Rochester Institute of Technology
RIT Scholar Works
Theses
Thesis/Dissertation Collections
1989
Distributed C++ : Design and implementation
Pradeep P. Mansey
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion
in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact
Recommended Citation
Rochester Institute of Technology
School of Computer Science and Technology
Distributed C++ : Design and Implementation
by
Pradeep P. Mansey
A thesis, submitted to
the Faculty of the School of Computer Science and Technology,
in
partial fulfillment of the requirements for the degree of
Master of Science
in
Computer Science
Approved by:
Dr. James Heliotis (Chairman)
Dr. Andrew Kitchen
Dr. Peter Anderson
Distributed
C++
:Design
andImplementation
I
Pradeep
P.
Mansey
hereby
grant permissionto the
Wallace Memorial
Library,
ofRIT,
to
reproducemy thesis
in
whole orin
part.Any
reproduction will notbe for
commercial use or profit.
Acknowledgements
This
thesis
is
dedicated
to my
late father.
I
wishto thank my advisor,
Dr. James Heliotis
for
his
adviceduring
the
variousstages of
this thesis.
I
alsothank
Dr. Andrew
Kitchen,
member ofmy advisory
committee
for his
guidance.Dr. Peter
Anderson,
I
wishto thank
for his
advice andsupport
throughout my
graduate study.Thanks
to
Daryl
Johnson,
Charles
Fung
and
Paul
Allen,
working
withthem,
I learned
allI know
aboutthe
Unix
operating
system.
Special
thanks
aredue
to my
friend Nagesh
Pabbisetty
for his helpful
suggestions.Finally,
I
wishto thank my
family
andfriends for
their
support and encouragementAbstract
Distributed
C++
is
alearning
tool
developed
to
investigate
distributed
programrning
using the
object paradigm.An
extensionis
designed for
C++,
to
enable
the
use ofC++
in
programming
distributed
applications.A
usertransparent
interface is
designed
andimplemented
to
create and manipulate remoteobjects on a network of workstations
running the
Unix
operating
system.The
concept of remote classes
is
introduced
and remote objectinvocation
is
Computing
Review Subject Codes
Programming
Languages/Language Constructs
(CR
D.3.2)
CONTENTS
1.
Introduction
1
1.1
An
Overview
ofTerminology
1
1.2
The Thesis
3
2.
Review
ofExisting
Systems
5
2.1
Background
5
2.2
Object
Based Distributed
Programrning
6
3.
Design
ofDistributed
C++
10
3.1
Objects
in
C++
10
3.2
Objects in Distributed
C++
11
3.3
Design
Issues
12
4.
Implementation
ofDistributed
C++
20
4.1
The Remote Procedure Call
(RPC)
Mechanism
20
4.2
The
Runtime
Library
33
4.3
The DCL Compiler
40
5.
Conclusions
andRecommendations
47
5.1
Features
ofDistributed
C++
47
5.2
Recommendations for future
work48
Bibliography
50
Appendix
A
56
Appendix
B
63
LIST OF FIGURES
Figure 1.
Distributed
C++
model12
Figure 2.
Proxy
object organization15
Figure 3.
Execution
ofremote methods17
Figure 4.
Component
interaction for
aRPC
execution22
-1.
Introduction
Object-oriented
programming
has
received considerable attentionin
recent years asa powerful means of
abstracting
data
and controlin
the
development
of software.The
object modelhas
a naturalflavor
to
express conceptsin
softwaredesign
andefforts
have been
madeto
extendthe
object modelfor
prograrrtming
in
distributed
computer environments.
1.1
An Overview
ofTerminology
The
object paradigm canbe
extendedto
distributed
systemsconsidering the
nodesof
the
distributed
systemsto
be
objects,
eachexporting
its
functions
andcommunicating
with other objects overthe
network.The
tenrdnology
associatedwith
these
systemsis introduced
briefly
in
the
following
sections.1.1.1
Object-Oriented
Programming
Object-oriented
programming
is
primarily
adata
abstractiontechnique,
programsbeing
composed of objects.A
classdescribes
the
structure andbehavior
of a set ofobjects.
An
objectis
aninstance
ofits
class andis
defined
by
its
associateddata
and
the
methods ofits
class.Methods
of a class arethe
operationsthat
canbe
performed on
the
data
associated with each object ofthe
class andform
the
interface
exportedby
the
class.This
isolates
the
programmerfrom
the
implementation
details
ofthe
object andthe
programmer needonly
know
what canbe
done
to the object,
nothow it is
being
done.
Besides information encapsulation,
a
key
feature
of object-orientedprogramming
is
inheritance.
It
allowsthe
programmer
to
define
new objectsin
terms
ofexisting
objectsby
providing
subclassing.
An
object canthus
inherit
state structures andbehavior from
otherobjects.
Inheritance
thus,
provides a mechanismfor
refinement andreusability
ofsoftware.
1.1.2
Distributed Systems
Advances
in
computerhardware
technology
have
led
to
the
emergence ofdistributed
processing
systems.These
encompassdistributed
data, functions,
andapplications.
A
distributed
systemmay
be
a singlememory
computer system withmultiple processors
processing
concurrently,
a set of computer systems managedby
a single networked
operating
system,
or a set of autonomous computer systemswhich are
geographically
dispersed.
The
latter
is
realizedby interconnecting
multiple computer systems
(nodes)
using
networks.This
has
resultedin
decentralization
oftasks
traditionally
performedby
a single computersystem,
whileplacing
additionalburden
onthe
application programmerto
write correct andreliable programs
executing
in
heterogeneous
environments.High
reliability
canbe
achieved
through the
use of networkoperating
systemsmanaging the
resourcesin
the
distributed
environments.This
restrictsthe
desired
independent
anddecentralized
nature ofthe
distributed
environment.More
loosely
coupledcommunication
is
desired
in
these
decentralized
systems.Programming
distributed
applications
in
suchheterogeneous
environmentshas
resultedin
the
emergence oflanguage
level
primitives as vitaltools
in
the
development
and use ofdistributed
computer systems.
