Rochester Institute of Technology
RIT Scholar Works
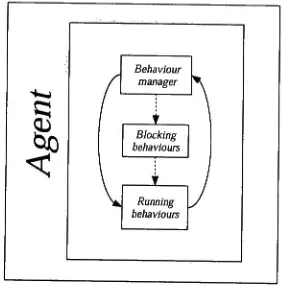
Theses
Thesis/Dissertation Collections
2007
Mutually Adaptive Distributed Heterogeneous
Agents for Data Classification
Joshua Alan Harlow
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion
in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact
Recommended Citation
Mutually
Adaptive
Distributed Heterogeneous
Agents
for Data
Classification
Master's Thesis Report
Department
ofComputer Science
Rochester Institute
ofTechnology
Dr. Leon
Reznik,
Chair
Professor,
Department
ofComputer Science
Dr. Roger
Gaborski,
Reader
Professor,
Department
ofComputer
Science
Dr.
James
Heliotis,
Observer
ROCHESTER
INSTITUTE
OF TECHNOLOGY
The Undersigned Faculty Committee
Approves the Thesis
Mutually Adaptive
Distributed Heterogeneous Agents
for Data Classification
Dr. Leon Reznik
, Chairman
Department of Computer Science
Dr
. Roger Gaborski,
Reader
Department of Computer Science
Dr. James Heliotis, Observer
Department of Computer Science
Thesis/Dissertation Author Permission Statement
Mriv"l\\>,
/0 ',.n+;ve
I;
'r!-(;
I
I
-J
Me+ero,-,ent/ov:
Title of
thesis or
dissertation:
~I'~
,
. ~~..:...JJ~",~(;l=--"~r~--=---,(j~c£...)..:....:..--,l>V~1!::-'---'-_ _ _ _
--:;-,f-'f-=--c.'-1_--L2
0.
9" ots
fn r
Jd6
c/aS'7ihCMI
0(\
Name of author:
J
\)t,
~
u
1
,IT 1411
l±a~ID~
Degree:
(V\\,t-er
~{
~!:'(~(,e
Program:
Co""
Q
~R.
Sci 6'\ C
e
College:
"
C
c..:r:
S
I understand that I must submit a
print copy of my
thesis or dissertation
to the RIT Archives, per
current
RIT guidelines
for
the completion of my degree
.
I hereby
grant to the
Rochester Institute
of Technology
and its
agents the non-exclusive license
to archive and make
accessible
my
thesis or
dissertation in
whole or
in
part
in
all forms of media
in perpetuity. I retain
all other ownership
rights
to the copyright of
the
thesis or dissertation. I
also
retain
the
right
to
use in future
works
(such as articles or
books)
all or part of this thesis
or dissertation
.
Print Reproduction
Permission
Granted:
I,
Joshua Harlow
,
hereby grant
permission
to the
Rochester Institute
Technology
to
re-produce
my
print thesis
or
dissertation in whole or in part
.
Any reproduction
will
not be for
commercial
use
or
profit
.
Signature of Author:
Joshua Harlow
Date:
________________________
__
Print Reproduction Permission
Denied:
I,
, hereby deny
permission to the RIT Library of the
Rochester Institute
of Technology
to reproduce
my print
thesis or dissertation in whole
or
in part.
Signature of Author:
_________________________ Date:
________________________
__
Inclusion
in
the RIT Digital Media
Library Electronic Thesis
&
Dissertation
(ETD)
Archive
I,
Joshua
Harlow
, additionally grant to the Rochester Institute of Technology Digital
Me-dia
Library
(RIT
DML)
the
non-exclusive license
to archive and
provide
electronic
access
to my
thesis or
dissertation in
whole
or in
part
in
all
forms
of media
in perpetuity. I understand
that
my work, in
addition
to its bibliographic record
and abstract,
will be
available to the world-wide
community of scholars and
researchers
through the
RIT DML. I
retain all other ownership rights
to the copyright of the thesis or dissertation
.
I also
retain the right
to use
in
future works (such as
articles or books)
all or
part of this thesis or
dissertation. I
am aware that the Rochester Institute
of Technology do
es
not require registration
of copyright
for ETDs.
I hereby
certify that,
if
appropriate,
I have
obtained and attac
hed
written permission statements
from
the owners of each
third party copyrighted matter to be included in my thesis or dissertation.
I certify that the version
I submitted is the same as
that approved by my committee.
Copyright 2007
by
Abstract
Efficient
and effectivedata
classificationis
one ofthe
mostfundamental
problems ofcomputer science
due
to
ahuge
number ofimportant
applications.As
such, there
have been
many
modelsthat
are capable ofdoing
someform
ofdata
classificationusing
alarge
numberof varied algorithms and architectures.
However,
few
share propertiesthat
implicitly
take
advantage of
the
distributed
environment where classificationhas its
most potential.Therefore,
to
resolvethis
dilemma in
this thesis
a generic classificationarchitecturecomposed of
mutually
adaptivedistributed heterogeneous
agents wasdesigned,
implemented
and
experimentally
analyzed.The
systemdefined
creates a multi-agentdistributed
architecture
whereby
individual
agents cooperate and collaborate with each otherto
autonomously
perform classification onarbitrary
data
using
ahierarchical
paradigm.The
maincontributions ofthis
work arethe
following:
agentsfollow hierarchical
processes
to
form
an organization which canautonomously
train, test,
assign and evaluatework of other agents.
Through
experimental analysisit
wasfound
that this
design improves
the
classificationaccuracy
relativeto previously
implemented
classification algorithms andarchitectures.
