International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-6, April 2019
Self-Taught Low-Rank Coding for Visual Learning
Using STL
Mr. Pandiaraj; Vipul Kumar Singh: Bhavesh Sharma: Subramanian; D. Guna⁴
Abstract: The absence of named information displays a typical test in numerous PC vision and AI errands.. Highlight learning assumes a focal job in example acknowledgment. As of late, numerous portrayal based element learning techniques have been proposed and have made extraordinary progress in numerous applications. Be that as it may, these techniques perform highlight learning and resulting classification in two separate advances, which may not be ideal for acknowledgment undertakings. In this paper, we present a directed low-position based methodology for learning discriminative highlights. By incorporating idle low-position portrayal (LatLRR) with an edge relapse based classifier, our methodology consolidates include learning with classification, so the controlled classification mistake is limited. Thusly, the removed highlights are progressively discriminative for the acknowledgment undertakings. Our methodology benefits from an ongoing disclosure on the shut structure answers for quiet Later. At the point when there is commotion, a vigorous Principal Component Analysis (PCA)- based demonising step can be included as pre-processing. At the point when the size of an issue is vast, we use a quick randomized calculation to accelerate the calculation of strong PCA. Broad exploratory outcomes exhibit the viability and power of our technique.
Keywords: PC vision, portrayal (LatLRR).
I. INTRODUCTION
The execution of visual learning calculations is vigorously subject to the nature of information portrayal.Meagre coding word reference learning and low rank learning have been generally utilized for speaking to visual information. Great portrayals are expressive, implying that a sensibly measured lexicon (i.e., premise capacities) can catch an immense number of conceivable info arrangements, and furthermore describe a given arrangement of information with certain worldwide basic outline. In any case, the nonappearance of getting ready data presents a run of the mill test in many refined depiction adapting calculations. Traditionally, this issue was incompletely tended to by semi supervised learning or exchange learning strategies.
Revised Manuscript Received on April 8, 2019.
Mr. Pandiaraj (M.E) Assistant Professor (S.G); Department of Computer Science and Engineering, SRM Institute of Science & Technology, Ramapuram, Chennai, India
Mr. Vipul Kumar Singh Student: Department of Computer Science and Engineering, SRM Institute of Science & Technology, Ramapuram, Chennai, India
Mr. Bhavesh Sharma Student: Department of Computer Science and Engineering, SRM Institute of Science & Technology, Ramapuram, Chennai, India
Mr. Subramanian T Student;Department of Computer Science and Engineering, SRM Institute of Science & Technology, Ramapuram, Chennai, India
D. Guna Student, Department of Computer Science and Engineering, SRM Institute of Science & Technology, Ramapuram, Chennai, India
Self-Taught Low-Rank Coding for Visual Learning Using STL
our methodology is truly reasonable for tending to the assignments that influence on the misuse of basic information structure, for example, object acknowledgment, scene characterization, face acknowledgment, and picture bunching. Particularly when the objective informational collection is little, our methodology is as yet ready to remove compelling element portrayals by prudence of expansive scale unlabelled information in the helper space. In the meantime, the low-position limitation is equipped for expelling clamour or exceptions from informationwhich causes us adapt progressively vigorous portrayals in the objective area.An expressive word reference is found out by demonstrating both assistant space and target area. In this procedure, the structure data in target space is implemented utilizing low-position imperatives. All the more explicitly, our methodology can be communicated as a rank-minimization and lexicon learning issue. We plan a powerful majorization– minimization enhancement calculation to get familiar with the low-position coding’s and word reference mutually. At long last, the adapted low-position coding’s relate to the objective space can be specifically utilized for bunching, or can be utilized to prepare an administered model like help vector machines (SVMs) for arrangement. Additionally, a few restrictions of existing STL techniques can be tended to by the proposed methodology. One of the least complex area adjustment approaches is the element increase work. The objective is to make a space explicit duplicate of the first highlights for every area. Each element in the first area of measurement N is mapped onto an increased space of measurement N 3 essentially by copying the element vectors.An element growth based strategy for using the heterogeneous information from the source and target spaces was as of late proposed. The methodology taken is to present a typical subspace for the source and target information with the goal that the heterogeneous highlights from two spaces can be looked at.
It eagerly interface the coding framework to the learning errands. This paper is an augmentation of our past work. In
synopsis, the significant commitments of this paper incorporate the accompanying.
1) All things considered, the execution of the mathematical based strategies within the sight of clamour decays as the quantity of subspaces increments.
