Faculty of Engineering & Surveying
ERROR RESILIENCE TECHNIQUES FOR
WIRELESS 3-D VIDEO TRANSMISSION
A thesis submitted by
Khalid Mohamed Alajel
B.sc.Eng., M.sc.Eng.
in fulfilment of the requirements for the degree of
Doctor of Philosophy
by
Khalid Mohamed Alajel
Three-dimensional (3-D) video has only recently become a buzzword. It offers a high quality and immersive multimedia experience on consumer electronic plat-forms. The year 2009 was a seminal year for 3-D video with the first successful film Avatar illustrated its use to a wide audience. As a result of advances in cap-turing, signal processing, transmission, and display technologies, both industry and academia are now focused on delivering 3-D media to home systems and to mobile devices. Wireless transmission of 3-D video content is expected to be the next big revolution in consumer multimedia applications. It faces many challenges in the processing chain from capture to display. Because of these challenges, this thesis investigates and presents a number of novel techniques for error resilience 3-D video transmission.
Four error resilience techniques for 3-D video transmission over wireless networks were proposed. The recent H.264/AVC standard and the video-plus-depth 3-D video format were adopted to assist in implementing these techniques. The pro-posed methods could also be applied to other video coding standards and to different 3-D video formats.
This thesis begins by investigating the standard error resilience source coding of H.246/AVC I-frame and of JPLW for still image transmission. Standard error resilience techniques are reviewed and compared. The experimental results show that H.264/AVC is much more robust in reducing transmission errors than JPWL.
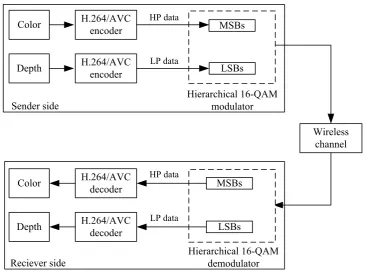
3-D video with depth image based rendering (DIBR). The video-plus-depth for-mat is partitioned into two sequences, i.e., a color sequence and a depth sequence, according to their respective importance to the overall quality of the 3-D video. In this approach, the highly important color sequence is better protected with the most significant bits (MSBs) of 16-QAM, while the less important depth sequence uses the less significant bits (LSBs).
The third part of the thesis investigates the use of cooperative diversity to enhance the performance of high data rate communication over wireless fading channels. Although cooperative diversity has received much research attention recently, it has not yet been investigated in the context of unique characteristics of 3-D video transmission. In this part, the performance of a cooperative 3-D video system, with amplify-and-forward (AF) relaying, for UEP 3-D video trans-mission through best relay selection is investigated. In particular, closed-form expressions for outage probability and bit error probability (BEP) were devel-oped. The results of the BEP, outage probability, and peak signal-to-noise ratio (PSNR) were presented to demonstrate the proposed UEP scheme in terms of the received quality of 3-D video.
Finally, for more efficient 3-D video transmission, relay selection and hierarchical quadrature amplitude modulation (HQAM) were joined because they help address the problems of diversity and robustness. This part is concerned with the use of hybrid relay networks and HQAM for improved UEP transmission of color-plus-depth 3-D representation. Hybrid relay selection along with HQAM was proposed as a method to overcome the decreases in video quality of high SNR values when HQAM was used alone. It has the advantages of both techniques at different SNR regions. Analytical expressions of the BER and outage probability of the SNR were given in closed-form.
My very unique and deceased mother, My dear father, and Siblings,
I certify that the ideas, designs and experimental work, results, analyses and conclusions set out in this dissertation are entirely my own effort, except where otherwise indicated and acknowledged. I also certify that the work is original and has not been previously submitted for assessment in any other course or institution, except where specifically stated.
Khalid Mohamed Alajel
W0091575
.../.../2013
Signature of Candidate Date
ENDORSEMENT
.../.../2013
A/ Prof. Wei Xiang, Principle supervisor Date
.../.../2013
First and foremost I am thankful to Almighty ALLAH, without his blessings it is impossible to complete this thesis. I would also like to express my gratitude to the Libyan government through the Higher Education Ministry and Almergheb University for providing me the scholarship to pursue my higher education.
Over nearly four years of my PhD journey, it has been a short time, short enough that I clearly remember my first day in Australia. Looking back at the joys and difficulties of this period of time, I have been lucky to work with my supervisors, research colleagues, friends and family.
I would sincerely like to thank my principal supervisor, Associate Professor Wei Xiang, who always provided me with challenging, instructive ideas and useful suggestions, and highly positive learning experiences throughout my PhD stud-ies. I feel myself fortunate to have him as my supervisor. Without his motivation and guidance, I could not finish my thesis so smoothly. I also would like to thank Associate Professor John Leis, my associate supervisor, for the many useful dis-cussions and the constructive feedback I received regarding my work. He is an indispensable source of knowledge for all his students.
Finally, but most importantly, I wish to convey special thanks to my parents, without their prayers and support I would not have been able to reach this far with my studies. I am especially indebted to my wife and my little daughters Ala, Asel, and Rahaf, who had to bear with me for the many times I had to work late into the night. I also wish to express my gratitude to my brothers and sisters for their encouragement and overall support.
Khalid Mohamed Alajel
University of Southern Queensland
During the course of this thesis, a number of journal and conference papers were published. These publications presented some of the major results discovered dur-ing the course of this thesis. The published papers are listed as follows:
A- Publications related to the contributions of the thesis
Fully refereed journal publications
Chapter 4
[1] Khalid Mohamed Alajel, Wei Xiang, and Yafeng Wang, “Unequal Error Pro-tection Scheme Based Hierarchical 16-QAM for 3-D Video Transmission,” IEEE Transactions on Consumer Electronics, Vol. 58, no. 3, pp. 731-738, Aug. 2012.
Chapter 5
[2] Khalid Mohamed Alajel, Wei Xiang, and Ibrahim Salih, “Unequal Error Pro-tection for Robust 3-D Video Transmission Through Best Relays Selection,” Jour-nal of AnJour-nals of Telecommunications, (under review).
Fully refereed book chapters
Chapters 2 and 4
[3] Khalid Mohamed Alajel and Wei Xiang, “A new hierarchical 16-QAM based UEP scheme for 3-D video with depth imagebased rendering,” inAdvanced Video Communications over Wireless Networks, 1st ed. C. Zhu and Y. Li, Eds. Bosa
Fully refereed conference publications
Chapter 3
[4] Khalid Mohamed Alajel, Wei Xiang, and John Leis, “Performance analy-sis of error resilient wireless image transmission using H.264/AVC I-Frame,” in
Proc. Southern Region Engineering Conference (SREC’10), Toowoomba, Aus-tralia, Nov. 2010, pp.78-80.
[5] Khalid Mohamed Alajel, Wei Xiang, and John Leis, “Error resilience perfor-mance evaluation of H.264 I-frame and JPWL for wireless image transmission,” in Proc. 4th International Conference on Signal Processing and Communication Systems (ICSPCS’10), Gold Coast, Australia, Dec. 2010, pp. 1-7.
Chapter 4
[6] Khalid Mohamed Alajel and Wei Xiang, “Color Plus Depth 3-D Video Trans-mission with Hierarchical 16-QAM,” in Proc. 3DTV-Conference 2012, The True Vision: Capture, Transmission and Display of 3D Video, Zurich, Switzerland, Oct. 2012, pp. 1-4.
Chapter 5
[7] Khalid Mohamed Alajel, Wei Xiang, and Ibrahim Salih, “Best Relays Se-lection Method for Error-Resilient 3-D Video Transmission,” in Proc. IEEE 12th International Symposium on Communications and Information Technolo-gies (ISCIT’12), Gold Coast, Queensland, Australia, Oct. 2012, pp. 1-5.
Chapter 6
[8] Ibrahim Salih, Khalid Mohamed Alajel, and Wei Xiang, “Cooperative relay selection based UEP scheme for 3-D video transmission over Rayleigh fading channel,” in Proc. IEEE International Conference on Digital Image Computing: Techniques and Applications (DICTA’11), Noosa, Queensland, Australia, Dec. 2011, pp. 689-693.