The
most popular paradigmfor
programming
distributed
applications
is
the
client-server model.A
serveris
a node which exports a serviceto
other nodes of
the
distributed
system,
for
example,
afile
serverin
a networkbased
file
system.The
nodesusing this
servicethen
become
the
clientsin
this
context.A
node of a
distributed
systemmay
act as a server and/orclient,
depending
uponthe
context of
the
application.1.2
The
Thesis
This
thesis
investigates
objectbased
programming
in
adistributed
environmentusing
existing
languages
that
providefacilities
for
object-oriented programming.Smalltalk,
Objective-C,
Eiffel,
andC++
are some ofthe
object-orientedprogramming
languages,
that
have
gained wide acceptancein
academics andindustry.
C++
[35]
was selected asthe
base
language
to
implement
remote objectinvocation
due
to
its
object-orientedfeatures
andcompatibility
withC.
An
interface
is designed
andimplemented
to
extendC++
for
usein
adistributed
system.
1.2.1
Scope
andGoals
For
the
purpose ofthis
thesis,
adistributed
systemis
defined
as a network ofautonomous computers
(workstations
running the
Unix
operating
system)
that
usea narrow channel
(Ethernet)
asthe
primary
medium of communication.Distributed
applications areviewed,
at ahigher level
ofabstraction,
as a set ofdistributed
objectscommunicating
with each other.The
concept of a remote classforms
the
basis
ofthis thesis.
A
mechanismis
designed
andimplemented
to
define
remote classes and create remote objectsusing
C++
and manipulatethese
objectsusing the
semanticsdefined
for
objectslocal
to
the
system.This
providesthe
application programmer with a simpletool
to
program
distributed
applications withoutworrying
about cominunication and otherdetails.
The
currentimplementation
is
based
onthe
"stubs
principle".The
compiler
implemented
compiles classdefinitions
for
remote objectsinto
client andserver
stubs,
whichtogether
withthe
user programsform
the
distributed
application.
It is
operational on a set ofAT&T
3B1
and3B2
computersrunning
UNLX System V
on aTCP/IP/Ethernet
network.Communication
with remoteobjects
is based
on a remote procedure callmechanism,
implemented
using the
Unix
System
V Transport Layer Interface
(TLI)
library.
Key
issues
addressedin
the
design
ofthis
interface
andtheir
implementation
arediscussed in
the
following
chapters.
2.
Review
of
Existing
Systems
Research
in
the
design
ofdistributed
systemsdates
back
to
the early 1970's.
Since
then
many
distributed
systemshave been designed
andimplemented. This
chapterdescribes
the
features
of somedistributed
programming
systems whichhave been
developed
and arebased
onthe
object model.2.1
Background
Notable
among the existing
distributed
systemsdesigned
andimplemented
arethe
Xerox Distributed File System
[24]
andGrapevine
[6]
atXerox,
the
Locus
system[30]
developed
atUCLA,
the
Apollo
Domain
[18],
the
V-system
[8]
atStanford,
Amoeba
[26]
atVrije
Univ.,
Amsterdam,
Unix BSD4.2
withSun NFS
[36],
Mach
[1]
at
CMU,
andChorus
[31]
atChorus
Systemes,
Paris.
Most
ofthese
systemshave
implemented distributed
computing
atthe operating
systemkernel level.
While
a greatdeal
ofdevelopment
has
taken
placein
distributed
computersystems,
research
in language
supportfor
these
systemshas
only
gained momentum morerecently.
The
two
approachesto
designing
an object-basedlanguage
for
distributed
programming
are,
(l)
to
design
a newlanguage
withbuilt
in
features
facilitating
distributed
programming,
or(2)
to
addfeatures
for distributed
programming
to
anexisting
object-orientedlanguage.
The first
approach would resultin
a majorproject,
involving
design
of a newoperating
system as well as alanguage
to
providea uniform object
based
distributed
environment.This is
atime consuming
effortand
beyond
the
scope ofthis
thesis.
Thus,
the
second approach was adoptedto
develop
alearning
tool
for distributed
programming using the
object model.C++
was chosen as
the
base
language due
its
object orientedfeatures,
its
availability,
and
its
compatibility
withC
(and
therefore
withUnix)
.2.2
Object Based Distributed
Programming
Several
effortshave been
madeto
extendexisting
languages
such asAda[25],
Modula-2
[23],
Pascal
[34],
Smalltalk
[4],
andC
[34]
for
usein
distributed
computing.
Argus
[20],
Emerald
[8],
Avalon/C++
[40],
andHERAKLIT
[15]
areobject
based
systemsdeveloped
to
supportdistributed
programming.Many
ofthe
ideas
usedin
this thesis
arederived from
the
implementation
philosophies ofthese
languages.
The
following
sectionbriefly
describes
the
features
of some ofthese
languages
that
arebased
onthe
object model.2.2.1
Distributed Smalltalk
Bennett
[4]
describes
the
design
of aSmalltalk implementation
that
allows objectson
different
machinesto
send and respondto
messages.Among
the
variousfeatures
of
this
implementation
are user-transparent remoteinvocation,
automatic creationof return references
for
remote messagearguments,
incremental distributed
garbagecollection and support
for
remotedebugging,
remote accesscontrol,
ahost
independent
naming
mechanism,
objectmobility,
reactive remoteobjects,
andsupport
for
messageinteraction
among
heterogeneous
hosts.
It
is
based
on amessage
passing
scheme,
consistent withthat
ofSmalltalk.
This
makescommunication with remote objects
transparent to the
user.Distributed Smalltalk
provides
limited
supportfor
objectsharing among
users.Object
names are notsystem-wide unique and classes and
instances
mustbe
coresident,
thus
limiting
mobility
of objects.The
design
of adistributed
objectmanager,
replacing
the
object managers on
the
currentSmalltalk
systems,
is
presentedby
Decouchant
[10].
This
allows severalSmalltalk
systemsto
share objects over alocal-area
network.2.2.2
Argus
Developed
atMIT
by
Liskov
and other members ofthe
Argus
researchgroup
[20],
Argus
is
anintegrated
programming
language
and systemfor
implementing
distributed
programs.The
language is based
onCLU,
an object orientedlanguage
developed
earlier atMIT.
