International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-12, October 2019
Feature Fusion for Image Retrieval using Image
Processing.
Amol Potgantwar, Shreyas Deshmukh
Abstract— Image processing and computer vision uses Content-based image retrieval (CBIR) function to solve the issue of image retrieval, which means, solving the issue of image searching in expansive databases. The actual data of the image will be evaluated when a search is performed that refers to content-based. The term content can be any attribute of an image like colour-shade, various symbols or shapes, sizes, or any other data. There are various approaches for image retrieval but the most prominent are by comparing the main image with the subsets of the relatable images whether it matches or not and the other one is by using a matching descriptor for the image. One of the main trouble for huge amount of CBIR is the representation of an image. When a given image is worked upon it is divided into number of attributes in which some are the primary ones and others are the secondary ones. These attributes are checked with the local and MPEG-7 descriptors. All this is then mapped in a single vector which is the same images but in compact form to save the space. Principle Component Analysis (PCA) is used lessen the attribute size. To store the attribute data in similar clusters and to train them to give the correct output the study also uses k-means clustering algorithm. Hence, the proposed system deals with the image retrieval using various algorithms and methods.
Index Terms—CBIR, image retrieval, MPEG-7 descriptors, PCA, k-means clustering.
I.INTRODUCTION
Now a days we have a lot of data in various forms, like documents, videos, images, etc. There are many softwares, apps, methods used to work with a particular kind of data. If the data is in text format then we have softwares like adobe reader, notepad, and so on. Same is with the images because a huge amount of data is transferred to one another using images in which some are open to all but some are private. But, we are continuously dealing with images in today's world.
There are many areas which are benefited by CBIR technology like video management. But it is still a topic under research. The technology is in boom but many things need to be tested and analyzed for efficient working of the system. Proposed System provide compact image representation and relevant result to the user query. As Using MPEG-7 descriptors number of features are extracted from an image which will provide high accuracy in image retrieval. Principle component analysis method provide compression of image features without loss of data.
The usage of images in toadys world is in huge quaantity over the internet which directly increases the number of users. Like, there are so many different images for a single word. Images play a very important role in the society. Today images are used in every field like, medicine, biology, aeronautics, crime, designing, advertising, archeology.
Revised Manuscript Received on October 05, 2019.
Prof. (Dr.) Amol Potgantwar, H.O.D, Computer Dept., SITRC, Nashik.
Shreyas Deshmukh, Student, Computer Dept., SITRC, Nashik.
People have been in the use of photographs, TV and a lot more other things. This contributes to the growth of image usage. Images were always stored manually is past years until there was any technology for storing data. The images were stored according to their similarities giving them the index number in shelves, folders, cupboards. But, as the number of images increased the manual work was hectic and difficult. So, basically there was a need to automate this work for proper storage and efficient image retrieval.
There is a necessity to develop sucha system that will effectively manage the image collection. It is obviously true that if there is a lot of data here are chances of them getting disturbed or the quality depreciation. These kind of thoughts give the rise to build new systems that would make life much easier and simpler.
The quantity of collections of digital images have grown due to increase in the number of online users during this period, for example, in web applications that allow to add digital albums and images.
To convey any kind of information people find it easy to communicate through images rather than text or any other medium of communication. It is also true that visuals are very easy to remember than texts hence ad agency use a set of images into a movie where the customer remember the ad for lifetime. There is a lot to play with the images and they a play a important role.
The goal of this system is to study the content-based image retrieval using different MPEG-7 descriptors. Also feature extraction of images,clustering of images, reranking of images. Goal of this system is to show that the advantages of using MPEG-7 Descriptors along with local descriptors and principle component analysis provide a better solution for many number of problems. These kind of scenarios are common in a many domains of data. Hence, the system has tried to find out a new way through which the classification problem has been solved by clustering way, which is providing high quality results due to incorporation of side information.
There is a lot of scope for this technology as it is used in many fields which will always help mankind to lessen their troubles and make the tasks easy. The future world is all about digitalization and the work would be done with one click.