B- Other fully refereed conference publications
on skin color modeling and modified Hausdorff distance,” in Proc. 2011 IEEE Consumer Communications and Networking Conference (CCNC’11), Las Vegas, USA, June. 2011, pp. 78-80.
Abstract i
Acknowledgments vii
List of Publications ix
List of Figures xix
List of Tables xxiv
List of Acronyms xxv
Chapter 1 Introduction 1
1.1 Background . . . 1
1.2 Research Motivation . . . 2
1.3 Scope of the Thesis . . . 5
1.4 Research Objectives . . . 5
1.5 Contributions of the Thesis . . . 6
Chapter 2 Background 10
2.1 Introduction . . . 10
2.2 Two-Dimensional (2-D) Video . . . 11
2.2.1 2-D Image and Video Coding . . . 11
2.2.2 Video Quality Assessment . . . 13
2.3 Three-Dimensional (3-D) Video . . . 14
2.3.1 Human 3-D Visual System . . . 15
2.3.2 3-D Video Communication System . . . 15
2.3.3 3-D Video Formats and Coding . . . 17
2.3.4 3-D Video Coding Standards . . . 27
2.4 Recent Efforts In 3-D Video Transmission . . . 30
2.4.1 3DTV . . . 31
2.4.2 MOBILE.3DTV . . . 31
2.4.3 3DPHONE . . . 32
2.4.4 3D4YOU . . . 32
2.4.5 DIOMEDES . . . 32
2.5 Error Control Techniques for 3-D Video Transportation . . . 33
2.5.1 Standardized Error Resilience Techniques . . . 33
2.5.2 Hierarchical Modulation (HQAM) . . . 35
2.5.3 Unequal Error Protection (UEP) . . . 37
2.6 Conclusions . . . 43
Chapter 3 Error Resilience Performance Evaluation of H.264/AVC and JPWL for Wireless Image Transmission 44 3.1 Introduction . . . 44
3.2 Motivation and Related Work . . . 45
3.3 2-D Image and Video Coding Standards . . . 48
3.3.1 Wireless JPEG 2000 (JPWL) . . . 49
3.3.2 H.264/AVC Video Coding Standard . . . 51
3.4 Review of Error Resilience Tools in JPWL and H.264 . . . 52
3.4.1 Error Resilience Tools in JPWL . . . 52
3.4.2 Error Resilience Tools in H.264/AVC . . . 54
3.5 System Configuration . . . 56
3.6 Experimental Results . . . 58
3.6.1 Parameter Settings . . . 58
3.6.2 Results and Discussions . . . 59
3.7 Conclusions . . . 69
Chapter 4 A New Hierarchical 16-QAM Based UEP Scheme for 3-D Video with Depth Image Based Rendering 70 4.1 Introduction . . . 70
4.2 Related Work . . . 72
4.3.1 Hierarchical Quadrature Amplitude Modulation
(HQAM) . . . 74
4.3.2 Depth Image Based Rendering (DIBR) in 3-D Video . . . 77
4.4 UEP Scheme for 3-D Video Transmission . . . 81
4.4.1 Problem Formulation . . . 81
4.4.2 System Model . . . 81
4.4.3 BER Performance of 16-QAM . . . 83
4.5 Simulation Results and Discussions . . . 86
4.5.1 Experimental Setup . . . 86
4.5.2 Discussion of Results . . . 86
4.5.3 Visual Examples for The Proposed Method . . . 93
4.6 Conclusions . . . 98
Chapter 5 Unequal Error Protection for Robust 3-D Video Trans-mission Through Best Relays Selection 99 5.1 Introduction . . . 99
5.2 Related Work . . . 100
5.3 System Model . . . 103
5.4 End-To-End Performance Analysis . . . 107
5.4.1 First Best Relay (Color) . . . 107
5.4.2 Second Best Relay (Depth) . . . 109
5.5.1 Outage Probability . . . 110
5.5.2 Average Bit Error Probability . . . 111
5.6 Simulation Results . . . 112
5.7 Conclusions . . . 122
Chapter 6 Combined Hierarchical QAM and Hybrid Relay Selec-tion for Error Resilience 3-D Video Transmission 123 6.1 Introduction . . . 123
6.2 Related Work . . . 125
6.3 System Model . . . 127
6.4 Hybrid Relay Selection Protocol (HRSP) . . . 131
6.4.1 AF group . . . 131
6.4.2 DF group . . . 131
6.4.3 HRSP . . . 132
6.5 Performance Analysis . . . 134
6.5.1 BER Performance . . . 134
6.5.2 Outage Probability Performance . . . 137
6.6 Simulation Results and Discussion . . . 138
6.6.1 UEP Using 16-HQAM . . . 139
6.6.2 UEP Using HRSP . . . 141
6.6.3 UEP Combining HQAM and HRSP . . . 144
Chapter 7 Conclusions and Future Work 148
7.1 Introduction . . . 148
7.2 Conclusions . . . 149
7.3 Future Work . . . 151
7.3.1 Video-Plus-Depth Frame Concealment for 3-D Video Trans-mission . . . 151
7.3.2 Scalable Multiple Description Video Coding for Multiview Video over Incremental Relay Networks . . . 151
7.3.3 Rate-Distortion Optimization for Video-Plus-Depth
Streaming over Cooperative Networks with UEP . . . 152
7.4 Final Remarks . . . 152
1.1 Block diagram of coverage and dissertation outline. . . 8
2.1 2-D video transmission system. . . 11
2.2 Spatial and temporal correlation of video sequence. . . 12
2.3 3-D video communication system architecture. . . 16
2.4 CSV formats. . . 18
2.5 Combined temporal and interview prediction for stereo coding. . . 19
2.6 Right view downsampling for MRS. . . 19
2.7 V+D format. . . 20
2.8 Block diagram of MPEG-C part 3 coding for video-plus-depth rep-resentation. . . 22
2.9 H.264/AVC coding for video-plus-depth representation. . . 22
2.10 H.264/MVC coding for video-plus-depth format. . . 23
2.11 Multiview coding structure with temporal/interview prediction. . 24
2.13 Layered depth video. . . 27
2.14 Simulcast coding structure with B pictures for temporal prediction. 29 2.15 Typical MVC prediction structure. . . 29
2.16 An example of a cooperative communication system. . . 39
3.1 JPWL system description. . . 50
3.2 Data partition in H.264/AVC. . . 55
3.3 Image transmission over wireless system. . . 57
3.4 Rate distortion curve for Boat image. . . 60
3.5 Rate distortion curve for Lena image. . . 60
3.6 Subjective results of Lena image comparing H.264/AVC Intra cod-ing and JPWL at 22 kbits per image. . . 61
3.7 PSNR vs. SNR for Lena image when DP is enabled and disabled. 64 3.8 PSNR vs. SNR for Lena image when FMO is enabled and disabled. 65 3.9 PSNR vs. SNR for Lena image with different slice mode. . . 65
3.10 Subjective results of Lena image using: No protection, CRC-32, Rs (37,32), and Rs (64,32) at SNR = 21 dB. . . 67
3.11 Subjective results of Boat image using: No protection, DP, FMO, and PS at SNR = 21 dB. . . 68
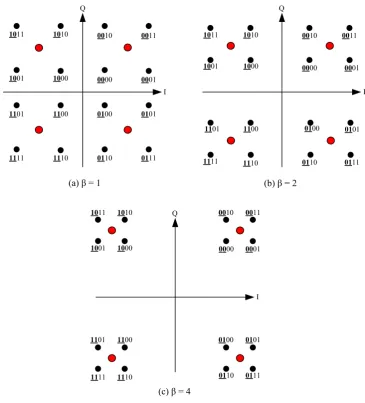
4.1 Hierarchical 16-QAM constellation diagram. . . 76
4.3 Color-plus-depth representation in DIBR forInterview test sequence. 79
4.4 Virtual view generation in DIBR process. . . 80
4.5 Average PSNR of video sequence. . . 80
4.6 System model of the proposed UEP scheme. . . 82
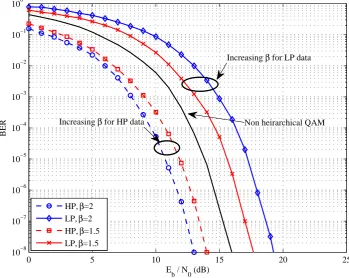
4.7 BER performance of hierarchical 16-QAM over AWGN channel with different values ofβ. . . 85
4.8 PSNR performance of the reconstructed 3-D video forOrbi sequence. 89
4.9 PSNR performance of the reconstructed 3-D video for Interview
sequence. . . 90
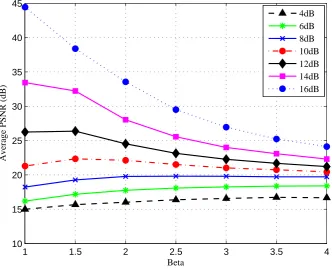
4.10 Average PSNR of a range of β values for Orbi sequence. . . 92
