International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-7, May, 2019
Abstract: Cloud computing enables the empowers professional clients to scale over the resource utilization dependent on cloud user requirements. Virtualization techniques are necessary for cloud environment to multiplexing the cloud resources. Here, virtualization techniques are used to allocate the cloud resources dynamically based on cloud user requirements. This paper consider green computing techniques has used for improving the quantity of servers. This paper considers the term” skewness” to improving the quality of service for server based on findings roughness with several dimensional strengths. Here we propose an algorithm names as Resource allocation using virtual machine with heterogeneous techniques. This algorithm helps to allocate the resources efficiently to the cloud users based on their needs. The results of this algorithm has compared with existing algorithm like skewness-avoidance multi-resource allocation (SAMR). Finally, this algorithm improved 67% of results in view of CPU utilization and 47% reducing memory consumption.
Index Terms: Skewness, Resource, Heterogeneous, Migration.
I. INTRODUCTION
Public clouds models have involved abundant responsiveness from mutually business industry and academic circles in lately. The resistance and the absence of open principal asset obtainable by Cloud Computing platform are attractive to numerous big productions. Based on cloud prototype different thought of discussion for benefits, costs, and requests against the cloud stage. We found the cloud data center often rigorously under-utilized or over utilized the physical hardware-based on-demand and utilization of hardware saves the electricity outlays in the huge cloud data center. Virtual machine monitors (VMMs) is a device for recording between corporal possessions through virtual machines. The cloud service worker to make certain the sufficient resources causal Physical machines (PMs) take to see their cloud user desires. Virtual machine conscious passage technology it’s a kind of planning among VMs and PMs while requests are running.In any case, a strategy subject rests as how to determine the plotting of flexible with the goal that the strength desires of virtual machines are encountered the measure of physical machines exploited is imperfect. This is challenging when the strength wants of virtual machines are mix since the different arrangement of usages they route and shift with time as the outstanding tasks
Revised Manuscript Received on May 10 ,2019
.Dr.T. SENTHIL MURUGAN, Associate Professor, School of Computing, Department of Computer Science & Engineering, Vel Tech Rangarajan Dr.Sagunthala R&D Institute of Science & Technology, Avadi, Chennai, India-600062.
N. VIJAYARAJ, Research Scholar, School of Computing, Department of Computer Science & Engineering ,Vel Tech Rangarajan Dr.Sagunthala R&D Institute of Science & Technology, Avadi, Chennai, India-600062.
at hand develop and therapist. The bound of PMs can equally be as sorted in light of the statistic that plentiful ages of tackle coincide in a server farm.
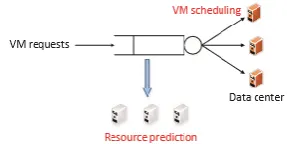
We object to an accomplish three goals in our procedure: • Load balancing: Physical machine capacity should be adequate to fulfill the wants cloud resource of all Virtual machines or else, performance of the Physical machine is over utilized or under-utilized VMs. • Green Computing: The quantity of physical machines utilized ought to be limited as extensive as they can in any case achieve the necessities of all VMs. Inert PMs can be killed to spare vitality. There is an inborn exchange off amongst the two objectives even with changing asset needs of VMs. For over-burden shirking, we should retain the use of PM slow to decrease the likelihood of over-burden on the off casual that the asset wants of VMs increment future. For green processing, we should retain the usage of physical machines sagely high to style productive consumption of their vitality. • Resource prediction and allocation. Cloud user can detriment from cloud server through elastic, scalable and cost-effective of resource utilizations. In this paper, we propose and implement to archives the automated resource management in cloud platform. It achieves the three goals. Are serves upper visions chemist can avoid the excess surplus, efficiently reduce the usage, improve the overall consumption of cloud server used by concept of skewness method and prediction method can determine the usage of resource for forthcoming usage of cloud platform.Amazon EC2, Rackspace cloud is a public cloud resource allocation in IaaS. It effectively allocates the resource scheduling and provisioning in cloud platform. Homogeneous resource allocation is a present work of cloud provider for allocating virtual machine with physical machine capacity. The heterogeneous resource allocation determines the various difficulties for allocation of resource. Cloud user approach the high demand and low demand for the specific resources among various resources. So complexity of resource allocation very difficult among the cloud platform and high computational power required for homogeneous based resource allocation which is expressively rise the complexity also rapidly change the cloud user job performance.
