Abstract:. The objective of this undertaking is to apply neural systems to phishing email recognition and assess the adequacy of this methodology. We structure the list of capabilities, process the phishing dataset, and execute the Neural Network frameworks. we analyze its exhibition against that of other real Artificial Intelligence Techniques – DT , K-nearest , NB and SVM machine.. The equivalent dataset and list of capabilities are utilized in the correlation. From the factual examination, we infer that Neural Networks with a proper number of concealed units can accomplish acceptable precision notwithstanding when the preparation models are rare. Additionally, our element determination is compelling in catching the qualities of phishing messages, as most AI calculations can yield sensible outcomes with it.
Index Terms: Neural Network, KNN, support vector machine, decision tree, Naive Bayes .
I. INTRODUCTION
As of late, a phishing email has been coursing in the Stanford people group, meaning to gather SUnetIDs and passwords. As most of phishing messages are organized to show up from a real source, a huge rate of email clients are unfit to perceive phishing assaults. Also, conventional spam email channels are slanted to fall flat to distinguish phishing messages since most phishing assaults use increasingly advanced methods and will in general be coordinated to a more focused on group of spectators. With the expanding seriousness of this issue, numerous endeavors have been dedicated to apply machine learning strategies to phishing recognition. A standout amongst the most well-known Artificial Intelligence systems for phishing order is to utilize a rundown of key highlights to speak to an email and apply a learning calculation to characterize an email to phishing or ham dependent on the chose highlights. [4] proposed a novel procedure to characterize phishing messages dependent on unmistakable auxiliary qualities, for example, the structure of the email title and some useful words. They utilized Support Vector Machine to test their highlights on 410 messages and acquired a 96% exactness rate. In any case, they didn't perform various parts among preparing and test information because of the little example measure. [6] utilized ten unique highlights explicit to the misleading techniques for phishing characterization and acquired a
Revised Manuscript Received on September 07, 2019
M. Arivukarasi, Computer science engineering, Hindustan Institute of Technology and Science, Chennai, India.
Dr. A. Antonidoss, Computer science engineering, Hindustan Institute of Technology and Science, Chennai, India.
F1-proportion of over 92% utilizing a help vector machine classifier. Anyway they utilized fundamentally more ham messages (7060) than phishing messages (866) in their reenactment. In this task, we utilize roughly 8762 messages out of which 4560 are phishing messages and the rest are ham. We see that few examinations have been done on applications of neural systems to phishing email separating. In spite of the fact that Neural Networks typically require extensive time for parameter preparing, they for the most part yield progressively exact outcomes than different classifiers [5]. In our undertaking, we attempt to identify phishing assaults through a feed forward neural system by joining some essential highlights relating to the email structure and outer connections.
II. RELATED WORK
phishing identification strategies can be partitioned into two classifications: list-based strategies and heuristic-based techniques. As indicated by [3], numerous famous internet browsers utilize a boycott based way to deal with identify phishing assaults. On the off chance that the Uniform Resource Locater of a visited site is to be incorporated into the boycott, the site will be set apart as a phishing site. What's more, on the off chance that an authentic Uniform Resource Locater rundown is utilized to identify a phishing site, it is alluded to as a whitelist. Despite the fact that the rundown based methodology is anything but difficult to execute and has high exactness, a lot of Uniform Resource Locater list data should be kept up, and the trustworthiness of the rundown is hard to ensure. With respect to heuristic-based methodology, it defeats the issue of over-dependence on the looked after rundown. The heuristic strategy concentrates capabilities from the site and employments capabilities to order to decide the authenticity of the site. For instance, Document Object Model (DOM), Uniform Resource Locater highlights, outsider data, and content highlights [4]. With the advancement of heuristic strategies, an assortment of heuristic techniques have risen. [7] proposed a heuristic strategy called Goldphish. The center thought is to recognize the personality of a site through Google's web index. The creator first screens the website page, separates the content substance through optical character acknowledgment and after that information sources the extricated content into the Google web search tool to assess the returned outcomes. The creator accepts that Google's web crawler can return important Uniform Resource
Artificial Intelligence Techniques for Phishing
Detection
Locater by means of content. The assessment of the list items is to check whether the space names of the returned sites are steady, and on the off chance that they are extraordinary, judge them as phishing sites. Another noticeable heuristic calculation depends on machine learning techniques. For instance, [6] use machine learning techniques to recognize the authenticity of sites by breaking down lexical highlights. What's more, befuddling Uniform Resource Locater is one of the basic strategies utilized by phishing assailants, [2] and [4] proposed a heuristic discovery strategy dependent on Uniform Resource Locater highlights. Since the Uniform Resource Locater is extraordinary, phishes may utilize visual highlights to change a little number of characters to trick the client. The string similitude calculation can be utilized to discover similitude between genuine Uniform Resource Locater and phishing Uniform Resource Locater. Notwithstanding, if the phishing Uniform Resource Locater does not contain any spelling mistakes, this recognition strategy may come up short. Also [3] proposes a strategy for phishing recognition utilizing logo pictures and confirms the attainability of the logo as a recognition medium. It downloads every one of the pictures of the site and uses the SVM order model to remove the interesting logo of the site. At that point utilize the Google Image Search Library to recognize the logo personality lastly use the consistency of the Uniform Resource Locater to recognize phishing assaults. The results demonstrate that Google's acknowledgment results enormously influence the achievement rate of phishing recognition.
