International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-8 June, 2019
Abstract: Fraud identification is for the most part seen as information mining order issue, where the goal is to effectively characterize the Visa exchanges as real or false. Despite the fact that misrepresentation recognition has a long history, not excessively much examination has showed up around there. The reason is the inaccessibility of genuine information on which specialists can perform results since banks are not prepared to uncover their touchy client exchange information because of security reasons. Card extortion starts either with the robbery of the physical card or with the tradeoff of information related with the record, including the card account number or other data that would routinely and essentially be accessible to a vendor amid a real exchange. Stolen cards can be accounted for rapidly via cardholders, yet a traded off record can be accumulated by a cheat for a considerable length of time or months before any fake use, making it hard to recognize the wellspring of the tradeoff. The cardholder may not find deceitful use until getting a charging proclamation, which might be conveyed inconsistently. In existing framework, Hidden Markov Model is the measurable devices for architect and researchers to tackle different issues. It is demonstrated that charge card extortion can be recognized utilizing Hidden Markov Model (HMM) amid exchanges. Shrouded Markov Model (SMM) acquires a high misrepresentation inclusion joined with a low false caution rate. The proposed extortion identification demonstrate (Fraud Miner) amid the preparation stage, legitimate exchange example and misrepresentation exchange example of every client are made from their lawful exchanges and misrepresentation exchanges, individually, by utilizing Apriori calculation visit mining. At that point amid the testing stage, the coordinating calculation identifies to which design the approaching exchange coordinates more. In the event that the approaching exchange is coordinating more with legitimate example of the specific client, at that point the calculation returns ‘0’ (i.e., legal exchange) and if the approaching exchange is coordinating more with extortion example of that client, at that point the calculation returns "1" (i.e., fraudulent exchange)Index Terms: Classification Model, Hidden Markov Model, Fraud Miner, Apriori Algorithm, SVM classification
Revised Manuscript Received on June 05, 2019
Dr.V.Vivek, Department of Computer Science & Engineering, Sethu Institute of Technolgy, Virudhunagar, Tamilnadu, India.
Dr.P.Senthil Pandian, Department of Computer Science & Engineering, Sethu Institute of Technolgy, Virudhunagar, Tamilnadu, India.
Dr.R.Rubesh Selvakumar, Department of Computer Science & Engineering, Sethu Institute of Technolgy, Virudhunagar, Tamilnadu, India.
Mr.S.Duraipandi, Department of Computer Science & Engineering, Sethu Institute of Technolgy, Virudhunagar, Tamilnadu, India.
Mr.R.Rajaguru, Department of Computer Science & Engineering, Sethu Institute of Technolgy, Virudhunagar, Tamilnadu, India.
Mr.B.Sivanantham, Department of Computer Science & Engineering, Sethu Institute of Technolgy, Virudhunagar, Tamilnadu, India.
Mrs. Sathish Kumar, Department of Computer Science & Engineering, Sethu Institute of Technolgy, Virudhunagar, Tamilnadu, India.
I. INTRODUCTION
Online Transaction Processing (OLTP) – the catching of exchange and occasion data utilizing innovation to (1) process the data as indicated by characterized business rules, (2) store the data, (3) refresh existing data to mirror the new data. Online Transaction Processing, or OLTP, alludes to a class of frameworks that encourage and oversee exchange situated applications, regularly for information section and recovery exchange handling. The "exchange" isn't just with regards to PC or database exchanges, yet additionally is characterized as far as business or business exchanges. OLTP has likewise been utilized to allude to handling in which the framework reacts promptly to client demands. A programmed teller machine (ATM) for a bank is a case of a business exchange handling application.
