Rochester Institute of Technology
RIT Scholar Works
Theses
Thesis/Dissertation Collections
7-1-2004
Genetic algorithms in cryptography
Bethany Delman
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion in Theses by an authorized administrator of RIT Scholar Works. For more information, please [email protected].
Recommended Citation
Genetic Algorithms in Cryptography
by
Bethany Delman
A Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science in Computer Engineering
Supervised by
Professor Dr. Muhammad Shaaban Department of Computer Engineering Kate Gleason College of Engineering
Rochester Institute of Technology Rochester, New York
July 2004
ApprovedBy:
Dr. Muhammad Shaaban Professor
Primary Advisor
Dr. Stanislaw Radziszowski
Professor, Computer Science Department
7-?.I-o~ Dr. Shanchieh Jay Yang
Thesis Release Permission Form
Rochester Institute of Technology Kate Gleason College of Engineering Master of Science, Computer Engineering
Title: Genetic Algorithms in Cryptography
I, Bethany Delman, hereby grant permission to the Rochester Institute of Technology to
reproduce my print thesis in whole or in part. Any reproduction will not be for commercial
use or profit.
I, Bethany Delman, additionally grant to the Rochester Institute of Technology
Digi-tal Media Library (RIT DML) the non-exclusive license to archive and provide electronic
access to my thesis in whole or in part in all forms of media in perpetuity.
I understand that my work, in addition to its bibliographic record and abstract, will be
available to the world-wide community of scholars and researchers through the RIT DML.
I retain all other ownership rights to the copyright of the thesis. I also retain the right to
use in future works (such as articles or books) all or part of this thesis. I am aware that the
Rochester Institute of Technology does not require registration of copyrights for ETDs.
I hereby certify that, if appropriate, I have obtained and attached written permission
statements from the owners of each third party copyrighted matter to be included in my
thesis. I certify that the version I submitted is the same as that approved by my committee.
Abstract
Genetic algorithms (GAs) are a class of optimization algorithms. GAs attempt to solve
problems through modeling a simplified version of genetic processes. There are many
problemsforwhich aGAapproach isuseful. Itis, however, undeterminedifcryptanalysis
is such a problem.
Therefore, thiswork explores theuse ofGAs in cryptography. Both traditional crypt
analysis and GA-based methods are implemented in software. The results are then com pared using the metrics of elapsed time and percentage of successful decryptions. A de terminationis madeforeach cipher under consideration asto the validityoftheGA-based
approaches found in the literature. In general, these GA-based approaches are typical of thefield.
Ofthe genetic algorithm attacks found in the literature, totaling twelve, seven were
re-implemented. Ofthese seven, only three achieved any success. The successful attacks
werethose on the transpositionand permutation ciphersby Matthews [20],Clark [4], and Griindlingh and Van Vuuren [13], respectively. These attacks werefurther investigated in
anattempttoimproveor extendtheirsuccess. Unfortunately,thisattempt wasunsuccessful,
as wasthe attemptto apply the Clark [4] attack to the monoalphabetic substitution cipher
and achievethe same orindeed any level of success.
Overall, thestandard fitness equation genetic algorithm approach, and the scoreboard
variant thereof, are not worth the extra effortinvolved. Traditional cryptanalysis methods
are moresuccessful, and easierto implement. While atraditional methodtakesmore time, a faster unsuccessful attack is worthless. The failure ofthe genetic algorithm approach indicatesthat supplementary research into traditional cryptanalysis methods may be more
Contents
1 Introduction .... .... ... .... 1
1.1 Document Overview .... 2
2 Genetic Algorithms 4
3 Cryptography ... 9
3.1 Monoalphabetic Substitutioncipher 9
3.2 Polyalphabetic Substitution cipher 11
3.3 Permutation/Transposition ciphers 12
3.3.1 Permutationcipher 13
3.3.2 Transpositioncipher 13
3.4 Knapsackciphers 15
3.4.1 Merkle-Hellman Knapsackcipher 16
3.4.2 Chor-RivestKnapsackcipher 18
3.5 Vernam cipher 22
3.6 Comments 22
4 Relevant Prior Works 23
4.1 Spillmanetal. 1993 25
4.1.1 Comments 26
4.2 Matthews- 1993 27
4.2.1 Comments 30
4.3.1 Comments 33
4.4 Clark 1994 34
4.4.1 Comments 35
4.5 Lin, Kao 1995 35
4.5.1 Comments 36
4.6 Clark, Dawson, Bergen 1996 37
4.6.1 Comments 38
4.7 Clark, Dawson, Nieuwland 1996 39
4.7.1 Comments 41
4.8 Clark,Dawson - 1997 41
4.9 Kolodziejczyk
-1997 42
4.9.1 Comments 42
4.10 Clark,Dawson - 1998 43
4.10.1 Comments 44
4.11 Yaseen, Sahasrabuddhe - 1999 45
4.11.1 Comments 47
4.12 Grundlingh,Van Vuuren submitted 2002 47
4.12.1 Comments 50
4.13 Overall Comments 51
5 Traditional Cryptanalysis Methods 52
5.1 Distinguishingamongthe threeciphers 53
5.2 Monoalphabeticsubstitution cipher 53
5.3 Polyalphabetic substitution cipher 54
5.4 Permutation/Transpositionciphers 56
5.5 Comments 58
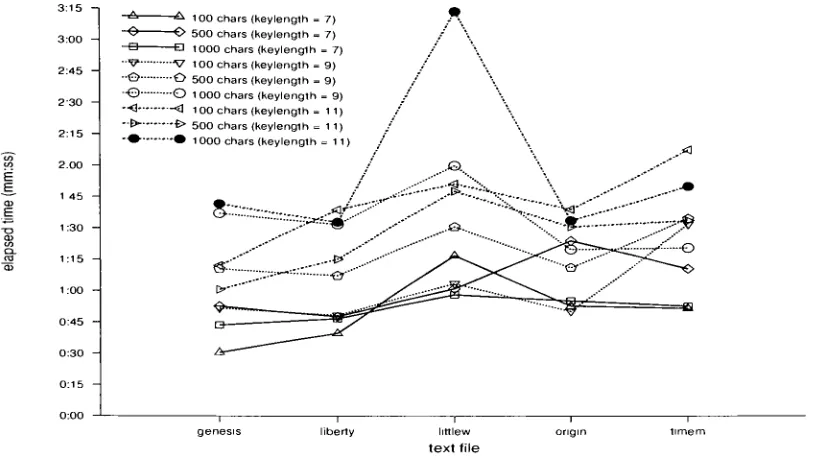
6 Attack Results . . 59
6.2 Classical Attack Results 61
6.3 Genetic Algorithm Attack Results 64
6.4 Comparison ofResults 71
7 ExtensionsandAdditions 74
7.1 Genetic Algorithm AttackExtensions 74
7.1.1 Transposition Cipher Attacks 75
7.1.2 Permutation Cipher Attack 76
7.1.3 Comments 77
7.2 Additions 77
7.2.1 Comments 79
8 Evaluationand Conclusion 81
8.1 Summary 81
8.2 Future Work 83
8.3 Conclusion 83
List
ofFigures
4. 1 Substitution CipherFamily andAttacking Papers 23
4.2 Permutation CipherFamilyandAttacking Papers 24
4.3 Knapsack CipherFamily andAttacking Papers 24
4.4 Vernam CipherFamily andAttackingPaper 24
6.1 Classical SubstitutionAttack 62
