Theses
Thesis/Dissertation Collections
2004
Feature Extraction Methods for Character
Recognition
Roman V. Yampolskiy
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion
in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact
Recommended Citation
Feature Extraction Methods for
Character Recognition.
Department
ofComputer
Science
Master's Thesis
by
Roman
V.
Yampolskiy
Department
ofComputer Science
Rochester
Institute
ofTechnology
Rochester,
NY,
USA
Feature Extraction Methods for Character Recognition
By
Roman V. Yampolskiy
A Thesis
Submitted to the Faculty of B. Thomas Golisano College of
Computing and Information Sciences in Partial Fulfillment of the
Requirements for the Degree of Master of Science in Computer
Science
Approved by:
Professor Leonid Reznik, Chair
Date
Approved by:
Professor Peter G. Anderson, Reader
Approved by:
________________________________
'_'_M~~~~~1
Professor Roger S. Gaborski, Observer
Date
Thesis Reproduction
Permission Statement
Permission granted
Title of thesis: Feature Extraction Methods for Character Recognition.
I, Roman V Yampolskiy, hereby grant permission to the RIT Library
of the Rochester Institute of Technology to reproduce my thesis in whole or
in part. Any reproduction will not be for commercial use or profit
.
Date: May 10, 2004
Page
5
conducted.
Optimal
parametersfor
learning
rate,
spread, momentum,
number
oflayers,
number of nodes and number of epochsfor
this
particularapplication were
found.
Radial
Basis
Function Network
was chosen asthe
superiorclassifier,
both in
terms
ofits
speed and accuracy.A
novelfeature
extractionmethod,
calledFuzzy Zoning,
wasdeveloped.
Fuzzy
Zoning
's
main competition was with otherzoning
approaches and unlike
all ofthem,
it
wasdesigned
to
counteractthe
problem ofsharp
zoneborders
by
allowing
a single pixelto
contributeto
multiple zones atthe
sametime.
Fuzzy Zoning
was analyzed andincluded in
the
classification with otherzoning
based
features.
Based
on experiments andtest results,
allfeature
extraction methods wereordered against
their
accuracy.As
this
ordering didn't
considertime
complexity
required ofthe
classifierto
work with a particularfeature,
the
size ofthe
feature
vectors wastaken
into
considerationfor
comparison purposes.A
new metric wasdeveloped,
which was calledNormalized
Accuracy
Mea
sure.
Unlike
a simpleaccuracy,
this
metric considerstime
complexity
offeature
classification.This
approach allowsoptimizing the total
characterrecognition
operation,
whichincludes both
feature
extraction and classification.
All feature
extraction methodswere compared and ordered againstthe
developed Normalized
Accuracy
Measure
metric.Keywords:
Feature
Extraction,
Optical Character
Recognition,
Nor
malized
Accuracy
Measure,
Fuzzy Zoning, Invariance, Handwritten,
Clas
sifier,
Off-line
features,
Pattern
Recognition,
Neural
Network,
Radial
Basis
Function
Network,
Multiple Layer Perceptron
Network, Handprinted,
Projec
tion
Histogram, N-tuple,
Hough
Transform,
Chain
Code
Transform,
Gabor
Filter,
Feature
Points, Strokes,
Character
Profiles,
Graph
Description,
Char
acteristic
Loci,
Shadow
Code,
Template
Matching, Zoning,
Angular
Parti
tions,
Radial
Coding,
Concentric
Circles,
Tracks
andSectors, Ring
Projec
tion,
Crossing
Method, Moments, Geometric, Central, Transformed,
Gegen-bauer, Legendre, Tchebichef
Krawtchouk,
Zernike, Pseudo-Zernike,
Fourier-Mellon, Wavelets,
Fractal
Encoding,
Fractal
Feature, Structural,
Statistical,
If
you wish your meritto
be
known,
acknowledgethat of
other people.Oriental Proverb
First
and
foremost,
I
would
like
to thank
members of
my
committee:
Dr.
Roger S. Gaborski
who
has
planted
in
me
the
seed of
interest
in
computer
vision
and
I'm
forever
grateful
to
him
for
that.
Among
other
things,
he has
wel
comed
me
into
the
world
of
Matlab
programming,
which
was
essential
for
the
success of
this
research project.
Dr.
Peter
G. Anderson
introduced
me
to the
field
of
pattern
recognition
and
laid
the
foundation
of
knowledge,
which
allowed
me
to
undertake
such
an
interesting
endeavor.
Additionally,
it
was
because
of
his
enthusiasm
that
I
was
able
to
learn
and master
the
art of
L^TgX. I
would
like
to
particularly
thank
my
advisor,
Dr. Leonid
Reznik,
whose
encouragement
and support made
the
process of
working
on
this
thesis
truly
enjoyable.
His
overall
contribution
Page 7
Special thanks goes to all the people who supported my
efforts: RIT librarians for doing the impossible in trying
to locate seminal papers from the early sixties. CS
de-partment lab personal for letting me print a forest worth
of drafts and sizable final copies of this thesis.
Gradu-ate Program Coordinator Dr. Hans-Peter Bischof and all
the secretarial staff for their help in processing my thesis
continuation requests. My fellow graduate student Dima
N ovikov for his help with Matlab.
On a more personal note, I would like to express my
grati tude to my parents who have always supported and
believed in me. Last but not least, I would like to
con-vey my appreciation to Kira Shvarts, who has helped in
a number of ways including proofreading this thesis.
