International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-9S3, July 2019
Machine Learning & its Classification Techniques
Atul B.Kathole, Prasad S. Halgaonkar, Ashvini A.Nikhade
Abstract:T RecentT developmentsT inT informationT systemsT asT
wellT asT computerizationT ofT businessT processesT byT
organizationsT haveT ledT toT aT faster,T easierT andT moreT accurateT dataT analysisT andT accuracy.T DataT miningT andT machineT learningT techniquesT haveT beenT usedT increasinglyT inT theT analysisT ofT dataT inT variousT fieldsT rangingT fromT
medicineT toT organization,T educationT andT energyT
applications.T MachineT learningT techniquesT makeT itT
possibleT toT deductT meaningfulT furtherT informationT fromT thoseT dataT processedT byT dataT mining.T SuchT meaningfulT
andT significantT informationT helpsT organizationsT toT
establishT theirT futureT policies.T ThisT studyT appliesT classificationT machineT learningT techniquesT alsoT surveyT ofT
activeT learningT regardingT selectionT methods,T queryT
strategies,T applications.
Keyword: Machine Learning, Data Mining,
Classification Techniques.
I. INTRODUCTION:
MachineT LearningT isT anT approachT orT subsetT ofT
ArtificialT IntelligenceT thatT isT basedT onT theT ideaT thatT
machinesT canT beT givenT accessT toT dataT alongT withT theT
abilityT toT learnT fromT it.T ItT learnsT fromT examplesT andT
experience,T withoutT beingT explicitlyT programmed.T
InsteadT ofT writingT code,T youT feedT dataT toT theT genericT
algorithm,T andT itT buildsT logicT basedT onT theT dataT
given.T InT aT veryT laymanT manner,T MachineT LearningT
(ML)T canT beT explainedT asT automatingT andT improvingT
theT learningT processT ofT computersT basedT onT theirT
experiencesT withoutT beingT actuallyT programmedT i.e.T
withoutT anyT humanT assistance.T TheT processT startsT withT
feedingT goodT qualityT dataT andT thenT trainingT ourT
machinesT (computers)T byT buildingT machineT learningT
modelsT usingT theT dataT andT differentT algorithms.T TheT
choiceT ofT algorithmsT dependsT onT whatT typeT ofT dataT
doT weT haveT andT whatT kindT ofT taskT weT areT tryingT toT
automate.
Revised Manuscript Received on July 25, 2019.
Atul B.Kathole, Faculty,Department of Computer
Engineering, Zeal College of Engineering and Research, Narhe, Pune, India.
Dr.Prasad S. Halgaonkar, Faculty, Department of
Computer Engineering, Zeal College of Engineering and Research, Narhe, Pune, India.
Ashvini A.Nikhade, Faculty, Department of Computer
Engineering, Zeal College of Engineering and Research, Narhe, Pune, India.
[email protected],prasad.halgaonkar@zealeducat ion.com, [email protected]
Data Science and Machine Learning
DataT ScienceT andT MachineT LearningT goT handT
inT hand.T DataT ScienceT helpsT evaluateT dataT forT
MachineT LearningT algorithms
DataT scienceT isT theT useT ofT statisticalT methodsT
toT findT patternsT inT theT data.
StatisticalT machineT learningT usesT theT sameT
mathT andT techniquesT asT dataT science.
TheseT techniquesT areT integratedT intoT
algorithmsT thatT learnT andT improveT onT theirT
own.
MachineT LearningT facilitatesT ArtificialT
IntelligenceT asT itT enablesT machinesT toT learnT
fromT theT patternsT inT data.
DifferenceT betweenT TraditionalT ProgrammingT &T
MachineT LearningT
TraditionalT Programming:T WeT feedT inT
DATAT (Input)T +T PROGRAMT (logic),T runT itT onT
machineT andT getT output.
MachineT LearningT :T WeT feedT inT
DATA(Input)T +T Output,T runT itT onT machineT
duringT trainingT andT theT machineT createsT itsT ownT
program(logic),T whichT canT beT evaluatedT whileT
testing.
