allmessage sizes.*
Many
techniqueshave been developedtodecreasethenumberof acknowledgmentsfortransportFor
shortmessages,MPIGB-DLPI
andMPIGB-MMAP roundtrip
latency
results arevery
closetoraw
data
transferresults obtainedfrom
thedevice driver. The difference
betweenraw
data
transfer andMPI
implementations for
thelong
packets canbe
attributed to theextra
copy done
tosatisfy
thehardware's DMA
engine requirements.MPI-GB
primarily
servesfor
guaranteed messagedelivery.
Worst-case
roundtrip
message
delivery latency
is nearly
one andhalf
times of the averageroundtrip
messagelatency during
high load. This
ratio was anywherebetween 7
to22
for MPICH-P4.
GB,
itself is
evaluated againstUDP/TP
when an externalload is injected
by
TTCP.
Along
with
RTP,
UDP
canbe
considered as a real timeprotocol.The GB
messagemiss ratiois
only
about5
%
during
high
asynchronous networkloads (50
Mbit/sec),
whereas thisvalue
is
closeto76
% for UDP/TP
packetsduring
thisload.
Inconsistent
results andfailures
are recordedin
back-to-back
send packetsbandwidth
testdue
to thelack
of optimizations ontherate andflow
control oftheGB
protocol.This
is
oneoftheareaswhere
MPI-GB
needstobe improved.
1.6
Thesis
Overview
The
outline ofthethesisis
asfollows:
In
chapter2,
we provide morebackground information
on thehardware
and softwareused
in
thisthesis.This
sectiondiscusses
theparadigmofparallelprocessing
on networksof workstations
(NOW).
It
continueswithabrief
overview ofFDDI
andits OSI
model.It
elaborates on synchronous
FDDI
device driver design
andimplementation
andhow
FDDI
fits in
to theMPI-GB
model.The
remainder of this section givesbackground
information
ofparallelprogramming APIs
such asParallel
VirtualMachine
(PVM)
andMessage
Passing
Interface
(MPI)
available onNOW. It
continues withintroducing
andcomparing MPI implementations:
MPI-CH
andOhio
SupercomputerCenter's MPI
implementation (LAM). It
classifies theexisting high
performance message passingsystems and comparesthemwith each other and
MPI-GB briefly.
Chapter 3 discusses MPI-GB
andits
building
blocks in detail. This
chapter starts withexplaining MPI-GB 's
abstractdevice interface
and continueswithdiscussing
the generaldesign
methodology,identifies
theproblem areas and concentrates onhow
it is
solvedin
three
different MPI-GB
versions.In
Chapter
4,
the performance measurements ofthreeversions ofMPI-GB
are presentedalong
with analysis of results.Metrics
such as average and worst caselatency,
averageand guaranteed
bandwidth
areusedin
the analysis.This
chapter compares MPI-GB withtheothers
using
themetricslisted
above.Finally
in Chapter
5,
the mostimportant lessons
welearned
during
thedesign
andimplementation
of MPI-GB arediscussed. This
section alsolists
the accomplishments2.
Background
2.1
Network
ofWorkstations
(NOW)
As
the performance to price ratio ofdesktop
workstations continues toincrease every
year,
they
arebecoming
common parallelcomputing
platforms to solvehigh-end
scientific and
engineering
problems.These
networks providewiring
flexibility,
scalability, and
incremental
expansioncapability.Utilizing
load
balancing
techniques andusing
widely
available software on these networks allow us todistribute
somecomputation of
heavily
loaded
workstations to theidle
orlightly
loaded
workstations.This helps
to prevent the waste of potential useful resources anddegradation
of theoverallresponsetime.
Researchers
anddevelopers
oftheseplatforms areaddressing many different
problemstomeettherequirements of
highly demanding
distributed
applications.The
first
problemis
the communication overheads.
Since
theexisting
communication technologies such asLAN
andWAN
were notinitially
developed for
parallelprocessing, the communicationoverheads
among
theworkstations arevery high. To
solvethisbottleneck,
theresearchersproposed two
different
solutions.One
solutionis
theuse ofexisting fast interconnection
technologies such as
FDDI,
Gigabit
Ethernet,
andATM.
The
other solutionis
to usecustom
interconnects
such asU-Net
[33],
Myrinet [8].