Argus
providesfor long-lived immutable
objects withatomic properties
based
on stable storage.An
application program consists of anumber of actions
that
make use of modules called guardians.An
actionis
anatomic
activity
andis
equivalentto
atransaction.
Guardians
are network wide andconsist of
data
objects and processesto
manipulatethem.
Objects in
guardians aremade crash resilient and communicate
through
remote procedure callsto
handlers,
data
being
passedby
value only.2.2.3
Emerald
Black
et al[7]
describe
Emerald,
an object-basedlanguage
and adistributed
runtime
systemfor
Emerald
that
facilitates
the
construction ofdistributed
programsfor
alocal
area network.This language
supports abstractdata
types,
asingle objectmodel
is
providedfor
defining
both
small(integers,
etc.)
andlarge
objects(directories,
etc.),
and an explicit notion of objectlocation
is
providedfor.
Each
Emerald
objecthas four
components,
a uniqueidentity,
a representationconsisting
of
the
data
storedin
the object,
a set of operationsdefining
the
functions
that the
object can
execute,
and an optional processoperating concurrently
withinvocations
of
the
object's operations.These
objects alsohave
several attributes.A location
specifies
the
node on whichthe
objectis
residing.The
objects are mobilebut
canbe
defined
to
be immutable.
Emerald
supportsconcurrency
both between
objectsand within an object.
All
entitiesin Emerald
are objects and a single semanticmodel suffices
to
define
them.
2.2.4
HERAKLIT
Designed
for
efficientdevelopment
and maintainence of softwarefor
distributed
systems,
HERAKLIT
[15]
is
a general purpose object orientedlanguage
with ahierarchic
type
concept.A
specialfeature
ofthis
language
is
the
ability
to
exchange modules
(objects)
at runtime withoutstopping
the
entire program.Objects
have
private and publicdata
entries and algorithms astheir
components.An
object canbe
activatedby
a synchronous object call(remote
procedurecall)
oran asynchronous object call which
leads
to
independent
activities ofthe
caller andthe
called object.Each
objectbelongs
to
a particulartype,
defined
by
its
type
interface
andtype
body.
The
type
interface
describes
the
public components.The
type
body
containsthe
privatecomponents, the
description
ofthe
objectactivity,
and
the
execution conditions.The
syntax ofHERAKLIT is
similarto
MODULA-2.
2.2.5
Avalon/C++
Avalon/C++
[40]
is
a proper superset ofC++,
developed
using
the
Camelot
distributed
transaction
processing
system atCarnegie
Mellon
University
for
implementing
reliabledistributed
programs.Avalon/C++
programs consist of a setof
servers,
each of which encapsulates a set of objects and exports a set ofconstructors.
Servers
communicateby
calling
one another's operations which areimplemented
as remote procedurecalls,
with callby
valuetransmission
ofarguments and results.
Objects
may
be
stablein
which casethey
survive crashes ormay
be
volatile and arelost
in
the
event of a crash.A
transaction
is
the
executionof a sequence of operations and
is
identified
with each process.Transaction
semantics are provided via atomic objects.
A
library
ofbuilt-in
atomictypes
is
provided and user
defined
atomictypes
canbe implemented
by inheriting
from
the
predefined
types.
Recoverable
objectsthat satisfy
certain weak propertiesin
the
presence ofcrashes can also
be implemented
using
non-atomic components.3.
Design
of
Distributed
C++
One
ofthe
major considerationsin
the
design
ofDistributed
C++
wasto
implement
remote objectinvocation
without modificationto
the
syntax ofthe
language.
A
stub generator approach was chosen asit did
not alterthe
syntax ofobject manipulation.
The
stub generator compilerimplemented,
translates
classesdefined for
remote objectsinto
client and server stubsthrough
whichthe
clientapplication program communicates with remote objects on
the
server.This
chapterdiscusses
some ofthe
design
decisions
madefor
this
implementation.
3.1
Objects
in
C++
The
key
conceptin
C++
[35]
is
a class.Classes
provide an excellent means ofdata
abstraction.
The
user candefine data
and operationsto
be
performed onthe
data
using
classes.These
arecollectively
called as members ofthe
class.In
C++,
objects are
instances
ofclasses,
eachinstance
defining
a unique object.Member
functions
(methods)
ofthe
classes provide an externalinterface
to the
objectsto
manipulate
their
privatedata,
andthe
implementation
details
ofthese
operationsneed not
be
visible outsidethe
classdefinition.
By
declaring
data
and methods of aclass
to
be
private(the
default),
these
cannotbe
accesseddirectly by
the
objectsdefined
by
the
class.Objects
of a class candirectly
accessonly
membersthat
have
been declared
as public.A
third
type
of member called protected memberis
alsoavailable.
Declaring
a member as protected makesit
visibleonly
to
members ofthat class,
andthose
derived
from
it.
Inheritance is
providedby
using
subclasses.Derived
classesdescribe how
the
objects ofthese
classesdiffer
from
those
oftheir
superclasses.
No
supportis
providedfor
objectsharing
and communicationbetween
objects on
different
machines,
orfor
cooperationbetween
processes on severalmachines.
3.2
Objects
in
Distributed
C++
Distributed
C++
extendsC++
to
include
the
concept of a remote classrclass,
which
defines
a class on a server machine and exportsits
definition
to
all clients onthe
distributed
system.This
providesfor
communication andinteraction
among
geographically
remoteC++
objects,
direct
accessto
remote objects andthe ability
to
constructdistributed
applicationsusing
C++.
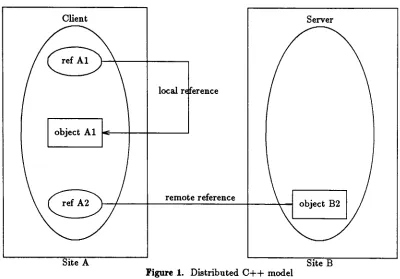
Figure
1
shows objects of a clientapplicationprogram on machine
A
referencing
objects on remote machineB.
The
concept of a remote classis introduced
sothat the
distributed
C++
compileris
able
to
differentiate
between local
and remote classesin
a classdefinition
file.
