Abstract: Effort estimation is a crucial step that leads to Duration estimation and cost estimation in software development. Estimations done in the initial stage of projects are based on requirements that may lead to success or failure of the project. Accurate estimations lead to success and inaccurate estimates lead to failure. There is no one particular method which cloud do accurate estimations. In this work, we propose Machine learning techniques linear regression and K-nearest Neighbors to predict Software Effort estimation using COCOMO81, COCOMONasa, and COCOMONasa2 datasets. The results obtained from these two methods have been compared. The 80% data in data sets used for training and remaining used as the test set. The correlation coefficient, Mean squared error (MSE) and Mean magnitude relative error (MMRE) are used as performance metrics. The experimental results show that these models forecast the software effort accurately.
Keywords: Machine Learning, Linear Regression, K-Nearest Neighbors, COCOMO.
I. INTRODUCTION
The software Effort, Duration and cost estimation are important things for developers and customers and these depend on the size of software [9]. There are many kinds of research done on the effort estimation of software projects. The standard methods cannot do early estimations; other models need the requirements, all specifications about the project [11]. COCOMO uses LOC for effort estimation which is unknown until completion of the project; the FPA method uses inputs, master files, logical files, interfaces and outputs for size estimation. These methods are also known as algorithmic methods and they use historical data and formularization. These algorithmic methods need attributes such as development team experience, software reliability, language used for developing software and final source line of code, complexity and so on as inputs that are not possible to find in the early stage of the development life cycle [21]. These two LOC, FPA cannot perform early estimation of effort so we need a method that could do an early estimation of the project effort using previous project knowledge [11].
.
Revised Manuscript Received on December 05, 2019.
Bhaskar Marapelli,,Scholar at Sri JagadishPrasad JhabarmalTibrewala University, Rajasthan, India. Email: [email protected]
II. SOFTWAREEFFORTDURATIONANDCOST ESTIMATION
The steps in software estimation are:
Estimate the size of the development product. Estimate the effort in person-months or
person-hours.
Estimate the schedule in calendar months.
Estimate the project cost in dollars (or local currency) [22].
The most important work in software development is Estimation. Various Software Effort Estimation models came into existence when people started following the standard project management process. Researchers often use KLOC, Story Points, Function Points and Use Case Points as a measure of size. There are several techniques used to calculate effort which is broadly classified into algorithmic models, and non-algorithmic models [23]. Algorithmic models such as COCOMO, COCOMO-II, Putnam’s, etc., cannot do early estimations because the attributes they use could only be calculated after project completion. So for doing early estimation, the best alternate is non-algorithmic models such as expert-based, learning-based, linguistic-based and optimization-based models. In this research we are discussing on machine learning techniques which can perform early estimations and have the ability to handle non-linear function, these are adaptable for any environment, we could calculate confidence in decision made.
COCOMO
Constructive Cost Model (COCOMO) is one of the types of algorithmic software cost models. In very simple form basic COCOMO model is proposed by Barry Boehm in 1981. Effort= a * KLOCb
Duration= c *(Effort)d Staff size= Effort/ Duration.
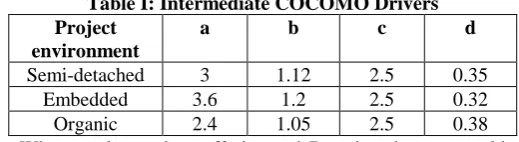
Where Duration is expressed in terms of months, Effort in man-months, the estimated lines of code for the project by KLOC. The co-efficient a,b,c, and d depends on application and environment.
Software Development Effort Duration and Cost
Estimation using Linear Regression and
K-Nearest Neighbors Machine Learning
Algorithms
Table I: Intermediate COCOMO Drivers Project
environment
a b c d
Semi-detached 3 1.12 2.5 0.35
Embedded 3.6 1.2 2.5 0.32
Organic 2.4 1.05 2.5 0.38
When we know the staff size and Duration then we could calculate the cost of the project by multiplying staff size (salary of each staff) and development time.
COCOMO II
COCOMO II is the updated version of COCOMO, which overcomes the weakness of COCOMO to estimate the efforts of the newer developed software. COCOMO II is good at allowing accuracy as 20% in cost and 70% in time [23]. Machine Learning Techniques
Machine learning techniques have been studied to estimate effort from software attributes. [1,2,3,4,5,13,21]. Any method of transforming data may be used for software estimation[24]. From the past two decades, machine learning algorithms have been used as a new way for effort prediction. [6]
In this work, we have discussed two machine learning techniques Linear Regression and K-nearest Neighbors. The results of machine learning models depend on the data sets used to train the model, the model's performance may be affected by the size of the data set, features of the data, missing values in data[10].
