Rochester Institute of Technology
RIT Scholar Works
Theses
Thesis/Dissertation Collections
1988
Dataflow: Overview and simulation
Steven I. Benjamin
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion
in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact
Recommended Citation
School of Computer Science and Technology
DATAFLOW: Overview and Simulation
by
Steven
I.
Benjamin
A thesis submitted to
The Faculty of the School of Computer Science and Technology,
in partial fulfillment of the requirements for the degree of
Master of Science in Computer Science.
Dr. Lawrence Coon
Approved by:
Approved by:
_D_r_.A_n_d_re_w_K_itc_h_e_n
ghs-/~ ~
~
3hS-/~
,
;
Date
Approved by:
Dr. Peter Lutz
Dataflow: Overview and Simulation
I
§3~venl:
Benjamin
hereby grant permission to the Wallace Memorial
Library, of RIT, to reproduce my thesis in whole or in part. Any
The
thesis
projectis
a software simulation ofthe
dataflow
machine prototyped atthe
University
ofManchester.
It
uses adynamic
token
matching
schemebased
onthe
U-interpreter,
and supportsI-structures,
an array-likedata
structure.An
assembly
language is
providedfor
programming
the
Table
of
Contents
1
Introduction
1
1.1
Data Flow
vs.Control Flow
2
1.2
Previous Work
2
1.2.1
Dennis
Machine
atMIT
4
1.2.2
Arvind Machine
atMIT
4
1.2.3
Manchester Machine
7
1.2.4
Utah DDM1 Machine
7
1.2.5
Toulouse LAU Machine
10
1.2.6
EDDY Machine
13
1.2.7
Other Projects
13
2
Project
Description
15
2.1 Functional Specification
16
2.1.1 Program Representation
16
2.1.2
Data
Representation
18
2.1.3 Structure Representation
18
2.1.4 Machine Organization
19
2.1.5 Instruction
Set
19
3
Project
Implementation
26
3.1 Assemble Instruction Process
28
3.2
Read Data Process
29
3.2.1 Token Implementation
29
3.5
Execute Operation Packet
Process
34
3.5.1
I-Structure Implementation
35
3.6
Monitors
andProcess Synchronization
37
4 Project
Application
40
4.1
Data Flow Graphs
40
4.1.1
Sequence Construct
41
4.1.2
Decision Construct
41
4.1.3
Repetition Construct
43
4.1.4
Subprograms
44
4.1.5
I-structures
46
4.2 Assembler
Language
48
4.2.1
Operator Instructions
53
4.2.2
Predicate
Instructions
54
4.2.3
Boolean
Instructions
55
4.2.4
Branch
Instructions
55
4.2.5
Loop
Instructions
56
4.2.6 Procedure Instructions
57
4.2.7 I-structure Instructions
58
4.2.8 Output Instructions
58
4.2.9 Comment
andConstant
Instructions
59
4.3
Input File
59
4.4
Debugging
61
4.5 Sample Programs
63
IV
4.5.2 Recursive Factorial Example
70
4.5.3
Fibbonaci Series
Example
73
4.5.4
Trapezoid Rule Example
77
4.5.5
I-Structure Example
81
4.5.6
Laplace Transform Example
85
4.6
Running
the
Simulator
94
4.7
Errors
95
5
Conclusion
96
Figure 1.
Data Flow
vs.Control
Flow
3
Figure
2. Data
Flow
History
5
Figure
3.
MIT Dennis Machine
6
Figure
4.
MIT Arvind
Machine
8
Figure
S.
Manchester Machine
9
Figure
6.
Utah DDM1 Machine
11
Figure
7.
Toulouse Machine
12
Figure
8.
EDDY Machine
14
Figure
9.
Trapezoid Rule Compilation
17
Figure
10.
Machine Organization
20
Figure
11.
System Process Diagram
27
Figure
12.
The
config File
28
Figure
18.
The
commandTableFile
30
Figure
14. Instruction
Store Data
Structure
31
Figure
15. Token
Data
Structure
32
Figure
16.
Token
Store Data Structure
33
Figure
17.
Operation
Packet
Data Structure
34
Figure
18. Instruction
Set
Summary
35
Figure 19.
I-structure
Store Data Structure
36
Figure
20. Dataflow
Graph
Sequence
Construct
41
Figure
21. Dataflow Graph
Decision
Construct
42
VI
Figure
23.
Dataflow Graph Subprogram
45
Figure
24.
Dataflow Graph I-structure
47
Figure
25.
Assembler
Command
Summary
48
Figure
26.