Figure 01:Difference between Traditional Programming & Machine Learning
What does exactly learning means for a computer? AT computerT isT saidT toT beT learningT fromT ExperiencesT
withT respectT toT someT classT ofT Tasks,T ifT itsT
performanceT inT aT givenT TaskT improvesT withT theT
Experience.T AT computerT programT isT saidT toT learnT
fromT experienceT ET withT respectT toT someT classT ofT
tasksT TT andT performanceT measureT P,T ifT itsT
improvesT withT experienceT E Need of Machine Learning
MachineT LearningT isT aT fieldT whichT isT raisedT
outT ofT ArtificialT IntelligenceT (AI).T ApplyingT AI,T weT
wantedT toT buildT betterT andT intelligentT machines.T ButT
exceptT forT fewT mereT tasksT suchT asT findingT theT
shortestT pathT betweenT pointT AT andT B,T weT wereT unableT
toT programT moreT complexT andT constantlyT evolvingT
challenges.
ThereT wasT aT realizationT thatT theT onlyT wayT toT
beT ableT toT achieveT thisT taskT wasT toT letT machineT learnT
fromT itself.T ThisT soundsT similarT toT aT childT learningT
fromT itsT self.T SoT machineT learningT wasT developedT asT
aT newT capabilityT forT computers.T AndT nowT machineT
learningT isT presentT inT soT manyT segmentsT ofT
technology,T thatT weT don’tT evenT realizeT itT whileT usingT
it.T FindingT patternsT inT dataT onT planetT earthT isT possibleT
onlyT forT humanT brains.T TheT dataT beingT veryT massive,T
theT timeT takenT toT computeT isT increased,T andT thisT isT
whereT MachineT LearningT comesT intoT action,T toT helpT
peopleT withT largeT dataT inT minimumT time.T IfT bigT dataT
andT cloudT computingT areT gainingT importanceT forT theirT
contributions,T machineT learningT asT technologyT helpsT
analyzeT thoseT bigT chunksT ofT data,T easingT theT taskT ofT
dataT scientistsT inT anT automatedT processT andT gainingT
equalT importanceT andT recognition.T TheT techniquesT weT
useT forT dataT miningT haveT beenT aroundT forT manyT
years,T butT theyT wereT notT effectiveT asT theyT didT notT
haveT theT competitiveT powerT toT runT theT algorithms.T IfT
youT runT deepT learningT withT accessT toT betterT data,T theT
outputT weT getT willT leadT toT dramaticT breakthroughsT
whichT isT machineT learning.
II. TECHNIQUES OF MACHINE LEARNING The Machine Learning has three main Techniques those are as follow,
Supervised learning Unsupervised learning
Semi-supervised and Reinforcement learning
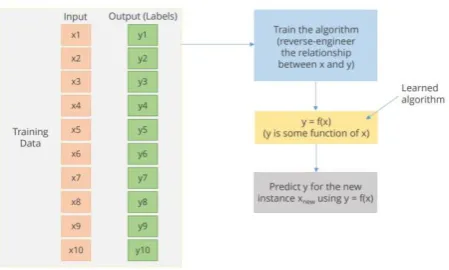
i) Supervised Learning:
SupervisedT LearningT isT aT typeT ofT MachineT LearningT
usedT toT learnT modelsT fromT labeledT trainingT data.T ItT
allowsT usT toT predictT theT outputT forT futureT orT unseenT
data.
[image:2.595.318.543.62.197.2]
Figure 02 : Algorithm of Supervised Learning
SupervisedT LearningT Flow
DataT Preparation TrainingT Step
EvaluationT orT TestT Step ProductionT Deployment
TestingT theT Algorithm
GivenT belowT areT theT stepsT forT testingT theT algorithmT ofT
SupervisedT Learning.
1. OnceT theT algorithmT isT trained,T testT itT withT
testT dataT (aT setT ofT dataT instancesT thatT doT notT
appearT inT theT trainingT set).
2. AT well-trainedT algorithmT canT predictT wellT forT
newT testT data.
3. IfT theT learningT isT poor,T weT haveT anT underfitT
situation.T TheT algorithmT willT notT workT wellT
onT testT data.T RetrainingT mayT beT neededT toT
findT aT betterT fit.
4. IfT learningT onT trainingT dataT isT tooT intensive,T
itT mayT leadT toT overfittingT –T aT situationT whereT
theT algorithmT isT notT ableT toT handleT newT
testingT dataT thatT itT hasT notT seenT before.T TheT
techniqueT toT keepT dataT genericT isT calledT
regularization.