III. RELATEDWORK
Pinkashia et.al., (2017), this paper reviews about machine learning techniques for software effort estimation. He presented with useful information related to software effort estimation, he presented metrics for algorithm analysis, data sets, validation methods.
Omar and Betul(2017) studied software effort estimation by using machine learning techniques instead of time-consuming estimation methods. Omar and Betul prepared Models using two machine learning techniques which are Support Vector Machine (SVM) and K-Nearest Neighbor (k-NN) they used two public datasets namely Desharnais and Maxwell. Omar and Betul conclude that combining these two classifiers gives 91.35% accuracy with the Desharnais data set and 85.48% accuracy using the Maxwell dataset.
Sidra Tariq et.al.,(2015), This paper gives an overview of effort estimation techniques with machine learning. He proposed a method for the reduction of cost and effort. Different metrics were used to evaluate the method that is proposed. Metrics like Mean Absolute Error, Root Mean Absolute Error and relative Absolute Error are used to validate the method.
E.Karunakaran et.al., (2015), the main aim of this work is to improve the size, effort, cost estimation. He gives a review of the previous many works and proposes improvements in estimation. He has used 150 papers from journals and conferences and analyzed models for size estimation, effort estimation, cost estimation.
Jyoti et.al., (2014), This paper presents a different process for estimation with machine learning techniques on non-quantitative data. He proposed two phases in the first phase feature selection is done in the second effort estimation is done based on first phase selected features. He has used
Navie Bayes Classifier and Artificial Neural Network and the methods are compared with evaluated results.
Petrônio et.al., (2007), proposes a method based on machine learning which gives effort estimation with a confidence interval, these intervals do not depend on errors in the training set. Petrônio et.al., reports robust confidence intervals that can be built successfully and concludes M5P/ model trees achieves the best performance.
Ahmed et.al., In his paper suggests performing prediction using three machine learning techniques Navie Bayes, Logistic Regression and Random Forest. These three methods were applied to COCOMO NASA benchmark data. He concluded the third method Random Forest performs better than the Naive Bayes and Logistic Regression techniques. Miyoung et.al.,(2000), proposed a way to generalize linear regression by using Radia Basis function. This paper presents a modeling methodology for selecting model parameters and model selection.
Younghee et.al., (2005), compared neural networks, regression tree and k-nearest neighbor for estimation ability. He found that neural networks give prediction accuracy more than the other two. The accuracy evaluation of these three models done using MMRE, MdMRE, and Pred(10).
Bilge et.al.,(2007), this paper gives research analysis of problems related to effort estimation and how to solve them. He proposed a machine learning model and evaluated the model using public data sets and also data taken from software organizations in Turkey. He concludes that static methods are not enough for effort estimation, machine learning models are useful for effort estimation.
Carolyn et.al.,(2000), This paper gives a comparative analysis of machine learning methods for effort prediction. He gives detail about machine learning methods and also he used data of 81 projects derived from Canadian Software house in the late 1980s to evaluate the models. He compared models with metrics like accuracy, explanatory value. He concludes the ANN method's accuracy is better than RI methods.
IV. RESEARCHMETHODOLOGY
A. Data Collection
Table II: Effort multipliers Category Driver
Product Attributes
Required software reliability (RELY) Database size (DATA)
complexity of product(CPLX) Computer
Attributes
Time constraint (TIME) storage constraint (STOR) Virtual machine volatility (VIRT) Computer turnaround time (TURN) Personnel
Attributes
Analyst capability (ACAP) Application experience (AEXP) Programmer capability (PCAP) Virtual machine experience (VEXP) Programming language experience (LEXP) Project
Attributes
Modern programming practices (MODP) Software Tools Use (TOOLS)
Development Schedule (SCED)
Table III: COCOMO Data Set Statistics
Sno Variables Min Max Mean Standard deviation
1 RELY 0.75 1.4 1.036 0.193
2 DATA 0.94 1.16 1.004 0.073
3 CPLX 0.7 1.65 1.091 0.203
4 TIME 1 1.66 1.114 0.162
5 STOR 1 1.56 1.144 0.179
6 VIRT 0.87 1.3 1.008 0.121
7 TURN 0.87 1.15 0.972 0.081
8 ACAP 0.71 1.46 0905 0.152
9 AEXP 0.82 1.29 0.949 0.119
10 PCAP 0.7 1.42 0.937 0.167
11 VEXP 0.9 1.21 1.005 0.093
12 LEXP 0.95 1.14 1.001 0.052
13 MODP 0.82 1.24 1.004 0.131
14 TOOL 0.83 1.24 1.017 0.086
15 SCED 1 1.23 1.049 0.076
16 LOC 1.98 1150 77.21 168.509
17 ACTUAL 5.9 11400 683.321 1821.582
The three mentioned datasets (COCOMO 81,
COCOMONASA and COCOMONASA_2) have some common features such as; having the same number of features besides having the same measure type for effort which is person-hours.
