Software Engineering Frameworks pdf
Full text
Figure
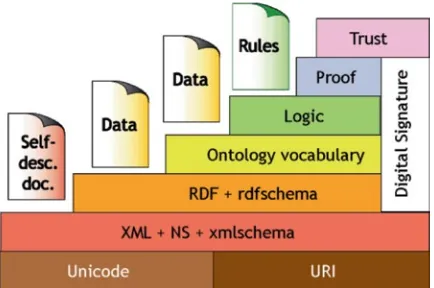
![Fig. 1.7 Linking open data cloud diagram giving an overview of published data sets and their interlinkage relationships [7]](https://thumb-us.123doks.com/thumbv2/123dok_us/8102079.234339/33.439.58.383.64.300/linking-cloud-diagram-giving-overview-published-interlinkage-relationships.webp)
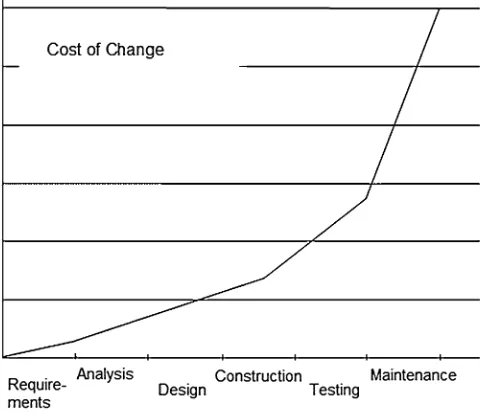
![Fig. 1.12 Extended COCOMO for SW dev. time [29]](https://thumb-us.123doks.com/thumbv2/123dok_us/8102079.234339/40.439.76.261.60.231/fig-extended-cocomo-for-sw-dev-time.webp)

Outline
Related documents
* Partial company results based on A&D activity, identified by A&D specific business segment where possible. Source: DTTL’s Global Manufacturing Industry group analysis of
Alternatively Certified Teachers – Teachers who have not graduated from an approved college or university teacher preparation program with a full teaching license; rather those
The conclusions of the present study are based on the post- release mortality estimates from the submerged-cage study rather than the floating-net-pen study, because the estimates
In the �nal application the public has the possibility to explore the virtual tomb, to get close up to the artifacts and to listen to the narrative contents directly from the
This publication presents the main outcomes of a partnership working towards “Harmonising Approaches to Professional Higher Education in Europe” (HAPHE) in 2012–2014,
Food based dietary guidelines Nutrition Centre Guidelines Healthy Diet Health Council Reference intakes Health Council Nutritional composition NEVO Wo5 or not-Wo5. Amounts
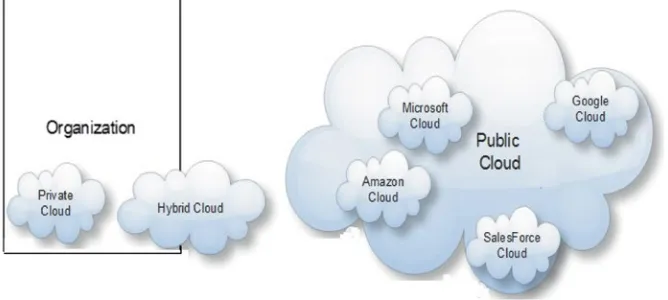
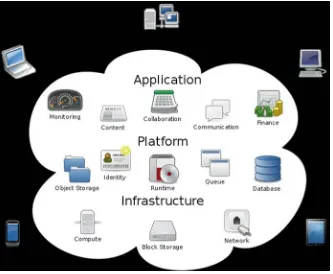
Clouds servicing models Private (On-Premise) Storage Server HW Networking Servers Databases Virtualization Runtimes Applications Security & Integration Y ou manag e
• multiply and divide integers using one of two methods: the table method or the like/unlike method.. Integers – Multiplying and