Assembler Syntax
Summary
50
Figure
27.
Dataflow Graph
andAssembler Program
52
This
sectionis
anintroduction
to
data flow
computers.Data flow
and controlflow
computersarecompared.
A
review ofdata flow
computer projectsis
given.There
aretwo
general approachesto
making
faster
computer systems.The first
approachis
to
use
technology
to
makeexisting
computer architecturesfaster.
The
second approachis
to
design
new,
faster
architectures.The
prevalentexisting
architecture wasdeveloped
by
vonNeuman
and others overthirty
years
ago,
it
solvedmany
engineering
andprogramming
problemsthat
existed atthat time.
In its
simplest
form
the
vonNeuman
computer consists ofthree
parts: aCPU (central
processing
unit),
amemory unit,
and a "tube"that transmits
data between
the two
units.This
tube
has
been
calledthe
"von Neuman
bottleneck"by
John Backus
[Backus
1978].
The
vonNeuman bottleneck is both
physical and conceptual.It is
physicalin
that
all changesto the
memory
unit canonly
be
madeby
passing
data
one word at atime through the
connecting
tube.
The
bottleneck
is
conceptualin
that
most conventionalprogramming
languages
have
evolvedto
be
high level
versions ofthe
vonNeuman
computer.This inhibits
the
natural expression of agiven
problem,
instead
a problemis
expressedin
terms
ofthe
underlying
machine architecture.The
goal ofmany
computer architectsis
to
reducethe
vonNeuman bottleneck.
The
mostcommon approach
is
to
develop
machines with several vonNeuman
processors,
thus
providing
several
connecting
tubes,
increasing
the
amount ofdata
that
canbe
passedbetween
the
CPU
andmemory
at onetime.
Other
architects areeliminating
the
vonNeuman bottleneck
altogether.They
aredoing
soby
designing
machinesbased
uponmodels ofcomputationthat
are altogetherdifferent from
that
ofthe
1.1. Data Flow
vs.Control Flow
One
novel architecture understudy
is
that
ofthe
Data Flow
machine.The data flow
machinearchitecture
is based
uponthe
data flow
model of computation.The data
flow
modelis
not a newidea, however,
technology
has
only recently
madeit
possibleto
consider computer architecturesbased
uponthis
model.The difference between
the
vonNeuman,
or"control
flow"model and
the
data flow
model,
lies in
what controlsthe
process of computation withinthe
individual
models:[Miklosko,
Kotov
1984]
Control Flow
(CF)
-it is
the
sequence ofinstructions.
Data Flow
(DF)
-it
is
the
availability
ofdata.
A CF
model programis
storedin memory
as a serial sequence ofinstructions.
Each
instruc
tion
is
fetched
from
memory
andthen
executedin
the
processor(the
vonNeuman
bottleneck).
No
instruction
can execute until all previousinstructions
have
executed.Thus,
the
processofcomputation
is
controlledby
the
sequence ofinstructions
in
the
program.This is
the
main obstaclein
exploiting the
naturalparallelism of algorithms.In
the
DF
computer,
computationis
controlledby
the
flow
ofdata
in
the
program.An
instruction
can executeonly
when allits
operands are available.Whether
aninstruction
precedesanother
depends
uponthe
algorithm and not uponthe
location
ofthe
instructions
in
memory.Using
this
method ofcomputation,
it
is
possibleto
execute asmany
instructions in
parallel asthe
given computer can
simultaneously
handle.
Refer
to
figure
1
for
anillustration
ofthe
difference between
CF
andDF
computation.1.2.
Previous
Work
The
originators of research ondata
driven
computing
can notbe
precisely
defined.
In
1968,
Jack
Dennis defined
graphsto
express algorithmsby
showing
data
dependencies
only;
Tesler
and[Ackerman
1982]
CONTROL FLOW
Sequence
of
Instructions
1.P
=X
+
Y
2.
Q
=P
/
Y
3. R
= X*P
4.
S
=R
-Q
5. T
=R
*P
6.RSLT
=S / T
Computation
Sequence
1
2
3
4
5
6
DATA FLOW
Graph
showing
data
dependencies
X
X
Y
1.P=X
+
Y
3. R
= X*P
R
,r
A^
4.
S
=R
-Q
Computation
Sequence
1
2
and
3
4
and
5
6
=
P/Y
5. T
=R
*P
[image:12.529.35.416.219.687.2]embody
the
syntactic and semanticfeatures for data flow
programming).Single
assignment wasdeveloped
by
Klinkhamer
andChamberlin in
1971,
anddata flow
graphs weredeveloped
atMIT
by
Misunas,
Rumbaugh
andKosinski.
