Evaluating Automatic Syllabification Algorithms for English
Yannick Marchand
1,2, Connie R. Adsett
1,2and Robert I. Damper
1,31
Institute for Biodiagnostics (Atlantic), National Research Council Canada,
1796 Summer Street, Suite 3900,
Halifax, Nova Scotia, Canada B3H 3A7
2Faculty of Computer Science, Dalhousie University,
Halifax, Nova Scotia, Canada B3H 1W5
3School of Electronics and Computer Science
University of Southampton, Southampton SO17 1BJ, UK
{yannick.marchand, connie.adsett}@nrc-cnrc.gc.ca, [email protected]
Abstract
Automatic syllabification of words is challenging, not least be-cause the syllable is difficult to define precisely. This task is im-portant for word modelling in the composition process of con-catenative synthesis as well as in automatic speech recognition. There are two broad approaches to perform automatic syllabifi-cation: rule-based and data-driven. The rule-based method ef-fectively embodies some theoretical position regarding the syl-lable, whereas the data-driven paradigm infers ‘new’ syllabifi-cations from examples assumed to be correctly-syllabified al-ready. This paper compares the performance of the two ba-sic approaches. However, it is difficult to determine a correct syllabification in all cases and so to establish the quality of the ‘gold standard’ corpus used either to quantitatively evaluate the output of an automatic algorithm or as the example-set on which data-driven methods crucially depend. Thus, three lexi-cal databases of pre-syllabified words were used. Two of these lexicons hold the same 18,016 words with their corresponding syllabifications coming from independent sources, whereas the third corresponds to the 13,594 words that share the same syl-labifications according to these two sources. As well as one rule-based approach (Fisher’s implementation of Kahn’s syl-labification theory), three data-driven techniques are evaluated: a look-up procedure, an exemplar-based generalization tech-nique, and syllabification by analogy (SbA). The results on the three databases show consistent and robust patterns: the data-driven techniques outperform the rule-based system in word and juncture accuracies by a very significant margin and best results are obtained with SbA.
1. Introduction
The syllable has been much discussed as a linguistic unit. Whereas some linguists make it central to their theories (e.g., [1, 2]), others have ignored it or even argued against it as a use-ful theoretical construct (e.g., [3]). Much of the controversy centers around the difficulty of defining the syllable. Crystal [4], for instance, states that the syllable is “[a] unit of pronun-ciation typically larger than a single sound and smaller than a word” but goes on to write: “Providing a precise definition of the syllable is not an easy task” [p. 342]. There is general agree-ment that a syllable consists of anucleusthat is almost always a vowel, together with zero or more preceding consonants (the
onset) and zero or more following consonants (thecoda). How-ever, determining exactly which consonants of a multisyllabic word belong to which syllable is problematic. Good general ac-counts of the controversy are provided by [5] and [6], with the former more specifically considering English—the language of interest in this paper—and the latter focusing on French.
However it is defined, and whatever the rights or wrongs of theorising about its linguistic status, syllable knowledge aids word modeling in automatic speech recognition and/or the unit selection and composition process of concatenative synthesis. For instance, M¨uller, M¨obius and Prescher [7] write “syllable structure represents valuable information for pronunciation sys-tems” [p. 225]. That is, the pronunciation of a phoneme can de-pend upon where it is in a syllable and therefore there are good practical reasons for seeking powerful algorithms to syllabify words.
Traditional approaches to automatic syllabification have been rule-based(or knowledge-based), implementing notions such as the maximal onset principle [1, 8] and sonority hierar-chy [9], including ideas about what constitute phonotactically legal sequences in the coda, for instance. An alternative to the rule-based methodology is the data-driven(or corpus-based) approach, which attempts to infer ‘new’ syllabifications from an evidence base of already-syllabified words (i.e., a dictionary or lexicon1).
This paper compares the performance of these two basic approaches to automatic syllabification in the pronunciation do-main. Our work attempts to bepredictive, aimed at finding good syllabifications for practical application in speech technology and computational linguistics, rather thandescriptive, aimed at explaining experimental data and/or giving insight into any lin-guistic theory of the syllable.