Furthermore
this
analysis showsthat the
generated architecture will autonomously
adaptto previously
unlearneddata
and respondsto
failures
withlittle
or noContents
1
Introduction
1
1.1
Distributed
systems2
1.2
Agent
systems4
1.3
K.D.D
7
2
Problem description
&:
research objective9
2.1
Problem description
9
2.2
Research
objective\\
2.2.1
Outline
13
3
Background
^5
3.1
Agents
'25
3.2
Classification
ig
3.2.1
Decision
trees
29
3.2.2
Neural
networks22
3.2.3
Clustering
24
4
Technologies
07
4.1
Java
274.2
XML
28
4.3
J.A.D.E
2g
4.4
Joone
34
4.5
Visualization
35
4.5.1
JFreeChart
36
4.5.2
JChart2D
36
4.5.3
Zeus J.S.C.L
37
4.6
Jakarta
commons37
5
Design
39
5.1
Architectural
overview39
5.1.1
Datasources
40
5.1.2
Supervisors &
employees42
5.1.3
Collectors
44
5.1.4
Receivers
45
5.1.5
Monitors
46
5.1.6
Applications
47
5.1.6.1
Agent
starter47
5.1.6.2
Neural
network repair48
5.2
Implementation details
49
5.2.1
Applications
49
5.2.1.1
Data
processor49
5.2.1.2
Agent
starter52
5.2.1.3
Neural
networkrepair53
5.2.2
Shared
agent components . .53
5.2.2.1
Configuration
56
5.2.2.2
Protocols
56
5.2.2.3
Behaviours
59
5.2.3
Ontologies
59
5.2.3.1
External
ontologies60
5.2.3.2
Internal
ontologies61
5.2.4
Datasources
62
5.2.4.1
Data
62
5.2.4.2
Behaviours
63
5.2.4.3
G.U.I
64
5.2.5
Supervisors
64
5.2.5.1
Employment
64
5.2.5.2
Behaviours
68
5.2.5.3
G.U.I
69
5.2.6
Employees
70
5.2.6.1
Intelligence
70
5.2.6.2
Employment
72
5.2.6.3
Behaviours
75
5.2.6.4
G.U.I
76
5.2.7
Collectors
77
5.2.7.1
Proxy
77
5.2.7.2
Behaviours
7
5.2.7.3
G.U.I
79
5.2.8
Receivers
7g
5.2.8.1
Results
79
5.2.8.2
Behaviours
2
5.2.8.3
G.U.I
82
5.2.9
Monitors
82
5.2.9.1
Monitoring
g2
5.2.9.2
Behaviours
33
5.2.9.3
G.U.I
83
6
Experiments
85
6.1
Method
85
6.2
Design
ofexperiments86
6.2.1
Accuracy
86
6.2.2
Adaptability
87
6.2.3
Fault
tolerance
88
6.2.4
Data-sets
89
6.2.5
Agent
configuration91
6.3
Results &
analysis93
6.3.1
Accuracy
94
6.3.2
Adaptability
105
6.3.3
Fault
tolerance
113
7
Future
work117
7.1
Agents
117
7.2
Data
118
7.3
Algorithms
119
8
Conclusions & implications
121
Appendices
A
User
guide123
A.l
Compiling
the
source124
A.2
Configuring
global parameters124
A. 3
Launching
a main container125
A.4
Launching
agents125
A. 5
Activating
agents126
A.5.1
Datasources
126
A.5.2
Supervisors
126
A.5.3
Employees
127
A.5.4
Collectors
127
A.
5.
5
Receivers
127
A.5.6
Monitors
128
A.
6
Examining
agents128
A.7
Additional
applications128
A. 7.1
Data
processor128
A.
7.2
Neural
network repair129
A. 7.3
Waveform
generator129
A.
8
Further documentation
130
B
Interfaces
231
Chapter
1
Introduction
Intelligent
systems, containing
"intelligent
entitiesthat
are capable ofindependent
actionin
dynamic,
unpredictable environments[26]",
have
recently
become
anincreasingly
de
veloped andfast
growing
segment ofthe
artificialintelligence
community.These
systemshave been developed for
usein
adiverse
area ofapplications,
varying
from
online webdata
mining[41]
to security
related areas such asintrusion
detection[l,
50].
Each
system sharessimilar concepts
in that
someintelligence
mechanismis taken
advantage ofto
allowthe
components
to
achieve somepredeterminedgoal.Furthermore
asdistributed
systemshave
become
increasingly
popular, these
intelligent
systemsare often also
distributed,
whetherthrough
classicaldistributed
models orthrough
aprogressively
popularmodel ofdistribu
tion through
separated agents.Additionally
sinceinput
and outputs areusually
presentin
suchsystems,
whethercompletely
autonomousorpartially
userdirected,
in many
casesprinciples
from
the
concept ofknowledge
discovery
in
databases
canbe
applied, whereby
"nontrivial
extraction ofimplicit previously
unknown,
andpotentially
usefulinformation
(is extracted) from
data[18]."Therefore,
asthese
conceptsform
the
backbone
ofthis thesis
they
willbe introduced
in the
following
section,
allowing
the
heart
ofthis
1.1
Distributed
systems
The
computational environmenthas
recently
been
shifting into
a newera,
one where"dis
tributed
systems areeverywhere[7]" and shared resources or serviceshave become increas
ingly
important.
These distributed
systemsbring
many
advantagesincluding
reducing
the
impact
ofindividual
componentfailures, increasing
reliability
andtaking
advantage ofsocial activities
to
aidin
whatever processes arebeing
performed.With distributed
architecture
models such asthe
centralized client/server(see
figure
1.1(a))
model, the
hybrid
peer-to-peer model
(see
figure
1.1(c))
andthe
pure peer-to-peer model(see
figure
1.1(b))
the
classificationof whatis
distributed has
alsobecome
increasingly
ambiguous.One
common attribute
that
is
sharedis the
concept of socialconnections, whereby
eitherthrough
a central server or
through
peerlinks
some communicativeactivity is
performedto
obtainsome
desired
goal,
whetherthis
be
a simple send andacknowledgmentor a more complexn-directional protocol.
As
canbeen
seenfrom
the
different
models, this
communicativeactivity is
handled
differently by
each variation onthe
distributed
environment.(a)
Client-server
(b)
Pure
peer-to-peer(c)
Hybrid
peer-to-peerFigure
1.1:
Distributed
system modelsThe
simplestmodel, that is
most common withdistributed
systemsis the
centralizedclient/server systemshown
in
figure
1.1(a).
This
model managesthe
communicativeactivity
by having
clientsinteract
with serversin
orderto
access sharedresources or messageother peers.
