On Concurrency Control for Inverted Files
Full text
Figure
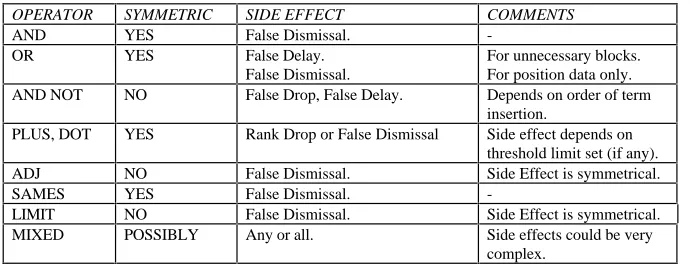
Related documents
The use of social media within supply chains is lagging behind their usage for other operational functions, however supply chain management is evolving into supply chain
This paper provides a new concept of viewing robot stiffness mapping problem, this method takes the turning points of working path into consideration, by analyzing
Results from both hypothetical tests can be concluded, the use of worksheet of temperature and heat through Scientific Process Skills Approach could increase the result
The DBL is not a prescribing or a diagnostic tool. Prescribers should refer to drug monographs and utilize professional judgment... CRITERIA FOR SPECIAL AUTHORIZATION OF SELECT
The purpose of Phase One was to examine change in (a) student-participants’ behavior and emotional problem scores through parent report (CBCL) and teacher report (TRF), (b)
• Wage employment can be defined as ‘a mutual agreement between two parties (known as employer and employee) in which the employee (generally an individual) agrees to work for
You will need to setup a new account with your bank. The bank will require your Tax File Number, ABN and business name registration to do this. Ensure these bank details are
North Eastern Metropolitan Integrated Cancer Services (NEMICS) commissioned Health Issues Centre to undertake a study examining consumers’ experiences of the varying pathways