Figure
2
shows some ofthe
data
flow
research carriedout since1968
[Evans
1982].
Following
is
asurvey
of some currentdata flow
projects.1.2.1.
Dennis Machine
atMIT
Development is
taking
place atMIT
by
Dennis
andMisunas.
Project
goals statedby
Dennis,
Second Data Flow
Workshop
[Misunas
1979]:
1.
Develop
userlevel
programming
language.
2.
Build
anengineering
model.3.
Address
translation,
optimization,
and code generation.4.
Develop
specificationsfor full-scale
machine.Current
project status[Hwang
andBriggs
1984]:
1.
Prototype
hardware is
under construction.2.
Compiler is
being
writtenfor VAL
programming
language.
3.
Fault
tolerance
studies arebeing
made.Figure
3 describes
the
Dennis
machine architecture.1.2.2.
Arvind Machine
atMIT
Development
wasbegun
atthe
University
ofCalifornia,
Irvine
andis
continuing
atMIT.
It is
being
directed
by
Arvind
andGostelow.
Project
goals statedby Gostelow,
Second Data Flow
Workshop
[Misunas
1979]:
1.
Design
general-purpose computercomposedofmany
smallprocessors.
2. Remove bottlenecks
from
the
architecture.3.
Develop
prototypebased
onID
programming
language.
4. Investigate fault
tolerance.
Current
project status[Hwang,
Briggs 1984]:
1.
ID
programming
language
has been developed.
2.
The
machinehas
not yetbeen
built.
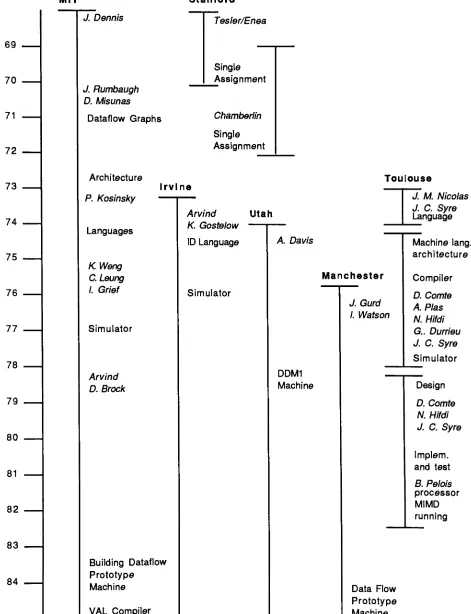
MIT
Stanford
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
J. Dennis
Tesler/Enea
J. Rumbaugh
D. Misunas
Dataflow Graphs
Single
Assignment
Architecture
P.
Kosinsky
Languages
HLWeng
C.
Leung
I. Grief
Simulator
Arvind
D. Brock
Chamberlin
Single
Assignment
Irvine
Toulouse
Building
Dataflow
Prototype
Machine
VAL
Compiler
Arvind
K. Gostelow
ID Language
Simulator
Utah
A
Davis
Manchester
DDM1
Machine
J. Gurd
I. Watson
Data Flow
Prototype
Machine
J. M. Nicolas
J. C. Syre
Language
Machine lang.
architectureCompiler
D. Comte
A. Plas
N. Hifdi
G.. Durrieu
J. C. Syre
Simulator
Design
D. Comte
N. Hifdi
J. C. Syre
[image:14.529.28.499.67.681.2]Figure
3.
MIT
Dennis Machine
[Misunas
1978]
[Dennis.Boughton,
Leung 1980]
Processing
Section
Processor
Processor
T
/
Control
Network
\
<en controlto
'F
fe.Distribution
Network
H
FInstruction Cell
Arbitration
Network
fe
fe,wInstruction Cell
Memory
Section
Static Execution Rule:
instruction
is
enabled
(can be executed)
if
a
data
token
is
present on
allits input
arcs and
no
token
is
present on
its
output arcs
Data Token
Control Token
Operation Packet
Memory
Section
Processing
Section
Arbitration
Network
Control
Network
Distribution
Network
-data
traveling
to the
input
arc
ofan
instruction.
-acknowledge signal
indicating
that
data
has been
removed
from
an
instruction's
output arc.
-
enabled
instruction
and operands
ready
to
be
processed.
-
instruction
cells
whichhold
instructions
and
their
operands.
-processing
units
that
perform
functional
operations
ondata
tokens.
-
delivers
operationpackets
from memory
section
to processing
section.
-
delivers
controltokens
from processing
section
to memory
section.