Notable
this
modelhas
inherent
disadvantages, including
the
centralizationofall resources at a
individual server,
which reducesthe
ability
ofthis type
of systemto
deal
withfailures
gracefully.Another fault
withthis
modelis
the
responsiveness ofthe
individual
servers, i.e. if
to
many
clients connectto
a single server adenial
of servicemay
result, whereby
clientsdo
not receivethe
desired
resourcesin
atimely
manner(if
at all).On
the
otherhand
this
modelis relatively
simple andeasy to
design
in that
a client mustonly
be
aware ofthe
serverthat
its
resources willbe
madeavailablefrom.
The
secondtype
referredto
asthe
pure peer-to-peermodel,
seefigure
1.1(b),
is
adistributed
modelthat
lacks
the
centralized server ofthe
client-server model.These
types
of model
instead
offer acompletely
scalable model where each peeris
aware of a certainnumber of other peers who are aware of a number of other peers and so.
In
this
modeleach peer can act as a client or server as needed
thereby
notnecessitating
a central server.This
modelhas
gained enormouspopularity recently through the
exposure of networkssuch asbittorrent* and
distributed hash
table
implementations
withcorresponding routing
overlay
networks such asPastry[52]
andCAN[51].
Unfortunately
this
model althoughoffering
inherently
limitless
scalability
andpotentially
unlimited resourceshas
problemswith
organization, coherence,
search andsecurity
whentens,
hundreds
orthousands
ofpeers are
accessing
resources providedby
other peers.To
correctthese
problemsthe third type
of network was created as acombinationofthe
client-servermodel and
the
purepeer-to-peermodel andis
shownin
figure
1.1(c)
whereby
instead
ofbeing
completely
decentralized
this
hybrid
model offers a central peer which
plays
the
role of anindex
(similar
to
abook
of yellow pages).This index
peer providesacentralized resourcewhere peers can search
for
anddiscover
other peers withoutrequiring
adirect
channelto the
desired
peer.The
index
peeraccomplishesthis
by
storing
information
about each peer
(such
as what servicesthey
canprovide) but does
not storeany
actualresources
therefore
maintaining
the
distributed
natureof a purepeer-to-peernetworkbut
generating
less
traffic
and moresecurity
sinceauthenticationandregistrationcan occur asneeded
to
gain accessto
the
index
peer.*http
://www
.bittorrent.com/These
modelsareespecially
relevantto this thesis
sincethe
agentsin this
system arein
herently
distributed
and requirethe ability
to
easily
search andlocate
other agents servicesand capabilities.
Since
the
location
of services and capabilitiesis extremely
important
in
anagent
system,
J.A.D.E.
the
agentframework
that this thesis
willbe
using,
and which willbe described
in
chapter3
willapply
a networkusing the
hybrid
peer-to-peer model shownin
figure
1.1(c).
This distributed
model ensuresthat
each agent can search andlocate
eachother, simply
by
ensuring
they
registertheir services,
languages
and other aspects oftheir
capabilities with
the
centralindex
peer asdescribed
previously.1.2
Agent
systems
To
understandhow
an agentis going
to
be
usedin this thesis
we mustfirst
understandwhat
typically
defines
an agent.In
a popular multi-agenttext
an agentis
a"computer
system
that
is
situatedin
some environment andthat
is
capable ofautonomousactionin
this
environmentin
orderto
meetits
design
objectives"[63]. This
extremely
loose definition
describes
the
abstract view of anagent,
as canbe
seenfrom figure
1.2.
From
this
figure
we can note
that this
agent willtake
someinput
from
whatever environmentit is
situatedin
and applies some sort ofprocessing
to that
input,
therefore giving it
partial control overits
environment.Thereafter
it
willpotentially modify the
environmentby
performing
anaction
to
reactto
its sensory inputs.
f
f \
Agent
\
[Sens
or At 01
:tion
\
itput]
V
Environment
^
Figure
1.2:
An
agentin its
environment[63]
[image:16.544.219.333.450.553.2]From
this
simpledefinition
wecantherefore
attemptto
define
what anintelligent
agentis.
Unfortunately
the
description
of whatexactly
describes intelligence
is
hotly
debated
in
the
A.I.
community.As
statedin
[64, 63]
mostlikely
anintelligent
agenthas
characteristicsthat
makeit
autonomous, social,
reactive and pro-active.Being
autonomous wouldinvolve
the
same concept asdescribed
in the
"basic
agent"whereby
an agent need notinteract
with
humans
or other agentsin
orderto
accomplishits
goals.Secondly, having
socialcharacteristics would
involve
the ability to
interact
withhumans
or other agentsin
anagreed upon
language.
Thirdly
anintelligent
agent mustbe
reactivein that
they
should"perceive
their
environment and respondin
atimely
fashion
to
changesthat
occurin it
in
orderto satisfy their
design
objectives.[63]"Finally
and mostimportantly
anintelligent
agent must
be
pro-activein that it
must"exhibit
goal-directedbehaviour
by
taking
the
initiative
in
orderto satisfy
(its)
design
objectives.[63]"Now
that the
definition
of anintelligent
agenthas been
solidified, the
nextstep in
understanding
agentsis
determining
the
architecturethe
agent shallbe
using
for
its in
ternal
systems.There
traditionally
existsfour base
architectures[63],
these
being
logic
based,
reactivebased,
belief-desire-intention
based
andlayered
architectures.The logic
based
architecturefollows
the
traditional
approachwhereby
an agenttakes
some symbolicdescription
ofits
environment andusing its
currentbehaviour
andfirst-order
predicatelogic
[53]
modifiesits
environmenttherefore
changing
its
symbolicdescription. This
type
ofarchitecture
has
many
advantagesencompassing
suchbenefits
asbeing
a welltheorized,
logically
clean,
welltested
and one ofthe
oldestknown
applicationsof artificialintelligence.
Unfortunately
though there
also existmany
problems which oftendeter
this
architecturefrom
being
usedin
an agentplatform,
such ashaving difficulty
representing
temporal
information
andbeing
to
computationally
complexfor
environments which aredynamic.
To
overcomethese
limitations
the
second architecture wasproposed, whereby
instead
of
the
complex architecture ofthe
logic based
system a reactivearchitectureis
proposed(made
popularby Rodney
Brooks
subsumption architecture[5]). This
architecture
simply
implements
behaviours
asreactionsto
situationstherefore
attempting
to
allowintelligent
behaviour
to
emergefrom
simplerbehaviours.
This
architecture gainsmany
advantagesover
the
logic
based
architecture
such asbeing
simplistic,
computationaltractability
andhaving
robustness againstfailure.