This
restricts
the
transparency
of remoteclasses,
but
avoidsthe
problem ofgenerating
server and client stubs
for
classesthat
are not remoteto the
client.Also,
a remoteclass
is defined
as a subset of aC++
class with some additional constraints.Thus
by
identifying
a remote classby
the
keyword
rclass,
no restrictions areimposed
onthe
classeslocal
to
a client or server and errorchecking
for
remote classesdefined
can
be done
at compilationtime.
Client
object
Al
Site A
3.3
Design Issues
local
reference
remote reference
Figure
1.
Distributed
C++
modelSiteB
Several
issues have
been
consideredin
the
design
of remote classes.These
andtheir
realization
in
this
implementation
arediscussed
in
the
following
sections.S.S.I
Representation
mechanismfor
remote classesin
application programsRemote
classes aredefined
using the
keyword
rclassin
the
applicationprograms,
using
a syntax similarto that
ofC++
classes.These
representthe
state structureand
behavior
of remote objects.This
keyword
is
addedto
the
language
to
differentiate
between
local
and remote objects.Remote
classes can containprivate,
protected,
and public members.Public
members makeup
the
interface
exportedby
the
remote class and arelimited
to
functions
(methods)
only.Thus,
data
of aremote object
is
accessibleonly through
one ofits
public methods.This
constraintwas
imposed
in
orderto
avoid modificationsto
the
syntax usedfor
accessing
[image:20.539.73.473.74.353.2]members of objects.
In
C++
these
are accessedusing the
syntaxfor
accessing
members of a structure.
In
case of remoteobjects, the
objects are not stored onthe
client machine and
data
ofthese
objects wouldhave
to
be
accessed acrossthe
network,
which wouldhave
resultedin
the
change of syntaxdefined for
accessing
object members.
Public
data
members couldhave been
allowed,
withoutchanging
the
syntaxby
whichthey
areaccessed,
by
implementing
object migration.In
this
case
if
a remote objecthas
publicdata
membersit
canbe
transferred to the
clientmachine when
it is
constructed.Object
migrationis
out ofthe
scope ofthis
thesis,
and
thus this
approach was not considered.Another
approachfor
permitting
publicdata
membersis
to
keep
acopy
ofthe
object onboth
the
client and servermachines.
This
would require an update ofboth
the
copies eachtime the
state ofan object
is
modified.This
approach consumesdata
resources onboth
the
machines and
it is inefficient
to modify
both
object copiesfor
every
operation.An
advantage of
disallowing
publicdata
membersis
that
it
enforcesthe
information
hiding
feature
of object orientedlanguages
by
requiring that the
state ofthe
objectbe
modifiedonly through the
operations exportedby
its
class.Arguments
allowedin
remote class methods arelimited
to
specificdata types
permitted
by
the
remote procedure call mechanismimplemented.
This
is
discussed
in detail in
chapter4.
Arguments
containing
addresses are not allowedin
remoteclass methods and all arguments are passed
by
value only.This
limits
the
capabilities of remote
objects,
but
these
features
canbe
addedin
future
implementations.
S.S.2
Location
of
remote classdefinition
andinstances
Permitting
classdefinitions
andinstances
ondifferent
machines makes objectmigration or
duplication
of code mandatory.A
classdefinition defines
the
methods(functions)
exportedby
the
class.If
an objectis instantiated
on one machine andits
classdefinition
resides on anothermachine, the
object willhave
to
be
movedbetween
the two
machinesto
manipulateits
state.Another
way to
permit classdefinitions
and objectinstances
to
resideindependently
is
to
create copies ofthe
object on
both
the
machines.In
this
casethe
object state onboth
the
machineshave
to
be
updated eachtime
it is
modified.To
avoidduplication
of code andobject
migration,
classdefinitions
and objectinstances
mustbe
coresident.S.S.S
Instances
of
Remote Classes
A
predefined class calledServer is
providedfor
useby
the
client applicationprograms
to
create remote objects.Application
programsinstantiate
aServer
object which establishes a communication channel
between
the
client applicationand
the
server on whichthe
remote objects areto
be
instantiated. Remote
objectsare
instantiated
using
the
constructorsdefined
for
their
remote classes.The
constructors must
be
suppliedinformation
aboutthe
desired
location
ofthe
remoteobjects.
This
is done
by
passing the
Server
objectrepresenting
the
desired
servermachine as
the
first
argumentto
the
constructorsfor
remote classes.When
the
constructor of a remote class
is
invoked,
aninstance
ofthat
classis
created onthe
server machine and a
proxy
objectrepresenting this
remote objectis
created onthe
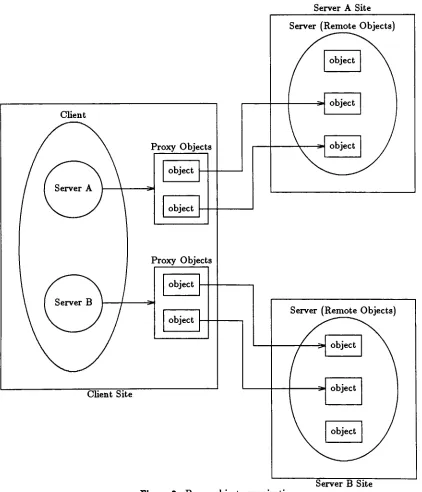
client machine.
The
client application references remote objectsthrough the proxy
objects and
this
is
transparent to the
user.A
clientmay
communicate with severalservers at
any
giventime.
Figure
2
shows a client applicationinstantiating
objectson
two
remote serversA
andB.
Client
Proxy
Objects
object
object
Proxy
Objects
object
object
Client
Site
Server A Site
Server (Remote
Objects)
Server
(Remote
Objects)
object
Figure
2.
Proxy
object organizationServer B Site
[image:23.539.64.486.158.650.2]8.3.4
Nature
of
Remote Objects
Remote
objects createdin
distributed
C++
are volatile.No
mechanismis
providedfor
saving the
state ofexisting
objectsin
the
event of crashes andrecovering these
states when
the
machine recovers.In
the
event of a crash ofthe
client orserver,
the
communication channelis
destroyed
and allthe
objects aredestroyed
too.
Stable
objects couldbe implemented
using
atomic operations.In
stable objectsatomic operations are grouped
together
in transactions
that
are guaranteedto
have
the
atomic property.If
atransaction commits, then
allthe
operationshappen,
otherwise
if it
aborts,
none ofthem
happen.