4.11 Average PSNR of a range of β values for Interview sequence. . . . 92
4.12 Original frames of Interview sequence. . . 94
4.13 Reconstructed frames at SNR =12 dB and EEP for Interview se-quence. . . 95
4.14 Reconstructed frames at SNR =12 dB and β = 1.5 for Interview
sequence. . . 96
4.15 Reconstructed frames at SNR =12 dB and β = 2 for Interview
sequence. . . 97
5.1 System model. . . 104
5.3 Outage probability versus the SNR (dB) with DT, M = 2, and
M = 6. . . 114
5.4 Outage probability versus the SNR (dB) with respect to different values of channel gains. . . 115
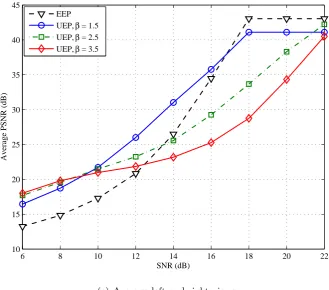
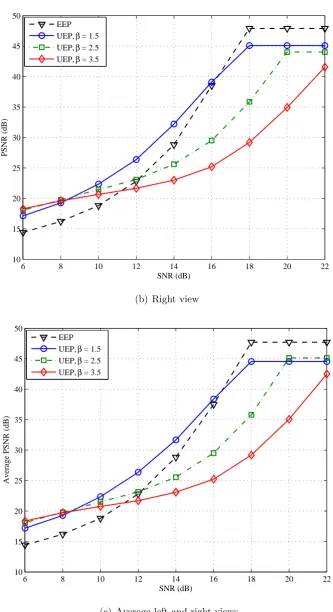
5.5 Average left and right PSNR performance of reconstructed 3-D video of Orbi sequence when N = 1, 2. . . 117
5.6 Average left and right PSNR performance of reconstructed 3-D video of Interview sequence when N = 1, 2. . . 118
5.7 Original frames ofOrbi sequence. . . 119
5.8 Reconstructed frames with UEP at SNR = 13 dB, M = 2, when first best relay is used to transmit the color sequence. . . 120
5.9 Reconstructed frames with UEP at SNR = 13 dB, M = 2, when first best relay is used to transmit the depth sequence. . . 121
6.1 The proposed system model. . . 128
6.2 Time slot organization. . . 129
6.3 Flowchart of the proposed HRSP. . . 133
6.4 PSNR of Orbi sequence for different SNR using 16-HQAM. . . 140
6.5 PSNR of Interview sequence for different SNR using 16-HQAM. . 141
6.6 BER performance of HRSP with different numbers of relays. . . . 142
6.8 UEP performance of 16-HQAM at different regions of SNR ofOrbi
sequence. . . 144
6.9 Comparisons of the proposed combined UEP scheme with 16-HQAM and HRSP forOrbi sequence. . . 146
3.1 H.264/AVC codec parameters . . . 59
3.2 Comparison of average PSNR for Lena image using no protection and CRC-16, CRC-32 codes in JPWL . . . 62
3.3 Output bitrate values at H.264/AVC encoder for Lena image . . . 63
3.4 Comparison of average PSNR for Lena image using no protection, DP, FMO, and PS in H.264 . . . 63
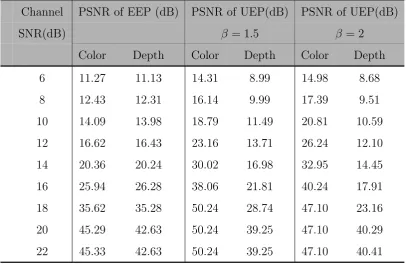
4.1 Average PSNR with and without UEP for Orbi sequence. . . 87
5.1 Simulated system with different configurations. . . 116
2-D Two-dimensional
3-D Three-dimensional
3DTV Three dimensional television
3DTV-CON Three dimensional television-conference
3G Third generation
4G Fourth generation
AF Amplify-and-forward
AVC Advanced video coding
AWGN Additive white Gaussian noise
B Bidirectional
BEP Bit error probability
BER Bit error rate
BMP Bitmap
BPSK Binary phase shift keying
CABAC Context-adaptive binary arithmetic coding
CAVLC Context-adaptive variable-length coding
CDF Cumulative density function
CIF Common intermediate format
CRC Cyclic redundancy check
CSI Channel state information
CSV Conventional stereo video
DCP Disparity compensation prediction
DCPM Differential plus code modulation
DF Decode-and-forward
DIBR Depth image-based rendering
DP Data partitioning
DSPLap Digital signal processing lab
DT Direct transmission
DTV Digital television
DVB-H Digital video broadcasting Handheld
DVB-T Digital video broadcasting-terrestrial
DWT Discrete wavelet transform
EBCOT Embedded bitplane coding with optimal truncation
EEP Equal error protection
EPB Error protection block
EPC Error protection capability
ESD Error sensitivity descriptor
EZW Embedded zerotree wavelet
FEC Forward error correction
FMO Flexible macroblock ordering
FVV Free viewpoint video
GOP Group of pictures
GSM Global system for mobile communications
HDTV High definition television
HEVC High efficiency video coding
HM Hierarchical modulation
HP High priority
HQAM Hierarchical quadrature amplitude modulation
HRSP Hybrid relay selection protocol
HVS Human visual system
IDR Instantaneous decoder refresh
IEEE Institute of electrical and electronics engineers
I-frame Intra-frame
I.I.D Independent and identically distributed
ISO International organization for standardization
ITU-T International telecommunication union-telecommunication
JMVC Joint multiview video coding
JPWL Wireless JPEG2000
JSCC Joint source channel coding
JVT Joint video team
LDPC Low density parity check
LDV Layered depth video
LP Low priority
LSBs Less significant bits
MBAmap Macroblock allocation map
MBs Macroblocks
MCP Motion compensation prediction
MDC Multiple description coding
MGF Moment generation function
MDC Multiple description coding
MIMO Multiple-input-multiple-output
MP Main-profile
MPEG Moving picture expert group
MRC Maximum ratio combining
MRS Mixed resolution stereoscopic
MSBs Most significant bits
MSE Mean squared error
MVC Multiview coding
MVD Multiview video-plus-depth
MVE Motion vector extrapolation
MVV Multiview video
NAL Network abstraction layer
NALU Network abstraction layer unit
OFDM Orthogonal frequency division multiplexing
P Predictive
PDF Probability density function
PS Picture segmentation
PSK phase-shift keying
PSNR peak signal-to-noise ratio
QAM Quadrature amplitude modulation
QoE Quality of experience
QoS Quality of services
QP Quantization parameters
QPSK Quadrature phase shift keying
RCPC Rate compatible punctured codes
R-D Rate-distortion
RED Residual error descriptor
R-S Reed-Solomon
RS Redundant slice
SEI Supplement enhancement information
SEP Symbol error probability
SER Symbol error rate
SG Slice groups
SNR Signal-to-noise-ratio
SPIHT Set partitioning in hierarchical trees
STC Space-time code
SVC Scalable video coding
TC Turbo code
TV Television
UEP Unequal error protection
VCEG Video coding expert group
VCL Video coding layer
VLC Variable-length code
V+D Video-plus-depth
YUV A color space
Introduction
1.1
Background
With the rapid growth of multimedia communication systems, such as Inter-net and wireless Inter-networks, many applications that deliver multimedia content have affected the every-day life of people. Some of these applications include: video conferencing, video telephone, video on demand, and video over mobile net-works. Delivery of multimedia content over wireless channels is becoming more popular. More than four billion people depend on cellular communication for their day to day activities. The quality of service (QoS) required to guarantee multimedia content transmission is a key factor influencing the success of future generation wireless communication systems. However, the effects of transmission errors on the reconstructed bitstream pose a major problem in being able to guar-antee the QoS. Because of this, techniques for more reliable transmission systems are still an active research topic.