2. Electronic lexical databases
A key issue in assessing algorithms for automatic syllabifica-tion is the quality of the ‘gold standard’ corpus used to define the correct result. Further, in the data-driven paradigm, this cor-pus forms the evidence base for inferring new syllabifications;
1In this paper, we will use the termsevidence base,lexical database,
hence, it is vital that its content is accurate. This, however, is extremely difficult due to the absence of any means of deter-mining canonically correct syllabifications. Our approach is to use multiple dictionaries and to seek consensus among them, so as to reduce the possibility that our results are affected by the choice of a particular, idiosyncratic corpus.
In this work, we used two public-domain dictionaries— Webster’s Pocket Dictionary and the Wordsmyth English Dictionary-Thesaurus—as the sources from which we derive three lexical databases, as described below.
2.1. Webster’s Pocket Dictionary
The primary lexical database in this work isWebster’s Pocket Dictionary (20,009 words), as used by [10] to train their NETtalk neural network. The database is publicly available for non-commercial use fromftp://svr-ftp.eng.cam. ac.uk/pub/comp.speech/dictionaries/ (last ac-cessed 11 May 2007). For consistency with our previous work on pronunciation using this dictionary, homonyms (413 en-tries) were removed from the original NETtalk dataset leav-ing 19,596 entries. Sejnowski and Rosenberg have manually aligned the data, to impose a strict one-to-one correspondence between letters and phonemes2. The phoneme inventory is of size 51, including the null phoneme and ‘new’ phonemes (e.g., /K/ and /X/) invented to avoid the use of null letters when one letter corresponds to two phonemes, as in <x>→/ks/. The null phoneme (represented by the ‘–’ symbol) was introduced to give a strict one-to-one alignment between letters and phonemes to satisfy the training requirements of NETtalk. In this paper, we retain the use of the original phonetic symbols (see [10], Ap-pendix A, pp. 161–162) rather than transliterating to the sym-bols recommended by the International Phonetic Association. We do so to maintain consistency with this publicly-available lexicon.
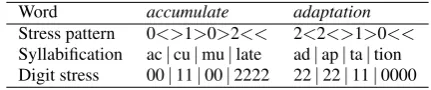
In addition to the pronunciation, Sejnowski and Rosenberg have also indicated stress and syllabification patterns for each word. The form of the data is:
accumulate xk-YmYlet- 0<>1>0>2<<
adaptation @d@pteS-xn 2<2<>1>0<<
The second column is the pronunciation and the third column encodes the syllable boundaries for the words and their corre-sponding stress patterns:
< denotes syllable boundary (right)
> " syllable boundary (left) 1 " primary stress 2 " secondary stress 0 " tertiary stress
Stress is associated with vowel letters and arrows with conso-nants. The arrows point towards the stress nuclei and change di-rection at syllable boundaries. To this extent, “syllable bound-ary (right/left)” is a misnomer because this information is not adequate by itself to place syllable boundaries directly. We can, however, infer four rules (or regular expressions) to identify syl-lable boundaries. Denoting boundaries by ‘|’:
R1: [<>]⇒[<|>]
R2: [<digit]⇒[<|digit]
R3: [digit>]⇒[digit|>]
R4: [digit digit]⇒[digit|digit]
2See [11] for extensive discussion of this alignment process and an
algorithm for doing it automatically.
Word accumulate adaptation
Stress pattern 0<>1>0>2<< 2<2<>1>0<<
[image:2.595.316.532.73.118.2]Syllabification ac|cu|mu|late ad|ap|ta|tion Digit stress 00|11|00|2222 22|22|11|0000
Table 1:Examples of stress and syllabification patterns.
These have been confirmed as correct by Sejnowski (personal communication). Table 1 gives the syllable patterns of the three above examples.
2.2. Wordsmyth English Dictionary-Thesaurus
Disagreements may exist about the way a word should be seg-mented into syllables. A second (independent) lexical source was therefore used, namely theWordsmyth English Dictionary-Thesaurus, so that our results would not be overly specialized to one particular dictionary. This source is also available via the World Wide Web fromwww.wordsmyth.net(last ac-cessed 11 May 2007). This on-line lexical database originated in the early 1980’s when Robert Parks, a Fulbright Fellowship researcher in Japan, began to develop an English dictionary for students to use on their computers. In 1991 and 1992, the dic-tionary was licensed to IBM to integrate into their products, and IBM in turn supported the development of the associated the-saurus. In 1996, the University of Chicago’s ARTFL (American and French Research on the Treasury of the French Language) Project assisted in presenting the first World Wide Web edition. The dictionary is composed of about 50,000 headwords cov-ering all areas of knowledge without technical vocabulary. It provides the syllables, pronunciation, part of speech, inflected forms, and definition for each word.
