Exploring the Effects of Language Skills on Multilingual Web Search.
Full text
Figure

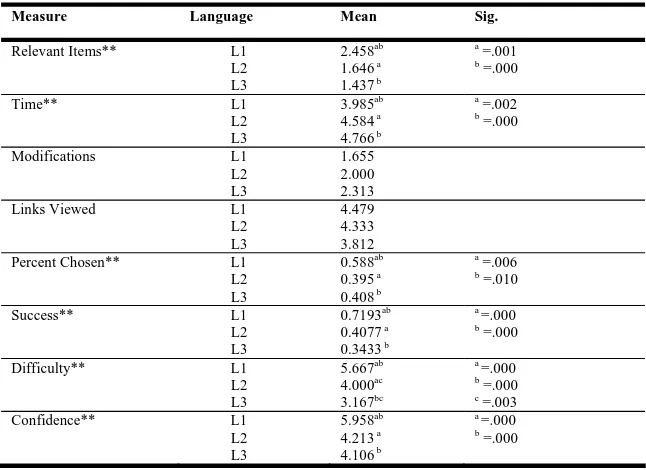

Related documents
In the study that involved 518 pupils in a primary school in Singapore, where the relationships between weight-for- height classifications, body weight satisfaction,
National Institute of Statistics (ISTAT), involving representatives from stakeholder organizations and external scientific experts as well. The project, launched in
The purpose of this empirical study was to investigate whether financial risk-tolerance differs among business graduates in Pakistan based on their demographic factors (i.e.,
The research examines the growth in the supply of traditional tourist accommodation, through controversial projects which have led to the emergence of social movements against
Those plan members contributed on salary up to the maximum in place each year, but their current pension benefit is being capped by pension benefit maximums in effect since 1992..
Thus, although numbers are very small, and no great value can be attached to these findings, findings from various measures all provided consistent support for the research
Keywords: theories of religion; worldview; meaning; spiritual (faith) development; religious
5: Different Stage output image in Zigzag collarette boundary localization; (a) Cropped eye image, (b) Image after histogram equalization,(c) Image after 2-D DFT and FFT Shift,