Table IV: Summary of data sets
Datasets Number of
features
Number of projects
COCOMO 81 16 63
COCOMONASA 16 60
COCOMONASA_2 16 93
We randomly divided the datasets using two techniques which are percentage split and k-fold cross-validation to form a training set and testing set. The three datasets were analyzed in their context by using two machine learning techniques which linear regression and K-nearest Neighbors.
B. Model Creation
The Proposed model includes identifying the problem domain, scanning data, partition data into test and training or classification. We have used Weka Tool to create models and analyze them. Weka supports a large number of machine
learning algorithms. We have used Regression algorithms Linear Regression and K-nearest neighbors.
Linear Regression
Linear Regression estimates coefficients for the line or hyperplane to fit the training data. The linear regression algorithm is fast to train and give good performance if the output variable is a linear combination of inputs.
K-nearest neighbors
K-nearest neighbor’s technique works when there is no past knowledge about data description. This technique works by computing distance between an instance with other instances and finds the k-nearest neighbor for that instance.
Fig 1: k-nearest neighbor’s
C. Evaluating the Performance of the Models
Correlation Coefficient
The correlation coefficient is a measure of the statistical relationship between two variables. The variables may be columns of a given dataset. If the value of the correlation coefficient is higher the relationship is strong, if low the relation is weak [21].
Mean Absolute Error (MAE)
The mean absolute error tries to find how far the estimated values are from actual values. In this measure, all individual difference is weighted equally.
MAE
Here Pi = Predicted value of data point i Ai = Actual value ofdata point i n = Total number of data points.
Root Mean Squared Error (RMSE)
The root mean squared error gives the sample standard deviation of differences between predicted values and actual values.
In the above Pi = Predicted value of data point i; Ai =Actual value of the data point i; n = Total number of data points.
Relative Absolute Error (RAE)
The Relative absolute error gives a summation of the difference between predicted values and actual values, divides it with the summation of the difference between the actual value and the average of actual value.
Where Pij = Predicted value by the individual data set j for data point i.
Ai = Actual value for data point, n = Total number of data points, Am = Mean of all Ai
Root Relative Squared Error (RRSE)
For an individual data set j root relative squared error is defined as
Where Pij = Predicted value of the individual dataset j for data point in i;
Ai = Actual value of the data point i, n = Total number of data points, Am =Mean of all Ai,
V. RESULTANALYSIS
In this paper, we used three datasets COCOMO81, COCOMONASA, COCOMONASA_2 to predict software effort. The model was prepared by dividing datasets data into training, testing sets, 80% of data was used for training the model and 20% was used for testing the model.
The COCOMO81 dataset consists of 63 projects, The COCOMONASA dataset consists of 60 projects, these two datasets described by 17 attributes, 15 independent and two dependent. The dependent attributes are an effort (Actual) and LOC (kilo lines of code). COCOMONASA_2 dataset consists of 93 projects and 24 attributes in which 7 attributes (recordnumber, projectname, cat2, forg, center, year, and mode) are not effort multipliers so we can ignore them. For our experimentation, we divided datasets into the training set and the test set. Two types of experiments were done on datasets cross-fold validation and percentage split.
We used five measures to evaluate the accuracy of software effort prediction models. In this paper, we employ measures that are most commonly used in the literature [21].