6.2 Classical Vigenere Attack 63
6.3 Classical Permutation Attack 64
6.4 Classical Transposition Attack 65
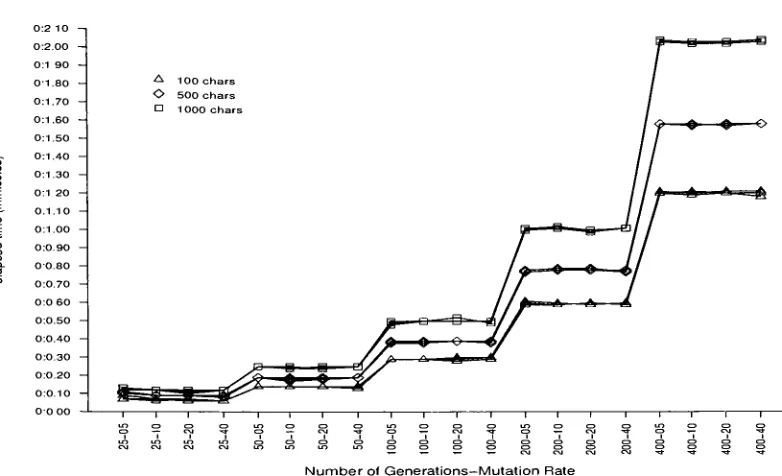
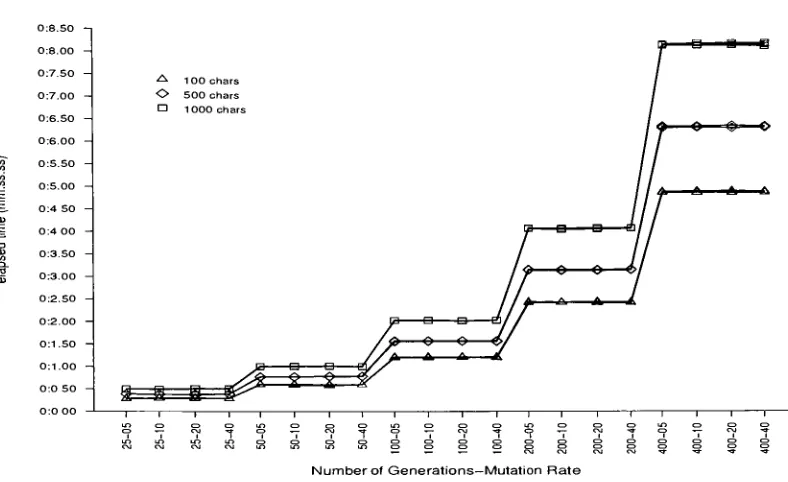
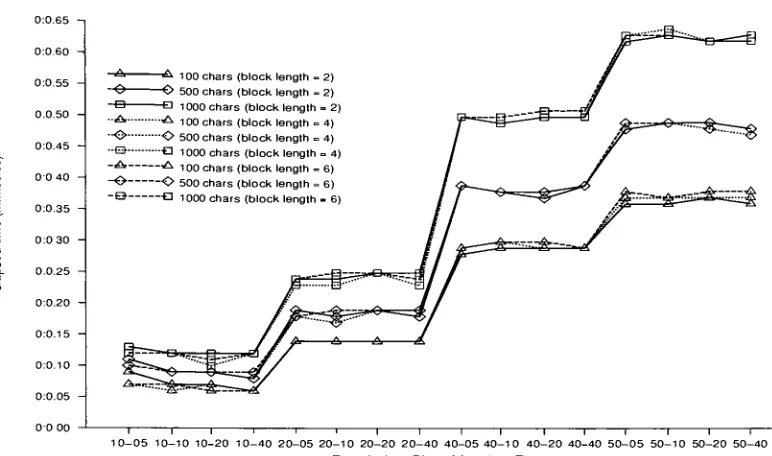
6.5 EffectofNumberofGenerations atPopulation Size 10 67 6.6 EffectofNumberofGenerations atPopulation Size 20 67 6.7 EffectofNumberofGenerations atPopulation Size 40 68 6.8 EffectofNumberofGenerations atPopulation Size 50 68
6.9 EffectofPopulation Sizeat25 Generations 69
6.10 EffectofPopulationSizeat50 Generations 69
6.11 EffectofPopulation Size at 100Generations 70
6.12 EffectofPopulation Sizeat200Generations 70
Glossary
block
block length
chromosome
cipher
ciphertext
crossover(mating)
cryptanalysis
cryptography
cryptosystem
decryption
digram
encryption
A sequence of consecutive characters encoded at one
time
Thenumberofcharactersin ablock
The genetic material ofa individual represents the in formation about a possible solutionto thegiven problem
Analgorithmfor performingencryption (andthe reverse,
decryption) a series of well-defined steps that can be followed as a procedure. Worksatthelevel ofindividual
letters,or small groups ofletters
A text in the encrypted form produced by some cryp
tosystem. Theconventionis forciphertextstocontain no
whitespaceor punctuation
Crossover is the process by which two chromosomes
combine some portion of their genetic material to pro
duce a child orchildren
The analysis and deciphering of cryptographic writings
orsystems
Theprocessorskill ofcommunicating inordeciphering
secret writings orciphers
Thepackage ofall processes, formulae, andinstructions for encoding anddecodingmessagesusingcryptography
Any procedure used in cryptography to convert
cipher-text(encrypted data)intoplaintext
Sequence oftwoconsecutive characters
fitness
generation
genetic algorithm(GA)
key keylength monoalphabetic mutation one-timepad order-basedGA plaintext polyalphabetic
The extent to which a possible solution successfully
solvesthe given problem
-usuallya numerical value
Theaverage interval oftimebetween thebirth of parents
andthebirth oftheiroffspring- in the
genetic algorithm
case, this isone iteration ofthe main loopof code
Search/optimization algorithm based on the mechanics
ofnatural selectionand natural genetics
A relativelysmall amount ofinformation that is used by
an algorithmtocustomizethe transformationof plaintext
intociphertext (duringencryption) or vice versa (during
decryption)
The size ofthekey- how
manyvaluescomprisethekey
Usingone alphabet
-referstoa cryptosystem where each
alphabetic character is mapped to a unique alphabetic
character
Simulation of transcription errors that occur in nature
with alowprobability
-a childis randomlychangedfrom
whatits parents producedin mating
Anothername forthe Vernamcipher
A form of GA where the chromosomes represent per
mutations. Special care must be taken to avoid illegal
permutations
A message beforeencryption or afterdecryption, i.e., in
its usual form which anyone can read, as opposedto its
encryptedform
Usingmany alphabets referstoacipher where each al
phabetic character canbe mapped toone ofmany possi
population
scoreboard
trigram uni gram Vigenere
The possible solutions (chromosomes) currently under
investigation,as well as the number of solutions thatcan
be investigatedat onetime, i.e., per generation
Methodofdetermining thefitness of a possible solution takes a small list ofthe most common digrams and tri-grams andgives each chromosome a scorebasedon how oftenthese combinationsoccur
Sequence ofthreeconsecutive characters Single character
Chapter
1
Introduction
The application of a genetic algorithm (GA)to the field of cryptanalysis is rather unique.
Few works exist on this topic. This nontraditional application is investigated todetermine
thebenefitsofapplyingaGAtoacryptanalyticproblem,ifany. IftheGA-based approach
proves successful, itcould lead tofaster, more automated cryptanalysis techniques. How ever, since this area is so different from the application areas where GAs developed, the
GA-based methods willlikelyprovetobe less successful than the traditionalmethods.
The primary goals of this work are to produce a performance comparison between
traditional cryptanalysis methods and genetic algorithmbased methods, and to determine
thevalidityoftypical GA-basedmethodsinthe fieldof cryptanalysis.
The focus will be on classical ciphers, includingsubstitution, permutation, transposi
tion, knapsackandVernam ciphers. Theprinciples used in theseciphers form thefounda
tionfor many ofthe modem cryptosystems. Also, ifaGA-based approach isunsuccessful
on these simplesystems, it is unlikely tobe worthwhileto apply aGA-based approach to
more complicated systems. A thorough search ofthe availableliterature found GA-based
attacks on only these ciphers. In many cases, these ciphers are some ofthe simplest pos
sible versions. For example, oneoftheknapsack systems attacked is theMerkle-Hellman
knapsack scheme. Inthis scheme,a superincreasingsequenceoflengthn isusedas apub
lic key. According to Shamir[23],atypicalvalue fornis 100. IntheGA-basedattacks on
this cipher,nwaslessthan 16. Thisisalmost anorder of magnitudebelowthetypical case,
GAs.
InotherGA-basedattacks,thereisahuge gap intheknowledgeneededtore-implement
theattack andtheinformationprovidedinthepaper. Forexample, thevalues ofpand hare
vitally necessary foran implementationoftheChor-Rivestknapsack scheme. Thissystem utilizesafinitefield, q,of characteristicp,whereq =
ph,p > h,andthediscrete logarithm
problemis feasible. In theGA-based attack onthis cipher, these values are not provided. This information holemeans that this attack couldhave been mnusing trivia] parameters,
orparameters knowntobe easytoattack. Thisattackcan notbeconsidered remotely valid withoutknowingtheseparameters.