Online exchange would be finished by utilizing charge card issued by bank. This exchange might be either Online Purchase or exchange. In both the cases if the card or card subtleties are stolen the fraudster can without much of a stretch do extortion exchanges which will result in considerable misfortune to card holder or bank. On account of Online Fund Transfer a client makes utilization of subtleties, for example, Login Id, Password and exchange secret phrase. Charge card misrepresentation is a wide-going term for robbery and extortion submitted utilizing a Visa or any comparative installment instrument as a deceitful wellspring of assets or exchange. The reason might be to acquire products without paying, or to get unapproved assets from a record. Mastercard misrepresentation is likewise an aide to fraud. The extortion starts with either the robbery of the physical card or the trade-off of information related with the record, including the card account number or other data that would routinely and fundamentally be accessible to a shipper amid a genuine exchange. The trade-off can happen by numerous basic courses and can normally be directed without tipping off the card holder, the vendor or the backer, in any event until the record is at last utilized for extortion. A basic precedent is that of a store agent replicating deals receipts for later use. The quick development of Visa use on the Internet has made database security slips by especially exorbitant; at times, a large number of records have been undermined. Stolen cards can be accounted for rapidly via cardholders, yet a traded off record can be accumulated by a cheat for quite a long time or months before
any false use, making it hard to recognize the wellspring of the trade-off. The
Detection on Credit Card Scam Using Self
Organization Approach with of Support Virtual
Machine Model
cardholder may not find deceitful use until accepting a charging explanation, which might be conveyed rarely. In the current charge card extortion location business preparing framework, deceitful exchange will be recognized after exchange is finished. It is hard to discover false and budgetary loses will be banned by issuing experts. Concealed Markov Model is the factual instruments for architect and researchers to take care of different issues. In this paper, it is demonstrated that Mastercard misrepresentation can be identified utilizing Hidden Markov Model amid exchanges. Concealed Markov Model gets a high misrepresentation inclusion joined with a low false caution rate.
It decides the time allotment framework utilized by the framework to process information. This test is led before usage to exchange decide to what extent it takes to get a reaction to a request, make a reinforcement duplicate of a document, or send a transmission and get a reaction.
It decides if the framework will deal with the volume of exercises that happen when the framework is at the pinnacle of its preparing request. For instance, test the framework by enacting all terminals in the meantime
The charge card misrepresentation discovery framework will not make physical damage clients and nonusers.
The charge card extortion location framework won't impedance outside frameworks or any sort of get into mischief.
Fraud exchange design (fraudster personal conduct standard) for every client and hence changed over the imbalanced Mastercard exchange dataset into a decent one to take care of the issue of awkwardness.
II. RELATEDWORK
V. Bhusari, S. Patil describe that credit card fraud can be detected using HMM during transactions. It helps to obtain a high fraud coverage combined with a low False Alarm Rate (FAR). A HMM each state is linked with a probability distribution. Transitions among these states are governed by a set of probabilities are called transition probability. A possible outcome or observation can be generated which is associated symbol of Probability Distribution (PD). Hence, this HMM is the perfect solution for addressing detection of fraud transaction through credit card.
Priya Ravindra Shimpi, Prof. Vijayalaxmi Kadroli present survey of some most powerful method. In this method a Credit Card Fraud Detection using algorithm is Decision Tree Learning. Although focus on the Information Gain based Decision Tree Learning in this technique estimating the best split of Purity Measures of Gini, Entropy and Information Gain Ratio to test the best classifier attribute. In this
Technique simply find out the Fraudulent
Customer/Merchant through Tracing Fake Mail and IP Address. Customer /merchant are suspicious if the mail is fake they are traced all information about the owner/sender through IP Address. It can find out the Location of the customer and Trace all details.
Salvatore J. Stolfo, Wei Fan, Wenke Lee depict the results played out the use of the JAM distributed certainties digging device for the worldwide issue of extortion recognition in financial actuality framework, modern recognition framework
are considerable to venture forward in halting misfortunes on the account of misrepresentation by means of consolidating one or more displays of fake exchange shared among differenced banks.
Delamaire, L, Abdou, HAH and Pointon, J defines common phrases in credit card fraud and highlights key statistics and figures. Fraud confronted with banks or credit card organizations, numerous measures can be followed. This work likelihood to have useful attributes in terms of financial savings and improved efficiency. This shows the clustering techniques for the behavioral fraud. The peer institution analysis is a device that lets in figuring out money owed that are behaving differently from others at one moment in time whereas they were behaving identically. Fraud analysts is to investigate the instances. The hypo-paper of the peer organization analysis is behave the same for a certain period of time after which one account is behaving substantially differently.
Suman, Nutan presents a survey of current techniques used in credit card fraud detection. Fraud detection methods based on neural network are the most popular ones. An artificial neural network consists of an interconnected group of artificial neurons .The principle of neural network is influenced by the functions of the brain especially pattern recognition and associative memory. The neural network recognizes similar patterns, predicts future values or events based upon the associative memory of the patterns it was learned. It is widely applied in classification and clustering. By employing banks can detect fraudulent use of a card, faster and more efficiently. With the reported credit card fraud studies most have focused on using neural network. In general terms the neural networks are non-linear statistical data modeling tools. It can be used to model the complex relationships between every inputs and outputs or to find patterns in available data.