Title
1
Signature
Page
2
Thesis Reproduction Permission Statement
3
Abstract
4
Acknowledgements
6
Contents
8
List
ofFigures
13
1
Introduction
25
1.1
Introduction to
Character Recognition
. .25
1.2
Pattern Recognition
System
. . . .26
1.2.1
Data
Collection
26
CONTENTS
Page 9
1.2.3
Feature Extraction
28
1.2.4
Classification
28
1.2.5
Postprocessing
29
2
Feature Extraction Methods
30
2.1
Features Utilized
by
aHuman
Reader
30
2.2
Image
Partitioning
Approaches
32
2.2.1
Zoning,
a.k.a.Sub-window Pixel Count
32
2.2.2
Fuzzy
Zoning
34
2.2.3
Zoning
-Meta
Feature
37
2.2.4
Angular Partitions
.412.2.5
Radial
Coding
a.k.a.Concentric Circles
. .43
2.2.6
Tracks
andSectors
. . ....46
2.3
Histogram Based Approaches
.502.3.1
Projection Histograms
. .502.3.2
Ring
Projections
55
2.4
Method
ofMoments
58
2.4.1
Geometric Moments
....59
2.4.2
Normalized Central Moments
... ....62
2.4.3
Moments
ofTransformed Patterns
. ...63
2.4.4
Radial
andAngular Moments
68
2.4.5
Gegenbauer Moments
69
2.4.7
Tchebichef Moments
72
2.4.8
Krawtchouk Moments
76
2.4.9
Zernike Moments
78
2.4.10
Pseudo-Zernike Moments
81
2.4.11
Fourier-Mellon Moments
83
2.5
Structural Approaches
85
2.5.1
Structural Features
85
2.5.2
Feature Points
87
2.5.3
Strokes
89
2.5.4
Character Profiles
92
2.5.5
Graph Description
98
2.5.6
Crossings Method
99
2.6
Transform
Based Approaches
103
2.6.1
The Fourier Transform
. .103
2.6.2
Gabor
Filter
108
2.6.3
Hough Transform
Ill
2.6.4
Chain Code
120
2.7
Fractal
Based Approaches
128
2.7.1
Fractal
Encoding
128
2.7.2
Fractal Feature
130
2.8
Other
Approaches
132
2.8.1
Characteristic Loci
132
CONTENTS
Page 11
2.8.3
Shadow Code
140
2.8.4
Template
Matching
.1463
Classification
Using
Neural
Network
150
3.1
NN
for Pattern Recognition
150
3.1.1
Multiple
Layer Perceptron Network
.... .1523.1.2
Radial Basis
Function
Network
.1533.1.3
MLPN
vsRBFN
. .153
4
Experiment
andProgram Descriptions
155
4.1
Description
ofPrograms
. .155
4.2
Data
Set Description
158
4.3
Description
ofExperiments
161
4.3.1
Experiment
1:
Optimization
ofMLPN
162
4.3.2
Experiment 2:
Optimization
ofRBFN
165
4.3.3
Experiment 3: Performance
Comparison
165
4.3.4
Conclusions
with respectto
MLPN
andRBFN
.169
5
Summary
ofResults
170
5.1
Taxonomy
ofFeatures
170
5.2
Summary
ofResults
175
5.3
Normalized
Accuracy
Measure
.... .179
5.4
More
onIndividual Features
... .183
5.4.2
Histogram Based
Approaches
185
5.4.3
Method Of Moments
186
5.4.4
Structural Approaches
187
5.4.5
Transform Based Approaches
188
5.4.6
Fractal Based
Approaches
...190
5.4.7
Other
Approaches
190
6
Conclusions
192
6.1
Accomplishments
... . .192
6.1.1
Future
Work
194
7
Appendix A:
Taxonomy
ofGeometric
Features
195
List
of
Figures
1.1
A
gap
and noisein
the
characterT
[171]
. . .272.1
Bouma's
classification ofletters
[272]
31
2.2
Upper-left:
characterA;
Upper-Right:
Zoning
gridimposed;
Lower-Left:
binary
zoning
feature;
Lower-Right:
sub-windowpixel counts .
32
2.3
Zoning
on agray level image,
(a)
A
4
x4
grid on agray
scalecharacter,
(b)
The resulting
averagegray
levels for
each zone[262]
34
2.4
Fuzzy
contribution of pixelslocated
in
a corner orin
a middleof a pattern
35
2.5
Fuzzy
mask withlinear decrease
in
pixel contribution of10
percent
for
each concentric square . . .36
2.7
Zoning
method withfuzzy
borders.
Pixel
Px
has
afuzzy
membership
value of .25in
each ofthe
four
zonesA, B,
D,
andE.
P2
has
a .75membership
valuein
zoneE
and .25in
zoneF
[262]
38
2.8
Zoning
combined with contourline
segment counts,(a)
character subdivided
into 16 equally
sizedzones;
(b)
contourlines
in
the
upper-right zoneonly;
(c)
count ofcontourlines
for
this
zone.
[262]
39
2.9
(a)
Normalized
digit
4.
(b)
Digit 4
partitionedinto 6x4 boxes.
(c)
pattern ofdigit
4
plottedusing
extractedfeatures
[92].
. .40
2.10
Zoning
using
a quadtree
[256]
41
2.11 Left:
Digits
'0',
'3', '6',
and '9' with16
angular partitions.Right:
Digit
'3'with
32
Angular
partitions[206, 205]
42
2.12
Differences between
the
letters
'M' and 'N'[260]
43
2.13
Difference in
size ofthe two
largest
arcs outsidethe
patternfor
the
letters
'M' and 'N'[260]
44
2.14
Concentric
circles appliedto
letters
'M' and'N'
[260]
44
2.15 Normalized
differences
obtainedfor
the
letters
'M'and 'N'
[260].
45
2.16
Concentric
circles appliedto
letter
LE\
shownin
different
rotations
and sizes.Numbers
in
the
first line indicate
the
numberof
intensity
pixel changesin
each one ofthe
eight circumferences.
Second line
representsthe
normalizeddifferences
overLIST OF FIGURES
Page
15
2.17
A
segmentation scheme with12
sectors and3
tracks
[57].
...47
2.18
Semented
images
of characters'G'
and
'H'
[57].
. ....48
2.19 Segmented
image
ofdigit
6
[100]
48
2.20 Horizontal
and vertical projectionhistograms
for digit five
[262]
51
2.21 2D
reductionto
ID using
a slit oflight
[180]
51
2.22
Horizontal, Vertical,
Left
diagonal,
andRight diagonal
projection
histograms
[234]
...52
2.23 Horizontal
and vertical projectionhistograms
on a mesh partitioned
Korean
character[133]
53
2.24
Horizontal
and vertical projectionhistograms
ofMarathi
character
[203]
53
2.25 Different
geometric shapes can produceidentical
projectionhistograms
[180]
54
2.26
Ring
Extraction
panel[246]
55
2.27
Ring
projection[246]
55
2.28
Ring
Projection
associated with accumulation[246]
57
2.29
Reconstruction
ofthe
letter
'E'
by
Legendre
moments.From
top
to
bottom
row andleft
to
rightin
each row: originalinput
image,
reconstructedimage
withup to
second order momentthrough up to twentieth
order moment[47]
71
2.30
Reconstruction
ofthe
letter
'E'by Tchebichef,
Legendre
and2.31
Reconstruction
ofthe
Chinese
characterby
higher
orderTchebichef
and
Legendre
moments with reconstruction error shown[183].
75
2.32
Reconstruction
ofthe
Chinese
characterby
higher
orderTchebichef
and
Legendre
moments with reconstruction error shown[183].