Solving
the communication overhead problemis important but
not sufficient.In
ordertobring
MPP-like
performance and reliability,NOW
shouldhave high
performancemessaging
protocols, parallelprogramming
environmentssupporting load
balancing,
scheduling, and
fault
tolerance.In
thisthesis,
weintend
todesign
andimplement
ahigh
performance
messaging
protocoltocontributetoa solutionofthisproblem.As
aninterconnection
network,due
to thelack
of custominterconnect
networkslike
Myrinet,
we choseFDDI
because
ofits
availability,reliability
and synchronousbandwidth
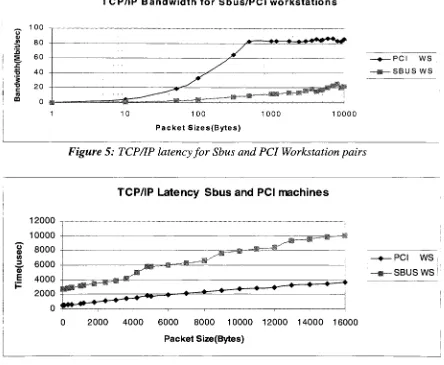
support.Figure 4: TCP/IP bandwidth for Sbus
andPCI
WorkstationpairsTCP/IP Bandwidth for Sbus/PCI workstations
100
?PCI ws SBUS WS
100
PacketSizes(Bytes)
[image:24.583.75.519.181.546.2]1000 10000
Figure 5: TCP/IP
latency
for Sbus
andPCIWorkstation
pairs12000
10000
8000
3 6000
0)
TCP/IP
Latency
Sbus
andPCI
machines- PCI ws
-* SBUSWS
0 2000 4000 6000 8000 10000 12000 14000 16000
Packet
Size(Bytes)
The figures
above showthelatency
andbandwidth
resultsfor TCP/IP
packetsfor
variouspacket
lengths
recordedusing Sbus
andPCI SPARC
workstation pairs withFDDI
network
listed in Table 1 (PTI Test Bed).
The
majordifference in
two samplesis
notonly due
to thedifferent CPU
speeds, cache sizes andI/O buses (PCI
vsSBus).
Network
memory
systemthatit
can affordtousepoorly
optimized, general purposedata
structuresand paths.
FDDI
couldbe
considered as afast
networkfor
oldSBus SPARC
machines.The
overhead addedby
networkprotocolsby
data copying in
and out oftheuserbuffers
andnetwork
buffers
canbe
toleratedonfast hosts but
noton slowerhosts.
The
next sectionbriefly
overviewsFDDI
andits OSI
model.It
elaborates on synchronousdevice driver design
andimplementation
andhow FDDI fits in
totheMPI-GB
model.2.2
Fiber Distributed Data Interface
(FDDI)
andits
interface
to
MPIGB
FDDI
is
a100 Mbps data
ratelocal
area network standard.Figure
6
showsatypicalFDDI
network.Figure 6: Typical
FDDITopology
Wiring Concentrator
(WC)
Some
stations areconfiguredonFDDI
withtworings
and some are configured with one.The dual
attachment stations(DASs)
use twofibers,
and the single attachment stations(SASs)
useonefiber. The IEEE 802.1
standardspecifiesthegenericOSI
referencemodel [image:26.583.119.498.189.451.2]for LAN.
FDDI
network modelis
comparedwiththegenericOSI
modelin Figure 7.
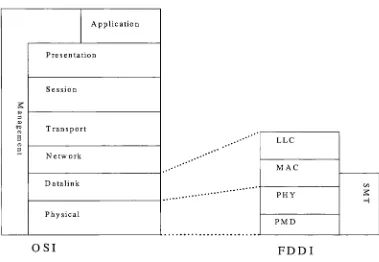
Figure 7: OSI
andFDDI
modelApplication
s.
3 fa crq a> 3 CD 3
Presentation
Session
Transport
Network
Datalink
Physical
LLC
MAC
PHY
PMD
OSI
FDDI
The FDDI
physicallayer
is divided into
two sublayers:(a)
the physicallayer
(PHY)
protocol and
(b)
the physicallayer
mediumdependent
(PMD)
interface. The PMD
interface is
responsiblefor
defining
thetransmitting
andreceiving
signals,providing
proper power
levels,
andspecifying
cables and connections.The
physicallayer
protocolis
intended
tobe
mediumindependent.
It
defines
symbols,coding
anddecoding
The data link layer
consists oflogical link
control(LLC)
and media access control(MAC).
The FDDI MAC
provides the procedures usedfor
frame
formatting,
errorchecking, token
handling,
multiple classes oftraffic,
dual
mode of operation andmanaging
thedata link
addressing.FDDI
alsohas
a station management(SMT)
function. The
station management standardprovides the procedures
for managing
the station attached toFDDI.
It
providesprocedures
for
remote/local node configuration, error statistics, errordetection
andrecovery,and connection management.
As
mentioned above,FDDI
MAC
protocol provides multiple classes of service:synchronous and asynchronous.
The
synchronous class of servicehas
a guaranteedbandwidth
and accessdelay. It is
also thehighest priority
traffic.This
is very
usefulfor
applications that require
deterministic
access to the network, minimumjitter (variations
in inter-frame
arrival timesin
destination),
bandwidth
guarantee requirements.This
synchronous class
is necessary for
stream-oriented traffic such as voice, video andmission critical
distributed
control applications, which require adeterministic
responsetime.
