Abstract: With the developing utilization of data innovation in all life areas, hacking has turned out to be more contrarily powerful than any other time in recent memory. Additionally, with creating advances, assaults numbers are developing exponentially like clockwork and become progressively refined so conventional I.D.S ends up wasteful recognizing them. We accomplish those outcomes by utilizing Networking Chabot, a profound intermittent neural system: Long Short Term Memory (L.S.T.M) [2]over Apache Spark Framework that has a contribution of stream traffic and traffic conglomeration and the yield is a language of two words, typical or strange.
The new and proposed blending ideas of the language are preparing, relevant examination, circulated profound adapting, huge information, and oddity discovery of stream investigation. We propose a model that portrays the system dynamic typical conduct from an arrangement of a great many parcels inside their unique circumstance and examines them in close to constant to identify point, aggregate and relevant inconsistencies. The examination shows lower false positive, higher identification rate and better point abnormalities location. With respect to demonstrate of relevant and aggregate oddities identification, we talk about our case and the explanation for our speculation. Be that as it may, the investigation is done on arbitrary little subsets of the dataset as a result of equipment restrictions, so we offer examination and our future vision musings as we wish that full demonstrate will be done in future by other intrigued specialists who have preferable equipment foundation over our own..
Keywords:-I.D.S, L.S.T.M, R.N.N, M.A.W.I, M.A.W.ILAB, A.G.U.R.IM.
I. INTRODUCTION
As of late, we have seen heaps of genuine instances of assaults' tremendous effects in various areas, for example, legislative issues and financial matters. Hacking has turned out to be more basic and riskier than any other time in recent memory. The quantity of hacking assaults is developing exponentially like clockwork. That implies signature-based
Revised Manuscript Received on November 05, 2019. * Correspondence Author
J.S.V.G.Krishna, Associate rofessor of CSE, Sir CRR Engineering College, Eluru. AP. INDIA. Email: [email protected]
Dr.M.Venkateswara Rao, Professor of IT, GITAM Uniersity, Visakhapatnam, AP, India. Email: [email protected]
K.Sudhakar, Associate Professor of CSE, PSCMR College of Engineering and Technology, Vijayawada, AP, India. Email:
I.D.S aren’t helpful any longer as we can't refresh it with new marks like clockwork. Likewise, with creating innovations assaults become increasingly complex, APT assaults are more typical than any time in recent memory. Customary I.D.S wind up wasteful. Different reasons why conventional I.D.S can't bolster long haul, huge scale examination as [1] said. 1. Holding huge amounts of information wasn't monetarily attainable previously.
2. Performing examination and complex questions on enormous, unstructured datasets with fragmented and uproarious highlights, was wasteful
3. The administration of huge information distribution centers has generally been costly, and their sending for the most part requires solid business cases. The Hardtop system and other enormous information devices are currently commoditizing the arrangement of huge scale, solid bunches and consequently are empowering new chances to process and break down information.
II. DESIGNPROCESS
A. I.D.S and its Types:
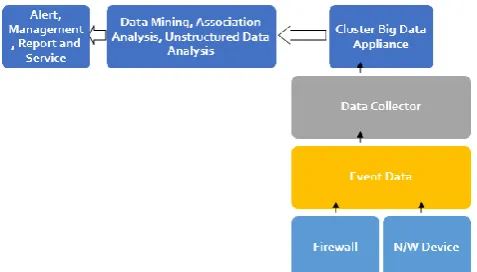
[image:1.595.313.540.607.736.2]I.D.S as a rule has three essential sorts dependent on its area: have I.D.S, arrange I.D.S and mixture I.D.S, as indicated in Fig. 1. System I.D.S is the space of this analysis, so we will discuss in more subtleties. After profound research, we finish up NI.D.S[4] Hierarchy appeared in Fig. 2. NI.D.S has two fundamental sorts dependent on the information source that it is observing.
Figure 1: The Intrusion Detection System Categories
Enormous Information Examination using Big
Data in a Distributed Environment with
Profound Learning of Next Generation
Interruption Identification Framework
Enhancement
Figure 2: NI.D.S Categories (no reference, it is our conclusion)
• Traffic-based that contains the entire bundles' information, headers and bodies.
• Flow-based that contains just headers of parcels.