[image:15.529.54.452.90.321.2]Figure 4 describes
the
Arvind
machine architecture.1.2.J.
Manchester Machine
Development is
taking
place atManchester,
England.
It is
being
directed
by
Gurd, Watson,
and
Kirkham.
Project
goals statedby Watson,
Second Data Flow
Workshop
[Misunas
1979]:
1.
Major
motivationis
the
exploitation of parallelismto
develop
high
speed machine.2.
Secondary
motivationis
realization of cost effective and reliabledesign.
Current
project status[Gurd,
Kirkham,
Watson
1985]:
1.
A
data flow
machinehas been
constructedlarge
enoughto tackle
realistic applications.2.
A
small range ofbenchmark
programshas been
written and executed.3.
Preliminary
evaluationresults are asfollows:
a. a widevariety
of programs containsufficientparallelism
to
exhibitspeedup.b.
a usefulindicator
ofprogramparallelismhas
been
established.c. aweakness
in
the
present pipelineimplementation
has been
identified
andfixed.
d.
the
needfor
a separate structurestoragehas been
indicated.
4.
Future
studies:a.
build
and evaluate amulti-ring
architecture.b.
investigate
programsthat
cause match-unitoverflow.
c.
study
low-level
code optimization.d.
study
data
flow implementation using
VLSI
technology.
e.
improve
machineto
exceed performanceofVAX
11/780
mini-computer.Figure
5 describes
the
Manchester
machine architecture.1.2.4.
Utah
DDM1 Machine
Development
wasbegun
atBurroughs.
It is
currently
based
atUtah University.
Davis is
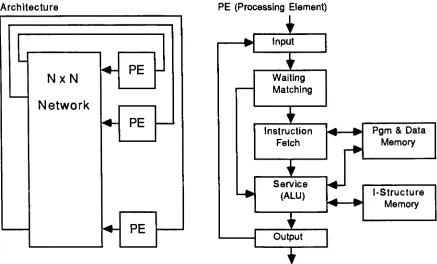
Figure 4. MIT Arvind Machine
[Arvind.Kathail
1981]
[Arvind.Gostelow
1977]
Architecture
NxN
Network
PE
PE
(Processing Element)
PE
Input
T
Waiting
Matching
T
Instruction
Fetch
V
Service
(ALU)
T
Output
Pgm
&
Data
Memory
l-Structure
Memory
T
The Arvind
machine
does
not
follow
the
static execution rule as
does
the
Dennis
Machine (see figure
3).
It instead
allows several
tokens to
be
present on
the
input
and
output arcs
that
lead into
and out
of aninstruction.
In
this way
several
instantiations
of
the
same
instruction
(provided
there
are no
data
constraints)
can execute concurrently.
The
architecture of
the
Arvind
machine
is
said
to
be dynamic.
Input Section
Accepts
tokens
from
eitherthe
communicationsystem orthe
output section
ofits
same
PE.
Waiting-Matching
Section
Input
tokens
whose
destination activity
requires
two
operands are sent
to
this
section
and are
buffered
untilthey
can
be
matched.
When
matched, the
token
set
is
then
sent
to
the instruction-fetch
section.Instruction-Fetch Section
Combines
an
instruction's
opcode
withits
operands,
and
sends
the
resulting
operation
packet
to
the
service section.
Service Section
Processes
the
operation
packet;
sends
the
resulting data
token to the
output section.
I-Structure
Memory
Stores
l-structure
tokens.
I-Structures
are an
array-like
data
structure
[Arvind,Thomas1980].
Output Section
[Gurd.Kirkham,
Watson
1985]
[Gurd.Watson
1977]
[Watson.Gurd
1979]
[Watson,
Gurd
1982]
token
packets
J
r
to
h
i
osti
Token
Queue
token
packetsI
r
i
Matching
Unit
Overflow
Unit
I/O Switch
i i ii
token-pair
j^
y
packets
Instruction
Store
executa packetsble
I
Processing
Unit
frorri
nusitoken
p<acketsThe Manchester
machine
is
a
dynamic dataflow
machine,
as
is
the
MIT Arvind
machine
(see
figure
4).
I/O Switch
Token Queue
Matching
Unit
Instruction
Store
Processing
Unit
-
loads
programs and
data
from
host;
permits
results
to
be
output
for
external
inspection.
-smooths out uneven rates of generation and
consumption
of
tokens in
the
ring.
-pairs
together
tokens
destined for
the
same
activity.
-contains
machine code of
dataflow
program.
[image:18.529.59.420.86.360.2]
10
1.