2.3. The three lexical databases
Homonyms were removed from the originalWebster’s Pocket Dictionaryleaving 19,596 entries. Of these words, 18,016 were also found in the Wordsmyth English Dictionary-Thesaurus. These two independant dictionaries, each consisting of 18,016 syllabified entries, are referred to asS&RandWordsmyth, re-spectively. A third database of syllabified words (hereafter Overlap) was derived consisting of the 13,594 words present in both public-domain dictionaries with identical syllabification patterns in these two independent lexical sources.
3. Syllabification algorithms
In this section, we briefly describe the four automatic syllabifi-cation techniques for which performance was compared.
3.1. Fisher’s implementation of Kahn’s procedure
/@n|breId/. By contrast, /rk/ is considered a universally-bad syllable-initial consonant cluster because no English word be-gins with this sound combination. Therefore the pronunciation /mark@t/ (<market>) would be syllabified as /mar|k@t/ and not /ma|rk@t/.
A C implementation of Kahn’s theory was developed in 1996 by William Fisher and can be downloaded from the file: ftp://jaguar.ncsl.nist.gov/pub/ tsylb2-1.1.tar.Z(last accessed 11 May 2007). Because we were interested in the standard syllabification, we selected the two most appropriate of the five speech rates available in the program, the “slow, over-precise” (hereafter Basic) and the “ordinary conversational speech” (hereafter OCS) rates. The program also allowed the unsyllabified input to be provided with stress information (primary, secondary and no stress) on some specific phonemes3 and without stress information. We processed the word list both ways, using the stress informa-tion provided inS&R(i.e., the digit stress—see Table 2.1). The phoneme set used in his program was translated to the phoneme set ofS&Rand all instances of the null phoneme were also re-moved because this special ‘phoneme’ was not part of Fisher’s set.
3.2. Syllabification by analogy
Syllabification by analogy closely follows the principles of pro-nunciation by analogy (PbA) set out in detail in our earlier pub-lications [12, 13, 14, 15]. In PbA, when an unknown word is presented as input to the system, so-called full pattern match-ing between the input letter strmatch-ing and dictionary entries is per-formed, starting with the initial letter of the input string aligned with the end letter of the dictionary entry. If common letters are found in matching positions in the two strings, their cor-responding phonemes (according to the prior alignment) and information about their positions in the input string are used to build a pronunciation lattice, as detailed below. One of the two strings is then shifted relative to the other by one letter and the matching process continues, until the end letter of the input string aligns with the initial letter of the dictionary entry.
The pronunciation lattice is a directed graph that defines possible pronunciations for the input string, built from the matching substring information. A lattice node represents a matched letter,Li, at some position,i, in the input. The node is labelled with its positioniand the phoneme corresponding toLiin the matched substring,Pimsay, for themth matched substring. An arc is labelled with the phonemes intermedi-ate betweenPimandPjm(j > i) in the phoneme part of the matched substring and the frequency count, increasing by one each time the substring with these phonemes is matched dur-ing the search through the lexicon. Arcs are directed from i
to j. If the arcs correspond to bigrams, the arcs are labelled only with the frequency. (The string of phonemes intermediate betweenPimandPjmis empty.) PhonemesPimandPjm la-bel the nodes at each end of the arc, i.e.,iandjrespectively. Additionally, there is aStartnode at position 0 and anEndnode at position equal to the length of the input string plus one.
Finally, the decision function identifies the ‘best’ candidate pronunciation of the input according to some criterion. Possi-ble pronunciations correspond to the string assemPossi-bled by con-catenating the phoneme labels on the nodes or arcs in the or-der that they are traversed in moving through the lattice from
3. . . designated as syllabic by Fisher. These are: ‘ux’, ‘ih’, ‘ix’, ‘ey’,
‘eh’, ‘ae’, ‘aa’, ‘aax’, ‘s’, ‘ao’, ‘ow’, ‘uh’, ‘uw’, ‘ay’, ‘oy’, ‘aw’, ‘er’, ‘axr’, ‘ax’, ’ah’, ‘el’, ‘em’, and ‘en’ using his phoneme notation.
