Sketch of Big Data Real-Time Analytics Model
Full text
Figure
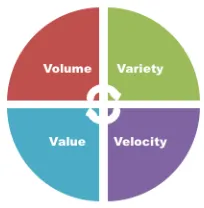
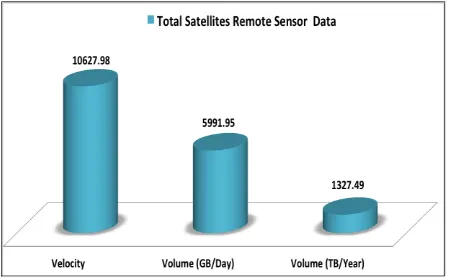
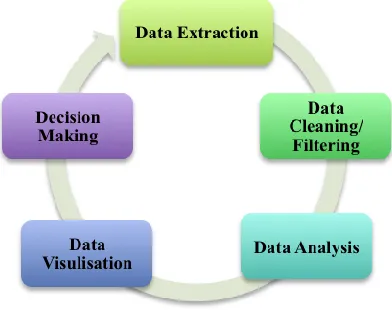
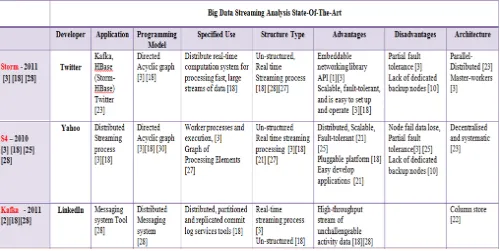
Related documents
The main wall of the living room has been designated as a "Model Wall" of Delta Gamma girls -- ELLE smiles at us from a Hawaiian Tropic ad and a Miss June USC
Hertel and Martin (2008), provide a simplified interpretation of the technical modalities. The model here follows those authors in modeling SSM. To briefly outline, if a
Extrapolating from the 2012 revision time line, the 2017 revi- sion process is likely to commence as early as 2013 (Figure 1), giving the industry ap- proximately two years
Guidelines typically include dictionaries; style manuals; agency instructions concerning such matters as correspondence, or the handling of classified information; and
Discrimination - Minority/Womens’ Business Enterprises (MBE) (WBE) are encouraged to submit bids. The City does not discriminate against any Proposer or
Our results suggest that if the bottom line of the EU proposal were that at least 50% of GHG emissions reductions must be achieved via domestic actions for the Annex I countries as
Note: For all semester system examinations, the exam forms or lists of the students (as the case may be) alongwith fee must be submitted to the University as per the above
Abstract In this paper the well-known minimax theorems of Wald, Ville and Von Neumann are generalized under weaker topological conditions on the payoff function ƒ and/or extended