After
acrash,
objects are recoveredby
continuing
the
systemfrom
the
last
checkpoint.Implementation
of atomictransactions
is
beyond
the
scope ofthis thesis.
3.3.5
Consistency
andAccess
of
remote class methodsRemote
class method executionis
consistent withthat
oflocal
objects.Invocation
of operations on remote objects
is
through the
stub operations generatedby
the
compiler and
is
transparent
to the
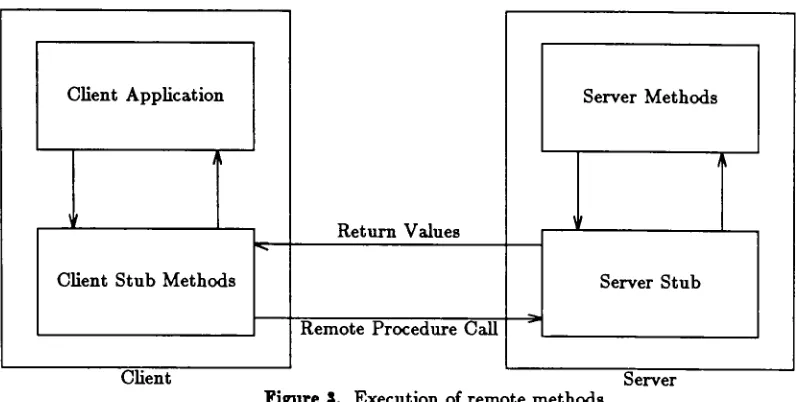
client application program.When
the
userprogram
invokes
an operation on a remoteobject,
controlis
transferred to the
stubmethod.
The
stub methodinvokes
the
remote operationthrough
anunderlying
remote procedure call mechanism.
This is discussed in detail in
chapter4.
This
method eliminates
the
needfor
a changein
the
syntax or semantics ofaccessing
remote class methods.
Figure 3
showsthe relationship
between
the
user programsand
the
stubs ofthe
distributed
application,
when a remote object methodis
invoked.
Return Values
Client Application
Server Methods
\
l A
V
Client Stub Methods
Server Stub
Remote Procedure Call
Client
Server
Figure
3.
Execution
of remote methods3.3.6
Remote Class
naming
mechanismThe
ideal
naming
mechanism wouldbe location
independent
whileproviding
the
user with
facilities
to
controlthe
location
of remote objects.In
this
implementation
of
distributed
C++
aremote classis
defined
by
its
classidentifier
(integer)
andthe
address of
its
server(integer).
These
aredefined
in
the
remote classdefinition file.
This
is
done
to
simplify
the
currentimplementation.
To
makethe
naming
mechanism
transparent
a replicateddatabase
canbe designed
to
store system-wideunique class names and
locations,
making the
location
ofthe
objectstransparent to
the
user.This
will eliminatethe
needfor
specifying
Server
objectsin
the
constructors
for
remote objects.Also,
the
user canbe
given control ofthe
location
by
allowing the
userto
create aServer
objectfor
a particular machine.Checking
can
be done
at runtimefor
existence of remote classdefinitions
onthat
serverwithout
trying
to
establish a communication channel. [image:25.539.69.467.77.278.2]S.S.7
Inheritance in
remote objectsRemote
classes canbe derived from
other remote classes only.This
restrictionis
imposed
as otherwise a mechanismto
permit rclassdefinition
andinstances
ondifferent
machines wouldhave
to
be
provided.The
base
rclass of aderived
rclassmay
be
public or private.In
caseit is
public,
instances
ofthe
derived
rclasshave
access
to the
interface
exportedby
the
base
rclass, otherwise, only
methods ofthe
derived
rclasshave
accessto
it.
Also,
base
rclasses andderived
rclasses mustbe
present on
the
same machine.3.S.8 Local
object managementTo
maintaininformation
about and accessto
remote objects created onthe
servermachine, the
notion ofproxy
objectsis introduced.
For
each remote objectcreated,
a
proxy
remote objectis
created onthe
local
machine.These
contain a referenceto
the
actual remoteobject,
andinformation
aboutits location.
A
classRemoteObj
is
designed
to
maintain a uniform representation of all remote objects onthe
clientmachine.
This is
accomplishedby
automatically compiling
all rclassesto
have
this
RemoteObj
class astheir
base
class.Thus,
aproxy
objectis
aninstance
of classRemoteObj.
Access
to
remote objectsis
handled
viathese proxy
objects.3.S.9
Remote
object managementRemote
objects are createddynamically
onthe
server machine whentheir
constructors are
invoked
in
the
userprogram,
andhave
the
life
oftheir
corresponding
proxy
objects onthe
client machine.These
objectshave
to
be
identified
and retrieved at runtime when objects onthe
clientinvoke
their
classmethods.
A
table
of remote objects createdby
the
user programis
maintained onthe
serverfor
eachimporting
client.This
table
storesinformation
to
identify
aremote
object,
and a referenceto
the object, using
whichit
is
retrieved whenreferenced
by
the
user.3.3.10
Protection
No
elaborate mechanismsfor
protection aredesigned.
The
currentdesign
permitsany
userto
use a remoteclass,
providedthey
have information
onits location
andcommunication address.
The
design
canbe
extendedto
provide a mechanismfor
authentication of clients
instantiating
Server
objects.In
the
currentdesign
eachuser
is
given alogically
distinct
process and address space onthe
server.This
eliminatesthe possibility
of objectsharing among users,
but does
secure a user'sobject
from
being
accessedby
other users.4.
Implementation
of
Distributed
C++
This
chapterdescribes
how
the
design
decisions
discussed
in
chapter3
areimplemented.
The implementation
ofdistributed
C++
consists ofthree
majorcomponents
1.
Remote
procedure call mechanism2.
Runtime
library
interface
3.
Front
end compilerThe
following
sectionsdiscuss
eachin
detail.