2.Related work
Hongbing Wang [1] introduced the suitability empowered public sale method for allocating cloud reserve amongst cloud service benefactor and cloud operator which guarantees for fitness in terms of performance traits.
Skewness Based Dynamic Resource Allocation
The allocating algorithm taking the constraints of financial effectiveness, organization presentation and researches have given the results stating that the distribution is far more effective in comparing it with the incessant dual public sale in which the knowledge of suitability is not announced. Cloud reserve allocating algorithm via fitness enabled auction (CRAA/FA) it has dealt and introduced a original measure like fitness, original enquiring/command approach, active bartering prototype, auction theory, and equivalent price and scheming the closing selling worth and revenue.
Auction theory can be confidential by four elementary kinds like rising public sale, downward public sale, initial worth and additional worth wrapped public sale and the duple public sale. Cloud environment with a combination of Cloud services and cloud resources has identified three types of service features like Type-1, Type-2 and Type-3 service for QoS. Type-I service includes the mandatory retort period Tj RST and proportion of provision request n it permitted to mandatory retort spell. Type-II services are assigned with deadlines and user request are satisfied within the prescribed time limit. Type-III services in turn don’t restricted with any deadline but has been successful in dealing the user request in a short span of time. All the Type-I, Type-II and Type-III services are classically based on the OLTP and OLAP services. These types of service have given the better QoS which eliminates the bottleneck problem in deploying the cloud environment. Fitness and equivalent price are argument.
Fitness mainly contributes in analysing the cloud services which in turn monitors the level of Cloud Resource consumption in the cloud environment [2]. Equivalent prices together with the fitness provide the higher fitness value associated with the cloud services, cloud resources, cloud user and auctioneer of cloud environment. The active bargaining set is calculated and inspected over the fitness which is based in equivalent price in terms of some auctioning process. Finally, they concluded the overall market efficiency with fully improvement as it’s shown more efficient than the allocating methods. However, this algorithm is not suitable for thousands or ten thousand of servers due to the restraint in exploration capital. Moreover, it is unbearable to research extra than a thousand servers or practical machine. The future enhancement has proposed the oligopoly and monopoly algorithm that may overcome the above limitation.
Zhen Xiao et al., [4] have anticipated lively supply provision method based on the application demands using the virtualization technology together with the data centre adopted by green computing with optimized quantity of servers. The writers have also familiarized the multidimensional resource utilization of a server for unevenness of resource in terms of “skewness” which improves the performance utilization of the server workload and prevents and saves the energy used. Physical resources are mapped with virtual machine and that are monitored by the virtual machine monitor (VMM). Data centre enclosed with different generation hardware for heterogeneous Physical machine (PM). Their proposed work achieved with binary areas like excess evasion and green computing. Excess evading works in the sense of using the effective
utilization of the physical machine to satisfy the cloud user and the needs of cloud service provider. Green computing primarily is used to found the idle PMs and turned off the same to minimize the energy. The skewness algorithms periodically evaluate the resource allocation by using hot and cold spots methods. Irrespective of both the hot and cold spots, it is mainly used for utilization of resource in case if idle resources should be turned off. Finally, they have concluded, stating that the skewness algorithm is well implemented in achieving the overall avoidance and it is well effective of using the green computing for monitoring the utilization of all resources.
Xingwei Wang et al., [6] introduced multiple cloud users that can facilitate multiple cloud providers by accessing and enabling the combinatorial double auction protocol with a new bright financial method for lively reserve distribution (IEDA). Now a day's Cloud resource allocation is very competitive in the real world. Variant cloud services such as distributed Cloud, inter cloud and open cloud exchange (OCX) are considered as emerging methods and it’s been implemented in the resource allocation. Price matching algorithm and price prediction algorithm are used for different mechanisms such as price formation, bidding and multi round auction which in turn is used to determine the suitable transaction with provider and customer which is comprised of back prolife ration neural network (BPNN) founded on worth matching and forecast procedure [11]. This proposed method resulted as unfair with the participants from the cloud market, in order to overcome such anomalies paddy field algorithms (PFA) were implemented with winner determination problem (WDP). Combinatorial double auction protocol is used for tender description in terms of cloud service consumer tender (CSC) and cloud service provider tender (CSP).
