Rochester Institute of Technology
RIT Scholar Works
Theses
Thesis/Dissertation Collections
1997
A Comparison of pattern classification techniques
for orienting chest X-rays
Martin R. Hoffmann
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion
in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact
Recommended Citation
Rochester Institute of Technology
Computer Science Department
A Comparison of Pattern Classification Techniques for
Orienting Chest X-rays
by
Martin R Hoffmann
A thesis, submitted to
The Faculty of the Computer Science Department,
in partial fulfillment of the requirements for the degree of
Master of Science in Computer Science.
Approved by:
Professor Peter Anderson
Dr. Roger Gaborski
Professor John Biles
Permission To Copy
Title of thesis: A Comparison ofPattem Classification Techniques for Orienting Chest X-rays
I, Martin
R.
Hoffmann, hereby grant permission to the Wallace Library of the Rochester
Institute of Technology to reproduce my thesis in whole or in part. Any reproduction will not be
for commercial use or profit.
Abstract
The
problemoforienting
digital images
ofchestx-rays,
which were captured at some multiple of90 degrees from
tli rtrue
orientation,
is
atypicalpattern classification problem.In this case, the
solutionto
theproblem must assignan
instance
of adigital
image
toone offour
classes,
where each class correspondstoone ofthefour
possibleorientations.
A
large
number oftechniquesareavailablefor
developing
a pattern classifier.Some
ofthese techniquesarecharacterized
by
independent
variableswhosevaluesaredifficult
torelateback
to theproblembeing
solved.If
atechnique
is
highly
sensitiveto thevalues ofthese variables,
thelack
of a rigorousway
ofdefining
themcanbe
asignificant
disadvantage
to
theinexperienced
researcher.This thesis
presents experimentsby
theauthortosolvethechestx-ray
orientation problemusing
four
different
patternclassification
techniques:
geneticprogramming,
an artificial neural networktrainedwithback
propagation,aprobabilisticneural
network,
and asimplelinear
classifier.In addition,
theauthor willdemonstrate
thatanunderstanding
ofthedesign
of afeature
setmay
allow aprogrammertodevelop
atraditionalprogram whichdoes
an adequatejob
ofsolving
theclassificationproblem.Comparisons
ofthedifferent
techniqueswillbe
based
notonly
ontheirsuccess atsolving
theproblem,
but
also onthe timerequiredtofind
an acceptable solution andthedegree
towhich eachtechniqueis
sensitiveto thevalues ofthevariables which characterizeit.
The
thesisdemonstrates
thatall ofthe techniquescanbe
usedtoderive very
accurate chestx-ray
orientationclassifiers.
While it
is dangerous
togeneralizetheresults oftheseexperimentstopattern classification problemsin
general,
theauthor will arguethatthemagnitude ofthedifferences
in
performancebetween
thedifferent
techniquesminimizesthis
danger.
In particular,
theexperiments suggestthat thelinear
classifieris
socomputationally
inexpensive
thatit
is
always worthtrying,
unlessthereis
a prioriknowledge
thatit
willfail.
The
experiments alsosuggestthatgenetic
programming
is
much morecomputationally
expensivethanarethelinear classifier,
artificialneuralnetwork,and probabilistic neural networktechniques.
Of
thefour
conventional pattern classificationtechniqueswhich wereexamined, it
willbe
shownthat theartificialneural network producedthemost accurate classifiers
for
thex-ray
orientation problem.In addition,
theresultsof anumber oftrialssuggestthat the
final accuracy
oftheclassifieris relatively
insensitive
to thevalues oftheparameters which characterizethis
technique,
making it
an appropriate choicefor
theinexperienced
researcher.With
respectto theability
oftheresulting
classifiertoaccurately
orient sample x-rays which were notincluded
in
the
training
set, theartificial neural network performedwell,when comparedto theothertechniques.Although
theclassifiers producedby
thegeneticprogramming
techniqueweresignificantly
more expensivetoconstruct and were
slightly
less
accuratethan thebest
artificialneuralnetworks, theresults of geneticprogramming
experiments can provide
insights into
theproblembeing
studied,which wouldbe difficult
todiscern from
theclassifiers produced
by
theothertechniques.For
example,oneoftheclassifiers which was producedby
geneticprogramming
usesonly
eightofthetwenty
feature
values extractedfrom
thesample x-ray.Not only
does
thisreducethecostof
extracting
thefeature
valuesfrom
an unknownsample,but
theclassifieritself
wouldbe
muchTable Of
Contents
1.
INTRODUCTION
1
2.
PATTERN CLASSIFICATION TECHNIQUES
3
2.1. Genetic
Programming
3
2.2. Artificial Neural
Network
30
2.3.
Probabilistic
Neural
Network
(PNN)
42
2.4.
Linear
Pattern Classifier
48
3. CHEST X-RAY FEATURE
EXTRACTION:
57
3.1. Common
Elements
Of The Two Feature Sets
59
3.2. Feature Set
F]
60
3.3.
Feature
Set
F2
61
3.4. The Feature Extraction Program
63
4. DESIGN OF
EXPERIMENTS
66
4.1. The Latin Square Technique
67
4.2.
Analysis
Of Variance
69
5. THE CHEST X-RAY ORIENTATION EXPERIMENTS
71
5.1. Genetic
Programming
Experiments
71
5.2. Artificial Neural Network Experiments
80
5.3. Probabilistic Neural Network Experiments
88
5.4. Linear Classifier Experiments
95
6. A TRADITIONAL PROGRAM FOR CHEST X-RAY ORIENTATION
97
7. CONCLUSIONS
99
7.1.
Accuracy
Of The Classifiers
99
7.2.
Validity
Of The Sample Data
100
7.3. The Cost Of
Developing
A Classifier
103
7.4.
Sensitivity
To Tunable Parameters
104
7.5.
Ideas For Further Research
104
A. ANALYSIS
OF CLASSIFIER PRODUCED BY GENETIC PROGRAMMING
106
B.
NEURAL NETWORK WEIGHTS
110
C. PROBABILISTIC NEURAL NETWORK EXEMPLARS
112
D. LINEAR CLASSIFIER MATRICES
121
1.
Introduction
In
ordertoinvestigate
theproblem of chestx-ray
orientation,
theauthorimplemented
classifiersusing
four
different
patternclassification
techniques:
geneticprogramming,
artificial neural networkstrainedwithback propagation,
probabilisticneural
networks,
and simplelinear
classifiers.In addition,
theauthor employedknowledge
usedin
thedesign
of a particularfeature
settodevelop
a moretraditionalprogram which could alsobe
used as a chestx-ray
orientationclassifier.
Each
oftheseclassifiers wasimplemented
using Sun
C++3.1,
and all oftheexperiments were executed on aSun
SPARCstation
10
with64 MBytes
ofRAM,
running Solaris
V2.3.
The
author obtained238
sample chestx-ray
images from
theEastman Kodak
Company
Research Labs. Each
sample was
repeatedly
rotated90 degrees
toproduce a sampleimage
in
each ofthefour
targetorientations,
resulting in
atotalof952
sampleimages.
The
original samples were45x55 pixel, 8-bit
gray-scaleimages. These
were cropped abouttheircenterstoproducesquare,
45x45
pixelimages.