Unfortunately
though this
architecturehas
its
share ofproblems as well
including being
unableto
learn from
past experiences andbeing
limited
inherently
to
a shortterm
view ofthe
surrounding
environment.The
third type
ofarchitecture
takes
acompletely different
view onhow
an agent shouldprocess and manipulate
its
environment.This
architectureis
founded
aroundtwo
impor
tant processes,
"deciding
what goals we wantto
achieve(deliberation)
andhow
we aregoing to
achievethese
goals(means-ends
reasoning).[63]"Initially
these
goals areformed
as
persisting
intentions,
whichthen
direct
the
agents actions andfuture
reasoning.Then
once
these
goals are established sometype
of actionis
selectedin
orderto
achievethese
goals,
whichmay
involve
moreintentions
being
created.As
a ratherintuitive
modelthis
modelabstracts
the
daily
processeswe all makein selecting
intentions,
goalsand actionsto
achieve
these
intentions.
Unfortunately,
as with all modelsthere
aredownsides;
onedown
side of
this
modelis the complexity
ofimplementing
these
intentions,
goals,
and actionscorrectly.
Output
...layer
Input .layer Output
Layer...
Layer3 Layer 2
Layer 1
....layer
Input
(a)
Horizontal
model(b)
Vertical
modelFigure
1.3:
Layered
architecturesThe fourth
andfinal
modeldeals
with a combination ofreactive andpro-activelayers
whereby
a controlflow
hierarchy
ofinteracting
layers is
created, in
either ahorizontal
or vertical pattern.Horizontally
layered
models(see
figure
1.3(a)) directly
connectthe
soft warelayers
withthe
input
andthe
action output and producepotentially
actions whichmay
have
outcomesinternally
to the
agent orexternally
as messages.Vertically
layered
models
(see
figure
1.3(b))
onthe
otherhand have
sensorinput
and action outputhandled
through passing
ofinformation
vertically
as neededto
reachthe
action outputlayer. These
models although
allowing
for
reactive and pro-activebehaviours
to
existconcurrently
andhaving
"conceptual
simplicity"have
problems withcompeting
behaviours.
Solving
this
requires an application of some
type
of mediatorto
decide
whichbehaviour
shouldbe
in
voked at
any
giventime,
therefore
increasing
design
complexity
asany
interactions between
layers
mustbe
consideredandhandled
by
the
mediator or mediators.The importance
ofintelligent
agentsto this thesis is
inherently
obvious,
but
the
selectionofarchitectures
is
not asinherent.
Throughout
chapter5,
certaindesign decisions
willbe
made
that
select reactive orlayered
architectures asthe
foundation
ofdifferent
agentsin
order
to
obtainthe
minimal amount ofcomplexity
during
implementation.
1.3
Knowledge
discovery
in
databases
The knowledge
discovery
in
databases
(K.D.D.)
process,
as canbe
seenfrom figure
1.4
playsan
important
rolein the
analysis andprocessing
ofdata
as"we
aredrowning
in
data,
but
starving
for
knowledge"[28]. The
processesthat
composeK.D.D.
eachhave
major effects onthe quality
ofthe
data outputted,
withselection,
preprocessing
andtransformation
(data
cleaning/conversion)
processescomprising
the
most work(60%
ofthe
effort)
andhaving
the
largest
impact
onthe
entire process.These
processesdescribed here
briefly
from
beginning
to end,
starts withselecting
alarge
enough samplein the
selection processto
preprocessing
whereany
"repairing"ofthe
data-set
occursto
the
processoftransformation
where
the
data
is
madeinto
a suitableformat for
the
data
mining
engine(such
asstring
to
numericaltransformations)
then to take
over.Thereafter
data-mining
algorithms
willattempt
to
perform sometype
of analysis onthe
data,
potentially
performing
classification,
clustering,
patternidentification
or some othertype
ofdata
analysis asdesired
by
the
endusers of
the
system.Once
this
processhas
completedin
most cases alarge
amount of newdata
willbe
generated,
hopefully
less
than the
originalinput,
whichthen
mustbe
analyzedto
gain sometype
of usefulknowledge
(or
the
processmay
repeat with new conditions).The
connection withthis thesis
is partially in the
first
three processes,
which mustbe
performed
before
the theses
architecturecanbe
activated.Thereafter
oncethese three
processes arecompleted
this theses
agent system willthen
usethat
data
to
operateits
agentson.
Subsequently
the
system shall providethe
data-mining
aspects(through
classification)
and attempt
to
aidin the
interpretation
and evaluation processes ofK.D.D.
by displaying
progress and outputs
in
a userfriendly
format
(see
chapter5
and appendixB).
(^Selection')
(preprocessing
J
fTransformation
J
(
Data mining)
I
EvaluationJ
Data
Target data Preprocessed
Transformed
Patterns.
KnowledgeFigure
1.4:
K.D.D.
processChapter
2
Problem
description &
research objective
2.1
Problem description
Efficient
andeffectivedata
classificationis
one ofthe
mostfundamental
problems of computer science
due
to
ahuge
number ofimportant
applications.Over
yearsmany
algorithmsboth statistically
oriented andbased
onheuristics have been
developed, including
but
notlimited
to
k-means,
neuralnetworks,
anddecision
tree
algorithms such asCART, C4.5,
ID3, ID4,
andID5R
(see
chapter3).
Typically
these
algorithmsare appliedin
environmentswhich are not
distributed
and usestatically
defined
data-sets[19,
56, 49,
3];
environments which are unrealisticin
the
occurring
distributed
revolution.This
revolutionbrings
withit
situations wherethe
data involved
in
classificationsis
dynamic,
the
resourcesdistributed
with alow
resistanceto
failures,
thereby
making
it very
difficult
to
apply
conventional classificationmethods.Previously
these
situationshave been
approached
by
using
afixed
set ofclassification algorithmswhich reactto
the
surrounding
environment,
withadaptationoccurring
at an algorithmiclevel.