Renu, Suman describe the purpose of fraud detection, two Bayesian networks to explain the conduct of user is built. First one is a Bayesian community, to build a version conduct beneath the idea that the consumer is Fraudulent and every other version below the idea the user is a legitimate. The Fraud Net (FN) is installation by way of the use of expert understanding. The Consumer Net (CN) is installation by way of the use of records from non-fraudulent customers’. All through operation person net is customized to a particular person primarily based on rising records. Through putting proof in those networks and propagating it via the network, the opportunity of the size ‘x’ less than two above noted hypotheses is obtained. This means, it offers judgments to what degree discovered user behavior meets ordinary fraudulent or non-fraudulent conduct.
Sushmito Ghosh and Douglas L. Reilly discussed about the overall performance of the community in this records set in terms of detection accuracy and earliness of fraud detection. In a rigidly managed check on real world facts from Mellon bank credit card portfolio, a neural community based fraud detection gadget has been proven to provide significant enhancements in each accuracy and timeliness of fraud detection. The feasibility
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-8 June, 2019
stumble on fraudulent patterns on credit card money. It is possible to reap a reduction of 20% - 40% in general fraud losses at substantially reduced caseload for human overview. The Software program enforcing this neural community method to fraud detection has been effectively set up and included into the manufacturing environment on Mellon financial institutions mainframe computer and Mellon is achieving fraud loss reductions consistent with the ones anticipated within.
III. METHODOLOGY
The proposed approach is to prevent fraudulent users’ from misusing the details of the credit card of the genuine users’ for their personal profit. The ways of managing money of the charge card proprietor are distinguishing the extortion. As the phony client probably won't know about the spending propensities for the proprietor, there will be an anomaly in the spending design, which the framework will distinguish. The proprietor is quickly cautioned about the endeavored extortion and the exchange is blocked. Consequently, the framework shields authentic clients from budgetary misfortune. The framework helps in making electronic installment more secure and increasingly dependable. The standards in the proposed framework can likewise be received and executed in other electronic installment administrations, for example, web based financial office and installment entryways.
In the event of Visa misrepresentation discovery the current framework is identify the many frauds has been happen. Existing framework keep up the vast measure of information when client comes to think about irregularity in exchange client made objection and afterward misrepresentation discovery framework begin it working. It first attempts to identify that extortion has really happen after that it begins to follow misrepresentation area, etc. If there should arise an occurrence of existing framework there is no affirmation of recuperation of extortion and client understanding.
Hidden Markov Model
A Mastercard progress likelihood is gotten from likelihood of set exchange of states. For a specific state exchange, conceivable probabilities can be created dependent on progress likelihood. The result which is not obvious to external client and subsequently is called Hidden Markov Model (HMM). For detection of fraud in online transactions using HMM is the perfect solution. Generally HMM classifies states probability into 3 types,
Low
Medium
High.
The aim of the HMM system is to implement an R-Tool which has capability to restrict and block the transaction performing by aggressor from genuine users credit card information.
While registration takes required information which is efficient to detect fraudulent user activity.
This works on transaction behavior of user. By Using HMM, after certain transactions we find one threshold value by using this threshold value we can compare current transaction with threshold value if transaction is quite different from user behavior then check whether it is genuine or fraud OTP (One Time Password) and security questions are used.
Working is quite good after certain transactions (i.e. after 10 transactions).
For particular customer if they performing their transaction then counter ‘C’ will increase after successful transaction.
When Fraud detection phase the user is performing his transactions the counter will be checked. For example if Ci<10 then customers limit will be checked if transaction and limit are nearby then customer will able to perform transactions by filling particular details. If Ci >10 then HMM comes into picture here threshold value generated by HMM will be checked and according to this value further transaction will be handled.
Hidden Markov model steps:
Step1: Read the credit card fraud transaction dataset.
Step 2: Sort the transaction dataset and split the transaction for Credit
Step 3: Create a markov model for transaction amount.
Step 4: Create a class based on baseline score and keeping all transaction feature extract from baseline score
Step 5: Check the transaction state for conversion, path and null state give credit card transaction dataset. The prediction state values is C1 state is 0.55, C2 state is 0.44, C3 state 066 and C4 state is 0.22 display.
Step 6: Create dummy class transaction and check feature credit card transaction state. The state is return value 1 means illegal transaction state for given dataset and return value 0 means legal transaction state for predicted.
Best Match Algorithm
This approach is the best match for calculating the basic most CBRs, arranges a case as either false or clear by choosing the aftereffect of the nearest coordinating case. This calculation is profoundly delicate to case base thickness and populace and for the most part picks the overwhelming by and large sort
proposing that
one another. Earlier measurable examination had just proposed this relationship inside the information. The best match algorithm results in a 90/10 demonstrative split (i.e. 90% acknowledgment) on non-extortion cases, 10% on misrepresentation, inquisitively scores all the more exceedingly on those cases which have not been misused by different calculations (60/35) in the suite.