Two
feature
sets were extractedfrom
the952
samplesimages,
tobe
usedin
training
and
evaluating
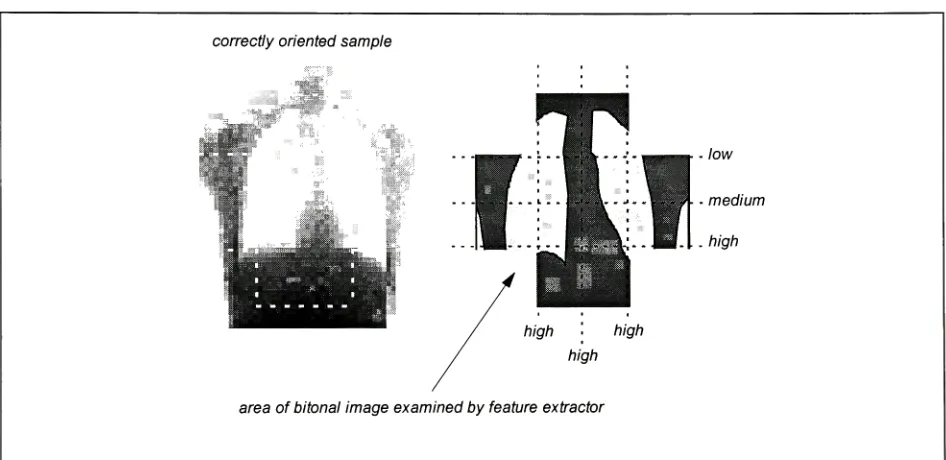
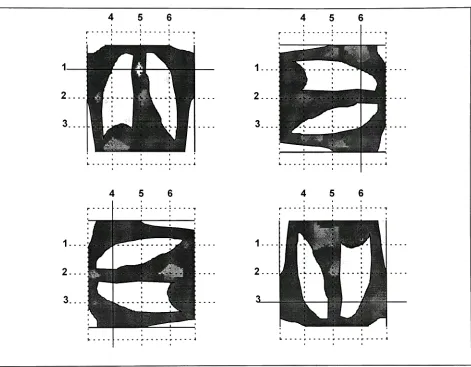
theperformance ofthevarioustechniques.The
simpler ofthe twofeature
sets wasderived
by
summing
pixel values across various pathsthrough theimage.
A
second more complex
feature
set wasdesigned
todetect
theorientation ofthedark
region which appearsbetween
the
lungs in
typicalchestx-ray images.
A
number of experiments were performedin
whicha classifier wastrainedusing
afraction
ofthesampleimages,
andtheoverall
accuracy
oftheresulting
classifier wasevaluatedusing
theremaining
samples.Care
wastaken toensurethat thesamples used
for
training
originatedfrom
adifferent
set oftheoriginal238
images
thandid
thesamplesused
for
evaluating
thefinal
classifier.Experiments using
thegeneticprogramming
and artificial neural networktechniquesrequiretheselection of valuesfor
a numberofdifferent
independent
variables whicharedifficult
torelateto theproblembeing
solved.The
authoremployedthe
Latin Squares
techniquetodevelop
a suiteof experiments whichtested theclassifiers against variousThis
paperis
organized asfollows.
Following
thisintroduction
are sections whichdescribe
each ofthefour
patternclassificationtechniqueswhich were usedtosolvethechest
x-ray
orientation problem.Each
ofthese sectionsbegins
by briefly describing
thetechnique,
and concludes with adescription
oftheauthor'simplementation
ofthetechniqueused
in
theexperiments.After
thesections whichdescribe
thepatternclassificationtechniquesis
a section whichdescribes
thesamplex-ray
images
usedin
theexperiments andthe twofeature
sets which were extractedfrom
theseimages. Subsequent
sections ofthepaper will
describe
theexperiments performed with each ofthefour
techniquesandtwofeature
sets,including
thesetup
oftheexperiments andtheresultsfrom
theseexperiments.Finally,
theauthordescribes his
attempttowrite atraditionalprogramfor orienting
thex-rays and offershis
2.
Pattern Classification Techniques
This
sectionofthepaperdescribes
thefour different
pattern classificationtechniqueswhich were usedtoorientthechestx-rays.
Each
description begins
with somebackground
aboutthe techniqueand ends withdetails
oftheimplementation
usedin
theexperimentsdescribed
in
thispaper.2.1.
Genetic
Programming
In
1975,
John Holland
publishedAdaptation
In Natural AndArtificial
Systems,
which showedhow
theevolutionary
process can
be
appliedtoproblemsin
adaptation.The
techniqueofGenetic Algorithms
wasdeveloped
as a meansof
using
evolutiontosolve such problems andis
thefoundation
upon whichtheGenetic
Programming
techniqueis
based.
2.1.1.
Genetic
Algorithms
With
thesimplestform
ofGenetic
Algorithm,
candidate solutionstoa problem are representedby
fixed-length
strings.
A
population of candidate solutions arerandomly
selectedfrom
theset of all possible solutions andtheindividuals
in
thepopulation are rankedaccording
totheirability
tosolvethe targetproblem.Based
ontheresultsobtained
for
this population,a new populationis drawn from
thesolution space and evaluated.This is
repeateduntil an acceptable solution
is found.
A
new population of candidate solutionsis
generatedfrom
theprevious populationby
applying
threedifferent
methodsof
breeding:
asexualreproduction, cross-over,and mutation.Asexual
reproductioninvolves
selecting
acandidate
from
thecurrent population andcopying it into
thenew population.Figure
1: Example
OfBreeding By
Asexual Reproduction
Candidate Solution A:
"Ax
A2 A3 A4 A5 A6 A7 A8
A9"New Candidate Solution A'
:
"A
A2
A3
A4 A5 A6 A7 A8
A9"(same as original)
Cross-over
is
done
by
selecting
twoindividuals from
theexisting
population andrandomly
selecting
a point whereFigure 2:
Example
OfBreeding By
Cross-Over
Candidate
Solution A:"Ax
A2 A3 A4
A5
A6 A7
A8
A9"Candidate
Solution
B:"Bi
B2
B3
B4 B5 B6 B7 B8
B9"Randomly
SelectedCross-Over
Position = 4New
Candidate
Solution A':
"Ax
A2 A3 B4 B5 B6 B7 B8
B9" NewCandidate
Solution B':
"Bx
B2 B3 A4 A5 A6 A7 A8
A9"Like
asexualreproduction,
mutationinvolves selecting
a singleindividual
from
thecurrent population andcopying
it
into
thenew population.With mutation,
however,
one characterin
thenewstring
is
randomly
selected andchangedtoa
different
value.Figure 3: Example
OfBreeding By
Mutation
Candidate Solution A:
"A
A2 A3 A4 A5 A6 A7 A8
A9''New Candidate Solution A'
:
"Ai A2 A3 A4 A5 A6 B7 A8
A9"While
mutation can preserve variationin
theresulting population, in
practiceit
seeslittle
use(Koza,
1992:105).
The
relativefrequencies
by
which asexualreproduction, cross-over,
and mutation are usedtogeneratethenewpopulation of candidate solutions aretunableparameters oftheapplication ofthealgorithm.