4.1
The
Remote
Procedure Call
(RPC)
Mechanism
The
remote procedure callis
modeled onthe
local
procedurecall,
a well understoodmechanism
for
transfer
of control anddata
within a programrunning
on a single computer.The
difference lies in
that
aRPC is
executedin
adifferent
process,
usually
on adifferent
computer,
to
transfer
control anddata
acrossthe
communication network.When
a remote procedureis
invoked,
the
calling
program's executionis
suspended, the
parameters are passed acrossthe
networkto
the
environment wherethe
procedureis
to execute,
andthe
desired
procedureis
executed
there.
The
results are passedback
to
the calling
program whenthe
procedurefinishes
executionin
the
remoteenvironment,
andthe calling
program resumes execution asif
returning
from
a simple single machine call.Clean
and simplesemantics, efficiency,
andgenerality
are some ofthe
features
that
have
madethe
idea
ofRPC
more attractive as comparedto
messagepassing
systems
to
constructdistributed
applications.Several RPC
systemshave
been
designed
andimplemented
overthe
pastfew
years.A few
ofthese
arelisted
in
references
[2] [5] [12] [13] [19] [21] [22] [28] [29]
[32-42].
The
RPC
mechanismimplemented
for
Distributed
C++
derives from
the
Xerox Courier RPC
protocol[41]
andthe
Sun
RPC
protocol[36]
specifications.In
their
classic paperBirell
andNelson
[5]
discuss
several
key
issues in
the
design
of reliable remote procedure call mechanisms.These
issues
andtheir
realizationin
this
implementation
arediscussed
in
the
following
sections.
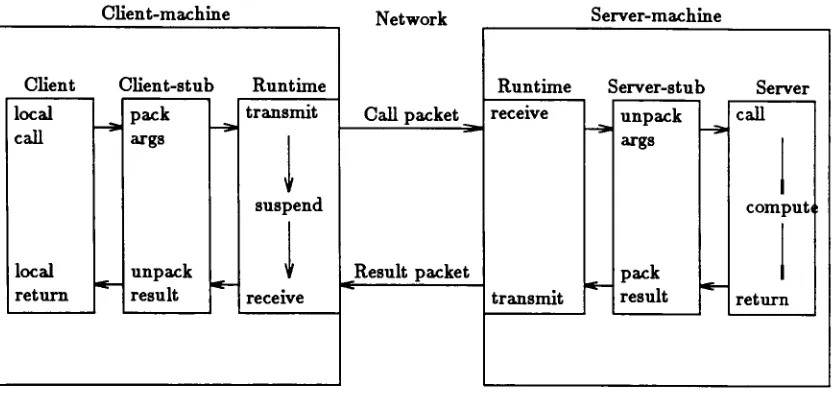
4-1.1
Structure
of the
Remote Procedure Call
The
remote procedure call mechanismimplemented is
based
onthe
concept ofstubs.
In
this
approachRPC is implemented
using
language level
stubs generatedby
a stub compiler.Each
remote callinvolves five
pieces of code :the
clientapplication
program, the client-stub, the
runtime
communicationenvironment, the
server-stub,
andthe
server application program.The
relationship
between
these
is
as shown
in
figure
4.
When
the
client(etc.)
program executes a remoteprocedure,
it
actually
invokes
alocal
procedurein the
client stub.The
client stub creates adata
packetinto
whichit
packsthe
arguments ofthe
remote procedure andinformation
to
identify
the
target
procedure onthe
server machine.The
runtime communicationenvironmentClient-machine
Client
Client-stub
Runtime
local
calllocal
return pack args unpack result transmit suspend receiveNetwork
Call
packetServer-machine
Result
packetRuntime
Server-stub
Server
transmit unpack args pack result call computi: return
Figure
4.
Component
interaction for
aRPC
executionthen transmits this
packet overthe
networkto the
servermachine.The
server stubreceives
this
data
packetfrom
the
runtime environment onthe server,
and unpacksthe
arguments and executesthe target
procedurein
the
server application program(again
alocal
call)
.Upon
completion ofthe
callin
the server, the
server stub packsthe
resultsreturned,
andthe
runtime environmenttransmits the
result packetto
the
client machine.The
result packetis
retrievedby
the
client stub andthe
resultsare unpacked.
The
client stub returnsthe
resultsto the
user program andthe
callreturns
in the
user program.The
remote callin
the
user programis
suspendedfor
the
duration
ofthis
entire process.The
runtime environment usesTCP
(Transmission
Control
Protocol)
for
reliabletransmission
ofdata
overthe
network.It
consists of alibrary
of objects usedby
the
stubs.
The
user and server programs are part ofthe
distributed
application,
andare written
by
the
user.The
stubs areautomatically
generatedby
the
front
endcompiler.
The
remote procedure callis
the
underlying
mechanismby
whichmethods exported
by
a class ofremote objects are executed. [image:30.539.57.474.72.269.2]4.1.2
Remote
Procedure Call
Semantics
Call
semanticsdescribe
the
behavior
of remote procedure calls.The
two
casesto
be
considered
are,
RPC in
the
presence ofcrashes,
andRPC
in
the
absence of crashes.Crashes
may
be
due
to
local
or remote processfailure,
ordue
to
cornrnunicationfailure.
It is
desired
that
local
and remote callshave
the
same semanticsin
orderto
maintain
local
and remotetransparency.
Local
procedure calls use exactly-oncesematics,
i.e.
the
callertransfers
parametersand control
to the callee,
blocks
untilthe
procedurefinishes
executing exactly
onceand resumes when
the
callee returns results.In
the
case of absence ofcrashes,
RPC
achieves
these
exactly-once semantics.This is
achievedby
reliabletransmission
ofcontrol
passing
(call
andreturn)
messages,
which ensuresthat these
messages areexchanged
exactly
once asdesired.