75
2.33 Reconstruction
ofthe
letter
'E'by
Tchebichef,
Legendre,
Zernike,
Pseudo-Zernike
andKrawtchouk
moments of orders9
through
16,
with reconstruction error shown[284]
77
2.34
Reconstruction
ofthe
letter
'E'by
Zernike
moments.From
top
to
bottom
row andleft
to
rightin
each row: originalinput im
age,
reconstructedimage
with second order momentthrough
up
to twentieth
order moment[47]
78
2.35 Examples
ofletters
reconstructed withZernike
momentsup
to the twelfth
order[171]
79
2.36
Examples
ofdigits
reconstructed withZernike
momentsup to
the twelve
order[136]
79
2.37 Reconstruction
ofthe
letter
'E'by
Pseudo-Zernike
moments.From
top
to
bottom
row andleft
to
rightin
each row: original
input
image,
reconstructedimage
withup to
second ordermoment
through
up
to
twentieth
order moment[47]
82
2.38 Examples
ofletters
reconstructed withPseudo-Zernike
moments
up to the twelfth
order[171]
82
2.39 Reconstruction
ofthe
letter
'b'by
Fourier-Mellon
moments.LIST
OF
FIGURES
Page
17
2.40
Reconstruction
ofthe
letter
'h'
by
Fourier-Mellon
moments.Reconstructed
image
withup to
441
moments[97]
84
2.41
Digit
six with some ofits
structuralfeatures
shown85
2.42
Decision
tree
for
numericalimages
[142]
86
2.43 Basic
pointtypes
with examples[237]
87
2.44
Templates
usedfor
extraction offeature
points[65]
88
2.45
Examples
ofChinese
characters withdifferent
feature
pointsshown
[291]
88
2.46
Basic
types
of strokes[3]
89
2.47
(a)
Original
characters;
(b)
Horizontal
strokes;
(c)
Right-diagonal
strokes;
(d)
Vertical
strokes;
(e)
Left-diagonal
strokes[46].
. .90
2.48
Inter-stroke
relationtypes
[153]
91
2.49
Digit
'5'with
left
profileXL(y)
and right profileXR(y).
For
each
y value, the
left
(right)
profilevalueis
the
leftmost
(right
most)
x value onthe
character contour[262]
92
2.50
Left, Right,
Lower
andUpper
profiles[115]
93
2.51
Maxima
andMinima
points on contour ofdigit
'3'[125].
...94
2.52
Contour
profilesampling
[76]
96
2.53 Feature
extractionusing
HPBA
andHPLD
[243].
. .97
2.54 Demonstration
of graph representations ofletters
'K' and'X'.
It
is clearly
seenhow different
characters canhave
same graphmorphology
98
2.56
Crossing
method,(a)
'2' and'5'
images
can'tbe
distinguished
when
only
the
verticaldetecting
lines
areused;
(b)
'2', '3',
and'5'
images
cannotbe
distinguished
by
the horizontal
detecting
lines
[180]
100
2.57
Sonde
method.Extracted feature
vectors shown undertheir
respective patterns.
Digit
zero means notcrossing
and onedenotes
strokecrossing
[180]
101
2.58 Contour
ofthe
character'A'
reconstructed with an
increasing
number of
Elliptic
Fourier descriptors.
[171]
103
2.59 30
Fourier
descriptors
extractedfrom digits
'2'
and
'6'
[112].
.104
2.60 Character
'4'reconstructed
by
ellipticFourier descriptors
oforders
up to:
1, 2,
...,10,
15,
20,
30,
40, 50,
100
[262]
106
2.61
Character
'5' reconstructedby
ellipticFourier descriptors
oforders
up to:
1, 2,
...,10, 15, 20, 30, 40, 50,
100
[262]
106
2.62
Character
'S' reconstructedusing the
Zahn
andRuskies'Fourier
transform
withthe
number of coefficients equalto
5, 13,
25
and
65
[129]
107
2.63
Character
'S' reconstructedusing
the
Granlund
Fourier
trans
form
withthe
number ofcoefficients equalto
5, 13,
25
and65
[129]
107
2.64
Character
'S' reconstructedusing
Zehn
and Ruskies'FT
modified
by
Krzyzak
at al.Number
of coefficients equalto
5,
13,
LIST
OF
FIGURES
Page
19
2.65
The
results ofusing the
Gabor
filtering
process:(a)
anoriginalimage;
(b)horizontal
feature
image;
(c)
right-diagonalfeature
image;
(d)
verticalfeature
image;
(e)
left-diagonal
feature
im
age
[236]
109
2.66
Orientation
maps producedby
Gabor filters for letters
'A7,
'L',
T
and'o'.
(b)
r =.1;
(c)
r=
1.1
[253].
110
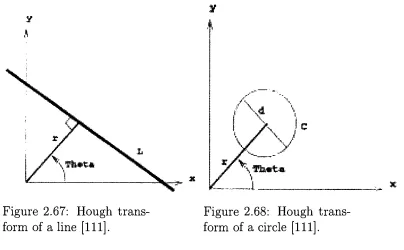
2.67
Hough
transform
of aline
[111]
Ill
2.68
Hough
transform
of a circle[111]
Ill
2.69
Hough
transform
of aline
on pattern 'p'[111].
112
2.70
Generalized
Hough
transform
of circle on pattern T'[111].
. .112
2.71
Fuzzy
setmembership
functions defined
onHough
transform
accumulator cells
for
circledetection from
a pattern ofheight
X
and widthY
[241]
117
2.72
Membership
functions
offuzzy
setsdefined
onHough
trans
form
accumulator cells.X
andY
denote
the
height
and widthof each character pattern
[240]
118
2.73
Some
ofthe
fuzzy
features
extractedby
Hough
transform
from
eight scanned
Bengali
characters[240]
119
2.74
Synthesized
fuzzy
setdefinitions
using
t-norms
[241]
119
2.75 Chain
codenumbering
schemes:(a)
Directions for
4-directional
chain code,
(b)
Directions
for 8-direcional
chain code[175].
. .120
2.77
Conventional
(1,
2,3)-Generalized
Chain Code
coding
rings[288]
122
2.78 Normalized
GCC
8-node
ring
[288]
122
2.79
(a)
The
8-directional Freeman
chaincode;
(b)
The
contour ofa sample
shape,
square;
(c)
Chain
Code
representation of asquare;
(d)
The Chain Code
Histogram
ofthe
square[109].
. .123
2.80
Example
ofChain Code
Transform:
(a)
A
45stroke;
(b)
Same
stroke after
thinning;
(c)
Stroke
labeled
withchain-codes;
(d)
Transformed
pattern[44]
125
2.81
Run Length
coding
example[185]
126
2.82
(a)
Binarized digits
T,'4'and
'7';
(b)
Digit
covering
withfour
self-affine
transformations;
(c)
Digit
fractal
reconstruction[9].
128
2.83
'F'is
covered with six contracted copies ofitself,
eachbar
is
being
covered withtwo
contracted copies placed sideby
side[9].