through a communication channel using all of its available bandwidth. To achieve this objective. The source coding should compress the original video sequence as much as possible and the compressed video data should be robust and resilient to channel errors. However, while achieving a high coding efficiency, compression also makes the coded video bitstream vulnerable to transmission errors. Thus, the process of video data compression tends to work against the objectives of robustness and resilience to errors. Therefore, error control techniques are essen-tial to provide a satisfactory QoS for video communication systems.
1.2
Research Motivation
An ideal communication system should adaptively change its information depend-ing on the available channel capacity because the signal-to-noise-ratio (SNR) can be highly variable in wireless channels. A feedback channel can be used to provide knowledge of channel conditions to the transmitter. Unfortunately, this feedback channel may not be available in many applications such as broadcasting and wireless channels.
In wireless video communication, the two major obstacles when transmitting mul-timedia services are bandwidth limitations and high probability of error. The first problem has been addressed in the last two decades by several proposed video coding standards. In particular, the state-of-the-art video compression standard H.264/ACV (advance video coding) [1] provides both better compression and bet-ter quality. However, H.264/AVC adopts variable-length-codes (VLCs) as entropy codes to achieve a high coding efficiency. The nature of VLC is the root cause of error propagation because it is very sensitive to channel errors. Even a single bit error can render the entire bitstream undecodable in the worst case. Thus, highly efficient source compression algorithms exacerbate the bit-error-rate (BER) prob-lem.
grown rapidly within the last few years. 3-D video may be captured in different ways such as stereoscopic dual-camera and multi-view settings. Since 3-D video formats consist of at least two video sequences and possibly additional depth data, many different coding techniques have been proposed [2, 3]. In many cases, compressed 3-D video data, such as video-plus-depth or multi-view video need to be transmitted over error-prone channels. This raises the problem of protection against errors. However, transmitting 3-D video over error-prone channels poses more challenges than the conventional two-dimensional (2-D) video because ex-isting 2-D video transmission algorithms cannot be applied straightforwardly to 3-D video data.
To address the error resilience problem, this observation has led to the suggestion of methods to minimize the effect of transmission errors on the reconstructed 3-D video quality when transmitted over wireless channels; this motivates the research work of this thesis. The loss of synchronization between the decoder and encoder, caused by error-prone channels, could be solved by using retransmission. Error free transmission could be achieved by retransmitting packets that have been lost or corrupted. However, the problem with such a scheme is that it causes increased delays which may not be acceptable in some applications.
An alternative approach is to use effective data protection to create compressed bitstream signals error resilience to transmission errors. Several standard source coding approaches are available and have been added to the H.264 standard. These techniques are used to provide robust source coding for 2-D video and many of these can also be used for 3-D video. Standardized error resilience techniques may include: slice coding, redundant slice (RS), flexible macroblock ordering (FMO), and data partitioning (DP). Exploiting the correlation that exists in different 3-D video formats could lead to finding more error resilience video encoding schemes for 3-D video transmission.
error protection (UEP). UEP of the coded bitstream signal is one of the most effective techniques for addressing the quality degradation caused by channel er-rors. Normally, a compressed video stream presents different bit error sensitivities to channel errors. Therefore, the reconstructed video quality will be highly de-graded when errors occur on the important components of the coded data. Thus, these important components should have higher protection than the other com-ponents. To provide UEP, one can apply channel coding techniques such as turbo coding (TC) or low density parity check (LDPC) with different levels of protec-tion. However, these introduce more overhead to the encoded data. More specif-ically, the amount of overhead data added to 3-D encoded video will be much higher than for 2-D video. Therefore, alternative concepts for achieving UEP have emerged, such as hierarchical quadrature amplitude modulation (HQAM) where the high priority (HP) data is mapped to the most significant bits (MSBs) of the modulation constellation points; whereas the low priority (LP) data is mapped to the less significant bits (LSBs). However, in 3-D video transmission, UEP still remains a challenging research topic.
The most recent research literature indicates that the performance of video trans-mission over error-prone channels can be improved by the use of diversity tech-niques such as antenna diversity and cooperative diversity. Cooperative diversity has recently been widely discussed in wireless networks as a promising technique to overcome the limitations imposed by multiple-input-multiple-output (MIMO) systems. However, the advantage of cooperative diversity comes at the cost of a reduction in spectral efficiency. To alleviate these drawbacks, the technique of best relay selection can be used to improve transmission performance.
it is useful to exploit a combination of the two methods in order to obtain more efficient video transmission. However, UEP can also be realized by combining hybrid relay selection with HQAM. For example, in video-plus-depth 3-D video format, the best AF could be used for delivering high priorities video data (color video), while DF is used to transmit low priorities video data (depth map).
1.3
Scope of the Thesis
Transmitting 3-D video over unreliable networks poses new challenges. Consumer 3-D video applications will not gain much popularity until the transmission prob-lems of 3-D video are solved. The goal of error control (error resilience) tech-niques for video transmission is to alleviate the effect of errors and improve the reconstructed video quality caused by packet loss or corruption. Error resilience techniques that have been developed in the past have not directly aimed at 3-D video. Thus, by using the unique properties of 3-D video formats better error resilience techniques could be developed. As mentioned earlier, error resilience wireless transmission is a very broad research area with many aspects for investi-gation. It is nearly impossible to cover and review all the approaches that can im-prove the error resilience of wireless video transmission. However, this thesis will focus primarily on four important techniques. These are: error resilience source coding, UEP, HQAM, and cooperative diversity. The video-plus-depth (V+D) 3-D video format will be adopted in this work together with the previously men-tioned error resilience techniques. The H.264/AVC video compression which was standardized in 2003, is the most widely used international video coding standard and will be used throughout this thesis.
1.4
Research Objectives
Objective 1
To investigate and analyze the performance of error control techniques that are employed for source coding in error prone environments through investigating the performance of H.264 I-frame and JPWL error resilience source coding tools for still image transmission.
Objective 2
To propose UEP scheme for color and depth map 3-D video transmission over wireless channels using hierarchical 16-QAM. The proposed system takes into consideration the unequal importance of the color and depth map in 3-D video data.
Objective 3
To develop a new technique for UEP 3-D video transmission by utilizing the specific properties of best relay selection and color-plus-depth video format.
Objective 4
To propose a technique to combine hybrid relay selection and HQAM to minimize the drawback of HQAM at high SNR and benefit from the advantages of both techniques at different SNR regions.
Objective 5
To apply the proposed hybrid relay selection method and HQAM to analyze the effect of losses during transmission of color-plus-depth representation which takes advantage of 3-D video data characteristics.
1.5
Contributions of the Thesis
Contribution 1
An analysis of the error resilience source coding tools of two different image/video coding standards, namely, H.264/AVC and JPWL for still image wireless trans-mission. The performance of H.264/AVC I-Frame and JPWL is compared in an error-prone environment. Objective and subjective simulation results reveal that H.264/AVC is more robust for still image transmission than JPWL. The proposed scheme was published in [4, 5].