II.LITERATURESURVEY
In the proposed system [2], RootSIFT method is used instead of SIFT to improve retrieval performance. It is a new method where we get high perpormance without the need to change the other requirements. They have also introduced a method for expansion of the query where a higher model is used for retrieval of image using the concept of inverted index. The main objective of
dynamically from large databases, where the image has a query subset to compare and give the output correctly.
In [3], the authors have majorly worked upon VLAD. They have focused on the same problem that of huge requirements fpr storing the data. Here, three contributions are done: firstly they have used normalization with a little change to it which will ultimately improve the performance, second being the adaptation of vocabulary where if one word is typed incorrectly images are shown only for the correct word but it should also show the other images relating to that word, third is the multi-VLAD which allows the system to localize the data or the image that is only a small part of the whole image which gives a high and fine resolution of the image.
In this study [4] a new data structure is introduced which is the and evaluated a new data structure called the Inverted Multi-Index. They have used databases of SIFT and GIST vectors. A comparative of inverted index and inverted multi-index is also done to check the efficiency. A well known method is used for query image that is the nearest neighbour search.
Here in [5], the concept of bag-of-words is used which means if two or more attributes come under a same zone then it will be counting 1 or else in different zones then count 0. Matching of kernels is the main key here. There will be a set of local attributes and a dictionary where the local attributes will be checked with the dictioanry we have. Experiments are done using Caltech. It gives prominent and high efficiency.
L. Chu, in [7] have discussed some problems like huge number of attributes in the non-duplicate zones, small number of prototypical attributes, duplicate zones. Here they have proposed PDIR (Partial Duplicate Image Retrieval) which correctly retrieves the noisy or duplicate images by correctly matching the SIFT attributes. The study is based on COP (Combined Orientation Position) model. It has two parts one being the consistency to accept the proper data and consistency to reject the noisy data. Experiments are performed to check the performance of the developed system.
In the proposed study O. Chum and other authors have proposed an algorithm which is formed from the min-Hash. This model tells us about the dependencies of data where the attributes that occur in high probability [8].
This study presents the objective of retrieving all the occurances of a given image from a large database. They have also used the concept of bag-of-words but have also mentioned some issues with it. Re-issuing of the documents add into the new query and new terms. The main idea is to retrieve the images that match to the input query image. Then to combine the retrieved image and the original query. This gives a rich and qualified model of images. Continue this again and again to from a high leveled model [9].
In [10], gain the concept of VLAD is used. The system uses indexes that are given to the images using the local descriptors which are closely related to VLAD and FV (Fisher Vector). It is suggested that it is easy to encode an image giving excellent results by combining the mentioned descriptors with some coding technique.
[12] demonstrates video annotation using image query. The images are saved in the database then from the video similar kind of images are seggregated. These images are then compared with the images in the database and the
output is given. They have proposed a framework of hierarchical video-to-near-scene annotation.
III.PROBLEMSTATEMENT
The aim of this system is image retrieval using image fusion. The type of feature that the system is extracting Edge Histogram Descriptor (EHD) and Scalable Color Descriptor (SCD). When a given image is worked upon it is divided into number of attributes in which some are the primary ones and others are the secondary ones. These attributes are checked with the local and MPEG-7 descriptors. All this is then mapped in a single vector which is the same images but in compact form to save the space. Principle Component Analysis (PCA) is used lessen the attribute size. To store the attribute data in similar clusters and to train them to give the correct output the study also uses k-means clustering algorithm. Hence, the proposed system deals with the image retrieval using various algorithms and methods.