3.Proposed methodology
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-7, May, 2019
We accept completely physical machines segment a backend stockpiling. The multiplexing of virtual machines to physical machines is overseen utilizing User structure [7]. The primary rationale of our framework is actualized by way of a lot of modules to User. Each hub turns a Use neighborhood hub chief (LNM) on space0which gathers the use insights of assets for individually VM on that hub. The Central Processing Unitand the system utilization can be determined by observing the booking occasions in Xen. There membrane uses inside a VM, be that as it may, isn't noticeable to the hypervisor. Unique procedure is to construe remembrance lack of a virtual machine by view in gets exchange exercises [8]. Lamentably, the visitor OS is compulsory to introduce a different trade segment. Besides, it might be past the point where it is possible to alter the memory designation when swapping happens. Rather we actualized a waged set prober on each hypervisor to gauge the occupied set sizes of virtual machines consecutively on it. We utilize the arbitrary folio testing system as in the VMware ESX Server [9].
The Scheduler has a few parts. The indicator forecasts the upcoming asset needs of VMs and the future heap of PMs dependent on previous insights. We progress the heap of a PM by collecting the asset operation of its VMs. The subtleties of the heap forecast calculation will be depicted in the following area. The LNM at every hub initially endeavors to fulfill the original applications locally by modifying the asset portion of VMs having the equivalent VMM. The MM Allotter on area 0 of every hub is in charge of modifying the nearby recall distribution.
The problem area solver in our VM Scheduler identifies if the asset custom of any PM is over the hot edge. Assuming this is the case, some VMs consecutively on them will be moved absent to reduce their heap. The virus spot solver checks if the normal use of effectively utilized PMs is underneath the green figuring edge. Provided that this is true, a portion of those PMs could possibly be killed to spare vitality. It distinguishes the arrangement of PMs whose use is underneath the chilly limit and after that endeavors to relocate away all their VMs. It at that point assembles a movement rundown of virtual machines and passes it to the user control for performance.
We deliberate the situation where cloud clients lease VMs from IaaS open mists to track their requests in a compensation as-you-go way. Cloud suppliers care clients as indicated by the asset sums and consecutively spell of VMs. Fig 2 demonstrates the framework prototype of our future heterogeneous asset allotment method SAMR. By and large, we expect that a cloud server farm with N total PMs proposals K distinctive asset kinds. The cloud framework proposals X diverse VM sorts, every one of which is with an asset mix V~x = fvx I ji = 1; 2; Kg (x = 1: 2; :::;X) where vx
I signifies the asset limit of ith+ asset kind in xth VM sort. Cloud clients present their VM asks for (additionally signified as remaining tasks at hand in this paper) to the cloud server farm as per their heterogeneous asset requests and pick the VM types that are most proper as far as fulfilling the client requests while limiting the asset wastage. We allude a demand for x th kind of VM as a sort x ask for in outstanding tasks at hand. All VM asks for are kept up by a booking line. For each demand from clients, asset timer allots the assets for asked for virtual machine in N existing dynamic PMs uncertainty the asset opening of the VM is accessible. Something else, the demand resolve be postponed trusting that extra PMs will control active and join the administration. As indicated by the landing charges and administration charges of solicitations, SAMR manners asset expectation dependent on a Markov Chain display intermittently in each schedule vacancy with a span of t to fulfil the client involvement regarding VM designation delay. By such way, Centre around taking care of the issue in a little time span to expand the forecast exactness. Later the working expectation of obligatory assets, the could framework arrangements comparing sum of dynamic PMs N in the future schedule vacancy. In VM booking stage amid apiece availability with the length t, cloud suppliers apportion assets and host each VM into PMs utilizing SAMR allotment calculation. In cloud administration, a standout amongst the most noteworthy effects on client experience is the administration stay brought about by schedulers. Here we think about the asset distribution stay as the primary measurement for administration stage-understandings among clients and cloud suppliers. In particular, SAMR utilizes a VM designation defer limit D to be the most extreme SLA esteem that cloud suppliers ought to follow. Accordingly, there is an exchange off among expense and SLA for cloud suppliers. To adapt to the substantial measure of arbitrary demand entries from clients, it is imperative to arrangement enough dynamic PMs. Nonetheless, keeping up such a large number of dynamic PMs may adapt well even under pinnacle load however squanders vitality superfluous. Keeping up too couple of PMs may cause noteworthy corruption in client experience because of absences of dynamic PMs and the need to sit tight to control up more PMs. It is trying to locate the satisfactory quantity of dynamic PMs.