Develop
a recursivemachine architecture.a. performance gain
is
made as machineis
physically
extended.b.
no needfor
electronictuning
ashardware
modules are added.
2.
Develop
ahigh-level data-driven
graphicallanguage
[Davis,
Lowder
1981].
Current
project status[Treleaven,
Brownbridge
,Hopkins1982]:
1.
DDM1 became
operationalin
1976
(first
in
the
USA).
The DDM1
communicates with aDEC
20/40.
The DEC
systemis
usedfor
compilation,
input,
output,
and performance measurement.2.
The language is
currently
a statementdescription
of adirected
graph.An interactive
graphicalprogramming
language is
underdevelopment.
Figure
6 describes
the
DDM1
machine architecture.1.2.5.
Toulouse
LAU Machine
Development is
taking
placein
Toulouse,
France
by
Plas, Comte,
Syre,
Hifdi.
Project
goalsstated
by
Comte,
Second Data
Flow
Workshop
[Misunas
1979]:
1. Project
wasinspired
by
Tesler
andEnea
paper onsingleassignment.
2.
Design
a single assignmenthigh level language:
a.
that
is
easy
to
useby
non-specialists.b.
that naturally
exploits parallelismin
algorithms.c.
that
is
readableanddebuggable.
3.
Develop
a machine architectureto
suitthe
singleassignment
language.
Current
project status[Treleaven,
Brownbridge
,Hopkins1982]:
1.
The
first
of32
processorsbecame
operationalin
1979.
2.
The
remaining
processorshave
been
constructed since.[Davis
1979]
[Davis
1978]
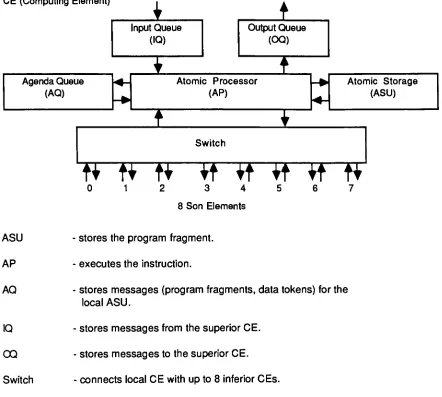
CE
(Computing
Element)
i
?
Input Queue
(IQ)
Output Queue
(CO)
T
t
Agenda Queue
(AQ)
Atomic Processor
(AP)
Atomic Storage
(ASU)
t
1
Switch
0
1
t
n
it
vt
2
3
4
8 Son
Elements
vf
'
5
6
ft
7
ASU
-stores
the
program
fragment.
AP
-executes
the instruction.
AQ
-stores messages
(program
fragments,
data
tokens)
for
the
local ASU.
IQ
-stores messages
from
the
superior
CE.
CQ
-stores
messages
to
the
superiorCE.
Switch
-connects
local CE
withup to
8
inferior
CEs.
Work in
the
form
of
a
programfragment is
allocated
to
a
computing
element
by
its
superior
via
the IQ.
If
the
fragment
contains subprogramsand
the
CE
has
sons, then
it
willdecompose
the
fragment
and
allocatethe
subprogramsto
its
inferior
elements.Otherwise
the
fragment
is
stored
in
the
local
ASU.
[image:20.529.46.488.79.476.2]Figure
7. Toulouse Machine
[Comte.Hifdi.Syre
1980]
[Syre,Comte,Hifdi
1977]
[Plas.etal
1976]
I
Input Queue
1
Control
Unit
instructions
ready
Memory
Unit
updatecO
d
c2w
instructions
I
t
t
ijpdate cd1
Processing
Unit
P0
..P31
read operand
read cd write operand
writ*i
descripto
Memory
Control I
Process
Input Qu
Uni
J
nit
ng
I
eue
[
Jnit
-stores
instructions
and
data.
-maintains
the
control
memory (CO C1 C2).
-consists of
32 identical
processing
elements.
-pool
of workfor the
memory
unit.The LAU
programming
language is based
on single assignment
rules,
but
the
computer's
program organization
is based
on controlflow
concepts.
In
the computer,
data
is
passed via
sharable
memory
cells
that
are accessed
through
addresses embedded
in instructions.
Separate
controlsignals are used
to
enable
instructions.
However,
as
in
data
flow,
the
flow
of
controlis
tied to the
flow
of
data.
Each
instruction
has
three
controlbits
that
denote its
state.
C1
and
C2 define
whether
the
two input
operands are
present.CO
provides environment control
(for
example,
instructions
within
loops). Cd is
associated
witheach
data
operand and
indicates
if the
operand
is
available.