StarttoEnd. If there is just one candidate corresponding to a unique shortest path, this is selected as the output. If there are tied shortest paths, five different scoring strategies are applied and the winning candidate selected on the basis of their rank [13, 14].
The major modification in converting PbA to SbA is to rep-resent all junctures between phonemes explicitly. This repre-sentation must be different in the case of:
1. input words, where the syllabification is unknown; 2. lexical entries, where it is known;
3. the SbA output, where it is inferred.
For example, the input pronunciation /@bi/4(<abbey>) is ex-panded to /@∗b∗i/. Here the ‘∗’ symbol merely indicates the possibility of a syllable boundary. On the other hand, a dictionary entry such as /@bncrmL/<abnormal>is expanded to /@∗b|n∗c∗r|m∗L/. In this case, the ‘∗’ symbols indi-cate the known absence of a syllable boundary. During pattern matching, ‘∗’ in the input is allowed to match either with ‘∗’ or with ‘|’ in the dictionary entries. A ‘∗–∗’ match is entered into the syllabification lattice as a ‘∗’ whereas a ‘∗–|’ match is entered into the syllabification lattice as a ‘|’. The syllabi-fication lattice has exactly the same form as the pronunciation lattice, except that ‘∗’ is explicitly represented as an input sym-bol (labelling nodes), ‘∗’ and ‘|’ are explicitly represented as possible output symbols (labelling arcs), and there is no pro-nunciation information labelling the nodes and arcs. From here, the process proceeds exactly as for PbA, eventually produc-ing as output a syllabified version of /@bi/<abbey>such as /@∗b|i/, from which the ‘∗’ symbols are removed to yield the final output /@b|i/. The modifications to perform SbA in the pronunciation domain should now be obvious.
In our previous syllabification work using analogy [15], we obtained best results by combining only 3 of the 5 scoring strategies when choosing between tied shortest paths. These were the product of arc frequencies, the frequency of the same pronunciation, and the ‘weak link’ (see [13] and [14] for full specification). Accordingly, in this work, these same three scor-ing strategies are used exclusively, and combined by rank fu-sion, for SbA.
3.3. Look-up procedure
This method was originally proposed by [16] as a means of letter-to-phoneme conversion (i.e., automatic pronunciation), where it was shown to be superior to NETtalk, the well-known neural network [10]. It was then adapted for the syllabification process and presented in the comparison of syllabification algo-rithms for Dutch spellings by [17]. The first step is to construct a table encoding the knowledge implicit in the training set by converting each syllabified entry into a series ofN-grams. Each
N-gram has a left and right context and a central, ‘focus’ char-acter. The length of theN-gram (i.e.,N) is equal to the sum of the sizes of the left and right contexts plus one (the focus character).
For example, if the syllabified word /KId|ni/ (<kid|ney>) is part of the training corpus, then with a left context of 1 char-acter and a right context of 2 charchar-acters, theN-grams (or 4-grams in this case) for this word would be:<– KId>,<KIdn>,
<Idni>,<dni –>, and<ni – –>. That is, to allow every char-acter to be a focus charchar-acter, there is anN-gram for each char-acter in a word. When the focus charchar-acter has no left context 4Examples from this point on use the phoneme set fromWebster’s
(as in<– KId>) or right context (as in<ni – –>), the character positions in the context are filled with null characters. EachN -gram is stored in the table along with the corresponding juncture class, i.e., the syllabification information.
Once the construction of the look-up table is complete, words for which the syllabification is unknown can be syllab-ified based on the information in the table. Input words are broken down into a set of N-grams in the same manner de-scribed above for table construction. The table is then searched for the closest matches to eachN-gram. When found, closest matches are examined to determine whether the majority has, or does not have, a syllable boundary following the focus charac-ter. If the majority has a syllable boundary, a syllable boundary is placed at the appropriate position in the word; otherwise, a non-syllable boundary is placed at that position.
The process of determining which N-grams in the pre-compiled look-up table fit best a given N-gram is described in Algorithm 1. Here,NgramT is a givenN-gram stored in the table andNgramSis anN-gram to be syllabified. It fol-lows thatNgramT[i]is theith position in theN-gram (for example,NgramT[1] = mwhenNgramTis<midn>). The closest-fitN-grams are those with the highestMatchValue.