129
2.84
(a)
Digit
'7'inside
the
squarebox ABCD
and application offirst
affince contractionresulting in
A'B'C'D';
(b)
Coverage
using
five
contractions;
(c)
Fractal
reconstruction[9]
129
2.85
Diagram
offeature
extractionby
Fractal Feature for
the
Chi
nese character "Heart"
[247]
130
2.86
Diagram
offeature
extractionby
Fractal Feature for
the
characters
T
and 'J'[247]
131
LIST
OF
FIGURES
Page
21
2.88 Left:
full
ternary
code.Right:
4-tuples
withthree
orfour
zeroes removed
[171]
134
2.89
Left:
locations
ofthe
two
2-tuples. Right:
Same
two
2-tuples
learning
letter T
andthe
resulting
memory
states[17].
. . .135
2.90 System
learning
letter T in
two
different
locations
withinthe
image
[17]
136
2.91
Proximity
scoresfor
letters lT
and 'A'[17]
137
2.92
Templates for
characters*B\ 'G',
'5'[17]
137
2.93
10 basic
shapeslearned
by
the
system usedin
[17]
138
2.94
(a)
Seven-segment
bar
mask usedfor digit
recognition,(b)
13-segment
bar
mask usedfor
alphabetic capitalletters,
(c)
illustration
ofencoding the
character 'S' with shadow projections
shownin
black
[26]
141
2.95
(a)
16-bar
frame;
(b)A
binary
pattern andcorresponding
shadows;
(c)
Normalized
Shadow
Code
[248]
142
2.96 Shadow
codesfor
rotations multiple of90 canbe
obtainedby
simply re-ordering
the
components ofthe
code vector[249].
142
2.97
Bar domains
in
whichthe
dashed lines
indicate
(a)
horizon
tal,
(b)
vertical,
(c)
diagonal bars
where pixelsin
each regionproject
their
shadows[215]
. .143
2.98
32
segmentbar
mask[229]
144
2.99
Illustration
ofencoding
ofArabic digit
'8'2.100Shadow
maskfor
signature verification.Left:
An
individual
sampling
squareshowing
the
six projection areasto
be
measured.
Right:
The
signatureis drawn
over a grid ofthese
squares.
Bottom: Each
shadowcalculation projectsthe
signature
in
each square ontothe
projection areas[194]
144
2.
lOlFifteen bar
mask representations[215]
145
2.102Fitting
ofdifferent
templates
to the
patternin
question[93].
.146
2.103Multiple
templates
for digits
with alternative representations[93]
147
2.104Ten
templates
fitted
to
animage
with patternin
question[93].
148
2.105Determination
of an unknown pattern via pointto
pointdis
tance
measurement as performedby
Elastic
Matching
[220].
.149
3.1
Differences
in
performance ofRBFN
andMLPN
as reportedby
different
researchersif
the
field
of pattern recognition. . . .1513.2
Model
representation ofMLPN
152
3.3
Model
representation ofRBFN
154
4.1
Examples
ofdigits
1 through
6 from
the
data
set utilized. . . .159
4.2
Examples
ofdigits
7,
8,
9
and0 from
the
data
set utilized. ...160
4.3
Recognition
accuracy
in
percentages(vertical-axis)
achievedby
MLP
based
onthe
number ofhidden
nodes used162
4.4
Recognition
ratein
percentages(vertical-axis)
achievedby
LIST OF FIGURES
Page
23
4.5
Recognition
ratein
percentages(vertical-axis)
achievedby
MLP based
onthe
Alpha/Beta
value used164
4.6
Percentage
of accurate recognition(vertical-axis)
achievedby
RBFN based
on width of radialbasis
centers165
4.7
Time
requiredby
MLPN
andRBFN
to
fully
train,
based
onthe
size ofthe
training
set ...166
4.8
Performance
ofMLPN
vsRBFN
onthe
training
setsranging
in
sizefrom
100
to
2500
elements(horizontal-axis)
withrespectto
recognitionaccuracy in
percentages167
4.9
MLPN
performance statistics .168
4.10 RBFN
performance statistics168
5.1
Classification
offeature
extraction methodsfor
the
variouscharacter representation
forms
[262]
.171
5.2
Features
from
taxonomy
by Trier,
but
rearrangedand groupedand methods marked with an asterisk
have been
added[136].
.172
5.3
A
dichotomy
'strucuraT
versus'statistical'
reflects
the
corresponding
principles of classification.The
words'heuristic' and
'systematic'
refer
to
the way the
features
are selected[136]
. .173
5.4
A
taxonomy
proposedby
the
authorfor
the
feature
extractionmethods utilized
in
character recognition174
5.5
Listing
oftested
feature
extraction methods with achieved ac5.6
Listing
oftested
feature
extraction methods sortedby
accuracy.177
5.7
Listing
oftested
feature
extraction methods sortedby
respective
size ofthe
feature
vector178
5.8
Listing
oftested
feature
extraction methodssortedby
achievedaccuracy
normalizedfor
the
size ofthe
feature
vector180
5.9
Listing
oftested
feature
extraction methodswith achieved accuracy
normalizedfor
the
size ofthe
feature
vector andfor
random
guessing
182
5.10
Number
of2D
zones versusaccuracy
183
5.11
Location
offive
2D
zones versus accuracy.184
5.12
Confusion
matrix producedby
the zoning
feature
184
5.13 Number
ofGeometric
moments versus accuracy.187
5.14
Accuracy
producedby
different
types
ofProfile
feature
188
5.15 Confusion
matrix producedby
the
Hough
Transform
feature.
.189
5.16 Number
ofFast
Fourier
Transform
coefficients versus accuracy.190
Chapter
1
Introduction
The
beginning
of
knowledge
is
the
discovery
of something
wedo
not understand.
Frank Herbert
(1920
-1986)
1.1
Introduction
to
Character Recognition
Since
the
1950's
Optical Character
Recognition,
orOCR,
has been
an activefield
of researchfor
computer scientists worldwide[262].
The
main reasonis
that
OCR
is
notonly
aninteresting
area oftheoretical
research with relevance
to
many
pattern recognitionsub-fields,
but
also avery
needed and useful real-life application.Making
computers ableto
read paperdocuments
would allowfor
substantial
savingsin
terms
ofthe
costsfor
data
entry,
mailprocessing, tax
form
processing,
censusform
processing
andmany
other similar situations.Addi
tionally,
this
cansimplify
the
life
ofthe
handicapped
by
making
computers ableto
read outloud
to visually
impaired.
