International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-8, June, 2019
Abstract: Software defect prediction (SDP) is a challenging factor in the area of Computer Science. Software engineering is the fertile ground to each and every computer science project, which results the Computers the feature to develop the planning on an accurate job by means data. ML Machine based learning was enhanced by those implemented research on Pattern Identification with Computational intelligence based on Artificial Intelligence (AI)”. These (ML) Machine based knowledge tactics are boosted in resolving those faults which are occurring from validation in addition with Domain based systems. Those programming-based difficulties which are designated as the procedure-oriented knowledge with in those situations and alterations. A predictive model which is measured into two ways. First one is Defective Module and second one is Non-defective Module. The two predictive modules are formed by using (ML) Machine Learning techniques. Machine learning methods be cooperative in software defect prediction. For the existing data sets are collected from NASA and Eclipse from promise repository which is a motivated version of UCI repository which is developed in 2005. We have a lot of learning ways to notice defects in software. Here we are revisiting the ML methods for SDP (software defect prediction).
Index Terms: ML Techniques, Software defect prediction, Predictive analytics, Performance measures
I. INTRODUCTION
There are so many number of software products accomplished to meet up the requirements of the user. Due to increasing needs day to day software must meet the requirements of the user. By means of reliable Software Technologies, we can deliver the product without having any failure. The developed software has to be delivered to user to carry out the precious goods. SDLC (Software Development Life Cycle), has so many phases like requirements gathering, analysis, design, coding, testing and maintenance. among all those phases In SDLC maintenance plays a vital role, because the maintenance expenses are added in comparison with those enduring segments. The outgoings are demanding task to meet up the eminence manufactured goods. Within these Popular software development life cycle that concluding phase which may be called as the "Software Maintenance” is the considerable task. The important principle of SDLC is to renovate, construct high- quality
Revised Manuscript Received on June 08, 2019.
Y. Venkata RaghavaRao, Professor, Department of Computer Science and engineering,Professor in CSE , India.
Rama Devi Burri; Associate professor in I.T., Lakireddy Balireddy college of Engineering, Mylavaram, Krishna (Dt), A.P.,India.
V.B.V.N.Prasad, Professor, Department of Mathematics,Koneru Lakshmaiah Educational Foundation, Vaddeswaram, Guntur (Dt), A.P., India.
software applications. Due to increasing the number of products the Probability of having defective modules is also getting increased. The main task is to give defect free software to the People, to meet the expectations. The absolute testing of the complete arrangement may not be possible for each and every time due to proper lack of possessions and less time period issues. Our main aim is to deliver a defect free software to the customers, due to that we must deliver quality type of products. This type of flaw indicates kind of unforeseen performance of a system for given requests. In this kind of software based-testing the unpredicted presentation kept acknowledged and this components-based defect-detection packages specially treated as "Inadequacy" while developing software-based process indirectly producing unsuccessful-Software, in order to provide eye-catching prospective. the well-known recognition of programmatic defects is identified with the process the testing. The source segment in a well-organized approach in maintaining programming coders while getting better Architectures with high plan of design for classification of the important risk of the reputed-system. To overcome the essential technological complications, Artificial intelligence (AI) techniques can play a crucial role.The use of (AI) this kind of s Artificial intelligence-based practices with Software based engineering (AI&SE) consumes in generating optimistic grades, as a sub-field of Artificial intelligence, machine-based learning (ML) transactions with in these themes by putting collectively the supercomputer-based agendas are stepping forward to the construction at some task during acquaintance.The Relation Ship between Artificial Intelligence (AI) Techniques, Machine Learning (ML) and
Software Engineering (SE).
Fig1: Block diagram of proposed face recognition model
Machine learning Methods for
Software Defect Prediction a Revisit.
II. RELATION B/W (AI), (ML) AND (SE)
ML Methods are used for improving the information from unrelated perspectives and facilitate developers to get better constructive information. The techniques which will be utilized in tracing on programmatic blunders while gathering software-based datasets which are used for spot-out Machine based Learning practices.ML algorithms have been used in many diverse problems. Some typical applications are Data mining problems in these large databases contain significant inherent regularities that can be discovered robotically, programs must vigorously have converted with shifting circumstances. Machine based Learning can’t be treated always a solution for all the Software-based Engineering problems. To better use Machine based Learning approaches in working these tangible Software based Engineering complications, we need to have an unambiguous perceptive of the problems, the tools and methodologies utilized.
This manuscript will give details of the enhanced machine-based learning practices in making Software based Flaw Detection system with investigating a comparative performance study in Your ultimate plan.
