M
ASTER
T
HESIS
Improve the Active Subspace
Method by Partitioning the
Parameter Space
Author:
Cheng XUE
Supervisor:
A/Prof. Barry C
ROKEProf. Steve R
OBERTSA thesis submitted in fulfilment of the requirements
for the degree of Master of Mathematical Science (Advanced)
in the
“In the broad light of day mathematicians check their equations and their proofs, leaving no stone unturned in their search for rigour. But, at night, under the full moon, they dream, they float among the stars and wonder at the miracle of the heav-ens. They are inspired. Without dreams there is no art, no mathematics, no life. ”
AUSTRALIAN NATIONAL UNIVERSITY
Abstract
Mathematical Science Institute
Master of Mathematical Science (Advanced)
Improve the Active Subspace Method by Partitioning the Parameter Space
by Cheng XUE
Contents
Abstract iii
1 Introduction 1
2 Literature Review 3
2.1 Active Subspace . . . 3
2.1.1 Finding the Active Subspace . . . 7
2.1.2 Subspace Error Analysis . . . 12
2.1.3 Response Surface . . . 31
2.2 Gaussian Process . . . 34
2.3 Voronoi region . . . 36
2.4 KD trees . . . 38
3 Methods 41 3.1 Randomly Selected Points . . . 44
3.1.1 Regression using allN∗ points . . . 44
3.1.2 Regression using limited number of points . . . 46
3.1.3 Approximating gradients by Gaussian process . . . 47
3.2 Adaptively Selected Points. . . 49
3.2.1 Regression using allN∗ points . . . 50
3.2.2 Approximating gradients by Gaussian process . . . 50
3.3 Example for f(x1,x2) =10 sinx1+7 sin2x2 . . . 51
3.3.1 Random . . . 51
3.3.2 Adaptive (on squared error) . . . 53
3.4 Similar Methods . . . 55
3.4.1 Regression Trees . . . 55
3.5 Testing . . . 56
3.6 Active subspace python package . . . 56
3.7 Conclusion . . . 56
4.1.1 Rosenbrock - 2 dimensional . . . 58
4.1.2 Rosenbrock - 7 dimensional . . . 60
4.2 Robot Function . . . 63
4.3 OTL-circuit Function . . . 65
4.4 Computation Time Comparison . . . 72
4.5 Conclusion . . . 77
5 Discussion 79
6 Conclusion 83
Chapter 1
Introduction
along the coordinate directions; therefore, they only rank the importance of different parameters. For functions where the strongest variation direction is not one of the coordinate directions, the variation direction problem can be viewed as discovering the possible dependence of the outputs on a manifold in a lower dimensional input space. If such a subspace can be found, one will be able to construct a response surface by drawing samples from the active subspace alone rather than from the whole parameter space.
Chapter 2
Literature Review
2.1
Active Subspace
Subspace dependence is investigated by various researchers. Many works investigate the subspace dependence for functions with multivariate output or ODE systems (Grimme,1997; Bai,2002). Some works explore subspace de-pendence locally to construct a manifold with a lower dimension that main-tains local relationships to represent the original data (Donoho and Grimes,
In 2010, Russi introduced an iterative algorithm to search the active sub-space for a real-valued function f with input vector x s.t. x ∈ Rd and pro-vided applications to construct a response surface using regression techniques (Russi, 2010). In 2014, Constantine et al. developed a similar method and provided the theoretical foundation for gradient-based dimensionality re-duction and subspace approximation by constructing and decomposing an uncentred gradient covariance matrix. However, the number of samples that are needed to form the subspace with sufficient accuracy remains unknown. (Constantine and Gleich,2014) address this issue by first defining the mean-ing of accuracy as the difference of the matrix norm between the true active subspace and the numerically approximated active subspace. Then, by deriv-ing a lower bound on the number of gradient samples needed for a required accuracy and considering that the gradient samples are approximated by a finite difference, they recommend choosingαklog(m)samples, whereα is a multiplier between 2 and 10,k is the dimension of the active subspace, and
mis the dimension of the input parameter space. They also apply bootstrap to the finite difference gradients and find that, with a sufficiently small inter-valh, the estimated subspace is a good approximation of the true subspace. We know that approximating a gradient using the finite difference method requiresm+1 function runs, wheremis the input dimension. This presents challenges for the active subspace method in higher dimensions because one needs to calculateC = M1 ∑iM=0∇f(xi)∇f(xi)T and decompose it to find its eigen-pairs, where M is the number of gradients to be evaluated. This re-quires M(m+1) function runs. (Constantine, Eftekhari, and Wakin, 2015) propose an approach to reduce the number of function evaluations to con-struct the eigen-pairs forC. They consider the directional derivativeaT∇f(x)
measurement of the gradient vector. This requires only two function runs for each entry. Thus, forkdirections, we have k+1 function evaluations. In total, M(k+1) function evaluations provide the approximated eigenvectors that previously required M(m+1) function runs. By defining a ridge func-tion f : Rm →Randx∈ Rm, we have f(x) = g(ATx), whereA∈ Rm×n and
g :Rn →R. This suggests that f is invariant along the directions that are or-thogonal toA’s columns. For instance, letuasATu =0 andy ∈Rm =x+u; then, we have f(y) = g(AT(x+u)) = g(AT(x)) = f(x). (Constantine, Rosario, and Iaccarino, 2016) show that many physical laws can be repre-sented as ridge functions. This indicates that the active subspace may exist in many physical models, and hence, the active subspace method could be effective. (Constantine et al.,2017) exploit this result by proposing an itera-tive heuristic algorithm to construct the optimal subspaceA∗ for expensive computational models with several input parameters. They use the condi-tional average of the function value given the active subspace coordinates as the ridge approximation function. Then, they define the heuristic optimisa-tion problem as min12||f(x)−µ(ATx,A)||2 subject toA ∈ G(n,m), whereµ is the ridge approximation function andG(n,m)is the Grassmann manifold – the space of n-dimensional subspaces ofRm. They find that the active sub-space solution is a near-stationary point to the optimisation problem. Hence, using the active subspace solution as the initial subspace for the optimisation problem accelerates the convergence.
The active subspace method has been successful in various fields. From an engineering prospective, the active subspace method is applied in aerospace shape optimisation (Lukaczyk and Constantine, 2014), automotive design (Othmer et al.,2016), dimensionality reduction in single-diode solar cell mod-els (Constantine, Zaharatos, and Campanelli,2015) and air-foil shape parametri-sation (Grey and Constantine,2017). For uncertainty quantification, studies are performed for multi-physics scram-jet models (Constantine et al., 2015) and for combustion models (Bauerheim et al.,2016).
Specifically, MCMC is widely used in inverse problems (Kaipio and Somer-salo,2005), but its efficiency is questionable when the dimension of the pa-rameter space is large because MCMC needs to explore a high-dimensional parameter space to find regions corresponding to high probability. (Cui et al., 2014) propose a method to decrease the MC’s state space by finding a low-dimensional likelihood-informed subspace. Given the Gaussian prior and posterior and second-differentiable forward model, their method is im-plemented by first calculating the negative log-likelihood Hessian over the parameter space with respect to the posterior distribution and then apply-ing eigenvalue decomposition to the Hessian. The space of the orthogonal complement of the eigenvectors is informed by the prior. (Constantine, Kent, and Bui-Thanh, 2016)’s method extends this idea by identifying the active low-dimensional parameter subspace and sampling from the subspace us-ing only the prior of inactive variables. Because their method may introduce bias, they provide an error bound on the Hellinger distance between the true posterior and its approximation.