By
relating
thefitness
of a candidate solutionto theprobability
thatit is
selectedfor
breeding,
theGenetic
Algorithm
directs
thesearchfor
theoptimal solutiontothe targetproblem.Selection
is done
withreplacement,
sothat thesame solution
may be
selectedtoparticipatein
a number ofbreeding
operations.Holland
showedthat thegeneration ofthenewpopulation
using
these techniqueswasnearly
optimalin
minimizing
thecost associated withsampling
thesolution space(Holland,
1992:139).
2.1.2.
Genetic
Programming
John Koza
has developed
a variationonGenetic Algorithms
calledGenetic Programming. With Genetic
Programming,
solutionstothe targetproblem are representedby
programs ratherthansimple strings(actually,
In
his
book,
Genetic
Programming,
Koza
arguesthatrepresenting
candidatesolutions as parsetreesinstead
ofstrings
increases
the
expressive power ofthealgorithm,
withoutinvalidating
thework ofHolland.
Therefore,
he
concludesthat thealgorithm
described below is
a near optimal method ofsampling
a solution spaceconsisting
ofcandidateprograms
(Koza,
1992:116).
Each
node within a candidate parsetreerepresents aninput
orfunction.
Terminal
nodes areinputs
orfunctions
which require no arguments.
Non-terminal
nodes representfunctions
whichtakeone or more arguments.The
values ofthesearguments are
found
by
evaluating
child nodesin
the tree.Figure
4: Example
Of
A
Genetic
Programming
Parse Tree
In
ordertoensurethatrandomly
generated parsetreesand parsetreesresulting from
breeding
are always validprograms,
Genetic
Programming
requiresthat theprograminputs,
function
arguments,andfunction
return valuesbe
ofthesame
data
type.In
aGenetic
Programming
experiment,a population of programsis
randomly
generated.Each
member ofthepopulation
is
evaluated againsttestdata
andtheprogramsare ranked asto theirfitness
for solving
the targetproblem.
A
new populationis
generatedby breeding
individuals from
theprevious population.The
terminaland non-terminal nodes availablefor
program generationdepend
onthenature oftheproblembeing
solved,andare part ofthecharacterizationof a particular experiment.
The
fitness
measure usedtoassociate anumerical
rating
for
thesuitability
ofeach candidate programin
solving
the targetproblemis
alsodomain
specific.For
example,in
theexperiments conductedby
theauthor,
eachx-ray
was reducedto
a set of20
feature
values.The
plusonenode
for
each offour integer
constants:0, 1,2,
and3. The
set of non-terminal nodesincluded
addition, thegreater-than comparison
operator,
a conditional"if
operator,
andbitwise
AND, OR,
andNOT
operators.The
fitness
of a particular solution wasdetermine
by
evaluating
thecandidate programrepeatedly
againstthefeature
vectors associated with a
fixed
set of samplex-ray
images.
The
low
ordertwobits
oftheresultof an evaluation oftheprogram was usedtoselect
from
amongstthefour
possible orientation values.The
fitness
valueassignedto theprogram was
simply
thefraction
ofcorrectly
classifiedtraining
samples.2.1.3.
Creating
The Initial Population Of Programs
The
initial
population of candidate programsis
generatedrandomly using
thesets ofterminaland non-terminalnodes
defined for
theexperiment.Koza
describes
twomethods ofgenerating different
shaped parsetreesandthenrecommends a
hybrid
method called"ramped half-and-half
(Koza,
1992:91).
The
first
ofthe twobasic
parsetreegeneration methodsis
thefullmethod.Thefull
methodbegins
by
selecting
atarget
depth for
theparsetree.The
treeis
generatedfrom
thetop
down. When
a nodeis
neededas an argumenttoafunction in
thepreviouslevel
ofthetree,
a non-terminal nodeis
randomly selected, if
andonly if
thedepth
ofthecurrent
branch
ofthe treeis less
than the targetdepth. If
thedepth
ofthecurrentbranch is
equalto the targetdepth,
aterminalnode
is randomly
selected.Uniform
probabilities are usedfor
node selection.The
secondofthe twobasic
methods of parsetreegenerationis
thegrowmethod.With
thegrowmethod,only
themaximum
depth
of allbranches is
pre-defined.When
a nodeis
needed as an argumenttoafunction
in
thepreviouslevel
ofthe
treeandthe
depth
ofthe
currentbranch is less
than thetarget
maximumdepth,
thena nodeis
randomly
selected
from
eithertheset ofterminalornon-terminalnodes.This
meansthat thelengths
ofthedifferent branches
oftheparsetreecan vary.
Koza
suggeststhat theselection of nodes atintermediate levels
ofthe treebe
madeuniformly from
theunion ofthesets ofterminaland non-terminal nodes
(Koza,
1992:92). In
practice, thisleads
toratheruninteresting
parsetreeswhen
the
number ofterminalnodesis
significantly
greaterthan thenumber of non-terminal nodes.Figure 6: A
Parse
Tree Generated
By
The
"Grow"Method
Fi
F2
Fi
T,
/
/ s\
\
T3
Ti
Fi
F3
T2
T,
The depthof eachbranchcanbe different (max depth is
5)
The
rampedhalf-and-half
methodis
ahybrid
ofthese twomethods of parsetreegeneration.With
thismethod,
half
ofthe
initial
populationof parsetreesis
generatedusing
thefull
methodandtheotherhalf is
generatedusing the
growmethod.
The
minimumtargetdepth
usedtogenerateany
treeis
two.The
maximumtargetdepth is
atunableparameter
typically
around six(Koza,
1992:1 16). The
same numberof parsetreesare generatedfor
eachtargetDuring
thegenerationoftheinitial
population ofprograms,
duplicate
parsetreesare eliminatedby
replacing
one ofthe treeswith a newtreewiththesamecharacteristics.
Because
theprogramsdo
notinteract
withoneanother, thereis
noadvantagetohaving
duplicate
programsin
theinitial
population of aGenetic
Programming
experiment.After
thefirst
generation of programsis
created,
theprograms are evaluated againsttestdata
andare assignedfitness
values whichdefine
their
relative success atsolving
the targetproblem.Subsequent
generations of programsare created
by
breeding
individuals
from
thecurrent generation.2.1.4.
Creating
Subsequent Generations Of Programs
As
withthegeneralGenetic
Algorithm,
breeding
is done
by
asexualreproduction, cross-over,and mutation.In
thiscase,
cross-overis
performedby
randomly selecting
a nodein
each oftheparent programs.The
sub-trees rooted atthese twonodes arethenswappedtogeneratetwoprograms
for
thenewpopulation(see Figure 7).
The
mutation operation(which is rarely
used and was not usedin
theexperimentsdescribed in
thispaper)
is
performed
by
pruning
arandomly
selected sub-tree of a selected program andreplacing it
withanotherrandomly
generated sub-tree.
In
additiontoasexualreproduction, cross-over,and mutationKoza
describes
threemethods ofgenerating
newprograms
from
anexisting
populationof programs(Koza,
1992:107-1 12). Although described
below,
thesemethods were not employed
by
theauthorin his
experiments.A
permutationoperationgenerates a new programby
randomly re-ordering
theargumentstoone ofthefunctions in
an
existing
parsetree.The editing
operationmodifies anexisting
parsetreeby
recursively applying
a set ofdomain
independent
andoptionally domain dependent editing
rules.Koza
gives an example of adomain independent
editing
rule asfollows:
"If
any function
thathas
no side effects andis
not contextdependent has only
constant atoms asarguments, the
editing
operationwill evaluatethefunction
and replaceit
withthevalue obtainedfrom
theevaluation"(Koza, 1992:108)
The
final
method ofgenerating
new programsis
encapsulation.With
encapsulation,arandomly
selected sub-treeof a
randomly
selected candidate programis
wrappedby
a newprimitive,whichthenreplacesthesub-treein
theoriginal program.