ManyoftheGA-basedattacks alsolackinformationrequiredforcomparisonto the tra ditionalattacks. Thenumber of generations ittookfor a run oftheGAtogettosome state is notat all useful when attempting to compare andcontrast attacks. The most coherent
and seemingly valid attacks were re-implemented so that a consistent, reasonable set of metrics couldbecollected. These metricsincludeelapsed timerequired fortheattackand
thesuccess percentage of each attack.
1.1 Document Overview
Thisthesisis broken intoa number of chapters. Eachchaptercovers oneaspect ofthe thesis in detail. Chapter 2gives abrief introduction to genetic algorithms. Thegeneral formof
the selection,reproductionand mutationoperatorsarediscussed,asisthegeneral sequence ofeventsforaGA-based approach. Chapter 3 introduces thenecessaryclassical ciphersin detail. Thealgorithmforeach cipherisgiven, in some cases includinga small exampleto illustratetheprocess ofusingthegivencryptosystem.
Thenexttwochapters coverthedifferentattacksfound in theliterature. Chapter 4 dis
cussesthe variousGA-based attacks in detail. These attacks are coveredin chronological
chapter,Chapter5,detailstheclassical attack onthosecipherschosenfor furtherinvestiga
tion. Theciphers were selectedfor further investigation duetothedifficultyorlack thereof
ofthe traditional attack method, as well as theclarity and quality of theGA-based work.
Forexample, the Vernam cipherwas not selected for further investigation. This cipheris
unconditionally secure, meaningthat an attack is successful only when thereis a protocol or implementation failure. There is no basis for attacking this cipher when no mistakes
have been made.
The nextchapters detail theresults ofthe traditional and GA-based attacks, as well as
extensions to theGA-based attacks. Chapter6covers theresults ofthe traditional attacks,
anddiscussesthoseGA-based attacksthatachieved some success. Chapter 7 discussesthe
extensions madetoseveral ofthe GA-basedattacks,as well asnew work attempted.
Finally, Chapter 8 discusses the overall conclusions drawn from this work, as well as
Chapter
2
Genetic Algorithms
The genetic algorithm is a search algorithm based on the mechanics of natural selection
and natural genetics [12]. AssummarizedbyTomassini [29],themain ideais thatinorder fora population ofindividualsto adapttosomeenvironment, it shouldbehave likea natu
ral system. Thismeans thatsurvival andreproduction of anindividual is promoted bythe eliminationof uselessorharmfultraitsandbyrewardingusefulbehavior. Thegenetic algo rithm belongs to the familyofevolutionary algorithms, alongwith genetic programming, evolution strategies, and evolutionary programming. Evolutionary algorithms canbe con sidered as abroadclass of stochastic optimization techniques. An evolutionary algorithm maintains a population of candidate solutions fortheproblem at hand. The population is then evolvedby the iterativeapplication of a set ofstochastic operators. The set ofopera tors usuallyconsists ofmutation, recombination, and selectionor something very similar. Globallysatisfactory, ifsub-optimal, solutionsto the problem arefound in much thesame
way as populationsin natureadapt to theirsurroundingenvironment.
UsingTomassini 'sterms [29],geneticalgorithms(GAs)consider an optimization prob lem as the environment wherefeasible solutions aretheindividuals living in thatenviron
ment. The degreeof adaptation of anindividual toitsenvironmentisthecounterpart ofthe fitness functionevaluatedon asolution. Similarly, a setoffeasiblesolutionstakestheplace
In general, a genetic algorithm begins with a randomly generated set of individuals.
Once the initial population has beencreated, thegenetic algorithm enters aloop [29]. At
the end of each iteration, a new population has been producedby applying a certain num ber of stochastic operatorsto the previous population. Each such iteration is known as a
generation [29].
Aselection operatorisapplied first. Thiscreates an intermediatepopulationof n "par
ent"
individuals. To produce these "parents", n independent extractions of an individual from theold population are performed [29]. The probability of each individual being ex tracted shouldbe (linearly) proportional to the fitness ofthat individual. This means that above average individuals should have more copies in the new population, while below average individuals should have few tono copiespresent, i.e., abelow average individual risksextinction.
Oncetheintermediatepopulation of
"parents"
(those individualsselectedforreproduc
tion)has beenproduced, the individuals forthenext generation willbecreatedthrough the application of anumberof reproductionoperators[29]. Theseoperators caninvolve oneor
more parents. An operatorthat involves just oneparent, simulatingasexual reproduction, is called a mutation operator. Whenmorethan one parent isinvolved, sexual reproduction issimulated,andtheoperatoriscalledrecombination [29]. Thegenetic algorithmusestwo
reproduction operators
-crossover and mutation.
To apply a crossover operator, parents are paired together. There are several differ
ent types of crossover operators, and the types available depend on what representation is used forthe individuals. For binary string individuals, one-point, two-point, and uni formcrossover are often used. Forpermutation ororder-based individuals, order,partially
between thefirstand second cutpoints iscopiedfromthe firstparent to thechild [28]. The
remaining places are filled usingelements not occurring in this section, in the order that
they occurinthe secondparentstarting from the second cut pointand wrapping around as needed. For partially mapped crossover, the section between the two cut points definesa series ofswappingoperationstobe performed on the second parent [28]. Cyclecrossover satisfiestwo conditions every position ofthe child must retain a valuefound in the cor respondingposition of a parent, and the child must be a validpermutation. Eachcycle, a random parent isselected. Forexample [28]:
Parent 1 is (h kc ef d b 1 a i gj) and parent2is(abcdefghijkl)
Forposition#1 in the child, 'h' is selected
Therefore, 'a'
cannotbeselected fromparent2 and mustbe chosenfrom parent 1
Since 'a'
isabove
'i'
inparent 2, T mustalso beselectedfrom parent 1
So, if 'h'
isselected fromparent 1 forposition#1, then 'a', 'i\ 'j', and T mustalso beselectedfromparent 1
The positions ofthese elements are said to form acycle, since selection continues
untilthefirstelement
('h'
here) isreached again
After crossover, each individual has a small chance of mutation. The purpose ofthe
mutation operator is to simulatethe effect oftranscription errors that can happen with a very low probability when a chromosome is mutated [29]. A standard mutation operator forbinary stringsis bit inversion. Each bit in an individual hasa small chanceofmutating into itscomplementi.e. a
'0'
wouldmutateintoa T.
In principle, the loop of selection-crossover-mutation is infinite [29]. However, it is
usually stopped when a given termination condition is met. Some common termination
conditions are [29]:
2. A satisfactory solutionhas been found
3. No improvement in solution quality has taken placefora certain numberofgenera tions
The differentterminationconditions are possible since a genetic algorithm is notguar
anteed to converge to a solution. The evolutionary cycle can be summarized as follows [29]:
generation = 0
seed population
while not(termination condition)do generation = generation + 1
calculatefitness
selection crossover mutation endwhile
Typicalapplication areasforgenetic algorithms include:
Function Optimization
Graph Applicationssuchas
-Coloring
- Paths
- Circuit Layout
Scheduling
Satisfiability
Game Strategies
Computing Models
Neural Networks
Lens Design
Many ofthese application areas are concerned with problems which are hard to solve
but have easily verifiable solutions. Another trait common to these application areas is
the equation style offitness function. Cryptographyand cryptanalysis couldbe considered
to meet these criteria. However, cryptanalysis is not closely related to the typical GA
application areas and, subsequently, fitness equations are difficultto generate. This makes
Chapter 3
Cryptography
In general, the genetic algorithm approach has only been used to attack fairly simple ci
phers. Most oftheciphers attackedareconsideredtobe classical, i.e. thosecreatedbefore
1950 A.D. [21] whichhave becomewell knownovertime. Ciphers attacked include:
Monoalphabetic Substitutioncipher
Polyalphabetic Substitutioncipher
Permutationcipher
Transpositioncipher
Merkle-Hellman Knapsackcipher
Chor-RivestKnapsackcipher
Vernamcipher
3.1
Monoalphabetic Substitution cipherThesimplestcipherofthoseattackedisthemonoalphabetic substitution cipher. Thiscipher
is described asfollows:
Letthekeys, /C,consistof all possible permutations ofthesymbols in Z
Foreach permutationit G /C,
1. define theencryption function e7I(x) =
n(x)
2. and define the decryption function dn(y) =
Tt~l(y), where 7r_1
is the inverse
permutationton.
