Rochester Institute of Technology
RIT Scholar Works
Theses
Thesis/Dissertation Collections
8-2007
Automatic image segmentation by dynamic region
growth and multiresolution merging
Luis Enrique Garcia Ugarriza
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion
in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact
Recommended Citation
Automatic Image Segmentation by Dynamic Region
Growth and Multiresolution Merging
by
Luis Enrique Garcia U garriza
A Thesis Submitted in Partial Fulfillment of
the Requirements for the Degree of
Master of Science
Approved
By:
Eli Saber
Dr. Eli Saber
Electrical Engineering
Primary Adviser
In
Electrical Engineering
Vincent J. Amuso
Dr. Vincent Amuso
Electrical Engineering
Department Head
Sohail Dianat
Dr. Sohail Dianat
Electrical Engineering
Imaging Science Laboratory
Department of Electrical Engineering
Kate Gleason College of Engineering
Rochester Institute of Technology
Rochester, New York
Thesis Release Permission Form
Rochester Institute of Technology
Kate Gleason College of Engineering
Title: Automatic Image Segmentation by Dynamic Region Growth and
Multiresolution Merging
I, Luis Enrique Garcia U garriza, hereby grant permission to the Wallace Memorial
Library reporduce my thesis in whole or part.
Luis Enrique Garcia Ugarriza
Luis Enrique Garcia U garriza
Dedication
This
thesis
is
dedicated
to
my
family.
To
my
wife,
Dr.
Mary
Mulcahey,
for
her
continuedsupport, patience,
andinspiration.
To my
father,
Luis
Garcia,
who passed onto
mehis
viewthat
everything is
possible.To
my
mother,
Lucy
Ugarriza,
for her
never-failing love.
To my
sisters,
Monica
andTatiana,
for
alwaysbeing
there
for
me.Acknowledgments
I
wouldlike
to
thank
Professor Eli
Saber,
who gave methe
opportunity
to
work onthis
exciting
project.Dr. Saber
instructed
mein
the
art ofimage
processing,
and alsotaught
mevaluable
lessons
onlife,
such asresponsibility
andintegrity. He
showedmethe
importance
of
trying
all possible approachesbefore
asking
questions.He
showed methat
there
are nobad
ideas,
just incorrect
ways ofpromoting
them.
Most
importantly,
he inspired
meto
pursue perfection and
to
always searchfor
the
nextfrontier.
I
alsothank
my
co-advisor,
Dr. Vincent
Amuso,
without whoseguidance, reviews,
and recommendationsthis
projectwould not
have
cometo
its
level
ofquality
andimportance.
He
has
alwaysbeen
there to
talk
aboutmy
ideas,
to
proofread and markup my
papers andchapters,
andto
ask me good questionsto
help
methink through
my
problems,
whetheranalytical, computational,
oreven religious.
Besides
my
advisors,
I
thank the
restofthe
peoplethat
I
have
approachedfor different
questions:
Professor Sohail
Dianat,
who providedinsightful knowledge for any
questionI
wouldunexpectedly
askhim;
Professor
Eric
Peskin,
for his
continuedinsistency
onim
proving
the
quality
ofsegmentation;
Mark
Shaw,
for
his
support andtrust
in
the
workprovided;
andto
allmy
colleagues,
Mustafa
Jaber,
Sreenivas
Patil,
Manoj
Reddy,
Name
Harsha
andGuru
Balasubramanian,
who madethe
"HP
lab"a
fun
placeto
be
during
the
many days
and nights we spenttogether.
A
specialthanks
goesto
my
friend,
Professor Daniel
Phillips,
whois
mostresponsiblefor my
choosing
the
field
of signal processing.He
showed methe
fun
ofsearching for
answers, the thrill
ofdiscovering
new methodsto
achieve apurpose,
andthe
satisfactionofdeveloping
auseful andrelevantinvention
for
tomorrow.
Abstract
Image
segmentationis
afundamental
task
in many
computer vision applications.We
present a novel unsupervised color
image
segmentation algorithm namedGSEG,
which exploitsthe
information
obtainedfrom
detecting
edgesin
colorimages.
By
using
a color gradientdetection technique,
pixels without edges are clustered andlabeled
individually
to
identify
the
image
content.Elements
that
containhigher
gradientdensity
areincluded
by
adynamic
generation of clusters asthe
segmentation progresses.By
quantizing
the
colorsin
the
image
andextracting
texture
information
from
the
neighborhoodentropy
of eachpixel,
the
proposedmethod obtains accurate models oftexture that
arehighly
effectiveto
mergeregions
that
belong
to the
same object.Experimental
resultsfor
variousimage
scenariosin
comparison with state-of-the-art segmentationtechniques
demonstrate
the
performanceContents
Dedication
iii
Acknowledgments
iv
Abstract
vTable
ofContents
viiList
ofFigures
viiiList
ofTables
ix
List
ofNomenclature
1
1
Introduction
1
2
Background
6
2.1
Edge detection in
a vectorfield
6
2.2
One-Way
Variance
Analysis
8
2.3
Evaluation
ofImage
Segmentation
Algorithms
10
3
Proposed Algorithm
13
3.1
Region
Growth
andDynamic
Seed
13
3.1.1
Initial
Seed
Generation
14
3.1.2
Region
Growth
15
3.1.3
Dynamic
Seed
Generation
18
3.1.4
Seed
Growth
Tracking
andClassification
19
3.2
Texture Channel Generation
19
3.3
Multiresolution
Region
Merging
22
4
Results
25
5
Conclusion
31
References
32
List
of
Figures
3.1
Flowchart
ofRegion
Growth
Procedure
14
3.2
Histogram
ofEdge
Values
for Lena
19
3.3
Quantization
ofColors
21
3.4
Flowchart
ofMerging
Procedure
24
4.1
Distribution
NPR
scores.(a)GRF; (b)JSEG;
(c)GSEG
26
4.2
Balloon Results
27
4.3
China Results
28
4.4
Pilot
Results
28
4.5
London Results
29
4.6
Tribal Results
29
4.7
Lady
Results
29
List
of
Tables
4.1
Segmentation
algorithmresults25
Chapter 1
Introduction
In
recentyears,
automaticimage
segmentationhas become
a prominent objectivein
image
analysis and computer vision.Image
segmentationis defined
asthe
classification ofall
the
pictureelementsor pixelsin
animage
into different
clustersthat
exhibitsimilarfea
tures.
Various image
segmentationtechniques
have
been
proposedin
pastliterature,
wherecolor, edges,
andtexture
are used as propertiesfor
classification.Using
these properties,
the
images
canbe
analyzedfor
usein
several applicationsincluding
videosurveillance,
image
retrieval,
medicalimaging
analysis,
and object classification.Initially,
segmentationalgorithms[1]
wereimplemented using only gray
levels,
yielding
regions withoutany
significantinformation concerning
the
content ofthe
image.