The
new primitiveis
like
a subroutine.If
mutationis
being
usedtobreed
programs,
thenewFigure 7:
Example
Of
Cross-Over In
Genetic
Programming
Parent A
withParent B
withrandomly
selectedrandomly
selectedcross-over point
A5
cross-over pointB4
Ai
Bi
rA>^
,-<>-,A2
A3
B2
B3
X<T
r-O^n
A4
A5
Ag
B4
B5
>>>_,
A7
B6
B7
r-^P-n
Ag
Ag
Offspring
A'Offspring
B'A,
B,
rA>^
r^T^
A2
A3
B2
B3
Kt,
r-4NnA4
B4
Ae
A5
B5
r_Z^n
B6
B7
A7
>>_
Ag
Ag
As
withGenetic
Algorithms,
therelativefrequencies
with whichthedifferent
breeding
methods are employedin
generating
a new population of programs aretunableparameters.Programs
are selectedfor
breeding
with afrequency
whichis
proportionalto theirrelativefitness
atsolving
thetargetproblem.
The
same program canbe
selectedtoparticipatein
multiplebreeding
operations,
andbecause
asexual reproduction
is
also usedduring
breeding,
thesame program can appearmorethanoncein
thenewIn
his
book,
Koza
describes
othertechniques
which are usefulfor
improving
therate at which aGenetic
Programming
experimentconvergestoa solution.The
author ofthispaperincluded
twoofthese techniquesin
his
implementation: decimation
andgreedy
over-selection.Because
thegeneration oftheinitial
populationof programsis
almostpurely random,
therearelikely
tobe
alarge
number of candidate programs
in
thisfirst
generation withextremely
poorfitness
ratings.Decimation
providesafast way
ofeliminating
thepoorestcandidateprograms,
by
simply removing
afixed
number ofthemfrom
theinitial
population,
before
breeding
begins.
Even
afteremploying decimation
to trim theinitial
population of anexperiment,
thenumber of programs whichremain
may be
quitelarge.
The probability
thateventhefittest
candidate programis
selectedfor
breeding
may
be
relatively
small.Greedy
over-selectionis
a method whichincreases
theprobability
that theprograms which arebetter
candidate solutions are selectedfor
breeding.
With greedy
over-selection, theprogramsfrom
thecurrent population aredivided
into
twogroups.The
first group
containsthe
fittest
individuals
whichcollectively
accountfor
sometotalfraction
of overallfitness
ofthepopulation.The
secondgroup
contains all oftheother programs.When
a program needstobe
selectedfor
breeding,
agroup
is
randomly
selected andthena programis
randomly
selectedfrom
amongstthecandidate programsin
thegroup.The
probabilities ofselecting between
the twogroups are skewedtogreatly favor
thegroup
of programs whichcontainsthe
fittest individuals. Once
agroup is selected,
a programis
selectedbased
ontherelativefitness
oftheprograms withinthegroup.
Koza's
rules ofthumbarethat thefirst
group is
selected80%
ofthe timeandthat thefraction
oftotalfitness
whichdetermines
thedivision
of programsbetween
the twogroupsdepends
onthe totalnumber of programs as
follows
(Koza,
1992:99):
Table 1: Koza's Allocation
Of
Programs For
Greedy
Over-Selection
Number
Of Programs
Fraction Of Total Fitness From
Group-1 Programs
1,000
32%
2,000
16%
4,000
8%
2.1.5.
Characteristics
Of A Genetic
Programming
Experiment
With
theinclusion
ofdecimation
andgreedy
over-selection,
theset oftunableparameters associated with a geneticprogramming
experimentincludes:
Table
2: Tunable
Parameters
For
Genetic
Programming
Experiments
Terminal
Set
(the
set of programinputs
which can appear as parsetreeleaves)
Function
Set
(the
set offunctions
which can appear as nodesin
theparsetrees)
Fitness
Measure
(a
method ofassigning
a numericrating
to thefitness
of aprogram)
Population
Size
(number
of programsin
theinitial
population)
Maximum
Number Of
Generations (number
ofiterations
during
theexperiment)
Maximum Depth Of Parse Tree In Initial Population
Maximum Allowable Depth Of Parse Tree
During
Experiment
Probability
Of Cross-Over
Probability
Of Asexual Reproduction
Probability
Of Mutation
Probability
Of Permutation
Probability
Of Edit
Probability
Of Encapsulation
Probability
Of
Selecting
Leaf Node
During
Cross-Over
Fraction Of Programs Discarded
By
Decimation
Step
Fraction Of Overall Fitness Allocated To
Greedy
Over-Selection Group-I
Probability
Of
Selecting
Program From
Greedy
Over-Selection Group-I
Koza
claimsthat theaccuracy
oftheGenetic
Programming
algorithmis
relatively
insensitive
tomany
ofthesevariablesand
he
typically
usesthesameset of valuesfor
mostofhisexperiments(Koza,
1992:1 14). In
theexperiments
described
later,
theauthor variesa small number oftheseparameterstoevaluatethesensitivity
ofthechest
x-ray
orientationproblemto thesevalues.2.1.6.
Implementing
The
Genetic
Programming
Simulator
The implementation
oftheGenetic
Programming
algorithmby
Koza
wasdone
using
LISP,
because
oftherelativeease with which
individual programs,
stored ass-expressions,couldbe
manipulated.To
performtheGenetic
Programming
experimentsdescribed
in
this paper, theauthordeveloped
areasonably flexible
implementation
ofthealgorithm
using
the C++programming language.
[image:16.555.49.513.122.445.2]Unlike
LISP,
C++is
astrongly
typedlanguage.
To
maketheGenetic
Programming
environmentasflexible
aspossible,
theclassesdescribed
below
arein
generalimplemented
astemplate classes,
parameterizedby
the typeofdata
associated withtheprograminputs,
function
arguments,
andfunction
return values ofthegenerated parsetrees(there is
onedata
typefor
all ofthese).
For clarity
in
thedescriptions
whichfollow,
theauthor willforego
the C++templatenotation
in
referencestoclass names afterthefirst
(e.g.,
Node<T>andNode
willbe
usedtoreferto thesameclass).
The
mostbasic
of classesin
thedesign
is
theNode<T>class.Node
is
an abstractbase
classfor
allterminalandnon-terminal nodes which can appear
in
a parsetree.Derived
classes areimplemented for
eachtypeof nonterminalnodeto
be included
in
theexperiment,
and a singleclass,
TerminalNode<T>,is
usedtorepresenttheleaf
nodes oftheparsetrees.