Two
processors scan
the
control memory:the
update processor
sets
the
CO C1 C2
bits,
and
[image:21.529.46.485.74.257.2]1.2.6.
EDDY Machine
In
Japan,
development
ofthe
EDDY
(Experimental
systemfor Data-Driven Processor arraY)
is
taking
place.Current
project status[Hwang,
Briggs
1984]:
1.
Prototype has been
built.
2.
Compiler for
the
VALID
programming
language has been
developed.
3.
Statistical
data has been
collected:a. operation rates of
function
units.b.
average queuelengths.
4.
This data
willbe
usedto
build
customhardware for
the
machine.
Figure
8
describes
the
EDDY
machine architecture.1.2.7.
Other Projects
As
of1985
the
only
operationalData Flow
machinesareDDM
atUtah,
EDDY
in
Japan,
the
Manchester
machinein
the
U.K.,
andthe
French LAU
machine.Some
other projects ofinterest
arethe
Texas
Instruments
Distributed
Data
Processor
[Treleaven,
Brownbridge,
Hopkins
1982].
It
wasbuilt
using
off-the-shelftechnology
and uses a crosscompiler
to translate
FORTRAN 66 into
directed
graph representation.The Newcastle data-control
flow
computerintegrates data flow
and controlflow
computation[Treleaven,
Brownbridge,
Hopkins
1982].
Sigmapl in Japan
[Shimada, Hiraki,
Nishida
1984]
willbe built
with256 processing
elementsFigure 8. EDDY Machine
[Hwang,
Briggs
1984]
Architecture
PE
(Processing
Element)
Host
Computer
Memory
Interface
[-? -?to
all16
PEs
Broadcast Control
V-/V-/VYVY
B
PE
PE
PE
PE-r
d
ocXX?
c
PE
PE
PE
PE-s
t
cXXX?
PE
PE
PE
PE-C
t
ocXX?
I
PE
PE
PE
PE
-/nrVurVnrvnr\
Instruc
Mem
Section
Opernd
Mem
Section
Opertn
Unit
Section
Comm
Unit
Section
TT
Broadcast Control
loads
or unloads programs and
data
to
or
from
all
PEs,
in
column or
row,
at
the
same
time.
Instruction
Memory
Section
fetches
an operand
token's instruction
and
sends
both
the
fetched
instruction
and
the
operand
data
to the
Operand
Memory
Section.
Operand
Memory
Section
for
two-operand
operations
the
memory is
searched
associatively for its
partner.
If
found,
the
packet
is
sent
to the
Operation
Unit
Section,
otherwise
it is
stored.
Operation
Unit
Section
executes
the
operation packet and sends
result
tokens
to
the
Communication Unit
Section.
2.
Project Description
This
sectiondescribes
the
data
flow
computerbeing
simulated.Program
representation,
data
representation,
structrurerepresentation,
machineorganization,
andthe
instruction
set aredetailed
in
this
section.This
thesis
projectis
an outgrowth of a previousthesis that
was submittedto
the
Rochester
Institute
ofTechnology.
The
previousthesis,
"Simulation
of aDataflow
Computer", by
Carol
M.
Torsone,
suggests waysto
improve its
implementation.
Euclid
was usedto
implement
the
originalsimulator, thus
limiting
the
use andtesting
ofthe
simulator
to
integers.
Torsone
concludedthat
many
"real
life"applications,
which wouldhave been
interesting
due
to their
high degree
ofconcurrency,
could notbe
programmedbecause
ofthis
limita
tion.
To
rectify
this,
Modula-2 is
usedto
implement
the
newsimulator,
it
supportsboth
integers
and
reals,
and provides coroutinesfor
concurrent programming.The
original simulatoronly
allowedfor
single-valued variablesto
be
used asdata
tokens,
which again
limited
the
applications ofthe
simulator.The
new simulatorsupports,
in
additionto
scalar
variables,
I-structures
[Arvind,
Thomas
1980],
which are array-likedata
structures.The
new simulatorfollows
moreclosely
the
U-interpreter
algorithm[Arvind,
Gostelow
1982]
for
tagging
data
tokens,
thus
allowing
nestedloops
to
be
programmed.Programs
to
be
run onthe
original simulatorhad
to
be
writtenusing
the
simulator's machinelanguage.