4. Experimental and results
Our analyses are led utilizing a gathering of 30 Dell Power Edge sharp edge servers with Intel E5620 Central Processing Unit and 24 GB of RAM. The servers run Xen-3.3 and Linux 2.6.18.We occasionally perused burden insights utilizing the GenStat public library. The servers are associated over a GB Ethernet to a gathering of 4NFS stockpiling attend ants wherever our VM Scheduler runs. We utilize a similar evasion parameter as in the reproduction.
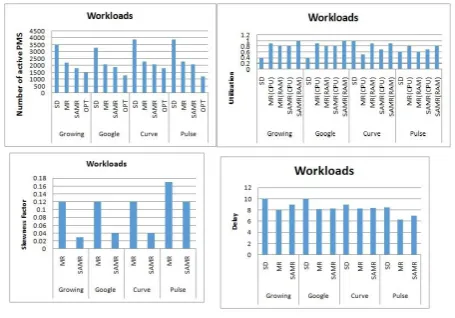
[image:3.595.91.235.558.630.2]The bars in the figure demonstrate the normal qualities for various outcomes and the upright sore outlines show the 95%confidence interims.
Fig. 3. Metrics results under 4 workloads.
We mention the accompanying objective facts dependent on the outcomes. Right off the bat, heterogeneous asset the board strategies (MR and SAMR) significantly lessen assets as far as number of dynamic PMs for similar outstanding tasks at hand. AsshowninFig.3(a), the supply maintenance attained by MR contrasted and SD is around 34% for every one of the four remaining burdens. SAMR supplementary lessens the compulsory sum of PMs by extra 11%, or about 45% contrasted and SD. It demonstrates that SAMR can adequately diminish the asset use by keeping away from asset starvation in cloud server farm. Plus, the quantity of dynamic PMs for SAMR is very near the ideal arrangement with just 13% contrast. Besides, in spite of the fact that the use of overwhelming asset utilizing SD technique is tall as appeared in Fig. 3(b), the non-prevailing assets are under-used. Be that as it may, the asset usages in MR and SAMR strategies are adjusted. This is the motive that SD must arrangement more PMs. Thirdly, the adequacy of asset assignment in SAMR is approved by the skewness factor appeared in Fig. 3(c), where the normal asset skewnessaspects in SAMR technique are not as much as that
in MR. At long last, entirely3
rulesattainthepredefinedVMdistributionsuspension edge by way of appeared in Fig. 3(d). SDgrasps slightly advanced normal postponements than SAMR and MR, which is because of the way that SD dependably responds gradually to the remaining task at hand dynamicityand root increasingly underneath-provisionedgearstostyle the defer lengthier.
Fig. 4. Comprehensive consequences of three measures beneath 4 job outlines
Effects by the measure of outstanding tasks at hand. Fig. 4 demonstrates the point by point consequences of all techniques for various measurements under four outstanding tasks at hand. We feature and dissect the accompanying marvels in the outcomes. Initially, heterogeneous asset portion strategies significantly diminish the obligatory sum of PMs in individually availability for 4 remaining burdens by way of in figures above from a to d. As in e to h we can realize that SAMR can keep up high PM use in server farm however the PM use of MR technique fluctuates , tumbling down under 80% much of the time. This is because of the starvation or unequal use among numerous asset kinds in MR as appeared in Fig. 4(i) to Fig. 4(l). Thirdly, we see that the usage of Central Processing Unit and RAM assets utilizing SAMR are almost in the three manufactured outstanding tasks at hand however the distinction in Google follow is substantial as appeared in Fig. 4(e) to Fig. 4(h). This is brought about by the way that the all-out requests of RAM are further than that of Central Processing Unit in follows from Google Collection. It can likewise be confirmed by the higher asset skewness issues in Fig. 4(i) to Fig. 4(l), wherever the skewness issues in Google follow are a lot advanced than the additional3 remaining burdens. We currently achieve affectability ponders on significant parameters. We examine the effect of the framework limits counting the level of heterogeneity, defer edge, the quantity of VM kinds and schedule vacancy length on the execution of various asset use. For individually trial, we contemplate the effect of shifting one stricture though location different limits to their evasion esteems.