Unfortunately,
the
maindesign
problem withthis
approachis
that
sincethese
algorithms areisolated,
they
there
algorithms
to
worktogether to
perform classifications.Concurrently
the necessity
for
aframework
which can accommodateand adaptto these
situationshas become
increasingly
relevant,
with an even greaterlevel
ofrelevancy to
areas such asintrusion detection
whichdepend
ondistributed
situations.In
orderto
accommodatethese capabilities, the
algorithms can
be distributed
in
some manner andmanaged as agroup in
someform;
whichif
done
intelligently
has
the
potentialto
improve
classificationaccuracy
and adaptability.Previous
multi-agent systemshave been
proposed which examinethe
mutualtraining
process,
andhave
shownthe
processto
be beneficial
(see
chapter3),
but
there
does
notcurrently
existany
such system which can use amutually
training
processto
aidin
generic classification.Therefore
to
overcomethe
previously
limiting
situations, this thesis
proposesa solution
by
applying
amutually
training
process whichhas
a structuraldesign
that
mimics
the
neocortex region ofthe
mammalianbrain,
whichis thought to
provide much ofthe
intelligence
mammalian species are endowed with[29].This
neocortexis
the
partFigure
2.1:
Neocortex
and cortical columns[8]
of
the
brain
we are mostfamiliar
with,
asit is the
"wrinkly"exterior
that is
most often representedin
pictures(see
figure
2.1).
It
is
composed of sixlayers,
whichhas
over100
billion
cells,
each with1,000 to 100,000 synapses,
all packedinto
a set oflayers
that
has
the
thickness
of a paper napkin[40].These layers
arethought to
perform multiplefunctions,
withdifferent layers
andinteractions between layers
aiding in sensory perception,
spatialreasoning,
vision,
touch,
balance,
movement and emotional responses[40]. These functions
are enabled
through
an application of neurons structuredinto
corticalcolumns[25,
42],
forming
ahierarchal
structurebetween
layers,
whichis
distributed
throughout
each ofthe
different
regions ofthe
neocortex.As
this
structurehas been
provenextremely
flexible
and
adaptable, this thesis theorizes that
oneway
ofgaining these
capabilitiesis
to
follow
a similardistributed hierarchy.
By following
this
design,
classification systems should gain greateradaptability, tolerance to
failures,
and providefor
flexibility by incorporating
algorithmsinto
disjoint but
connectedintelligent
regions.2.2
Research
objective
The
objective ofthis
thesis
is to
develop
algorithms and animplementation
of amutually
training
distributed
agents, employing research,
previous work andinnovations
asnecessary
to
accommodateprogress.The
goalis
to
develop
the
methodology for
adesign
andimple
mentation of a
framework
which willapply
multiple cooperative agentsworking together to
efficiently classify
data,
withpotential applicationsto
avariety
ofdifferent
problem areas.In
orderto
achievethe
objectivethe
following
plan will occur:Develop
cooperativehierarchy
principlesandalgorithmsdescribing
the
systemsfunc
tionality
Implement
the system, using the
principlesandalgorithms,
as asoftwareframework
suitable
for
easy
adaptionto
different
applicationareasTest
the
design
onintrusion detection
and waveformidentification data-sets
Compare
the
systemdesigned
andaccompanying
experimentalresultsto
conventional
algorithms andmethodswhereverapplicable
The
algorithmswillbe
centralizedaroundforming
apreviously
untriedhierarchy,
whichmimics
the
neocortexes regionsandits
cortical columns.This
hierarchy
willbe
composed ofmultiple
agents,
each withduties
that
mimicthe way the
variousregions ofthe
neocortexwork
together to
allowfor
emergence ofintelligent
behaviour.
In
orderto
achievethis
objective
it
wasdecided
that
adesign
wouldbe
selected whichfollows
anorganization'sstructure and
is
composed ofdistributed
agents who perform work relatedtasks,
withthe
tasks
forming
ahierarchical
dependency
on othertasks
oragents;
thereby
constituting
acooperative
hierarchy.
Supervising,
Classifying....
K.D.D.
i
\
i
/
processing
DataHosting
Organizational
activities
Result Output
Knowledge
Figure
2.2:
Framework
overviewThe
algorithms requiredto
performthese activities,
oncecompleted,
willthen
be
in
corporated
into
alarger
classificationframework
involving
data
hosting,
the
organizationalprocesses and result output
(as
canbe
seenin
figure
2.2).
Thereafter
a set of agents willbe
constructed which will performthe
actionsnecessary to invoke these algorithms, in
adistributed
manner,
thereby
increasing
the
fault
tolerance
ofthe
system as awhole,
as anindividual
agentsfailure
will cause a gracefuldegradation
in the quality
ofclassifications(similar
to the
neocortexesdistributed
redundancy).Although
the
goal ofthis thesis
is to
develop
these
algorithms/agentsand animplementation,
additionally
userfriendly
graphical
applications willbe
incorporated.
These
will allowfor
anyone without anin-depth
knowledge
ofthe
agents andunderlying
algorithmsto
be
ableto
usethe
developed
agentsand applications
(see
appendixA).
The
overallhope
is
that
if this
processis
done
intelligently,
with a organizationalstructure
that
follows
ahierarchal
process similarto the neocortex, the
classificationprocesswillproceedwith
increased
accuracy,
adaptability
and a greatertolerance
to
failures. This
solution, if successful,
shouldtherefore
have
animmediate
impact
on areas which arealready
dynamic, distributed,
orhave
ahigh failure
potential,
such asintrusion
detection
and waveform
identification.
Concurrently
the
developed
design, framework,
algorithms,
and
implementation
could also openup
new areas and applications where classificationscan
be
performed.2.2.1
Outline
In
orderto
accommodatethese
objectivesthe
following
outlinefor
this thesis
report willbe
conducted.
First
offthere
willbe
a review of relevantliterature
and relatedtopics
in the
area
in
whichthis thesis
willinnovate
in
chapter3.
This
will overview a subset of previousmutually
training
agentdevelopment
and classificationalgorithms anddiscuss
if
andhow
they
are relevantto this thesis.
Following
this,
in
chapter4,
willbe
anoverview ofthe
technologies
usedto
aidin the
implementation
ofthis
thesis,
including
various programming
resources andlibraries.
Directly
afterthis
willbe
the
design
andfunctionality
details
which will
be
providedin
chapter5.
This
chapter will gointo
the
high level
design,
andlower level implementation details
ofthe
generated agentsandalgorithms generatedto
accomplish
the
defined
research goals.Thereafter design
ofexperiments,
experimentalresultsand comparisons shall
be
providedin
chapter6.