Data Pre-Processing
Because of affectability and classification of required card holder information required for test and Banks constraint to give this information to test so before beginning Data arrangement stage it's required to have exchanges test system that in charge of mimic exchanges and get ready suitable imbalanced dataset. Information Pre-handling would be required after dataset definition as pursues: (a) Refine information by Remove the exchanges relating to those clients who have just a single exchange in dataset. (b) Segregate exchanges into lawful and misrepresentation exchanges.
Algorithms Implementation and Patterns Creation Prepare an Implementation for Apiriori according to the nature of simulated test data; with lingo attributes should be set within Lingo algorithm:
Set preferred Cluster count Base to 25 as this attribute talk to desired cluster be counted base as a Base element used to calculate the number of clusters based totally on the range of documents on input. The bigger the cost among extra clusters could be created. The variety of clusters created via the set of rules can be proportional to the cluster remember base no longer in a linear manner.
Set group Merging Threshold incentive to be 0.9 as this credit allude to Cluster combining edge. The rate cover between two group's records required for bunches to be converted into one bunches. Low qualities will result in progressively forceful consolidating, which may prompt unessential reports in groups. High qualities will result in less bunches being blended, which may prompt fundamentally the same as or copied groups.
Set forestall word Label filter. Enabled false rather than disabled as this attribute intend to dispose of forestall labels. Gets rid of labels which can be declared as prevent labels in the prevent labels. <lang> files. Please word that adding an extended listing of ordinary expressions to the stop labels file may additionally result in a substantive overall performance penalty.
Set report Assigner minimum cluster length 1 in preference to default 2 that’s determines the minimum wide variety of files in each cluster.
Algorithm
The algorithmic steps illustrating the overall execution process of the system are described below.
Step 1: Initially, a series of n transactions is fed into the training phase as a trained dataset.
Step 2: Process the transactions by determining different attributes of interest.
Step 3: Split the amount of each transaction into k (Transaction State) different ranges.
Step 4: Count the number of transactions falling into each
range (Transaction state).
Step 5: Further, this is used to generate a user details file illustrating the account number from which the transaction is made, the total number of transactions done by each account holder, and the average amount of all the transactions made. Step 6: Form clusters of each user on the basis of its prior transactions.
Step 7: It groups the users by considering the transactions made by each user based on the account number from which the transaction has taken place, the IP address of the account holder, the country from which the transaction is made, the account number to which the transaction is made and the country of the recipient’s account holder..
Step 8: Calculate the anomaly score for each user as well as the anomaly score for each of the transaction made by each user.
Step 9: Sort the anomaly scores in decreasing order. Step 10: The anomaly score with the highest value is considered as being abnormal and should be suspected by the analyst
Classification Using Support Vector Machine
An SVM classifier classifies records through locating the first-rate hyperplane that separates all statistics points of one magnificence from those of the opposite magnificence. The great hyperplane for an SVM means the only with the largest margin among the two instructions. Margin approach the maximal width of the slab parallel to the hyperplane that has no indoors records factors. The support vectors are the records factors that are closest to the isolating hyperplane; those factors are at the boundary of the slab. As with any supervised getting to know version, first train a help vector device, and then move validate the classifier. Use the skilled device to classify (predict) new facts.
Similarly, to gain first-rate predictive accuracy, various SVM kernel capabilities are used, and must tune the parameters of the kernel capabilities. SVM is educated with the featured set of indices and the class vector. Teach information refers back to the statistics to receive for education which the transactions of the dataset are and the elegance information refers back to the magnificence kind i.e. legal or fraud. Education is the system of taking content this is known to belong to designated classes and creating a classifier on the foundation of that regarded content.
The preparation is performed by giving the information contentions. The information is given as preparing information with each line compares to the exchange and every section speaks to the qualities. The following contention is the gathering variable which alludes to the class vector demonstrating legitimate or extortion. To outline information to include space for discovering hyper planes the portion capacities are must. There are numerous part capacities are accessible including direct, Gaussian and spiral premise work.
The default one is linear and inside the proposed work linear kernel has been used because the dataset attributes are of small and it is able to faster do the training as compared to nonlinear kernels. As the
proposed work consists of
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-8 June, 2019
(criminal/fraud) it's far excellent to use linear kernels for linearly separable data. Linear kernel reveals the dot product if you want to locate the maximal hyperplane for isolating the records. Schooling is the system of taking content material this is recognized to belong to certain classes and developing a classifier on the idea of that known content material. The training is executed right here via giving the enter arguments. The input is given as schooling facts with every row corresponds to the transaction and every column represents the attributes.