IV.PROPOSEDSYSTEM
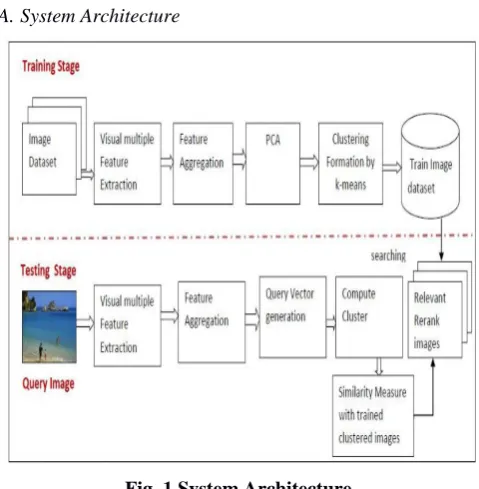
[image:2.595.308.548.292.537.2]A.System Architecture
Fig. 1 System Architecture
The proposed system is divided into following three blocks:
1. Attribute Extraction:
The term content can be any attribute of an image like colour-shade, various symbols or shapes, sizes, or any other data. In a CBIR system these attributes are represented in vector format. This group of attribute vectors of the images which is stored in the database is known as attribute database. This process is started as soon as the user gives a query as input like a drawing or image of any object. Then the query is comapred with the images present in the trained database. The whole image at once is not caompared but small paerts of it are compared. These attributes are checked with the local and MPEG-7 descriptors. For example if the query image given by the user is the face of horse then all the attributes will be compared and then in the further steps all the images that includes horse will be shown.
2. Attribute Space Reduction:
When attribute extraction is done on image using descriptors, there is an
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-12, October 2019
happens because every feature is extracted and stored separately which increases the storage space. To overcome this issue we use a method known as Principle Component Analysis (PCA). PCA has its applications in different fields like compression of images, pattern recognition, etc and is a useful technique. This method is used to find out the similarities and difeerences present in the data. If there is an image that is being checked as it is the input then every attribute from it is extracted and it happens that these attributes cannot be of high dimension hence, PCA represents it high dimension with less storage space and without the loss of data.
3. Cluster Formation:
Cluster formation is done by using a very popular method which is k-means clustering algorithm. This method forms various clusters based upon the similarities among the data. These clusters and the data in it is trained.
This algorithm is basically used to form groups of similar kind of data in k partitions or groups. For instance we are checking a dataset of different colours which has colours like red, blue, green, yellow, black, etc. First colour is taken and placed in the cluster number one which is red. Then the next colour is picked up if it is red then it will be placed in cluster one if it is other colour like blue then a new cluster will be formed. This algorithm goes on until last input. We then finally get all the clusters differentiated in a very good manner which will not cause any confusion. The same goes with the proposed system here all the images matchiing to the input image will be shown correctly.
The details of steps performed in proposed system are as follows:
Step 1: Get the the image that has to be matched with the images in the dataset.
Step 2: Extract attributes of the images Step 3: Combining all the attributes Step 4: Apply PCA on these attributes Step 5: Matrix calculation from step 4 output Step 6: Apply K-means clustering algorithm Step 7: Query Image
Step 8: Extract feature of query images Step 9: Classify cluster of image Step 10: Re-rank images. Step 11: Retrieve relevant images
Fig. 2 Data flow diagram
B. Algorithms
For implementation of this system following algorithms will be used:
1. Feature Extraction
2. Principle Component Analysis 3. Image Classification Using k-means 4. Similarity Measure
Algorithm 1 : Feature Extraction
Input : Query Image Process:
Edge Histogram Descriptor (EHD): It is used for image matching. This descriptor is an easy one because it only checks the edges of an image. There are five different types of edges which are horizontal edge, vertical edge, 45 and 135 degree edge and the last one being non directional edge. Then for an image the counting of edges is done which kind of edge is present how many times and then histogram is prepared showing all the edges regarding that image. After this labeling is done to keep a track record which edge is located where and how many times.
Scalable Color Descriptor (SCD): It is a descriptor related to colour of the images. It is used to compact the image but have a high accuracy. It is scalable in the way that the amount of bins/histogram can be set to a variety of five different settings, allowing a trade-off between accuracy and speed in real-time computation.
Output: Image Features
Algorithm 2 : Principle Component Analysis
Input: Image Features
Process: This algorithm contain following Stages:
1. Extracting the information from the image and acquire data
2. To construct the covariance matrix from the acquired data 3.Eigenvalues and corresponding eigenvectors are calculated.
4. Short Eigen vectors and find principle Eigen vectors vc = (av1, av2, av3,. . . ,avn) where, vc: Eigen vector
5. Finally the information is obtained which is in the form of matrix including eigenvectors (components) of the covariance matrix and the original image is obtained. Output: Dimention Reduction of image features.