The
asynchronous class of service on the otherhand,
is
theremaining
bandwidth,
which
is
dynamically
sharedbetween
all nodes.For
theinitial
phase ofthis thesis, aSolaris
OSdevice driver for PTI's FDDI
networkinterface
cardis designed
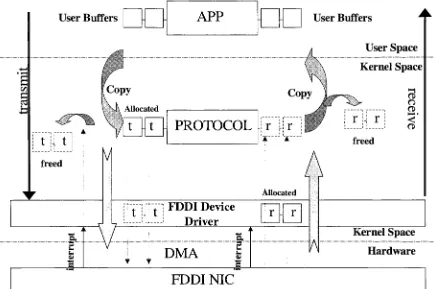
andimplemented. The host-NIC
interaction
is
achievedby
utilizing
theNIC's
threeDMA
channels.The
host
messagebuffer memory is
directly
memory
mappedto theboard,
andDMA
transfers to/from thehost
are performedthroughthis
kernel
memory.No buffer copying is
performedinside
thedevice
driver;
thephysicalpointer address ofthe message
buffers coming from
the transmit path aredirectly
givento the
board for DMA
transfer.The
physical pointers ofthepre-allocated messagebuffers [image:28.583.76.510.201.490.2]are providedto the
board's DMA
receive channelfor
theincoming
packets.(Figure8)
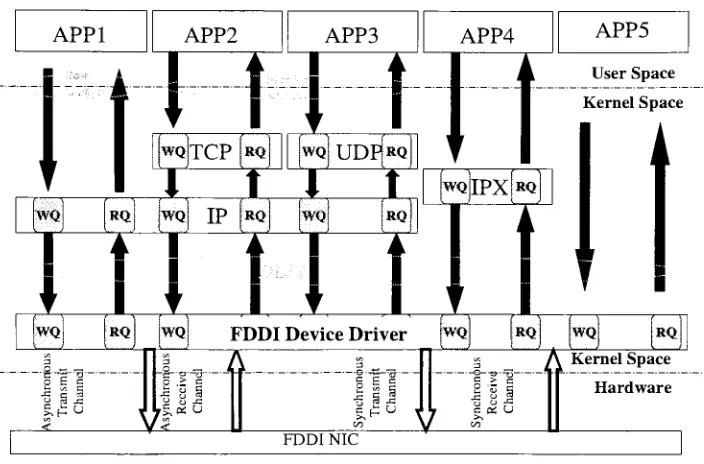
Figure 8: Buffer
managementinFDDI
device driver
User Buffers
APP
- User BuffersUser Space
Kernel
Space
3
o rt> i> < CDKernel
Space
Hardware
FDDI NIC
The driver is
fully
Data Link Provider Interface Specification
compatible; raw andIP
applicationstalk to the
device driver
viaDLPI
commandsutilizing Solaris
OS streams.Figure
9: FDDI
DeviceDriver
softwarelayers
APP1
APP2
APP3
APP4 APP5woJTCP
(rq) [wq]
UDp[rq|
*t~T
f
i
re
WQ IP RQ WQ RQ
.._J L * v J L_ i_
WQ RQ WQ IP RQ WQ RQ
i
I
fir
wq RQ wq FDDI DeviceDriver
_n----o o ^ ~ *_* _ 5
-a -ga--a
- - sg-' ct
IPX
UserSpace
KernelSpace
t
WQ RQ WQ RQ
A
KernelSpaceu 3jz
St
I
C rato
i
s o i
cOSU
Hardware
FDDINIC
In
thefirst
and second versions ofMPI-GB
implementation,
thisFDDI driver
is
usedwithout
any
modifications.In
these versions,MPI-GB
residesin
user space and utilizesDLPI
commands to communicate with thedevice driver. The first
version,Raw DLPI
implementation,
MPI-GB
opens the rawFDDI device
and attaches andbinds
to thisdevice
withDLPI
commands.The
second version,Raw IP
socketinterface,
MPI-GB
opens an
IP
socketandtalksto adevice driver using
this socketinterface
andIP layer. In
both
of these approaches,Solaris
OS
streams copies the user
buffers
to thekernel's
message
buffer
areabefore giving
thedata
tothedevice driver. As
explainedin
previouschapters, this user to
kernel
buffer copying is
one ofthe mostimportant
contributors to the overheadand shouldbe
avoidedwhere possible.Also
experiments showthat,
Solaris
OS
[image:29.583.125.477.112.344.2]Solaris
man pages[22]
the quantavary from 20
msto200
ms;this ofcourse canincrease
latencies in MPI-GB
protocol andnullify
allthegoodworkthathas been done.