Forexample,define Ztobethe26 letter Englishalphabet. Then,a random permutation
7r couldbe (plaintextcharacters are in lowercase and ciphertext characters in uppercase)
[27]:
a b c d e f g h i j k 1 m
X N Y A H P 0 G Z Q W B T
n o P q r s t u V w X y z
S F L R C V M U E K J D I
This definestheencryptionfunction likeso
-en(a) = X,
e^(b) = N, etc. The
decryp
tionfunction,dn(y) istheinversepermutation,and canbeobtainedby switchingtherows.
7T"1
is,therefore:
A B C D E F G H I J K L M
d 1 r y v 0 h e z X w P t
N O P Q R S T U V W X Y Z
b g f j q n m u s k a c i
Usingtheencryptionfunction,aplaintext of
'plain'
becomesaciphertext of'LBXZS'.
Aciphertext of 'YZLGHC woulddecryptto 'cipher'.
Monoalphabetic substitution is easy to recognize, since the frequency distribution of
course. This attribute allows associations betweenciphertext andplaintext characters, i.e.
if the most frequent plaintext character X occurred ten times, the ciphertext character X
mapstowill appearten times.
3.2
Polyalphabetic
Substitution cipherThis cipher is a more complex version ofthe substitution cipher. Instead ofmapping the
plaintext alphabet ontociphertext characters, different substitution mappings areused on
differentportions oftheplaintext[21]. Theresultiscalled polyalphabetic substitution. The
simplest case consistsofusing different alphabetssequentially andrepeatedly, so thatthe
position of each plaintext characterdetermines which mapping is applied to it. Under dif
ferentalphabets, thesame plaintext characterisencryptedtodifferentciphertextcharacters,
makingfrequencyanalysis harder.
Thiscipherhasthe followingproperties (assuming m mappings):
Thekeyspace/Cconsists of all ordered sets of m permutations
Thesepermutations arerepresentedas (ki,k2,.
,km)
Eachpermutation ki is definedonthe alphabetinuse
Encryptionofthemessage x = (x1,x2, . . .
,xm) is givenby
ek(x) =
ki(xi)k2(x2) . . . km(xm), assumingthekey k = (fci,k2,. . . ,km)
The decryptionkey associated with ek(x) isdk(y) = (k^1,k2l ,. . .
,fc"1).
The encryption and decryption functions could also be written as follows (assuming
that theaddition/subtraction operationsoccur modulothe sizeofthealphabet):
eK(x1,x2, .,xm)
= (xi + ki,x2 +k2,...,xm + km)
dK(yi,yo.,...,ym) = (y\ - h,y2-k2,. . .
,ym
The most common polyalphabetic substitution cipher is the Vigenere cipher. Thisci
pher encrypts m characters at a time, making each plaintext character equivalent to m
alphabetic characters. Aexample ofthe Vigenerecipheris:
Supposem= 6
Usingthemapping A <-> 0,B <-^-1, . . .
,Z <-> 25
IfthekeywordAC = CIPHER,
numerically (2, 8, 15,7,4, 17)
Supposethe plaintextis thestring 'cryptosystem'
Converttheplaintext elements toresidues modulo26- 2 17 24 15 19 14 18 24 18 19
4 12
Writetheplaintext elements in groups of6and addthekeywordmodulo26
2 17 24 15 19 14 18 24 18 19 4 12
2 8 15 7 4 17 2 8 15 7 4 17
4 25 13 22 23 5 20 6 7 0 8 3
The alphabetic equivalent oftheciphertextstring is: EZNWXFUGHAID.
Todecrypt,thesamekeywordisusedbutissubtractedmodulo26 fromtheciphertext
3.3 Permutation/Transposition ciphers
Althoughsimple transpositionciphers changethedependencies betweenconsecutive char
acters, they are fairly easily recognized sincethe frequency distribution ofthe characters
ispreserved [21]. This istrue for both ciphersconsidered,the permutation cipher andthe
columnartransposition cipher. Both ciphers apply the same principles, but differ in how
the transformation is applied. The permutation cipher is applied to blocks of characters
3.3.1 Permutation cipher
The idea behind a permutation cipher is to keep the plaintext characters unchanged, but
altertheirpositionsby rearrangementusinga permutation [27].
Thiscipheris defined as:
Let mbe a positive integer, andACconsist of all permutations of{1,... ,m}
Forakey(permutation) -n E AC,define:
Theencryption functione7r(xi,. . . ,xm)
= (x^i),
. . ,x^m))
The decryption functiond^(yi ym) = (2/^-1(1),
,y*-Hm))
A smallexample,assuming m = 6,andthe
key isthepermutation n:
ic(l) 2
The first row is the value of i, and the second row is the corresponding value of
7r(z). The inverse permutation,
ir~x
is constructed by interchanging the two rows, and
rearranging the columns so that the first row is in increasing order, Therefore, 7r_1 is:
X 1 2 3 4 5 6
TX~l(x) 3 6 1 5 2 4
Ifthe plaintext given is 'apermutation', it is firstpartitioned into groups of m letters
('apermu'
and 'tation') and then rearranged according to the permutation ir. This yields
'EMAURP'
and 'TOTNIA', makingtheciphertextequal
'EMAURPTOTNIA'
. The
cipher-textis decrypted in asimilarprocess, usingtheinverse permutation7r_1.
3.3.2 Transposition cipher
Anothertypeof cipherinthiscategory isthecolumnartranspositioncipher. Asdescribedin
[24], thiscipher consistsofwritingtheplaintextintoarectangle with a prearranged number
of columns and transcribing it vertically by columns to yield the ciphertext. The key is
rectangle andtheorderinwhich to transcribe thecolumns [24]. Thiskey is usuallyderived
from an agreed keyword by assigning numbersto the individual letters according to their
alphabetical order.
For example, ifthe keyword is SORCERY, the resulting numerical key would be 6 3
4 12 5 7 [24], where numbers are assignedto the keyword letters accordingto the alpha
betical order ofthe letters. Ifwe wishtoencipherthe message LASER BEAMS CAN BE
MODULATED TO CARRY MOREINTELLIGENCETHAN RADIO WAVES, it would
first be written out on a width of7underthe numerical key. As is traditional,white spaces
and punctuation are ignored in thisand all ciphertexts used. The rectangle wouldlooklike
this:
S O R C E R Y
6 3 4 12 5 7
L A S E R B E
A M S C A N B
E M O D U L A
T E D T O C A
R R Y M O R E
I N T E L L I
G E N C E T H
A N R A D I O
WAVE S Q R
Sincethe message length was not amultiple ofthe keyword length, the message does
not fill the entire rectangle. Deciphering is simplified if the last row contains no blank
cells, so two dummy letters are added (here, Q and R) to make the rectangle completely
filled [24]. Enciphering consists ofreadingthe ciphertext out vertically in the orderofthe
numbered columns. Itcan bewritten ingroupsoffive letters atthesametime, ifsodesired
[24]. The ciphertext is, therefore, ECDTM ECAER AUOOL EDSAM MERNE NASSO
The decipherer would countthe number of letters in the message (63) and determine
thelength oftheinscription rectangle by dividing this value by the length ofthe keyword.
This makes theinscription rectangle 7 x 9 in thiscase. The numerical key is then written
above the rectangle and the ciphertext characters entered intothe diagram in the order of
thekeynumbers [24]. The plaintextisread offbyrows, as itwas originallyentered.
3.4 Knapsack ciphers
Knapsack public-key encryption systems are based on the subset sum problem, an
NP-complete problem. Given in thisproblem are afinite setS C N+ (N+ is the set of natural
numbers {1,2, . . . }), and a target t G N+. The question is whether thereexists a subset
S'
C S whose elements sumtot [9]. Forexample:
If5 = {1,2,7, 14,
49, 98, 343, 686, 2409, 2793,16808, 17206, 117705, 117993}
Andt = 138457
Then thesubsetS' = {1,
2, 7, 98, 343, 686, 2409, 17206,117705} isa solution.