TypesT ofT SupervisedT Learning
GivenT belowT areT 2T typesT ofT SupervisedT Learning.
Classification Regression
ClassificationT SupervisedT Learning
LetT usT lookT atT theT classificationsT ofT SupervisedT
learning.
AnswersT “WhatT class?”
AppliedT whenT theT outputT hasT finiteT andT
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-9S3, July 2019
RegressionT SupervisedT Learning
GivenT belowT areT someT elementsT ofT RegressionT
SupervisedT learning.
AnswersT “HowT much?”
AppliedT whenT theT outputT isT aT continuousT
number
AT simpleT regressionT algorithm:T yT =T wxT +T b.T
Example:T theT relationshipT betweenT
environmentalT temperatureT (y)T andT humidityT
levelsT (x)
ii) UnsupervisedT Learning:
UnsupervisedT learningT isT aT termT usedT forT
HebbianT learning,T associatedT toT learningT withoutT aT
teacher,T alsoT knownT asT self-organizationandT aT methodT
ofT modellingT theT probabilityT densityT ofT inputs.
TheT unsupervisedT learningT toT createT clustersT
ofT heavenlyT bodies,T withT eachT clusterT containingT
objectsT ofT aT similarT nature.T UnsupervisedT LearningT isT
aT subsetT ofT MachineT LearningT usedT toT extractT
inferencesT fromT datasetsT thatT consistT ofT inputT dataT
withoutT labeledT responses.
ComparedT toT supervisedT learningT whereT
trainingT dataT isT labeledT withT theT appropriateT
classifications,T modelsT usingT unsupervisedT learningT
mustT learnT relationshipsT betweenT elementsT inT aT dataT
setT andT classifyT theT rawT dataT withoutT "help."T ThisT
huntT forT relationshipsT canT takeT manyT differentT
algorithmicT forms,T butT allT modelsT haveT theT sameT goalT
ofT mimickingT humanT logicT byT searchingT forT indirectT
hiddenT structures,T patternsT orT featuresT toT analyzeT newT
data.
TypesT ofT UnsupervisedT Learning
ThereT areT threeT typesT ofT UnsupervisedT LearningT are:
Clustering
VisualizationT Algorithms
AnomalyT Detection
Clustering
TheT mostT commonT unsupervisedT learningT
methodT isT clusterT analysis.T ItT isT usedT toT findT
dataT clustersT soT thatT eachT clusterT hasT theT
mostT closelyT matchedT data.
VisualizationT Algorithms
VisualizationT algorithmsT areT unsupervisedT
learningT algorithmsT thatT acceptT unlabeledT dataT
andT displayT thisT dataT inT anT intuitiveT 2DT orT
3DT format.T TheT dataT isT separatedT intoT
somewhatT clearT clustersT toT aidT understanding.T
AnomalyT Detection
ThisT algorithmT detectsT anomaliesT inT dataT
withoutT anyT priorT training.T ItT canT detectT
suspiciousT creditT cardT transactionsT andT
differentiateT aT criminalT fromT aT setT ofT people.
iii) Semi-SupervisedT Learning
ItT isT aT hybridT approachT (combinationT ofT
SupervisedT andT UnsupervisedT Learning)T withT someT
labeledT andT someT non-labeledT data.