To
avoid this andto preventthe to/fromkernel
spacedata
copying, the third version ofMPI-GB,
mmap
userinterface,
has been designed. In
this version, thedevice driver
mmaps all transmit and receive
kernel buffers
to user space whereMPI-GB
canread/write
from/to. To
solvethescheduling
problem,Sobalvarro's
approachis
used.[23]
Raising
thesleeping MPI-GB 's
processpriority
to maximumlets
anMPI-GB
processschedule and run
immediately
on aSolaris
platform.Please
refer to chapter3 for
thedesign details
ofthe three approaches.2.3
Parallel
Development
Tools
A
number of paralleldevelopment
toolshave been
usedto supportNOW
such asp4[18],Parallel Virtual Machine
(PVM)
[1],
andMessage
Passing
Interface
[2],
There
arecurrently
twoMPI
implementations
available.These
are theArgonne implementation
(MPI-CH)
andtheOhio
stateimplementation (LAM). We
willbriefly
discuss
thesein
thenext section
by
emphasizing
theargumentthattheselibraries fail
tobring
thehardware's
performancetothe application.
2.3.1
PVM
The development
ofPVM
startedin 1989
todesign
a virtual machineconsisting
of a setof
heterogeneous hosts
connected to a network that appearslogically
to the user as aIt
tookresearchersthreeyearsto accomplishthis goal.PVM 3.0
wasreleasedin 1993
toenable a
PVM
application to run across a virtual machine composed of multiplelarge
microprocessors.
As
thedesigners
ofPVM
admitin
[25],
portability
was consideredmuch more
important
than performance.The
researchersfocused
on problems withscaling,
fault tolerance,
andheterogeneity
of the virtual machine rather than theperformance,
based
on thefact
that communication over theInternet
was slow.Later
research was
focused
on the performance problem.Subramaniam found in
[26]
thatin
many
cases thePVM
communicationlibrary
achievesonly 15-20%
of the network'stheoretical capacity.
He
determined
that extralatency
is partially due
to overheadsinvolved in TCP/IP
communication and complexbuffering
schemein PVM. He
andVon
Eicken
[27]
even mentionedin
thiswriting
a user-controlleddevice
driver for
thenetwork
interface.
He
thought that thisinvolves
extensive patches to thekernel.
However MPI-GB
is designed
with no modification to thekernel
exceptfor
theFDDI
device driver.
The
PVM messagepassing
system consists of adaemon
process and a set ofcommunicationprimitives.
PVM
provides thestandardmessagepassing
routines suchaspvm_send(), which
is
ablocking
send, and pvm_recv(), whichis
ablocking
receive.Tasks
communicatewith each otherusing UDP
sockets. Adaemon
process runs oneachPVM
machine.The daemons
communicateamong
themselvestoperformoperations suchas
starting
up
a usertask, multicasting
messages, andfinding
the status of a particulartaskona particular
host. More information
aboutPVM
canbe found in [1].
2.3.2 MPI
The
acronym"MPI"
stands
for
"Message
Passing
Interface".
It
refers to a combinationof application
programming interfaces
and requiredbehaviors
that representlayers five
through seven of the
ISO OSI
reference modelfor Networking. MPI-1
and MPI-2 areboth
parallelcomputing MPI
standards.A
broadly
based
committee ofvendors,implementers
and usersdefined MPI-1 in
1993.The
impetus for
developing
MPI
was that eachMassively
Parallel
Processor(MPP),
workstation vendor was
creating its
ownproprietary
messagepassing API.
In
thisscenario
it
was not possibletowrite a portable parallel application.MPI
is intended
tobe
a standard
message-passing
specification that eachMPP,
workstation vendor wouldimplement
onits
system.One
major goal oftheMPI
is
to provide such a specificationwithout
sacrificing
performance.MPI
contains a range offeatures including:
The ability
tospecify
communicationtopologies,
-A
large
setof point-to-point and communicationroutines,A
communicationcontextthatprovides supportfor
thedesign
ofsafe parallelsoftware
libraries,
The
ability
to createderived
data
types thatdescribe
messages ofnoncontiguous
data.
In 1995
theMPI
committeebegan meeting
todesign MPI-2
[3]
specification to correctthe
ability
todynamically
startMPI
tasks on separatehosts
and to add additional-MPI_SPAWN
functions
tostartboth MPI
and non-MPIprocess,-One-sidedcommunication
functions
such as put and get-2
Nonblocking
collective communicationfunctions.