Thebasic idea of aknapsackcipheris toselect an instance ofthe subset sum problem
thatis easy to solve, andthen disguise it asan instance ofthegeneral subset sum problem
whichishopefullydifficulttosolve [21]. Theoriginal (easy)knapsackset can serve asthe
privatekey, whilethe transformedknapsack set serves asthepublickey.
The Merkle-Hellman knapsack cipheris important as it was the first implementation
of apublic-key encryption scheme. Many variations on it have been suggested but most,
includingthe original,have been demonstratedtobe insecure [21]. A notableexception to
3.4.1 Merkle-HellmanKnapsack cipher
TheMerkle-Hellman knapsackcipher attemptstodisguisean easily solved instanceofthe
subset sum problem, called asuperincreasingsubset subproblem, by modularmultiplica
tion and apermutation [21]. A superincreasing sequenceis a sequence (bi,b2,. . .
,bn) of
positive integerswith theproperty that6j > 2^7=1 fy> freacni,2 <i <n.
The integern is a common system parameter. 6j, b2,. . .
,bn is the superincreasing se
quence and M isthe modulus, selected such thatM > 6] + b2 + . . . + bn. W isa random
integer, such that 1 < W < M 1 and gcd(H/, 7\/) = 1. 7r is a random permutation
ofthe integers {1,2,...,n}. The publickey ofA is (ai,a2,. . .
, an), where a; =
Wbv^
mod M, andtheprivatekeyofA is (n,M, W, (h,b2, . . . ,bn)).
The steps inthe transmission of a message m are as follows (B isthe sender, A isthe
receiver) [21]:
1. Encryption - B
shoulddothefollowing:
Obtain A's authenticpublickey (a1;a2, . . . ,an)
Representthemessage m as abinary stringoflength n,
m =
m\m2 . . .mn
Compute the integerc=
m\a\ + m2a2 + . . . + mnan
Sendtheciphertext cto A
2. Decryption Torecovertheplaintext mfrom c,Ashould dothefollowing:
Compute d = W~lc mod M
Bysolvingasuperincreasingsubset sumproblem,findtheintegersr-\,r2, . . . ,rn,
Ti G {0, 1} suchthatd =
r-\b\ +r2b2 + . . . +rnbn.
Themessagebitsarem, =
r^), i =
1,2, . . . ,n.
1. Letn = 6
2. EntityAchoosesthesuperincreasingsequence(12, 17,33, 74, 157,316)
3. M = 737
4. VU =635
5. Thepermutation n of{1,2, 3,4, 5,6} is definedas:
6. 7r(l) =
3,7r(2) =
6,tt(3) =
1,tt(4) =
2,tt(5) =5,tt(6) =4
7. A'spublickeyistheknapsackset (319,196,250, 477, 200,559)
8. A's privatekey is (n,M, W, (12,17,33,74, 157,316))
9. Toencryptthemessage m 101101,B computesc as:
10. c= 319+ 250+477+559 = 1605
1 1. and sends ittoA
1. Todecrypt, Acomputes
2. d = W~lc mod M = 136
3. andsolves the superincreasingsubset sum problemof:
4. 136 = 12r: + 17r2 +
33r3 +74r4 + 157r5 +316r6
5. toget 136 = 12 +17+ 33+ 74
6. Therefore,rx =
1,r2 =
1,r3 =
1,r4 =
1,r5 = 0,
r6 = 0
7. Applying the permutation n producesthe messagebits:
8. m1 = r3 =
l,ra2 = r6 =
0,m3 = r1 =
1, mA =
r2 = l,m5 = r5 =
0,m6 =
3.4.2 Chor-Rivest Knapsackcipher
The Chor-Rivest cipher is the only known knapsack public-key system that does not use
some form of modular multiplication to disguise an easy subset sum problem [21]. This
cipheris by farthemost sophisticated ofthose attacked by agenetic algorithm. When the
parameters ofthis system are carefully chosen, and no information is leaked, there is no
feasible attack on theChor-Rivest system. It can not be covered in detail in a few pages,
soonly asummary ofthesystem will be given. Further numbertheoretical algorithms are
neededfortheset-up and operation ofthecipher.
Most of the parameters are based on a finite field q, of characteristic p, where q =
ph,p > hand forwhich thediscrete logarithmproblem is feasible [21]. f(x) is arandom
monicirreducible polynomial ofdegree h overZp. The elements ofq arerepresented as
polynomials in Zp[x] of degree less than h, with multiplication done modulo f(x). g(x)
is a random primitive element ofq. Foreach ground field element i G Zp, the discrete
logarithm ai = log^^x +
i) ofthefieldelement (x + i) to the base g(x) mustbe found.
The random permutation n is on the set of integers {0, 1, 2,. . .
,p 1}, and the random
integerd is selected such that 0 < d < ph
2. c, is then computed as c* =
(a^j)
+ d)mod (ph 1),0 < i < p 1. A's publickey is ((c0,Ci, . . .
,cp-i),p,h) andits privatekey
is (f(x),g(x),n,d).
A message mis transmittedasfollows (B isthesender,Aisthereceiver) [21]:
1. Encryption - B
shoulddothefollowing:
Obtain A'sauthentic public key ((c0,c\,. . .
,cp_i),p,h)
Represent the message m as abinary string oflength |lg (^)J, where
()
is abinomialcoefficient
Considerm as thebinary representationof an integer
Transformthisinteger intoabinaryvectorM = (M0,
Mi,...
,Mp_i) oflength
p havingexactly h l's asfollows:
(b) For% from 1 topdothefollowing:
(c) Ifm >
(p;')
then set M^*-l,m*-m-{p~li), I <- I - 1
(d) Otherwise, setA/,_i < 0
(e) Note:
()
= 1 forn > 0,(?)
=0) forI > 1
Computec =
2_X^> ^c mo<^ (Ph ~ 1)
Sendtheciphertext ctoA
2. Decryption Torecovertheplaintext mfrom c, Ashoulddothefollowing:
Computer =
(c-hd) mod (ph 1)
Compute u(x) = g(x)r
mod f(x)
Compute s(x) ~
u(x) + f(x), a monic polynomial ofdegree hoverZp (Zpis
theset of integers {0, ...
,p 1}. Addition, subtraction, and multiplication in
Zp are performed modulop.)
Factor s(x) into linear factors overZp : s(x) =Ylj=1(x +tf), where
tj G Zp
Computeabinary vectorM = (M0,Ml5 . . .
,Mp_i) asfollows:
(a) The componentsofMthatare 1 have indices7r_1(tj), 1 < j < h.
(b) The remainingcomponents are0.
Themessage misrecovered fromM as follows:
(a) Setm
<-0,/ <- h
(b) Fori from 1 topdothefollowing:
(c) ifMj_x = 1, then set m
<-m+
(P7')
andI < / -1An exampleusing artificiallysmall parameters wouldgo asfollows [21]:
1. EntityAselectsp
= 7 andh = 4
2. Entity A selects the irreducible polynomial /(x) = x4
+ 3x3 + 5x2 + 6x + 2 of
degree 4overZr. Theelements ofthefinite field 7i are represented as polynomials
3. EntityA selectsthe random primitive elementg(x) = 3x3 + 3x2
+ 6
4. EntityA computesthefollowingdiscrete logarithms:
. o.o =
logg(:r)(x) = 1028
a2 = logg{x)(:r +
1) = 1935
. a2 = logs(l)(./; +
2) = 2054
. a3 = log9(l)(r +
3) = 1008
a., = log5(l)(x+
4) = 379
a5 = logs(l)(.T+
5) = 1780
. a6 = log3(l)(.r +
6) = 223
5. Entity A selectstherandom permutation n on {0, 1,2,3,4,5,6} definedby 7r(0) =
6,tt(1) =
4,tt(2) =
0,tt(3) =
2,tt(4) =
1,tt(5) =
5,tt(6) = 3
6. EntityA selectsthe randominteger d = 1702
7. EntityA computes:
Co = (a6+
d) mod 2400 = 1925
a = (a4+
d) mod 2400 = 2081
C2 = (o0+d) mod 2400 = 330
c3 = (a2+
d) mod 2400 = 1356
c4 = (ai +
d) mod 2400 = 1237
c5 = (a5+
d) mod 2400 = 1082
c6 = (a3+
d) mod 2400= 310
8. EntityA'spublickey is ((c0,Ci,c2, c3,r4, c5,c6),p = 7,h= 4),andits private
key is
9. Toencryptamessagem = 22 forA,
entity B doesthefollowing:
(a) Obtains A'sauthentic publickey ((c0,Ci, c2, c3,c4,c5, c$),p,h)
(b) Represents m as abinary string oflength 5: m = 10110 (Notethat [lg
Qj
=5).