The subsequent argument is the grouping variable which refers to the magnificence vector indicating criminal or fraud. To map the facts to feature area for locating hyper planes the kernel capabilities are should. There are many kernel features are to be had along with linear, Gaussian and radial foundation characteristic. The default one is linear and within the proposed paintings linear kernel has been used as the dataset attributes are of small and it could quicker do the schooling in comparison to nonlinear kernels. As the proposed work includes handiest 2 training (criminal/fraud) it is exceptional to use linear kernels for linearly separable facts. Linear kernel unearths the dot product for you to locate the maximal hyperplane for setting apart the statistics.
SVM Classification:
Step 1: Read the transaction dataset
Step 2: Create the SVM class base prediction model using e107 package.
Step 3: The SVM model check a credit card transaction state similarity.
Step 4: The results shows, prediction state from SVM model using linear sequences process.
Step 5: Repeat step 2 to 4
Step 6: To calculate TP,TN,FP and FN state and return the accuracy values.
Step 7: Similarity finding for legal and illegal transaction data.
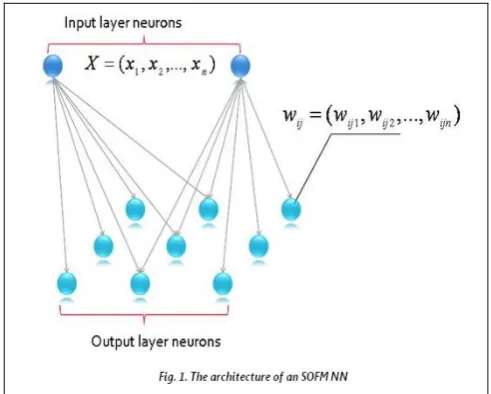
Self-Organized Feature Maps
[image:5.595.303.549.49.246.2]The proposed system implements all the existing system methodologies. Instead of using DBN, Self-Organized Feature Maps are used for classification. The Self-prepared feature Maps includes layers of neurons showed in Figure 1. The first layer isn't always virtually a neurons layer, it best gets the enter records and transfers it to the second one layer. Allow us to keep in mind the simplest case, while neurons of the second layer are blended right into a two-dimensional grid.
Figure 1: Self-Organized Feature Map (2D) Every neuron of the 0.33 layer connects with each neuron of the second layer. The wide variety of neurons within the second layer can be selected arbitrarily, and differs from undertaking to venture. each neuron of the second one layer has its very own weights vector whose dimension is same to the dimension of the enter layer. The neurons are related to adjacent neurons by means of a community relation, which dictates the topology or structure of the map. One of these community relation is assigned by a unique feature referred to as a topological community. In the starting of the functioning, all weights vectors of the second one layer’s neurons are set to random values. After that, some input-vector from the set of getting to know vectors is chosen and set to the enter of the NN. At this step, the differences between the input vector and all neurons vectors are calculated as follows:
Where, i and j are the indices of neurons inside the output layer. After that, the NN chooses the winner neuron, (i.e., the neuron whose weights vector is the most just like the enter vector).
Where, k1 and k2 are records of the victor neuron. Presently, we have to make an amendment of the loads vectors of the champ and all the nearby neurons. The area of a neuron is controlled by a topological neighborhood work.
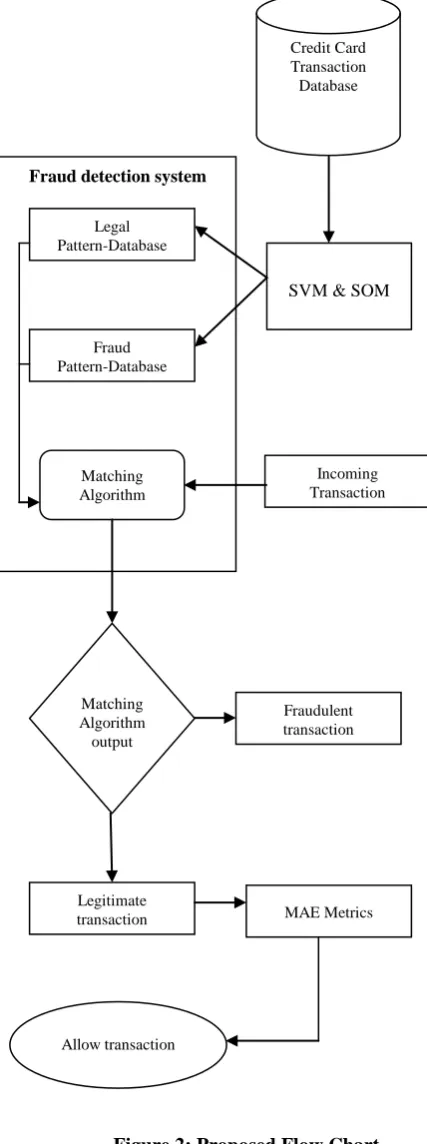
Figure 2: Proposed Flow Chart
IV. EXPERIMENTRESULT
A. DATA SET INFORMATION
This exploration went for the example of clients default installments in Taiwan and thinks about the prescient exactness of likelihood of default among six records mining strategies. From the point of view of hazard the board, the aftereffect of prescient exactness of the evaluated likelihood of default can be extra giant than the twofold result of grouping - trustworthy or not valid clients. Due to the fact that the genuine probability of default is difficult to understand, this exam exhibited the novel Sorting Smoothing approach, to
evaluate the genuine chance of default.