Algorithm 1: Computation of best-fitN-gram in the look-up procedure.
FindMatchValue(weights, NgramT, NgramS) MatchValue := 0
fori := 1tolength(weights)do if(NgramT[i] = NgramS[i])then
MatchValue := MatchValue + weights[i]
end if end for
We ran the look-up procedure using all 15 different sets of weights presented in the original description of the method [16].
3.4. Exemplar-Based Generalization
The version tested here (also known as IB1-IG) is due to [18]. It operates in a manner similar to the look-up procedure with the only difference being the weights used to determine the closest-fitN-grams. In this method, the weights are calculated with a function that determines the relative importance of each posi-tion in theN-gram (i.e., phoneme positions). The process of determining the weights is based on the concept of information entropy by using information from the table of storedN-grams. Each position in anN-gram is considered to contribute a real-valued amount of information to the process of determining the placement of a syllable boundary. This value can be determined via the series of steps presented below.
First, the entropy of the entire table ofN-grams extracted from the training corpus is calculated. Essentially, Daelemans, van den Bosch and Weijters define database (or look-up ta-ble) information entropy as “the number of bits of informa-tion needed to know the decision [whether a syllable boundary should be placed after the focus character or not] of a database given a pattern [orN-gram].” This is calculated as:
E(D) =−
2 X
i=1
Pilog2Pi (1)
whereE(D)is the information entropy of databaseD, P1 is
the probability of anN-gram being associated with a
syllable-boundary decision, andP2is the probability of anN-gram
be-ing associated with a non-syllable-boundary decision. As there are only two possibilities—to place or not to place a syllable boundary after the focus character—equation (1) can also be written as:
E(D) =−αlog2α+βlog2β
whereα= NS NT
andβ=N¬S NT
(2)
whereNSis the number of storedN-grams that have a syllable boundary following the focus character,N¬Sis the number of storedN-grams that do not have a syllable boundary following the focus character, andNT is the number of storedN-grams (i.e.,NS+N¬S).
From equation (2), the information gain of each position in anN-gram can now be determined. This requires two ad-ditional equations. The first computes the average information entropy at positionfin anN-gram,E(Df), by taking the “in-formation entropy of the database [or table] restricted to each possible value [or character] for the [position in theN-gram].” This is given by:
E(Df) =
X
c∈V
E(Df=c)
card(Df=c) card(D)
whereDf=cis the set of thoseN-grams in the table that have charactercat positionf,V is the set of characters that occur at positionfin aN-gram, and card( ) is the cardinality of a set (i.e., card(D) is the total number ofN-grams in databaseD).
The second equation necessary for calculating the informa-tion gainG(f)at a given positionfin anN-gram is:
G(f) =E(D)−E(Df)
To run this method, we first followed Daelemans, van den Bosch and Weijters and used the same values ofN as in their work, namely 3, 5 and 7 with the focus letter in the middle of theN-gram. In addition to these values, we extended the study to useN-grams of size 9 and 11 (with left and right contexts of 4 and 5 respectively).
4. Results
For the rule-based method, there is no difficulty in evaluating syllabification performance on each of the three datasets in their entirety. For data-driven methods, we use the well-established leave-one-out procedure, whereby each word is removed from the corpus in turn, and its syllabification inferred from the re-maining words.
Tables 2, 3 and 4 show the results for the various automatic syllabification methods on the S&R, Wordsmythand Overlap databases. For table look-up, the three sets of weights which provided the best results (for each dictionary) are presented in the tables5. Results were obtained forN-grams fromN = 5
up toN = 11for the exemplar-based approach. As expected, results were poor forN= 3as insufficient context is captured around the focus phoneme, and byN = 11the algorithm in-dicates that performance was falling off. For the Fisher/Kahn system, there was no difference between the results when stress was provided and when it was not for the Basic (slow) rate of
5Version 8:[1,4,16,4,2]; Version 10:[1,4,16,64,16,5,1]; Version
Accuracy
Algorithm Word Juncture | *
Fisher/Kahn
Basic 54.23 78.93 62.63 85.34
OCS 54.14 77.47 59.84 84.41
OCS with stress 68.97 86.41 75.65 90.64
SbA 88.53 96.02 92.29 97.50
Look-up Table
1st, version 10 80.20 94.95 90.51 96.70 2nd, version 8 79.75 94.90 90.49 96.63 3rd, version 13 79.40 94.78 89.90 96.70 Exemplar-based
N= 5 76.47 94.17 87.54 96.79
N= 7 79.37 94.80 88.92 97.11
N= 9 79.36 94.78 89.04 97.04
[image:5.595.316.537.73.242.2]N= 11 79.10 94.71 88.91 96.99
Table 2:Syllabification results (percentage correct) on theS&R database for word and juncture accuracy.