Assuming
errorfree
communication and nocrashing
ofhost
computers,
local
and remote calltransparency
is
achieved.In
the
presence of machine crasheslocal
callshave last-one
semantics,
i.e.
if
the
machine crashes
during
the
execution of a procedure call andrecovers,
andits
crashed programs are restarted either
from
checkpoints orfrom
scratch,
the
procedure call
is
repeated.This
repetition continues untilthe
callfinally
completesand
the
program usesthe
results ofthe very
last
callthat
executes.In
the
case of aRPC,
it
canfail due
to the
local
machinecrashing, the
remote machinecrashing,
orthe
failure
ofthe transport
mechanism.In
the
event ofany
ofthese
crashes,
if
the
processes are restarted and
the
RPC
resumes,
the
last
oneis
executed andthe
results returned
to
the
caller.Thus last-one
semantics are used.In
this
implementation
TCP/IP
is
usedfor
network communication.TCP
guarantees
reliable,
errorfree
communication andexactly
once semantics are used.Even
though
connection overheadis
high,
TCP
was chosen asit
performscomparably
withUDP
once a connectionis
established.It
providesfor
astraightforward
RPC
implementation
and a reliable communication channel.A
connection
between
the
client and serverhost
is
establishedonly
once andit is
destroyed
uponthe termination
ofthe
program orexplicitly
by
the
applicationprogram.
In
the
case of crashes of either ofthe
hosts
orthe
networkthe
local
andremote processes
terminate
andhave
to
be
restartedfrom
scratch.4-1.3
Semantics
of
Arguments
of
Procedures
The ideal RPC
mechanism would permit afull
range oftypes
as arguments andresult
parameters,
asin
the
case oflocal
calls.This is
easy
for languages
withsimple scalar and static
array types.
Problems
occur when parametershave implicit
or explicit
pointers,
asin
the
case ofC++.
Typically
arguments are passedto
alocal
callby
reference orby
value.Passing
argumentsby
referenceis
semantically
equivalentto passing
a pointerto
the
argument.Call
by
reference can alsobe
implemented
by
using
callby
value-result,
in
which case acopy
ofthe
argumentis
made upon procedureentry
andthe
final
resultis
copiedback
into
the
argument whenthe
procedure returns.In
case ofremote procedures since
the
caller and calleehave distinct
addressspaces,
addressesvalid
in
one machine are not meaningfulin
the
other.Thus,
using
callby
referencecould
be
catastrophic.Call
by
value-result parameters caneasily
be
supportedby
RPC,
by
transmitting
back into
the
caller's reference argumentsthe
final
values ofthe corresponding
formal
argumentsfrom
the
site ofthe
remoteinvocation.
This
copy-in copy-out mechanism provides uniform
local
and remote semanticsfor
callby
reference value-result parameters.Pointers
to
arguments are passedto
proceduresprimarily
for
efficiency,
for
passing
structures and other
bulky
values,
andfor list
structures.If
pointers are usedfor
efficiency
reasonsonly,
callby
value-result semantics canbe
usedto
implement
pointer arguments
in
remote procedures.In
the
case oflist
structures anotherproblem arises
in
encoding the
structureto
sendit
overthe network,
whereit is
decoded,
reconstructed,
and passedto
the
remote procedure.This
requiresextensive pointer
chasing
and storage allocation.Also,
the
application programmerwould
be
responsiblefor
programming
the
encoding
anddecoding
of eachlist
structure used.
In
C++
arguments canbe
passedby
value,
by
reference,
andby
the
explicit use ofpointers
to
arguments.Arguments
passedby
reference areimplemented
ascontextually
deferenced
pointersto the arguments,
asC
allows argumentsto
be
passed
by
value only.In
C
addresses of arguments are passedby
using
pointersto
the
arguments.So
in
effectC++
allows argumentsto
be
passedby
value,
andpointers
to
them.
In
orderto
keep
the
implementation
simple andfree
the
programmer
from
writing
the
encoding
anddecoding
proceduresfor
addresscontaining arguments,
parameters are passedby
value only.The
semantics of callby
valuefor
remote calls arethe
same asfor local
calls.This includes
array
andcharacter
string
arguments.Procedure
arguments are not allowed.Data
types
allowed as arguments are
discussed later.
Values
are returnedto the
clientusing
normal
function
return semantics oflocal
calls.4-1-4
Binding
Mechanism
For
remote procedure callsthere
aretwo
aspectsto
binding.
The first is
naming
which addresses
the
problem ofhow
the
client specifies whathe
wantsto
be
bound
to,
andthe
secondis
the
problem oflocating
the
appropriateserver,
i.e.
how
a callerdetermines
the
machine address ofthe
callee andhow does
the
callerspecify to the
callee which procedure
is
to
be
executed.The
ideal
binding
mechanism would provide alocation
transparent
naming
mechanism,
and also providefacilities for
the
userto
controlthe
location
ofthe
remote procedures.
This
wouldinvolve
the
implementation
of adistributed
database,
possibly
replicatedto
improve
reliability,
which would store pertinentinformation
about names andlocations
ofRPC
interfaces
exported onthe
distributed
system.Upon
invocation
of a remote procedureby
the
clientapplication
program, the
client stub wouldthen
bind
to
a serverusing this
database
at execution
time.
Also,
server programsthat
exporttheir
interface
woulddo
soeitherviaa shell
interface
or when executedby
updating the
database
if
necessary.The
RPC
mechanismimplemented is
the underlying
mechanismthrough
whichremote objects
invoke
their
class methods.Thus,
in
this
casebinding
is
done
atthe
object
level
and notfor
specific procedures.The
binding
mechanismdescribed
in
chapter
3
is
nottransparent
andthe
userexplicitly
specifiesthe
location
ofthe
remote object
instances.
4-1-5
Protocols
for
Transfer
of
Data
andControl
between
Caller
andCallee
In
aheterogeneous distributed
environmentinternal
representation ofdata
types
may
be
different
ondifferent
machines,
for
example,
aninteger
on one machinemay
be
32
bits
and on anothermay
be
16
bits.
In
case ofRPC
the
argumentshave
to
be
transferred
from
the
caller's environment on one machineto the
callee on aremote machine.
Thus,
argumentshave
to
be
transferred
in
a machineindependent
form
to
avoidincompatabilities
in
representation ofdata
types
onthe
two
machines.
The
process ofpackaging
andunpackaging
parametersinto
a call or a returnmessage
is
called marshalling.Remote
procedure calls when executedin
the
application
program, transfer
controlto the
client stub procedures.Arguments
aremarshalled
by
the
the
stub procedures andthe
communication environmenttransmits the
call and return packetsbetween
the
client and server machines.The
order and manner
in
which parameters axeflattened
and marshalleddefine
adata
protocol
for
the transmission
ofdata.