The
advancement
in
colortechnology
helped
in obtaining
meaningful color segmentation ofimages
asdescribed in
[2,
3].
Color
provideddefinite
advantages over gray-levelseg
mentations,
but
these
procedures consisted ofonly clustering
pixelsby
the
similarity
ofcolors.
Location
of pixels was nottaken
into
accountand,
therefore,
regionsdid
notdis
play
the
compactness of objectscontaining varying
colorsthroughout.
This
realization wasthe
beginning
of a series of challengesthat
have
provento
be
some ofthe
mostdifficult
and
important
stepsin
achieving
effectiveimage
understanding.Different
approacheshave
been
introduced
to
improve
onthe
shortcomingsof pastalgorithms.The
initial step is
to
assurethat
each regionis
notonly
clusteredbased
onthe
colorproblem was confronted
in
the
gray-leveldomain in
[4]
by implementing
the
k-means
clustering
algorithm andGibbs
random-fieldmodelto
obtainspatially
contiguous regions.This
methodwasextendedfor
multichannelimages
by
Chang,
etal,
[5]
by
assuming
that
eachindividual
channelis conditionally independent. A
goodsegmentationtechnique
requires that each regionis bounded
by
continuous edgesthat
separateindividual
objectsin
the
image.
Saber,
etal,
dealt
withthis
problemby
extending
the
algorithmin
[5]
with avector-edge
field
and asplit-and-mergeprocedureto
obtain animproved
segmentation and linked-edge map.Images
canhave different
content and cannotbe
restrictedto
afixed
number of regions.The
workin
[6]
uses a predetermined number of clusters atthe
beginning
to
yieldthe
final
segmentation map.To
this effect, the
algorithmforces
any
type
ofscenarioto
fit into
a set number ofclusters,
yielding
anincoherent
segmentationmap
in
some cases.Therefore,
it is
necessary
to
develop
atechnique to
choosethe
number of clustersfor
eachimage
priorto
segmentation.Jianping
et al.[7]
proposed a methodto
selectthe
numberof clustersin
animage
by
acquiring
the
location
of clustersbetween
adjacent-edge regions.The
challengein
this
methodis
to
evaluatethe
correctthreshold
that
differentiates
edge pixels withfalse-edge
pixels.Jianping
attemptsto
solvethis
problemusing
afast,
entropic-thresholdtechnique
in
a second-orderneighborhoodof each pixel.However,
the
final
segmentationmap
obtainedby
this
proceduredoes
not yield meaningful continuous edges.A different
approachto
define
the
numberof clusters needed wasinstituted
by
Wan
etal.[8]
whodeveloped
a setof rules
that
split or mergethe
clustersto
obtainafinal
segmentationmap
withindividual
meaningful regions.
algorithm vulnerable
to
match withincorrect
shapes.On
the
otherhand,
D'Elia
etal.[10]
initiates
the
proposed algorithmby
considering
the
entireimage
as a single region and obtainsthe
final
segmentationmap
by
combining
the
Bayesian
classifierandthe
Split-and-Merge
technique.
This
approach solvesthe
problem ofidentifying
the
correct number ofinitial
clustersby investigating
individual
regionsfor further
segmentation.The
major setback
ofthe
Bayesian
approachis
that
it
yieldstoo
many
segmentsin
a pattern ortexture
region, which,
in
turn,
producesaclutteredfinal
segmentation map.The
task
ofsegmenting images containing
texture
is
anongoing
area of researchin
image
processing.Derin
et al.[11]
proposed atechnique
ofcomparing
theGibbs distribu
tion
resultsto
known
textures.
This
technique
was not applicablein
the
presence of noise and provedto
be computationally
prohibiting.It
became
obviousthat
an alternate scheme was requiredto
identify
patternsin images.
Pyramid-structured
wavelettransforms
first
appearedin
the
work ofMallat
etal.[12]
andhas become
animportant
alternate approachto
identify
patterns.Unser
et al.[13]
uses a variation ofthe
discrete
wavelettransform
for
characterizing
texture
properties.In
this
study
they
limited
their
detection
to
a set of12
Brodatz
textures.
Further
analysis of wavelettheory
wascompletedby
Fan
et al.[14],
who showedthat
in
naturaltextures the
periodicity
resultsin
dependencies
acrossthe
discrete
wavelet transform subbands.This
approach was extendedto
55
Brodatz
textures.
Chen
etal.[15]
modifiedthe
approach ofidentifying
textures
withoutusing Brodatz
modelsby
simply
classifying
textureinto
alimited
number of classes:smooth,
horizontal,
vertical,
and complex.
This
simplification madethis
approachdifficult
for images
that
containmulcolors will often generate clusters
for
each shade ofblue,
whichultimately
over-segmentsthe
image.
We
propose asegmentation algorithmthat
automatically
selects clustersfor
images
andcharacterizes
the texture
presentin
each clusterto
obtainthe
final
segmentation.Using
anedge-color
detection
algorithm[17],
which providesvarying
edge valuesaccording
to
colordifferences,
ourprocedurefirst
created clusters onlocations
without edges.All
the
pixelsin
a cluster are given alabel,
andthe
collection ofthese
labeled
pixelsis
referredto
asseeds.
A limited
area of animage is
selected atthis
stage.The remaining
areais
segmentedby
both
growth of existent seeds and generation of newseeds,
whichis
performed atin
creasingly higher
values of color changes until allthe
pixelshave
received a segmentationlabel.
The
characterization oftexture
is
performedby
quantizing
the
colorin
the
image
and
evaluating
the
entropic colorinformation
present at each seed.The
seedsthat
are partof
textures
have
similar values of colorentropy
andconsequently
are mergedto
obtainthe
final
segmentation.This
effective proceduretakes
into
accountthe
fact
that
segmentationis
alow-level
process
and,
assuch,
should not requirealarge
amount of computational complexity.No
training
or priorknowledge
ofthe
input image is
part ofthe
algorithm.The
algorithmis
compiled
in
aMATLAB
environment over alarge database
ofdiverse images.
Compared
to
othersegmentationalgorithms,
andusing
the
Berkeley
manually
segmenteddatabase
asa ground
truth,
the
proposed algorithmconsistently
outperformsthe
segmentation resultsfrom
othersegmentationtechniques.In
chapter2,
areview ofthe
necessary background
requiredto
effectively implement
and
test
our algorithmis
presented.Our
proposed algorithmis
subdividedinto
three
sections:
3.1
introduces
the
Region Growth
andDynamic
Seed
procedure,
3.2
explains ourapproach
to
characterizetexture
present onimages,
and3.3
providesthe
methodology
usedin
our novel multiresolutionmerging
of color andtexture
information. Results
obtainedin
chapter4.
Finally,
chapter5
providesthe
summary
of our accomplishmentsin
the
creChapter 2
Background
Years
of researchin
the
image
and signalprocessing
areahave
provided essentialtools
in
the
implementation
of various applications.This
chapter willintroduce
techniques that
provide essential
information
requiredfor
the
optimalimplementation
of our algorithm.We
will
discuss
an edge-detection algorithmthat
providesthe
intensity
ofthe
edges presentin
the
image.