Modern
OCR
systems are ableto
recognize most printedfonts
and evensome neat
handwritten
text
with acceptable accuracy.As
aresult, the
cur rent researchin
OCR has
shiftedtowards
omnifont machine printedtext,
1.2
Pattern
Recognition
System
All
completeOCR
systems consist ofmultipleprocessing
steps, namely:im
age acquisition,preprocessing,
feature
extraction, classification,
andfinally,
postprocessing.In
this
work, we will concentrate onthe
feature
extraction step, since selection of goodfeatures
is
arguablethe
mostimportant step
towards
achieving
high levels
ofaccuracy
by
the
OCR
system.1.2.1
Data
Collection
Data
collection approaches canbe
asdiverse
asthe
characterdata
itself,
from
optical scannersto
onscreen pointers.Regardless
ofthe
type
ofdevise
producing
the
image
ofthe
pattern,
data is
usually
collectedin
avery
raw state.Typical
sources ofdata
include
postalzip
codes and addresses, censusform
data,
surveys,
medical reports, etc.The handwritten
text
is
typically
comprised of whole words notisolated
characters and one ofthe
first
stepsis
to
break
up
sentencesinto
words and wordsinto individual
symbols.The
resulting
images
ofindividual
symbols are what we need asinput
data
for
the
character recognition system.1.2.2
Preprocessing
Preprocessing
involves cleaning up
the
data
andtrying
to
makeit
aseasy
to
classify
as possible.The
cleaning
ofdata
includes
filling
of gaps and removal ofnoise,both byproducts
ofimage
acquisition process or ofthe
later
character
segmentation algorithm.Examples
of agap
and noise aredemonstrated
in
the
Figure
1.1.
Usually
afilter
is
used onthe
image
to
closethe
gaps andto
remove noiseparticles,
which aretypically
detected based
ontheir
small size with respectto the
main pattern.Additional
preprocessing may
be
neededin
case of color or grayscaleim
ages.
Normally
colorimages
are rare and areeasily
convertedto
grayscale.Grayscale images
needto
be binarized for
which athresholding
algorithmis
utilized, withthe
finding
ofthe
optimalthreshold
valuebeing
the
most1.2.
PATTERN
RECOGNITION
SYSTEM
Page
27
Another
step,
callednormalization, may
be
presentif
wedesire
to
obtain animage,
whichis
processedto
counteractthe
effects oftranslation,
scaling,
and rotation.In
each ofthose
special situations a particular algorithm canbe
applied:Translation This
is
the
casein
whichthe
patternis
located
offthe
center ofthe
image
containing
the
pattern.To fix
this the
pattern couldbe
shifted,
for
example, to the
point whereits
upper-left cornerlines
up
with a particular pixelin
the
image.
Rotation
This is
the
casein
whichthe
patternis
orientedin
away,
whichis
different
from
the
onein
whichhuman
reader wouldtypically
readit.
This
could rangefrom
just
afew degree
ofdifference
to
a complete upside-down pattern.There
is
noeasy
to
apply
solution asknowing by
how
muchto
rotatethe
pattern requiresfirst
to
recognizeit,
andthis
of courseis
not possible atthis
step.Scaling
This
is
the
casein
whichthe
patternis
stretched ortruncated
and soit is
hard
to
recognizedue
to the
difference
in
size.This is easy
to
fix
by
rescaling
the
patternto
some standard size expected of all patternsbeing
processed.1.2.3
Feature
Extraction
Since
direct
processing
ofscanned charactersimages is
computationally
prohibitive,
the widely
acceptedtechnique
of pattern recognitionis
to
extract somefeatures from
the
originaldata
and perform classification onthose
fea
tures.
Extracted
features
musthave
certain propertiesin
orderto
achievelow
error ratesin
character classification.Features
must provide maximum amountofinformation
aboutthe
originalpattern,
ideally
completely
describ
ing
it.
The
total
number offeatures
shouldbe
minimizedto
reduceburden
onthe
classification step.This
meansthat
usedfeatures
shouldbe
indepen
dent
of each otherin
orderto
maximizeentirety
of providedinformation
[171]
.Since
the
same character canlook
very different if it
is
translated,
scaled,
rotated, stretched, or skewed,ideally
we areinterested
in
finding features,
which remain constant underthe
above-mentioned morphing.If
features
with such properties cannotbe
extracted,
an alternativeis
to
useimage
nor malization with respectto
the
size,rotation,
andthickness
ofthe
character.Unfortunately,
this
methodhas
adown
side ofintroducing
new errorsinto
the
data.
Not
the
least
ofthe
good properties of a pattern'sfeature is
ahigh
tolerance to the
noise anddegradation
in
the
originalimage,
as well asthe
complexity
ofthe
computation ofthe
feature
[262,
171].
An
important
characteristic of a good pattern'sfeature
is reconstructability,
which meansthat the
feature
contains enoughinformation
to
reconstructthe
original pattern.While
not always achievable,reconstructability is
adesir
ableproperty
because it
serves as a proofthat the
feature
contains allthe
needed
information
to
recognizethe
patternin
question.For
somefeatures,
such asinfinite
series coefficientsonly
partial reconstruction ofthe
originalimage is
possible sinceonly
a small subset of aninfinite
seriesis
used as afeature. The idea is
that
if
such small subsetis
sufficientto
reconstructthe
original pattern even
approximately,
the
features
musthave high information
content and so poseshigh
discrimination
power[262].
1.2.4
Classification
Classifier
is
one ofthe
mostimportant
parts ofany
pattern recognition system.
The job
ofthe
classifieris
to
look
atthe
feature
vector extractedfrom
be-1.2.
PATTERN RECOGNITION
SYSTEM
Page 29
longs.
A large
numberofdifferent
classifiersexist,
but
they
all canbe
groupedunder
the
following
headings:
Template
Matching
Each
patternis
compared against all otheralready
classified patterns and
the
setto
whichthe
closest matchbelongs is
selected as
the
probable class ofthe
pattern.Statistical Classifiers In
this
approach afunction
is
designed,
whichhas
the
property
ofsubdividing
the
feature
space withhyperplanes
so char acters ofdifferent
types
a separatedinto
different
regions.Artificial Neural Networks
Based
onthe
neural networksfound
in
nature,
those
interconnected
tiny
computing
devices
cometogether
to
provethat
sometimesthe
wholeis
greaterthan the
sum ofits
parts.This
is
the
approach oftentried
in
different
fields
of artificialintel
ligence
andparticularly
in
computer vision and pattern recognition.Detailed
introduction
to the theoretical
properties ofArtificial
Neural
Networks
couldbe
found
in
Chapter
3.