2.2 Factor for failure of Software:
The most important features in making programmatic letdown are development thought-provoking factors and their response time are given below. According to Chaos Manifesto the following data is collected in the year 2013.The Project challenging Factors along with Responses Percentage is given.
1. Deficiency with properties -- 6.52% 2. Varying specifications with requirements -- 11.99% 3. Things which are unclear -- 5.42% 4. Specifications and requirements which are 12.3%
5. Deficiency with handler contributions -- 12.73% 6. Unsuitable decision-making Provisions -- 7.67% 7. Unreasonable Timing factors -- 4.23%
8. Expertise Insufficiency -- 7.31% 9. Innovative expertise -- 3.67% 10. Impracticable expectations -- 5.79% 11. Others -- 23%
III. RELATED WORK
If "Less Mann" projected a unique construction in programmatic Flaw Prophecy with categorization procedures with diverse based Data-sets. These provide a decent recognition of precision with spotting these categorizations of devices and metrics which are acknowledged. Area under curve (AUC) is useful for categorization investigations. Area under curve (AUC) signifies this unbiased indicator of prognostic accurateness is indicating the mainly useful in a perspective. Completely AUC is a main precision indicator, so it is suggestible to use AUC for software defect
prediction(SDP).
WEKA is discovered by Jain and Sharma for the classification of the decision tree algorithms. They both used
a definite method for understanding and developed process for WEKA tool in order to make use of the datasets. Software
metrics are used for defect prediction. Through different metrics we can achieve high rate of precision. In common in
of the modifications which are predicting on the Software Defects are limited in Performing comparative examination
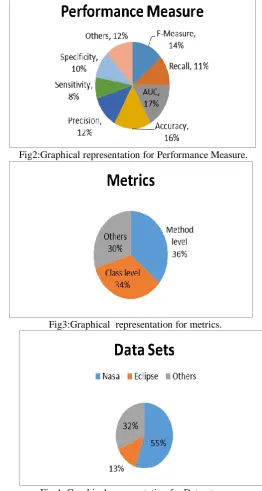
similar to machine learning methods, which provide about performance measures. Performance measure, Metrics and data sets which are used in Software defect Prediction.
Fig2:Graphical representation for Performance Measure.
[image:2.595.296.559.211.703.2]Fig3:Graphical representation for metrics.
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-8, June, 2019
Data set is the collection of information which is used in the particular field for the problem. Many practitioners propose different frameworks for different data sets.
In the above pie Chart Different data sets are considered for this paper.
The problem of unavailability of standard data sets has been widely faced by the practitioners of machine learning, So UCI repository help the developers. The PROMISE repository is the motivated version of the UCI repository which is developed in 2005. NASA data sets are used in software defect prediction.
Applicable Machine Learning methods for Software engineering responsibilities.
Various ML methods for Software engineering tasks are as below.
ML methods for (SRE) Software necessities-based engineering are AL, DT, BBN, ILP, LL. In making reverse engineering and test adequacy the machine learning technique is CL. In Rapid Prototyping the applicable machine learning technique is GP, Machine learning Technique for test generation and validation which are software engineering task is AL, for test adequacy we use CL , for cost and Effort prediction in software engineering we use BBN ,DT, IBL, ANN machine learning techniques. Component reuse and predicting defects are fulfilled by IBL, BBN machine learning techniques.
. T y p e Represe ntation of Target functio n Target function generatio n
Search Inductive Bias Sample Algorith m A L Hor n clauses Supervis ed, Eager, D +B, Deductive reasoning B + based unimportant established with Horn articles Prolog with-EB G B L Prob ability tables Bayesia n networ k Eager, supervise d, D (global), explicit or implicit Probabi listic, no explicit search Minimu m description length MAP, BOC, Gibbs, NBC C L Conjun ction of attribut e constrai nts Eager , supervise d, D (global) Variety Intergalact ic (VI) directed
c ∈ H Candidat e eliminati on D T Decisio n trees Eager, supervise d, D (global)
entropy Preferred for small trees ID3, C4.5, Assistant E L Indir ectly defined through ensemb Eager , D (global), supervise classificati on combinati on, Determined by ensemble members Ada Boost (for ensemble of DT) le of compon ent functio ns d, Ensem ble constructio n G A G P prog ram trees, Bit strings, unsup ervised ,Eager, no D. Hill climbing Fitness- driven Protot ypical algorith ms N N Wei ghts for neural networ ks Eager , supervise d, D (global) Gradie nt descent guided Smooth interpolatio n between data points Back propa gation I A L Dete rmined by underly ing learnin g method s Eager , D + B, supervise d Determ ined by underlying learning methods Determi ned by underlying learning methods KBANN, EBNN. FOCL S V M Decisio n functio n in inner product form D (local, support vectors), Eager, supervise d, Kernel mapping Maximal margin separator SMO
IV. MACHINE LEARNING TASKS IN SOFTWARE TOOLS: There are so many methods for software Defect prediction which are displayed in table as shown below. Techniques used for software defect prediction are
1.Stastical Algorithms 2. Machine based learning Set of rules. Here considering Algorithms of machine-based learning in predicting shortcomings with the help of software-based estimation.