With the real probability of default because the response variable (Y), and the prescient probability of default as the unfastened aspect (X), the truthful direct relapse result (Y=A+BX) demonstrates the estimating model created with the aid of counterfeit neural system has the maximum expanded coefficient of assurance; its relapse block (An) is close to zero, and relapse coefficient (B) to 1. On this manner, a number of the six records mining strategies, counterfeit neural system is the special case that could precisely assess the genuine chance of default.
Attribute Information:
This examination utilized a double factor, default installment (Yes=1, No=zero), as the response variable. These watches audited the writing and utilized the accompanying 23 factors as illustrative factors:
X1: Amount of the given credit (NT dollar): it includes both the individual consumer credit and his/her family (supplementary) credit.
X2: Gender (1 = male; 2 = female).
X3: Education (1 = graduate school; 2 = university; 3 = high school; 4 = others).
X4: Marital status (1 = married; 2 = single; 3 = others). X5: Age (year).
X6 - X11: History of past payment. We tracked the past monthly payment records (from April to September, 2005) as follows: X6 = the repayment status in September, 2005; X7 = the repayment status in August, 2005; . . .;X11 = the repayment status in April, 2005. The measurement scale for the repayment status is: -1 = pay duly; 1 = payment delay for one month; 2 = payment delay for two months; . . .; 8 = payment delay for eight months; 9 = payment delay for nine months and above.
X12-X17: Amount of bill statement (NT dollar). X12 = amount of bill statement in September, 2005; X13 = amount of bill statement in August, 2005; . . .; X17 = amount of bill statement in April, 2005.
X18-X23: Amount of previous payment (NT dollar). X18 = amount paid in September, 2005; X19 = amount paid in August, 2005; . . .;X23 = amount paid in April, 2005.
B. PERFORMANCE MEASURES
Every example is assessed into lessons in a binary category model. The 2 instructions are genuine and fake class. This gives upward push to 4 possible classifications for every instance particularly:
True Positive (TP): The number of correct predictions that an instance is positive.
False Positive (FP): The number of incorrect predictions that an instance is positive.
False Negative (FN): The number of incorrect predictions that an instance is negative.
True Negative (TN): The number of correct predictions that an instance is negative.
This situation may be depicted as a confusion matrix
additionally called
contingency desk as proven in table 1 below.
Credit Card Transaction Database
SVM & SOM Fraud detection system
Legal Pattern-Database
Fraud Pattern-Database
Matching Algorithm
Incoming Transaction
Matching Algorithm output
Fraudulent transaction
Legitimate transaction
Allow transaction
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-8 June, 2019
Table 1: Confusion matrix
Observed True False
Fraud Prediction
state
True True Positive True Negative
False False
Positive
False Negative The observed classifications for a phenomenon are in comparison with the anticipated classifications of a version in a confusion matrix. In table 1 the class which can be shown alongside the fundamental diagonal of the table are the appropriate classifications refereed as genuine positives and actual negatives. The version mistakes are signified by using the alternative fields. Simplest the real superb and proper negative fields would be filled out for a perfect model and the alternative fields could be set to 0. From the confusion matrix, a number of model performance metrics may be derived. In this state describe an evaluation metrics for credit card fraud prediction state.
The table 4.2 describes Performances analysis for credit card fraud Prediction State for HMM model. The table contains number of dataset attribute and fraud classification values details show,
Table 2: HMM- State Classification S. No Credit Card
Attribute TP TN FP FN
1 X1 T T F F
2 X2-X5 T F F T
3 X6-X11 T T F F
4 X12-X17 T F T F
5 X18-X23 F T F F
The table 2 contains T values is 1 and F values 0 in binary classification model. The HMM model for return value of most true positive and true negative values.