With respect to Traffic-based (parcel level NI.D.S), likewise called Deep Packet Inspection (DPI) or customary bundle level NI.D.S, it is viewed as tedious with regards to huge information systems (more than 1 TB in second) or it will require a significant expense of required servers for only a little streamlining in execution, so we need to choose a tradeoff cost and exactness. A few scientists channel a few bundles to decrease costs [3]. With respect to Flow-based (stream level NI.D.S), additionally thought to be Behavioral Analyzer NI.D.S, the body of every parcel is disregarded, just headers of bundles are utilized to remove tuples. [5]Each tuple has five qualities Source IP, Destination IP, Source Port, Destination Port, Protocol. Stream level is superior to anything parcel level in huge systems with regards to the expense of handling and capacity, as it has less cost since it forms just headers without bodies.
Stream based approach is a lightweight process, all in all Flow level NIDS[6], uses peculiar discovery strategy and parcel level NIDS uses signature based location techniques.
Anomaly Network Attack
Point U2R, R2L
Contextual Scanning Probe
Collective DoS
Table 1: Attacks in network
B. Anomaly Types: Anomaly-I.D.S distinguish just point peculiarities. In any case, irregularities have numerous sorts that should be identified. Indeed, even it might be significantly more hazardous and progressively normal. Three essential classifications of abnormalities are.
I. From Fig 3. Inconsistency which was frequent and abnormally deviated with no specific importance. For example, Client always want to be root (U-to-R)
II. Aggregation of anomalies, as indicated in Fig. 4, speaks the gathering of connected, interconnected or consecutive. While every specific case of this gathering doesn't need to be bizarre itself, their aggregate event is atypical. For example, Deny of Service assaults (D.O.S) [4] are somewhat aggregate peculiarities as each solicitation is typical by its own, yet all together are viewed as abnormality.
Relevant oddities, as indicated in Fig. 5, represent an occurrence that could be considered as bizarre in some
particular setting. Which indicates the watching of a similar point through various settings won't generally give us a sign of peculiar conduct.
C. Investigation: We have two essential kinds of
investigates in this space, looks into of customary I.D.S improvement and inquiries about of utilizing enormous information for I.D.S streamlining.
Conventional I.D.S streamlining: The Data collection from Internet contains research explores that utilized fundamentally with the algorithm of SVM and upgrade it by adding another model to its outcome or to its info.
I.D.S streamlining utilizing huge information: We have two fundamental classifications of these explores. In the first place, inquiries about that just proposed utilizing enormous information for advancement. It expected promising outcomes without doing genuine investigations or having any verification of the thought as it was only a recommendation of a general model. The second sort of examines contains genuine investigations that was finished attempting to demonstrate these proposes. Some of them apply SVM as it was the best in the customary area, others recommend that may another calculation will be superior to SVM in huge information condition. Some of examinations center around utilized huge information instruments, for example, sparkle or tempest, without applying any mining calculation, only a basic edge.
General model: Many papers proposed utilizing enormous information on security for enhancement and obscure assaults location , as indicated in Fig. 6. From that point forward cutting edge abnormality security frameworks utilizing huge information has been a hot research subject space as it is promising to be one of the ideal answers for hacking location issue.
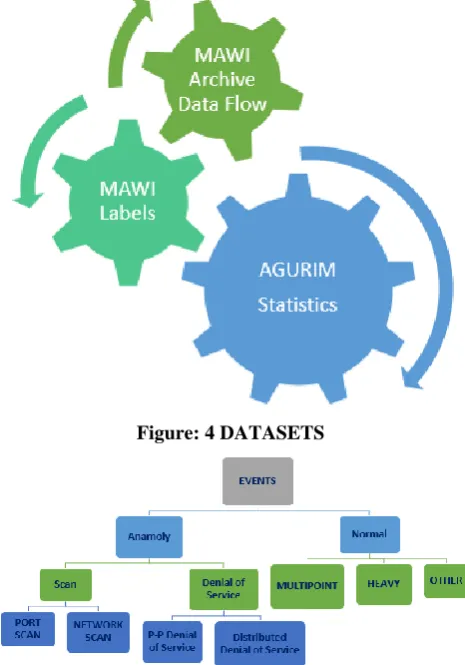
Data: The dataset utilized for this analysis is a blend of three datasets: Flows extricated from M.A.W.I Archives, marks from M.A.W.ILAB and amassed streams from A.G.U.R.I.M as appeared in Fig. 7.
Figure 3: Big data proposed model for I.D.S optimization The system traffic takes a progression with total data, for measurement per second after second in the process. The blend of the 3 sources of information is measured and calculated.
[image:2.595.308.547.507.643.2]It is gathered and preprocessed by a supporter of the Japanese service of correspondence. For protection concerns, all basic data is supplanted by different qualities and all bundle burdens are expelled. We use M.A.W.I traffic to concentrate stream data with measurements about stream. For instance, Source IP, Destination IP, Frame Length, IP Length, IP Version, TTL Window Size, Flags … and so on.