-Language
bindings for
C
++Finally,
MPI
started meetingsMPI/RT[4](Real Time
extensions toMPI)
in
1998. The
MPI-RT
wouldbe
a specificationto offerextremely low
costofportability
as comparedto
any
native software architecturefor
messaging, whileproviding
useful real-timenotions ofperformance, predictability, and
quality
of service.During
thewriting
ofthisthesis,
the8/98 draft
ofthis standardis
available at[4]
and noimplementation
ofthis [image:33.583.142.480.369.605.2]draft
standard(MPI/RT)
is
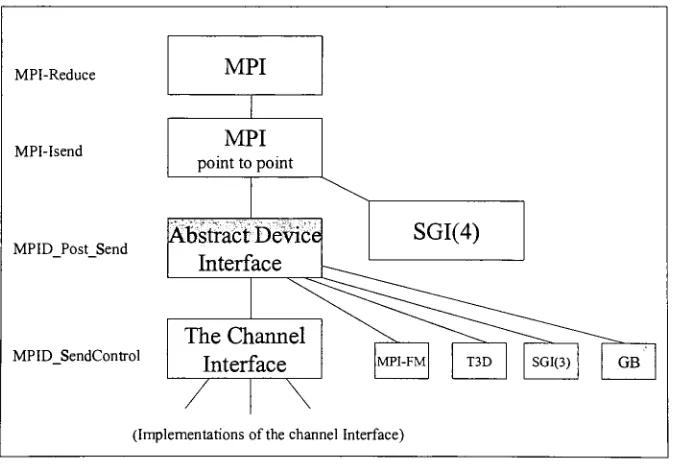
available.Figure 10: MPICH
layers.
MPI-Reduce
MPI-Isend
MPID Post Send
MPID SendControl
MPI
MPI
pointtopoint
Abstract Device
Interface
The
Channel
Interface
SGI(4)
(ImplementationsofthechannelInterface)
MPI
is
theonly
standard upon whichmany free
and commercialimplementations
exist.The
ones thathave
been
usedin
this thesis are:MPICH,
a portableimplementation
ofMPI developed
jointly by
Argonne National
Laboratory
andMississippi State
University
and
Ohio State University's MPI-2 implementation (LAM). As
aninteresting
variation tocommercial
implementations,
MPI Software
Technology
Inc is currently
designing
andimplementing
aJava based MPI
(JMPI)
[28].
2.3.2.1
MPICH
MPICH,
developed
by
Argonne National
Laboratory
is
a popular,free
and a portableimplementation
ofMPI. This implementation
ofMPI has been designed
tosimplify
thetask of
porting MPI
to new platformsby
providing
a multi-levelimplementation. The
MPI-CH layers
are shownin Figure
10.The MPICH implementation
contains an abstractdevice interface
(ADI)
that performsfour
mainfunctions:
sending, receiving,data
transfer queuing, anddevice dependent
functions. ADI
containsnearly
adozen
core routines[Table
1].
Implementing
ADI
[image:34.583.70.514.436.676.2]routines
is
all thatis
requiredtoportMPICH
to a new platform[29]
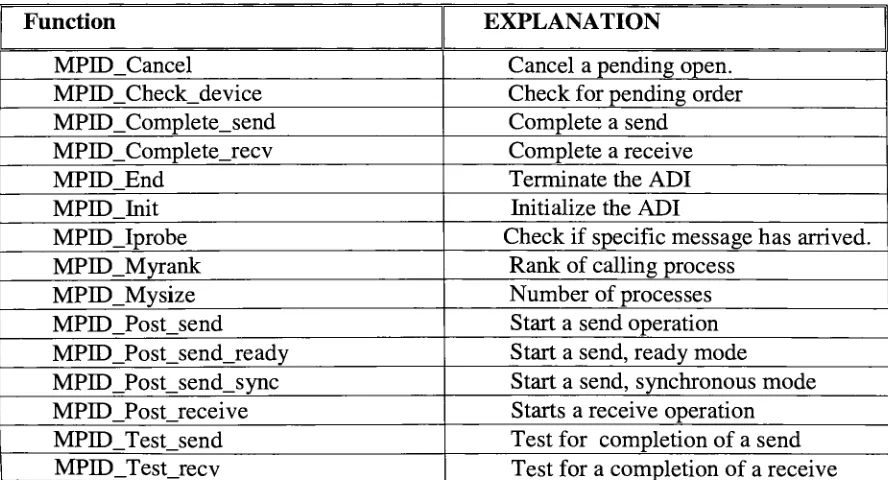
Table 1:
ADIcore routinesFunction
EXPLANATION
MPID_Cancel
Cancel
apending
open.MPID_Check_device
Check for pending
orderMPID_Complete_send
Complete
asendMPJD_Complete_recv
Complete
a receiveMPID_End
Terminate
theADI
MPH)_Init
Initialize
theADI
MPIDJprobe
Check if
specificmessagehas
arrived.MPID_Myrank
Rank
ofcalling
processMPID_Mysize
Number
ofprocessesMPID_Post_send
Start
a send operationMPID_Post_send_ready
Start
asend,ready
modeMPID_Post_send_sync
Start
asend, synchronous modeMPID_Post_receive
Starts
a receive operationMPTD_Test_send
Test for
completion of a sendKeeping
portability in
mind, theMPICH
implementers
offer an additional portablelayer,
the channel
interface,
that containsonly five
routines(bare
minimum) neededjust for
data
transfer[Table 2].