III. PHISHING ANALYSIS WITH VARIOUS AI TECHNIQUES
A. Neural Networks
[image:2.595.301.559.63.358.2]Neural Networks comprise of interconnected handling units called neurons. Different sorts of associations can be made between neurons to accomplish the ideal outcome. By utilizing a learning principle characterized on neural systems, it is proposed to diminish the blunder to zero [9]. The system loads can be changed for this reason. In this investigation, a neural system is utilized. In the neural systems, the data which goes to the system is handled through the info layer, the concealed layer and the yield layers separately and the outcome is acquired. Be that as it may, while the information are handled, they don't include associations inside a similar layer.
[image:2.595.62.284.643.756.2]Fig 1. Neural Network with input signals and error signals
Table 1. Estimation of neural network
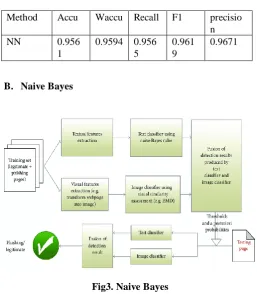
B. Naive Bayes
Fig3. Naive Bayes
Table 1. Estimation of Naive bayes
A Naive Bayes standards based content classifier is utilized to extract content from the page. Earth Mover's Distance based image classifier is utilized to manage pixel level substance the website page into the picture.
To set the proper limit, a Bayesian approach is utilized in disconnected preparing. A Bayesian based combination calculation is utilized to aggregate the results from the image and text classifiers. There are three noteworthy commitments of this methodology. First, it introduced a content classifier utilizing the guileless Bayes rule for phishing discovery. Second, it proposed a Bayesian approach to decide the edge for both the picture and text classifiers. In view of this limit, separate among phishing and real web pages. Third, they proposed another Bayesian way to deal with combine the grouping results from the content and picture classifiers
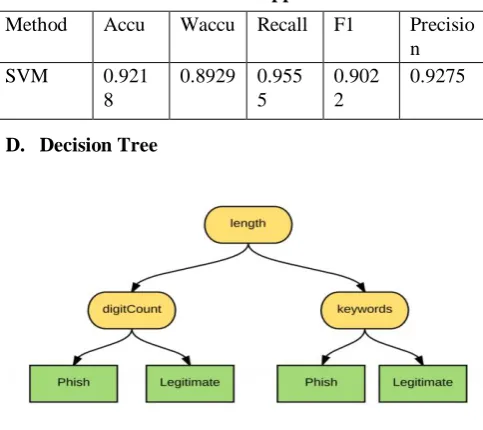
C. Support Vector Machine
Support Vector Machines expects to locate the perfect truth that isolates the two gatherings of information in a plane. From the endless number of lines, the two gatherings are chosen to be the most remote line, for example the one with the highest margin. Bolster vector machine points finding the ideal isolating hyper plane. This technique
lessens the blunder for
concealed designs [4].
There is no suspicion about
Method Accu Waccu Recall F1 precisio
n
NN 0.956
1
0.9594 0.956 5
0.961 9
0.9671
Method Accu Waccu Recall F1 precisio
n
NB 0.927
8
0.9370 0.926 0
0.927 3
the conveyance of information. In contrast with different strategies, the issue of overfitting is uncommon, adjustment to multidimensional information is simple. It tends to be adjusted to both straight and nonlinear information.