2) The new methodology is effective in subspace grouping for even exceptionally ruined information, anomalies, or missing sections.Lexicon learning for scanty portrayal has been ended up being extremely powerful in AI, neuroscience, flag preparing,
3) There are a few constraints of the element based and criterion exchange based visual space adjustment techniques explored in this overview. For example, the change put together methodologies talked about are based with respect to some thought of closeness between the changed source tests and target tests. They don't upgrade the target capacity of a segregating classifier straightforwardly. Likewise, the computational intricacy of these strategies is exceedingly subject to the all-out number of tests utilized for preparing. Then again, criterion adjustment based techniques, for example, advance the classifier specifically however they are not ready to exchange the adjusted capacity to novel classifications. To manage this issue, a few techniques have been created in the writing that endeavour to advance both the change and classifier criterions together
Self-Taught Low-Rank Coding for Visual Learning Using STL
II. SIMILARWORKS
A. Self-Taught Learning
The execution of a directed grouping calculation is regularly subject to the accessibility of an adequate measure of preparing information. In any case, marking tests is coself teaching techniquey and tedious because of the huge human exertion included. Accordingly, it is attractive to have strategies that become familiar with a classifier with high exactness from just a restricted measure of marked preparing information. In semi supervised learning, unlabelled information are misused to cure the absence of named information. This thus necessitates the unlabelled information originates from indistinguishable dissemination from the named information. Henceforth, in the event that we overlook the space contrast, and treat the marked source cases as named information and the unlabelled target area occasions as unlabelled information, at that point the subsequent issue is that of the semi supervised learning issue. Subsequently, one can apply any semi supervised learning calculation to the area adjustment issue. The inconspicuous contrast between space adjustment and semi supervised taking in originates from the accompanying two certainties
An inadequate coding-based methodology was proposed in for self-taught realizing, where a lexicon is found out utilizing unlabelled information. At that point, larger amount highlights are figured by unravelling a curved 1, - regularized least squares issue utilizing the scholarly lexicon and the marked preparing information. At last, a classifier is prepared by applying a managed learning calculation, for example, a help vector machine (SVM) on these larger amount marked highlights. A discriminative rendition of this calculation was additionally exhibited in. Besides, an unsupervised educated learning calculation called self-trained grouping was proposed in [23]. Self-taught grouping goes for bunching a little accumulation of target unlabelled information with the assistance of a lot of helper unlabelled information. It is accepted that the objective and helper information have an alternate dissemination. It was demonstrated that this calculation can extraordinarily outflank a few best in class grouping strategies when utilizing superfluous unlabelled information.
B. Low-Rank Learning
Low-position learning is a functioning examination point as of late, with numerous effectively applications in different spaces. Vigorous PCA can deteriorates a debased example set X ∈ Rd×N into a low-position (clean) part XL
∈ Rd×N and a meagre (commotion) segment E ∈ Rd×N, where d is the component of test and N is the example measure. Specifically, X = XL + E. RPCA accept that information is drawn from a solitary subspace. Moreover, LRR means to recuperate clean information from uproarious perceptions that are drawn from various subspaces.
The target capacity of LRR is as per the following: min rank(Z) + λ1E0
Z,E
s.Y., C = CX + ER (1)
here rank() means the rank capacity, Z ∈ RN×N is the low-position coding lattice for C, R∈ Rd×N is the reproduction blunder network, E0 signifies the l0 standard of framework E, and λ1 is a trade-offcriterion. The above issue is hard to tackle as a result of the nonconvexity of rank capacity and l0 standard. Generally, they can be changed over into follow standard (i.e., atomic standard) and l1 standard, separately, and afterward, various advancement calculations can be connected to take care of the issue. Numerous calculations have been proposed to improve the execution of LRR. For instance, seeking after compelling bases for LRR is a vital issue. As of late, a bound together multiscale LRR approach is intended for picture division. The low-position requirement can likewise be utilized to learn powerful subspace, to learn successful online measurements, to build dependable diagrams, to help troupe bunching, or to distinguish exceptions in Multiview settings.
There are critical contrasts between our S-Low coding methodology and the previously mentioned low-position learning techniques: 1) they just spotlight on a solitary area, while our methodology looks for assistance from the helper space and 2) existing work like and gains a word reference just from the objective area, and all other existing low-position strategies don't learn lexicons. Be that as it may, our methodology takes in a lexicon from both helper and target areas in the SELF TEACHING TECHNIQUE setting.