Decision
Trees Determine
type
ofthe
patternbased
onthe
set ofrules;
each
designed
to
further
subdivide patterns untilthe
identity
ofthe
patternbecomes
obvious.1.2.5
Postprocessing
This
is
an optionalstep,
whichtypically
involves
correction of errors and reconstructionof
the
originaldocument. Once
eachindividual
symbolhas been
recognized, the
symbols are groupedtogether to
form
words.Then
words are compared against adictionary
to
seeif
such combinations of characters existin
the
language.
A
simple spellchecker couldbe
usedto
replace anunexisting
word withthe
correct one.
Additionally,
the
wordssurrounding
the
onein
question couldbe
usedto
improve
the
correctiveability
ofthe
spellchecker.Such
systemsFeature
Extraction
Methods
There
is
much pleasureto
be
gainedfrom
uselessknowledge.
Bertrand Russell
(1872
-1970)
2.1
Features Utilized
by
a
Human Reader
In
construction ofthe
program capable of 'reading5individual
characters, it
may be
valuableto
considerhow
the
best-known
systemfor
the
purpose ahuman
being
operates.What
features do human
readers utilizeduring
char acter recognition process, and could weteach the
machinesto
usethe
same ones?Those
arethe
questionsanswers, to
whichmay
come asextremely
beneficial
to
construction of ahigh
accuracy
pattern recognition system.It
is
a well-knownfact
that
peoplerarely
have
to
recognizeindividual
characters
in isolation.
The
typical task
ofreading
consists ofrecognizing
symbols,
which make
up
complete words.As
establishedby
many
experiments,
the
meaning
of aword,
as well asthe
shape ofthe
wordcontributeto the
correctrecognition of
individual
characters.This is something
nottypically
pro grammedinto
the
character recognitionsoftware,
atleast
not priorto
afew
years ago[272].
In
researchinto reading,
asin
most ofpsychology,
observing
the type
oferrors made under
hard
circumstancesis
avery
fruitful
type
ofinvestigation.
2.1.
FEATURES
UTILIZED
BY
A HUMAN READER
Page
31
subjects
during
the task
of character recognition.He
presented character symbolsto the
subjects at adistance
orfor
avery
shortduration
oftime,
and examinedthe
confusions madebetween different
letters. Bouma
groupedthe
characters ofthe
English
alphabetinto
setsbased
onthe
errors madeby
the
subjectsin
his
experiments.The Bouma's
classification oipsychologically
closeletters
is
presentedin Figure 2.1.
Outer
contourBouma
shapeCode
Letters
Short
inner
parts and rectangular envelope1
a s z xround envelope
2
e o coblique outer parts
3
r v wvertical outer parts
4
n m uTall
ascending
extensions5
dhkbslenderness
6
ti
1 fProjecting
descender
7
g
j
p q y
Figure
2.1: Bouma's
classification ofletters
[272].
The
classification consists ofthree
large
sets,
namely
Short,
Tall
andProjecting
characters,
which arefurther
subdividedinto
asmany
asfour
subgroups withup to
five
charactersin
each.The
actualfeatures believed
to
be
usedby
human
readersvary
by
a re searcher.Hubel
andWiesel
believe
the
features
are generatedearly in
the
visual cortex.
The
complex cellsthey
found detect
the
presence ofbars
and edges and provide a representation oflines.
McGraw
et al. conducted experiments
with machine printed characters andfound
that
high-level
structuraldescriptors
ofletters
arevery
likely
utilized.For
example,
aletter
'b' couldbe described
as aloop
with a stroke attached atthe
lower
right.Intuitively,
this
latter
representation seemsvery
closeto
ahuman
heart,
but
we can notdismiss
the
value of unconscious processes[272].
Later
in
the
chapter we will seethat
both
types
offeatures
areindeed
put2.2
Image
Partitioning
Approaches
2.2.1
Zoning,
a.k.a.Sub-
windowPixel
Count
The
method ofzoning
wasintroduced in 1972
by
Hussain,
[107].
It is
one ofthe
easiestfeature
extraction methodsin
terms
ofimplementation.
The
feature
producedis
anarray
ofintegers representing
the
number ofturned-on pixels
in
the
sub-windows of an originalimage.
Refer
to
figure
2.2
for
a visual representation ofthe
aboveidea.
Figure
2.2:
Upper-left:
characterA;
Upper-Right:
Zoning
gridimposed;
Lower-Left:
binary
zoning
feature;
Lower-Right:
sub-window pixel countsIn
moreformal
terms
the
idea is
to
sub-dividethe
bilevel
image into K
non-overlapping
regions or zonesRi,
i
=1...K,
each of sizeh
x v.In
this
casethe
feature
f
is
the
number offoreground
pixelsin
i^.
This
2.2.
IMAGE PARTITIONING APPROACHES
Page
33
The
number ofsub-windows,
K,
usedduring
feature
extraction,
canvary
from
aslittle
asone, giving
usthe
area ofthe
binary image,
to the total
number
of pixelsin
the
image,
h
v,
resulting in image itself.
Smaller
sub-window
size results
in
better
discriminatory
performance,
sincein
large
sub-windowsimportant
patterninformation
gets smashed.Typically,
a window size of4x4
or8
x8
is
used.The
resulting
feature
vector remainsrelatively small,
even as a size ofthe
input image increases. For
example,
evenin
a small30
x30
pixelimage using 5x5
sub-windows we endup
with a36-dimensional
vector.In
the
original paperHussain
et al.[107],
summarizedthe
desirable
properties
oftheir
proposedfeature
extraction algorithm asfollows:
The feature
vectoris
obtainedfrom
the
pattern matrixby
a repetitiveprocedure
involving
only
the
simplelogical
operation ofcounting
the
number of
black
pointsin
a well-defined region.The
feature
vector'sdimensionality
is significantly
lower
than that
ofmany
other schemes andthe
features
themselves
assumeonly
a relatively
small number of values.Discontinuities
in
the
charactermatrix,
including
salt and peppernoise,
canbe
tolerated
[107].
An
additional reductionin
the
complexity
of an extractedfeature
canbe
achievedby
replacing
pixel countsfor
each sub-window with abinary flag
signifying
state ofthe
patternin
this
region.See bottom-left
offigure
2.2
for
an example of so calledbinary-zoning
feature.
Unfortunately
this
strategy
significantly
reduces adiscriminatory
ability
ofthe
zoning
feature.
In
additionto
being
applicableto
binary
images,
zoning
canbe
used ongray
scaleimages
as well.In
orderto
extractthe
feature
vector,
an averagegray
level is
computed as canbe
seenin
figure
2.3.
Unfortunately,
the
resulting
feature
is
notillumination invariant
[262].