Each
derived
classimplements
a small number of memberfunctions
which characterizethe typeofoperationperformed
by
thisclass of node.These
functions
include
thefollowing
functions
which aredeclared
pure virtualin
Node:
int
args(void);
Returns
thenumber of arguments required asinput
to thisnode.TerminalNode
implements
thisfunction
toreturn zero.The
integer
add nodedescribed later
returnsthevalue2,
because it
requirestwoinputs:
theleft
and right addends.const char"name
(void);
Returns
a shortdescriptive
namefor
theclassofnode,whichis
used when a parsetreeis
displayed
totheuser.Node
*gnu
(void);
Returns
a newinstance
ofthesame exact class asthereceiverofthegnu(
)
call.This
is
usedto generate new nodes of a particular class at runtime.In
theauthor's originaldesign for
thesimulator,
eachderivative
Node
alsoimplemented
a virtualfunction,
eval(
),
which obtainedthenode's
inputs from
its
childnodesin
theparsetreeand combinedtheseinputs
toproducetheresult
for
thenode.For
example:int
IntAdd::eval(void)
{
return
(
child[0]
->eval(
)
+ child[1]
->eval(
)
)
;The
inputs
to theprogram were storedin
anarray,
and eachinstance
ofTerminalNode
was assigned anindex
into
thearray.
The implementation
ofeval(
)
in
TerminalNode simply
returnedtheappropriate element oftheinput
array.
Because
oftherecursive callsto eval(
)
in
its
implementation
by
non-terminalnodes,
an entire parsetreecouldbe
evaluated
by
calling
eval(
)
againsttheroot node ofthe tree.While
theauthorbelieves
this tobe
goodobject-oriented
design,
theevaluation of a parsetree thenrequires a number of virtualfunction
calls,equaltothenumberof nodes
in
theparsetree.Virtual
function
calls arerelatively
expensive when comparedto theexecution ofaswitch
statement,
upon which a parsetreeinterpreter
mightbe implemented.
In
fact,
througha separateexperiment,theauthor estimatedthata virtual
function
call oftheform
shown above requires abouttwiceas muchCPU
timeastheexecution of a switch statement
(in
theenvironmentin
whichtheexperiments were conducted).In
ordertoavoidintroducing
an unfairbias
againsttheGenetic
Programming
technique,
theauthorimplemented
adifferent
approachtoprogram evaluation.In
thisapproach,
a4-byte
codeis
associated with each class of nonterminalnode and each unique
input
value.For
non-terminalnodes,thehigh-order bit
ofthecodeis
settodistinguish
thecodefrom
thatof aterminalnode.For
terminal nodes, thisbit is
not set andthecodeis
equalto thenode's
index
into
theinput
array.Through
aprocess,which willbe
referredtoasflattening,
a parsetreeis
compiledinto
a onedimensional
array
ofthese
byte
codes.Flattening
is
accomplishedby
calling
a virtualflatten( )
function
againsttheroot node ofthe tree.This
function is
passeda pointertoanarray
and a referencetoanindex
variable which pointsto thenext writableposition
in
thearray.Each
node respondstoflatten( ) by
calling
flatten( )
against eachchild,andthenpushing
thebyte
code which correspondsto thenodeitself,
ontotheend ofthearray:void IntAdd: :flatten (unsigned
int
*array,
unsignedint
&index)
{
child[l]->flatten
(array,
index);
child[0]->flatten
(array,
index);
array
[index++]
=IntAdd_Byte_Code;
}
In
ordertodetermine
thesize ofthearray
requiredtohold
theflattened
version of a particular parsetree,
Node
alsoimplements
a virtualfunction
toreturnthenumberofbytes
requiredtoflatten
thesub-tree rooted at a node.The
default implementation
ofthisfunction,
in
classNode,
is
sufficientfor
mostderived
classes.That
implementation
simply
callsthe
function
recursively
against each child(summing
the
results)
andthenaddsone,
toaccountfor
the
byte-code
ofthe nodeitself.
Thus,
theflattening
process requirestwocallstovirtualfunctions for
each nodein
theparsetree.Fortunately,
theflattened
parsetreewillbe
evaluated alarge
number oftimes, resulting
in
a net savings ofCPU
time(in
each oftheGenetic
Programming
experimentsdescribed later
in
thispaper,
theoriginalimplementation
ofthesimulatorwastestedand was
found
tobe
atleast
twiceas slow asthisnewversion,
whose results are usedfor
comparison withtheotherclassification
techniques).
To
evaluatetheflattened
parsetree,
aStack<T>classis
neededtohold intermediate
results.The
stack provides anMined
memberfunction
topush a value onto thestack,
and anotherinlined function
which popsthestackandreturnsthevalue
just
removed.Starting
with anempty
stack, theevaluatorfunction
iterates
through thearray
ofbyte-codes.
If
thecurrentbyte-code
is
thatof aterminalnode,
then thecorresponding
valuefrom
theinput
array
is
pushed onto thestack.
Otherwise,
aninlined eval(
)
function
is
called againsttheclass ofNode
indicated
by
thebyte-code.
This eval(
)
function
popstherequired argumentsfrom
thestack,
computestheresult ofthe operation,and pushestheresult ontothestack.
After
thelast
element ofthearray
has
been processed,
thestack contains asingle element which correspondsto theprogram result.
int
evaluateByteCodes (unsignedint
*array,
unsignedint
num_codes){
static Stack<int> s; s.clear
(
)
;for
(int
i=0;
i<num_codes;
i++)
switch
(array[i])
{
case IntAdd_Byte_Code: IntAdd: :eval
(s)
;break;
default: s.push( TerminalNode<int>inputs
[array
[i] ]
)
;}
return s.pop
(
)
;inline
void IntAdd::eval (Stack<int>&s)
{
s.push
(
s.pop()
+ s.pop()
);
This design
has
thedisadvantage
thatahard-coded
switch statement mustbe formulated in
theimplementation
ofthe
design becomes
even moreobfuscated,
withtheintroduction
ofthe
"conditional if
operation as atypeof nonterminalnode.
The
if-operator
acceptsthreearguments.If the
first
argumentevaluatestoa non-zerovalue,
then theoperation returns
its
second argument.Otherwise,
theoperation returnsits
thirdargument(thus
theif-operator
is
equivalentto the C++
"?
:"operator).
This
operation couldbe implemented
asfollows:
inline
void Intlf: : eval (Stack<int>&s)
{
int
argl =s.pop(
)
int
arg2 =s.pop(
)
int
arg3 =s.pop(
)
}
return
(argl
? arg2 : arg3) ;But
thisdesign
is
horribly
inefficient,
since allthreearguments areevaluated,eventhoughonly
one ofthesecondandthird
is
actually
needed(in
theauthor'sexperiments, thereis
no chance of side-effectsbeing
introduced
by
theevaluation of asub-tree,sotheevaluation need not
be
done
atall,if
theresultis
not used).In
ordertopreventtheunnecessary
evaluation of unusedresults,away
is
neededtodelay
theevaluationofthelatter
twoargumentsto theif-operator
until adecision
is
made astowhich willbe
evaluatedand which willbe ignored.
The
author's solutionis
similartoone whichhe
later discovered
wasdescribed
by
Keith
andMartin
(Keith,
1994:294).