[image:4.595.62.273.617.785.2]Effects by outstanding task at hand heterogeneity. We first examine the execution under various remaining task at hand circulations with various grades of heterogeneity. We track four examinations utilizing Increasing example in this investigation. In each investigation, the remaining task at hand comprises of just two kinds of VMs (the measures of two sorts of VM are the equivalent) with a similar heterogeneity grade. Specifically, we use < 1,1 > + < 1,1 >, < 1,4 > + < 4,1 >, < 1,8 > + < 8,1 >, and < 1,16 > + < 16,1 > in the 1st, 2nd, 3rd and 4rth trials, individually. For every one of the examinations, we keep the aggregate sums of overwhelming asset indistinguishable so as to think about the effects of heterogeneity on asset utilization. The favorable position turns out to be increasingly evident in SAMR which is specifically structured with skewness evasion.
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-7, May, 2019
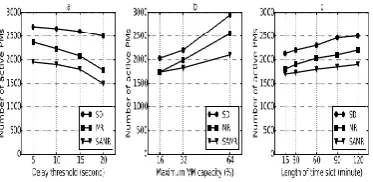
Fig 6. Studies of sensitivity for delay threshold Influencesbysuspensionthreshold.Fig.6(a)displays the outcomes for differing the postpone edge D for Google follow. We utilize a lot of defer limit (minutes): 15,30,60,90,120. We can understand from the figure that the quantity of dynamic PMs in apiece schedule opening lessens as we permit advanced postpone limit. This is on the grounds that a bigger D esteem allows more demands in the hanging tight line for fueling up extra PMs, and therefore the cloud framework can serve more VMs with existing dynamic PMs. Effects by most extreme VM capacity. In Fig. 6(b), we structure an investigation on Google follow where the cloud supplier’s proposal distinctive most extreme VM limit. For instance, a cloud framework with the standardized most extreme asset mi offers (log2 mi · 100 + 1) choices on asset type-I. We test 3 greatest asset esteems 16%,32%,64%, individually. From the figure we can understand that with greater VMs accessible by suppliers, additional PMs are expected to attend a similar measure of outstanding tasks at hand. The motive is that greater VMs have advanced opportunity to be postponed when the use of assets in the server farm is tall.