Table IV: Result Metrics for COCOMO 81 data set with cross fold – validation, 10-fold cross-validation Metric Linear Regression K-nearest neighbor Correlation
coefficient
0.6102 0.0768
MAE 874.477 782.5524
RMSE 1480.8087 1997.3894
RAE 96.3751% 86.2442%
RRSE 80.6645% 108.044%
Table V: Result Metrics for COCOMONASA data set with cross fold – validation, 10-fold cross-validation Metric Linear Regression K-nearest
neighbor Correlation
coefficient
0.7994 0.5768
MAE 247.0465 295.4267
RMSE 431.768 590.2186
RAE 57.2976% 68.5184%
RRSE 64.832% 88.6241%
Table VI: Result Metrics for COCOMONASA_2 data set with cross fold – validation, 10-fold cross-validation Metric Linear Regression K-nearest
neighbor Correlation
coefficient
0.7294 0.659
MAE 430.7269 445.7796
RMSE 826.1252 924.0382
RAE 66.6849% 69.0154%
RRSE 72.3107% 80.881%
Table IV: Result Metrics for COCOMO 81 data set with percentage split, 80% TRAING SET, 20% TEST SET Metric Linear Regression K-nearest
neighbor Correlation
coefficient
0.6561 0.2632
MAE 626.7228 255.2615
RMSE 690.2703 533.4206
RAE 93.0456% 37.8971%
RRSE 96.7897% 74.7948%
Table V: Result Metrics for COCOMONASA data set with percentage split, 80% TRAING SET, 20% TEST
SET
Metric Linear Regression K-nearest neighbor Correlation
coefficient
0.906 0.2407
MAE 195.5552` 326.75
RMSE 271.0137 688.0383
RAE 54.0193% 90.26%
Table VI: Result Metrics for COCOMONASA_2 data set percentage split, 80% TRAING SET, 20% TEST SET Metric Linear Regression K-nearest
neighbor Correlation
coefficient
0 0.767
MAE 477.3743 340.1368
RMSE 525.9181 704.3981
RAE 100% 71.2516%
RRSE 100% 133.9368%
VI. CONCLUSIONANDFUTUREWORK We have analyzed the results of Linear regression and K-nearest neighbor's machine learning techniques in this work. We have applied these techniques on three publicly available datasets (COCOMO81, COCOMONASA, and COCOMONASA_2) for predicting software development effort. The model with the lower Root- Mean- Square- Error(RMSE), Relative- Absolute- Error (RAE), Relative- Root- Square- Error(RRSE), Mean- Absolute- Error (MAE), and the higher Correlation Coefficient (25) has been considered to be the best among others[21]. From the results what we have got and presented Linear Regression model is a good estimator compared to K-nearest neighbors on the data sets COCOMO81, COCOMONASA, COCOMONASA_2 by having higher correlation coefficient value and low RMSE, RAE, RRSE, MAE.
As a future direction, the regression learning algorithms like Decision Tree, Support Vector Machines, and Multi-layer Perceptron can be used to test the Effort Estimation with the existing datasets. Another future work can be Artificial Neural Network (ANN), Fuzzy Inference Systems (FNS) and Genetic Algorithms (GA) techniques for effort prediction.
Our work will benefit the Software developers in selecting the best models for effort prediction of software projects before they are developed, which intern helps the project planners.
REFERENCES
1. Ahmed BaniMustafa, Predicting Software Effort Estimation Using Machine Learning Techniques, https://www.researchgate.net /publication/331472905
2. Petrônio L. Braga and Adriano L. I. Oliveira, Silvio R. L. Meira , Software Effort Estimation using Machine Learning Techniques with Robust Confidence Intervals , eventh International Conference on Hybrid Intelligent Systems, 2007 IEEE.
3. Vlad-Sebastian Ionescu, An approach to software development effort estimation using machine learning, 2017 IEEE
4. Miyoung Shin and Amrit L. Goel, Empirical Data Modeling in Software Engineering Using Radial Basis Functions , IEEE TRANSACTIONS ON SOFTWARE ENGINEERING, VOL. 26, NO. 6, JUNE 2000. 5. Younghee Kim, Keumsuk Lee, A Comparison of Techniques for
Software Development Effort Estimating, SYSTEM INTEGRATION 2005.
6. Omar Hidmi and Betul Erdogdu Sakar, Software Development Effort Estimation Using Ensemble Machine Learning, Int'l Journal of Computing, Communications & Instrumentation Engg. (IJCCIE) Vol. 4, Issue 1 (2017) ISSN 2349-1469 EISSN 2349-1477.
7. Sonam Bhatia, Varinder Kaur Attri, Implementing Decision Tree for Software Development Effort Estimation of Software Project, International Journal of Innovative Research in Computer and Communication Engineering, Vol. 3, Issue 5, May 2015, ISSN(Online): 2320-9801 , ISSN (Print): 2320-9798
8. Mohd. Sadiq, Aleem Ali, Syed Uvaid Ullah, Shadab Khan, and Qamar Alam, Prediction of Software Project Effort Using Linear Regression Model, International Journal of Information and Electronics Engineering, Vol. 3, No. 3, May 2013.