The
edges are utilizedto
detect
the
individual
regionsin
whichthe
image
is
segmented and
the
direction in
whichthe
region growth willtake
place.From
the
statistical
field,
webring
an effective methodto
analyze groupeddata;
analyzing
the
groupeddata is
requiredto
mergethe
regionsthat
were over-segmentedin
the
region growth procedure. And
finally,
amethodfor
quantifying
the
quality
ofimage
segmentationtechniques
is
introduced
to
evaluatethe
robustness of ouralgorithm.2.1
Edge
detection
in
a
vector
field
The initial
seeds or clusters are createdby
detecting
areas with no edgesinside them;
therefore,
the
first step
of our algorithmis
to
employ
an edgedetection
algorithm.Edge
detection
has
been extensively
studiedin
two
dimensional
space andwas generalizedfor
a multidimensional space
by
Lee
andCok
[17].
Assuming
that the
image is
afunction
a vector
field/,
Lee
andCok
expandthe
gradientvectorto
be defined
asD(*)
=>^(x)
Ztyi(x)
A/iM
Dtf2(x)
Drf2(x)
Drf2(x)
(2.1)
D]/m(x)
ZVm(x)
JDJm(x)_
where
>j/fe
is
thefirst
partialderivative
ofthe
kth component of/
with respectto the
jthcomponent of x.
The distance from
the
point x with a unit vector uin
the
spatialdomain
d
= v uTDTDuwillbe
the
corresponding distance
traveled
in
the
colordomain. The
vector whichmaximizes givendistance is
the
eigenvector ofthe
matrixDTD
that
correspondsto
its largest
eigenvalue.In
the
special case of anRGB
image,
the
gradient canbe
computedin
the
following
manner:let
u, v,
wdenote
each color channel andx, y
the
spatial coordinatesfor
a pixel.Defining
the
following
variablesto
simplify
the
expression ofthe
final
solution:q
=du
dx
+
dv
dx
+
dw
V
dx
J
'dudu\
(
dv dv\
t
dw dw
dy
J
\dxdyj
\dx
dy
du\
(dv\
(
dwY
dy)
\dy)
\dy
J
the
matrixDTD
becomes
DrD
=q
t
t
h
and
its
largest
eigenvalueA is
\
=(q
+
h
+
,j(q
+
h)2-4(qh-tz)
(2.2)
(2.3)
(2.4)
(2.5)
(2.6)
by
calculating
A,
the
largest differentiation
ofcolorsis
obtained,
andthe
edgesofthe
image
can
be defined
asG
=V\
2.2
One-Way
Variance Analysis
One-way
variance analysis allow usto take
regionsthat
have been
separateddue
to
occlusion,
or smalltexture
differences
and mergethem together.
The
core ofone-way
variance
lies
athighlighting
the
differences between
groupsthat
display
multiple variablesto
investigate
the
possibility
that
multiple groupsare associated with a singlefactor
[18].
We
consideredthe
general casein
whichp
variables x1}x2,.. .,xp are measured on
each
individual
group,
andany direction in
the
p-dimensional sample ofthe
groupsis
specified
by
the
p-tuple(ai,a2,
. . . ,ap).We
can convert each multivariate observationx'i
={xn,xi2,
. . .
,
xip) into
a univariate observationyt
=a'x;
where a'=
(ai,
a-i,
. . .,ap).
Since
the
samples aredivided into g
separategroups,
it
is
usefulto
relabel each elementusing
the
notationy^,
wherei
refersto the
group
that the
elementbelongs to,
andj
is
the
location
ofthe
element onthe
ith group.The
objective ofone-way
varianceis
to
find
the
optimal coefficients ofthe
vector awhich will yield
the
largest differences
across groups and minimizethe
distances
of elements within
the
group.To
do
this,
the
between-groups
sum-of-squares and productsmatrix
B0
andthe
within-groups sum-of-squares andproducts matrixW0
aredefine
by
9
B0
=^>i
(x,
-X)
(X;
-(2.8)
1=1and
wo
=(x^
-*0
(*i
-(2-9)
i=l;=1
where
the
labeling
x^
is
analogousto
that
ofyi3
.x
=^
"ii
x^, the
samplemean vectorin
the
ithgroup,
andx=\
Ef=i E"=i
Xy
=^
Ef=i
n%Xi
is
the
overall sample mean vector.Since
ytj
=a'x^
,it
canbe
verifiedthat the
sum ofbetween-groups
and within-groupsbecome
SSB
(a)
=a'B0a andSSW
(a)
=a'W0a(2.10)
With
nsample members andg
groups, there
are(g
-1)
and(n
-g) degrees
offreedom
differences in
mean valueamong
the
g
groupsis
obtainedfrom
the
meansquare ratiowhere
B
=^pxyBo
is
the
between-group
covariance matrix andW
= t^-tW0
is
the
within-groups covariance matrix.
Maximizing
F
with respectto
ais done
by differentiating
F
andsetting
the
resultto zero,
yielding Ba
-(^)
Wa
=0. But
atthe
maximumofF,
f^
mustbe
a constantI,
sothe
required value of a mustsatisfy
(B-ZW)a
=0
(2.12)
This
equation canbe
written(
W_1B
II)
a =0,
so/
mustbe
aneigenvalue,
andamust
be
the
eigenvectorcorresponding
to the
largest
eigenvalue ofW_1B.
This
result willprovide
the
direction in
the
p-dimensionaldata
space,
which willtend to
keep
the
distances
between
each class small andsimultaneously
maintainthe
distances
between
classes aslarge
as possible.In
thecase whereg is
large,
orif
the
originaldimensionality
is
large,
a singledirection
will provide a gross oversimplification of
the true
multivariate configuration.The
term
in
(2.12)
willgenerally
possess morethan
one eigenvalue/eigenvector pair which canbe
used
to
generate multipledifferentiating
directions. Suppose
that
Ai
>A2
> . . .As
>
0
are
the
eigenvalues associatedto the
eigenvectorsa^ a2,
. . .,as.
If
wedefine
new variatesj/i, 2/2)
by
g/i
=a^x, then the yt
aretermed
canonical variates.The
eigenvaluesA;
and eigenvectorsa,
are gatheredtogether
sothat
a^
is
the
ithcolumn
of a
(p
xs)
matrixA,
whileA;
is
the
ithdiagonal
element ofthe
(s
xs) diagonal
matrixL.
Then,
in
matrixterms,
equation(2.12)
may be
writtenasBA
=WAL,
andthe
collection ofcanonical variates
is
givenby
y
=A'x.
The
space of all vectorsy
is
termed the
canonicalvariate space.
In
this space, the
meanofthe
ith
group
ofindividuals is yt
=A%.