(c) Transforms mto thebinary vectorM = (1,
0, 1, 1,0,0,1) oflength 7
(d) Computes c = (c0 +
c2 +c3 +c6) mod 2400= 1521
(e) Sends c= 1521 toA
10. To decrypttheciphertext c= 1521,A doesthe following:
(a) Computes r = (c
-hd) mod 2400 =1913
(b) Computes u(x) =
#(x)(1913) mod /(.r) = x3
+ 3x2 +2x + 5
(c) Computes s(x) =
u(x) +f(x) = x4
+ 4x3 +x2
+x
(d) Factors s(x) = x(x +2)(x+ 3)(x+
6) (so*, =0,t2 =
2,*3 =
3,t4 = 6).
(e) Thecomponentsof7\/thatare 1 have indices 7r_1(0) =
2,7r-1(2) =
3,7r_I(3) =
6,ir-1
(6) = 0. Hence, M=
(1,0,1,1,0,0,1)
(f) Transforms M to theinteger m = 22,
recoveringtheplaintext
To illustrate how small the above parametersare, the parameters originally suggested
fortheChor-Rivestsystem are [21]:
p = 197 andh = 24
p = 211 andh = 24
p = 35 andh= 24
3.5
Vernam
cipherThe Vernam cipher is a stream cipher defined on the alphabet A = {0,1}. A binary
message niim2. . . mt is operated on by abinary key string kjk2. kt, ofthe same length
to produce aciphertext string cxc2. . . ct where c, = m, (b k,, 1 < i < t [21]. Ifthe key
string is randomly chosen and never used again, thiscipheris called aone-time system or
one-time pad.
The one-time pad can be shown tobe theoretically unbreakable [21]. Ifa cryptanalyst
has a ciphertext string c\c2...ct encrypted using a random, non-reused key string, the
cryptanalyst candonobetterthan guess attheplaintextbeingany binary stringoflength t.
It has been proven that an unbreakableVernam system requires a randomkey ofthesame
length asthemessage [21].
3.6
Comments
The above ciphers comprise all those cryptosystems attackedusing a genetic algorithm in
afairly exhaustive search oftheliterature. The newest ofthese systems are the knapsack
ciphers, with theChor-Rivest system published in 1985, and the Merkle-Hellman system
publishedin 1978 [21]. The other ciphers attacked are all systems olderthan that. In some
cases, centuries older. None ofthe modem ciphers, such as DES, AES, RSA, or Elliptic
Curve, were even attemptedusing a genetic algorithm based approach. The only ciphers
that are considered even remotely mathematically difficult are the knapsack systems, and
even they are nottrue numbertheoretical protocols. This lack makes many ofthe genetic
Chapter
4
Relevant Prior Works
While therehave been manypaperswritten on genetic algorithms and theirapplication to
variousproblems, therearerelatively fewpapersthatapplygenetic algorithmstocryptanal
ysis. Theearliest papers thatuse a genetic algorithm approach fora cryptanalysis problem
were writtenin 1993,almosttwenty years aftertheprimarypaperon genetic algorithmsby John Holland [12] [14]. These papersfocus on thesimplest classical and modem ciphers,
and are citedfrequentlybylaterworks.
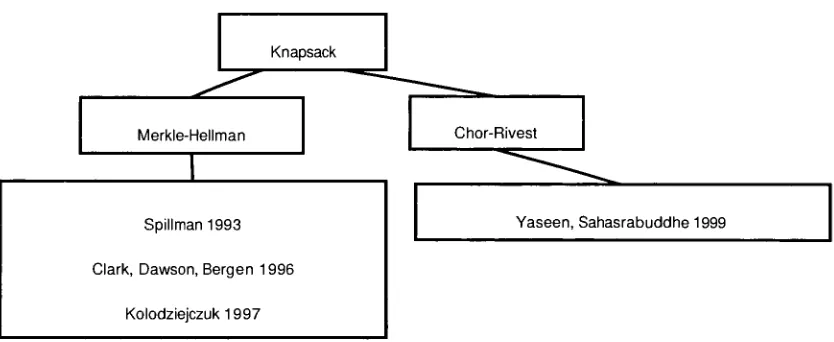
Figures 4.1 through4.4 show whichciphers areattackedby which authors.
Substitution
Monoalphabetic Polyalphabetic
/
V
Spillmanet. al.1993
Clark1994
Clarket. al.1996
Clark&Dawson1997
C
Clark & Dawson
rundlingh&Van Vu 1998
uren2002
Permutation/Transposition
Permutation Transposition
1
\
Clark1994
Matthews1 993
[image:35.521.101.420.75.220.2]Grundlingh&Van Vuuren2002
Figure 4.2: Permutation CipherFamily andAttacking Papers
Knapsack
Merkle-Hellman
Spillman1993
Clark, Dawson,Bergen 1996
Kolodziejczuk1 997
Chor-Rivest
[image:35.521.53.470.292.463.2]Yaseen,Sahasrabuddhe 1999
Figure 4.3: Knapsack CipherFamily andAttacking Papers
Vernam
Lin,Kao1995
[image:35.521.207.314.536.616.2]4.1
Substitution:
Spillman
et al. - 1993The firstpaper published in 1993 by Spillman, Janssen, Nelson and Kepner [26], focuses
on thecryptanalysis of a simplesubstitution cipher usingagenetic algorithm. This paper
selects a genetic algorithm approach so that a directed random search of the key space
can occur. The paper begins with a review of genetic algorithms, covering the genetic
algorithm life cycle, and the systems needed to apply a genetic algorithm. The systems
are consideredto be a key representation, a mating scheme, and a mutation scheme. The
selected systems are then discussed. Thekey representation is an ordered list of alphabet
characters,wherethefirstcharacterinthelist istheplaintextcharacterforthemostfrequent
ciphertext character, the second character is the plaintext character for the second most
frequentciphertextcharacter,and so on. The matingschemerandomlyselectstwokeys for
mating,weightedin favorofkeyswith ahigh fitnessvalue. The twoparentkeyscreatetwo
childkeysbyselecting fromeach slotintheparentsthemorefrequentciphertext character.
Thefirstchildkey iscreatedbyscanning left to right,andthe secondbyscanning right to
left. Ifthemorefrequentcharacteris already inthe child, then thecharacterfromtheother
parent is selected. The mutation scheme consists ofswapping two characters in the key
string. Thefitness function uses unigrams anddigrams, andis asfollows:
26 26
Fitness = (1
-J]{|5F[i]
-DF[i\\ +
Y^\SDF[i,j]
-DDF[i,j]|}/4)8
(4.1.1)
i=i i=i
Thefunctionrepresents anormalizederror value. Largerfitnessvaluesrepresentsmaller
errors. Sensitivity to small differences is increased by raisingthe resultto the 8th power,
while sensitivityto large differences is decreased by thedivision ofthe summationterms
by 4. SF[i] is the standard frequency of character i in English plaintext, while DF[i] is
the measured frequency ofthe decoded characteri in the ciphertext. This makes the first
summationtermequal to thesum ofthedifferences betweeneach character's standardfre
quency andthe frequency ofthe ciphertextcharacterthatdecodes to thatcharacter. SDF
is thestandardfrequency foradigram andDDFthe measured frequency. Whenthemea
fitnessvalueequal one. Thisfitnessfunction is bounded belowbyzero, butcannotevaluate
tozero. Since high fitnessvalues aremoreimportant,thisdoes not effectthe overall result.