Effects by schedule vacancy span. Fig. 6(c) demonstrates the outcomes for changing opening span from 15 minutes to 120 minutes utilizing Google follow. Our heterogeneous asset the executives permits cloud suppliers to indicate availability as per their prerequisites. As appeared in the figure, the quantity of dynamic PMs can be additionally advanced with littler availabilities. These outcomes recommend that we can get improved advancement impact if our projected forecast model and PM provisioning can be implemented all the more much of the time. Be that as it may, the model calculation overhead precludes a vacancy being excessively little. 5. Performance evaluation and discussion
Effectiveness of algorithm:
We assess the adequacy of our calculation in over-burden alleviation and green registering. We begin with a little gauge explore comprising of3PMsand5 VMsso we can show the outcomes for all servers in Fig. 7. Diverse tinted lenses are utilized for each VM. All VMs are designed with 128 MB of RAM. An Apache server keeps running on each VM. We use http ref to summon Central Processing Unit serious PHP contents on the Apache server. This enables us to expose the VMs to various degrees of Central Processing Unit load by
Effect of conscious Relocation
One worry near the utilization of VM live movement is its effect on request execution. Past examinations have observed this effect to be little [5]. We examine this effect in our very own analysis. We separate the information on the 340 live movements in our 30-server trial above. We locate that 139 of them are for problem area moderation. We center around these movements since that is the point at which the potential effect on application execution is the most. Among the 139 movements, we arbitrarily pick seven relating TPC-W sessions experiencing live relocation. Every one of these sessions run the "shopping blend" outstanding burden with 200 imitated programs. As an objective for correlation, we rerun the session with similar parameters yet play out no relocation and utilize the subsequent execution as the benchmark. Fig. 9 demonstrates the standardized Web collaborations every second (WIPS) for the 7 sessions. WIPS is the execution metric utilized by TPC-W. The figure demonstrates that most living relocation sessions display no discernible debasement in execution contrasted with the standard: the standardized WIPS is near 1. The main special case is session 3 whose debased execution is brought about by an incredibly bustling server in the first investigation. Next, we investigate one of the sessions in Fig. 9 and show how its execution shift after some time in Fig. 10. The dabs in the figure demonstrate the WIPS consistently. The two bends demonstrate the affecting normal over a 30 second window as registered by TPC-W. We set apart in the character when live relocation begins and wraps up. With self-swelling empowered, the measure of remembrance exchanged amid the relocation is around 600 MB. The figure checks that conscious movement causes no observable execution corruption. The term of the movement is under 10 sec. Review that our calculation is conjured at regular intervals.
Reserve Stability:
Review that the objective of the skewness calculation is to blend outstanding tasks at hand with various asset necessities composed so the general use of server limit is improved. In this investigation, we observe how our calculation grips a blend of Central Processing Unit, memory, and system serious remaining tasks at hand. We shift the Central Processing Unit load as previously. We infuse the system load by sending the Virtual Machines a progression of system bundles. The memory concentrated applications are made by distributing memory on interest. Again, we begin with a little scale analyze comprising of two PMs and four VMs so we can show the outcomes for all servers in Fig. 11. The two lines speak to the two PMs. The two segments speak to the Central Processing Unit and system measurements, separately. The remembrance utilization is kept low for this test. At first, the two Virtual Machines on PM1 are Central Processing Unit escalated while the two Virtual Machines on PM2 are organize serious.
We increment the heap of their bottleneck assets slowly. Around 500 sec, Virtual Machine4 is moved from PM2 to PM1 because of the system over-burden in PM2. At that point around 600 sec, Virtual Machine1 is moved from PM1 to PM2 because of the Central Processing Unit over-burden in PM1. Presently the framework achieves a steady state with a reasonable asset use for the two PMs—each with a Central Processing Unit concentrated Virtual Machine and a system serious Virtual Machine. Later we decline the heap of all Virtual Machines progressively with the goal that the two PMs end up virus spots. We can see that the two Virtual Machines on PM1 are merged to PM2 by green computing.
Subsequent, we broaden the size of the examination to a gathering of 72 VMs consecutively more than 8 PMs. Partial Virtual Machines are Central Processing Unit serious, though the additional escalated. At first, we retain the heap of all VMs short and convey all Central Processing Unit escalated and PM5 while all memory concentrated Virtual Machines on PM6 and PM7. At that point we increment the heap on all Virtual Machines bit by bit to make the hidden PMs problem areas. Fig. 12 indicates how the calculation blowouts the VMs to different PMs after some time. The character additionally demonstrates that the heap over the arrangement of PMs turns out to be all around adjusted as we increment the heap.
6. Conclusion, future scope and concluding remarks
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-7, May, 2019
REFERENCES
1. Kang, Zuling, Hongbing Wang, and Lei Wang. “Performance-Aware
Cloud Resource Allocation via Fitness-enabled Auction”, IEEE Communications on similar and Distributed Systems,2015.
2. Lei Wei, Chuan Heng Foh, Bingsheng He, Jianfei Cai, “Near Efficient Resource Allocation for Heterogeneous Workloads in IaaS Clouds”. IEEE Communications on Cloud Computing, 2018.
3. P. Barham, B. Dradovic, K. Fraser, S. Hand, T. Harris, A. Ho, R. Neugebauer, I. Pratt, and A. Warfield, “Xen and the Art of Virtualization,” Proc. ACM Symp. Operating Systems Principles (SOSP’03), Oct 2003.