Recently, the active subspace method has also been applied in sensitivity analyses such as in integrated hydrologic models (Jefferson et al.,2015), global spatial sensitivity analysis in subsurface flow permeability (Gilbert et al.,
2016), time-dependent sensitivity analysis for lithium-ion battery models (Con-stantine and Doostan,2017), sensitivity analysis for Ebola virus populations based on the SEIR model (Diaz, Constantine, and Kalmbach,2018), and sensi-tivity analysis of photosynthesis and stomatal resistance parameters in a land surface model (Jefferson, 2017). (Constantine and Safety, 2017) propose a new global sensitivity metric from the active subspace perspective and name the metric the activity score. This metric is defined asαi =αi(n) = ∑nj=1λjw2i,j fori =1, ...,m, wherenis the dimension of the active subspace to be used,m
square of wi,j removes the directional information because the magnitude rather than the direction is measured here. The idea is to sum all the rel-ative changes in the parameter i along all the active directions consider-ing their importance. There are a number of sensitivity metrics, such as variance-based total sensitivity indices (Sobol,2001), derivative-based sensi-tivity measurements (Sobol and Kucherenko,2009), and least-squares-fit lin-ear model coefficients (Saltelli et al.,2008), in practice. This metric can be con-sidered as a truncation of (Sobol and Kucherenko,2009)’s derivative-based metric, which is defined for the ith parameter as vi =
R
(∂f ∂xi(x))
2
ρ(x)dx, where ρ(x) can be considered to be some probability density function de-fined on the input space. Thus, vi is essentially a global sensitivity metric that averages the local sensitivity information across the input parameter space. If the input dimension is sufficiently low, one may use quadrature methods to accurately find the estimated value of vi. Otherwise, one may use the Monte Carlo method to drawMsamples independently according to
ρ(x)and providevi ≈vˆi = M1 ∑Mj=1(
∂f ∂xi(x))
2. The activity score
αiis bounded above by the derivative-based metricvi (Constantine and Safety,2017). Re-call that for identifying the active subspace, one needs to decompose the ma-trixC =R
∇f(x)f(x)Tρ(x)dx. Denote the derivative-based metric vector as v = [v1, ...,vm]T, where vis simply the diagonal of the matrix C. BecauseC can be written as the eigenvalue decomposition C = WΛWT, we can write
vi as vi = ∑mj=1λjw2i,j, where wi,j is the ith row and jth column element of W. This provides the inequality vi = ∑mj=1λjw2i,j ≥ αi(n) = ∑nj=1λjw2i,j. The equality holds whenn = m; in other words, one uses all input dimen-sions. Therefore, the activity score can be considered as a truncation of the derivative-based metric.
2.1.1
Finding the Active Subspace
Russi (2010) denotes a projection matrixSof shapem×nand an approxima-tion funcapproxima-tion of f and gs.t. f :Rm →Randg: Rn →R, where
f(x)≈ g(STx), (2.1)
m is the dimension of the parameter space, and n is the dimension of the corresponding active subspace. Note that this formulation suggests that f(x)
is nearly a ridge function.
By assuming that f ∈ C1and f(x) = g(STx), by the chain rule, we have
∇xf(x) =∇xg(STx)·ST. (2.2)
Then, assuming that we have N samples drawn using Latin hypercube sample design across all the input parameters, we define the matricesFand Gs.t. F =
∇xf(x1) ∇xf(x2)
.. .
∇xf(xN)
,G=
∇xg(STx1) ∇xg(STx2)
.. .
∇xg(STxN)
(2.3) We have
F =GST. (2.4)
If one adds gradients to F iteratively, the rank of F generally increases. Until the rank of the matrix stops increasing, i.e., the matrix F’s row space contains the gradient space, one can apply singular value decomposition (SVD) toFand obtain
F =UΣVT (2.5)
= "
U1
U2
# "
Σ11 0
0 Σ22
# "
VT1 VT2
#
The value ofΣ22represents the variation-inactive directions which in other
words have small values. Note that if Σ22 = 0, the function is a perfectly
ridge function. Therefore, if we ignore the variation in inactive directions, we have
F=U1Σ11VT1. (2.6)
By equation 2.4, we can treatU1Σ11 =G, and we haveST =VT1.
Note that this process can be interpreted as applying PCA to the gradient space of the function f.
The dimensions of U1 and VT1 are determined by the largest gap of the
the singular values are 10, 9.5, 9, 0.5, 0.2, and 0.1, we would have an active subspace of 3 dimensions because the first 3 directions account for most of the variation.
(Constantine, Dow, and Wang,2014) propose a similar method and pro-vide a more comprehensive theoretical background.
Start by defining a matrixC,
C =
Z
(∇xf)(∇xf)Tρ(x)dx, (2.7)
whereρ: Rm →R+is a probability density function. Practically, they recom-mend choosing a uniform distribution or normal distribution because these two distributions generally reflect the available information and are easy to work with.
Each element of the matrixCcan be viewed as the average of the product of partial derivatives, assuming that they exist:
Ci,j =
Z
(∂f
∂xi
)(∂f
∂xj
)ρ(x)dx. (2.8)
Note that the covariance between random variablesXiandXjis
Cov(Xi,Xj) =
Z
xi
Z
xj
(xi−µxi)(xj−µxj)p(xi,xj)dxidxj, (2.9)
whereµxi = E(Xi),µxj = E(Xj).
LettingX ∈ Rm, the covariance matrix can be defined as
Cov(X) =
Cov(X1,X1) Cov(X1,X2) ... Cov(X1,Xm)
Cov(X2,X1) Cov(X2,X2) ... Cov(X2,Xm) ..
. ... ... ...
Cov(Xm,X1) Cov(Xm,X2) ... Cov(Xm,Xm)
(2.10)
Thus, following the same logic, if one considers∇xf as a random vector,
the matrix C can be interpreted as an uncentred covariance matrix of the random vector∇xf.
vTCv=
Z
vT(∇xf)(∇xf)Tvρ(x)dx (2.11)
=
Z
(vT(∇xf))2ρ(x)dx≥0.
Additionally, C is clearly symmetric; thus, C permits an eigenvalue de-composition with non-negative real eigenvalues.
Therefore, we have
C =WΛWT,Λ =diag(λ1, ...,λm),λ1≥... ≥λn ≥0, (2.12)
whereWis anm×morthogonal matrix.
Because W’s columns [w1, ...,wm] are the normalised eigenvectors of C, we have
Cwi =λiwi wTi Cwi =λiwTi wi
Z
wiT(∇xf)(∇xf)Twiρ(x)dx=λi
Z
(wTi (∇xf))2ρ(x)dx=λi.