First,
a newbyte-code
called a"skip"codeis
introduced,
whichis
composed of anidentifying
flag
and anarray index
value which representstheelementtowhichtheevaluator should proceed next.This
newskip
codeis
usedin
theimplementation
offlatten for
theclassIntlf.
void Intlf::
flatten
(unsigned
int
*array,
unsignedint
&index)
{
childfO]->flatten
(array,
index);
//
encode 1starg
array
[index++]
=IntIf_Byte_Code;
//
add self tobyte-code
array
unsigned
int
save =index++;
//
leave
room for "goto"child
[1]
->flatten(array,
index);
//
encode 2ndarg
array[save] =
SkipFlag
|
(index+1);
//
"goto"points past 2nd
arg
save =index++;
//
leave
roomfor
2nd "goto"child[2]->flatten
(array,
index);
//
encode 3rdarg
array
[save]
=SkipFlag
|
index;
//
"goto"points past 3rd
arg
}
The
flattened
versionofan7?7/"operation
requirestwoadditionalslotsfor
theskip
codes.This
is
themain reasonthat the
function
whichdetermines
thenumber ofarray
elements requiredby
aflattened
parsetreemustbe
a virtualfunction. Unlike
otherNode eval(
) functions,
the
implementation
ofeval(
)
for
Intlf
does
not push a result valueontothestack.
Instead,
it
adjuststheindex
whichis
being
usedtowalkthrough thearray
ofbyte-codes
during
program evaluation:
inline
void Intlf: :eval (Stack<int>&s,
int
&i)
{
if
(
s.pop()
)
i++;
}
This
function
popsthestacktoretrievethefirst
argumentto theif-operator.
If
thisargumentis
zero,
then theeval(
)
function does
nothing.The
nextbyte-code
processed willbe
askip
code which causestheevaluatortojump
pastthe
byte-codes
associated withtheif-operator's second argumentto thestart ofbyte-codes
associated withtheif-operator'
sthirdargument.
Subsequently,
whenthatsection ofthebyte-code
array
has
been
processed, thevaluecorresponding
to the thirdargument will reside atthetop
ofthe stack,asif it had been
returnedby
theif-operator.
However,
if
thefirst
argumentto theif-operator is
non-zero,
then theeval(
)
function increments
theindex
being
used
by
theevaluator,
sothatit
will misstheskip
code.At
thispoint,
thesecond argumentto theif-operator
willbe
evaluated and pushed ontothestack.
The
byte-code
whichimmediately
follows
theflattened
second argumenttothe
if-operator
is
anotherskip code,
which causestheevaluatortoskip
pastthe thirdargument,
whichdoes
not needto
be
evaluated.Thus,
in
eithercase, only
one ofthesecond andthirdargumentsto theif-operator
willbe
evaluated.
In
additionto theoverrides ofthepure virtualfunctions
of classNode
andthememberfunctions
relatedtoprogramevaluation,
eachderived
class which representsa non-terminal nodeimplements
a special constructor whichis
usedonly once,
toregistertheclass of non-terminal nodein
a static registry.The
contents ofthisregistry
determines
which
Node derivatives
willbe
created and usedduring
theGenetic
Programming
experiment.A
single staticinstance
oftheclassis
constructedusing
this constructor, toaccomplishtheregistration.Here
is
an example oftheconst unsigned
int
IntAdd_Byte_Code
=NonTerminalFlag
|
0x00000001;
class
IntAdd
: public Node<int>{
private:
static
IntAdd
a;//
staticinstance
used to register class IntAdd(NodeType
t)
:Node<int>(t)
{
}
//
for registrationpublic:
static void eval (Stack<int>
&s)
{
s.push
(
s.pop()
+ s.pop()
);
}
int
args(void)
{
return2;
}
const char *name
(void)
{
return"+";
}
Node<int>
*gnu
(void)
{
return new IntAdd(instance)
;}
unsigned
int
byte_code(void)
{
returnIntAdd_Byte_Code;
}
void
flatten
(unsignedint
*array,
unsignedint
Sindex)
{
child
[1]
->flatten(array,
index);
child
[0]
->flatten(array,
index);
array
[index++]
=IntAdd_Byte_Code;
}
};
IntAdd IntAdd: :
instance
(NONTERMINAL);
When
theobject modulefor IntAdd is linked
into
anexecutable,
thestaticinstance
oftheclassis
automatically
registeredat application startup.
Registration
involves storing
a pointerto theinstance in
a staticarray
of pointersmaintained
by
theNode
class.At
runtime,
a class of non-terminal nodeis randomly
selectedby
choosing
aninstance
from
thisarray.A
newnode ofthisclassis
producedby
calling
thegnu(
)
function
againstthatinstance.
The
registrationofterminalnodesis handled
alittle
differently,
because
thereis
only
oneC++classtorepresentallofthe terminalnodes
in
theexperiment.At
applicationstartup,a globalfunction
namednumberOflnputs(
)
is
calledto
determine
thenumber of uniqueterminalnodes.This
function
mustbe
providedby
theexperimenter.The
valuereturned
by
thisfunction
is
usedtocreatethecorrect numberofinstances
ofTerminalNode
(one
perinput).
These
instances
are storedin
another staticarray
ofNode
pointers associated withthebase
class.At
runtime,
when a newterminalnode
is
needed,
one oftheinstances
maintainedby
theNode
classis
selected at random and clonedusing
the
gnu(
)
function implemented in TerminalNode.
Each
instance
ofTerminalNode
maintains anindex into
a staticarray
ofinput
values(the
sizeofthisarray
is
alsoequalto thevaluereturned
by
numberOflnputs(
)).
When
aTerminalNode is
created viagnu(
),
the
index
valueis
copiedsothat thenew node points
to
thesameinput
value.During
therun, the array
ofinput
valuesis loaded
appropriately before
a programis
evaluated.The
Node
base
class maintainsinformation
aboutthenode's place withinits
parsetree.This information includes:
A
pointerto thenode's parentin
theparsetreeAn array
of pointersto thenode's childrenin
theparsetreeThe
maximumdepth
ofany
sub-tree rooted atthisnodeThe
number of non-terminaldescendants
ofthisnodeThe
numberofterminaldescendants
ofthisnodeThis
information
is
usedduring
theconstruction andbreeding
of parsetrees througha number ofhelper functions
onthe
Node
class(these functions
describe
thecharacteristics ofthesub-tree rooted atthenode and can returnspecific elements ofthatsub-tree givena depth-
first
numericindex into
thesub-tree).The
class which usesthesemember
functions
is
theclass whoseinstances
representtheindividual
parsetreesin
theexperiment, Program<T>.
Each
Program
storesa pointerto theroot nodeoftheparsetreeit
represents.The
first
timeaProgram
is
askedtoevaluate
itself,
it
createstheflattened
versionoftheparsetreeby
calling
theflatten(
)
function
againsttheroot nodeofthe tree.
The Program
thencallstheglobalfunction,
evaluateByteCodes(
),
which wasdescribed
earlier.The
flattened
versionoftheparsetreeis
notdiscarded
untiltheProgram
is
deleted.
Thus,
it
canbe
evaluated multipletimes.