Algorithm 3 : Image Classification Using k-means
The k-means algorithm is used for clustering, by applying k-means algorithm the clusters of an images are formed and images are trained. The generalized k-means algorithm is explained in the following paragraph.
K-means clustering is a method commonly used to automatically partition a data set into k groups. First the value of k is decided and then the centers are randomly placed to which similar data will be put in the clusters. Then the similar kind of data is placed near the matching centers which forms a group of similar kind of data. Rearrange the sets again to find out whether the sets are the same or there is any change. If it is the same then exit out of the loop and again follow the same process for the new data.
Algorithm 4: Similarity Measure
Fig. 3 System showing the input image and output image
V.MATHEMATICALMODEL
Let S be the solution So,
let S = { IN, FT, OT } where,
S = Set of inputs, functions, outputs Now,
IN is the set if inputs i.e, IN ={ IN1, IN2 } Let,
IN1 = set of image dataset IN2 = query image Now,
FT is the set of functions
i.e, FT= { FT1, FT2, FT3, FT4, FT5, FT6, FT7 } Let,
FT1 = Edge Histogram Descriptor FT2 = Scalable Color Descriptor FT3 = Color Layout Descriptor FT4 = aggregate feature FT5 = train image dataset
FT6 = query image feature extraction FT7= classify image
Now,
OT is the set of output i.e, OT ={ OT1} Let ,
OT1 = get relevant images
VI.RESULTANALYSIS
[image:4.595.56.283.56.182.2]The analysis done here is for huge number of dataset. There are a lot of images from which the system gives the correct output and accuracy level is high. There are some figures that demonstrate the how the system performs.
Fig. 4 System screen
Now here one input image is given and then accorging to the stored data the most appropriate outut is given. There are
many buttons seen on the screen where we need to select the dataset and then extract the feature.
[image:4.595.309.551.72.374.2]Fig. 5 PCA+ Without clustering
Fig. 6 PCA+ With clustering
[image:4.595.308.556.440.744.2]The graphs gives an idea about how the system works at accuracy level. Here, different datasets are taken like african, bus, food, etc and the accuracy of each image is shown by different highlights. This is well shown in the tabular format.
Fig. 7 PCA + Kmeans by absolute distance
[image:4.595.51.290.627.766.2]International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-12, October 2019
There are many other methods by which the accuracy is calculated like PCA + Kmeans by cosine similariry, KNN by absolute distance, and many more.
VII.CONCLUSION
The goal of this system is to study the content-based image retrieval using different MPEG-7 descriptors. Also feature extraction of images,clustering of images, reranking of images. Goal of this system is to show that the advantages of using MPEG-7 Descriptors along with local descriptors and principle component analysis provide a better solution for many number of problems. These kind of scenarios are common in a many domains of data. Hence, the system has tried to find out a new way through which the classification problem has been solved by clustering way, which is providing high quality results due to incorporation of side information. There is a lot of scope for this technology as it is used in many fields which will always help mankind to lessen their troubles and make the tasks easy. The future world is all about digitalization and the work would be done with one click.
REFERENCES
1. Zhanning Gao, Jianru Xue, Wengang Zhou, Shanmin Pang, and Qi Tian, ''Democratic Diffusion Aggregation for Image Retrieval”, VOL. 18, NO. 8, AUGUST 2016
2. R. Arandjelovic and A. Zisserman, Three things everyone should know to improve object retrieval, in Proc. IEEE Conf. Comput. Vis. Pattern Recognition, Jun. 2012, pp. 29112918.
3. R. Arandjelovic and A. Zisserman, All about VLAD, in Proc. IEEE Conference Computer Vision and Pattern Recognition, Jun. 2013, pp. 15781585.
4. A. Babenko and V. Lempitsky, The inverted multi-index, in Proc. IEEE Conference Comput. Vis. Pattern Recognition, Jun. 2012, pp. 30693076.
5. L. Bo and C. Sminchisescu, Efficient match kernel between sets of features for visual recognition, in Proc. Adv. Neural Inf. Process. Syst., 2009, pp. 135143.
6. Y.-L. Boureau, J. Ponce, and Y. LeCun, A theoretical analysis of featurepooling in visual recognition, in Proc. Int. Conf. Mach. Learn., 2010, pp. 111118.