The
Mahalanobis-squared
distance between
the
ithandjthgroup is
givenby
D2
=
(x;
-ij)'W"1
(ii
and compared
to the
Euclidean distance
ofthe
group
meansin
the
canonical variatespace,
and
substituting for yt
andy
weobtain=
(xi-x^AA'ixi-Xj)
(2.14)
but it
canbe
proventhat
AA' =W"1,
thus
substituting for
AA'above yields(2. 13).
Hence,
by
constructing
the
canonical variate spacein
the
way
described,
the
Euclidean
distance
between
the
group
meansis
equivalentto the
Mahalanobis distance
ofthe
original space.Obtaining
the
Mahalanobis distance between
groupsis
important,
because
it
accountsfor
the
covariancebetween
variables as well asdifferential
variances,
andit is
now thepreferred measure of
distance between
two
multivariate populations.2.3
Evaluation
of
Image
Segmentation Algorithms
To
objectively
measurethe
quality
of our segmentation algorithm wehave implemented
a
recently
proposed measure ofsimilarity,
referredto
asthe
Normalized
Probabilistic Rand
(NPR)
index [19]. This
method comparessegmentations obtainedfrom
the tested
segmentation
algorithms and comparesthem to
a set of manual segmentations availablefor
the
given
image.
The
need of multiple manual segmentationsfor
a singleimage
is
that there
is
not asingularcorrectsegmentation;
therefore,
the
set of multiple perspectives of correctsegmentations
becomes
the
ground-truthsegmentationsfor
the
givenimage.
As its
nameimplies,
the
NPR
is
anormalizationofthe
Probabilistic
Rand
(PR)
index.
The PR index
allows comparison of atest
segmentationto
a set ofmultiple ground-truthsegmentation
images
througha soft nonuniformweighting
of pixels pairs as afunction
ofthe
variability
in
the
groundtruth
set[20].
Assume
that the
ground-truth setis defined
as{Si,
S2,
. . .,
SK}
of animage X
=
{xu
x2,
. . .,
xN} consisting
ofN
pixels.Let
Stest
be
the
segmentationthat
is
to
be
comparedwiththe
manually labeled
set.We
denote
the
label
of pixel
xn
as l%testin
the test
segmentation and asZf
*in
the
kth
manual segmentation.The PR
modelslabel
relationshipsfor
eachpixelpair,
where eachhuman
segmenter provides
information
(qj)
about each pair of pixels(xi,Xj)
asto
whetherthe
pairbelongs
to
the
samegroup 1
orbelongs
to
different
groups0.
The
set of allperceptually
correctsegmentations
defines
aBernoulli distribution for
the
pixelpair,
giving
a random variablewith expected value
denoted
as pi:j.The
set{pi:j}
for
all unordered pairs(i,j)
defines
the
generative modelofcorrect segmentations
for
the
image X.
The Probabilistic Rand index is
then
defined
as:PR(Stest,{Sk})
=-4y
[p$
(l-py)1-*]
(2.15)
This
measuretakes
valuesbetween
0
and1,
where0
meansStest,
{Si,
S2,
. . . ,Sk}
have
nosimilarities,
and1
means all segmentations are equal.Although
the
summationin
(2.
15)
is
overall possible pairs ofN
pixels,
Unnikrishnan
et al showsthat the
computationalcomplexity
ofthe
PR
index is
O (KN
+
fc
Lk)-The
NPR index
establishes a comparison method which meetsthe
following
require mentsfor
comparisoncorrectness:1.
Images
whose ground-truth segmentations are not welldefined
cannot provide abnormally large
values of similarity.2. The
comparisondoes
not assume equallabeling
of groups or same number of groups.3.
Boundaries
that
arewelldefined
by
the
human
manual segmentation are givengreaterimportance
than those
regionsthat
containill-defined
boundaries.
4.
Scores
provide meaningfuldifferences between
segmentations ofdifferent images
and
different
segmentationsofthe
sameimage.
The NPR is
defined
asPR
-E
[PR]
NPR=
MaX[PR)-nPR)
(2'16)
where
the
maximum possible value ofthe
PR
to
be
1,
andthe
expected value ofthe
PR
index is
computedasE
PR(Stest,{Sk})]
=-pyEJE[l(Zf-=
Zf-)
J
i<j
Pij
+
E
!(!?"#
I/"")]
(1-P)}
(2-17)
3
i<j
EAjPa
+
tt-AW-Pii)
where
I is
the
identity
function,
andp^- = E[I(lftest =lfest)}
is
defined
asthe
weightedsum of
PR(St,{Sk}).
Let
$ be
the
number ofimages
in
adata
set andK$
the
number of ground-truthseg
mentations of
image
<j>.Then, p'^
canbe
expressed as:^
^
-"-^ fe=i v yThe
normalizationofthe
Probabilistic
Rand
is
important,
sinceit
providesa meaningfulvalue of
similarity
when segmentations ofthe
sameimage
are compared and alow
valueof
similarity
when segmentationsofdifferent images
are compared.Chapter
3
Proposed Algorithm
An
overview ofthe technique
developed
to
segmentimages is
providedhere
to
serveasa reference
to the
reader.The
algorithmis
composed ofthree
different
modules.The
first
module uses an edge-detection algorithm
to
dynamically
create regions composed of contiguous
pixelsthat
display
similar gradient values.The
second module consists ofcreating
an additional channel
from
the
image. This
channel containsthe texture
information
ofthe
image.
The
last
module combinesthe
texture
information
andthe
initial
segmentationmap
obtained
in
the
first
moduleto
merge regionsthat
display
the
same variance of colors andtexture.
The
following
sections willdescribe
the
detailed
technique
for
each ofthe three
modules.
3.1
Region
Growth
and
Dynamic
Seed
The quality
ofregion-growing
techniques
is
highly
dependent
onthe
initial locations
chosen
to
initialize
the
growing
procedure.We
propose an alternative processfor
regiongrowth
that
does
notdepend exclusively
onthe
initial
assignment ofclustersfor
the
final
segmentation.
The
procedure searchesfor
regionsin
the
image
where noedgeshave been
detected.
The
selected regionsform
the
initial
set of clustersto
segmentthe
image.
Sky,
skin,
andin
general,
objectsof nostrong
color variance are selectedin
this
step.Subsequent
clusters are
incorporated
withvariouslevels
of edgedensity
during
the
growthprocedure,
to
accountfor
all other objectsthat
arefound
in
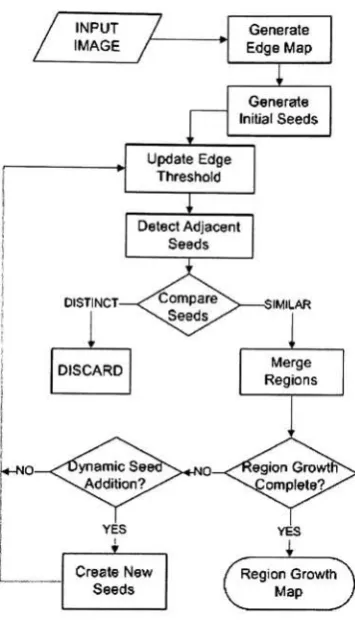
naturalimages. A flowchart for
this
moduleFigure
3.1:
Flowchart
ofRegion
Growth Procedure
is
shownin Fig.