Table 2: Channel Interface Routines
Function
EXPLANATION
MPID_Control_Msg_Available
Indicate
whether a control messageis
available
MPIDRecvAnyControl
Read
next control message.Block
if
noneavail.
MPHO_SendControl
Send
a control messageMPID_RecvFromChannel
Receive
adata from
particular channelMPID_SendChannel
Send data
toa particular channelMPICH includes
multipleimplementations
ofthechannelinterface.
Figure 11: Channel Interface
Send_cnt;-pkt
Plsend
The Channel
Interface
isend
P4 send C
SCI
write HP Rs6000 SUN DEC Alltcp
These implementations
are chameleon[30],
sharedmemory
(p2),
and architecturespecific ones
like
SGI,
andHP-Convex
andSCI.
Chameleon is
theonly
implementation
we
found
that couldbe
usedin
theNOW
paradigm.By
implementing
the channelinterface in
terms ofChameleon
macros, theimplementers
provide theportability
to anumberofsystems,withno additional overhead, since
Chameleon
macros are resolved atcompile time.
The Chameleon implementation involves
p4[18]
parallel programmingsystem
for Workstations
to ensureportability
toMPPs
withtheexpense ofbringing
extralayers
of overhead to overall performance.MPICH implementers
claim thatthey
areworking
on theTCP/IP
andUDP/IP
versions of theChameleon interface
andinclude
TCP
in Figure
11;
atthe timeofthis writing, these versions are notavailable[5].
The
channelinterface
is completely ignored in
ourMPI-GB
implementation. ADI
primitives are
directly
implemented
for
performancereasonsWith
thehelp
ofthis multi-layerapproach,MPICH is currently
availablefor
a wide rangeof
hardware
platforms,from NOWs
toMPPs like IBM
SP, Ncube, Paragon, Meiko,
Cray
T3D.
However,
thislevel
ofportability
comes atthe expense ofaddedsoftware overheadandperformance
degradation.
The
performance of rawdata
transfer,
TCP/IP
sockets and theMPICH-P4
implementation
ofMPI
onFDDI
networksis based
onlatency
andbandwidth
metrics.These
test results are taken with the networksetup detailed in Chapter 4.
The
performance comparisonofraw
data
transferfor TCP/IP
andMPI,
gives a good estimateoftheoverheads associated with
using higher level
abstractionof protocol stacks.Figure
2
and3
show thelatency
andbandwidth
ofMPICH,
TCP/IP
andrawdata
transferfor different
packet sizes.We
proposedMPI-GB
toimprove
the performance ofMPI
based
onlatency
andbandwidth.
The
goal was tobring
MPI data
transfer performanceproper
scheduling
andimplementation,
theMPI-GB
performs close to the rawdata
transfer rate and much
better
thanTCP/IP for larger
packets.(Refer
toSection
4,
figure
31)
2.3.2.2
LAM
LAM is
anotherimplementation
ofMPI developed
attheOhio
SupercomputerCenter
ofthe
Ohio
State University.
It
is based
on a network ofdaemon
farms providing
communication as well as remote program execution and
file
access.Unlike
MPICH,
LAM is based
on theMPI-2
standard and providesfeatures like dynamic
processspawning.
LAM
andMPICH
alsodiffer in how
they
setup
communication channelsbetween MPI
processes.MPICH
makes connection on ademand driven basis
whereasLAM
setsup
afully
connectednetworkatinitialization
time.The
latency
ofLAM
andMPICH
was measured and comparedby
using
theMPI ping
latency
program onSPARC PCI
workstationpairsin
thePTI
testbed 1 (Table 11). Figure
[image:37.583.262.503.469.706.2]12containstheresults.
Figure 12:
Latency
for MPICH
andLAM
Ping-PongLatencyfor LAM and M PICH forshort messages
Ping-Pong Latencyfor LAMandMPICH forlong messages
3 1500
E
,
2000
MPICH
LAM
2000 4000
Packet Size(bytes)
4800 6800 8800 10800 12B00 14800 16800
Packet Size(Bytes)
All LAM
testsuse"-c2c",
"-nger" and "-O"switches tompirun.
The first
selectsclient-to-client mode
in
which theLAM
library
bypasses
thedaemon
and clients communicatedirectly. The
second turns offtheGuaranteed Envelope Resources feature
ofLAM. The
third
informs
theLAM/MPI
library
that the clusteris homogeneous
andhence
turns offthe
data
conversion.Obviously,
LAM has
a smallerlatency
in sending
small packetsless
than8Kbytes. When
themessage size
is
above8Kbytes,
thesending
latency
ofLAM
increased. This is due
tothe
fact
thatLAM
switches overtolong
message protocolfor
messageslonger than8192
bytes in length.