Some ongoing works brought low-position limitations into exchange learning issues. Low-position exchange subspace learning technique forces a low-position requirement on a low-dimensional subspace shared by source and target areas, and low-position space adjustment strategy plans to lessen the space conveyance uniqueness utilizing LRRs. An inert low-position exchange learning approach is proposed to handle the missing methodology acknowledgment issue. Our methodology contrasts from them in three viewpoints. Initially, these techniques have confinements as far as utilizing related homogenous undertakings in source and target areas, while our methodology loosens up such confinements. Second, they can't learn word references because of their concern settings. Third, the learning crosswise over various areas is exchanged by means of a common subspace, while our methodology exchanges information through a lexicon.
II.
SELF-LEARNINGLOW-RANKINGTECHNIQUE
In this area, we define the proposed self-educated low rank coding structure, and build up our methodology deliberately. At that point, we present a successful enhancement calculation to comprehend the model. Table I abridges the documentations utilized all
Self-Taught Low-Rank Coding for Visual Learning Using STL
A. Motivation
We will likely take points of interest of the copious unlabelled information, so as to improve the coding execution for different visual learning assignments. To accomplish this objective, we propose a Self-low ranking coding system, by utilizing a top-notch word reference preoccupied from the abundance of data behind the helper space. Our instinct is that numerous kinds of visual information are very much portrayed by substantialspace structure, and subsequently, it is conceivable to use on such data from both start and destination areas, laself teaching techniquey learn abnormal state portrayals for the objective space. In particular, we present a low-position imperative in our system to exploit worldwide structure data in the objective space. Stressing such sort of structure data through low-position
TABLE I NOTATIONS
requirements could incredibly profit expansive visual learning errands particularly bunching and grouping, in which perceiving the fundamental structure of a given example set is our definitive objective. The low-position limitation is likewise equipped for expelling commotion and anomalies from information which prompts powerful information portrayals.
B. Problem Statement
Thinking about the SELF TEACHING TECHNIQUE issue, we are given a lot of bounteous, unlabelled examples, XS = {xS1,..., xSm} ∈ Rd×m, in the assistant area (or source space), and we likewise have constrained examples in the objective space, XT = {xT1,..., xTn} ∈ Rd×n. Our methodology expects to learn efficientcoding’s, in which the substantial space basic data is encoded, for the examples in the objective space. Like other strategies, we have been a few works in the writing that stretch out semi directed learning strategies to area adjustment. A guileless Bayes' exchange classifier calculation, which takes into account the preparation and test information conveyances to be diverse for content characterization, was proposed. This calculation first gauges the underlying probabilities under a dissemination of one marked informational index and afterward utilizes a desire augmentation (EM) calculation to
change the model for an alternate conveyance of the test information which are thought to be unlabelled. This EM-based space adjustment technique can be appeared to be proportional to a semi directed EM calculation
Generally, the meagrecoding, lexicon learning, or low-position learning techniques around speak to the examples in a solitary area (i.e., the objective space)
XT ≈ DT ZT (2)
where ZT ∈ Rr×n is the portrayal coefficient lattice and DT
∈ Rd×r is a word reference. r is the extent of word reference. Here,
ZT is typically expected to be inadequate or low-position, as indicated by the application situation. Note that the lexicon DT is frequently set as the example set in some inadequate portrayal and low rank learning techniques (i.e., DT = XT ), which may endure the lacking testing issue.
With the assistance of helper area, we can become familiar with a progressively educational word reference, and furthermore handle the inadequate information inspecting issue.
To start with, we can take in the word reference from all the accessible examples in two spaces. The entire example set is X = [XS XT ]. We expect to speak to all examples in X utilizing a word reference D ∈ Rd×r. Subsequently, we present the imperative
[XS XT ] =[ZS ZT ] + [ES ET ], where ZS ∈ Rr×m and ZT
∈ R× are the coefficient grids relating to helper space and target area, separately. ES ∈ Rd×m and ET ∈ Rd×n are the scanty clamour lattices that display the remaking mistakes in assistant and target spaces. The clamour networks ES and ET are regularly compelled utilizing the surrogate of l0 standard, for example, l1 or l2,1 standard. As a general rule, target tests may contain different kinds of clamour. Considering the scanty commotion frameworks in the model empowers us to become familiar with a hearty word reference.