[image:3.595.316.538.138.213.2]Fig 4. Support Vector Machine
Table 2. Estimation of Support Vector Machine
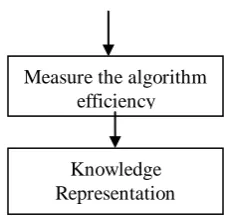
D. Decision Tree
Fig 6. Decision Tree
Choice trees can be utilized as an order technique. They demonstrate a model as tree structure comprising of choice and leaf hubs which are assessed as property and target. The choice tree calculation is created by isolating the informational collection into littler and much littler pieces.
Table 3. Estimation of Decision Tree
A choice hub may contain at least one branches. It tends to be utilized to process both numeric and class information and has low computational intricacy. Choice tree has three kinds of hubs, root hub, inward hubs and leaf-terminal hubs. In a choice tree, every class relegate to fitting leaf hubs. The remaining non-terminal hubs are given to test the states of the particular ascribes which are used to exact the distinctive normal for the information. A choice tree is developed
recursively by apportioning the preparation records into progressively cleaner subsets [5]
E. K-Nearest
K-nearest is an effective supervised learning method for many problems including security techniques.
Fig7. K-Nearest classifier
[image:3.595.44.286.288.503.2]Fig.7 shows that K-Nearest is a compelling administered learning strategy for some, issues including security procedures. K-nearest neighbor depends on the bunching of the components that have similar qualities; it chooses the class classification of a test model dependent on its k neighbor that is close to it. The estimation of k in the K-Nearest relies upon the size of dataset and the sort of the order issue . K-Nearest arranges the objective dependent on its neighbors. Fig. 7.
Table 4. Estimation of K-nearest
A k-nearest neighbor classifier K-Nearest is clarified as pursues: Find the closest components from the test information a to preparing information K dependent on Euclidean separation to compute the separation.
IV. RESEARCH METHODLOGY
Method Accu Waccu Recall F1 Precisio
n
SVM 0.921
8
0.8929 0.955 5
0.902 2
0.9275
Method Accu Waccu Recall F1 Precisio
n
DT 0.922
1
0.9332 0.938 3
0.931 2
0.9616
Method Accuracy Waccu Recall F1 Pre
cisi on K-Neares
t
0.9458 0.9576 0.958 4
0.957 3
0.9 679
phishing dataset
Preprocessing
Feature selection
[image:3.595.308.555.371.440.2] [image:3.595.355.476.509.703.2]Fig 8. Flowchart for phishing classification
Since the consequent areas in this review will look at various recognition systems, we think that its valuable to present the assessment measurements utilized in the phishing writing. In table 5 where NP→ Phishing is the quantity of phishing
examples that are accurately delegated phishing, NL→ Phishing is the quantity of genuine occurrences that are inaccurately named phishing, NP→ Legitimate is the quantity of phishing cases that are mistakenly named real, and NL→ Legitimate is the quantity of authentic cases that are effectively named real.
Table 5 Classification Confusion Matrix
Classified as phishing Classified as real Is phishing NP→
Phishing NP→ Legitimate Is genuine NL→ Phishing NL→ Legitimate Based on our audit of the writing, coming up next are the most regularly utilized assessment measurements: • True Positive rate — measures the rate of effectively distinguished phishing assaults in connection to all current phishing assaults.
True Positive = NP-->Phishing/
NP-->Phishing + NP-->Legitimate (1) • False Positive rate — measures the rate of genuine
occasions that are mistakenly recognized as phishing assaults in connection to all current real examples. False Positive = NL-->Phishing/
NL-->Legitimate + NL-->Phishing (2) • True Negative rate — measures the rate of effectively distinguished real examples in connection to all current genuine cases.
True Negative = NL-->Legitimate/
NL-->Legitimate + NL-->Phishing (3) • False Negative rate — measures the rate of phishing assaults that are erroneously identified as real in connection to all current phishing assaults.
False Negative = NP-->Legitimate/
NP-->Phishing + NP-->Legitimate (4) • Precision — measures the rate of effectively distinguished phishing assaults in connection to all occurrences that were recognized as phishing.
Positive = NP-->Phishing/
NL-->Phishing + NP-->Phishing (5) • Recall — proportionate to TP.
R = TP (6)
• f1 score — Is the symphonious mean among P and R. f1 =2PR/P + R (7) • Accuracy — measures the general rate of effectively distinguished phishing and genuine occasions in connection to all occurrences.