Thecomplete algorithm used in thisworkis:
1. Generatearandompopulationofkeystrings
2. Determine afitnessvalue foreachkey inthepopulation
3. Doabiased random selection of parents
4. Applythecrossover operation to theparents
5. Applythe mutationprocessto thechildren
6. Scanthenew population ofkeystrings andupdatethe listofthe 10"best"keysseen
Theprocessstops after afixed number ofgenerations, at whichpoint, thebest keysare
usedtodeciphertheciphertext. Resultsare givenfor 100generation runs ofthe algorithm,
using populations of 10 and50 keys, and mutation rates of 0.05, 0.10, 0.20, and 0.40. In
the smaller population size, the exactkey is found aftersearching less than 4x10 23 of
thekey space, or afterthe examination of about 1000 keys. In the larger population size,
only about20 generationsare needed to examine 1000keys. The best mutation rates for
thisexperiment were thoselessthan0.20.
4.1.1 Comments
Overall, thispaperis a good choice forre-implementation and comparison. It is an early
work, sodoesnotcompareits results to others,butprovidesadecent level ofresult report
ing and discussion, makingcomparison possible. It presents the basic genetic algorithm
conceptsclearly, anduses examplesanddiagrams to clarify importantpoints.
Typicalresults:
- The
- Visual inspection
ofthe plaintextis required mostofthe time todetermine the
exact key
Re-implementationapproach:
- The
sameparameters are re-used
- Additional
parameters areusedtoexpandtherangeof parameter values
Observedcryptanalytic usefulness:
- None
-noexactkeys found intesting
Commenton resultdiscrepancy:
- Differentmeasures ofsuccesswere used
4.2 Transposition: Matthews - 1993
The second paper published in 1993 [20], by R. A. J. Matthews, uses an order-based ge
netic algorithmto attack asimpletranspositioncipher. Thepaperbeginsby discussingthe
archetypal genetic algorithm. This includes the typical genetic algorithm components, as
well as the two characteristics a problem must have in orderfor it to be attackable by a
genetic algorithm. Thefirstcharacteristicisthatapartially-correctchromosomemusthave
ahigherfitnessthananincorrectchromosome. Thesecond characteristicisanencoding for
theproblem thatallows geneticoperators to work. The next sectionofthepaperdiscusses
the cryptanalytic use ofthegenetic algorithm. Itconcludesthatsubstitution,transposition,
permutation, and otherciphers areattackablebyagenetic algorithm,while ciphers such as
DES(DataEncryption Standard),which is aFeistelcipher, are not attackable.
Thecipher selectedforattack in thiswork isaclassical two-stagetransposition cipher.
Here, a key of length N takes the form of a permutation ofthe integers 1 to N. The
plaintext, L characterslong, iswrittenbeneaththekeyto forma matrix TVcharacters wide
thecolumnsintheorderindicatedbytheintegers in thekey. Decryptionconsists ofwriting
down the key, determining the length ofthecolumns, writing the ciphertext back intothe
matrixinsequence, andreadingacrossthecolumns. Breakingthiscipheristypically a
two-stage process as well. The stages are determining the lengthofthe transposition sequence
(TV), and thenfindingthe permutation oftheTV integers.
The genetic algorithmsystem used toattackthe transposition cipheris knownas
GEN-ALYST. It incorporates allthestandardgenetic algorithmfeatures, withthe addition ofthe
items needed foran order-based approach. The GENALYSTsystem usesa fitness scoring
system basedon the number oftimes commonEnglish digrams andtrigramsappearinthe
decrypted text. Ten digramandtrigramswere used
-TH, HE, IN, ER, AN, ED, THE, ING,
AND, andEEE. The presence ofEEE resultedin a subtraction offitnesspoints, as itprac
tically never appears in English. This process was checkedforcorrelation betweenfitness
valueand correctness ofchromosome, toimproveconfidencein GENALYST. GENALYST
selectsthefittestchromosomesusinga roulette wheel approachbasedon normalizedfitness
values. This means that the probability of a chromosomegetting selected is proportional
to its normalized fitness value.
"Elitism"
is present to ensure that the fittestor most elite
chromosomesfoundsofarare alwaysincluded inthebreedingpool. Afterselectionoccurs,
breeding is done with a proportion of theremaining chromosomes. The proportion used decreases linearly as the search continues, in order to help optimize the effectiveness of GENALYST. Breeding is done usingtheposition based crossover method fororder-based
genetic algorithms. In this method, a randombit string ofthe samelength as the chromo
somesis used. The randombit string indicateswhich elements to takefrom parent#1 bya
1 inthe string, andtheelementsomitted fromparent#1 are addedintheorderthey appear
inparent#2. The second childisproducedbytakingelements fromparent#2 indicatedby
a0 inthe string, andfilling in fromparent#1 asbefore. Twopossible mutation types may
then be applied. The firsttype isa simpletwo-point mutation wheretworandom chromo
some elements are swapped. The secondtypeis ashufflemutation, wherethepermutation
A testprocedure isgiven toensurethat test textshave atrue fitness value thatis repre
sentativeofEnglish text. This is calculated mathematically, based on digram/trigram per
centagefrequency in thetext,the fitnessscore givenby GENALYSTto thatdi- ortri-gram,
andthe summation over all di-and tri-gramschecked. The textlength is also important, as
it is easierto attacktexts with a lengththatis an integermultiple ofthekey length. Based
ontheseconsiderations,atesttextwith alengthof 181 characters was selected. This length
isprime, butclose tomultiples of6, 9, 10, and 12. This is a worst-case scenario since not
all column lengths arethe same, and multiple possibilities forthe key length are present.
A MonteCarlo search is run on the same text so that the genetic algorithm results can be
compared to the results from a traditional search technique. In a Monte Carlo search, a
series ofguesses is made to determine the correct key, and the most elite chromosome is
kept.
Thebreaking ofatranspositioncipherhastwoparts: findingthecorrectkeylength, and
finding thecorrect permutation ofthe key. GENALYSTwas tested on both parts. Forthe
first part, the test text was encrypted using a target key. GENALYST was then used to
find the best decryption ofthe text, using seven different keylengths in the range of 6 to
12, which includes the length of the targetkey. Thegoal of this section was tosee ifthe
fittestoftheseven chromosomeshadthesame lengthasthe targetkey. Thepopulation size
used was 20, and the number ofgenerations was 25. The probability ofcrossover started
at0.8 anddecreasedto0.5. Mutation probability started at0.1 for bothpoint mutation and
shufflemutation, increasingto 0.5 forpoint mutation and to 0.8 forshuffle mutation. The
experiment was runfivetimeseach forthree targetkeylengths, K = 7,
9,11. GENALYST
was successful in 13 ofthe 15 runs (87%). However, the random Monte Carlo algorithm
performed equally well in this task, alsoproducinga success rate of87%. Forthesecond
part, the sameparameters of population size and number ofgenerations were used. GEN
ALYSTmanaged tocompletely break thecipherin one ofthe runsfor K = 7 and one of
the runs for K = 9.
Overall, GENALYST involves little more computational effort than
Therefore, a genetic algorithm approach is useful even when only a small advantage is
produced. Using alarger gene pool and number of generationsboosts GENALYST's per
formance significantly overtheperformance ofMonte Carlo. Thegreatest improvementin
GENALYST's performance comesfrom hybridizing the algorithm with other techniques,
such as perming.
4.2.1 Comments
Overall, this is one ofthe best reference papers available. It is an early work, but is very
complete. Itcovers background material and problem considerations well, and has a very
balanced approachtoconsideringthegenetic algorithm as apossible solution. Theparam
eters are clearly reported, as are the algorithms used. This is an excellent candidate for
re-implementation andcomparison.