Contribution 2
The proposal of UEP scheme based on hierarchical modulation for 3-D video transmission. The aim of this scheme is to reduce the effects of transmission errors in the reconstructed video. The proposed method is based on the unequal importance of the color and depth map of 3-D video data. Performance evaluation shows that the proposed method results in higher quality; and it outperforms the conventional EEP in low to moderate SNRs (very noisy channels) in terms of left and right views quality. For higher SNR, the average PSNR is much lower than EEP. The average PSNR of the proposed scheme is slightly worse than that of EEP at high SNRs. The proposed error resilience method was published in [6–8].
Contribution 3
The proposal of a new UEP-based cooperative error resilience technique for video-plus-depth transmission. First and second best AF relays were proposed for trans-mitting color and depth information, respectively. Closed-form expressions for the bit error probability (BEP) and outage probability of the proposed method were obtained. All the analytical expressions and theoretical analysis were vali-dated through Monte Carlo simulations. These results showed that the simulation results were in a close match with their counterparts, which validates the BEP and outage probability analysis. The proposed best-relay selection error resilience technique was published in [9].
Contribution 4
degradation under low noise conditions. In this contribution, an efficient combi-nation of hybrid relay selection and HQAM was proposed to overcome the HQAM limitation and to enhance error resiliency and reliability of 3-D video transmis-sion at different SNR regions. Simulation results show that, over a wide range of SNRs, a significant improvement in performance is achievable when the pro-posed scheme is used and that it outperforms UEP with HQAM alone. Part of the proposed scheme was published in [10].
1.6
Thesis Outline
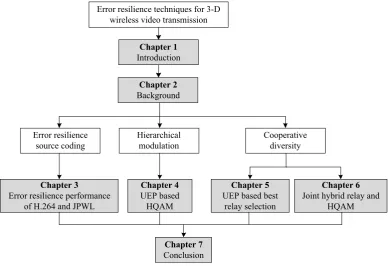
The remainder of this thesis is organised into six chapters, a chapter dedicated to the basic concepts of predictive coding techniques and a review of the existing literature related to the work presented in this thesis. Another four chapters representing specific technical contributions to the thesis. A final chapter focuses on conclusions and future work. Each chapter starts by introducing the related research problem, reviewing relevant work and then the proposed techniques are described. Figure 1.1 shows the overall scope and the coverage of dissertation.
Chapter 1
Introduction
Chapter 2
Background
Error resilience techniques for 3-D wireless video transmission
Error resilience source coding
Hierarchical modulation
Cooperative diversity
Chapter 3
Error resilience performance of H.264 and JPWL
Chapter 4
UEP based HQAM
Chapter 5
UEP based best relay selection
Chapter 6
Joint hybrid relay and HQAM
Chapter 7
[image:35.595.82.474.475.741.2]Conclusion
• Chapter 2: This chapter reviews basic concepts of predictive coding,
3-D video formats and their associated coding techniques, and error control techniques that could be used to improve 3-D video transmission. Previous studies are briefly covered to highlight the relevant challenges that need to be addressed.
• Chapter 3: Standard error resilience techniques of different image/video source coding standards are investigated in this chapter, where the error resilience performance of JPWL and H.264/AVC is evaluated.
• Chapter 4: A new UEP scheme for color and depth map 3-D video
trans-mission over wireless channels using hierarchical 16-QAM is proposed.
• Chapter 5:This chapter proposes to exploit the relay cooperation benefits
to protect the color information more than the depth information. In par-ticular, closed-form expressions for the probability density function (PDF), cumulative density function (CDF), and the moment generation function (MGF) of SNR at the destination are derived. Subsequently, closed-form expressions for the outage probability and the bit BEP are obtained.
• Chapter 6: In this chapter, an efficient combination of relay cooperative
and hierarchical modulation to enhance error resilience and reliability of 3-D video transmission is introduced. The idea is to use hybrid AF-DF relay selection protocol to reduce the quality degradation at low noise condi-tions when HQAM is used. Moreover, the high priority bits are additionally protected using the proposed hybrid relay.
• Chapter 7: This chapter concludes the thesis and summarises the
Background
2.1
Introduction
This chapter provides the necessary background information so as to make this thesis self-contained. The chapter starts with a brief overview of digital video compression principles and the coding standard with an emphasis on the parts that will directly contribute to understanding of the thesis. A brief background on the 3-D human visual system (HVS) will be provided, followed by a comprehensive overview of 3-D video communication system with the main focus on 3-D video representations, coding and transmission. Finally, the focus will be on some error resilience techniques that are applicable to 3-D video transmission.
2.2
Two-Dimensional (2-D) Video
A digital video sequence consists of images, which are known as frames. Each frame consists of small picture elements, pixels that describe the color at that point in the frame. To describe fully the video sequence, a huge amount of data is required. Therefore, the video sequence is compressed to reduce the amount of data to make possible transmission over channels with limited bandwidth. Figure 2.1 describes a 2-D video transmission system, where the encoder is used to compress the input sequence before the transmission over the channel. The reconstructed video sequence at the decoder side contains distortion introduced by the compression and the distortion in the channel respectively.
2.2.1
2-D Image and Video Coding
Video data creates a tremendous amount of data that needs to be transmitted or stored. The huge amount of data is a heavy burden for both transmission and decoding processes. Therefore, video data needs to be compacted into a smaller number of bits for practical storage and transmission. Source coding is the first important part in a communication system chain. The objective of this part is to remove the redundancy in the source as much as possible. Although there are many different categories of source coding techniques, depending on the source information itself, this section will focus on image and video coding techniques widely used in the recent international video standards. These standards are used in the simulations in the subsequent chapters.
There are currently many data compression techniques used for different
pur-Encoder Channel Decoder
poses in video coding. One compression method employs statistical and sub-jective redundancy. Statistical redundancy can be efficiently compressed using lossless compression, so that the reconstructed data after compression are identi-cal to the original video data. However, only a moderate amount of compression is achievable using lossless compression. In subjective redundancy, elements of video sequence can be removed without significantly affecting the visual qual-ity. As a result, much higher compression is achievable at the expense of a loss of visual quality. The compression method employs both statistical and subjec-tive redundancy which form the basis of current video standards. Generally, most of all the recent video techniques used in today’s video encoders are based on exploiting both temporal and spatial redundancy in the original video data (see Figure 2.2). The following paragraph will describe the background of predictive video coding.
In spatial redundancy, there is a high correlation between successive frames of video. The process of removing redundancy within a frame is called intraframe coding. On the other hand, in temporal redundancy, there is a high correlation between pixels (samples) that are close to each other. The process of removing redundancy between frames is called interframe coding. Redundancy reduction is used to predict the value of pixels based on the values previously coded and code the prediction error. This method is called differential pulse code modu-lation (DCPM). Most of video coding standards such as 1 [11] MPEG-2 [1MPEG-2], MPEG-4 [13] by the moving picture experts group (MPEG) of the
inter-Temporal correlation
Spatial correlation
national organization for standardization (ISO), and H.261 [14], H.263 [15], and H.264 [1] by the video coding expert group (VCEG) of international telecommu-nication union-telecommutelecommu-nication (ITU-T), employ a predictive coding system and variable-length code (VLC) techniques which are the root cause of error propagation.
2.2.2
Video Quality Assessment
In order to evaluate and compare video transmission systems, the quality of video is measured at the user end. There are two types of visual quality metrics. One is objective quality metric (using electrical measurement) and the other is a subjective quality metric (using human observers). Subjective quality is usually influenced by illumination, type of display, and the distance between the observer and the displaying device. All of these factors inevitably influence the perceived image and video quality. This has led to a huge amount of research in the field of objective video quality assessment [16]. In the majority of cases, video coding quality is measured using objective quality metrics. An overview of different video quality metrics is given in [17]. The video quality metric used in this work is the peak signal-to-noise ratio (PSNR).