Accuracy =NL--->Legitimate + NP--->Phishing/
NL--->Legitimate + NL--->Phishing + NP--->Legitimate+ NP--->Phishing (8)
V. SOFTWARE TOOLS USED IN THE PHINSHING
Examined information parts by phishing recognition strategies are portrayed , to look at the discovery procedures as they are assessed in the writing. This suggests the utilization of various informational indexes, and that the outcomes are not straightforwardly similar. Be that as it may, since the assessment tests are taken from a similar populace, the contrasts ought not be critical. And their recognition rates regarding False Positive and False Negative. It tends to be seen that most of the methods don't depend on the assets over the Internet so as to perform characterization choices. We accept this is reflected because of the way that getting to assets over the Internet can be costly, and could frame a potential bottleneck. It ought to be likewise noticed that among the strategies that require Internet access incorporate, and two systems that are identified with Google Blacklists can accomplish low False Positive rates. In any case, boycotts have been assessed to be inadequate against party time assaults, as they just recognize 30% of phishing assaults at hour zero . Then again, heuristics are viable against party time assaults, anyway they should be physically adjusted to adapt. to future phishing patterns and they will in general reason high False Positive rates. All methods that utilized boycotts joined with heuristics, for example, Phish Net and Phish Wish have commonly high False Positive rates. For instance, Phish Net and Phish Wish have 6% and 9.3% False Positive rates individually, which is brought about by the heuristic trial of the discovery systems separately. Like standard based heuristics, Machine Learning-based classifiers can identify party time phishing assaults notwithstanding better adaption than future phishing qualities. The adaption to changes in phishing patterns can be accomplished through fortification learning or essentially rehashing the learning stage occasionally to build a more current model with better adaption to current phishing assault attributes. The best performing enemy of phishing email classifiers utilized Machine Learning procedures. In opposition to heuristics, Machine Learning methods were likewise ready to accomplish low False Positive rates. For instance, Andre Berghol'z model-based email classifier and Google's enormous scale site classifiers accomplished 0.1% False Positive rates. Fergus Toolan's R-Boost accomplished 1.4% False Positive rate, anyway it ought to be noticed that the point of the R-Boost strategy is to limit the False Negative rate just, which the method come to by accomplishing a False Negative rate of 0.1%. Common Language Processing methods are once in a while found in the phishing moderation writing,
Phishing /Legitimate
Phishing sites Legitimate sites
Phishing N P Phishing Np Legitimate Legitimate N L phishing NL Legitimate
Measure the algorithm efficiency
which to the best our insight to be because of absence of adequate development in NLP systems concerning effectively understanding the semantics of messages written in regular dialects that additionally may contain mistakes. Email and web perusing are basic errands and programming procedures still discovers it incredibly testing to effectively comprehend the semantics of regular languages. Moreover, many email messages can have errors, which further confounds the activity of NLP methods. A case of a NLP-based enemy of phishing system is EBDIS with a False Positive rate of 1.8%, and a False Negative rate of 35% which isn't as exact as the challenge.
VI. EXPRIEMENT AND RESULT
[image:5.595.304.544.183.336.2]As referenced in the past area, to assess each neural system classifier, we compute the normal Accuracy .
[image:5.595.42.286.283.621.2]Table 6 Evaluation of Classification algorithms
Fig 2. Neural Network classifier with specific hidden units
and Waccuracy (λ = 8) in 18 cross approval techniques for each preparation measure. when the preparation size is little, increasingly shrouded units tend to overfit the information while less concealed units tend to underfit. Be that as it may, when the preparation set is enormous enough, the quantity of shrouded units does not incredibly influence execution.To further show the overfitting of the dataset with a little preparing size, we analyze the Accuracy and Waccuracy for the 0.1% preparing set in Figure 3 and Figure 4. We see that the two bends both top at 8 shrouded units and begin to decay
as progressively concealed units are utilized. It is likewise important that the Waccuracy for the most part drops in the wake of punishing False Positive more than False Negative. We think about the Neural Network execution utilizing two enactment capacities: hyperbolic digression capacity and sigmoid capacity. The outcomes are appeared in Figure 5 and Figure 6. It is observable that the sigmoid capacity performs somewhat superior to anything the hyperbolic digression work. We additionally contrast the Neural Network execution and other AI procedures.
Fig 5. Support vector machine and Accuracy
The outcomes are appeared in Figure 7 and Figure 8. Choice tree has the best generally execution, while it misses the mark on little preparing sets contrasted with Neural Network and K-closest. By and large, most calculations can achieve a precision of 95%, which recommends that the chose list of capabilities has caught the basic qualities of phishing messages. When we perform unsupervised 2-implies bunching on the whole dataset, we can accomplish 87% precision, which further backings the legitimacy of our list of capabilities.