Typicalresults:
-Keylength correctly determined 87%ofthe time
- Correct
keyfound 13.33%ofthe time
Re-implementationapproach:
- Differenttextlengths
used, sameparameters re-used
- Additional parameters are usedtoexpandthe
range ofparameter values
Observedcryptanalytic usefulness:
- Low- low decryption
percentage
Commentonresultdiscrepancy:
-Percentages reported are based on number of tests and different numbers of
4.3
Merkle-Hellman
Knapsack: Spillman -1993
The third paper published in 1993, by R. Spillman [25], applies a genetic algorithm ap
proach to aMerkle-Hellman knapsack system. This paperconsiders thegenetic algorithm
assimply anotherpossibility forthecryptanalysis ofknapsackciphers. Aknapsackcipher
is basedon theNP-complete problem ofknapsack packing, which is an application ofthe
subset sumproblem. Theproblem statement is: "Given n objects each with aknown vol
ume and aknapsack offixed volume, is there a subset ofthe n objects which exactly fills
theknapsack ?". The idea behind the knapsack cipheris that findingthe sum is hard, and
this fact can be used toprotect an encoding ofinformation. There must also be a decod
ingalgorithmthatis relatively easy for theintended recipientto apply. Aneasy decoding
algorithm can be made by using the easy knapsacks. An easy knapsackconsists of a se
quence of numbersthat issuperincreasing, i.e., each numberis greaterthan the sum ofthe
previous numbers. However, aneasy knapsack does not protectthe data ifthe elements of
the knapsack areknown. A Merkle-Hellman knapsack system converts an easy knapsack
into a trapdoorknapsack. A trapdoor knapsack is not superincreasing, making it harder
toattack. The Merkle-Hellmanprocedure tocreate atrapdoorknapsacksequence A is as
follows:
1. Givena simpleknapsacksequence A'
=
(a\, . . .
,a'n)
2. Selectan integeru > 2a'n
3. Selectanotherintegerw such thatgcd(u,w) 1
4. Find theinverseof w mod u
5. Constructthe trapdoorsequence A =
wA'
mod u
Once the easy knapsack has been converted into a trapdoor knapsack, both the easy
knapsack andthevalue ofw~l
must be known to decodethe data. Thetarget sum forthe
w_1
togetherand thenreducing it modulo u. This system canbecomeapublic-keycipher,
with the trapdoorsequencethe public key. The private key would be the superincreasing
sequenceandthevalues ofu, w, andw"1.
Thenext section ofthepaperintroducesgenetic algorithmsusingbinarychromosomes.
The applicable processes ofselection, mating, and mutation are described. Selection is a
random process which is biased so thatthe chromosomes with higher fitness values are
more likely to be selected. The matingprocess is a simple crossover operation, i.e., bits
s + 1 to rof parent#1 are swapped withbits s + 1 tor of parent#2. Mutationconsists of
switchingabit inthechromosometoitscomplement,i.e., a0 becomesa 1.
Thethree systemsthatneedto be defined fora genetic algorithm application are: rep
resentation scheme, matingprocess, and mutation process. The representation used here
isthatofbinary chromosomes,which representthesummation termsoftheknapsack, i.e.,
a 1 in the chromosome indicates that that term should be included when calculating the
knapsack sum. The evaluation function is determined once a representation scheme has
been selected. Here, thefunction measures howclose a given sum ofterms isto the target
sum oftheknapsack. Otherpropertiesincluded forthisexperiment are:
Function rangebetween 0and 1, with 1 indicating an exact match
Chromosomesthatproduceasum greaterthan the targetshouldhavealowerfitness,
ingeneral, than those thatproduce a sumlessthan the target
It shouldbe difficulttoproduce ahigh fitnessvalue
Theactualevaluationfunctionuseddependsontherelationship betweenthe target sum
andthechromosome sum.The function isdeterminedasfollows:
1. Calculatethe maximum differencethatcould occurbetween achromosome andthe
targetsum
MaxDiff =
m&x(Target,FullSum
-Target) (4.3.1)
2. Determinethe Sumofthecurrent chromosome
3. IfSum < Targetthen
Fitness= 1 \J\Sum Target\/Target (4.3.2)
4. IfSum > Target then
Fitness = 1 - {/\Sum
-Target]/MaxDiff (4.3.3)
As described above, the mating process is simple crossover. The mutation process
consists ofthree different possibilities. Abouthalfthe time, bitsare randomly mutated as
described above (switched to theircomplement). Next most likely is the swapping of a
bitwith a neighboring bit. The final possibility is a reversal ofthe bit order between two
points.
A description of the complete algorithm is given, as well as results for one 15-item
knapsack appliedto a5 charactertext. The charactersare encoded as 8 bit ASCIIcharac
ters. Eachofthe5 sums (onepercharacter) wasattacked usingthegenetic algorithm,with
an initial populationof20random 15-bitbinarystrings.
4.3.1 Comments
Thispaperisreasonablefor its length (about 10pages) and year. Aminimallevelofexperi
mentationis included buttheresultsandparameters aredecentlyreported. Theintroductory
material anddiscussion are reasonable, although short. Re-implementationshould not be
difficult, andtherearesufficient resultstomakea comparison possible. Overall,thispaper
isareasonable choiceforre-implementationandcomparison.
Typical results:
- Used 5 ASCII
characters,each ofwhich wasdecrypted
-Notre-implemented
Observedcryptanalyticusefulness:
- None
-theknapsacksize istrivial
Commenton resultdiscrepancy:
- No
comment, notre-implemented
4.4
Substitution/Permutation:
Clark - 1994The only paper published in 1994, by AndrewClark [4], includes the genetic algorithm as
one ofthreeoptimizationalgorithmsappliedtocryptanalysis. Theothertwoalgorithms are
tabusearch and simulatedannealing. Thefirstsection ofthepaperdescribesthe twociphers
used
-simple substitution and permutation. Next, suitabilityassessmentis discussed. This
section is wherethe fitness functionsaredeveloped. Forthesubstitutioncipher, the fitness
function is
Fk =
(a|SF[t]
-DF[t\\+P^2J^\SDF[i\[i)
-DDF[t\\j]\) (4-4.1)
A denotes the set of characters in the alphabet (A, B,C,...,Z,space). SF[i] is the
relative frequency of characteri in English, while DF[i] is the relative frequency ofthe
decoded characteri in the message decrypted usingthekey k k. SDF[i\[j] is the relative
frequency ofthe digram ij in English, while DDF[i][j] is the relative frequency of that
digram in the message decrypted using k. Varying a and /?allows one tofavor eitherthe
unigram or digram frequencies. For the permutation cipher, the same approach was used
as in [20]
-the scoring tablefor digrams andtrigrams.
The next three sections introduce the basic concepts of simulated annealing, genetic
algorithms, and tabu search. The genetic algorithm section is fairly standard, and con
specifics aboutthealgorithm used. The final sectionin thepaperdiscusses theresults. It is
fairly short, anddoes not givemany details.
4.4.1 Comments
Overall, thispaper is too short (5 pages) tobe useful. It is well written, but lacks details.
Thetinygeneticalgorithm section andfewreported resultsmake it difficulttore-implement
or even tocompare against. This paperis nota good candidatefor furtheruse.
Typicalresults:
- Convergence
ratesandcomputation timearethe only reported results
Re-implementationapproach:
- Parameterswere not reported
- Standard
parameter values usedin other re-implementations were used
-Only the permutation attack was re-implemented as alater workfromthis au
thorwas usedforthe substitution attack
Observedcryptanalytic usefulness:
- Medium- the
correctkey wasfoundwith ahigh successrate
Comment on resultdiscrepancy:
- Noreal discrepancy, differentcombination of metrics used
4.5 Vernam:
Lin,
Kao
- 1995This is the only paperpublished in 1995. By Feng-Tse Lin and Cheng-Yan Kao, [18] is a
ciphertext-only attack on aVernamcipher. Thepaperbegins by introducing cryptography
itself. The Vernam cipher is a one-time pad style system. Let M =
m\,m2, ...
,mn
denote a plaintextbit stream andK =
ky, k2, . . .
,kr akey bitstream. The Vernamcipher
generates a ciphertext bit stream C =
Ek(M) =
cuc2, ,cn, where a
= (m{ +
ki)
modp andp is a base. Since this is a one-key (symmetric orprivate-key) cryptosystem,
the decryption formula has the same key bit stream K, only M Dk(C) =
my, m2, . . .,
wherem{ = (ct
kt)mod p. Theproposed approachistodetermineK fromanintercepted
ciphertext C, anduseitto break thecipher.
Sincethedescribedcryptosystemis nottheVernam cipher,andtherearemanyerrorsin
this paper,both in notation and logic, this applicationneeds nofurtherdiscussion. The ge
neticalgorithm approach is rendered invalidby theerrors presentin thereported approach
and assumptions.
4.5.1 Comments
This paper is of below average quality. It is rather short, and was written forthe IEEE
International Conference on Systems, Man, and Cybernetics. There are some problems
with Englishgrammar,possibly dueto translationfromthe originallanguage. Thesystems
are adequately described, but are, however incorrect. The cipher given inthispaper is not
<