During
this chapter, the
experimentsto
be
performed willbe described
in
detail
along
withthe
results achievedby
running those
experiments, therefore
allowing for
an analysis ofthis theses
methods.Subsequently,
fol
lowing
this
experimentalanalysis willbe
potentialfuture
workbeing
providedin
chapter7.
Finally
to
endthesis
conclusions& implications
willbe discussed
in
chapter8.
For
those
interested
in using the
developed
applicationsthe
accompanying
user guide andG.U.I.
screenshots
in
appendicesA
andB
canbe
referenced.These
appendices provide aguide andscreenshotsto
learn how
to
usethe
agents and what needsto
be done
to
getthem up
and running.
Chapter
3
Background
As
we"stand
onthe
shoulders of giants"(Isaac
Newton)
most newtechnologies
andin
general
any
innovative
idea,
has
someunderlying
core of previous work.These
pieces ofwork
may
be
a source of resources or a source of contrast on which newideas
or variationsare
built
upon.This
thesis
is
nodifferent,
with sources of work which shallfollow
in this
chapter
that
have inspired
this work,
eitherby having
flaws
whichthis thesis
attemptsto
solve or
remedy
to
a certaindegree
orby having
abeneficial
idea
whichthis thesis
willapply
orbe
inspired
from.
3.1
Agents
One
ofthe
first
mutually
learning
agentimplementations
[62]
proposedtwo
learning
schemelabeled A.C.E.
(action
estimation)
andA.G.E.
(action
group
estimation)
whereby
mutually
learning
occursin
reactive agents.The first
algorithm,
A.C.E.,
proposesa systemwhereby
three
activitiesoccur,
determination,
competitionandcredit assignment.The first activity
determines
a set of actions whichthe
agentbelieves
it
cancarry
outrelativeto
its
environmental state and current
knowledge. Then
the
secondactivity
occurswhereby the
agents"compete for
the
rightto
become
active"actually
carriedout."Thereafter
the
actionwiththe
highest bid
is
carried out and a creditassigning
process occurs[62]
to
weightthe
selected actions against potentialfuture
actions.The
secondalgorithm,
A.G.E.,
is
similarto
A.C.E. but
modifiesthe
competition phaseby
competing
for
groups of actionsinstead
ofsolidarity
actions.Thereafter the
samebidding
and creditassigning
processesoccur,
but
instead
of a single actionbeing
carried outthe
wholegroup
of actions are performed.Following
this description the
authors comparetheir
results against a random search algorithm
using both
algorithmsto
moveblocks
aroundin
the traditional
blocks
worldproblem(choosing
actions sets eitherrandomly
orthrough the
proposed algorithms).Their
results showedthat the
learning
schemes performsignificantly
better
over random walk schemes and were ableto
learn
stable sequences of action sets.This
therefore positively
enforcesthe
ideology
that
agentsworking
together,
even whenthose
agents arereactive,
can performbetter
than
agentschoosing
random actions sets.In
[57],
the
authorMing
Tan
investigates
"given
the
same number of reinforcementlearning
agents,
will cooperative agents outperformindependent
agents whodo
not com municateduring
learning?"Using
reinforcementlearning[33]
the
author attemptsto
de
termine
the
performance of nindependent
agents with n cooperative agents andidentify
any
trade-offs
whichmay
result.Therefore
as reinforcementlearning
typically
appliesq-learning
[61]
the
author performs analysisto
comparethe
strategic performance of agentsacting in
ahunter-prey
simulation.In
this
simulationeach agentis setup to
be
ahunter
orprey,
withalimited
depth
offield,
and random startlocation.
To
implement
a reinforce mentpolicy
whenthe
hunter
group
captures aprey
they
receive a+1
reward,
and whenthey
movebut
do
not capture aprey
they
receivea -0.1 reward.Through
multiple case studies andexperimentaltests
the
authorempirically
determines
that
cooperative agents canlearn faster
and converge soonerthan
independent
agents.The
paper also showsthat
the
communicationneededfor
this
cooperationcomesat a communicationcost, providing
tradeoffs
whichthis thesis
must also analyze.In
[24, 23]
the
authors present a cooperative multi-agentlearning
algorithmwhereby
the
agentsfirst
gothrough
atraining
session and"are
then
ableto
choosetheir
actionsby
generalizing
whatthey
have
learned."Using
ateacher-learner model, the
authors proposea
trainer/teacher
agent whoinstructs
"students"on
how
to
behave.
In
this
model eachagent can
be
atrainer
or alearning
agent,
wherethe trainer tries to train the
learner
for
its
own
benefit. The
trainer
also gradesthe
learning
agentsbehaviours,
through
afeedback
mechanism which
therefore
affectsthe
learning
agents next action.The learner
agentsubsequently
computesits
satisfactionlevel based
the
current worldstate,
the
agents goalsand
its
feedback
to
determine
which actionto
choose nextto
increase
its
satisfactionlevel.