4. Zhen Xiao, Weijia Song, Qi Chen, “Go-aheadReserve Allocation Using
Virtual Machines for Cloud Computing Environment”, IEEE Transactions on Parallel and Distributed Systems, 2013.
5. C. Clark, K. Fraser, S. Hand, J.G. Hansen, E. Jul, C. Limpach, I. Pratt, and A. Warfield, “Live Migration of Virtual machines,” Proc. Symp. InteractedSchemes Design and Implementation (NSDI’05), May 2005.
6. Wang, Xingwei, Xueyi Wang, Hao Che, Keqin Li, Min Huang, and
Chengxi Gao. “An Intelligent Economic Approach for ActiveReserve Allocation in cloud services”, IEEE Transactions on Cloud Computing, 2015.
7. M. McNett, D. Gupta, A. Vahdat, and G.M. Voelker, “Usher: An
Extensible Framework for Managing Clusters of Virtual Ma-chines,” Proc. Large Installation System Administration Conf. (LISA ’07), Apr. 2007.
8. T. Wood, P. Shenoy, A. Venkataramani, and M. Yousif, “Black-Boxand
Gray-Box Strategies for virtual machine systems migration,” Proc.Symp. Networked Systems Design and Implementation (NSDI’07), Apr 2007.
9. C.A. Waldspurger, “Memory Resource Management I VMWare ESX
server,” Proc. Symp, operating Systems Design and Implementa-tion (OSDI’02), Aug., 2002.
10.[L.A. Barroso and U.H” olzle,” The instance for liveliness-relative computing,” IEEE computer, vol.40, no.12, pp.33-37,2007.
11.Vishnupriya S, Saranya P., and Suganya P. “Effective management of resource allocation and provisioning cost using virtualization in cloud”, 2014 IEEE International Conference on Advanced Communications Control and Computing Technologies, 2014.
12.M. Lin, A. Wierman, L. L. H. Andrew, and E. Thereska,” Dynamic
right-sizing for power-proportional data centers,” in INFOCOM’11,2011.
13.“TPC-W: Transaction Processing Performance Council,”
http://www.tpc.org/tpcw/2012.
14.C. Reiss., A. Tumanov, G.R.Ganger. R.H.Katz, and M.A.Kozuch,
“Heterogeneity and dynamicity of clouds at scale: Google trace analysis,” in Proceedings of the Third ACM Symposium on cloud computing, ACM,2012.
15.L. Wei, B. He, and C.H. Foh,” Towards Multi-Resource physical machine
provisioning for IaaS Clouds,”in IEEE ICC 2014-Selected Areas in Communications Symposium (ICC’14 SAC),2014.
16.T.J. Hacker and K. Mahadik, “Flexible resource allocation for reliable virtual cluster computing systems,” in Proc.ofSC’11,2011.
17.D. Villegas, A. Antoniou, S.M. Sadjadi, and A. Iosup,” Ascrutiny of provisioning and distribution rules for infrastructures-a-service clouds,” in Proc. Of 2012 12th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGrid’12). IEEE, 2012,pp.612-619.
18.K.Mills, J.Filliben and C.Dabrowsli,”Comparingym-placement
alogorithms for on-demand clouds,” in Proc. Of CLOUDCOM’11,2011.
19.E.G. Coffman, M.R. Gary, and D.S Johnson, “Estimate algorithms for bin
packing: A survey,” in Estimate algorithms for NP-hard problems. PWS Publishing Co.,1996,pp. 46-93.
20.D. Xie, N. Ding, Y. C. Hu, and R. Kompella, “The only continuous is change: incorporating time-varying network reservations in data centers,” ACM SIGCOMM CENTRAL PROCESSING UNITCommuniqué Evaluation.
AUTHORSPROFILE
Dr.T. SENTHIL MURUGAN, Associate Professor, School of Computing, Department of Computer Science & Engineering, Vel Tech Rangarajan Dr.Sagunthala R&D Institute of Science & Technology,(Deemed to be University) Avadi, Chennai, India -600062.