PSNR [18] is the most commonly used objective metric and is computed in decibels and based on the mean squared error (MSE) between an original and a reconstructed video frame. The higher value of the PSNR indicates better video quality. PSNR is calculated as
P SN R= 10 log10
2552
M SE
(dB), (2.1)
where 255 is the maximum value of the pixel data type (8 bits).
Mean squared error (MSE) is the sum of squared error between the original and compressed video and is given by
M SE = 1
N
N X
i=1
where N is the number of pixels within the video signal and xi and yi represent
pixeli in the original and distorted video sequence, respectively. The lower value of MSE means lower error and better quality.
2.3
Three-Dimensional (3-D) Video
A three-dimensional (3-D) video system is able to offer to the user a sense of “being there” and thus provide a more impressive and realistic experience than two-dimensional (2-D) video. Recently, 3-D video has received increased attention due to the recent advances in capturing, coding and display technologies and it is anticipated that the 3-D video applications will increase rapidly in the near future. 3-D video system is able to offer to the user a depth perception of the observed scene. Such 3-D depth perception can be achieved by special 3-D display systems which allow 3-D visual data to be viewed by the user with each eye. There exist a variety of ways to represent 3-D content, such as conventional stereo video, multiview video and video-plus-depth [19]. As a consequence, there are a variety of compression and coding algorithms that are available for the different 3-D video formats [20, 21]. In general, the additional dimension that the 3-D video provides results in tremendous amount of data that needs to be transmitted or stored. Consequently, there is a significant increase in the complexity of the whole 3-D video transmission system.
2.3.1
Human 3-D Visual System
Understanding how the human visual system (HVS) [22] works is crucial to un-derstanding how 3-D imaging works. The HVS consists of two parts, the two eyes and the brain. Each eye has a retina that collects information and transfers it to a region of the brain called lateral geniculate body and then to the visual cortex through the optic nerve. The pictures produced at each of the retinas are one up-side-down and as the pieces of visual information are processed by the visual cortex, one single upright image is produced. As the two human eyes of an individual are separated by about 6-8 cm, the 3-D depth perception is realized by two slightly different images projected to the left and right eye retinas (binocular parallax) and then the brain fuses the two images to give the depth perception.
Although the binocular parallax is the most dominant cue for depth perception, natural scenes contain a wide variety of visual cues known as monocular depth cues to determine depth. Monocular depth cues do not require the observer to have two eyes to perceive depth. Instead the HVS still uses several monocular depth cuses such as motion parallax, relative size, and occlusion.
The two eyes (binocular) are still the most important and widely used depth cues which provide enough information for the HVS. The binocular disparity is available because of the slight differences between the left and right eye points of view [23].
2.3.2
3-D Video Communication System
The 3-D video communication chain consists of the 3-D content creation, 3-D representation, 3-D coding, 3-D transmission, and 3-D display, as depicted in Figure 2.3. All these technologies are broad research areas on their own. Depend-ing on the application scenario and 3-D video formats, various different algorithms and systems are available for each part of the 3-D video communication chain.
Depth estimation
Stereoscopic dual camera
3D depth range camera
2D-to-3D conversion
Multiview video camera
3-D Representation
3-D Coding
Conventional 2-D display
Binocular display
Auto-stereoscopic display 3-D
Transmission
Content generation Display system
Figure 2.3: 3-D video communication system architecture.
natural data sources. In general, there are four types of 3-D content generation that result in different types of data formats [24, 25] as briefly outlined below.
1. The stereoscopic dual camera approach [26], captures 2-D images and results in left and right views. The generated left and right views are pro-jected to the left and right eye of the viewer and the brain fuses the two views and reconstructs the three dimensional image.
2. The 3-D depth range camera approach, uses two cameras to capture 3-D content as two video sequences and generates a 2-D video plus associated depth map [27]. In this approach the left and right eye views must be reconstructed at the viewer side using the technique known as depth image-based rendering (DIBR) [28, 29].
3. The 2-D-to-3-D video conversion approach, converts existing 2-D video into 3-D video by estimating depth information from the original 2-D video, then the DIBR technique can be used to create 3-D video content.
For coding and display purposes, the collected video data needs to be converted from production into the representation (transport) formats for various applica-tions. 3-D formats include conventional stereo video, video-plus-depth, multiview video, multiview plus depth, and layered depth video [19, 30]. Since 3-D video formats consist of at least 2 video sequences and possibly additional depth data, many different coding techniques have been proposed [20, 30]. More details on 3-D video formats and coding can be found in Section 2.3.3.
For 3-D video, among persistent challenges is the problem of 3-D video transmis-sion over wireless networks. Error resilience 3-D video transmistransmis-sion, e.g., error resilience source coding, unequal error protection (UEP), hierarchical quadrature amplitude modulation (HQAM), and diversity technique are effective approaches to relieve the negative impact of 3-D video transmission. Error resilience 3-D video transmission is the scope of this work and these topics will be addressed in the following chapters. 3-D video transmission will be discussed in Section 2.4. Dis-playing 3-D video content is the last component of the 3-D video chain where various types of 3-D displays are adopted.
2.3.3
3-D Video Formats and Coding
2.3.3.1 Conventional stereo video (CSV) format
Conventional stereo video (CSV) is considered the least complex 3-D video format and it is a special case of multiview (2 views only). In CSV, the 3-D video consists of two videos (views) representing the left and right views of the same scene with slight difference in the angle of view corresponding to the distance of separation of the human eyes. Each view forms a normal 2-D video and the human brain can fuse these two different frames to generate the sensation of depth in the scene being viewed. Figure 2.4 illustrates the CSV formats.
Since both cameras capture essentially the same scene, a straight-forward ap-proach is to apply the existing 2-D video coding schemes. Using the 2-D video coding approach, the two separate views can be independently encoded, trans-mitted, and decoded with a 2-D video codec like H.264/AVC. This method is known as simulcast coding. However, since the two views have similar content, and therefore are highly redundant, coding efficiency can be increased by com-bined temporal/interview redundancy. This coding method is called multiview coding (MVC) [36, 37]. To achieve this goal, a corresponding standard has been defined in H.262/MPEG-2 multiview profile [38] as illustrated in Figure 2.5. The left view is encoded independently using MPEG-2 codec and for the right view, interview prediction is allowed in addition to temporal prediction. However, the gain in compression efficiency provided in the two views stereo video coding is
Left view Right view
Left view
Right view P I
B B
B P
B B
B
B B P B
B B
B
Figure 2.5: Combined temporal and interview prediction for stereo coding.
limited compared to individual coding of each view. Some other coding methods are using view interpolation to compensate from camera geometry [39].
In CSV, the amount of data is twice that of 2-D video. Another alternative method for coding CSV data is called mixed resolution stereoscopic (MRS) coding [40]. In this method, the resolution of CSV data is downsampled to one fourth of its original resolution. Thus, a lower bit rate is achieved at equal quality. This makes the approach attractive for mobile devices [40]. MRS coding is illustrated in Figure 2.6. Recently, a so called stereo supplement enhancement information (SEI) message was added to H.264/AVC to encode CSV as described by [41].
Left view Right view
2.3.3.2 Video-plus-depth (V+D) format
One of the most popular formats for representing 3-D video is video-plus-depth (V+D), which consists of a conventional 2-D video with an associated per-pixel depth map represented with luma component only. For video and depth infor-mation, a stereo pair can be synthesized at the decoder. With this technique left and right views are generated at the display side by a method known as DIBR [28,42]. This method will be covered and used in this thesis. The depth map represents the per-pixel distance from the camera and it is between Znear = 255
and the maximum Zf ar = 0, indicating the distance of the corresponding 3-D
point from the camera, where the near objects appear brighter and the far ob-jects appear darker. The V+D format is illustrated in Figure 2.7.