The
new simulator comes equipped with anassembler,
andis
programmedusing
anassembly
language
whichis
astatement representation ofthe
dataflow
graph.Other differences between
the two
simulatorsinclude
the
machineinstruction
format,
the
han
dling
ofconstants,
andthe
handling
ofinput
andoutput.Both
projects simulate adynamic
dataflow
machinebased
uponthe
machine organizationunder
development
atthe
University
ofManchester
[Gurd, Kirkham,
Watson
1985].
The
machine16
2.1. Functional
Specification
The
simulatoris based
uponthe
Manchester
machine architecture[Gurd,
Kirkham,
Watson
1985],
usesthe
token
tagging
scheme ofthe
U-interpreter
[Arvind,
Gostelow
1982],
has
anassembly
language based
on[Dennis
1975],
and supportsthe
I-structure data
structure[Arvind,
Thomas
1980].
2.1.1.
Program Representation
Dataflow
compilerstranslate
high-level
programsinto directed
graphs.Vertices
in
the
graphcorrespond
to
machineinstructions,
and edges correspondto the
data dependencies
which existbetween
the
instructions.
The implication is
that
instructions
whichdepend
on otherinstructions
shouldbe
sequencedaccordingly,
but
where nodependencies exist,
the
instructions
canbe
executedin
parallel.A
graphical
translation
is
shownin
figure
9,
it
was compiledfrom
the
following
high-level
program,
whichintegrates
afunction
f from
ato
b
over nintervals
ofsizeh
by
the trapezoid
rule:s=(f(a)+f(b))/2
x= a
+
h
for i
=1
to
n-1
s =s
+
f(x)
x=x+
h
end
for
s =s*h
In figure
9
the
box
markedf
representsthe
subgraph offunction f.
Instructions
D,
Dl,
L,
andLI
areincluded
to
provide properentry,
iteration,
and exitby
manipulating
context-identifying
information
(discussed in
the
next section).The
remainder ofthe
operators arearithmetic,
relaI
l
/
2
+hSW
T
F
SW
T
F
SW
T
F
1
+
h
<
[image:26.529.74.504.25.717.2]18
2.1.2. Data Representation
It is
the
processors's
task to
propagatedata
valuesthrough the
programgraph,
triggering
instructions
whenthe
operands are available.Data
values are carriedby
logical
entities calledtokens.
A
token
contains notonly
adata
valuebut
alsothe
address ofits
destination instruction.
Conceptually,
tokens
move about onthe
vertices ofthe
graph.Instructions
axe enabled whentokens
are present on all
input
edges.Program
execution consists of aninstruction absorbing its input
tokens,
andproducing
an outputtoken
for
the
nextinstruction in
the
graph.A
programterminates
when
there
are no enabledinstructions left.
In
adynamic
model,
morethan
onetoken
is
allowedto
be
present on anarc;
therefore,
the
next-instruction
label
also containsdynamic,
or context-sensitiveinformation
(called
the
tag).
These
next-instructionlabels
oractivity
names[Arvind,
Gostelow
1982]
containthree
parts:u:
The
contextfield,
whichuniquely
identifies
the
contextin
whichthe
instruction is
invoked.
The
contextfield is itself
anactivity
name.i:
The initiation
number,
whichidentifies
the
loop
iteration
in
whichthis
activity
occurs.The
field
is
1
outside aloop.
s:
The
instruction
address.Since
instructions
may
have
morethan
oneinput
operand,
anindex
value,
calledthe
port(p),
which specifies
the
operand number associated withthis
token,
is
also carried on eachtoken.
The
complete
token
looks like
this:
<u
i
sdata>p
2.1.8.
Structure Representation
Data
structure operations present a problemfor dataflow
machines.In functional languages
(the
language
ofdataflow),
adata
structureis
acted upon as a singleentity;
the
entiredata
structure
movesthrough the
programgraph,
and each structure operation resultsin
the
creation of a newbecause it is
not possibleto
operate on morethan
one structure element at onetime.
[Arvind,
Tho
mas
1980]
proposethe
I-structure
as anew array-likedata
structure,
which cansignificantly
reducestructure
overhead,
and providefor
highly
parallel structure creation and operation.I-structure
operations are
based
onthe
premisethat,
in
many circumstances,
full
generality
ofdata
structureoperations
is
notneeded;
hence
significant gains shouldbe
possibleby
substituting
restricteddata
structureoperations.
An I-structure is
an asynchronous structure with a constraint onits
construction.I-structure
producerscan
only
append a value onceto
a particular selector of anI-structure,
no other value canever
be
appendedto that
selectorin
that
particularI-structure.
The
definition
ofI-structure
producers
permitsindividual
appendsto
be done
out oforder,
thus
allowing
concurrent construction ofan
I-structure.