Second, for some vision issues like grouping or order, tests in the objective space for the most part lie in a few fundamental subspaces. Numerous ongoing exploration endeavours have demonstrated that upholding low-position imperative is a compelling method to find the basic subspace structure. Utilizing such structure data can extraordinarily profit the ocularlearning assignments. In light of this observation, we force a low-position requirement on the coefficient grid ZT in the goal territory, where the learning assignments are done. Hence our objective of this project is successfully executed as: min T rank(ZT ) + λ1ES0 + λ2ET 0 D,ZS,Z , ES,ET s.t. XS = DZS + ES, XT = DZT + ET (3)
where rank(·) means the rank capacity, ·0 is the l0 standard, and λ1 and λ2 are two trade-off symbols.
Self-Taught Low-Rank Coding for Visual Learning Using STL
In this way, it can't be fathomed specifically. By and by, the l0 standard and the rank capacity can be loose by the l1 standard and atomic standard, individually. Some raised enhancement calculations, for example, the substituting course strategy for multipliers, can accomplish satisfactory execution. Be that as it may, it has demonstrated that the l1 standard and the atomic standard are really one-sided estimators, as they over punish expansive sections and substantial particular qualities. To handle this issue, we utilize the nonconvex surrogates of l0 standard and rank capacity, which are MCP standard and grid γ-standard, individually.
The meaning of framework MCP standard for a grid B ∈
Rp×q is
Mλ,γ (B) = φλ,γ(Bi,j) (4)
i,j where
By supplanting the rank capacity and l0 standard with framework γ-standard and Majorization standard, the goal work (3) can be changed as
min TZT γ1 + λ1Mγ2(ES) + λ2Mγ2(ET ) D,ZS,Z ,
ES,ET
s.t. XS = DZS + ES, XT = DZT + ET . (6)
Third, the word reference is mutually gained from both helper and target areas, so as to exchange valuable information from the assistant space. The two requirements in (6) share a similar word reference D. As the source informational collection XS more often than not contains significantly more examples than target informational collection XT , the learning of word reference is effectively ruled by the source information. In any case, it is progressively balanced to stress the remaking intensity of D in the objective area in which our learning undertaking performs. Hence, we present a l2,1 standard requirement on the source coefficient framework ZS. Along these lines, a few columns in ZS are urged to be zero, which empowers XS to adaptively choose bases from D. Then again, D is completely used to recreate tests in the objective space. From that point onward, our goal moves toward becoming min TZT γ1 + λ1Mγ2(ES) + λ2Mγ2(ET ) + λ3ZS2,1 D,ZS,Z ,
ES,ET
s.t. XS = DZS + ES, XT = DZT + ET (7) whereλ3isatradeoffcriterion,and
ZS2,1=nj=1 (di=1 ([ZS]ij )2)1/2 is the l2,1 standard.
Every section in the scholarly coefficient network ZT relates to one example in the objective area, which is named low-position technique in this journal.Fig. 5 shows the evaluated mean of each band on the reconstructed data matrix denoted by the product of a dictionary and its sparse representation C. Advancement
In this segment, we structure a majorization– minimization increased Lagrange multiplier calculation to tackle this problem. We initially present the summed up compressed administrator Dγ,E and the summed up particular esteem shrinkage administrator Sτ,
[Dγ,W(B)]ij = sgn(Bij)(|Bij| − τWij )+ (8)
VTX (9)
where both and are positive lattices.
To encourage the streamlining, we include an unwinding variable
J ∈ Rr×n to (7)
minJγ1 + λ1Mγ2(ES) + λ2Mγ2(ET ) + λ3ZS2,1
D,ZS,ZT ,ES,ET ,Js.t. XS = DZS + ES, XT = DZT + ET , ZT = J. (10) The Majorization– minimization increased Lagrange multipliercalculation contains an inward circle and an external circle. In every cycle, the external circle uses the locally straight estimation of the first nonconvex issue, and structures a weighted curved issue for enhancement. In the inward circle, we embrace the estimated expanded Lg-rangian multiplier calculation. In the external circle, we have to modify the goal work. As the goal in (10) is inward regarding (σ(J),|ES|,|ET |), we can rough Jγ1+λ1Mγ2(ES)+ λ2Mγ2(ET )
by its LLA at (σ(Jold),|ES|old,|ET |old), and we acquire the accompanying target work:
D,minZS,ZT , Qγ1(σ(J)|σ(Jold)) + λ1Qγ2ES|ESold ES,ET ,J + λ2Qγ2ET |ETold + λ3ZS2,1
s.t. XS = DZS + ES, XT = DZT + ET , ZT = J (11) where
Qγ(B|Bold) = Mγ (Bold) + i,j 1 − Bijoldγ +|Bij | − Bijold . is the LLA of Mγ (B) given Bold.