Efficient coding of video-plus-depth format is necessary for mobile video services, due to its bandwidth and processing power limitations, for realizing 3-D video. For coding V+D format, both MPEG-2 and H.264/AVC can be used. If MPEG-2 is used, MPEG-C part 3 defines a video-plus-depth representation which allows en-coding video and depth data as conventional 2-D video [43]. The video and depth sequences are encoded independently, where one view is transmitted simultane-ously with the depth signal. The other view is synthesized by DIBR techniques at the receiver side. In this case, the transmission of a depth map increases the required bandwidth of 2-D video stream by about 20% [44]. If the H.264/AVC
Color video Depth data
is used, the H.264 codec is applied to both sequences simultaneously but inde-pendently, where the video is the primary coded picture and the depth is the auxiliary coded picture. In this case, the required bandwidth increases by only 8% as mentioned by [1, 44]. The following coding standards are applicable to the video-plus-depth format, namely MPEG-C 3, H.264/AVC, H.264/MVC.
MPEG-C part 3
The video-plus-depth format has been standardized within MPEG by a joint effort of Philips and Fraunhofer Heinrich Hertz Institute (HHI). The new stan-dard has been finalized at the MPEG meeting in Marrakech, Morocco (January 2007). According to (ISO/IEC 23002-3), MPEG-C part 3 was presented for stan-dardization of the video-plus-depth coding which allows encoding the depth maps as conventional 2-D video. Due to the very nature of the depth data, higher cod-ing efficiency of depth data could be achieved than the video data which results in small extra needed bandwidth for transmitting the depth data. Thus, the total bandwidth required for video-plus-depth is reduced compared to that of stereo video.
MPEG-C part 3 is combined with H.264/AVC for coding video-plus-depth as il-lustrated in Figure 2.8. H.264/AVC is used to encode the video and depth data sequences independently. The two coded bitstreams are interleaved in the mul-tiplexer frame-by-frame resulting in one stream for transmission. The demul-tiplexer separates the transmitted stream back into two bitstreams which are then decoded independently using the H.264/AVC decoder after transmission over wireless channels.
H.264/AVC
H.264/AVC Encoder
H.264/AVC Encoder
Mux
H.264/AVC Decoder
H.264/AVC Decoder Dmux
Wireless channel
Figure 2.8: Block diagram of MPEG-C part 3 coding for video-plus-depth
repre-sentation.
H.264/AVC Encoder
H.264/AVC Decoder
Wireless channel
Primary pic (video)
auxiliary pic (video)
Primary pic (video)
auxiliary pic (video)
Figure 2.9: H.264/AVC coding for video-plus-depth representation.
sequences are interlaced line-by-line into one sequence, where the top field con-tains the video data and the bottom field the depth data. H.264/AVC coder is applied to both sequences simultaneously but independently where the video is the primary coded picture, and the depth the auxiliary coded picture, resulting in one coded bit-stream. After transmission, this stream is decoded resulting in the distorted video and depth sequences. However, with this approach the backward compatibility is not supported.
H.264/MVC
In multiview video coding, the picture can have temporal and interview predic-tion, respectively. Figure 2.10 shows the MVC coding process for video-plus-depth data. Interview predictive coding is applied through the H.264/AVC encoder for both sequences. Since the H.264/MVC combines temporal and interview predic-tion, thus, the input sequences must be with identical resolution. The advantage of this method is the backward compatibility.
H.264/MVC
Encoder Mux
H.264/MVC Decoder
Wireless channel
Figure 2.10: H.264/MVC coding for video-plus-depth format.
achieved. For instance, the existing correlation between the 2-D video sequence and its corresponding depth map sequence can be exploited to improve the com-pression ratio as proposed by [45, 46]. Alternative approaches based on so-called Platelets were also proposed [47].
The V+D concept is highly interesting due to the backward compatibility and the use of the available video codec. This format is alternative to CSV for mobile 3-D services and is being investigated by Fraunhover Institute for telecommuni-cations. However, the advantages of V+D format come at the cost of increased encoder/decoder complexity [48].
2.3.3.3 Multiview video (MVV) format
tem-View 0
View 1 B I B B B B B B B
B B B B
B B B B P B B B P B B B
B B P B
B B B I B P B
P B B B B B B B P View 2
View 3
View 4
T0 T1 T2 T3 T4 T5 T6 T7 T8 Time
V
ie
w
s
Figure 2.11: Multiview coding structure with temporal/interview prediction.
poral and spatial correlation within one view is exploited. However, multiview video contains a large amount of interview statical dependencies which can be exploited for combined temporal/interview prediction. The multiple correlation makes multiview video coding have a different structure from single view, where the images are predicted temporally from neighbouring images within the same view and also from corresponding images in adjacent views, as illustrated in Figure 2.11. Significant gain can be achieved by combining temporal/interview prediction as proposed by [50, 51].
In July 2008, H.264/MVC standard [52] was specified as an extension to H.264/AVC. H.264/MVC uses the intra prediction for each view to reduce inter-view dependency. At the same time, it applies interinter-view prediction from neigh-bouring views to every 2nd view using previously encoded frames from
hi-erarchical prediction (B) is proposed. This structure outperforms the simulcast coding by 20% of coding efficiency as reported in [56, 57]. According to Merkle et al. [57], H.264/AVC and hierarchical B-frames have been shown to achieve the highest coding efficiency. As H.264/MVC combines temporal and interview prediction, the identical resolution of the input video sequence is required.
Although this approach enhances the coding efficiency of multiview video, its drawback is increased complexity. To address this issue of complexity, one solution is to allow interview prediction only at key frames, which slightly reduces the coding efficiency compared to the one using key frames for all frames. However, as shown by Merkle et al. in [57], in the case of sparsely positioned cameras, interview prediction may not have any impact on coding efficiency while the complexity of the encoder is reduced substantially. For more details of MVC, the reader is referred to [49, 58].
2.3.3.4 Multiview plus depth (MVD) format
Transmitting all views requires a high bit rate where, the number of views in-creases the bit rate linearly. Therefore, MVC is inefficient if the number of views to be transmitted is large. At the same time, V+D format provides a very lim-ited free viewpoint video (FVV) functionality. The solution to the problem of high bit rate when transmitting all views, and the limited FVV, is multiview plus depth (MVD) format. MVD format contains multiple views and associated depth information for each view as illustrated in Figure 2.12.
View 0 View 1 View 2
Figure 2.12: Multiview video-plus-depth.
Platelet-based depth coding as shown in [47].
2.3.3.5 Layered depth video (LDV) format
Although MVD can reduce the required bandwidth to transmit the color and depth data for all views, the overall required bandwidth is still very large. To further reduce the bit rate, LDV is an effective technique. Layered depth video (LDV) [62, 63] is a derivative and alternative to MVD where only one full view with additional residual data is transmitted. One representation of LDV again uses color video with associated depth map (V+D) representation and an addi-tional component called the background layer with its associated depth map, as illustrated in Figure 2.13.
Background layer
Color video Depth data
Background layer depth data
Figure 2.13: Layered depth video.
2.3.4
3-D Video Coding Standards
Coding and compression of 3-D video formats is the next block in the 3-D video processing chain as shown in Figure 2.3. To realize an efficient transmission over bandwidth limited channels, 3-D video representation formats discussed in the previous section, have to be compressed efficiently. The scope of this subsec-tion is to describe related compression standards. In particular, H.264/AVC and H.264/MVC, are briefly reviewed.
upcoming new standard is referred to as the high efficiency video coding (HEVC) or H.265 [65, 66] which is expected to be ready in 2013.
2.3.4.1 H.264/AVC codec
Apart from the deblocking filter, most of H.264 standard functions (prediction, transform, and entropy coding) are presented in prior standards but the most important changes in H.264 appear in the details of each function. The input to the H.264 encoder is video frames in YUV format. H.264/AVC encoder will try to exploit redundancies to reduce the amount of bits necessary to represent it. Then, the decoder will identify the syntax of representation and decode the received bit stream to reconstruct the video at the receiver side. The H.264/AVC standard consists of two layers, known as the video coding layer (VCL) and the network abstraction layer (NAL) as discussed in Section 3.3. The reader is referred to the standard itself [67] and some overview papers that have discussed this matter [49, 68, 69].