[image:3.595.53.286.251.584.2]M.A.W.ILAB is a venture done over M.A.W.I document that contains marks of information, and it is refreshed consequently consistently. Naming information is finished by network of four classifiers. Classifiers are Principal segment examination (PCA), Gamma Distribution, Hough Transform, [7]Kullback–Leibler (KL). Marks are labeled by class of lion's share classifiers discovery. That helps lessening false positive rate. Marks are finished by scientific classification of irregularities in system traffic as indicated in Fig. 4.
Figure: 4 DATASETS
Figure 5: Network traffic anomaly classification taxonomy
D. The Process:
M.A.W.ILAB Meta information: According to, Anomalies are accounted for in the C.S.V design. Each line in the C.S.V documents comprises of a 4-tuple portraying the traffic attributes and extra data, for example, the heuristic and scientific categorization arrangement outcomes. The genuine request of the fields is given by the [8] C.S.V documents header: anomalyID, srcIP, srcPort, dstIP, dstPort, scientific categorization, heuristic, separation, nbDetectors, name peculiarity ID is an exceptional abnormality identifier. A few lines in the C.S.V record can depict various arrangements of parcels that have a place with a similar abnormality. The oddity ID field licenses to recognize lines that allude to a similar abnormality.
All fields are:
Source IP – Abnormal Traffic
Source Port- Typical Traffic
Destination IP – Distinguished Traffic
Destination Port- Peculiar Traffic
Traffic Inconsistency found in the taxonomy of categorization
Heuristic- The odd utilizing factor on PORT, TCP, ICMP
Distance: Dn-Da
Detectors are the quantity of setups detailed in inconsistency
An odd, suspicious, kindhearted or noted are the labels of M.A.W.ILAB
Names:
Abnormal, if each of the four classifiers thinks about it as an assault.
Benign, if every one of the four classifiers thinks about it as typical.
Suspicious, if three out of four classifiers think about it as an assault.
Notice, if three out of four classifiers think about it typical.
We use M.A.W.ILAB for naming traffic information. The yield of our Chabot is a language that has two words in particular, Anomaly and Benign.
Marks for yield are extricated from M.A.W.ILAB four names where we consider the dominant part classifier result.
Abnormal, suspicious we think of it as Anomaly on the grounds that most of classifiers identify it as an assault.
Benign, see we consider it as Benign on the grounds that most of classifiers recognize it as ordinary.
The explanation for picking the lion's share results is defeating false positive issue.A.G.U.R.I.M is an undertaking done on M.A.W.I document follows which is a system traffic screen dependent on adaptable n dimensional stream total so as to distinguish noteworthy total streams in rush hour gridlock. It has two perspectives, one dependent on traffic volume and the other dependent on parcel tallies, address or convention traits, with various worldly and special granularities.
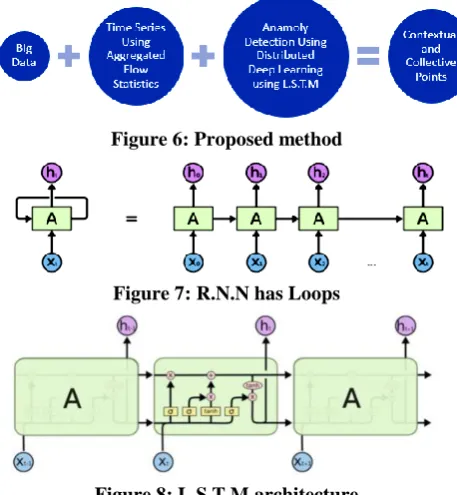
The upheld information sources are P.C.A.P, sFlow, and netFlow. Information has two arrangements, Texts and plots as should be obvious in Figs. 9, 10. A.G.U.R.I.M Meta information each occurrence of information is spoken to by two lines. The primary line of a section demonstrates the data of the source–goal pair: the position, source address, goal address, rate in volume, and rate in parcel tallies. The subsequent line demonstrates the convention data inside the source goal pair convention, source port, goal port, rate in volume, and rate in parcel tallies. A trump card, "*", is utilized to coordinate any. Technique we propose Networking Chabot, a profound intermittent neural system: utilizing Long Short Term Memory (L.S.T.M) over Apache Spark Framework that has a contribution of stream traffic and traffic accumulation.