Accuracy
Algorithm Word Juncture | *
Fisher/Kahn
Basic 58.02 81.34 67.04 86.91
OCS 52.58 75.93 57.16 83.24
OCS with stress 63.37 83.40 70.49 88.43
SbA 85.88 94.87 90.32 96.64
Look-up Table
1st, version 10 75.71 93.41 87.93 95.54 2nd, version 8 75.37 93.36 87.96 95.47 3rd, version 11 74.86 93.26 87.44 95.53 Exemplar-based
N= 5 72.92 92.81 85.04 95.84
N= 7 74.92 93.17 85.76 96.05
N= 9 82.90 95.54 89.23 97.71
[image:5.595.63.282.73.243.2]N= 11 74.87 93.12 85.86 95.96
Table 3: Syllabification results (percentage correct) on the Wordsmythdatabase for word and juncture accuracy.
speech. However, this was not the case for the ordinary con-versational speech condition, where the inclusion of stress im-proves the results.
Results are remarkably consistent across dictionaries. The rule-based method (Fisher/Kahn) is much worse than the data-driven methods. We do not think such a rule-based method is valuable in computational linguistics and/or speech technology. In regards to the data-driven methods, it is difficult to choose between the best table look-up and exemplar-based results al-though the former does better on two of the three dictionaries. The most striking result, however, is the obvious superiority of SbA.
These tables also show junctures-correct performance over-all, as well as the percentages of correct syllable (|) and non-syllable (*) identifications. For all methods, non-syllable boundary identification is less error prone than syllable bound-ary detection. It seems that all methods are conservative in their placement of syllable boundaries, which are rarer than non-syllable boundaries, resulting in a preponderance of false negative errors over false positives.
Accuracy
Algorithm Word Juncture | *
Fisher/Kahn
Basic 63.40 83.54 67.80 88.97
OCS 60.90 79.68 60.07 86.44
OCS with stress 74.42 88.14 76.56 92.13
SbA 91.08 96.82 92.90 98.17
Look-up Table
1st, version 10 83.66 95.74 90.58 97.52 2nd, version 8 83.60 95.76 90.66 97.52 3rd, version 11 82.71 95.55 89.99 97.47 Exemplar-based
N = 5 81.26 95.20 88.51 97.50
N = 7 83.12 95.56 89.28 97.73
N = 9 82.90 95.54 89.23 97.71
N = 11 82.87 95.52 89.23 97.69
Table 4: Syllabification results (percentage correct) on the Overlapdatabase for word and juncture accuracy.
5. Conclusions
Automatic syllabification is an important but difficult problem that has implications on pronunciation generation for text-to-speech synthesis and pronunciation modeling in text-to-speech recog-nition. There are essentially two possible approaches to auto-matic syllabification: rule-based and data-driven.
In this work, we have compared one rule set based on ex-pert knowledge and three data-driven methods based on auto-matic inference from a corpus of already-syllabified words. In the latter case, the issue of a gold standard arises. We attempt to address this by using two independent dictionaries of syllab-ified words. We also use the ‘overlap’ or conjunction of entries in the different dictionaries as a separate corpus which ought to be closer to a gold standard than either of the individual contrib-utors, since it does not include words on which they disagree. In this work, we have used two independent dictionaries (S&Rand Wordsmyth) and their overlap. The four methods studied are the rule set from Fisher/Kahn, a table look-up method developed by Weijters, the exemplar-based method of Daelemans, van den Bosch and Weijters and syllabification by analogy (SbA) from Marchand and Damper. In each case, performance is evaluated across the whole of each available corpus.