Semi-supervisedT learningT isT aT classT ofT
machineT learningT tasksT andT techniquesT thatT alsoT makeT
useT ofT unlabeledT dataT forT trainingT –T typicallyT aT smallT
amountT ofT labeledT dataT withT aT largeT amountT ofT
unlabeledT data.T Semi-supervisedT learningT fallsT betweenT
unsupervisedT learningT (withoutT anyT labeledT trainingT
data)T andT supervisedT learningT (withT completelyT
labeledT trainingT data).T ManyT machine-learningT
researchersT haveT foundT thatT unlabeledT data,T whenT
usedT inT conjunctionT withT aT smallT amountT ofT labeledT
data,T canT produceT considerableT improvementT inT
learningT accuracyT overT unsupervisedT learningT (whereT
noT dataT isT labeled),T butT withoutT theT timeT andT costsT
neededT forT supervisedT learningT (whereT allT dataT isT
labeled).TheT acquisitionT ofT labeledT dataT forT aT learningT
problemT oftenT requiresT aT skilledT humanT agentT (e.g.T toT
transcribeT anT audioT segment)T orT aT physicalT experimentT
(e.g.T determiningT theT 3DT structureT ofT aT proteinT orT
determiningT whetherT thereT isT oilT atT aT particularT
location).T TheT costT associatedT withT theT labelingT
processT thusT mayT renderT aT fullyT labeledT trainingT setT
infeasible,T whereasT acquisitionT ofT unlabeledT dataT isT
relativelyT inexpensive.T InT suchT situations,T
semi-supervisedT learningT canT beT ofT greatT practicalT value.T
Semi-supervisedT learningT isT alsoT ofT theoreticalT interestT
inT machineT learningT andT asT aT modelT forT humanT
learning.
III.T DATAT PREPROCESSINGT INT
MACHINET LEARNING
Here,T weT willT DiscussT DataT Preprocessing,T FeatureT
Scaling,T andT FeatureT EngineeringT inT detailT
Objectives
RecognizeT theT importanceT ofT dataT preparationT
inT MachineT Learning
IdentifyT theT meaningT andT aspectsT ofT featureT
engineering
StandardizeT dataT featuresT withT featureT scaling AnalyzeT datasetsT andT itsT examples
ExplainT dimensionalityT reductionT withT
PrincipalT ComponentT AnalysisT (PCA)
DataT PreparationT inT
AT quickT briefT ofT DataT PreparationT inT MachineT
LearningT isT mentionedT below.
MachineT LearningT dependsT largelyT onT testT
data.
DataT preparationT isT aT crucialT stepT toT makeT itT
suitableT forT ML.
AT largeT amountT ofT dataT isT generallyT requiredT
forT theT mostT commonT formsT ofT ML.
DataT preparationT involvesT dataT selection,T
filtering,T transformation,T etc.
DataT PreparationT Process
TheT processT ofT preparingT dataT forT MachineT LearningT
algorithmTT comprisesTT theTT following:
DataTT Selection DataTT Preprocessing DataT Transformation
DataT Selection
StepsT involvedT inT DataT SelectionT involves:
ThereT isT aT vastT volume,T variety,T andT velocityT
ofT availableT dataT forT aT MachineT LearningT
problem.
ThisT stepT involvesT selectingT onlyT aT subsetT ofT
theT availableT data.
TheT selectedT sampleT mustT beT anT accurateT
representationT ofT theT entireT population. SomeT dataT canT beT derivedT orT simulatedT fromT
theT availableT dataT ifT required.
DataT notT relevantT toT theT problemT atT handT canT
beT excluded.
DataT Preprocessing
Let’sT understandT DataT PreprocessingT inT detailT below.
AfterT theT dataT hasT beenT selected,T itT needsT toT beT
preprocessedT usingT theT givenT steps:
1. FormattingT theT dataT toT makeT itT suitableT forT
MLT (structuredT format)
2. CleaningT theT dataT toT removeT incompleteT
variables
3. SamplingT theT dataT furtherT toT reduceT runningT
timesT forT algorithmsT andT memoryT
requirements.
DataT cleaningT atT thisT stageT involvesT filteringT itT basedT
onT theT followingT variables:
InsufficientT Data:T TheT amountT ofT dataT requiredT forT
MLT algorithmsT canT varyT fromT thousandsT toT millions,T
dependingT uponT theT complexityT ofT theT problemT andT
theT chosenT algorithm.
Non-RepresentativeT Data
TheT sampleT selectedT mustT beT anT exactT representationT
ofT theT entireT data,T asT non-representativeT dataT mightT
trainT anT algorithmT suchT thatT itT won'tT generalizeT wellT
onT newT testT data.
SubstandardT Data
Outliers,T errors,T andT noiseT canT beT eliminatedT toT getT aT
betterT fitmentT ofT theT model.T MissingT featuresT suchT asT
ageT forT 10%T ofT theT audienceT mayT beT ignoredT
completely,T orT anT averageT valueT canT beT assumedT forT
theT missingT component.