9. Sonam Bhatia, Varinder Kaur Attri, MACHINE LEARNING TECHNIQUES IN SOFTWARE EFFORT ESTIMATION USING COCOMO DATASET, IJRDO - Journal of Computer Science and Engineering, Volume-1 | Issue-6 | June,2015 | Paper-13, ISSN: 2456-1843.
10. Abdelali Zakrani, Mustapha Hain, Abdelwahed Namir , Software Development Effort Estimation Using Random Forests: An Empirical Study and Evaluation , International Journal of Intelligent Engineering and Systems, Vol.11, No.6, 2018.
11. Simon WU Iok Kuan, FACTORS ON SOFTWARE EFFORT ESTIMATION, International Journal of Software Engineering & Applications (IJSEA), Vol.8, No.1, January 2017.
12. Amid Khatibi Bardsiri, Seyyed Mohsen Hashemi, Software Effort Estimation: A Survey of Well-known Approaches, International Journal of Computer Science Engineering (IJCSE), ISSN : 2319-7323, Vol. 3 No.01 Jan 2014.
13. Bilge Başkeleş, Burak Turhan, Ayşe Bener, Software Effort Estimation Using Machine Learning Methods, 2007 IEEE.
14. Carolyn Mair, Gada Kadoda, Martin Lefley, Keith Phalp, Chris Schofield ,Martin Shepperd, Steve Webster, An investigation of machine learning based prediction systems, The Journal of Systems and Software 53 (2000) 23-29.
15. Rekha Tripathi, Dr. P. K. Rai, Machine Learning Methods of Effort Estimation and It’s Performance Evaluation Criteria, IJCSMC, Vol. 6, Issue. 1, January 2017, pg.61 – 67, ISSN 2320–088X.
16. Pinkashia Sharma, Jaiteg Singh, Systematic Literature Review on Software Effort Estimation Using Machine Learning Approaches, International Conference on Next Generation Computing and Information Systems (ICNGCIS), 2017 IEEE.
17. Jyoti Shivhare, Santanu Ku. Rath, Software Effor t Estimation using Machine Learning Techniques , ISEC ’14 February 19 - 21 2014, ACM 978-1-4503-2776-3.
18. E.KARUNAKARAN, N.SREENATH, Survey on Software Effort Estimation Technique – A Review, International Journal of Scientific & Engineering Research, Volume 6, Issue 12, December-2015, ISSN 2229-5518.
19. Sidra Tariq, Muhammad Usman, Raymond Wong, Yan Zhuang, Simon Fong, On Learning Software Effort Estimation, 2015 3rd International Symposium on Computational and Business Intelligence, 2015 IEEE. 20. Jianfeng Wen , Shixian Li , Zhiyong Lin , Yong Hu , Changqin Huang,
Systematic literature review of machine learning based software development effort estimation models, Information and Software Technology 54 (2012) 41–59.
21. Prabhakar and Maitreyee Dutta, Application of machine learning techniques for predicting software effort, Elixir Comp. Sci. & Engg. 56 (2013) 13677-13682.
22. Kathleen Peters, Software Project Estimation, [email protected] or [email protected]
23. Nancy Sharma, Vineeta Bassi, Comparative Study of Software Effort Estimation Models, International Journal of Engineering Technology Science and Research, ISSN 2394 – 3386,Volume 5, Issue 5,May 2018. 24. Colin J. Burgess, Martin Lefley, Can genetic programming improve software effort estimation? A comparative evaluation, Information and Software Technology 43(2001) 863-873.
AUTHORSPROFILE
Bhaskar Marapelli is a Scholar at Sri JagadishPrasad
JhabarmalTibrewala University, Rajasthan, India. He has got a Bachelor's degree in Computer science and Information Technology (2005) from the Department of Information Technology Adams Engineering College of Jawaharlal Nehru Technological University, Hyderabad, India (JNTUH). He got Masters in Software Engineering (2009) from Auroras Engineering College of JNTUH. He has worked as Assistant Professor at the department of computer science Engineering Vidya Bharathi Institute of Technology (2010 –2014) affiliated to JNTUH. He has been working as Lecturer at Wolkite University, Ethiopia from November, 2014. He authored/co-authored research papers in reputed journals and conferences. His main research interests include Artificial Intelligence, Machine Learning, Software