In the inward circle, the estimated ALM calculation is utilized to illuminate (11). Given an instated word reference D, we refresh different factors J, ZS, ZT , ES, and ET . The expanded Lagrangian capacity of (11) is
L = Qγ1(σ(J)|σ(Jold)) + λ1Qγ2ES|ESold +λ2Qγ2ET |ETold + λ3ZS2,1 + Tr(RT (ZT − J))
+Tr(Y T (XS − DZS − ES)) +Tr(QT (XT − DZT − ET )) XS − DZS + XT − DZT − ET 2F (12)
where · F is the Frobenius standard, Y ∈ Rd×m, Q ∈ Rd×n, and R ∈ Rr×n are Lagrange multipliers, and μ is a +ve punishment area.
Self-Taught Low-Rank Coding for Visual Learning Using STL
Jk (Rk/μk)) (13)
ZT(k+1) = (In + DT D)−1(DT XT − DT ETk
+ Jk+1 + (DT Qk − Rk)/μk) (14)
ZS(k ZS2,1 ZS − ZSk − DT ×(XS − DZSk − ESk + Yk/μk)
ES(k+1) = Dλ1/μ,W(XS − DZS(k+1) + Yk/μk) (16) ET(k+1) = Dλ2/μ,W(XT − DZT(k+1) + Qk/μk). (17) At the point when the factors J, ZS, ZT , ES, and ET are improved, we refresh the lexicon D utilizing an effective solver displayed in [2]. All the more explicitly, by disregarding the unessential terms
D. Algorithm and Discussion
The entire enhancement process, including both internal circle and external circle, is rehashed until combination. The issue (15) can be understood by. The nitty gritty systems of our advancement are laid out in Algorithm 1.
Combination: Lemma 1 shows the nearby intermingling property of our calculation.
Lemma 1: When D is fixed, the target work estimations of (11) obey f (J, ES, ET , ZS)
≤ Qγ1(σ(J)|σ(Jold)) + λ1Qγ2ES|ESold
+λ2Qγ2ET |ETold ZS2,1
≤ Qγ1(σ(Jold)|σ(Jold)) + λ1Qγ2ESold|ESold
+λ2Qγ2(ETold|ETold) + λ3ZoldS 2,1 = f Jold, ESold, ETold, ZoldS .
This lemma can be effectively demonstrated utilizing. It shows the nearby combination property of our calculation. Introduction: In Algorithm 1, the lexicon D is instated by some arbitrarily chosen tests from X. ZS and ZT are instated by arbitrary ordinary lattices. The various factors are introduced by 0. Our analyses demonstrate that both D and Z are not touchy to the irregular introductions.
Time Complexity: Given r < n, the stage 5 in Algorithm 1 includes particular esteem deterioration decay of a framework with size r×n that costs O(nr2), and the augmentation and the reverse of lattices in stage 6 likewise expense O(nr2). Since the external circle merges rapidly by and by, which will be delineated in examinations, we just consider the inward circle in the time intricacy investigation. Give t a chance to indicate the quantity of emphasess in the inward circle, the unpredictability of our calculation is O(tnr2).
IV. LEARNING WITH S-LOW CODING
In this segment, we present two learning calculations dependent on our S-Low coding methodology, including grouping and characterization.
A. S-Low Clustering
We arbitrarily select an immaterial picture from Google and down sample it to 12 to10. We at that point process the inadequate portrayal of the picture against the equivalent Extended Yale B preparing information the got coefficients,
plots the relating residuals. Contrasted with the coefficients of a substantial test picture in Fig. 3, see that the coefficients ^ x here are not focused on any one subject and rather spread broadly over the whole preparing set. Hence, the dissemination of the evaluated meagre coefficients ^ x contains critical data about the legitimacy of the test picture: A substantial test picture ought to have a scanty portrayal whose nonzero sections focus for the most part on one subject, though an invalid picture has inadequate coefficients spread generally among various subjects. Given two coding vectors zi,z j ∈ ZT , the chart weight G(i, j) is characterized as
ziT z j
G(i, j) = . (19)
zi2z j2
Then again, sparsity is constantly underscored amid chart development, and in this way, we prune those edges with little loads to make the diagram inadequate. At long last, a viable grouping calculation, standardized cuts (NCuts) , is utilized to deliver the bunching results. The entire systems of S-Low bunching are abridged in Algorithm 2.