3.1
andthedetailed
explanation of eachstep is described below.
3.1.1
Initial
Seed
Generation
Using
themagnitude ofthe
gradientG(i,j)
ofthe
colorimage
field,
computedasde
scribed
in
2.1,
the
edgemap
ofimages is
obtained.Ideally,
athreshold
value couldbe
selected
to
provide us withthe
mostedges,
whileignoring
noisepresentin images. The
problem is
that the
natureofimages
does
not allowfor
this
disposition. A
threshold that
may
correcdy
delineate
the
boundary
ofa given regionmay
allow otherregionsto
be
merged.Due
to this
factor,
weinitiate
our algorithmby
selecting
regionsthat
do
not presentany
edges
within, and,
if
such regions are notfound,
the
edge value orthreshold
is increased
until regions are
detected.
To
prevent multiple seed generation withinhomogeneous
and [image:24.509.170.348.72.385.2]connected
regions, the
region selectionatthis
stageis
restrictedto
clusters of pixels whichare
larger
than
0.5%
ofthe
image. Each individual
clusteris
assignedaparticularlabel
for
differentiating
purposes.This label map is
referredasthe
Parent
Seeds (PS). The
labeling
procedureuses
the
general procedure outlinedin
reference[21].
1. Run-length
encodetheinput image.
2. Scan
the runs,
assigning preliminary labels
andrecording label
equivalencesin
alocal
equivalencetable.
3. Resolve
the
equivalenceclasses.4. Relabel
the
runsbased
onthe
resolvedequivalenceclasses.3.1.2
Region Growth
The
procedurecontinuesby increasing
the threshold
found
in
the
initial
seed generationand
detecting
new regions or child seedsthat
fall below
the
newthreshold.
These
childseeds need
to
be
classifiedinto
adjacent-to-existent or non-adjacent seeds.In
orderto
make
the
region growth processefficient,
it is important
to
alsoknow
the
parent seedto
which
the
childis
adjacent.The
objectiveis
to
be
ableto
process all adjacent childseedsin
a vectorized approach.To
achievethis task
weproceedto
first detect
the
outside edgesofthe
PS map
using
a nonlinear spatialfilter.
The
filter
operates on thepixels ofa3
x3
neighborhood,
andthe
response ofits
operationis
assigned atthe
center pixel oftheneighborhood.
The
size of neighborhoodsbeing
operated willbe
assumedto
be 3
x3
unless specifiedotherwise.
The filter
operatesaccording
to
F(i,j)
= <0
ifPS(i,j)>0,
0
if(min)e/3PS(7n,n)is0,
(3.1)
1
otherwisewhere
/3
is
the
neighborhoodbeing
operated.The
resultofapplying
this
filter is
a maskindicating
the
borders
ofthe
PS
map.The
child seeds areindividually
labeled,
andthe
ones adjacentto the
parent seeds areidentified
by
performing
an element-by-element multiplication ofthe
parent seeds edgemask and the
labeled
child map.The remaining
pixels are referredto
asthe
adjacentchild pixels.
The
pixels whoselabels
are members ofthe
set oflabels remaining
afterthe
multiplication
become
part ofthe
adjacent child seeds map.For
the
proper addition ofadjacent child
seeds,
it is necessary
to
comparetheir
individual
colordifferences
to their
parents
to
assure ahomogeneous
segmentation.Reduction
ofthe
number of seedsto
be
evaluated
is
accomplishedby
attaching
to their
parentsthe
child seedsthat
have
a sizesmaller
to
the minimum seed size(MSS).
In
ouralgorithm, the
MSS is
setto
0.01%
ofthe
image.
The
child seed sizes are computedutilizing
sparse matrix storagetechniques to
allowfor
the creation oflarge
matrices withlow
memory
costs.Sparse
matrices storeonly
the
nonzeroelements ofthe
matrix, together
withtheirlocation in
the
sparse matrix(indices).
The
sizeof each child seedis
computedby
creating
a matrix ofM
xN
columnsby
C
rows,
where
M is
the
number of columns of pixelsin
the
image,
N
the
numberofrows,
andC
thenumber of adjacent child seeds.
The
matrixis
createdby
allocating
a1
at each columnin
therowthat
matchesthe
pixellabel. The
pixelsthat
do
nothave
alabel
areignored.
By
summing
allthe
elementsalong
eachrow,
we obtainthe
number of pixels per child seed.This
procedureis
usefulfor
any
operationthat
requiresthe
knowledge
ofthe
number ofelements per
group in
the
segmentation algorithm.To
attach regions anassociationbetween
childseeds andtheir
parentsis
required.The
adjacent child pixelsprovide
the
childlabels,
but
notthe
parentlabels. A
new spatialfilter
is
appliedto the
PS map
to
obtainthe
parentlabels.
The
filter
response at each centerpoint
is
equalto
themaximumpixel valuein
its
neighborhood.The
associationbetween
child and parent can now
be
obtainedby
creating
a matrix withthe
first
column composedof
the
adjacentchild pixels andthe
secondcolumn,
withlabels found
atthe
location
ofthe
adjacent child pixels
in
the
matrix obtainedafterapplying
the
maximum valuefilter
to the
PS
map.It is important
to
notethat
non-linearfilters
are usedto
provideinformation
aboutthe
seeds and notto
directly
manipulatethe
image;
therefore,
it
does
notimpair
the
final
result.
The
functionality
of the association matrixis
manifold.It
providesthe
numberof childpixels
that
are attachedto
parent seeds andalsoidentifies
which child seeds share edgeswith more
than
one parentseed.Child
seeds smallerthan
MSS
can nowbe
directly
attached
to their
parents.Child
seedsthat
shareless
than
5
pixels withtheir
parents and arelarger
than
MSS
arereturnedto the
unsegmented regionto
be
processed whenthe
regionshares a moresignificant
border.
Finally,
the
remaining
seeds are comparedto their
parentsto
analyzeif
they
shouldbe
addedto
a parent seed or not.Given
thatspatial regionsin
images
vary
gradually,
only
the
nearby
area ofadjacency
between
parent and childis
comparedto
provide atrue
representation ofthe
colordiffer
ence.
This
objectiveis
achievedby
using
two
masksthat
will excludethe
areas ofboth
parent and child seeds
that
aredistant from
their
commonboundaries.
The
first
maskis
adilation
ofthe
PS map using
an octagonalstructuring
element with adistance
of15
pixelsbetween
thecenter pixelto the
sides oftheoctagon,
as measuredalong
the
horizontal
andvertical axis.
The
second maskis
the
samedilation but
this time
appliedto the
adjacentchild seeds map.