(2.13)
This shows that the mean squared directional derivative along the eigen-vector direction wi is small if the corresponding eigenvalue is small. For example, if λi is zero, we can say that the function is invariant along the corresponding eigenvector direction. Because we arrange the eigenvalues in decreasing order, we can partition the matricesWandΛas
W= [W1W2], (2.14)
Λ=
"
Λ1
Λ2
#
, (2.15)
where Λ1 is a diagonal matrix that contains the largest n eigenvalues, and hence,W1contains the corresponding eigenvectors.
Now, we can define
z=WT2x,z ∈Rm−n. (2.17)
Thus, for anyx ∈Rm, we have
x =WWTx=W1W1Tx+W2WT2x=W1y+W2z, (2.18)
and by the chain rule, we have
∇yf(x) = ∇yf(W1y+W2z) =WT1∇xf(x). (2.19)
Therefore, one can show that the average inner product of gradient of f
w.r.t. yandzwith itself is
Z
(∇yf)T(∇yf)ρ(x)dx= Z
trace((∇yf)(∇yf)T)ρ(x)dx
=trace Z
W1T∇xf(x)f(x)TW1ρ(x)dx
=trace(W1TCW1) =trace(Λ1)
=λ1+...+λn.
(2.20)
Similar toz, we haveλn+1+...+λm.
Let λn+1+...+λm =0, one can imagine standing on the surface of f. If they were to look at the surface from the direction of the column space ofW2, they would find that the surface is flat.
This leads to the definitions of the active subspace as the column space of W1and the inactive subspace as the column space ofW2. The active variable is thereforey, andzis the inactive variable.
In practice, finding the active subspace is challenging because one needs to solve anm-dimensional integration problem to obtain the matrixC. How-ever, deterministic numerical integration methods are inefficient when m is large. Thus, a straightforward and easy-to-implement random sampling ap-proach is used here instead. In other words, we approximateC by Cˆ, such that
ˆ C= 1
M
M
∑
i=1
where Mis the number of samplesxi that are drawn independently from ρ, and∇xfi =∇xf(xi). Note that this can be viewed as an application of Monte Carlo integration.
By decomposingCˆ, we obtain the approximated eigenvaluesΛˆ and eigen-vector matrixWˆ :
ˆ
C=W ˆˆ ΛWˆ T (2.22)
ˆ
Λ =diag(λˆ1..., ˆλm).
2.1.2
Subspace Error Analysis
Because the Monte Carlo method is used to approximate the high-dimensional integral (equation 2.21) and because the gradients may need to be approxi-mated using finite difference methods in practice, the estiapproxi-mated active sub-space is generally different from the true active subsub-space. In this section, we restate the theorems used to derive the error bound between the true ac-tive subspace and the estimated acac-tive subspace. Because the proofs from the book (Constantine,2015) are primarily for seasoned researchers and ad-vanced graduate students in applied mathematics, statistics, and engineer-ing, we provide a more detailed version of the proofs, together with our comments, for students who are not yet familiar with the content.
Note that comparing the error between the true active subspace and the estimated active subspace can be seen as finding the distance between the range ofW1 and the range of the estimated Wˆ 1; in other words, we need to find an error bound fordist(ran(W1),ran(Wˆ 1)). Recall thatW1andWˆ 1 con-sist ofn eigenvectors (ranked by corresponding eigenvalues from largest to smallest) of the matrixC(equation 2.12) andCˆ (equation 2.21); it is thus nat-ural to start the comparison between the eigenvalues ofC, λ1,λ2, ...,λm and the eigenvalues ofCˆ, ˆλ1, ˆλ2, ..., ˆλm. As a standard procedure, (Constantine,
2015) apply work on the spectrum of sums of random matrices (Gittens and Tropp,2011). Note that the error bound for the perturbed matrix and eigen-values can also be found in the bookMatrix Computationsby Gene H. Golub and Charles F. Van Loan.
eigenvalue and the largest eigenvalue, respectively. In addition, all the vec-tor norms are Euclidean norms, and all matrix norms are induced by the Euclidean norm, in other words, the spectral norm. We have the following:
Theorem 1(Spectrum of sums of random matrices theory (Gittens and Tropp,
2011)). Consider a finite sequence{Xj}of independent, random, symmetric
matri-ces with dimension m, all of which satisfying the subexponential moment growth condition
EhXjpi p!
2 B p−2Σ2
j, for p=2, 3, 4, . . . , (2.23)
where B is a positive constant andΣ2j are positive-semi-definite matrices. Given an integer k≤m, set
µk =λk(
∑
j E
Xj
). (2.24)
ChooseV+as an orthogonal matrix of size m×m−k+1that satisfies
µk =λmax(
∑
j
VT+E
Xj
V+), (2.25)
and define
σk2=λmax(
∑
j
VT+Σ2jV+). (2.26)
Then, for any t≥0,
P
"
λk(
∑
j
Xj) ≥µk+t
#
≤(m−k+1)exp{−1
4t 2/σ2
k}, for t≤σk2/B, (2.27)
and
P
"
λk(
∑
j
Xj) ≥µk+t
#
≤(m−k+1)exp{−1
4t/B}, for t≥σ 2
k/B. (2.28)
We need this theorem because we can define a finite sequence of random symmetric matrices{Xj}for j=1, 2, ...,M, where
and the only thing that is random isxj, as fj = f(xj), wherexjis randomly drawn from the distributionρ. Therefore, the expected value ofXjis simply the matrixCbecause
E(Xj) =
Z
(∇xfj)(∇xfj)Tρ(xj)dxj =
Z
(∇xf)(∇xf)Tρdx=C. (2.30)
In addition, note that ∑jXj is simply the Monte Carlo estimation of C; thus, λk(∑jXj) is simply thekth largest eigenvalue of the estimated matrix
ˆ
C. Therefore, if we can prove the conditions inTheorem1, we can obtain a probability bound for the eigenvalues of the matrixC. This leads toTheorem
2as follows.
Theorem 2(Theorem 3.3 in (Constantine,2015)). Let m be the dimension of the input space, M be the number of samples,λk be the true eigenvalue of the matrixC,
andλˆk be the estimated eigenvalue, and assume that ||∇xf|| ≤ L for all x ∈ X.
Then, fore ∈ (0, 1], we have
P(λˆk ≥(1+e)λk) ≤(m−k+1)exp(
−Mλke2
4L2 ), (2.31)
and
P(λˆk ≤(1−e)λk) ≤kexp(
−Mλ2ke2 4λ1L2
). (2.32)
Proof. If we define fj = f(xj)andXjas
Xj = (∇xfj)(∇xfj)T, (2.33)
we can see thatXj is a random symmetric matrix because xj is drawn ran-domly and independently from the distributionρ. Therefore, we have a fi-nite sequence of independent, random and symmetric matrices {Xj} with dimensionm.
Because the only randomness comes from the sequence of{xj}, we have, for allj,
E
Xj
=
Z
(∇xfj)(∇xfj)Tρ(xj)dxj =
Z
To useTheorem1, we need to first prove that the subexponential condi-tion holds. Recall that we assume||∇xf|| ≤ L; we have
E(Xpj) =
Z
(∇xf∇xfT)pρdx
=
Z
(∇xf∇xfT∇xf∇xfT...∇xf∇xfT)ρdx
=
Z
(∇xfT∇xf)p−1∇xf∇xfTρdx
=
Z
(||∇xf||2)p−1∇xf∇xfTρdx
(L2)p−1
Z
∇xf∇xfTρdx
as we have p =2, 3, 4, .., p!