B. S-Low Classification
At the point when mark data is accessible in the objective area, we plan a characterization calculation dependent on our S-Low coding way to deal with train a classifier. At that point, with the assistance of the educated word reference D, our calculation could arrange new test tests. As talked about in Section III-A, low-position coding’s ZT can be considered as new portrayals of the objective example set XT . Given a test y, we can ascertain the portrayal coefficients of y ∈ Rd×1 by comprehending
Without the loss of sweeping statement, we can prepare any classifier utilizing ZT . In this paper, we embrace the ordinarily utilized classifier, SVMs, to anticipate the class mark of y. Calculation 3 outlines every one of the methodology in our S-Low characterization calculation.
V. EXPERIMENTS
In this segmentAt the point when information are corrupted,the execution of SSC is substandard compared to all LRR-based strategies, which demonstrates that inadequate portrayal isn't great at dealing with defiled information, for example, LRR. In spite of the fact that our model utilizes a scanty portrayal on the component space, our model TLRRSC still performs best among every one of the techniques on the debased informational index. This is on the grounds that TLRRSC investigates information spatial relationship data with a LRR, which ensures precisely grouping information into various subgroups.
A. Data Sets and Settings
1) Assistant Domain
Self-Taught Low-Rank Coding for Visual Learning Using STL
unlabelled pictures from the BaseLabeLWeb website to build the example set in assistant space. Right now, the LabelMe informational index contains in excess of 100 thousand pictures gathered from different assets, which give us an incredible helper area for SELF TEACHING TECHNIQUE. Fig. 2(a) demonstrates a few pictures in the LabelMe informational collection.
2) To assess how the information estimate in the assistant space influences the execution of learning assignments in the objective area, we change the quantity of helper tests from 2000 to 600, and look at the execution in various settings. In our trials, we locate that expanding the span of helper test set would improve the execution of learning assignments, however the enhancements are negligible when the size is more than 300. Because of as far as possible, we just report the aftereffects of SELF TEACHING TECHNIQUE calculations under two settings that utilization 200 and 300 assistant pictures, separately.
3) Target Domain Data Sets: To broadly affirm our methodology and related strategies, we use the accompanying 5 benchmark informational indexes.
1) Given another test y from one of the classes in the preparation set, we initially figure its scanty portrayal ^ x x1 by means of (6) or (10). In a perfect world, the nonzero passages in the gauge ^ x x1 will all be related with the sections of A from a solitary item class I, and we can without much of a stretch allot the test y to that class. Notwithstanding, commotion and demonstrating blunder may prompt little nonzero passages related with numerous article classes (see Fig. 3). In light of the worldwide scanty portrayal, one can structure numerous conceivable classifiers to determine this. For example, we can essentially dole out y to the article class with the single biggest passage in ^ x x1. In any case, such heuristics don't bridle the subspace structure related with pictures in face acknowledgment. To all the more likely bridle such direct structure, we rather characterize y dependent on how well the coefficients related with all preparation tests of each article duplicate y
2) Kaltech-UCSD Birds information set4 contains the photographs of 200 winged animal’s species (for the most part American). There are 603 pictures altogether. In the investigations, we select the initial 30 classifications. Fig. 2(e) demonstrates a few pictures in the Caltech-UCSD Birds informational collection.
TABLE II
TARGET DATA SETS FOR EXPERIMENTS
3) Baselines: We contrast our S-Low bunching
calculation and a few agent subspace grouping techniques, including adaptable inadequate subspace grouping , LRR,
inactive LRR, and fixed position portrayal (FRR) . Despite the fact that the DSRTL strategy isn't intended for grouping issues, we likewise affirm its execution on subspace bunching to additionally delineate the contrasts between our methodology and DSRTL. We use an unsupervised form of DSRTL, by supplanting the class in DSRTL with the diagram development system. In detail, the educated lexicon D is utilized for producing new coding’s of each example, and after that, a chart is built utilizing the coding’s. As we have two diverse helper test sets, we use DSRTL-An and A to indicate the techniques utilizing 100 pictures from the assistant space, and DSRTL-B and Ours-B utilize the helper test set with 300 pictures. For the picture arrangement errand, we contrast our S-Low order calculation and managed learning strategy SVM,semi supervised learning technique transudative SVM (TSVM), low-position learning strategies inactive LRR, and FRR. We additionally contrast our methodology and the best in class area adjustment and SELF TEACHING TECHNIQUE techniques, including the tourist spots determination-based subspace arrangement (LSSA) strategy, STL, and DSRTL.
mapping capacity that maps each group mark ri to the identical name from the informational index
MI(S, N)
NMI(A, B) = (22)
max(H(S), H(N))
where S and N are the anticipated bunching file and the ground truth, individually. MI(S, N) indicates the common data among A and B. H(A) and H(B) signify the entropies of p(a) and p(b).