The
two
masksmutually
excludethe
pixelsthat
fall beyond
eachother'sdilation
masks.The
values usedin
our algorithm are optimizedto
work withimages
that
range
from 300
x300
pixelsof resolutionto
1000
x1000
pixels.The
comparisonof regionsis
performedusing
the
Euclidian
distance between
themeancolors of
the
groups.The
reasonfor
choosing
this
methodis
that
only
the
nearby
areaof regions
is
being
compared, and,
therefore,
the
increased complexity
ofusing
the
Mahalanobis
distance does
notimprove
the results,
because
the
variance ofthe
regions compared willbe
small.Also,
priorto
comparing
the colors, the
image is
convertedto the
CEE
L*a*b*color
space,
assuring
that
comparing
colorsusing
the
Euclidean
distance is
similarto the
differentiation
of colorsby
the
human
eye.The
maximum colordistance
to
allowthe
in
tegration
ofthe
child seedto the
parentseedis
setto
20. This distance is
chosento
allowthe
differentiation
ofatleast 10 different
colorsalong
the
range ofthe
a*channel or b* channel.
3.1.3
Dynamic Seed Generation
When
the
parent seeds are createdin
the
initial
seedgeneration,
theregions representedby
these
seeds are characterizedby
areas ofthe
image
that
have
notexture.
These
areascan
be instances
ofsky, water, skin,
andin
general,
regions wherethere
is
either no colorvariance or a gradual
transition
from
one colorto the
next.The
dynamic
addition of seedsto the
PS
map
is
ouranswerto
include
the
remaining
regionsthat
display
different
levels
of edge
intensities
through them
but
are part ofthe
sameidentifiable
object.Dynamic
seedgeneration consist of
selecting
a set ofthreshold
values at which additional seeds are addedto the
parent seeds.The
threshold
values are adjustedto
accountfor
the
exponentialdecay
of edge values as seen
in Fig.
3.2.
Ranges in
the
low-edge
values accountfor large
areasin
theimage.
To incorporate
newareas, the threshold
values needto
increment
exponentially
to
include
additional elements of considerable sizeinto
the
segmentation map.The
threshold
values selectedfor
the
addition of new seeds are:15, 20, 30, 50, 85,
and120
accounting
for
anincrement
of10%
ofthe
area ofthe
image
added at eachinterval.
At
these
intervals,
theadditionof new seedsfollow
a similar procedureto the
methodexplained
in
3.1.2.
The
regionsthat
fall
below
the
selected edgethreshold
aredetected.
All
the
regions thatare not attachedto
any
parent seeds and arelarger
than the
MSS
areadded
to the
PS
map.For
the
additionof new seedsthat
shareborders
with existentseeds,
they
are requiredto
meettwo
qualifications:1)
the
group
mustbe large
enoughto
become
a
group
by
itself,
and2)
thecolordifferences
between
the
regionandits
neighbor mustbe
greater
than the
maximumcolordifference
allowed.(a)
Original
(b)
Edge
Map
[image:29.509.177.359.71.251.2](c)
Edge Histogram
Figure 3.2: Histogram
ofEdge
Values for Lena
3.1.4
Seed Growth
Tracking
and
Classification
Region
growth withoutfeedback
ofthe
growth rate of each seedmay
cause parent seedsto
overflowinto
regions of similar colorsbut different
textures.
Regions in images
display
similar edge
density
throughoutthe region;
therefore,
to
maintainhomogeneity,
the
regionsthatare createdat
low
gradientlevels
and slowtheir
growth rateshouldbe
classified as agrownseed and should
be
removedfrom
thegrowth procedure.The
sizetracking
of each seedis
performedat eachdynamic
seed additioninterval. The
number of pixels per seedis
computedateach
interval,
and whenthe
increment
ofa parent seeddoes
not reach above5%
ofits
originalsize, the
growthofthis seedis
stopped.When
the
last interval has been
reached,
allthe
identifiable
regionshave
been
given alabel
and allremaining
areas areedges ofthesegmented regions.
At
this
stage all seeds are allowedto
growto
completethe
region growth procedure.
3.2
Texture
Channel Generation
Much
ofthe
problemin image
segmentation algorithmsis
causedby
the
presence ofregions
that
containdistinct
patterns.The
issue is
that
patterns arecomposedofmultipleshadesofcolors and cause
over-segmentation
andmisinterpretation ofthe
edges surrounding
the
patterned object.These
objects are referredto
in
the
computer visionindustry
astextures.
Texture
regionsmay
contain regular patterns such as abrick
wall, to
irregular
patterns suchas
leopard
skins,
bushes
andmany
objectsfound in
nature.The
presence oftexture
in images is
solarge
anddescriptive
ofobjectsthat
wehave
decided
to
generateanadditional channel
containing
this
important information.
A
methodfor obtaining information
ofpatterns within animage is
to
evaluatethe
randomness
presentat various areas ofthe
image.
Entropy
provides a measure ofuncertainty
of a random variable
[22].
If
the
random variableis
composedfrom
the
pixel values ofa
region, the
entropy
willdefine
the
randomness associatedto the
regionbeing
evaluated.Texture
regions contain various colors andshades;
therefore,
texture
regions will containaspecific value of
uncertainty
associated withthem, providing
a structureto
merge regionsthat
display
similar characteristics.Information
theory
introduces
entropy
asthe
quantity
which agrees withthe
intuitive
notion of what a measure of
information
shouldbe [22]. In
accordance withthis
supposition,
wecan select a randomgroup
of pixels sfrom
animage,
with a set of possible values{ai,
a2,
. . .,aj}.
The probability
for
a specific valuea,
to
occuris
P(dj),
andit
containsI
(aj)
=l9p-(\
= ~l9p(aj)
(3-2)
units of
information. The
quantity
/(%)
is
referredto
asthe
self-information ofa,.If
k
values are present on
the set, the
law
oflarge
numbers stipulatesthat, for
asufficiently
large
value ofk,
symbol%
will on averagebe
outputkP(dj)
times.
Thus
the
averageself-information obtained
from
k
outputsis
-kP
(ai)
logP
(ai)
-...-kP(aj)
logP
(aj)
(3.3)
or
j
-kJ2P(aj)logP(aj).
(3.4)
Red
[image:31.509.153.349.64.253.2]Green
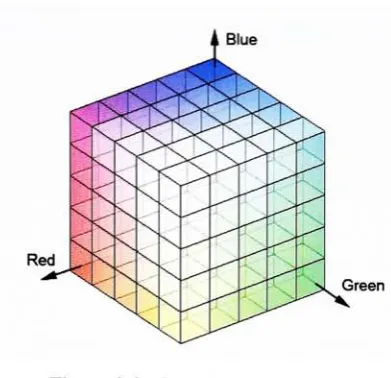
Figure 3.3: Quantization
ofColors
The
averageinformation
persourceoutput,
orentropy is defined
by
H(s)
=~'P(aj)logP(aj)
(3.5)
This quantity is defined for
a single randomvariable,
andfor
the
case ofcolor,
multiplevariablesare used.