SelectingT theT rightT sizeT ofT theT sampleT isT aT keyT stepT inT
dataT preparation.T SamplesT thatT areT tooT largeT orT tooT
smallT mightT giveT skewedT results.
SamplingT Noise
SmallerT samplesT causeT samplingT noiseT sinceT theyT getT
trainedT onT non-representativeT data.T ForT example,T
checkingT voterT sentimentT fromT aT veryT smallT subsetT ofT
voters.
SamplingT Bias
LargerT samplesT workT wellT asT longT asT thereT isT noT
samplingT bias,T thatT is,T thenT theT rightT dataT isT picked.T
ForT example,T samplingT biasT wouldT occurT whenT
checkingT voterT sentimentT onlyT forT theT technicallyT
soundT subsetT ofT voters,T whileT ignoringT others.
DataT Transformation
TheT selectedT andT preprocessedT dataT isT transformedT
usingT oneT orT moreT ofT theT followingT methods:
1. Scaling:T ItT involvesT selectingT theT rightT featureT
scalingT forT theT selectedT andT preprocessedT data.
2. Aggregation:T ThisT isT theT lastT stepT toT collateT aT
bunchT ofT dataT featuresT intoT aT singleT one.
IV.T TYPEST OFT DATA
LabeledT DataT orT TrainingT Data
ItT isT alsoT knownT asT markedT (withT values)T
data.
ItT assistsT inT learningT andT formingT aT predictiveT
hypothesisT forT futureT data.T ItT isT usedT toT
arriveT atT aT formulaT toT predictT futureT behavior. TypicallyT 80%T ofT availableT labeledT dataT isT
markedT forT training.
UnlabeledT Data
DataT whichT isT notT markedT andT needsT
real-timeT unsupervisedT learningT isT categorizedT asT
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-9S3, July 2019
TestT Data
DataT providedT toT testT aT hypothesisT createdT
viaT priorT learningT isT knownT asT testT data. TypicallyT 20%T ofT labeledT dataT isT reservedT forT
theT test.
ValidationT data
ItT isT aT datasetT usedT toT retestT theT hypothesisT (inT caseT
theT algorithmT gotT overT fittedT toT evenT theT testT dataT dueT
toT multipleT attemptsT atT testing).
TheT illustrationT givenT belowT depictsT howT totalT
availableT labeledT dataT mayT beT segregatedT intoT theT
trainingT dataset,T testT dataset,T andT validationT dataset.
V.T CONCLUSION:
Today,T itT isT inevitableT toT considerT andT useT
dataT miningT inT viewT ofT theT ever-increasingT amountT ofT
computerizedT businessT processesT andT theT hugeT amountT
ofT dataT toT beT analyzedT inT parallel.T ItT isT possibleT toT
makeT accurateT estimationsT orT predictionsT aboutT futureT
resultsT throughT applyingT machineT learningT techniquesT
toT theT dataT madeT availableT forT analysisT viaT dataT
mining.T ThisT studyT usedT inT variousT classificationT
techniquesT toT aT groupT ofT individualsT whoT areT inT theT
process.T SinceT usingT machineT learningT techniquesT inT
classificationT studiesT resultsT inT accurateT outcomesT
accompaniedT withT significantT savingT inT termsT ofT timeT
andT cost,T itT isT highlyT recommendedT toT makeT useT ofT
machineT learningT techniquesT inT DataT Processing.T ItT isT
consideredT thatT thisT studyT willT beT usefulT forT
organizationsT andT individualsT operatingT inT allT areasT ofT
workT thatT haveT goneT forT computerizationT ofT theirT
businessT processes.