In
the
articlethe
authorsapply their algorithm, comparing
agents who choosetheir
actionsrandomly
versuscooperativeagentsusing
atraffic
light
simulation.Through
experimentalresults
the
authors were ableto
give show resultsshowing that
cooperative agents wereable
to
achieve0%
collisions and cooperatedin
49%
ofthe cases,
withthe
downside
that
a
large
queue of cars was maintained.In
[45, 44]
the authors,
Luis Nunes
andEugenio Oliveira
attemptto
determine "how
can agents
benefit from exchanging information
during
learning?"Interesting
in this
set ofpapers
is that the
authors considerthe
possibility
that the
agentsmay
have different
structures
anddifferent
learning
algorithms, therefore
notbeing
ahomogenous
set of agents.In
orderto
attemptto
determine
the
answerto this
important
question, the
authorsgenerate agents
whereby
different
learning
algorithms are used(random
walk,
evolutionary
algorithms,
simulatedannealing
andq-learning)
.Similarly
as[24, 23]
the
authors use a
traffic
light
simulation, whereby the
agents"observe
the
state of(their)
environmentfor
their
local
scenario anddecide
onthe
percentage of green-timeto
attributeto the
North
and
South
lanes.[44]"During
this
processthe
agentsexchangeadviceby
broadcasting
their
best
average resultfor
each epochwhereby then
atthe
beginning
ofthe
next epoch agenti
will compare all resultsto
determine
which agenthas
the
highest
average resultto then
seek advise
from. Thereafter
the
"advisee"sends
its
stateto the
"advisor"who
then
runsthat
state and returns a resultusing its
learning
algorithm, therefore giving
supervisedfeedback
to the
"advisee."After
running many
experimentaltrials
withthe
variouslearn
ing
algorithmsthe
authorsdetermined
that
"advice-exchange
seemsto
be
apromising way
in
whichagents can profitfrom
mutualinteraction
during
the
learning
process"but
they
also
found
that
"bad
advice,
orblind
reliance,
canhinder
the
learning
process,
sometimesbeyond
recovery."In
[32],
the
authors analyzethe
effect ofcommunication,
when each agenthas "ac
cess
to
a small set oflocal information
andthrough
experiencelearns
to
communicateonly the
additionalinformation that is
important."In
orderto
analyzethe
effect of communication
the
authorsdevelop
apredator-prey simulation, whereby the
goalis to
have
four
predator agents surround aprey
on allfour
sidesin
a grid-world.To
allowfor
communication
to
be
analyzedthe
authorsdevelop
ablackboard
[9]
like
architecturewhereby
all agents post
binary
messages(messages
only containing
{0, 1})
to
a messageboard.
Therefore
using this
messageboard
the
authorsdevelop
the
predator agentsby
applying
genetic algorithms
[22]
to
evolvedifferent
agents; whereby
each evolution producesdifferent
languages
and strategies.Applying
these
agentsthrough
variouslife-cycles,
the
authorsdetermined
that
"genetic algorithm(s)
can evolvecommunicating
predatorsthat
outperform
the
best
evolvednon-communicating predators,
andthat
increasing
the
language
sizeimproves
performance."These
previous seven papers provide a conclusive answerto the
question of whethercooperative
learning
is
beneficial
and evenachievable,
asthey
showthat
social agentscooperating
andcommunicating
together
can exist anddo
performbetter
than
independent
agents.This
resultis imperative
for
this thesis
sincethe
agentsin the
implementation
ofthis thesis
willbe
inherently
communicating
andcooperating to
accommodate classificationprogress.
Also
these
papersbring
forward
areas whichthis thesis
mustbe
aware asthe
effect of
blind
reliance andthe
cost of communication are areas which couldhinder
this
theses
classification capabilities.3.2
Classification
As far
as classification algorithms areconcerned,
there
have been
alarge
range ofdifferent
algorithmsover
the
past20
years whichhave
attemptedto
define
methodsfor
classification.These different
methods span alarge
range of artificialintelligence
such asdecision
trees,
rule
induction,
neural networks and clustering.As
the
goal ofthis thesis
is
to
provide adynamic
classificationframework
using agents,
a selection ofthese
previous classificationworks and associated methods will provide a sense of contrast
/comparison
asmost
do
not provideeasily
distributable,
adapting
algorithmsfor data
classification.As for
the
algorithmswhich
do
provide anadapting
view ofdata
classification,
a subset ofthese
will.be
appliedin the
design
stage(see
chapter5).
Additionally
in
chapter6
certain experimentswill
be
performedallowing
for
acomparison, if possible,
ofthe
capabilities ofthis
thesis
with
previously
implemented
classificationalgorithms and applications.3.2.1
Decision
trees
One
ofthe
approachesfor
generating
classificationshas been
to
generatedecision
trees
for
the
instances
being
classified.These decision
trees
are "tree"like
structureswhereby
each node
in the tree
represents either a specific class or sometype
oftest that
splitsthe
tree
into
separate subtrees withleaf
nodes alwaysassigning
aclassification.These decision
trees
arefrequently
usedfor
classification asthey
provide a"divide
and conquerstrategy
for
object classification."[58]
One
ofthe
wellknown
algorithmsfor
building
these trees is the
ID3
algorithmwhichattempts
to
useinformation
entropy
defined
in
[55]
andinformation
gainto
determine
the
"importance"of
the
data
at eachlevel
ofthe tree.
On
abasic level
the entropy
calculation,
shownin
equation3.1,
determines
the
information
gainedby
acertain attributeby being
provided a collectionS
andthe
proportionof classI in
S.
Similarly
the
information
gainshown
in
equation3.2
attemptsto
determine how
well a attribute of adata-set
splitsthe
data-set into different
classes.This
occursthrough the
application ofthe entropy
formula,
but
alsotaking
into
accountSv
which representsthe
subset ofthe total
data-set
for
which attributeA
whichhas
value vtherefore
determining
the
gainthat this
attributeA
offers.The ID3
algorithm proposedtakes
a set oftraining
instances
andrecursively
selects attributes of
those
training
instances,
calculating their entropy
and gain and selectsthe
attribute withthe
most gain asthe
currenttree
node.This
process repeats withthe
attributes not partitioned until no more
features
are availableto
partition orthe
algorithmperfectly
classifiesthe
training
instances.
As
canbe
inherently
seenthis
algorithmis
non-iterative,
in that
as newdata
is
obtainedthe
wholetree
mustbe
rebuiltfrom
scratch.Entropy(S)
=-?(/)
log2(p(7))
(3.1)
Gain(S,
A)
=Entropy(S)
-W
f^\
Entropy
(Sv)\
(3.2)
Another
populardecision
tree algorithm,
C4.5[49]
builds
uponthe
ID3
classificationalgorithm
by
providing
a number of extensions.These improvements include
allowing
unknown
ormissing
attributevalues, tree
pruning to
reducethe tree size, attempting to
avoidover-fitting,
handling
continuous values(i.e.
time)
andgenerally
improving
computational efficiency.This
algorithm althoughproviding
many
advantagesfor
softwarehas limitations
in that its pruning
methods are statedby
the
'creator(Ross
Quinlan)
asbeing
a"heuristic
with questionable
underpinnings."
The
C4.5
alsoby
being
a relative ofID3 does
not allowfor
iterative tree
building,
therefore
alsolimiting
its
usageto
areas where staticdata is
being
classified or wherethe
time to
rebuildthe
entiretree
is
inexpensive
or need notbe
a concern.