By
default MPICH
changes protocol at 16384bytes.
Please
refer toChapter 3 for design details
of threedifferent
versions of MPIGB andChapter 4
for
theanalysis and comparison ofMPI-GB
withLAM
,MPICH
and others.2.4
MPI-GB
andRelated
workThere
have been
a number of research efforts toimprove
the performance of messagepassing
systemin
aNOW
environment.The
techniquesfor
improving
performance ofmessage
passing
systems canbe
largely
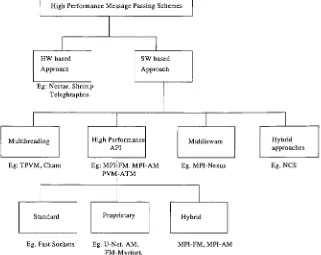
classifiedin Figure 13 [12].
We
willfocus
onthe MPI-FM
[8], U-Net[33],
fbufs[31],
NCS
HPI[12]
andFast Sockets implementations.
These implementations
provided a valuableframework
whiledesigning
anddeveloping
High PerformanceMessagePassingSchemes
HW based
Approach
SW based
Approach
Eg:Nectar,Shrimp Teleghraphos
Multihreading High Performance API
Eg:TPVM,Chant Eg: MPI PVN-ATM
Standard
Middleware Hybrid approaches
FM,MPI-AM Eg. MPI-Nexus Eg.NCS
Proprietary Hybrid
Eg. Fast Sockets Eg.U-Net, AM, FM-Myrinet,
[image:39.583.180.501.16.271.2]MPI-FM,MPI-AM
Figure 13: Classification
ofHigh Performance
Message-Passing
Schemes
2.4.1
Hardware Based Solutions
Hardware based
approachesfocus
onbuilding
specialhardware
[9]
to reduce thecommunication
latency
and achievehigh
throughput.The developers
of communicationhardware
shouldimplement
thedevice
drivers
andproprietary
APIs
for
theircommunication
hardware.
However
the constraint to use special communicationhardware
makesit difficult
to portexisting
applications to adifferent computing
platform.
2.4.2
Software Based Solutions
On
the otherhand
softwarebased
approachesincorporate
one or more ofthefollowing
softwaretechniques.
Optimized implementations
ofkernel
protocols.Other
low level kernel messaging layers.
An
efficient userlevel
protocollayering
High
performanceAPIs.
Multithreading
andutilizing
middle-ware servicesto utilizeexisting
network
interfaces.
The
most common and successful techniqueis
to replace standard communicationinterfaces (Eg. Socket
Interface)
usedin existing
messagepassing
systems withhigh
performance communication
APIs.
(
Fast
Sockets[34],
FM[8],
U-Net,[33]
Active
Messages
[27]
and others).Fast
Sockets[34]:
Fast
Sockets,
based
onActive
messages,is
animplementation
oftheBerkeley
Sockets
ontop
ofits lightweight
protocol.The Fast
Sockets
user spacelibrary
explores"an
advancereceive
buffer
posting"
copy
avoidance technique to eliminate the extracopy
at thereceive site
if
possible.(Figure
14)
When
thepacket arrives,for any
reasonif
thereceivebuffer
is
not yet posted, orit is
not possible toDMA
to receiverbuffers
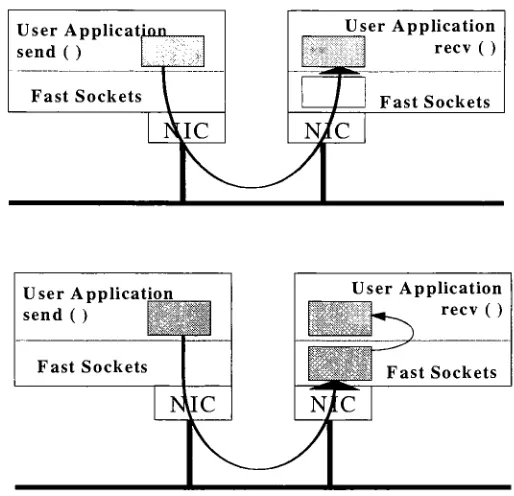
addresses, theFigure 14: Data
transfervia receiveposting(True
zero copydata transfer)
User
ApplicatjiUL,
send ( )
Fast Sockets
User Application
recv ( )
FastSockets
User Application User Application
send ( )
1
j-^
recv( )Fast Sockets Fast Sockets
f^IC
N>
Ic
V
^ 'y
Figure 15: Data
transferinFast Sockets.