In
additiontostoring
a pointertotheparsetreeandthebyte-code
array, Program
maintains a number of otherdata
members
including
data
membersfor:
thenumberoftimestheprogram
has been
run(i.e.,
evaluated).thenumber of
hits
scoredby
theprogram(a
"hit"is
scored eachtime theprogram returns anexactly
correctresult andis
usefulif
somenon-zeroamount ofthefitness
measureis
awardedfor
answers which are
"close but
not exact").the
probability
that thisprogram shouldbe
selectedfor breeding.
thenumber oftimes theprogram
has
actually
been
selectedfor
breeding
a
description
ofhow
theprogram was produced(e.g.,
from
cross-over)
withdata
toidentify
theparent
program(s)
which werebred
toproducethisprogramMuch
ofthisdata is
simply
gatheredfor
measuring
statistics oftheexperiment,
althoughthefitness
measureis
usedtocomputetheselection
probability
andtheselectionprobability
is
usedduring breeding
toselect programs atfrequencies
which are proportionalto theirfitness
atsolving
the targetproblem.The Program
class providesthreemethodsfor creating
a new program.During
thecreation ofthefirst
generationof programs within an
experiment,
a public constructor ofProgramis
usedtocreate new programsby
eitherthe"full"
or"grow"methods
described
earlier.Subsequently,
acopy
constructoris
providedfor
asexual reproductionand a
breed( )
methodis
implemented
for
cross-over(mutation is
also supported via amutate(
)
method, but
theauthor
has
nottested this).Both
the"full"and "grow"methods of
generating
atreefrom
scratch areimplemented
by
Program
via recursivecallsto
its
generateTree(
)
memberfunction. This function is
passed an enumerated valuetodistinguish
themethodof generation and a pair of values which representtheminimum and maximum
depths
allowedfor
thegeneratedtree.
The generateTree(
)
function randomly
selectsatargetdepth, d,
for
thenewtree,
suchthatd
lies
in
therangebetween
thespecified minimum and maximum allowable.The
C++run-timelibrary
function
erand48(
)
is
usedfor
this and all other situations
in
which random numbers are needed.Separate
random number streams are usedfor
each
decision,
by
maintaining
multipleseed arrays.The
"full"method oftreegeneration
is implemented
asfollows:
if
(
d
is
less
than or equal to one)
{
return a new,
randomly
selected, terminal node}
else
{
create a new,
randomly
selected, non-terminal node nfor each argument required
by
n, generate a new sub-treeby
calling
generateTree(
)
recursively, with minimum and maximumdepth
parametersboth
equal to(d
-1)
(and
usingthe "full"
method)
attach these arguments
(i.e.,
sub-trees) to node n and return n.}
This
algorithm resultsin
atreein
whichthedepth
ofeachbranch
extending
from
therootis
exactly
equalto thedepth
selectedin
theoriginal calltogenerateTree(
).
Program
implements
the"grow"method oftreegeneration
slightly
differently
thanasdescribed
by
Koza. In
thisimplementation,
therewill alwaysbe
exactly
onebranch
which reachesthe targetmaximum
depth for
the tree.The generateTree(
)
methodimplements
"grow"as
follows:
if
(
d
is
less
than or equal to one)
{
return a new,
randomly
selected, terminal node}
else
{
create a new, randomly selected, non-terminal node n
randomly
select one of the arguments to n and create a sub-tree forit
by
calling
generateTree(
)
recursively, with minimum and maximum depths set to(d
-1)
(and
using
the "grow" method)create the other arguments to n
by
calling
generateTree(
)
recursively with a minimum depth parameter of 1 and a maximum depth of
(d-l)
(again,
the "grow"method
is
usedin
these recursive calls).attach these arguments to node n and return n.
}
This
algorithm alsodiffers from
thatdescribed
by
Koza
in
that thedepths
ofthevariousbranches
ofthe treesareindependent
oftherelativedifference
in
thenumberof classes of non-terminalnodes andthenumber ofdifferent
inputs
(i.e.,
terminalnodes).Thus
thegeneratedtreeswill notbe artificially
flattened
whenthenumber ofinputs
is
The
"full"and"grow"methods are
only
usedtogeneratetheinitial,
random population of programs evaluated aspart ofthe
first
generation oftheGenetic
Programming
experiments.Later
generations of programs are createdby
breeding
programsfrom
theprevious generation.The
twomethodsofbreeding
employedin
theexperimentsby
theauthor are
implemented
viathecopy
constructor oftheProgram
class andProgram's
breed(
)
method.The copy
constructoris
usedfor
asexualreproductionof aProgram
during
breeding.
The
countsfor
numberofruns,
hits,
andcumulativefitness
are preservedin
thenewProgram,
but
otherdata
members,like
theprobability
ofselection
for
breeding
andthenumber oftimes theprogram was selected are not copiedfrom
theexisting
Program,
because
thesedata
members willdepend
ontheresultsfound
in evaluating
theother programsin
thenewgeneration.
As
anoptimization,
thefitness
of a program produced via asexual reproductionis
not recomputedfor
thenewgenerationof programs.
Such
evaluation wouldbe
a waste oftime,
sinceit is
assumedthat thefitness
ofa particularprogram
is independent
of generationin
whichit
appears.Obviously,
thissame optimization cannotbe
appliedtoprograms produced
by
cross-over,
sincetheresulting
programs will almostcertainly be different
than theirparentprograms.
Cross-over
is implemented in
thebreed( )
method of classProgram. The
methodis
passed a pointertoanotherprogram
(which
serves asthesecond parentin
thecross-over)
andit
returnsthe twoprograms which resultfrom
thecross-over.
Cross-over
is
implemented
asfollows:
1
.Use
thecopy
constructor ofProgram
toproducetwonew programs which areidentical
in
structureto the twoparent programs
involved
in
thecross-over.2.
Randomly
selecta nodefrom
each ofthe twoparsetreesasthecross-over points.3.
Swap
thesub-trees rootedatthese twonodesby
extracting
eachfrom its
current parsetreeandinserting
it in
theother parsetree.Even if both
oftheparent programswerein fact
the
sameinstance
of classProgram,
theabove algorithmworks,
because
thechildren arefirst
producedby
cloning,
before
thecross-over occurs.One
situation whichdoes
requirespecial
handling
is
when one orboth
ofthecross-over pointsaretheroot nodes ofthechild programs.In
thiscase,
an entire program
is
being
replacedandthepointerstoredto therootnodein
theProgram
object mustbe
updated.The
selection ofa cross-over pointis
atwostep
process.First,
adecision is
madeastowhetherthecross-over pointshould
be
aterminalor non-terminal node.The
probability
ofselecting
aterminalnodein
thisstep
is
atunableparameter.
Next
therootNode
is
askedfor
thenumber of nodes oftheselectedtypewhichexistin
the treerooted at thatnode.An
index
toone ofthesenodesis
randomly
generated andtherootNode
is
askedtoreturna pointertothenode which correspondsto this
index,
given adepth first ordering
ofterminalor non-terminal nodes.The
nodewhich
is
returnedbecomes
thecross-over point.The
twoProgram
constructors andthebreed( )
memberfunction
eachimplement
a singlestep
in
theprocess ofgenerating
a population oftestprograms.These
steps mustbe
repeated an appropriate number oftimestoproduce thecomplete population.The responsibility for generating
andevaluating
a population of programsfalls
to theGeneration<T> class.
A
Generation
maintains a collection ofProgram
objects.The
class providestwoconstructorsfor
creating
newgenerations,
a methodtoevaluateall of programsin
the generation,and a methodtosaveinformation
aboutthegenerationtoa
file. This information includes
theprogramsthemselves,
as wellas some performancestatistics,which will
be described
shortly.The
classGeneration
providestwoconstructors.The first
constructoris
thevoidconstructor,whichis
usedtocreatethe
first
generation of programsfor
an experiment.This
constructorimplements
the"ramped
half-and-half
method of program generation
described
earlier,using
the"full"and "grow"methods of parse-tree generation
implemented
by
Program.