2 ≥1, therefore, we obtain
p!
2(L 2)p−2(
L2C)
(2.35)
By settingB =L2,Σ2j = L2C, we complete the proof of the subexponential condition.
In accordance with equation 2.24, we have
µk =λk
M
∑
j=1
Z
(∇xf∇xfT)ρdx
!
= Mλk(C) = Mλk. (2.36)
µk =λmax M
∑
j=1
WT+E[Xj]W+
!
=λmax M
∑
j=1 WT+
Z
(∇xf∇xfT)ρdxW+
!
=λmax M
∑
j=1
WT+CW+
!
=Mλmax
WT+CW+
apply eigenvalue decomposition onC
=Mλmax
WT+WΛWTW+
partitionW = [W−W+], whereW− =W[:, :k−1]
partitionΛcorrespondingly as =Λ= "
Λ− 0 0 Λ+
#
=Mλmax WT+[W− W+]
"
Λ− 0 0 Λ+
#
[W− W+]TW+
!
Note that asCis symmetric, we orthonormal eigenvectors, therefore
=Mλmax [0 1]
"
Λ− 0 0 Λ+
#
[W− W+]TW+
!
=Mλmax
"
0 0
0 Λ+
#
[0 1]T !
=Mλmax(Λ+)
=Mλk
=µk
(2.37) Then, we can define equation 2.26 as
σk2 =λmax( M
∑
j=1
WT+(L2C)W+)
= ML2λmax(W+T(C)W+)
= ML2λk.
(2.38)
P
"
λk(
∑
j
Xj) ≥µk+t
#
≤(m−k+1)exp{−1
4t 2
/σk2}, fort≤σk2/B.
Note that M1 ∑jXj is simply the Monte Carlo approximation of C, and plugging inµk,Bandσk2, we have
P
"
λk(
∑
j
Xj)≥ Mλk+t
#
≤(m−k+1)exp{−1
4t 2
/ML2λk},
fort≤ ML2λk/L2
as for everyt >0, this property holds, we can let Mt =t
P
"
λk(
∑
j
Xj)≥ Mλk+Mt
#
≤(m−k+1)exp{−1
4(Mt)
2/ML2 λk},
for Mt≤ ML2λk/L2
asMt ≤ML2λk/L2→ t∗ ≤λk, fore∈ (0, 1], we havet=eλk(C)
P
"
1
Mλk(
∑
j Xj)≥ M(1+e)λk #≤(m−k+1)exp{−1
4(Meλk) 2
/ML2λk}
P
"
λk(
∑
j
Xj)≥(1+e)λk
#
≤(m−k+1)exp{−1
4M 2
e2λ2k/ML2λk}
P
λk(Cˆ)≥(1+e)λk
≤(m−k+1)exp{−1
4M(eλk) 2/L2
λk}
P
λk(Cˆ)≥(1+e)λk
≤(m−k+1)exp{−1
4Me 2
λk/L2}
This completes the proof for the upper estimate asM >1.
P
λk(Cˆ)≤λk(C)−t
=P
−λk(Cˆ)≥ −λk(C) +t
by the fact thatCˆ = 1 M
M
∑
j=1
∇xf∇xfT
=P "
−λk( M
∑
j=1
∇xf∇xfT) ≥ −Mλk(C) +Mt
#
Note that the negativekth largest eigenvalue ofCis the same as them−k+1th largest eigenvalue of−C; therefore,
=P "
λm−k+1(
M
∑
j=1
−∇xfj∇xfjT)≥ Mλk∗(−C) +Mt
#
=P "
λk∗( M
∑
j=1
−∇xfj∇xfjT) ≥ M(λk∗(−C) +t)
#
,
(2.40)
where we letk∗ = m−k+1; we can then useTheorem1 again. Similarly, we first need to prove the subexponential moment growth condition, as here we setE(−(Xj)p) = R
−(∇xf∇xfT)pρdx. We have
E(−Xpj) =
Z
−(∇xf∇x)pfTρdx
using the fact that E(Xpj)is a positive semi-definite symmetric
matrix, E(Xpj)−E(−Xjp)must also be positive semi-definite.
Therefore, E(−Xjp)E(Xpj)
Z
(∇xf∇xfT)pρdx
p!
2(L 2)p−2
(L2C)
(2.41) Therefore, the subexponential moment growth is valid.
Then, we set
µ∗k =λ∗k M
∑
j=1
−∇xf∇xfTρdx
!
=Mλk∗(−C), (2.42)
µk =λmax M
∑
j=1
WT+E[Xj]W+
!
=λmax M
∑
j=1 WT+
Z
(−∇xf∇xfTρdx)W+
!
= Mλmax(−WT+CW+)
= M(−λk(C))
= M(λm−k+1(−C))
= M(λk∗(−C)).
(2.43)
This is the same as equation 2.42; therefore, the condition onµkis satisfied. Next, we need to find the value ofσk2∗; similarly, we can obtain
σk2∗ =λmax( M
∑
j=1
WT+(L2C)W+)
= ML2λmax(WT+(C)W+)
as this time ourW+consists of the firstkeigenvectors;
= ML2λ1.
(2.44)
Therefore, all the conditions are verified, and we have
P
λk∗(−Cˆ) ≥λk∗(−C) +t ≤kexp{−1
4(Mt) 2
/σk2∗}
for Mt≤σk2∗/B
Thus, similar to the upper estimate, sett =−eλk∗(−C) = eλk(C)
P
λk∗(−Cˆ) ≥(1−e)λk∗(−C)
≤kexp{−1
4Me 2
λ2k/λ1L2}
recall thatλk∗(−C) =λk(C)and similarly for the estimated ˆλk∗ Pˆ
λk(C)≥(1−e)λk(C)
≤kexp{−1
4Me 2
λ2k/λ1L2}
Pˆ
λk ≥(1−e)λk
≤kexp{−1
4Me 2
λ2k/λ1L2}.
(2.45)
Therefore, we have completed the proof.
for some fixed valueL, with more samplesM, the probability that the eigen-value is not close to the true eigeneigen-value decreases. If M goes to infinity, we have ˆλk = λk. However, we cannot choose M =∞as each evaluation of the gradient requires(m+1)function runs. Therefore, we need to find anMthat can decrease the probability of ˆλkbeing not close to λkto an acceptable level while simultaneously is small enough considering computational efficiency.
To address this issue, we present the following theorem, from which we can find a suitable value forMto make ˆλkbe close toλkwith high probability.
Theorem 3 (Corollary 3.5 in (Constantine, 2015) ). for e ∈ (0, 1], and some
positive constant c, andβ,
M =c(L
2λ1
λk
λ1e2 log(m)) (2.46)
impliesλˆkis close toλk with high probability.