FM[8]:
Illinois Fast Messages
(FM)
provides a streamlinedinterface
similar to that ofFast
Socket. The
maindifference
is
thatFast Messages
supportspacketization andthus workswith messages of
arbitrary
message size.MPI
ADIis
also createdfor Fast Messages 2.0
and uses the streams abstraction to offer
layer
interleaving
ofFM's
and the applicationthread ofexecution on thereceiver site.
A
typicalmessageprocessing
scenario withinthereceiver packet
handler
is illustrated below:
[8]
int myHandler
(FM_stream,
*str,
unsigned sender){
struct header myheader;
int msglen;
/* Get the header */
sizeof(struct
header) )
; msglen = myHeader.length;
if(myheader.
littlemsg)
/* Short Messages */
FM_receive(littlebuf++, str, msglen)
else /*
Long
Messages */FM_receive
(
findbuf(msglen)
,str, msglen)return FM_CONTINUE;
}
The first
FM_Receive()
callis
used to extractthemessageheader. Then
thehandler
readsthe
header
fields,
identifies
the message, and selects thebuffer into
which tocopy
themessage payload.
The
streamimplementations
ofMPI-GB
use a similar approach withreal time
scheduling
of the messagehandler. Note
thatFM
requires onecopy from
thestreams
buffer
to theposted receivebuffer if
notrunning
ontop
oftheMyrinet.
FMusesscatter-gatherapproachto
fragment
andreassemblethepacketslarger
than1Kbyte.
In
MPI-GB,
this thresholdis
set to the maximum transmit size ofFDDI
MTU,
4352
bytes. Like Fast
Sockets,
FM does
not offerany features for
real-timescheduling
ofhandler
and thereforeproviding
supportfor
guaranteeddelivery. Fast Sockets
andFast
Messages
provide receiveflow
control,allowing
thereceiverto control therate atwhichdata is
processedfrom
the network.This
approach eliminates network overruns ofapplication
buffer
pools,thereby
avoiding memory
copies.MPI-GB
uses the sameapproach
by
checking
thebuffer low
andhigh
water marks andsending
a negativeacknowledgementto thesender
if
thehigh
watermarkis
reached.U-Net[33]:
U-Net,
developed originally for ATM
networks,is
anotherhigh
performancemessaging
flexible
access to thelowest layer
of networklayer. Like
thememory
map
version ofMPI-GB
andcontrary
to other versions ofMPI-GB
andFM,
U-Net
tries to avoid thepassage of
data
throughkernel memory
by
performing DMA
transfersdirectly
into
theuser
buffers.
The
problem with this approachis that,
theuser must allocate aphysically
contiguous
buffer
and pinit down
to a physicalmemory
address.In MPI
thebuffers
needed
by
applications and theirlocations
aregenerally
notknown
in
advance.There
is
an
on-going
research effortfor U-Net
todynamically
map
andunmap
thoseuserbuffers
using TLB. Thus
messages canbe
transferred to/from amemory
allocated after theinitialization
phasein
theMPI
application.Because
of the time constraints,MPI-GB
will notinclude
thisfeature in
the currentrelease.
MPI-GB
assumes that all ofthe receive and transmitbuffers
aredefined before
the
initialization
phase and sothatthey
canbe
mappedto theboard's
DMAenginein
theMPI
processstartup
NCS[12]:
The implementations discussed
sofar do
not address theissues
ofquality
of service(QoS).
In
ordertoprovide theQoS
todistributed
applications,issues
such as scheduling,context
switching
and synchronousbandwidth
allocation shouldbe
addressed.Syracuse
University's
NCS implementation
[12]
tries to eliminate the overhead ofOS scheduling
and context
switching
by
sendandreceivetrap
routinestoinvoke
thedevice driver's
readand write routines
directly.
This
requireschanging
thetrap
vector tablein using
thekernel debugger (ADB). This
approach creates an overhead at the receive site since
it only
allowsit
to eliminate theoverhead after an
inquiry
to receive the packetis
made.This
received packetmay be
waiting
onkernel buffers for
sometime.MPI-GB
approachesthisproblemby
raising
thepriority
tomaximumfor
thesleeping
process thatis waiting for
this packetin
the devicedriver's interrupt
serviceroutine.Therefore the blocked
receive process canbe
awakenedimmediately.
fbufs[31]:
The
other approach tofast
communicationis
to tuneexisting kernel-mode
protocolimplementations like
tcp/udp
todeliver
more performance.The implementations using
this approach,
try
to eliminate thecopying
ofthedata
presentedby
theuser applicationsfor
output, andfor data
obtainedfrom
networkdevices
and protocols oninput
operations.New Solaris OS 2.6
release contains zerocopy
tcp[32]
which uses a similar approach tofbufs. This TCP implementation
re-maps pages ofdata from
onedomain
to anotherinstead
of copying.It
uses copy-on-write pages to