The
secondGeneration
constructoris
passeda pointertoanexisting
generation.This
is
not acopy
constructor.Instead,
a new generationis
producedby breeding
theprogramsfrom
thespecified generation.The
programsin
theexisting
generation mustalready have
been
evaluated and sortedaccording
to theirrelativefitness. In addition,
theprobability
of selectionfor
breeding
mustalready
have
been
computedfor
each program and a cumulative valuefor
thisprobability
storedin
eachoftheprograms.Breeding
proceedsasfollows:
1.
A
method ofbreeding
is
selectedat random.The
frequency
with which each ofthemethodsis
selected
is
atunableparameteroftheexperiment.2.
If
theselected methodis
cross-over, then twoprogramsfrom
theprevious generation are selectedselected
for
breeding
is
proportionaltoits
relativefitness
withintheprevious generation ofprograms.
Selection
is done "with
replacement".3.
The
new programis
produced(two
programsin
thecase ofcross-over)
by
calling
theappropriatemethod ofthe
Program
class.4.
Steps
1
through3
are repeated until a complete population of programsis
generated.Currently,
only two
methods ofbreeding
are supportedby
theclassGeneration:
cross-overand asexualreproduction.
A
methodis
selectedby
comparing
a random numberin
therange0.0
to1
.0withthe targetprobability for
cross-over.If
thisrandom numberis less
than theprobability
ofcross-over,
then themethod selectedis
cross-over.The
algorithmtoselect programs with appropriate selectionfrequencies is
implemented
asfollows:
a randomnumber
is
generatedin
therange0.0
to1.0. The
sorted collection of programs are searchedin
order ofdecreasing
fitness,
until a programis found
whosecumulativeprobability
of selection exceedstherandom number.This
program
is
selected.Greedy
over-selectionis implemented
during
theassignment of selectionprobabilities,
sothedivision
oftheprogramsinto
twogroups,
asdescribed for
thattechnique, is implicit
in
theselection algorithmdescribed here.
Once
theentire populationof programshas
been created,
theGeneration
canbe
evaluatedby
calling
its
eval(
)
method.
Although
theprocess ofevaluating
thefitness
of each programin
thegenerationis implemented
in
agenericway,
it depends
on callstoa number offunctions
which are externalto theclassGeneration
and areprovided
by
theexperimenterto tailor thealgorithmtotheproblembeing
studied.These
functions include:
int
numberOflnputs(void)
This
function,
which was mentionedearlier,
defines
thenumber ofdifferent
terminalnodestobe
registeredat application startup.
int
numberOjTests(void)
The
evaluation ofa programis broken
down
into
one or more"tests".
At
thestart of atest,
the experimenteris
askedtoload
thearray
ofterminalnode values withinputs
appropriateto thenext test.Then,
theexperimenteris
askedtoevaluate each programin
thepopulation,
one at atime,
and assign afitness
valueto theprogramfor
this test.The function numberOfTests(
)
is
calledtodetermine
thenumber ofdifferent
testswhich willbe
performed.This
number mustbe independent
ofthegenerationbeing
evaluated,
because
programs produced
by
asexual reproduction are not reevaluated.In
theexperimentsdescribed in
thispaper,
a"test"consistsofevaluating
each program againstthefeature
setextractedfrom
a singlesamplex-ray image.
The
number oftestsis
thereforeequaltothenumber of
training
samples.The
author'sGenetic
Programming
framework
actually
evaluatestheentire population ofprograms against
only
a subset ofthetests
indicated
by
numberOfTests( ).
Then,
after a selectionprobability
has
been
assignedtoeachprogram,
theremaining
testsare usedtoevaluatethe"best
of
generation"
program.
Since
theselatter
testsnever affecttheselectionof programsfor
breeding,
they
serve as a good measure ofthesuccess ofthealgorithm atfinding
a solution whichis
general enoughtowork well withintheproblem space representedby
the testsamples.void
loadlnputs
(void)
This
function is
called atthebeginning
ofeachtest,
topreparethearray
ofterminalnode valuesfor
thestart ofthenexttest.In
theexperimentsby
the author, theset ofinputs
wasexactly
equalto the
feature
values extractedfrom
a single samplex-ray (in
one ofits
orientations),
plus someconstants.
The
implementation
ofloadlnputs
would populatetheinput
array
with valuesfor
asingle
training
sample.The
number of callstoloadInputs( )
for
each generationis
equalto thenumber returnedby
numberOfTests( ). The
version ofloadInputs( )
implemented
by
theauthorautomatically
restartsatthe
beginning
ofthecollection oftraining
samples,
afterthefeatures
for
thelast
training
samplehave been loaded.
The function correctly
presumesthat thisrestartoccursonly
when a newGeneration
begins
evaluating
its
programs.void evalProgram(Program<T>
*program,
double &
fitness,
int
&hits,
...)The Generation
class callsevalProgram(
)
toobtain afitness
valuefor
a specified programduring
thecurrenttest.
The
fitness
values ofa single program are summed over alltests toproducetheprogram'scumulative
fitness,
whichis
a measure oftheprogram's success atsolving
the targetproblem.
In
its
simplestform,
evaluating
a programduring
atestinvolves
calling
theeval(
)
function
oftheProgram
andusing
thereturn valuetoassign afitness
valueto theprogramfor
this test.Koza
givesexamples wheretheevaluation of a program
for
a singletestmay
involve
multiple callstoits
eval(
)
method,
whereeach evaluationis
usedtoadjuststheinput
array
before
thenext call(Koza,
1992:147).
In
thesecases,
thefitness
measureis
ofteninversely
proportionalto thenumber oftimes theprogramneedsto
be
evaluatedtosatisfy
someterminationcondition.This
kind
oftestcanbe
implemented using
thisauthor'sframework,
providedthat theevalProgram(
)
function
restorestheinput
array
toits
original statebefore
returning.double
adjustFitness(double
fitness)
This
function is
called onceper program afterit has
been
evaluated against alltests.The
fitness
valuepassedto this
function is
thecumulativefitness
oftheprogramdetermined
overthecourseofthetests.
The
experimenter canimplement
Because
programs producedby
asexualreproductionare notreevaluated,andtheircumulativefitness is
notreadjusted,
theadjustment performedby
thisfunction
mustbe
independent
ofboth
thecharacteristicsofthecurrentgeneration andtheprograms
it
contains.This
restrictionseverely
limits
what canbe done
by
thisfunction,
andin
practice,
theauthorfound
no needtomodify
thecumulative
fitness
values.double
perfectScore(void)
This
function
returnstheadjustedfitness
valuethatwouldbe
achievedby
a program whichperformed
perfectly
during
all ofthe tests.One
ofthestopping
criteriafor
theexperimentis
finding
a program whose adjustedfitness
equalsperfectScore(
).
int
evaluateByteCodes(unsigned int
*array,
unsignedint numcodes)
This
is
theinterpreter function
described
earlier.The
actual returntypedepends
onthe typeofdata
associated withtheprograminputs
and return values.The
first
argumentis
anarray
containing
aflattened
parsetree.The
second argumenti