Delivering Census Interaction Data to the User: Data Provision and Software Development
Full text
Figure
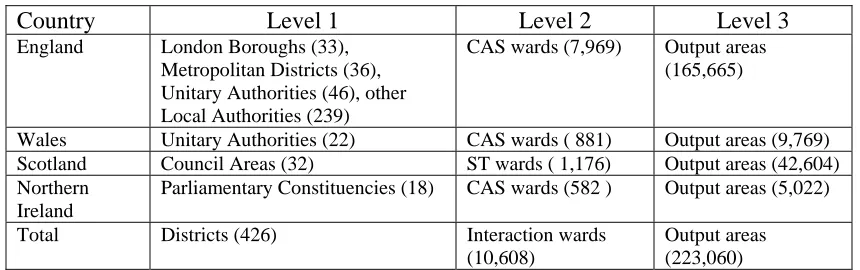
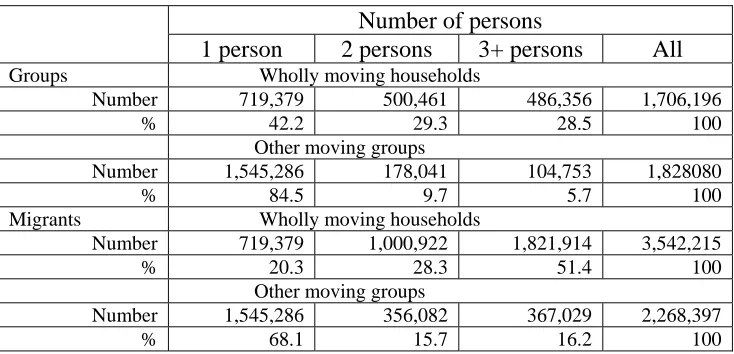



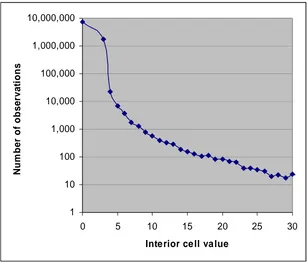

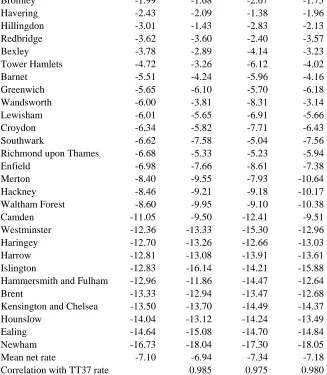
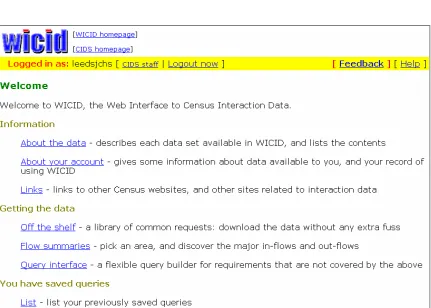

Related documents
52 Precisely synthesizing plasmonic nanostructures in ultrahigh yield; creating the plasmonically enhanced EM field on many nanostructures, often assembled in a reproducible
If the roll is equal to or higher then the model's shooting skill then it hits and wounds as described in close combat.. If the roll was lower then the model's shooting skill then
Traditionalist Salafi bypassing of centuries of Muslim legal scholarship leads Late Sunni Traditionalists to level accusations of arrogance against Traditionalist Salafis... In
HCC is developing in 85% in cirrhosis hepatis Chronic liver damage Hepatocita regeneration Cirrhosis Genetic changes
This reflects previous findings on resilience in vulnerable populations [46] and on preference for grass roots community-oriented platforms for tackling crime over
A number of studies have been done on optimal experience or “flow” but few have compared the differences between individual and team sports. The information you provide will
Public awareness campaigns of nonnative fish impacts should target high school educated, canal bank anglers while mercury advisories should be directed at canal bank anglers,
In the study presented here, we selected three rep- resentative pathogenic PV mAbs cloned from 3 different PV patients: F706, an anti-Dsg3 IgG4 isolated by heterohybridoma, F779,