Proof. Using the upper estimate from Theorem 1, if we setMas
M≥ 4L
2
λke2(β+1)log(m)≥
4L2
λke2(βlog(m) +log(m−k+1)), (2.47)
we have
P(λˆk ≥(1+e)λk) ≤m−β, (2.48)
and similarly, if we chooseMas
M ≥ 4L
2 λ1
λ2ke2
(β+1)log(m) ≥ 4L 2
λ1
λ2ke2
(βlog(m) +log(k)), (2.49)
we have
P(λˆk ≤(1−e)λk))≤m−β. (2.50)
Thus, if we choose
M ≥(β+1)
L2λ1
λk
λ1e2
Msatisfies both conditions, and hence, ˆλkis close toλkwith high probability.
The next step is to find a way to measure the difference betweenCˆ andCˆ. Constantine, 2015uses the matrix Bernstein theorem in (Gittens and Tropp,
2011). Regarding completeness, we restate the matrix Bernstein theorem here.
Theorem 4(matrix Bernstein: bounded (Gittens and Tropp, 2011)). Consider a finite sequence{Xj}of independent, random, symmetric matrices with dimension m. Assume that
E
Xj
=0andλmax(Xj) ≤R (2.52)
for some real R.
Compute the norm of the total variance
σ2=||
∑
j
EhX2ji||. (2.53)
Then, the following inequality holds for all t ≥0:
P
"
λmax(
∑
j
Xj) ≥t
#
≤mexp(−3t2/8σ2)for t≤σ2/R (2.54)
and
P
"
λmax(
∑
j
Xj) ≥t
#
≤mexp(−3t/8R)for t≥σ2/R. (2.55)
Then, by treatingXj =∇xfj∇xfjT−C, we can obtain a probability bound for||Cˆ −C|| ≥ e||C||for small e. To be more specific, we introduce the next theorem.
Theorem 5(Theorem 3.7 in (Constantine,2015)). Assume that||∇xf|| ≤ L for
all x in the parameter domain. Then, fore∈ (0, 1], we have
P
||Cˆ −C|| ≥e||C|| ≤2mexp−3Mλ1e 2
8L2 . (2.56)
positive semi-definite, the singular value is simply the eigenvalue, and thus, the norm is λmax(Cˆ −C). Otherwise, the norm is |λmin(Cˆ −C)|, which is λmax(C−Cˆ).
Therefore, one can write the probabilityP
||Cˆ −C|| ≥t
as
P
||Cˆ −C|| ≥t =P
λmax(Cˆ −C) ≥torλmax(C−Cˆ) ≥t
using basic probability theory thatP(A) +P(B) ≥P(A or B) = P(A)∪P(B)
≤P
λmax(Cˆ −C) ≥t+Pλmax(C−Cˆ)≥t
recall thatCˆ = 1 M
M
∑
j=1
∇xfj∇xfjT, we have
=P "
1
Mλmax(
M
∑
j=1
∇xfj∇xfjT−C) ≥t
#
+P "
1
Mλmax(C−
M
∑
j=1
∇xfj∇xfjT)≥t
#
similarly
=P "
λmax(
M
∑
j=1
∇xfj∇xfjT −C) ≥ Mt
#
+P "
λmax(C−
M
∑
j=1
∇xfj∇xfjT) ≥ Mt
#
(2.57) Note that if each of the terms can be applied in theorem 4, we can find a boundθsuch that
θ ≥P
"
λmax(
M
∑
j=1
∇xfj∇xfjT −C) ≥ Mt
#
and
θ ≥P
"
λmax(C−
M
∑
j=1
∇xfj∇xfjT) ≥ Mt
#
.
Then, if we write
P
||Cˆ −C|| ≥t
≤2θ,
our problem becomes finding the error boundθ.
Next, we need to prove that we can use theorem 4 for
P
"
λmax(C−
M
∑
j=1
∇xfj∇xfjT) ≥ Mt
and
P
"
λmax(
M
∑
j=1
∇xfj∇xfjT−C)≥ Mt
#
.
The first condition oftheorem 4isEXj
=0. In our case,Xj =∇xfj∇xfjT−
C and the other Xj = C−nablaxfj∇xfjT . Similarly, the only randomness
arises from fjis from the random selection of gradients; therefore, we have
E
Xj
=
Z
((∇xfj)(∇xfj)T −C)ρ(xj)dxj
=
Z
((∇xf)(∇xf)T−C)ρdx
=
Z
(∇xf)(∇xf)Tρdx−C Z
ρdx
=C−C∗1
=0,
(2.58)
and similarly,
E
Xj
=
Z
(C−(∇xfj)(∇xfj)T)ρ(xj)dxj (2.59)
=0. (2.60)
Therefore, the first condition oftheorem 4is satisfied by both equations. Next, we need to prove that the maximum eigenvalue ofXj is bounded. In other words,λmax(Xj) ≤R.
By assuming that we have a finite gradient norm such that||∇xf|| ≤ L,
λmax(∇xf∇xfT−C)
= max
||v||=1v T(∇
xf∇xfT−C)v
= max
||v||=1v T(∇
xf∇xfT)v−vTCv
asCis positive semi-definite
≤ max ||v||=1v
T(∇
xf∇xfT)v
≤ max ||v||=1||v
T(∇
xf)||2
by Cauchy inequality
≤ max
||v||=1||v||||∇xf|| 2
≤L2.
(2.61)
WhenXj =C− ∇xf∇xfT, we have
λmax(C− ∇xf∇xfT)
= max
||v||=1v
T(C− ∇
xf∇xfT)v
= max
||v||=1v
TCv−vT(∇
xf∇xfT)v
asCand∇xf∇xfT are both positive semi-definite
≤ max ||v||=1v
T(C)v
= max
||v||=1v
T(Z (∇
xf)(∇xf)Tρdx)v
= max
||v||=1(
Z
vT(∇xf)(∇xf)Tvρdx)
= max
||v||=1(
Z
||vT(∇xf)||2ρdx)
≤ max ||v||=1(
Z
||v||||∇xf||2ρdx)
≤
Z
L2ρdx
=L2.
(2.62)
σ2=|| M
∑
j=1
Z
(∇xfj∇xfjT −C)2ρdx||
=||
M
∑
j=1
Z
(∇xf∇xfT−C)2ρdx||
= M||
Z
(∇xf∇xfT−C)2ρdx||
= M||
Z
(∇xf∇xfT−C)T(∇xf∇xfT−C)ρdx||
= M||
Z
(∇xf∇xfT−CT)(∇xf∇xfT−C)ρdx||
= M||
Z
∇xf∇xfT∇xf∇xfT− ∇xf∇xfTC−CT∇xf∇xfT+C2ρdx||
Using the facts that symmetric matrix multiplication is commutative
and CT =C, we have
≤ M||
Z
L2∇xf∇xfT−2C∇xf∇xfT +C2ρdx||
= M||L2C−2C
Z
∇xf∇xfTρdx+C2||
= M||L2C−2C2+C2||
= M||L2C−C2||
by the Cauchy inequality
≤ M||C||||L2I−C||
= Mλ1||L2I−C||
= Mλ1L2||I−C/L2||
= Mλ1L2 max ||v||=1v
T(I−C/L2)v
= Mλ1L2(max ||v||=1v
TIv−vTC/L2v)
Using the fact thatλ1 ≤L2,
we have that 1
L2λ1less that 1; therefore,
≤ Mλ1L2.