7. L. Chu, S. Jiang, S. Wang, Y. Zhang, and Q. Huang, Robust spatial consistency graph model for partial duplicate image retrieval, IEEE Trans. Multimedia, vol. 15, no. 8, pp. 19821996, Jun. 2013. 8. O. Chum and J. Matas, Unsupervised discovery of co-occurrence in
sparse high dimensional data, in Proc. IEEE Conf. Comput. Vis. Pattern Recog.,Jun. 2010, pp. 34163423.
9. O. Chum, J. Philbin, J. Sivic, M. Isard, and A. Zisserman, Total recall:Automatic query expansion with a generative feature model for object retrieval, in Proc. IEEE Int. Conf. Comput. Vis., Oct. 2007, pp. 18.
10. J. Delhumeau, P.-H. Gosselin, H. J ́egou, and P . P ́erez, “Revisiting the VLAD image representation,” in Proc. ACM Int. Conf. Multimedia, 2013, pp. 653–656.
11. M. Douze, A. Ramisa, and C. Schmid, Combining attributes and Fisher vectors for efficient image retrieval, in Proc. IEEE Conf. Comput. Vis.Pattern Recog., Jun. 2011, pp. 745752.
12. Chien-Li Chou, Member, IEEE, Hua-Tsung Chen, Member, IEEE, and Suh-Yin Lee, Senior Member, IEEE Multimodal Video-to-Near-Scene Annotation, IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 19, NO. 2, FEBRUARY 2017
13. L.-Y. Duan et al., Overview of the MPEG-CDVS standard, IEEE Trans.Image Process., vol. 25, no. 1, pp. 179194, Jan. 2016. 14. L.-Y. Duan, J. Lin, Z. Wang, T. Huang, and W. Gao, Weighted
compo-nent hashing of binary aggregated descriptors for fast visual search, IEEE Trans. Multimedia, vol. 17, no. 6, pp. 828842, Jun. 2015.
15. Z. Gao, J. Xue, W. Zhou, S. Pang, and Q. Tian, Fast democratic ag- gregation and query fusion for image search, in Proc. ACM Int. Conf. Multi-media Retrieval, 2015, pp. 3542.
16. T. Ge, K. He, and J. Sun, Product sparse coding, in Proc. IEEE Conf.Comput. Vis. Pattern Recog., Jun. 2014, pp. 939946.
17. T. Ge, Q. Ke, and J. Sun, Sparse-coded features for image retrieval, inProc. Brit. Mach. Vis. Conf., Sep. 2013, pp. 132.1132.11. 18. Y. Gong, L. Wang, R. Guo, and S. Lazebnik, Multi-scale orderless
pool-ing of deep convolutional activation features, in Proc. Eur. Conf. Comput. Vis., 2014, pp. 392407
19. H. J egou and O. Chum, Negative evidences and co-occurences in imageretrieval: The benefit of PCA and whitening, in Proc. Eur. Conf. Comput. Vis., 2012, pp. 774787.
20. H. J egou, M. Douze, and C. Schmid, Hamming embedding and weakgeometric consistency for large scale image search, in Proc. Eur. Conf. Comput. Vis., 2008, pp. 304317.
21. J. Sivic and A. Zisserman, “Video Google: A text retrieval approach to object matching in videos,” in ICCV, 2003.
22. J. Philbin, O. Chum, M. Isard, J. Sivic, and A. Zisserman, “Objectretrieval with large vocabularies and fast spatial matching,” in CVPR, 2007.
23. O. Boiman, E. Shechtman, and M. Irani, “In defense of nearest- neighbor based image classification,” in CVPR, 2008.
24. J. Deng, A. C. Berg, K. Li, and F.-F. Li, “What does classifying morethan 10, 000 image categories tell us?” in ECCV, 2010. 25. T. Malisiewicz and A. A. Efros, “Beyond categories: The visual
memex model for reasoning about object relationships,” in NIPS, 2009.