The yield is a language of two words, typical or irregular. We propose blending the ideas of language preparing, logical examination, disseminated profound adapting, enormous information, abnormality
location of stream investigation. We need to distinguish point,
peculiarity by making a model that depicts the system theoretical typical conduct, as appeared in Fig. 10. Utilizing huge information examination with profound learning in peculiarity discovery indicates brilliant mix that might be ideal arrangement. Profound adapting needs a large number of tests in dataset and that is the thing that enormous information handle and what we have to develop huge model of typical conduct that decreases false positive rate to be superior to anything little inconsistency models.
Utilizing huge information with time arrangement will enable us to investigate greater periods than previously and using it in I.D.S space may permit to recognize propelled dangers that remaining parts undetected in framework unreasonably long, for quite a long time or May years. Since APT assaults happens gradually, examining 90 days just of customary I.D.S isn't sufficient to distinguish those aggregate inconsistencies. Likewise, utilizing huge information with setting of time spans will permit to identify relevant abnormalities that were unrealistic to recognize by customary I.D.S. Framework comprises of two sections, include extraction and grouping. Highlight extraction we get the P.C.A.P documents from M.A.W.I file at that point concentrate stream measurements and name them by consolidating them with M.A.W.I LAB best quality level marks. Additionally, last came about dataset is converged with stream collection from A.G.U.R.I.M dataset so we can arrange of time periods, a casing of one second is utilized in this examination.
[image:4.595.311.545.268.594.2]The thought behind utilizing information stream total is to manage time periods of streams like we manage time spans in recordings that we contrast every scene and its neighbor outlines by their slopes. Moreover, we can include a degree of deliberation of system conduct by adding information conglomeration to neural system input. This informational index is utilized for preparing and testing.
Figure 6: Proposed method
Figure 7: R.N.N has Loops
Figure 8: L.S.T.M architecture
Arrangement choosing appropriated profound neural system has been utilized by a wide range of scientists as the supposition that it will enhance results by demonstrating a great many examples of information and increasingly confused neural systems with more choices. The purpose for
picking R.N.N is its capacity to manage arrangements. R.N.N [9] is augmentation of a show feed-forward neural system. Not at all like feed forward neural systems, has R.N.N had cyclic associations making them incredible for displaying groupings. As a human nobody think about every occasion independently. That is the possibility of R.N.N that has loops to manage contribution as a grouping, and that what we have to deal with every occasion on system inside its specific circumstance, as indicated in Fig. 10. Long Short Term Memory is an uncommon instance of R.N.N that takes care of issues looked by the R.N.N model.
1. Long haul reliance issue in R.N.Ns.
2. Evaporating Gradient and Exploding Gradient. Long Short Term Memory is intended to conquer evaporating angle plummet since it maintains a strategic distance from long haul reliance issue. To recall data for significant stretches of time, every normal concealed hub is supplanted by L.S.T.M cell. Each L.S.T.M cells
Figure 9: L.S.T.M Cell
Figure 10: L.S.T.M cell equations
Comprises of three principle doors, for example, input entryway it, overlook door ft, and yield entryway to. Other than ct is cell state at time t. Long Short Term Memory design is appeared in Figs. 10. The conditions to compute the estimations of doors is appeared in Fig. 10, where xt, ht, and ct relate to info layer, shrouded layer, and cell state at time t. Moreover, σ is sigmoid capacity. At long last, W is indicated by weight network.
The explanation for picking huge information with inconsistency recognition is our enthusiasm for oddity identification favorable position of recognizing new dangers and our objective to lessen peculiarity discovery drawback of high false positive via preparing model with progressively ordinary examples.
[image:4.595.60.289.469.717.2]the requirement for many examples with high number of highlight arrangements for preparing and that what huge information frameworks can deal with and that we suggest to enhance ordinary replica via preparing model with increasingly typical cases more setting highlights to decrease false positive without confronting the issue of over fitting as quick as in customary learning.
The purpose for picking L.S.T.M is our enthusiasm for relevant peculiarities. So, we propose a system language as a contribution for our Chabot. Each sentence in the system language incorporates time arrangement of parcels streams, streams conglomerations and measurements of each second with second prior and second after. Proposed system and libraries Colab Collaborator is a free research instrument offered by Google, for AI instruction and research. It's a Jupyter journal condition that requires no arrangement to utilize.
Code is composed on program interface. Code is executed in a virtual machine devoted to client account (choices accessible currently are CPU, Graphical Processing Unit GPU, Tensor Processing Unit TPU). Elephas carries profound learning with Keras to Spark. Elephas means to keep the straightforwardness and high ease of use of Keras, in this way taking into consideration quick prototyping of appropriated models (conveyed profound learning), which can be kept running on monstrous informational collections .
With the results from GoogleCoLab with KERAS LIBRARY we apply L.S.T.M of 64 shrouded hubs with Relu initiation capacity and dropout = 0.5.