Another
non-iterativedecision
tree
algorithm whichis
used quite oftenfor
constructing
decision
trees
is
CART[4]. This
algorithm uses adifferent
modelthan
ID3,
whereby
instead
ofinformation
gain a probabilistic modelis
usedinstead.
The CART
algorithmhas
variousstrengths[65]
overC4.5
andID3
such asit
candeal
withdata
withhigh
sionality,
handle
missing
values andis
notbe
affectedby
outliers.Unfortunately
it
alsohas
weaknesses[65]
asit is
not aniterative
algorithm andthe
variablesin
CART
are notrequired
to
follow
any
statisticaldistribution.
In
orderto
allowfor iterative
tree
building,
quite afew
algorithmsbuilding
off ofID3
have been
proposed.One
ofthe
first
attempts wasthe
ID4
algorithm proposedin
[54]
whereby the
algorithm maintains a score at each possibletest
attribute.This
scoreis
updated as new
instances
arrive and resultsin
ashifting
oftest
nodes aslower
scoring
nodes get replaced with
higher
scoring
nodes.Unfortunately
this
algorithm alsodiscards
the
subtree oflower
scoring
nodes wheneverthey
are replacedtherefore causing
chaoticmovement and
lose
of subtrees(and
the
information
they
contain)
asthe
tree
attemptsto
stabilize.These
problems prevented usage ofthis
algorithm as some concepts are unlearn-ableif the tree
never reaches a stable state[58]
.A
solutionto
ID4's
problems was proposedin
[58]
whereby the
authorsprovideanother attemptlabeled
ID5R.
This
article provides a well written overview ofthe
ID4
algorithmand goes
into depth
theoretically
andempirically
onhow
their
algorithm modifiesthe
basic
methods of
ID4
to
providefor
a practicalrestructuring
procedure.This
is
accomplishedby
the
following
method; instead
ofdiscarding
subtreesthis
algorithm performs a"pull-up,
atree
manipulationthat
preservesconsistency
withthe
observedinstances.
[58]"Overall
this
algorithm,
provedthrough experiments,
wasfound
to
be less
expensivefor
updatesthan
applying the
ID3
algorithmrepeatedly
and overcamethe technical
problems which were
inherent
withthe
ID4
algorithm.A
third
iterative
algorithmproposedin
[59]
appliesaslightly different methodology
to
iterative
tree
building
whereby
amapping
from
aprevioustree
to
a newtree
is generated,
using
similartest
information
asID4
andID5R
stores.This
algorithmlabeled I.T.I, for
iterative
tree
induction
performsthe
following
over-viewedprocedure[59].
As
eachinstance
arrives, it is
passeddown
to
the
branches
until aleaf
nodeis reached,
updating
at each node passedthrough the test
information
andmarking that
node stale.After
this
newinstance
has been incorporated
visitthe
stalesnodes andmodify the test
atthat
nodeto
reflectthe
changes
that
instance
may
have
caused.This
algorithm andits slightly
modifiedrevisionspresented
in the
articleshowthrough
experimental resultsthat
comparedto
C4.5,
accuracy
is
equalto
orbetter.
Unfortunately
the
cost ofupdating
data-sets
andcorresponding
instances
withlarge
amountsof numeric values wasfound
to
be
extremely
costly.3.2.2
Neural
networks
A
secondmethodfor generating
classificationsis
using the
capabilities of computationalneural networks
to
internalize
classificationsas a reflection ofthe
neuron structure[30];
oneof
their many
applications.These
artificial neural networks act as approximations ofthe
neuron structure
that
acts asthe
main component of our nervous system.As
artificialneurons
(see
figure
3.1(b)) directly
map to
biological
neurons(see
figure
3.1(a))
both have
a similar structure and perform
many
ofthe
same responsibilities.These biological
andcomputational responsibilities
include
being
the
mainprocessing
elements andtransmit
ters
ofinformation
in
all vertebrateanimals[31]
and computational environments wherethey
are applied.These
processes occurthrough
a complicated communication processusing
electrical and chemicalinteractions
for biological
neurons orfor
artificial neurons acomplicated structure and various algorithm are used
to
simulatethe
biological
neuronsprocesses.
As
the topic
of neural networks covers wholebooks
an overview ofthe
structureand
the
background
of neural networks willbe
providedin the
following
section.The biological
process startsfrom
one neuron'sterminals whereby
neuro-chemicals arereleased which
then
passthrough
the
synapticboundary
and arepotentially
acceptedby
another neurons
dendrites.
Then through
a complicated processinvolving
the
chemicalstransmitted
andthe
changein ionic
balance
inside the
receiverthese
chemicalsmay
activatethe
action potential ofthe receiving neuron, causing
a potential retransmission of neurochemicals
to
another neuronthrough the
receivers axonterminals.
It
is through this
process
that
initially
inspired the
development
of artificialsimulationsofthe
neuron andits
(a)
Biological
neuronstructure[31]
O.-Activationvalue of unitj
W-Weightonthelink betweenMoron IandJ
Function '^"a
(b)
Artificial
neuron structureFigure
3.1:
Neuron
structurescomplicatednetwork of
interactions. These
artificialprocessesfollow
a similarbut
simplerprocedure, whereby
a number of artificialneurons arelogical
connectedtogether through
different
types
of synapses.The input
synapsesto
a artificial neuron arethen
processedin
some manner and placed
through
an activationfunction
to
producean output whichis then
logically
sentto
areceiving
artificial neuron.Depending
onthe
different
type
of networkmodel
being
used andthe
area andtype
ofdata
being
processedthese
activationfunctions
can
vary
from
a sigmoidfunction
(see
figure
3.2(a))
to
ahyperbolic
tangent
function
(see
figure
3.2(b))
to
a signfunction
(see
figure
3.2(c))
to
various otherfunctions
that modify
the
inputs in
various manners.As biological
neurons adaptto changes,
artificial neuronalso
inherently
adaptto
changesin the
input data. This
learning
process occursthrough
supervision and reinforcement of a set of
training
data
which containsthe
classesthat
f
![Figure 1.2: An agent in its environment[63]](https://thumb-us.123doks.com/thumbv2/123dok_us/60540.5645/16.544.219.333.450.553/figure-an-agent-in-its-environment.webp)