To
take
advantageofthecolorinformation
withoutextending
the
process
to
compute thejoint
entropy,
the colorsin
animage
are quantizedinto
63,
or216
different
colors.The
quantization of colors canbe done using
uniform quantization whichcuts
the
RGB
color cubeinto
smallerboxes,
andthen
maps all colorsthat
fall
within eachbox
to
thecoloratthe
center ofthatbox.
Uniform
quantizationis
representedin
Fig.
3.3.
After
the
colorshave been
quantized,
eachpixel ofthe
image
canbe indexed
to
one ofthe
216
representativecolors,
effectively reducing
the
probability
of each coloroccurring
to
a one-dimensional random variable.To
createthe texture channel, the
local entropy
is
computed on a9-by-9
neighborhood around each pixelin
the
indexed
image,
andthe
resulting
valueis
assignedto the
center pixel ofthe
neighborhood.3.3
Multiresolution
Region
Merging
The
texture
channel obtainedfrom
the
second moduleis
combined withthe
colorinfor
mation
to
describe
the characteristicsof each region segmentedby
theregion growth module.
Using
amultivariate analysis ofthe
independent
regions, the
resultantMahalanobis
distances between
groupsis
usedto
merge similarregions.To
this
pointthe
segmentationofthe
image has been
performed with an absence ofinformation
aboutthe
individual
regions.Now
that the
image has been
segmentedinto
different
groups,
information
canbe
gatheredfrom
eachindividual
region.Given
that
wehave four
sources ofinformation
(Red, Green, Blue,
andTexture)
andindividual
regionsdisplaying
adifferent
number of pixels pergroup,
we require a suitable methodto
display
the
data in
orderto
investigate
relationshipsofthe
regions.The data
canbe
modeledusing
an
(N
*P)
matrix,
whereN
is
the total
number of pixelsin
the
image,
andP
arethe
total
number of variablesthat
containinformation
about each pixel.G is
the total
numberof groups
in
whichthe
image has been
segmentedin
the
region growthprocedure; then
the matrix
is
composed ofG
separate sets.The
objectiveis
to
obtain a mean valuefor
each
group
that
is
usedto
comparethe
different
groups.The
method usedto
achievethis
objective
is
aone-way
analysis ofvariance,
whichis
explainedin detail in
section2.2.
The Mahalanobis-squared distances
are obtainedfor
each pair of groupsfrom
the
oneway
analysis ofthe
data. The
algorithm usesthese
distances
to
find
the
similar groups andmerge them.
Once
agroup has
been
merged, the
similarity
ofthis
group
to the
othersis
unknown,
but
requiredif
the
newgroup
needsto
be
mergedto
other similar groups.To
prevent
the
needto
re-evaluatethe
Mahalanobis distances
for
the
groups after each regionmerging has
occurred,
an alternate approach wasintroduced.
Having
thedistances
between
groups,
thesmallestdistance
valueis
found. This
valueonly
provides one pair ofgroups;
therefore,
the
similarity
valueis increased
until alarger
set of
group
pairsis
obtained.Five group
pairs werefound
to
be
an adequate number ofgroups
to
reducecomputationtime
withoutmerging
groupsinadequately. We
initiate
by
merging
the smallergroup in
this set andthen
continueto
mergethe
nextlarger
group.After
the
first
merge,
acheckis
performedto
seeif
one ofthe
groupsbeing
mergedis
nowpart ofa
larger
group.In
this
caseallthe
pair combinations ofthe
groups shouldbelong
to
the pairs selected
initially
in
the
setto
be
mergedtogether.
Once
allthe
pairs ofthe
sethave been
processed, the
Mahalanobis distance
is
recomputed
for
the
new segmentationmap,
andthe
processis
repeated until adesired
number ofgroups
is
achieved.The
value ofsimilarity
obtained,
afterthe
desired
numberofgroupshas been
achieved,
shouldbe
used as a minimum value ofmerging
to
assurethat
allthe
images
display
a similarlevel
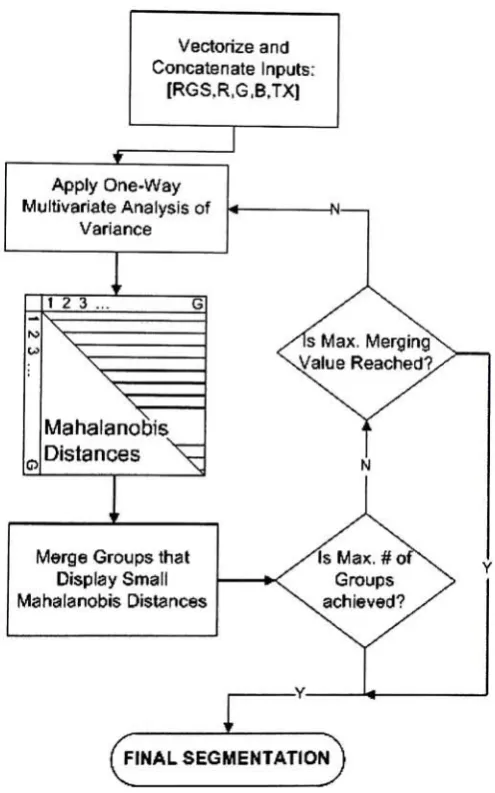
of segmentation.A flowchart
ofthe
procedureis
shownin
Fig.
3.4.
Vectorize
andConcatenate
Inputs:
[RGS,R,G,B,TX)
Apply One-Way
Multivariate Analysis
ofVariance
o
1 2 3 ...
v;
X
x~x:
Mahala
nobisDistances
\^
Merge Groups
thatDisplay
Small
Mahalanobis
Distances
Figure
3.4:
Flowchart
ofMerging
Procedure
[image:34.509.131.379.151.548.2]Chapter
4
Results
Until
recently,
different
segmentation algorithms provedtheir
effectiveness
by display
ing
the
results obtained on alimited
set ofimages. Hebert
et alintroduced
a methodfor
actually assigning
aquantitativevalueto the
quality
of a givensegmentationby
calculating
the
Normalized Probabilistic Rand
(NPR)
index [19].
The
technique
involved
in
the
calculation
ofthe
NPR index is
summarizedin
section2.3. Because
the
NPR
providesa valuewhich
is
directly
relatedto the
manualsegmentationsutilizedin
the
evaluationprocess,
aset of manualsegmentations
is
requiredthat
display
the
following
characteristics:1. It
cannotbe
chosenselectively
to
favor
a givenalgorithm.2.
It
displays
variousscenarioswithmultiplelevels
of complexity.3. It
containmorethan
oneindividual
perspective.4. It
canbe
accessedby
anyoneto
performthe
sametest
ondiverse
algorithms.Table
4.1: Segmentation
algorithm resultsGRF
JSEG
GSEG
Avg. Time
(sec)
280
28
46
Avg.