(2.63) Therefore, we have σ2. Note that for Xj = C− ∇xfj∇xfjT, we have
R
(∇xfj∇xfjT−C)2ρdx = R(C− ∇xfj∇xfjT)2ρdx; thus, we have the same σ2.
P
"
λmax(
∑
j
Xj) ≥t #
≤mexp(−3t2/8σ2)fort ≤σ2/R (2.64)
and
P
"
λmax(
∑
j
Xj) ≥t
#
≤mexp(−3t/8R)fort ≥σ2/R. (2.65)
In our case, we have t = Mt, σ2 ≤ Mλ1L2 and R = L2. Let us choose
σ2 = Mλ1L2, and we have
σ2/R =Mλ1. (2.66)
Let Mt =Me||C||fore ∈ (0, 1], and we have
Me||C||= Meλ1 ≤ Mλ1 =σ2/R. (2.67)
Therefore, we obtain
P
"
λmax(
∑
j
Xj) ≥t #
≤mexp(−3t2/8σ2)
P
"
λmax(
M
∑
j=1
∇xfj∇xfjT−C) ≥Me||C||
#
≤mexp(−3(Me||C||)2/8Mλ1L2)
P
λmax(Cˆ −C)≥e||C|| ≤mexp(−3(Meλ1)2/8Mλ1L2)
P
λmax(Cˆ −C)≥e||C|| ≤mexp(−3e2Mλ1/8L2).
(2.68) Note that the probability bound for Xj = C− ∇xfj∇xfjT is the same.
Therefore, ourθ =mexp(−3e2Mλ1/8L2); thus,
P
||Cˆ −C|| ≥e||C|| ≤2θ =2mexp(−3e2Mλ1/8L2),
which completes the proof.
Then, using the same logic as intheorem 3, (Constantine,2015) produces anMs.t.
M =c
L2
λ1e2
log(m)
that makesP
||Cˆ −C|| ≥e||C|| small. However, in practical applications, we normally do not know L2 or λ1 in advance; therefore, (Constantine and Gleich,2014) recommend choosing Msamples
M=αklog(m). (2.70)
In principle, αk corresponds to the c L2
λ1e2 term, where k is the dimension
of the active subspace. It is also proved that an α that is between 2 to 10 is sufficient to achieve an acceptable accuracy. (Constantine and Gleich,2014)
After we obtain the probability bound for ||Cˆ|| being close to ||C|| and we obtain anM that makes the probability acceptable, we finally are able to derive the difference between||Wˆ 1||and||W1||. The theorem to be used here is from (Tropp,2012). For completeness, we restate the theorem here. Note that we follow the definition ofdist(ran(W1),ran(Wˆ 1))from (Stewart,1973), as
dist(ran(W1),ran(Wˆ 1)) =||WT1W1−Wˆ T1Wˆ 1||=||W1TWˆ 2||.
Theorem 6 (Corollary 8.1.11 in Tropp, 2012). Let C and Cˆ = C+Ebe sym-metric m×m matrices with eigenvalues λ1, ...,λm and λˆ1, ..., ˆλm and eigenvector
matrices
W = [W1 W2]
and
ˆ
W = [Wˆ 1 Wˆ 2]
,
whereWandWˆ contain the first n <m columns. Ifλn >λn+1and
||E|| ≤ λn−λn+1
5
, then
dist(ran(W1),ran(Wˆ 1))≤
4||WT2EW1||
λn−λn+1
.
Theorem 7(Corollary 3.10 in (Constantine,2015)). Lete>0s.t.
e ≤ λn−λn+1
5λ1 , (2.71)
and choose M according to equation 2.69. Then, with high probability,
dist(ran(W1),ran(Wˆ 1)) ≤4 λ1e
λn−λn+1
.
Proof. First, we know that Cˆ andCare both symmetric m×m matrices. We can define
E =Cˆ −C
.
Hence,
||E|| =||Cˆ −C||
Usingtheorem 5and Min equation 2.69, we have with high probability that
||E|| ≤ e||C||=eλ1
.
Then, we need to show that
||E|| ≤ λn−λn+1
5
.
If we choose oure according to equation 2.71, we have
λn −λn+1
5 ≥eλ1 =||E|| .
dist(ran(W1),ran(Wˆ 1))
≤ 4||W
T 2EW1||
λn−λn+1
asW2T andW1are all orthonormal,WT2Erepresents extraction and rotation of some column vectors inE,
the max eigenvalue ofW2TEis less than the max eigenvalue ofE. MultiplyingW1gives the same results;
therefore,||WT2EW1|| ≤ ||E||, and thus,
≤ 4||E||
λn−λn+1
≤ 4eλ1
λn−λn+1
.
(2.72)
Therefore, the proof is completed.
This is interesting because it suggests that a larger gap between eigenval-ues results in a more accurate subspace. Hence, in practice, we determine the dimension of the active subspace by finding the largest gap between the eigenvalues. However, we may face problems when the largest gap between the eigenvalues is not large enough. For example, given a 6-dimensional in-put space, we may have a set of eigenvalues as(10, 9.9, 9.8, 8, 7.9, 7.8). Note that the largest gap occurs between the third and fourth eigenvalues, which indicates a 3-dimensional active subspace of the 6-dimensional space. How-ever, the eigenvalues for the inactive subspace are still relatively significant. This produces problems, which we will discuss in chapter 4.
In addition, this bound requires a number of assumptions. For example, we need the norm of gradients to be bounded, and we needσ2 to be at its upper bound. Moreover, this error bound is derived by assuming that we use
Mas in equation 2.69 so that we obtain this error bound to high probability. This, however, does not mean that the error bound always works because there is still a low probability that problems may occur. Therefore, this error bound only works "with probability".
Firstly, we need to assume that
||g(x)h− ∇xf(x)|| ≤√mγh, (2.73)
where m is the number of dimensions, g(x)h is the approximated gradient with some termhsuch thatγhis assumed to be
lim
h→0γh =0. (2.74)
Then, write the approximated gradient forxjasg(xj) =gj, one can define
ˆ G = 1
M
M
∑
j=1 gjgTj
Here we drop the subscript h ash is not important in the derivation of the error bounds. As the matrixGˆ analogous to Cˆ (22) but using approximated gradients to replace the true gradients. Then, one can prove that||Cˆ −Gˆ|| is bounded by(√mγh+2L)
√
mγh. The proof is relatively straight forward. Note that
||Cˆ −Gˆ||=|| 1
M
M
∑
j=1
∇xf(xj)∇xf(xj)T−gjgTj
!
||. (2.75)
One can decompose∇xf(xj)∇xf(xj)T−gjgTj as
1
2(∇xf(xj)−gj)(∇xf(xj) +gj) T+1
2(∇xf(xj)−gj)(∇xf(xj) +gj) T.