Zoning
methodis
a universalfeature
extractor,
capable ofoperating
onbi
nary, gray scale, contour,
and even skeleton character representations.But,
it
does have
some obviousproblems,
such asits
lack
oftolerance
for
eitherrotation, shifting
or scaling.While
invariance is
adesirable
property
of a goodfeature,
through
some cleverpreprocessing
we can almostcompletely
4
mmWT. mm
1
w
%
|
|
|
:'
'
i
=:-(a)
0>)
Figure
2.3:
Zoning
on agray
level
image,
(a)
A
4
x4
grid on agray
scalecharacter,
(b)
The
resulting
averagegray
levels for
each zone[262].
Zoning
Pseudonyms
It
is
a well-knownfact,
that
sometimesin
the
process of scientificdiscov
ery
different
researches stumble uponthe
sameidea
independently
of one another.Nothing
is
truer
aboutfeature
extractionmethods,
in
particularZoning. While
it
is
most popular underthat
name, it is
not at all uncommonto
read aboutit
under a pseudonym.For
examplein this thesis
it
is
referredto
as pixel-sub count method.It
is described
asDensity
Feature
in
the
work ofBajaj
et al.[8]
named after a smallmodification,
namely
normalization processin
whichthe
sum ofthe
pixelsin
each subwindowis
being
divided
by
the
total
number of pixelsin
that
zone,
resulting in
the
black
pixeldensity
for
that
region.The
samefeature
without modificationsis
calledAveraging
Algorithm
in the
paperby
Toroketal.
[261].
Finally
Hanmandlu
et al.[92]
refersto
it
asBox
Approach.
Such
multitude ofnames makes comparisonofworksby
different
researchersmore complicated and
hopefully
this
thesis
willbe
astep towards
universalnaming
conventionfor
different features
usedin
character recognition.2.2.2
Fuzzy
Zoning
The
method ofFuzzy
Zoning (FZ)
developed
by
the
authoris
aimed2.2.
IMAGE PARTITIONING
APPROACHES
Page
35
position and
size,
which cause problemsfor
the
classicalzoning
approachBBMP'
! *.*l*****4l
Figure
2.4:
Fuzzy
contribution of pixelslocated
in
a corner orin
a middle ofa pattern.
The
main problem withthe zoning
methodis its
reliance onrigid
zoneborders.
Each
pixel either contributesto
a particular zone ordoes
not,
de
pending
onits location. This has
particularly
negative effectin
case ofnear-border
pixels as eventhe
smallest shiftin
the
pattern resultsin
adifferent
feature
vector.Cao
at el. attemptedto
counteractthis
problemby
creating
something
calledFuzzy
Borders
(FB).
The
maindistinction
ofFB lays
in
the
fact
that
points ofthe
patternlocated
near zoneborders
are givenfuzzy
membership
valuesin up
to
four
zones atthe
sametime.
Fuzzy
membership
values are normalized
by
alwaysadding
up to
onefor
all zones[31].
Taking
the
idea
behind
FB
andexpanding
onit
we cameup
withthe
concept ofFZ.
Unlike
in
a case ofFB
in
whichonly
border-pixels
have
fuzzy
properties
andonly in up
to
four different
zones,
our method gives all pixelsfuzzy
image
depends
onits
relativelocation
withinthe
zone as well as withinthe
global pattern.
Figure 2.4
demonstrates
this
idea.
Pixel PI located
in
zoneCA
contributesheavily
to
that
zone sinceit is
located
almostin
a middle ofit,
but
it
also contributes,but
to
a muchlesser
extent,
to
zonesCB,
BB
and
BA. Pixel
P2
located
in
zoneBC
also contributesheavily
to
its
home
zone,
but
it
alsocontributes,to
zonesAD, AC, AB,
BB,
CB, CC,
CD
andBD.
The
actual contribution of each pixelto
each zonedepends
onthe
distance
between
the
pixel andthe
zone andis automatically
calculatedby
performing
multiplication operationbetween
the
original pattern andthe
special fuzzy-maskdeveloped
by
us.The fuzzy-mask
is
agroup
of concentric squares whose weighted valuediminishes
linearly
asthe
distance from
the
center ofthe
maskincreases.
Figure 2.5 is
a samplefuzzy-mask
withlinear decrease
in
pixel contribution of10
percentfor
each concentric square.By
moving
the
fuzzy-mask
acrossthe
entire originalpattern,
we were ableto
obtainFZ
feature
vectorconsisting
of25
individual
elements eachrepresenting
a unique zone andthe
fuzzy
contribution ofthe
zone's neighbors.Figure
2.5:
Fuzzy
mask withlinear decrease
in
pixel contribution of10
per2.2.
IMAGE PARTITIONING APPROACHES
Page
37
*4M
7
/
r
l I \
Figure
2.6:
Discriminative
ability
oflocal information
[192].
2.2.3
Zoning
-Meta
Feature
Zoning
feature has
already
been described
in
section2.2.1,
whereit
was equated withthe
sub-window pixel counts.In
that case, the
image
was subdivided
into
zones andfor
each zone an area ofthe
character patternfalling
in
that
zone was computed.The
concept ofzoning
canbe
abstractedinto
the
so-calledmeta-feature, by
saying
that
it simply involves
breaking
the
originalimage
into
a number of subzones.The
resulting
subzones canbe
processedwith
any
feature
extraction methoddescribed
in
this thesis.
The
resulting
feature
vectors canbe
concatenatedinto
one comprehensivefeature
vectordescribing
the
overall pattern.The
main advantage ofthe
zoning
meta-methodis
that the
properties ofindividual
subparts ofthe
image
are notmixed,
but
extracted separately.This
allowsfor local information
to
play
a more significant rolein
pattern classification.It is
a well-knownfact
that
local information
is
often all you needto
distinguish
patternsbelonging
to
a particular subset of all possible patterns.Figure 2.6 demonstrates how digits
'3' and '5' canbe
ruled outif
lo
cal
information
in just
one subzoneis
moretypical
of adigit '7's
pattern[192]
.de-A
B
C
llr r.
D
1
E
1
F
P2
G
H
1
Figure 2.7:
Zoning
method withfuzzy
borders. Pixel
P\
has
afuzzy
membership
value of .25in
each ofthe
four
zonesA,
B, D,
andE.
P2
has
a .75membership
valuein
zoneE
and .25in
zoneF
[262].
gree of variation
into
the
feature
subvectors.The
subpatternsmay
showup
differently
in
subwindowsdue
to
even small shapevariationsin
the
wholepattern,
resulting in
radicaldifferences
in
the
values computedfor
subvectors, whichin
turn
makesthe
concatenatedfinal feature
vectorless
continuous patterndescriptor
[136].
Cao
at el. attemptedto
counteractthis
problemby
creating something
they
calledfuzzy
borders. The
maindistinction
offuzzy
borders
is in
the
fact
that
points ofthe
patternlocated
near zoneborders
aregiven
fuzzy
membership
valuesin
up to
four
zones atthe
sametime.