26. J. Hays and A. A. Efros, “Scene completion using millions ofphotographs,” ACM Trans. Graph., vol. 26, no. 3, 2007.
27. H. Lejsek, B. T. J onsson, and L. Amsaleg, “NV-Tree: nearest neigbors at the billion scale,” in ICMR, 2011.
28. A. Torralba, R. Fergus, and W. T. Freeman, “80 million tiny images: A large data set for nonparametric object and scene recognition,” TPAMI, vol. 30, no. 11, 2008.
29. D. Nist ́er and H . Stew ́enius, “Scalable recognition with a vocabulary tree,” in CVPR, 2006.
30. J. L. Bentley, “Multidimensional binary search trees used for associative searching,” Commun. ACM, vol. 18, no. 9, 1975. 31. H. J ́egou, M. Douze, and C. Schmid, “Product quantization for
nearest neighbor search,” TPAMI, vol. 33, no. 1, 2011.
32. H. J ́egou, R. Tavenard, M. Douze, and L. Amsaleg, “Searching in one billion vectors: Re-rank with source coding,” in ICASSP, 2011. 33. C. D. Manning, P. Raghavan, and H. Schutze, Introduction to
Information Retrieval, C. U. Press, Ed., 2008.
34. J. Philbin, M. Isard, J. Sivic, and A. Zisserman, “Descriptor learning for efficient retrieval,” in ECCV, 2010.
35. W.-L. Zhao, X. Wu, and C.-W. Ngo, “On the annotation of web videos by efficient near-duplicate search,” in Transactions on Multimedia, 2010.
36. P. Indyk and R. Motwani, “Approximate nearest neighbors: Towards removing the curse of dimensionality,” in STOC, 1998.
37. M. Charikar, “Similarity estimation techniques from rounding algorithms,” in Proceedings of the Symposium on Theory of Computing, 2002.
38. Q. Lv, M. Charikar, and K. Li, “Image similarity search with compact data structures,” in CIKM, 2004.
39. R. Salakhutdinov and G. E. Hinton, “Semantic hashing,” Int. J. Approx. Reasoning, vol. 50, no. 7, 2009.
40. A. Torralba, R. Fergus, and Y. Weiss, “Small codes and large imagedatabases for recognition,” in CVPR, 2008.
41. M. Raginsky and S. Lazebnik, “Locality-sensitive binary codes from shift-invariant kernels,” in NIPS, 2009.
42. H. Jegou, M. Douze, C. Schmid, and P . P ́erez, “Aggregating localdescriptors into a compact image representation,” in CVPR, 2010.
43. H. Jegou, M. Douze, and C. Schmid, “Hamming embedding and weak geometric consistency for large scale image search,” in ECCV, 2008.
44. A. Babenko and V. Lempitsky, “The inverted multi-index,” in CVPR, 2012.
45. T. Ge, K. He, Q. Ke, and J. Sun, “Optimized product quantization,” Tech. Rep., 2013.
46. M. Norouzi and D. J. Fleet, “Cartesian k-means,” in CVPR, 2013. 47. Y. Kalantidis and Y. Avrithis, “Locally optimized product
quantization for approximate nearest neighbor search,” in in Proceedings of International Conference on Computer Vision and Pattern Recognition (CVPR 2014). IEEE, 2014.
49. D. G. Lowe, “Distinctive image features from scale-invariant key-points,” IJCV, vol. 60, no. 2, 2004.
50. A. Oliva and A. Torralba, “Modeling the shape of the scene: A holistic representation of the spatial envelope,” IJCV, vol. 42, no. 3, 2001.
51. M. Douze, H. Jegou, H. Sandhawalia, L. Amsaleg, and C. Schmid,“Evaluation of gist descriptors for web-scale image search,” in CIVR, 2009.
AUTHORS PROFILE
Dr. Amol Potgantwar has completed Ph.D and is H.O.D of Computer Department, Sandip Foundation, Nashik. The focus of his research in the last decade has been to explore problems at near field communication and its various applications, in particular interested in applications of mobile computing, wireless technology, near field communication, image processing and parallel computing. He has registered 5 patents on indoor localization system for mobile device using RFID and wireless technology, RFID based vehicle identification system and access control into parking, Standalone RFID nad NFC based healthcare system. Since last 5 years he is working with the organization Sandip Institute of Technology and Research Center. His focus has always been on nurturing and guiding the students in different domains and projects.