This implementation
defines
adata
protocolbased
onthe
External Data Representation
(XDR)
protocol[36]
specifications,
henceforth
calledthe Distributed
C++
Language
(DCL).
DCL
uses a32
bit
representationto
transfer
data.
Each basic
data
type
is
converted
to
a multiple of32
bits,
for
example,
a characterhas
a size of8
bits
andis
stored as one32 bit
word andtransmitted,
while adouble
precision numberis 64
bits
long
andis
stored astwo
32
bit
wordsin
the
data
packet.Marshalling
ofpointers requires
chasing
ofpointers,
asfor
atree structure,
each nodein
the tree
has
to
be
traversed
and marshalledfor
transferring
the
call packet andsimilarly the
tree
has
to
be
reconstructedin
the
callee's environment.It is
not possibleto
automatically
generatefunctions
to
marshall such pointerdata
types
andthe
userwould
have
to supply these
functions for
each pointertype
defined.
To
avoidthese
problems pointer
types
are not permittedin DCL.
To
ensuresecurity
ofdata
transmitted,
it
may
be
encryptedbefore
transmitting
it
overthe
network.Since
security
is
not considered as a majorissue,
this
implementation does
not encrypttransmitted
data.
Data
types
permitted aredescribed in
the
following
sections.4-1.5.1
Data Types
Basic
data
types
allowed arethe
C++
data
types.
[unsigned]
int
[unsigned]
long
[unsigned]
short[unsigned]
charfloat
double
Derived
data
types
allowed arestructures
enumerated
types
fixed
size arraysdiscriminated
unionsclasses
remoteclasses
The
runtimelibrary
desribed
later
defines
aPacket
objectinto
which callparameters are marshalled.
Operations
for
marshalling
basic
data
types
arepredefined
for
the
object.Code is
generatedby
the
compilerto
marshall userdefined
types.
A
subclass of classPacket
is
createdto
marshall all userdefined
types
and a methodfor
eachtype
is
defined.
Derived
data
type
marshalling is
described in
the
following
sections.The
grammarfor
DCL is
described
in Appendix
A.
Type definitions
Type
definitions
aredeclared
using the
keyword
typedef,
asin C++.
For
example,
typedef string
char[100];
declares
a newtype string,
whichis
anarray
of100
characters.Constant declarations
Integer
constants canbe defined
using the
constkeyword.
const
SIZE
=100;
defines
SIZE
to
be
a constant ofvalue100.
This
declaration
gets compiledinto
const
int
SIZE
=100;
The
compiler replacesevery
instance
of adeclared
constantby
its
value.Structures
DCL
structures are similarto
C
structures withthe
restrictionthat
structurescannot
be
nested.For
example,
adefinition
ofthe
form
struct
foo
{
data_type
a;
struct
bar
{
data_type
b;
data_type
c;
}d;
};
is
not allowed.This limitation
is
only
syntacticalasthe
same canbe
written asstruct
bar
{
data_type
b;
data_type
c;
};
struct
foo
{
data_type
a;
bar
d;
};
Another limitation
is
that
structures cannot containfunction
members,
whichis
permitted
in C++.
For marshalling
structuretypes
a methodis
defined
whichinvokes
methodsto
marshall each member ofthe
structure.If
the
structurecontains
any
pointermembers, it
cannotbe
used as an argumenttype
for
a remoteclass
method,
andthe
compilerdoes
not generate codeto
performmarshalling
ofthat
structure.A
structuredeclaration
automatically
becomes
atype
definition
when
declared.
Enumeration
Type
Enumeration
types
aredefined
asin
C++,
but
only
named enumerationtypes
canbe declared.
Integer
valuesmay
be
assignedto
enumerationtypes.
If
there
is
noexplicit
assignment, the
C++
compiler assignsvaluesto these types.
For
example,
enum
BOOLEAN
{
TRUE
=1,
FALSE
=0
}
;
declares
an enumerationtype
BOOLEAN
which canhave
two
valuesTRUE
andFALSE.
Enumeration
types
alsobecome
type
definitions
upondeclaration.
These
are marshalled
using
a predefined methodfor
enumerationtypes assuming that
enumeration
types
have
the
same representation asintegers
or shortintegers.
Fixed
Size Arrays
Array
declarations
mustspecify the array
size.For
example,
int
x[];
is
not allowedby
the
compiler.Elements
of arraysmay
be basic data
types
or userdefined
types.
These declarations
arelimited
to
onedimension
only,
but
multidimensional
arrays canbe declared
using type
definitions.
typedef
int
x50[50];
x50
foo[lOO];
Here foo
is
defined
to
be
atwo-dimensional array
(100
x50).
Array
declarations
aremarshalled
using
a predefined method pkt_vektor which marshalls each element ofthe
array using the
methoddefined for
the
elementtype.
Character
arrays are aspecial case and are marshalled
using the
method pkt_bytesdefined for
the
classPacket.
Discriminated
unionsThis
data
type
is
adaptedfrom
the
XDR
[36]
protocol.These
unions mandatethe
use of a
tag
to specify the
union membertype
being
accessed atany
instant.
For
example,
union
foo
switch(tag_type
tag)
{
case
A
:int
a;
caseB
: charb[lOO];
default
: unsignedc;
};
defines
a union with atag
which mustbe
an enumerationtype.
The
default
caseis
optional.
In
caseit is
present andthe
tag
is
notany
ofthe
declared
casesthe
default
type
is
used asthe
union memberbeing
accessed.This
uniondeclaration
is
compiled
into
a structuredeclaration
ofthe
form
struct
foo
{
tag_type
tag;
union
{
int
a;
char
b[lOO];
unsignedc;
};
};
The
tag
memberis
checkedto
determine
the
union memberto
be
marshalled at runtime.
This
changein
syntax wasnecessitatedto
determine
the
union memberbeing
accessed
for
marshalling that type.
Classes
Class declarations
using the
keyword
class are similarto
C++
classes with somerestrictions.
Data
members of classes cannot containpointers,
asthese
have
to
be
marshalled
for
arguments ofthe
classtype.
Also,
class methods cannot containarguments passed
<