Fuzzy
membership
values are normalizedby
alwaysadding
up to
onefor
all zones[31].
Figure
2.7
demonstrates
zoning
withfuzzy
borders.
Since
the
zoning
method as presentedhere
is
just
away
to
break
up
the
original
image,
we are stillfaced
with a choice offeature
extraction methodto
be
used with our subdivision approach.Different
researchershave
tried
out
different feature
extraction methods withvarying
degrees
of success.Examples
of some ofthe
features
utilized aredescribed below.
In
general,
2.2.
IMAGE
PARTITIONING APPROACHES
Page
39
J
^^3
(
/
<
N,
\.
/
V
(a)
orientation count
0 45 90 135
9
1
2
4
(c)
Figure
2.8:
Zoning
combined with contourline
segment counts,(a)
character subdividedinto 16 equally
sizedzones;
(b)
contourlines
in
the
upper-right zoneonly;
(c)
count of contourlines for
this
zone.[262].
Kimura
andShridhar
worked with contour curves asthe
pattern representation technique.
After
applying zoning
they
groupedthe
contourline
segmentsbased
on orientationinto four
subgroups,
namely:horizontal,
vertical,
diag
onal (45 and
135)
orientations.The
number of contour segmentsbelonging
to
eachgroup
was used asthe
extractedfeature for
each zone.Figure 2.8
demonstrates
this
approach[125].
Another
researcher,
Takahashi,
also usedorientation
histograms,
but
in
additionhe
alsofound high
curvature pointsalong
the
contour.For
each suchpoint,
Takahashi
computed contourtan
gent,
curvaturevalue,
and position withinthe
zone[262].
Singh
andHewitt
[231]
used a modifiedHough
transform
(see
Section
2.6.3
for
details)
in
combination with nine3x3
windowsin
their
work on cursivedigit
and character recognition.000 00001 000000 000000000000000 0 OODOOOOIQOOQOO00000000000 00000
00000001000000 00600000000 00000
OOOOOO I I ! 1)110 l I IHH!IHHMHJ flit
00000100000000 0000000000000800
OOOOI00OQOOOOO0000009000000011 000 IfOAAOAOOOBOA0O0O0OO6AAOO1 8 OOO1OO0O0OO0O00O0O0OOO0O0OOI00
ODD10000000 UO0O0BU 00 0O0O0OO100
001O0O0O0OO0O8OOO0OO0O000O1000 OOIOOOOOOOOODOOOOOOOOOOOQI1000 0100000 0000000 0000 0000000 16000 I I000O0OO0O00009OQ00OO0OO10000 100000000000000000000000110000
lOOOAOOAOAOOAAOAOOOOOOOOIOOOOO
I1 1 00000000 0000000 OOOOOO I 00000 OH 1000000000OO00 000000 0100 0000
0001 I000000000 00 00 ODOOO I OOOOOO
n n minii1 1 nnnnnnnnnnnnnninnnnnn 00000000011 I 100O0000OO01OO0000 000000000000011100000001000000 OOOOOOOOOOOOOOOOI 1I 1I1 II t 11000 OOOOOOOOOOOOOOOOOOOOOOIOOOOIIO
0OO00O0OOOO0OOOOD000010OO0000I
OOOOOOOO 000 0000000000100000000 000000000000000000001100000000 0000000 0000001000000 1000000000
OOOOAOOOO0OOOBAAOOAO1OAOOAAA0A
OOOOOOOOOOOOOOOOOOOIOOOOOOOOOO U IMRHHI t) UO UllUIHUIOU1MMUOOOOOOOUU OOOOOOOOOOOOOOOOOOOIOOOOOOOOOO OOOOOOOOOOOOOOOOOOOIOOOOOOOOOO (a) _^_ " .
12 3 4
(c)
Figure 2.9:
(a)
Normalized
digit
4.
(b)
Digit 4
partitionedinto 6x4 boxes.
(c)
pattern ofdigit
4
plottedusing
extractedfeatures
[92].
For
examplein
[92]
bottom
left
corner ofthe
originalimage is
usedfor
such purpose.The
vectordistance for fcth
pixelin
6th box
atlocation
(i,j)
is
calculated as,d\
= (i2+ j2)'5.
By dividing
the
s![Figure 2.46: Basic types of strokes [3].](https://thumb-us.123doks.com/thumbv2/123dok_us/125656.12183/90.613.160.411.298.583/figure-basic-types-of-strokes.webp)
![Figure 2.50: Left, Right, Lower and Upper profiles [115].](https://thumb-us.123doks.com/thumbv2/123dok_us/125656.12183/94.613.145.429.138.509/figure-left-right-lower-upper-profiles.webp)
![Figure 2.51: Maxima and Minima points on contour of digit '3'[125].](https://thumb-us.123doks.com/thumbv2/123dok_us/125656.12183/95.613.131.492.298.519/figure-maxima-minima-points-contour-digit.webp)
![Figure 2.52: Contour profile sampling [76].](https://thumb-us.123doks.com/thumbv2/123dok_us/125656.12183/97.613.190.416.129.436/figure-contour-profile-sampling.webp)
![Figure 2.53: Feature extraction using HPBA and HPLD [243].](https://thumb-us.123doks.com/thumbv2/123dok_us/125656.12183/98.613.114.458.141.411/figure-feature-extraction-using-hpba-hpld.webp)
![Figure 2.55: Method of stroke analysis via slits [232]](https://thumb-us.123doks.com/thumbv2/123dok_us/125656.12183/100.613.173.403.234.533/figure-method-stroke-analysis-slits.webp)
![Figure detectingcannot be distinguishedc2' detecting by (b) the horizontal lines '5' imageswhen only the Crossing verticalmethod, lines are '5'used; images 2.56: (a) and can't be distinguished '2', '3', and[180].](https://thumb-us.123doks.com/thumbv2/123dok_us/125656.12183/101.613.107.498.156.534/detectingcannot-distinguishedc-detecting-horizontal-imageswhen-crossing-verticalmethod-distinguished.webp)
![Figure 2.59 shows 30 Fourier descriptors extracted from digits'2' and'6'[112].](https://thumb-us.123doks.com/thumbv2/123dok_us/125656.12183/105.613.161.440.460.680/figure-shows-fourier-descriptors-extracted-digits.webp)
![Figure 2.66: Orientation maps produced by Gabor niters for letters 'A','L'Tand'o'. (b)r = .l; (c) r = 1.1 [253].](https://thumb-us.123doks.com/thumbv2/123dok_us/125656.12183/111.613.122.483.112.676/figure-orientation-maps-produced-gabor-niters-letters-tand.webp)