As per the statistical algorithms applying regression, linear regression; Step wise regression, ordinary least square regression and multivariate Adaptive regression are present. In machine learning algorithms we have so many different types of algorithms. They are Bayesian algorithms, Decision tree algorithms, Clustering algorithms, Artificial Neural Networks and Ensemble learning algorithms [9].
In Bayesian Algorithms we have Bayesian network, Gaussian bayes, Multinomial Naive Bayes, and Augmented Naive Bayes.
Here we explained few of the above machine learning algorithms which are displayed in the above table.
V. SOFTWARE DEFECT PREDICTION BY MACHINE LEARNING TECHNIQUES
Decision trees have the fundamental mechanisms similar as decision-based nodes, branches and leaves. Decision-based building of trees are generally used in data structures, operations research and in machine learning also. The formation of algorithm contains 2 different phases. To keep away from the over fitting these two phases to be used. It Scale up the large data sets, to get the Target Function. For calculating conditional probability, we can use decision trees.
5.2 (ANN) Artificial Neural networks: Learning a “Target Function” in Artificial Neural networks (ANN) amounts to discover the weights for a known stable Network construction. Accepted out comes as precise with the so-called training data. Weights taking place with the help of vector which describes this targeting function. It computes this target-function very dense and aimed at individuals in understanding. ANN be situated Supervised, showing high Unbalanced-learning tactics for not including prior-facts. this prevalent algorithm in feed-forwarding networks with Back- propagation, this ubiquitous medhod adopting esteemed gradient-descent explorations, also authorizing an inductive bias of even interpolation between data points unchanging association structure, knowledge a target function in (ANN) neural network amounts to discovering weights.
5.3 Ensemble Learning: Ensemble learning can have some improved predictive Accuracy. By integrating all the multiple classifiers to construct-classification which is helping in improving the flaw-prediction presentation. The bagging is for cross-validation and boosting for constructing ensembles. Constructing ensembles, we can follow two approaches. One method is to merge constituent functions that are homogeneous.
Second method is to merge constituent functions that are heterogeneous. The application generally aims at developing the overall presentation in predicting these sets-of knowledge methods.
5.4 Random Forest:
The random forest learning method includes the regression and classification. These two regression and classification methods are operated by the production of a huge quantity of training these decision-based trees in generating these outputs as separate classes. The pruning procedure is used at each node of the decision tree.
5.5 (NB) Naïve Bayes Classifiers: The Naïve Bayes classifiers are used in Statistics and computer science engineering based on the conditional probability of the Bayes rule. This is a simple technique for classification; Naive Bayes-classifier used in analysing every attribute independently and assumes that all attributes are important and independent. This Classifier makes strong assumptions about each entering variable, which is more efficient and simple for huge amount of problem domains.
5.6 (SVM) Support Vector Machine: One of supervised learning models is the support vector machines, these support vector machines use a kernel function as an alternative of learning a nonlinear function. Kernel function plays very significant role in support vector machines. Support vector machines search for optimal linear hyper plane for division.
5.7 (RBF) Radial Basis Function Networks: mainly neural-network based applications, these components mainly using radial-biasing as predominant Activation-function. The RBF (radial basis functions) have plenty of uses in classification and time series prediction.
5.8 Waikato Environment for Knowledge Analysis tool: (WEKA) This tool is a collection of visualizing different algorithms and tools for analyzing data and for predictive modelling combining with GUI for easy adaption of functions, due to free availability and portable nature we can access easily and is fully implemented in java platform. since its GUI nature we can easily
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-8, June, 2019
VI. PERFORMANCE INDICATORS:
Performance indicators were measured from promise data sets. The Defect detectors are to be approximated by following mode. Precession and Recall are the performance indicators. The basis of precision and recall are Accuracy, Mean absolute error and F-measure. Defect detectors are able to be assessed according to following measures:
The entire number of accurately recognized errors Divided by the particular number of Errors is defined as the Accuracy Percentage. This can be considered in the Following Way:
ACC (Accuracy) = (w + z) / (w + x + y + z).