Then,by put it back to equation 2.75 and rearrange them with triangle inequality, one can get
||Cˆ −Gˆ|| ≤ ||(∇xf(x)−g)||||(∇xf(x) +g)T|| (2.76)
We can drop the subscriptjbecause we can apply a general error bound here. The error bound for the first term is assumed in equation 2.73. For the second term, by first letting∇xf(x) = ∇xf and ||g+∇xf|| = ||g− ∇xf +
2∇xf||, one can apply the triangle inequality and obtain a bound of √
mγh+ 2L. Put it back to equation 2.76, we get||Cˆ −Gˆ|| ≤ (√mγh+2L)
√
column space ofW1and the column space of the Monte Carlo and approxi-mated gradient counterpart ofW1, say,Uˆ1, as
dist(ran(Uˆ1),ran(Wˆ 1))≤ 4 √
mγh(
√
mγh+2L)
(1−e)λn−(1+e)λn+1
+ 4λ1e
λn−λn+1
,
where we can see that the first term associates with the error arising from the approximated gradient while the second term is the error associated with the Monte Carlo method.
2.1.3
Response Surface
Russi (2010) uses a regression-type technique to approximate the approxima-tion funcapproxima-tiongafter the matrixSis calculated.
Specifically, letφ(·)be basis functions,Φ=
φT(STx1)
φT(STx2)
.. .
φT(STxN)
and y =
f(x1)
f(x2)
.. .
f(xN)
The weight vectorw∗ can be found as
w∗ that min
w kΦw−yk
s.t. the approximation function f(x)≈ g(x) ≈g(˜ x) = w∗Tφ(STx).
Using an identical idea, (Constantine,2015) provides a clearer mathemat-ical definition for this procedure and develops error bounds for such setting.
First, recall that
f(x) = f(W1y+W2z). (2.77)
For the best case,W2z= 0, which means that the function is invariant in the range ofW2, and we have
g(y) = f(W1y)
When W2z is not zero but|f(W1y+W2z)− f(W1y)|is small, asW2z is along the inactive direction, we have
g(y) ≈ f(W1y). (2.79)
The next problem is to find g(.). This is an ill-posed problem because generally we have an infinite number ofx s.t. WT1x = y. Thus, how should one choose the value g(y) from infinitely many f(x)s? (Constantine, 2015) proposes a method named conditional expectation and Monte Carlo approx-imation.
If we define
π(y,z) = ρ(W1y+W2z), (2.80)
the the marginal densities are
πY(y) =
Z
ρ(W1y+W2z)dz, (2.81)
πZ(z) =
Z
ρ(W1y+W2z)dy, (2.82)
and the conditional densities
πY|Z(y|z) =
π(y,z) πZ(z)
, (2.83)
πZ|Y(z|y) =
π(y,z)
πy(y) . (2.84)
Then, for a fixedy, the best guess that one can make for the value of f is simply the average of all f(x)s.t. WT1x =y, which is simply the conditional expectation of f giveny. Therefore, one can define gas
g(y) =
Z
f(W1y+W2z)πZ|Y(z|y)dz. (2.85)
g(WT1x) ≈ f(x). (2.86)
However, we would have a similar problem for each value of y as for evaluating the matrixC; we would evaluate an higher order integral, which can be intractable. The cure here is also the Monte Carlo method.
If the eigenvalues λn+1, ...,λm are small, we expect that ˆg is a good ap-proximation ofgwith small N, where
ˆ
g(y) = 1 N
N
∑
i=1
f(W1y+W2z). (2.87)
Note that if λn+1, ...,λm is not exactly zero, ˆg(y) has noise. Therefore, rather than using exact interpolation methods, one may use regression-type methods. In other words, we can construct the response surface R for M
number ofyas
ˆ
g(y) =R(y; ˆg(y1), ..., ˆg(yM)). (2.88)
Thus, we can use this response surface to predict f as
f(x) = R(WT1x). (2.89)
The error bounds for this construction are presented in Chapter 4.2 of (Constantine,2015).
Algorithm 1: Constructing a regression surface using the active sub-space method.
1. Uniformly drawM =αklog(m)samples from them-dimensional parameter space according toρ.;
2. For each samplexi, evaluate∇f(xi).; 3. EvaluateCˆ = M1 ∑Mi=1(∇xfi)(∇xfi)T.;
4. Apply eigenvalue decomposition toCˆ and obtainCˆ =W ˆˆ ΛWˆ T.; 5. Find the largest eigenvalue gap inΛˆ and hence determineWˆ 1.; 6. Evaluateyi =Wˆ 1Txifor eachxi.;
7. Construct the response surface using{yi, f(xi)}.;
The error analysis for the response surface is given in section 4.2 of Con-stantine, 2015. In particular, the error between f(x) and the approximated
g(y)is bounded by a poincare constant times the sum of eigenvalues of the inactive eigenvectors. This means that the less the value of inactive eigenval-ues, the better the approximation will be.
2.2
Gaussian Process
The Gaussian process is a stochastic process whereby any finite subset of the elements follows a multivariate Gaussian distribution. For prediction, let us assume that there exists an unknown function f s.t., for training input data xi fori = 1, ...,M,xi ∈ Rm and output data yi for i = 1, ...,M,yi ∈ Rn, we haveyi = f(xi). The best approach to make a predictiony∗on the given new inputx∗ is to infer a distribution over f (Kevin,2012). Specifically, we need to compute
p(y∗|x∗,x1,x2, ...,xM,y1,y2, ...,yM) =
Z
p(y∗|f,x∗)p(f|x1,x2, ...,xM,y1,y2, ...,yM)d f.
(2.90)
f(x1)
f(x2) .. .
f(xM)
∼ N(
m(x1)
m(x2) .. .
m(xM)
,K) (2.91)
, wherem(xi)are the mean functions andKis the covariance matrix.
Kij =κ(xi,xj), (2.92)
for whichκ is a positive-definite kernel function. In this thesis, we use the Gaussian kernel, aka the RBF kernel
κ(xi,xj) =exp(−1
2(xi−xj) TΣ(x
i−xj)). (2.93)
This suggests that ifxi and xj are close (in terms of the kernel function),
f(xi)and f(xj)should also be close. Note that here we assume that the train-ing set is free of noise; therefore, the function value interpolates the data. Specifically, the diagonal of the covariance is all 1s.
Therefore, letX= [xT1,x2T, ...,xTM], and we can write our probability distri-bution of the function f as
p(f|X) = N(f|µ,K), (2.94)
whereµ =
m(x1) m(x2)
.. .
m(xM)
For a test set X∗ with dimension M∗×m, test meanµ∗ ∈ RM∗, and test covariance matrixK∗ =κ(X∗,X),K∗∗ =κ(X∗,X∗), the joint off∗andfcan be written as
"
f f∗
#
∼ N( " µ µ∗ # , " K K∗
KT∗ K∗∗
#
This is then a joint distribution of a multivariate Gaussian. We can de-velop the conditional distribution using section 2.3 of (Bishop,2006), and we have
p(f∗|X,X∗,f) = N(f∗|µ∗,Σ∗)
=N(f∗|µ(X∗) +K∗TK−1(f−µ(X)),K∗∗−K∗TK−1K∗).
(2.96)
If we have a noisy training set, i.e.,y = f(x) +e,e ∼ N(0,σy2), the model is then not required to interpolate the training data exactly. Specifically, the diagonal of the covariance matrix is no longer all 1s, as we need to consider the variation of the data itself. We can then define the new covariance matrix Knew as
Knew =K+σy2I, (2.97)
whereIis an identity matrix of dimensionm×m.