The table 3 describes Performances analysis for credit card fraud Prediction State for SVM model. The table contains number of transaction dataset attribute and fraud classification values details show,
Table 3: SVM - State Classification S.
No
Credit Card Attribute
T
P TN FP FN
1 X1 T T T F
2 X2-X5 T F T F
3 X6-X11 T T F F
4 X12-X17 T T T T
5 X18-X23 T T F T
The table 3 contains T values is 1 and F values 0 in binary classification model. SVM model is returning the value of most True Positive, True Negative, False Positive and False Negative state values.
Table 4: HMM- State Accuracy
The table 4 describes Performances analysis for credit card fraud accuracy values for HMM model. The table contains number of dataset attribute and accuracy values details show,
[image:7.595.313.555.56.157.2]The table 5 describes Performances analysis for credit card fraud accuracy values for SVM model. The table contains number of dataset attribute and accuracy values details show,
Table 5: SVM- State Accuracy
The table 6 and Fig. 3 describes Performances analysis for credit card fraud accuracy values for HMM and SVM model. The table contains accuracy values of HMM and SVM model
[image:7.595.303.548.257.640.2]details show,
Table 6: Binary Classification HMM and SVM model Binary
Classification HMM
SVM Model
True Positive 0.2023 0.2357
True Negative 0.1982 0.2214
False Positive 0.1998 0.2928
False Negative 0.2012 0.2357
Binary Classification HMM and SVM model
0 0.05 0.1 0.15 0.2 0.25 0.3 0.35
True Posi
tive
True Neg
ative
False Posi
tive
False Neg
ative
Class
A
cc
u
ra
cy
HMM SVM Model
Figure 3: Binary Classification HMM and SVM model The proposed approach were tested on various varieties of transactions with similar formatting and obtained encouraging results and experimental results show that proposed approach outperforms the present technique. The results indicate that the method using efficient clustering and classification algorithms has the efficiency to discriminate between legal and fraudulent transactions of each user and detect the fraudulent transactions.
S. No
Credit Card Attribute
TP TN FP FN
1 X1
0.2023 0.1982 0.1998 0.2012
2 X2-X5
3 X6-X11
4 X12-X17
5 X18-X23
S. No
Credit Card Attribute
TP TN FP FN
1 X1
0.2357 0.2214 0.2928 0.2357
2 X2-X5
3 X6-X11
4 X12-X17
[image:7.595.47.292.335.464.2] [image:7.595.45.255.540.675.2]V. CONCLUSION
This paper has discussed on credit card fraud detection system. Data mining techniques is applied for credit card fraud detection process .Fraud/Legal Pattern creation for each customer facilitate customer profile detection not only for normal behavior but also fraudster behaviors on his account and this made fraud detection easier. Also, the Apiriori algorithm proved to be used to create Legal/Fraud patterns for each user .By using simulated test transactions, it’s found that Apiriori algorithm generate meaningful summarized patterns more than output patterns from Apriori Algorithm.
Fraud sample creation enables fasten fraud detection manner and could be used to verify transaction near real time transactions. In line with comparison results of proposed model, better Fraud Miner algorithm to attain exact improvements especially with the excessive critical degree of fake alarm charge that could reduce more inside the proposed model .therefore; it is far observed that improvements had been made on algorithm exceptional that represents from SVM model.
The proposed method has been extensively tested on different types of transactions. The outcomes were promising, practically all the deceitful exchanges could be recognized effectively and the proposed technique have been contrasted and the current strategy and the outcome demonstrates that the proposed technique performs superior to existing strategies. In this research, fraudulent transactions have been detected and recognized which illustrates the robustness of the proposed system. This proposed method enables the transaction at various types and improves the clustering process, which can significantly improve the classification and detection performance. The proposed system gives the following advantages are,
Propelled information mining methods utilizes bolster vector machines for Mastercard misrepresentation identification. Here this desk work utilizes test dataset with much lower extortion rate (0.5%) than preparing dataset with various dimensions of under inspecting.
SVM predicts 94.3% customer correctly, only 6.7% true bad customer are predicted as good customer and 13.3% true good customer are predicted as bad ones.