2.3.4.2 MVC extension of H.264 standard
The large amount of data required to represent multiview video applications, which requires the development of highly efficient coding schemes, is the major challenge for multiview video transmission. MVC is based on the single-view video compression standard. For the general case of two or more views, the joint video team (JVT) of the ITU-T video coding is developing a multiview extension of the H.264/AVC standard, known as H.264/MVC extension. MVC provides a new technique to improve coding efficiency by exploiting temporal as well as interview statical dependencies between neighboring views. Consequently, MVC takes advantage of the redundancies among the inter-pictures of one view and the interview pictures of other views as illustrated in Figure 2.15.
View 0
View 1 B I B B B B B B B
B B B B
B B
B
I
B
T0 T1 T2 T3 T4 T5 T6 T7 T8 Time
V
ie
w
s
Figure 2.14: Simulcast coding structure with B pictures for temporal prediction.
View 0
View 1 B I B B B B B B B
B B B B
B B
B
P B B P B B P B
I
B
P View 2
T0 T1 T2 T3 T4 T5 T6 T7 T8 Time
V
ie
w
s
Figure 2.15: Typical MVC prediction structure.
video codec including H.264/AVC. In simulcast coding, the prediction process is limited to the reference pictures in the temporal dimension. Figure 2.14 shows the simulcast coding structure with hierarchical bi-directional B pictures for temporal prediction with two views and a group of pictures (GOP) of length of 8. This scheme is simple, but is an inefficient way to compress multiview video sequences because it does not benefit from the existing correlation between the different views.
is coded independently, as in simulcast coding, and for the remaining views, in-terview reference pictures are additionally used for prediction. As a consequence, MVC provides up to 40% bit rate reduction for multiview data in comparison to single view AVC coding. This is at the cost of random access delay. The random access delay is measured based on the number of frames that must be decoded to access a B-frame. The access delay is given by:
Fmax = 3∗levelmax+ 2∗[(N −1)/2] (2.3)
where levelmax is the highest hierarchical order and N is the total number of
views. A more detailed description of the H.264/MVC is given in [49, 58, 70]
As discussed in this section, the 3-D video coding standards are mainly 3-D exten-sions of existing 2-D video coding standards modified to support 3-D application requirements.
2.4
Recent Efforts In 3-D Video Transmission
Immersive media content provides a more natural scene representation compared to conventional 2-D video. Extra information that needs to be transmitted in 3-D video has brought new problems that must be solved. Transmitting 3-3-D video over networks such as the Internet and wireless networks presents a new challenges and consumer applications will not gain more popularity unless the transmission problems of 3-D video are addressed.
address these challenges, it is necessary to propose new error resilience techniques in order to alleviate the influence of errors in 3-D video transmission.
There are two potential architectures for video delivery, namely, the digital tele-vision (DTV) architecture for broadcast, and Internet protocol (IP) architecture for wired and wireless streaming [71]. A summary of existing 3-D media systems delivery could be found in [72]. This subsection describes the current research trends in the area of 3-D video transmission. The most funded research areas that investigate the 3-D video transmission are briefly discussed in the following subsections.
2.4.1
3DTV
Many on-going projects have been the result of the European union (EC)-funded 3DTV project. However, the 3DTV-CON conference was started as an outcome of the completed EC-funded 3DTV project in 2007. The last series was conducted in October 2012. 3DTV-CON is one of the few events that are able to joint be-tween display technologies and content creation, representation, and delivery. The technical focus of this research project was 3-D video communication where an end-to-end platform for 3-D video over IP was developed and maintained. Mul-tiview and video-plus-depth formats are supported by this platform. A survey of 3DTV transport methods is described in [71].
2.4.2
MOBILE.3DTV
were all considered. Error resilience tools to alleviate DVB-H noise were also provided. In January 2011, the Mobile.3DTV project ended.
2.4.3
3DPHONE
The focus of the 3DPHONE project was to develop an end-to-end all 3-D imaging mobile phone. Cellular phone channels such as GSM and 3G were used to deliver 3-D video content, where multiview video delivery was targeted.
2.4.4
3D4YOU
This project focuses on how to establish practical 3-D television. 3-D delivery format and a content creation process are specified. The key technical problems that hamper the practical 3-D television to the mass market are difficulties in capturing 3-D video delivery using the current camera technology. Thus, the objective of 3D4YOU is to handle these technical problems. A camera system that consists of a stereoscopic high definition television (HDTV) camera set, two satellite cameras, and a depth camera was developed and tested.
2.4.5
DIOMEDES
2.5
Error Control Techniques for 3-D Video
Trans-portation
The previous sections focused mainly on 3-D video formats, related techniques and standards to efficiently compress them, and recent efforts in transmission. These compression standards are heavily based on predictive coding and VLC techniques which are the root cause of error propagation. As discussed in Section 2.3, the encoded 3-D video data includes more dependency exploited by interview prediction compared to 2-D video. Therefore, 3-D video stream needs more bandwidth to deliver more views than 2-D video. The existing 2-D video transmission scheme cannot be applied directly to 3-D video formats because temporal motion compensation is quite different from disparity compensation. On the other hand, the evolution of cellular communications into fourth generation (4G) wireless communication systems results in significant improvements of band-width and reliability. Resiliency against transmission errors can be achieved in many ways and it is impossible here to cover and review all approaches that can improve error resilience. Therefore, four promising directions will be covered and investigated in this section: standardized error resilience techniques, hier-archical modulation (HQAM), unequal error protection (UEP), and cooperative communication.
2.5.1
Standardized Error Resilience Techniques
1. Slices - provide spatial resynchronization points within the video data of a single frame. This is achieved by introducing a slice header, which contains syntactical and semantical resynchronization information.
2. Flexible macroblock ordering (FMO) - FMO allows mapping of MBs to slice groups by means of macroblock allocation maps. The main objective of FMO is to avoid error accumulation in a limited region by scattering errors to the whole frame.
3. Redundant pictures - this feature allows the H.264/AVC encoder to send redundant representations of regions of pictures that can be used if the primary representation is lost during data transmission.
4. Data partitioning (DP) - since some of the data representing the video content are more important than others, H.264/AVC allows the syntax of each slice to be separated into a header, motion information, and texture information. This error resilience feature enables the application of UEP.
Bugdayci et al. [75], studied the effect of the slice mode error resilience tool of the H.264/AVC encoder for 3-D video transmission over DVB-H. To study its influence, slice interleaving as standardized in H.264/AVC, is employed as an efficient application layer error resilience tool and integrated to joint multiview video coding (JMVC) reference software version 5.0.5. Both video-plus-depth and stereo representation of 3-D video with and without slicing have been tested.
In [78], the transmission of multiview video encoded streams over packet erasure networks was examined. Macroblocks (MBs) were classified into unequal slice groups by examining their relative significance to the video, so that more im-portant MBs could be transmitted with better protection using the FMO tool of H.264/AVC.
The above error resilience techniques will be discussed in more detail in Chapter 3
2.5.2
Hierarchical Modulation (HQAM)
To deal with different streams of information, hierarchical modulation (HM) (known also as embedded modulation) was designed as an alternative to the con-ventional modulation, such as, quadrature phase shift keying (QPSK), 16-QAM, and 64-QAM, in the digital video broadcasting-terrestrial (DVB-T) standard. In DVB-T, two data streams can be transmitted on a single television (TV) fre-quency channel with different transmission qualities.
Several research on HM has been carried out. Some of the literature has shown that one practical method of achieving UEP is based on HM. The Multiresolution digital HDTV broadcast system using HM, under JSCC framework, is proposed in [79]. DVB-T standard incorporated hierarchical QAM for layered video data transmission is discussed in [80]. Pursley and Shea [81] have also proposed a multi-media communications system based on hierarchical modulation. In this scheme, an adaptive hierarchical phase-shift keying (PSK) was proposed to support si-multaneously delivering differe