Here, onlyKnewchanges; therefore, we can apply the same formula as in equation 2.96, which gives
p(f∗|X,X∗,f) = N(f∗|µ∗,Σ∗)
=N(f∗|µ(X∗) +K∗K−1new(f−µ(X)),K∗∗−K∗K−1newK∗T). (2.98) Although the performance of the Gaussian process depends solely on the selected kernel, the optimisation of the kernel hyperparameter is beyond the scope of this thesis. Regardless, it is optimised during the Gaussian process fitting by thesklearnpython package.
2.3
Voronoi region
modelling (Wolfram, 2002), epidemiology (Steven, 2002), detecting neuro-muscular diseases (Sanchez-Gutierrez et al.,2016), and computational physics (Kasim, Muhammad, and FirmansyahM,2017).
More specifically, a Voronoi diagram is a partitioning of a space into re-gions based on distance to points, usually known as seeds, sites, or genera-tors. The seeds are specified beforehand, and for each such seed, the corre-sponding region contains all the points that are closer to the seed than to any other ones.
Let X be a metric space and let x ∈ X {si} be seeds for i = 1, ...,M; the corresponding region{Rk}fork =1, ...,Mcan be defined as
Rk ={x ∈ X : d(x,Pk) <d(x,Pj)for∀k6=j}. (2.99)
The distance function d can be defined arbitrarily. In this thesis, the L-2 norm is used as the distance function.
2.4
KD trees
The KD trees algorithm is used to solve nearest neighbour problems (Manee-wongvatana and Mount,2001).
To make the brute-force nearest neighbour algorithm more efficient, a number of tree-based algorithms, such as KD trees and ball trees, have been developed. In general, these algorithms aim to decrease the number of calcu-lations of distances by encoding the distance information for each data point. Specifically, if point a is close to point b but far away from point c, we can conclude that b is far away from c without actually computing the distance between them.
As an early attempt to use the encoded information, (Bentley,1975) pro-posed a method named KD trees, which essentially adopts a binary tree structure. The binary trees are constructed by repeated partitioning of the input data space into halves according to the median along the parameter axis (Figure 2.2). This process is fast because the partitioning only occurs on the axis of the input data, and no high-dimensional distance calculation is needed. Although this is a heuristic algorithm, once it is constructed, the querying of points only takesO[log(N)]computations. This is a large reduc-tion from brute-forceO[log(DN)], whereDis the dimension of the parameter space.
Note that the KD trees method is efficient when D is not too large. The rule of thumb is usually to set D as 20D. All the test functions used in this thesis have a parameter space of dimension less than 20.
Chapter 3
Methods
As mentioned in the introduction, one of the major drawbacks of the active subspace method is that it uses the average outer product of gradients across the whole parameter space. This works nicely when the outer product of gradients does not change significantly in the input space, but it results in a poor approximation otherwise. This problem can be addressed by partition-ing the parameter space and constructpartition-ing the response surface for each of the partitioned regions individually.
Mathematically, by first defining the partition regions{Rk}fork=1, ..,M∗, one can define the uncentred covariance matrixCkfor regionRk, as in equa-tion 2.7, as
Ck =
Z
x∈Rk
(∇xf)(∇xf)Tρ(x)dx. (3.1)
Thus, decomposition as in equation 2.12 yields
Ck =WkΛkWTk. (3.2)
Moreover, in the same manner as in equation 2.18, forx ∈ Rk,
x =WkWTkx (3.3)
=Wk1y+Wk2z. (3.4)
ˆ
gk(y) =R(y; ˆgk(y)), (3.5)
wherey=WTk1x,∀x∈ Rk.
In such settings, we have three questions to answer. First, how should one define{Rk} fork = 1, ..,M∗? In other words, how can one partition the parameter space? Second, how should one construct the active subspace for each region Rk? Finally, how should one construct the response surface for each region by utilising the corresponding active subspace?
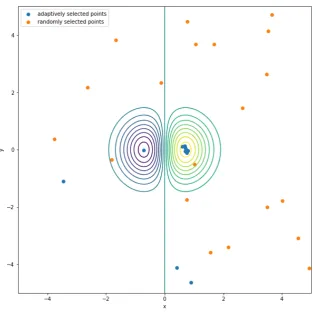
There are a number of partitioning methods to address the first ques-tion. Some of these methods require one to define specific patterns across the parameter space beforehand and use an NP-hard algorithm to partition the whole space (Pitt et al., 2006). The determination of patterns generally requires professional prior knowledge. This is not applicable in this thesis because we aim to apply the methods on to more general functions. Instead, the Voronoi region is used in this thesis(section 2.3). This is based on the assumption that the underlying model is sufficiently smooth; therefore, the gradients, and hence the active subspace, should be similar around an evalu-ated point. This directly leads to the use of Voronoi regions because gradients of points should be close to, in the sense of the L-2 norm, the closest evaluated gradient. Hence, by first generating{xk}for k = 1, ..,M∗, one can construct the corresponding Voronoi regions as{Vk} fork =1, ..,M∗ as in section 2.3. Then, the problem becomes how to generate{xk}fork =1, ..,M∗. In this the-sis, we propose two methods to define the values of{xk}. The first method simply uses randomly selected points drawn from a uniform distribution, and the second method uses adaptively selected points based on the squared error (SE) (sections 3.1 and 3.2).
The next problem is how to compute equation 3.1, namely, how to find the corresponding active subspace. In this thesis, we suggest two ways to construct the partitioned active subspaces. The first one is simply to use the outer product of gradientxk, which is to say that we have
Ck ≈Cˆk = (∇xkf)(∇xkf)
T
. (3.6)
Specifically, we model the gradient by fitting a Gaussian process on{∇f(xk)} with its corresponding{xk}. Therefore, for the approximated active subspace of regionk, let the approximated gradients at points{xki}fori =1, ...,Nk∗ be
∇xkifˆ(xki), and let ˆf(xki) = fˆki; we have
Ck ≈Cˆk = 1 Nk
Nk∗
∑
i=1
(∇xfˆki)(∇xfˆki)T. (3.7)
To address the last question, we use multivariate regression to construct the surfaces. This is because we generally have non-zero eigenvalues in the inactive directions, which introduce noise. With non-zeroW2z, our approx-imation function g(y) is not exactly equal to f(W1y). Therefore, we need regression rather than interpolation in this situations. Then, one needs to decide how many regression points should be used. In this thesis, we pro-pose two methods. The first method is randomly and uniformly generating points beforehand across the parameter space. The other method is gener-ating points from a Gaussian distribution for each region after the regions have been constructed (sections 3.1.2 and 3.2.2). Note that in these settings, the response surfaces are generally discontinuous.
Note that we have 2 choices for selecting points, 2 choices for constructing partitioned active subspaces and 2 choices for choosing regression points. This provides us with a total of 8 different combinations. We examine 5 of the combinations as:
• 1) randomly partition M∗ regions using only one point to construct in-dividual active subspaces and using N∗randomly generated points for regression (section 3.1.1),
• 2) randomly partition M∗ regions using one one point to construct in-dividual active subspaces and using a particular number of samples inside each region as regression points (section 3.1.2),
• 3) randomly partition regions using a Gaussian process to construct in-dividual active subspaces and using N∗randomly generated points for regression (section 3.1.3),