1.Utilizing paired cross-entropy misfortune work. 2.Utilizing RMSprop streamlining agent.
3.Learning rate = 0.001, rho = 0.9, rot = 0.0.
Colab has space impediments notwithstanding execution time restrictions that were the explanation that we demonstrate just point abnormalities however can't demonstrate aggregate and logical inconsistencies. Results and discussion, we needed to demonstrate five parts of results upgrades, yet we had the option to demonstrate just three of them as a result of equipment confinements. We were attempting a year ago genuinely to execute the investigation on better equipment with no expectation.
We are in Syria and we have budgetary forbiddance. Despite the fact that war and troublesome conditions, we need to add to look into. Accordingly, we share this paper with you, to share the bits of knowledge we got and approximated aftereffects of normal of investigations we did. What's more, we wish that the total investigation will be done in future by intrigued specialists. In view of equipment restrictions, tests are done on arbitrary subsets of dataset. Thusly, we will discuss bits of knowledge and a rough level of every done trial by and large. We won't refer to numbers and outlines as it isn't the careful one.
We got various rates for each investigation as it is irregular examples, so numbers are not very exact to give them as diagrams or something like that. We need more equipment to test relevant peculiarities and aggregate oddities for long occasions. We analyze just point peculiarities. Results we get by examination demonstrate that the precision of circulated relevant stream Chabot model is higher than the exactness of customary learning model. False positive is getting lower by 10% not exactly conventional learning model. We utilized S.V.M [10] to contrast and, as it has perhaps the most noteworthy outcome among customary learning classifiers.
Adding stream accumulation data to highlights, notwithstanding stream insights data, is a decent decision that builds precision and better portrays the dynamic conduct on a system. We can get utilization of slopes between each second and the seconds previously, then after the fact. Likewise, adding setting to be thought about causes defer time equivalent to time span taken in setting. Consolidating huge information with abnormality discovery with profound learning is an ideal arrangement that takes care of the issue of over fitting that causes high false positive. It enables us to distinguish new dangers by abnormality techniques with lower false positive by stretching out dataset of preparing to incorporate increasingly ordinary cases and significantly more highlights without confronting the issue of over fitting as customary learning.
III. CONCLUSION
Using huge information with profound abnormality I.D.S is promising in cutting edge I.D.S in view of its capacity to recognize new dangers in various settings with lower false positive than effectively utilized I.D.S. The proposed new model is to break down arrangements of streams and streams accumulation for each second with seconds prior and then afterward. The test shows lower false positive, higher discovery rate and better point inconsistencies location. With respect to verification of relevant and aggregate abnormalities recognition, we examine our case the purpose for our theory, yet we were not ready to do finish try as a result of equipment confinements. The examinations we did on arbitrary little subsets of dataset were promising however insufficient to demonstrate our speculation. The total test will be done in future by other intrigued scientists who have preferred equipment foundation over our own.
REFERENCES
1. Managing Security with Snort & I.D.S Tools: Intrusion Detection with Open by Kerry J. Cox, Christopher Gerg
2. Deep Learning by Ian Goodfellow, YoshuaBengio, Aaron Courville 3. Intrusion Detection Systems edited by Roberto Di Pietro, Luigi V.
Mancini
4. DDoS Attacks: Evolution, Detection, Prevention, Reaction, and Tolerance ByDhruba Kumar Bhattacharyya, Jugal Kumar Kalita 5. Web Services Essentials: Distributed Applications with XML-RPC,
SOAP, UDDI ... By Ethan Cerami
6. Managing Next Generation Networks and Services: 10th Asia-Pacific Network ... edited by Shingo Ata, Choong Seon Hong
7. Foundations of Statistical Natural Language Processing By Christopher D.. Manning, Christopher D. Manning, HinrichSchütze 8. Machine Learning Mastery With Python: Understand Your Data,
Create Accurate ... By Jason Brownlee
9. Neural Networks with R: Smart models using CNN, R.N.N, deep learning, and ... By Giuseppe Ciaburro, Balaji Venkateswaran 10. Information Systems Design and Intelligent Applications: Proceedings
of ... edited by Vikrant Bhateja, Bao Le Nguyen, Nhu Gia Nguyen, Suresh Chandra Satapathy, Dac-Nhuong Le
AUTHORSPROFILE
Dr.M.Venkateswara Rao- Professor of IT, GITAM University, Eminent professor, guide and researcher in Algorithms, Image Processing, Big Data, Cloud Computing, AI and Machine Learning. Member of various professional bodies and distinguished professor.