Fig 9.Accuracy of AI Algorithms using phishing VII. CONCLUSION
In this examination, to order the phishing assaults on the sites, neural systems, Nb, support vector machines, k-nearest and choice trees are utilized. At the point when the grouping procedure is completed, the information size utilized for preparing has been changed and tried. In Figure.
Metho d
Accura cy
Wacc u
Precision Recal l
F1
DT 0.9221 0.933
2
0.9383 0.931
2
0.9616
SVM 0.9218 0.892
9
0.9555 0.902
2
0.9275
NB 0.9278 0.937
0
0.9260 0.927
3
0.9387
K-Near est
0.9458 0.957 6
0.9584 0.957
3
0.9679
NN 0.9561 0.959
4
0.9565 0.961
9
[image:5.595.315.544.483.641.2]9 exactness consequences of the strategies are presented. It is seen that for each situation decision tree achieved the best precision.
REFERENCES
1. Pujara, Er Purvi & B Chaudhari, M. (2019). Phishing Website Detection using Machine Learning : A Review.
2. M.Arivukarasi, & Antonidoss.A. (2019). comprehensive survey of deceitful conclusion and counteractive action in multimodal datasets utilizing data mining and machine learning. Journal of adv research in dynamical and control system, vol 11.
3. Taha, Altyeb. (2017). Phishing Websites Classification using Hybrid SVM and KNN Approach. International Journal of Advanced Computer Science and Applications. 8. 10.14569/IJACSA.2017.080611.
4. yi, Ping & Guan, Yuxiang & Zou, Futai & Yao, Yao & Wang, Wei & Zhu, Ting. (2018). Web Phishing Detection Using a Deep Learning Framework. Wireless Communications and Mobile Computing. 2018. 1-9. 10.1155/2018/4678746.
5. Kumar, Sanjay & Faizan, Azfar & Viinikainen, Ari & Hamalainen, Timo. (2018). MLSPD - Machine Learning Based Spam and Phishing Detection: 7th International Conference, CSoNet 2018, Shanghai, China, December 18–20, 2018, Proceedings. 10.1007/978-3-030-04648-4_43.
6. Basnet, Ram & Mukkamala, Srinivas & Sung, Andrew. (2008). Detection of Phishing Attacks: A Machine Learning Approach. 10.1007/978-3-540-77465-5_19.
7. Lam, Thuy & Kettani, Houssain. (2019). PhAttApp: A Phishing Attack Detection Application. 10.1145/3325917.3325927.
8. Srinivasa Rao, Routhu & Ali, Syed Taqi. (2015). PhishShield: A Desktop Application to Detect Phishing Webpages through Heuristic Approach. Procedia Computer Science. 54. 147-156. 10.1016/j.procs.2015.06.017. 9. Zhu, Erzhou & Chen, Yuyang & Ye, Chengcheng & Li, Xuejun & Liu,
Feng. (2019). OFS-NN: An Effective Phishing Websites Detection Model Based on Optimal Feature Selection and Neural Network. IEEE Access. PP. 1-1. 10.1109/ACCESS.2019.2920655.
10. Liang & Lin, Derek & , Chunsheng & Zhai, Yan. (2015). A Hybrid Learning from Multi-Behavior for Malicious Domain Detection on Enterprise Network. 10.1109/ICDMW.2015.38.
11. Sinwar, Deepak & Kumar, Manish. (2014). Anomaly Detection using Decision Tree based Classifiers. 3.
12. Kumar Pernati, Madan. (2019). Web Spam Detection Using Decision Trees.
13. Nagaraj, Kalyan & Bhattacharjee, Biplab & Sridhar, Amulyashree & Sharvani, G.s. (2018). Detection of phishing websites using a novel twofold ensemble model. Journal of Systems and Information Technology. 10.1108/JSIT-09-2017-0074.
14. Chaudhary, Priyanka. (2018). Mobile Phishing Detection using Naive Bayesian Algorithm”.
15. Nivya Johny, C & K. Ratheesh, T. (2019). Novel Defence Scheme for Phishing Attacks in Mobile Phones. 10.1007/978-3-030-03146-6_136. 16. yi, Ping & Guan, Yuxiang & Zou, Futai & Yao, Yao & Wang, Wei & Zhu,