[image:7.595.306.554.312.421.2]Self-Taught Low-Rank Coding for Visual Learning Using STL
B. Properties
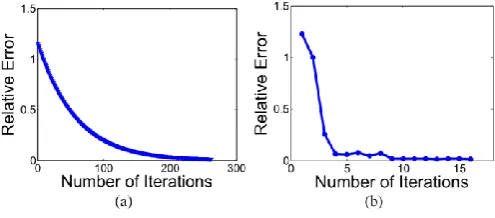
1) Convergence Analysis: Figure. 3(a) and (b)
demonstrates our methodology unites rapidly. The relative mistakes in Fig. 3(a) and (b) are determined by ZT(k+1) − ZTkF/ZTkF and D j+1 − D jF/D j F, individually. Particularly, Fig. 3(b) demonstrates that our word reference meets after a couple of times, which is valuable to some extensive scale applications.
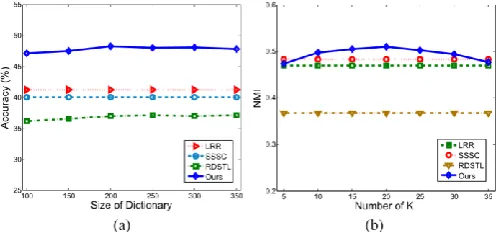
2) Sensitivity of Criterion: In our methodology, there are three noteworthy criterions, λ1, λ2, and λ3. To pick appropriate qualities for them, we assess the criterion sensitivity on the informational index. We directed an interior 5fold cross approval in the preparation set to calibrate the criterions. Fig. 4 demonstrates the exactness of Ourbasic approach with various particulars of λ1, λ2, and λ3, separately. Here, λ1 and λ2 expect to deal with the noise in information, while λ3 controls the basic sparsity in ZT , which enables the source information to choose a few bases from D. Fig. 4 additionally demonstrates that our methodology accomplishes moderately stable execution when λ3 is modified from 1 to 2. In the interim, λ2 does not influence the outcomes altogether in the range.
As TLRRSC needs additional opportunity to illuminate the scanty representationalongthe featuremode,the time cost ofTLRRSC is a little moreexpensivethanTLRR. Moreover, when the sparsity esteem is 20, TLRRSC performs best contrasted and other sparsity esteems, which proposes that our strategy can precisely bunch information with a little sparsity esteem. To entirety up, our new technique TLRRSC can accomplish better execution with a practically identical time cost in the higher method of tensor.
In many computer vision applications, data often come in multiple views or styles. For instance, in object recognition, one has to deal with objects in different poses (views) and lighting conditions.
We contrast our calculation's execution and another cutting edge calculation LRSSC in [28], which likewise exploits SC and LRR. LRSSC limits a weighted aggregate of atomic standard and vector 1-standard of the portrayal framework all the while, in order to safeguard the properties of interclass detachment and interclass availability in the meantime. In this manner, it functions admirably in the networks where information conveyance is skewed and subspaces are not free. Not at all like LRSSC expressly has satisfies LRR and SC property at the same time, our model updated the criterions for LRR and SC then again, and our model spotlights on multidimensional information with a high-dimensional element space.
C. Clustering Results
[image:8.595.306.557.50.166.2]Self-Taught Low-Rank Coding for Visual Learning Using STL
Relating non measurement index of every strategy. We can see that all the not high-position related techniques outflank previous technique, since they unequivocally take consideration of the structure data in test space. At the point when class names are not accessible, the hidden structure data of information assumes a critical job in learning errands. Inert LRR, which models the impact of shrouded information, performs superior to LRR and FRR. By excellence of an increasingly useful lexicon gained from both helper area and target space, our methodology accomplishes preferable execution over different contenders on all the five informational indexes.
Moreover, by expanding the information estimate in assistant space, the execution of self-teaching strategies could be somewhat improved, as DSRTL-B and Ours-B
beat DSRTL-A and
Ours-A much of the time, individually. We additionally seen that, on the Caltech-UCSD Birds informational collection, unsupervised bunching is a somewhat difficult issue, and the grouping exactness of all looked at strategies are somewhat low. One conceivable reason is that most classes share numerous basic visual components, for example, unique winged animals in nature.