NPR
0.358
0.440
0.486
Std. Dev. NPR
0.345
0.319
0.313
Environment
C
C
MATLAB
[image:35.509.139.367.537.644.2]GRF NPRdistribution JSEG NPR distribution GSEG NPR distribution
lj a
-06 -04 -0.3 D 0.3 04 06 08 Ia
$.6 -OB -04 -0.2 0 02 04 0.6 08 NPR index [image:36.509.47.467.79.218.2](a)
(b)
(c)
Figure 4.1: Distribution NPR
scores.(a)GRF; (b)JSEG;
(c)GSEG
Such
a setis
available onthe
publicly
accessibleBerkeley
Segmentation
Database. This
database
provides1633
manual segmentationsfor 300 images
createdby
30 human
subjects [23]. State-of-the-art
algorithms werechosento
comparethe
quality
ofthe
segmentation
results.These
segmentationtechniques
areFusion
ofColor
andEdge
Information
for improved Segmentation
andEdge
Linking
(GRF)
[6],
the
unsupervised segmentationof color-texture regions
in images
andvideo(JSEG)
[16],
andthe
novel algorithmauto matic segmentationby
dynamic
region growth and multiresolutionmerging (GSEG). To
preventany
discrepancy
atthe
time
ofcomparing
the results,
allthe
availableimages
weresegmented
using
the
available segmentation algorithms onthesame machine.The
testing
computer
has
aPentium
4
CPU
3.20GHz,
and1.00 GB
ofRAM. The
GRF
andJSEG
algorithms wererun
from
theexecutablefile
providedby
Rochester
Institute
ofTechnology
andthe
University
ofCalifornia
respectively.The
proposed method was processedusing
MATLAB
R2006a.
The
normalizationfactor
was computedby
evaluating
the
Probabilistic Rand
(PR)
for
all available manual
segmentations,
andthe
expectedindex
obtained was0.6064. Results
obtained
for
the
distinct
methods aredisplayed
in
table
4.1.
The
results showthat the
GSEG
algorithmhas
the
highest
overallNPR
results,
andthe
varianceofthe
resultshas
the
narrowest
spread,
proving
that
the proposedalgorithm performsconsistently
better
than
the
otheralgorithms.Fig. 4.1
display
the
distribution
ofthe
NPR
scoresfor
allthe tested
images.
It
canbe
observedthat
273
out of300 images using
the
proposedalgorithm are(a)
Original
(b)GRF
[image:37.509.109.408.76.405.2](c)
JSEG
(d)
GSEG
Figure 4.2:
Balloon
Results
distributed into
the
top
half
or acceptable segmentation range.This is
similarto the
numberof segmentations
that
fall
withinthisrangeusing
the
JSEG
algorithm.The
actualimprove
ment canbe
seenin
the
number of segmentation scoresthat
fall
withinthe
range ofvery
good segmentation results[0.7
<
NPR
<
1]. These
numbersfor
the
GRF, JSEG,
andGSEG
were47, 74,
and98
respectively.This
indicates
that
closeto
athird
oftheimages
segmented
using
our algorithm matchclosely
to the
segmentations performedby
human
beings. The
evaluation ofthe
segmentationalgorithms were performedby
maintaining
the
standardparameters available as the
inputs
for
the
segmentationprograms.Some
ofthe
results obtainedfrom running
the
GSEG
algorithm,
as well as the othersegmentationsmethods without
any
parametertuning
areshownin Figs. 4.2
-4.7. Clear
(c)
JSEG
(d)
GSEG
Figure
4.3: China
Results
(a)
Original (b)GRF(c)
JSEG
(d)
GSEG
Figure
4.4:
Pilot Results
[image:38.509.95.416.91.325.2] [image:38.509.95.417.381.623.2](a)
Original
(b)
GRF
(c)
JSEG
Figure
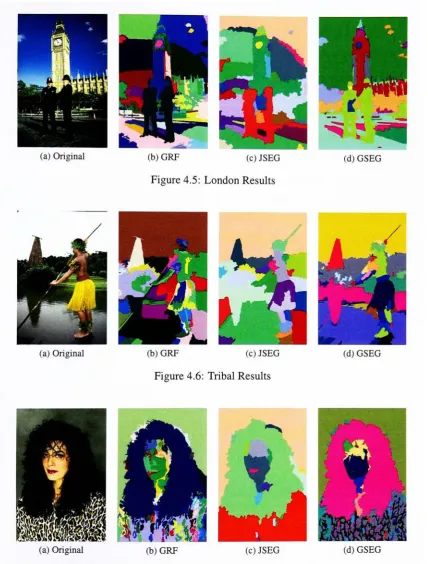
4.5:
London Results
(d)
GSEG
(a)
Original
(b)
GRF
(c)
JSEG
Figure 4.6: Tribal Results
(d)
GSEG
(c)
JSEG
Figure 4.7:
Lady
Results
[image:39.509.43.472.68.633.2]advantages can
be
seen onthe
level
ofdetail
achievedfrom
our segmentationin
comparisonto the
JSEG
segmentationfor
allthe
images. The boundaries
ofthe
GRF
procedurematchdirectly
the
boundaries
ofthe objectin
the
image.
Fig.
4.4(c),
andFig.
4.5(c)
displays
the
disadvantage
ofguiding
the
segmentationmethodbased
onthe
quantizationof colorsto
createthe
initial
clusters.In
these
images
the
sky has
been
oversegmented,because
the
change oflight
providesdifferent
shades ofblue. Advantages
ofthe
multiresolutionmerging
method canbe
seen onFigs.
4.3(d)
and4.7(d).
In
these
results multiple regionsthat
create a pattern are assignedto the
sameclass,
allowing
the
algorithmto
reducethe totalnumber of classes without
losing
information
obtainedfrom
multiple similar regionsthat
are not adjacent
to
each other.The
GRF
resultshave
the
samelevel
ofdetail
asthe
GSEG
approach,
but its lack
oftexture
modeling
does
not allowit
to
differentiate
objects withsimilar colors
but
different
texture.
Figs.
4.4(b), 4.5(b),
and4.6(b)
have
regions mergedthat
display
similarcolorsbut
containsubstantially different
textures.Chapter
5
Conclusion
This
work provides aneffective methodfor
automaticimage
segmentation on simpleto
compleximages.
The
algorithmis based
on color edge-detection anddynamic
regiongrowing,
completedby
a multiresolution region merging.The
segmentation procedurehas
been
tested
onthe
publicly
availableBerkeley
database,
andthe
quality
ofits
resultshas
been
measured.The
robustness of our algorithmis displayed
onthe results,
along
withthose
obtained onthe
sameimage
when segmentedby
other methods.Future
researchwould
be focused
on object classificationbased
onthis
segmentation algorithm.References
[1]
J. B.
McQueen,
"Some
methodsfor
classificationand analysis ofmultivariate obser vat