REFERENCES:
1. J.T Qi,T P.T Yang,T G.T Min,T O.T Amft,T F.T Dong,T andT L.T
Xu,T "AdvancedT InternetT ofT ThingsT forT personalisedT
healthcareT systems:T AT survey,"T PervasiveT andT MobileT
Computing,T vol.T 41,T pp.T 132-149,T 2017.T
2. T.T Pawar,T N.T Anantakrishnan,T S.T Chaudhuri,T andT S.T P.T
Duttagupta,T "ImpactT ofT ambulationT inT wearable-ECG,"T
AnnalsT ofT BiomedicalT Engineering,T vol.T 36,T no.T 9,T pp.T
1547-1557,T 2008.T
3. L.-J.T KauT andT C.-S.T Chen,T "AT smartT phone-basedT
pocketT fallT accidentT detection,T positioning,T andT rescueT
system,"T IEEET journalT ofT biomedicalT andT healthT
informatics,T vol.T 19,T no.T 1,T pp.T 44-56,T 2015.T
4. M.T Ermes,T J.T Pärkkä,T J.T Mäntyjärvi,T andT I.T Korhonen,T
"DetectionT ofT dailyT activitiesT andT sportsT withT wearableT
sensorsT inT controlledT andT uncontrolledT conditions,"T IEEET
transactionsT onT informationT technologyT inT biomedicine,T
vol.T 12,T no.T 1,T pp.T 20-26,T 2008.T
5. D.T RiañoT etT al.,T "AnT ontology-basedT personalizationT ofT
healthcareT knowledgeT toT supportT clinicalT decisionsT forT
chronicallyT illT patients,"T JournalT ofT biomedicalT
informatics,T vol.T 45,T no.T 3,T pp.T 429-446,T 2012.T
6. M.T S.T Organization.T (2018,T NovT 2).T TopT 83T AIT
startupsT inT Healthcare.T Available:T
http://www.medicalstartups.org/top/ai.
7. Y.T GordienkoT etT al.,T "DeepT learningT withT lungT
segmentationT andT boneT shadowT exclusionT techniquesT forT
chestT x-rayT analysisT ofT lungT cancer,"T inT InternationalT
ConferenceT onT TheoryT andT ApplicationsT ofT FuzzyT
SystemsT andT SoftT Computing,T 2018,T pp.T 638-647:T
Springer.T
8. M.T T.T BrownT andT J.T K.T Bussell,T "MedicationT
adherence:T WHOT cares?,"T MayoT ClinicT proceedings,T vol.T
86,T no.T 4,T pp.T 304-314,T 2011.T
9. K.T Teng.T (2012,T May).T WhatT IsT PersonalizedT
Healthcare?T FromT patientsT toT medications,T oneT sizeT doesT
notT fitT all.T Available:T https://health.clevelandclinic.org/what-is-personalizedhealthcare.
10. A.T AraT andT A.T Ara,T "CaseT study:T IntegratingT IoT,T
streamingT analyticsT andT machineT learningT toT improveT
intelligentT diabetesT managementT system,"T inT 2017T
InternationalT ConferenceT onT Energy,T Communication,T DataT
AnalyticsT andT SoftT ComputingT (ICECDS),T 2017,T pp.T
3179-3182.T
11. R.T VargheeseT andT Y.T Viniotis,T "InfluencingT dataT
availabilityT inT IoTT enabledT cloudT basedT e-healthT inT aT
30T dayT readmissionT context,"T inT 10thT IEEET InternationalT
ConferenceT onT CollaborativeT Computing:T Networking,T
ApplicationsT andT Worksharing,T 2014,T pp.T 475-480.T
12. M.T D.T Naylor,T L.T H.T Aiken,T E.T T.T Kurtzman,T D.T M.T
Olds,T andT K.T B.T Hirschman,T "TheT importanceT ofT
transitionalT careT inT achievingT healthT reform,"T HealthT
affairs,T vol.T 30,T no.T 4,T pp.T 746-754,T 2011.T
13. S.T TilsonT andT G.T J.T Hoffman,T "AddressingT MedicareT
hospitalT readmissions,"T CongressionalT ResearchT Service,T
2012.T
14. S.T Shahrestani,T "AssistiveT IoT:T DeploymentT ScenariosT
andT Challenges,"T inT InternetT ofT ThingsT andT SmartT
Environments:T Springer,T 2017,T pp.T 75-95.T
15. M.T A.T HansonT etT al.,T "BodyT AreaT SensorT Networks:T
ChallengesT andT Opportunities,"T Computer,T vol.T 42,T no.T
1,T pp.T 58-65,T 2009.T
16. M.T J.T Rothman,T S.T I.T Rothman,T andT J.T BealsT IV,T
"DevelopmentT andT validationT ofT aT continuousT measureT
ofT patientT conditionT usingT theT ElectronicT MedicalT
Record,"T JournalT ofT biomedicalT informatics,T vol.T 46,T no.T