A Holistic Resource Management for Graphics Processing Units in Cloud Computing
Full text
Figure
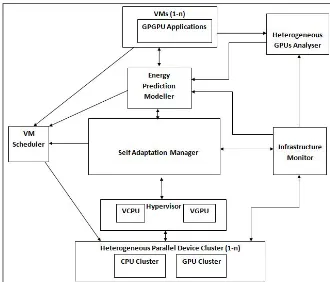
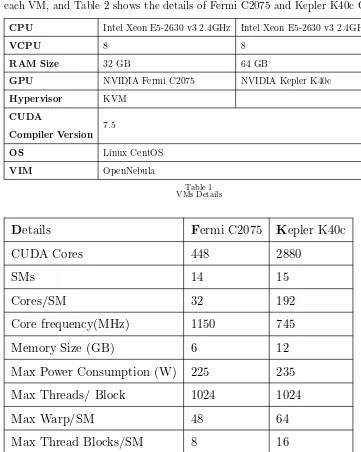
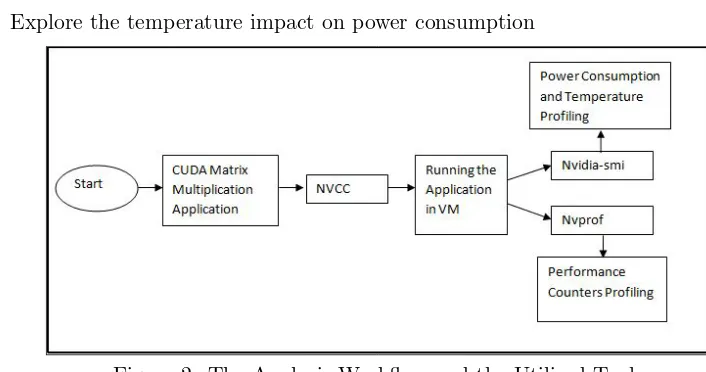
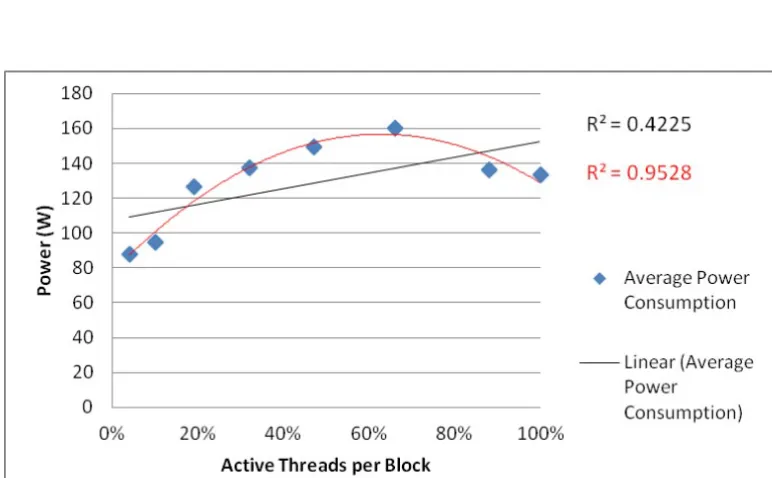
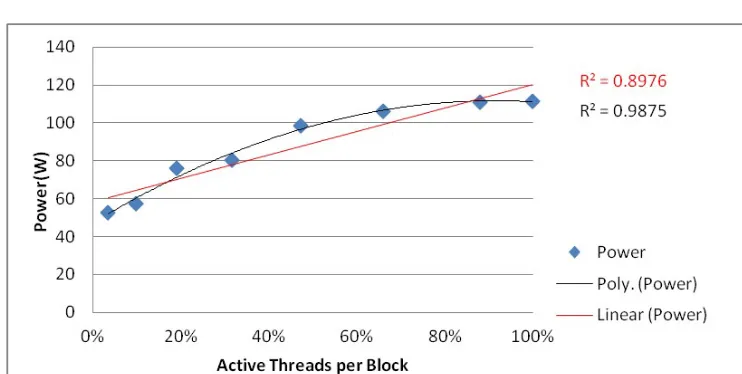
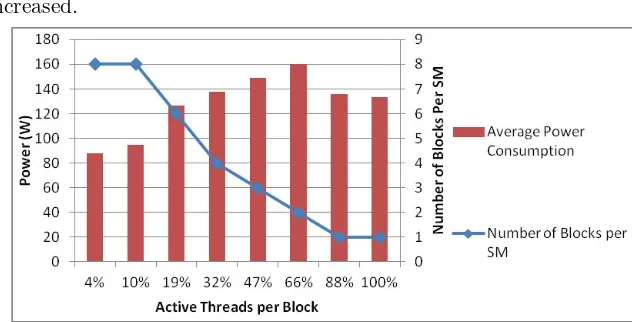
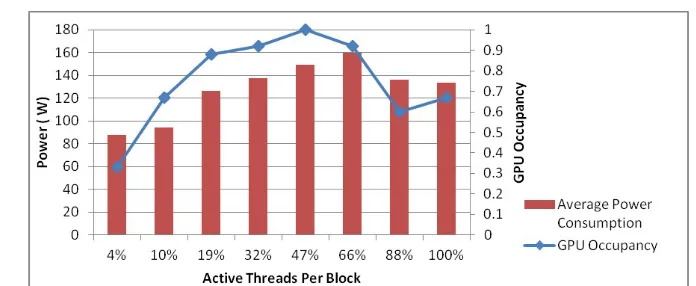
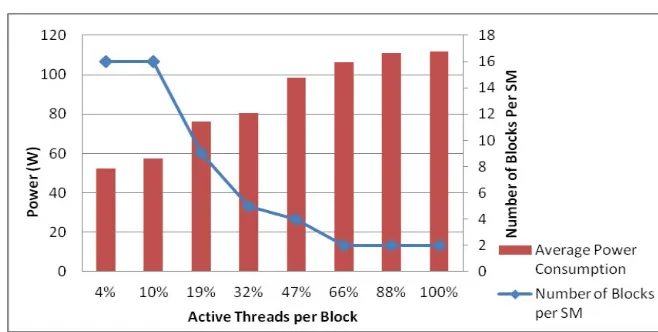


Related documents
a Carmencita identifier (Karmn), spectral type, e ffective temperature, surface gravity, metallicity, v sin i, mass, Ca ii emission flag, and instrument with which the spectrum
The presentation has not been updated since it was originally presented, and does not constitute a commitment by any CDF entity to underwrite, subscribe for or place any securities or
Crew Member Name Position MINOGUE, CHRISTOPHER R Rear Changer D'HONDT JR, EDDIE J Tire Carrier. PETREA, MATT
PETERSHAM Metropolitan Rehabilitation Hospital PORT MACQUARIE Port Macquarie Private Hospital RANDWICK Eastern Suburbs Private Hospital RANDWICK Prince of Wales Private
The present study evaluated the effects of a foliar application of a commercial formulation of cytokinin (6-benzyladenine) during the early stages of seedling development, prior
To examine if the higher sweep net recapture of marked bugs from rows with different release times could be explained by predation, a separate analysis was conducted on sweep
Mesenchymal stem cells (MSCs) which can be isolated from almost all postnatal organs and tissues [23] , are stromal unspecialized cells that have the ability
Figure 6.. In basic Pi calculus, strong / weak bisimulation equivalence have been defined [11], while in Buffer-Pi calculus, the impact which buffer operations bring in need to