Detection recall for probability = z / (x + z).
false Alarm Probability = y / (w + y).
Precision = z / (y + z).
EFF (Effort = Quantity of code chosen with Detector = (y.LOC + z.LOC) / (Total LOC).
The Accuracy measure is recognized as Precision and this is the percentage among completely Classified Software Defects and authentic amount of Software defects which assign to Category. Precision is measured by means of the following method:
Percentage of Accuracy= (Perfectly Classified Software Defects/Total Software Bugs) *100
PRECISION = D / (C + D)
We can calculate the precision by using Machine Learning (ML) techniques, which the ability of searching the accuracy and exactness. By combing both Accuracy and Exactness is called precision.
The precision can be designed by using the method: = D/ (D + C).
Recall: Recall can be defined as the precisely classified Software defects and Software defects which belong to the particular group. The Precision and Recall can be bringing together to calculate the Performance Measure. The performance measure is indicated with F-Measure. F- Measure = (2 * (precision * recall)) / (Precision + recall).
VII. CONCLUSION
This paper was reviewed that we can able to Detect software defects by using different machine learning algorithms, like Bagging, (DT) Decision tree, Random
forest, K Nearest Neighbor, radial basis function kernel and K-means. By using machine learning techniques (ML), software engineering (SE) will be benefited.
REFERENCES
1. .B. Boehm, “Requirements that handle IKIWISI, COTS, and rapid change,” IEEEComputer, Vol. 33, No. 7, July 2000, pp.99-102. 2. Harry A, "machine learning capabilities, limitation and implications "
Technology Futures Researcher at Nesta 2015.
3. Martin S, David B, and T. H, "Researcher Bias: The Use of Machine Learning in Software Defect Prediction "Ieee Transactions On Software Engineering, vol. 40, pp. 603-616, JUNE 2014.
4. Yogesh S, Pradeep K, and O. S, "A Review of Studies On Machine Learning Techniques," International Journal of Computer Science and Security vol. 1, pp. 70-84.
5. T. M. Mitchell, "Machine Learning " 1997. 6.K. Srinivasan and D. Fisher, “Machine learning approaches to estimating software development effort,” IEEE Trans. SE, Vol. 21, No. 2, Feb. 1995, pp. 126-137.
6. T. Khoshgoftaar, E.B. Allen and J. Deng, Using regression trees to classify fault-prone software modules, ZEEE Transactions on Reliability, Vo1.51, No.4, 2002, pp.455-462.
7. C.J. Burgess and M. Lefley, Can genetic programming improve software effort estimation? A comparative evaluation, Information and Software Technology, Vo1.43, No.14, 2001, pp.863- 873
8. M. Liu, L. Miao, and D. Zhang, "Two-stage cost-sensitive learning for software defect prediction," IEEE Transactions on Reliability, vol. 63, pp. 676-686, 2014
9. .R. S. Wahono, "A systematic literature review of software defect prediction: Research trends, datasets, methods and frameworks," Journal of Software Engineering, vol. 1, pp. 1-16, 2015
10. .R. J. Vidmar. (1992, August). On the use of atmospheric plasmas as electromagnetic reflectors. IEEE Trans. Plasma Sci. [Online]. 21(3). pp. 876—880.Available:http://www.halcyon.com/pub/journals/21ps03-vid mar
AUTHORS PROFILE
Dr. Y. Venkata Raghav Rao has B. Tech in computer science and engineering from Nagarjuna University, M. Tech degree in CSE from JNTU and Ph.D. in computer science from JNTU, Hyderabad. He is working as professor in University. Rao research work was on distributed hyper ledger, IOT based fog computing, big data analytics. Rao has published more than 65 number of publications in various reputed journals and international conference proceedings and successfully supervised master’s students and supervising PhD students.
Dr Rama Devi Burri; is working as a Associate professor in, IT, LBRCE, published a good number of papers in international journals and conferences. her research work was on datamining, and advanced computing,
Dr V.B.V.N Prasad is a Professor in dept of Mathematics, Koneru Lakshmaiah Education Foundation. And published a good number of research papers in cse and mathematics areas. his research work was on machine learning, advanced computing,
Classifier Type res N
O
YE S predicts
no defects
NO w x
predictin g defects