Syllabification performance is found to be very consistent across dictionaries in terms of the relative merits of the four techniques. The knowledge-based rule set performs poorly compared to the data-driven methods. Among the data-driven methods, SbA is easily the best. With regards to the dictionar-ies, best performance is obtained on theOverlapdictionary— probably because the overlap process removes idiosyncratic en-tries fromS&RandWordsmyth.
6. Acknowledgements
This work was supported in part by funding from the Nat-ural Sciences and Engineering Research Council of Canada (NSERC). In addition, the second author was funded by the National Research Council (NRC) Graduate Student Scholar-ship Supplement Program (GSSSP), and an Izaak Walton Kil-lam Predoctoral Scholarship.
7. References
[1] E. Pulgram,Syllable, Word, Nexus, Cursus. The Hague, The Netherlands: Mouton, 1970.
[2] E. Selkirk, “The syllable,” inThe Structure of Phonologi-cal Representations, H. van der Hulst and N. Smith, Eds. Dordrecht, The Netherlands: Foris, 1982, vol. 2, pp. 337– 383.
[3] K. J. Kohler, “Is the syllable a phonological universal?” Journal of Linguistics, vol. 2, no. ??, pp. 207–208, 1966. [4] D. Crystal,A First Dictionary of Linguistics and
Phonet-ics. London: Andr´e Deutsch, 1980.
[5] R. Treiman and A. Zukowski, “Toward an understanding of English syllabification,”Journal of Memory and Lan-guage, vol. 29, no. 1, pp. 66–85, 1990.
[6] J. Goslin and U. H. Frauenfelder, “A comparison of theo-retical and human syllabification,”Language and Speech, vol. 44, no. 4, pp. 409–436, 2000.
[7] K. M¨uller, B. M¨obius, and D. Prescher, “Inducing prob-abilistic syllable classes using multivariate clustering,” in Proceedings of 38th Annual Meeting of the Association for Computational Linguistics, Hong Kong, China, 2000, pp. 225–232.
[8] D. Kahn, Syllable-Based Generalizations in English Phonology. Bloomington, IN: Indiana University Lin-guistics Club, 1976.
[9] G. N. Clements, “The role of the sonority cycle in core syllabification,” 1988, working Papers of the Cornell Pho-netics Laboratory, WPCPL No. 2, Research in Laboratory Phonology, Cornell University, Ithaca, NY.
[10] T. J. Sejnowski and C. R. Rosenberg, “Parallel networks that learn to pronounce English text,”Complex Systems, vol. 1, no. 1, pp. 145–168, 1987.
[11] R. I. Damper, Y. Marchand, J.-D. S. Marsters, and A. I. Bazin, “Aligning text and phonemes for speech technol-ogy applications using an EM-like algorithm,” Interna-tional Journal of Speech Technology, vol. 8, no. 2, pp. 149–162, 2005.
[12] R. I. Damper and J. F. G. Eastmond, “Pronunciation by analogy: Impact of implementational choices on perfor-mance,”Language and Speech, vol. 40, no. 1, pp. 1–23, 1997.
[13] Y. Marchand and R. I. Damper, “A multistrategy approach to improving pronunciation by analogy,” Computational Linguistics, vol. 26, no. 2, pp. 195–219, 2000.
[14] R. I. Damper and Y. Marchand, “Information fusion ap-proaches to the automatic pronunciation of print by anal-ogy,” Information Fusion, vol. 71, no. 2, pp. 207–220, 2006.
[15] Y. Marchand and R. I. Damper, “Can syllabification im-prove pronunciation by analogy?”Natural Language En-gineering, vol. 13, no. 1, pp. 1–24, 2007.
[16] A. Weijters, “A simple look-up procedure superior to NETtalk?” in Proceedings of International Conference on Artificial Neural Networks (ICANN-91), vol. 2, Espoo, Finland, 1991, pp. 1645–1648.
[17] W. Daelemans and A. van den Bosch, “Generalisation per-formance of backpropagation learning on a syllabification task,” inTWLT3: Connectionism and Natural Language Processing, M. F. J. Drossaers and A. Nijholt, Eds. En-schede, The Netherlands: Twente University, 1992, pp. 27–37.
[18] W. Daelemans, A. van den Bosch, and T. Weijters, “IGTree: Using trees for compression and classification in lazy learning algorithms,”Artificial Intelligence Review, vol. 11, no. 1–5, pp. 407–423, 1997.