Toward collaborative open data science in metabolomics using Jupyter Notebooks and cloud computing
Full text
Figure

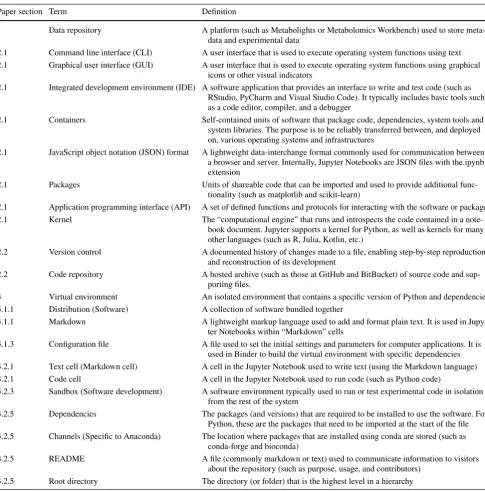
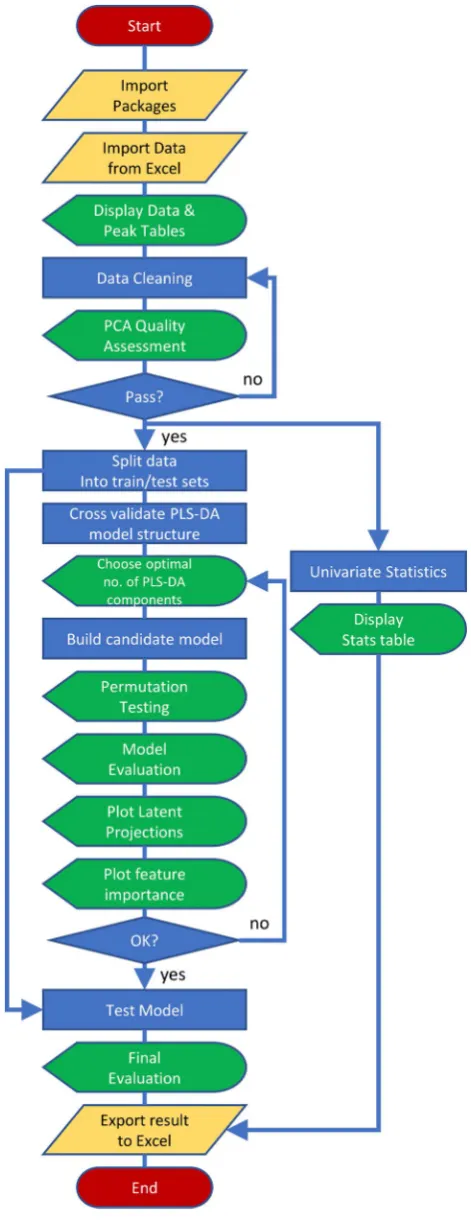
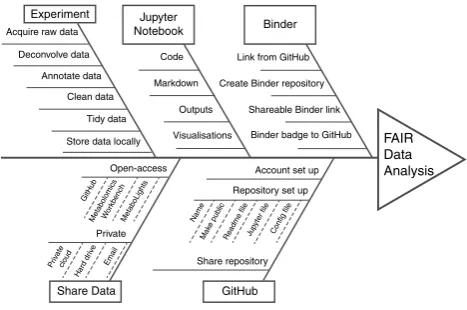
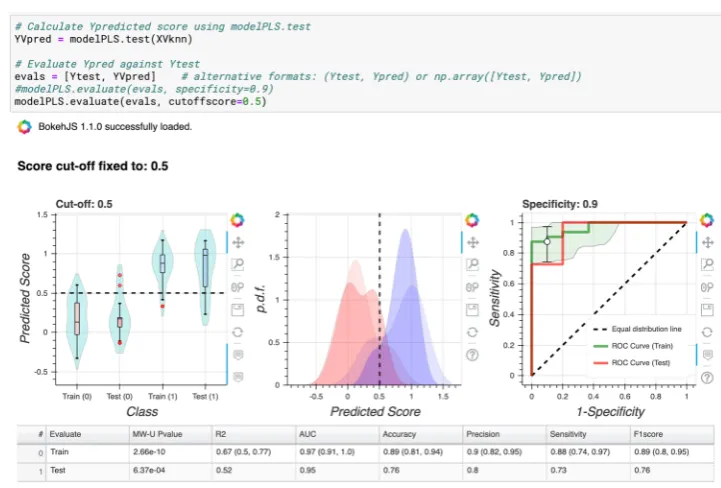
Related documents
By the use of such meetings and systems like the Supplier and Contract Management System (see section 12. Electronic Procurement) adopted by the Yorkshire and Humber region, we are
• Plans, organizes, directs, coordinates and reviews the project management activities of the Local District Facilities Director and Local District Project Manager with regard
This theorem allows us to prove observational equivalence using swapping: we prove that a bipro- cess in compiler (P) satisfies observational equivalence using ProVerif (by Theorem
Also, because security is a game where the attacker gets the last move, and where it can be very costly if a security hole is discovered after a system is widely deployed, it pays
Uzziah, Menahem began to reign over Israel, and he reigned ten years ; 2 Kings xv.. Perhaps
We thus use the data to examine the “Sophie’s choice” faced by families of whom to send away, the earnings and schooling of those sent away and those not sent away, and the
BGP Domain Name Server Connection Controller End Station Policy Server Call Controller Call Control Policy Control Connection Control Data Plane ARP DNS STP MPLS Network
Domain Name Server Connection Controller End Station Policy Server Call Controller Call Control Policy Control Connection Control Data Plane ARP DNS STP OSPF MPLS Network
