Performance Evaluation of MapReduce applications on Cloud Computing Environment, FutureGrid
Full text
Figure
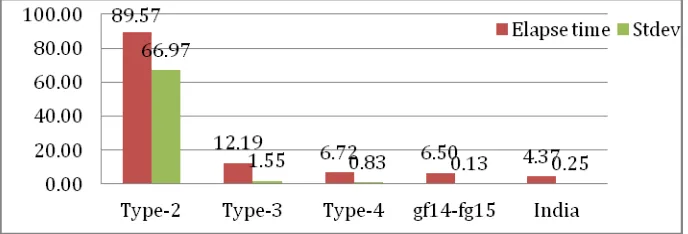
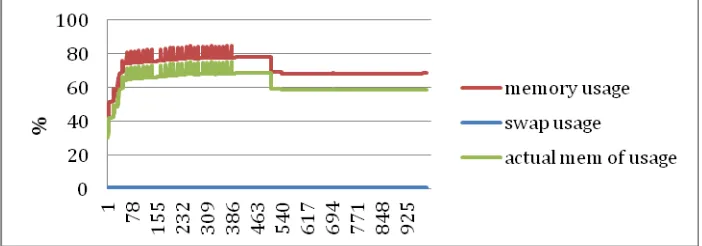
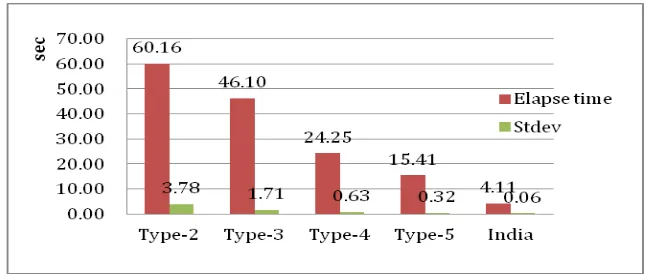
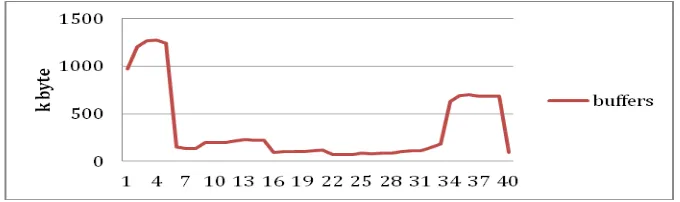
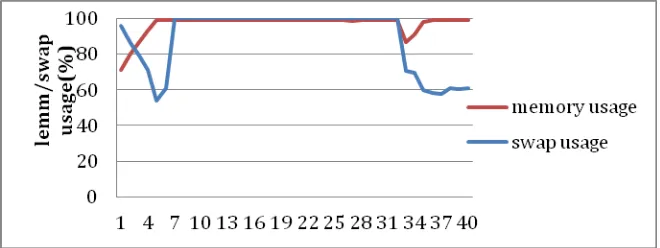
Related documents
W hen SpaceX sought a partner to conduct test- ing for development of the company’s ambi- tious Raptor rocket engine, its focus naturally fell on the versatile high-pressure
It has been found that the retail chain farmers could realize higher profits compared to non-RC (traditional market supplying) farmers mainly because of higher yield and higher
RFC 3479 Fault Tolerance for the Label Distribution Protocol (LDP) RFC 3509 OSPF ABR Behavior RFC 3526 More Modular Exponential (MODP) Diffie- Hellman groups for Internet Key
Ringgit borrowings obtained by residents (individual or company) whether from a resident or non-resident, are allowed to be converted (i.e. swapped) to foreign currency
Nevertheless, the finding of this study that the duration of high cognitive demand questions predicted children’s expressive vocabulary learning, along with Gonzalez et al.’s
The results of the analysis suggest that the passage of a sexual orientation anti-discrimination law does not have an effect on the relative earnings or employment of lesbians, but
We applied Big Data analytics to the study of physiologic signatures of subacute, potentially catastrophic illnesses – respiratory failure leading to urgent, unplanned
Then, a multi-objective model was developed for designing an integrated rail transit and bus network to maximize rail ridership and minimize total passenger travel time.. An