On the whole, the system is successful on achieving its objectives and can be utilized for automatic extraction, detection and recognition of credit card fraudulent transaction. The fraud detection and recognition technology itself seems to have reached a certain maturity. no longer with status numerous demanding situations in utilizing the Visa misrepresentation identification frameworks in proper programs, the significance and helpfulness of this field continues on pulling in a lot attention. Further research can be directed to the following topics. The future work suggested applying frequent item set as Enhanced Apriori and SVM algorithm are,
Accomplishing very rapid clustering over large snippets of credit score card information, improving cluster label satisfactory.
Hierarchical Clustering promotes specific transaction or transaction information set inside the output cluster labels. Defining companies of credit card transaction records have been dealt with as synonymous with superior results tuning.
REFERENCES
1. Aman Angrish, Extraction of Text from Noisy Scanned Images, Dissertation Report, Punjabi University, 2007.
2. Bhusari S. Patil, “Study of Hidden Markov Model in Credit Card Fraudulent Detection”, International Journal of Computer Applications Vol. 20, No. 5, April 2011.
3. Priya Ravindra Shimpi, Vijayalaxmi Kadroli Angrish, “Survey on Credit Card Fraud Detection Techniques”, International Journal of Engineering and Computer Science. Sep. 2012, (2319-7242). 4. Salvatore J. Stolfo, Wei Fan, Wenke Lee, “Cost-based Modeling for
Fraud and Intrusion Detection Results from the JAM Project”, In Proceedings of the ACM SIGMOD Conference on Management of Data, PP. 207–216, January 2014.
5. Delamaire, L, Abdou, HAH and Pointon, J,”Credit card fraud and detection techniques”, Banks and Bank Systems, Vol. 4, No. 2, 2009. 6. Suman, Nutan, “Review Paper on Credit Card Fraud Detection”, International Journal of Computer Trends and Technology. Vol. 4 Issue No. 7. July, 2013.
7. Renu, Suman, “Analysis on Credit Card Fraud Detection Methods”, International Journal of Computer Trends and Technology, Vol. 8, No. 1, Feb. 2014.
8. Sushmito Gosh and Douglas L. Reilly, “Credit Card Fraud Detection with a Neural Network” Proc. IEEE First Int. Conf. on Neural Networks (2014).
9. Deepak Pawar, Swapnil Rabse, Sameer Paradkar, Naina Kaushi, “Detection of Fraud In Online Credit card Transactions”, International Journal of Technical Research and Applications (2320-8163). 10. Mohamed Hegazy1, Ahmed Madian, Mohamed Ragaie, “Enhanced
Fraud Miner: Credit Card Fraud Detection using Clustering Data Mining Techniques”, Egyptian Computer Science Journal (1110 2586), Vol. 40, No. 3, Sep. 2016.
AUTHORSPROFILE
Dr.V.Vivek is an active analyst and Researcher in the field of Face Recognition, Intelligent systems and DBMS, He received his Ph.D. in Computer Science & Engineering, Manonmaniam Sundaranar University-Tirunelveli on May, 2018. Done his M.E. (CSE) in the same University in the year of 2014. Completed his B.Tech (IT) in Anna University, Chennai, and Tamilnadu. Currently he is working as an Assistant Professor (Senior Grade) in the Department of Computer Science & Engineering at Sethu Institute of Technology, Virudhunagar, and Tamilnadu, India. He has published 14 papers in various International Journals.
Dr.P.Senthil Pandian, received the M.E. (Computer Science & Engineering) from Anna University, Trichy, in 2009, He received his Ph.D. from Anna University, Chennai in the year 2016. His interests include Web Mining, IoTand Data Analytics. He has published 18 papers in various International Journals.
Dr.R.Rubesh Selvakumar, received the M.E. (Computer Science & Engineering) from Anna University, Chennai, in 2005, He received his Ph.D. from Anna University, Chennai in the year 2016. His interests include image processing, signal processing and neural network. He has published 7 papers in various International Journals.
Mr.S.Duraipandi, is Completed his M.E Computer Science & Engineering in Anna University, Tamilnadu, India. He has completed her Bachelor’s in Engineering at Anna University, Chennai. He has published more papers in reputed conferences and journals.
Mr.R.Rajaguru is currently pursuing Ph.D. in Anna University, Chennai. His area of Research includes Wireless Communication, Cognitive Radio Networks and Security. He is having 7
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-8 June, 2019
he is working as an Associate Professor in the Department of Computer Science & Engineering at Sethu Institute of Technology, Virudhunagar, and Tamilnadu, India
Mr.B.Sivananthan, Assistant Professor, Department of Computer Science and Engineering, Sethu Institute of Technology. He Obtained his Undergraduation B.Tech in Information Technology and Postgraduation M.E in Computer Science and Engineering. His research ares in the field of load balancing, user management in Cloud Computing.