D. Classification Results
The principle preparing steps engaged with complex based adjustment methods are registering the geodesic between the source and target areas, and afterward testing focuses along
the geodesic to construe halfway spaces that represent the space move. This includes mapping elements on the complex to the locally Euclidean digression plane and distorting the outcomes from the digression plane back onto the complex. Computationally productive calculations for these means have been examined in the writing for Grossmann manifolds [94]. For symmetrical networks of measurements, NN 12 # the geodesic calculation has an intricacy of ONN 1 2 ^h alongside an ONN12 ^h cost for examining each point along the geodesic. For profound learning approaches [77], [78], the multifaceted nature depends, among others, on the quantity of layers utilized in the chain of importance to learn include connection for adjustment. While the profound system circuits can have diverse designs, for example, auto encoders and limited Boltzmann machines, there is a functioning stream of work in making the preparation method of these circuits
[image:9.595.61.553.294.574.2]computationally tractable. See [72] for an increasingly itemized discourse on the unpredictability of profound structures. A noteworthy computationally overwhelming advance of lexicon based area adjustment strategies is commanded by scanty coding. Proficient bunch techniques have been proposed to learn word references for vast scale issues. For example, a cluster symmetrical coordinating interest based KSVD calculation for learning word references was proposed in [95].
Self-Taught Low-Rank Coding for Visual Learning Using STL
It was demonstrated that the task check per preparing cycle for learning a word reference of size elk # with R number of preparing signals where T0 is the objective sparsity. One can likewise adjust quick solvers for meagre coding instead of utilizing eager symmetrical coordinating interest calculations. For the low-position estimation based strategies, the real calculation is in finding the SVD of a network. Therefore, these strategies will in general be tedious if the grid is extensive. Be that as it may, proficient strategies do exist for finding the low-position estimate of extensive networks.
VI. CONCLUSION AND FUTURE WORK
This article endeavoured to give a review of late advancements in area adjustment for PC vision, with an accentuation on applications to the issues of face and item acknowledgment. We trust that the accessibility of gigantic information has conveyed considerable chances and difficulties to the examination of informational indexes inclination or co variation movements and space adjustment issues. We trust that the study has guided intrigued peruses among the broad writing somewhat, yet clearly it can't cover the majority of the writing on area adjustment, and we have concentrated on a delegate subset of the most recent advancement made in PC vision. There stay a few intriguing headings for our future work:
1) Given a preparation set in target area, we may naturally pick tests from the assistant space and
2) we would give quick answers for our structure by utilizing the separation and-overcome strategy.
REFERENCES
1. O. Chapelle, B. Schölkopf, and A. Zien, Semi-Supervised Learning. Cambridge, MA: MIT Press, 2006.
2. Shrivastava, S. Shekhar, and V. M. Patel, “Unsupervised domain adaptation using parallel transport on Grasmann manifold,” in Proc. IEEE Winter Conf. Applications of Computer Vision, 2014, pp. 277– 284.
3. L. Zhang, M. Yang, X. Feng, Y. Ma, and D. Zhang. (2012). “Collaborative representation based classification for face recognition.” [Online]. Available: http://arxiv.org/abs/1204.2358
4. M. Yang, L. Zhang, X. Feng, and D. Zhang, “Fisher discrimination dictionary learning for sparse representation,” in Proc. 13th IEEE Int. Conf. Comput. Vis., Nov. 2011, pp. 543–550.
5. L. Ma, C. Wang, B. Xiao, and W. Zhou, “Sparse representation for face recognition based on discriminative low-rank dictionary learning,” in
Proc. 25th IEEE Conf. Comput. Vis. Pattern Recognit., Jun. 2012, pp 6. Laptev, “On space-time interest points,” Int. J. Comput. Vis., vol. 64,
nos. 2–3, pp. 107–123, 2005. [51] H. Wang, M. M. Ullah, A. Kläser, I. Laptev, and C. Schmid, “Evaluation of local spatio-temporal features for action recognition,” in Proc. 20th Brit. Mach. Vis. Conf., London, U.K., Sep. 2009, pp. 124.1–124.11..
7. V. Zografos, L. Ellis, and R. Mester, “Discriminative subspace clustering,” in Proc. 26th IEEEConf. Comput. Vis. Pattern Recognit., Jun. 2013, pp. 2107–2114.