Because I-structures
areasynchronous,
values canbe
selectedfrom
anI-structure
before
the
I-structure is
complete.The
read-before-write problemis
handled
by
deferring
allreadrequests of an
empty
cell until afterthe
first
write operation.2.1.4.
Machine Organiiation
The
organizationis
based
onthe
Manchester
machine architecture.(See
figure
10).
2.1.5.
Instruction
Set
The
instruction
setis
taken
largely
from
[Dennis
1975]
in
whichhe defines
adata
flow
programas a
bipartite directed
graph wherethe two types
ofnodes are calledlinks
and actors.He
regardsthe
arcs of adata
flow
program as channelsthrough
whichtokens
flow carrying
valuesfrom
eachactor
to
other actorsby
way
ofthe
links.
The instruction
set proposedhere differs from
[Dennis
1975],
in
that
data is
permittedto travel
directly
from
one actorto
another actor.Links
are usedonly to
replicatetokens
with multipledestinations.
The
thesis
instruction
set alsoincludes
actorsnecessary
for
implementing
the
U-Interpreter
[Arvind,
Gostelow
1982],
andfor
implementing
Figure
10. Machine
Organization
INPUT TOKENS
DATA TOKENS
I
"
OUTPUT TOKFN5
MATCHING
UNIT
1
TOKEN SETS
DFPGM
UNIT
DF
PGM
INSTRUCTION
UNIT
i i
i
1
OPERATION PACKETS
Dl IT
PROCESSING
UNIT
I-STRUCTURE
STORE
TOKENS
RESULT TOKEIMS
OUTPUT TOKENS
10 Unit
Assembles
program
and
loads
machine
instructions into
the
instruction
store.
Sends input
tokens to
matching
unit.Sends
output
tokens
to
output
device.
Matching
Unit
Forms
token
set
based
on
activity
name.
Sends
token
set
to instruction
unitInstruction Unit
Forms
operationpacket
from
machine
instruction
opcode and
token
set.
Sends
operation
packet
to processing
unit.Processing
Unit
Sends
incoming
operationpacket
to
an
available processor.
Executes
operationpacket.
Sends
result
token
to the matching
unit.Sends
output
token
to the
10
unit.-Structure
Store
[image:29.529.44.492.59.351.2]LINK:
replicatesits
input
token
anddistributes
the
copiesto
its
outputdestinations.
LK
-T
+
i
OPERATOR
ACTOR:
appliesits
function
to
its
two
input
tokens
(one,
input
tokenfor
unary
functions)
and sendsthe
resultto
its
outputdestination.
T* *T"
f negation, sqrt. abs. -<-, -, /,
DECIDER
ACTOR:
appliesits
predicateto
its
input
tokens
and sendsthe
resulting
control
token
(true
orfalse)
to
its
outputdestination.
T* *T'
22
BOOLEAN
ACTOR:
appliesits
boolean
function
to
its
input
tokens
and sendsthe
resulting
controltoken
(true
orfalse)
to
its
outputdestination.
*t* *t*
b - and, or, not
-T-T-GATE CONTROL ACTOR:
passesits input
token
to
its
outputdestination if it
receivesthe
valuetrue
atits
controloperand;
the
data
operandis discarded if false is
received.-tru -false
F-GATE
CONTROL
ACTOR:
passesits
input
token
to
its
outputdestination
if
false
is
received,
discards
its
input
if
true
is
received.SWITCH
CONTROL
ACTOR:
allows a control valueto
determine
which oftwo
outputdestinations
its
input
shouldbe
passedto.
A
true
control value will causethe
input
data
to
be
routedto
the
T-destination;
afalse
value will causethe
data
to
be
routedto
the
F-destination.
T F T F T F
LOOP
ACTORS
(L, LI, D,
Dl):
manipulatecontext-sensitive
information
in
the
tokentag,
making it
possibleto
concurrently
execute severaliterations
of aloop.
The
L
actor adds new contextsto
the
token
tag
whenloops
areentered;
LI
removescontexts added
by
L
whenloops
are exited.The D
actor adds1
to
the
initiation
value;
Dl
resetsthe
initiation
valueto
1.
while
(p(x))
x =
f(x)
end while
L
D
?
Initial Token
|
x|
->|
1
s|
x =data
1
=iteration
s=
sending
addressAdd
new contextto
tag
|
x|
->|
1
c|
->|
1
s|
c=codeblock
Increment initiation
value1
:|
x|
->|
2
c|
->|
1
8|
n :
|
x|
->|
n+1 c|
->|
1
s|
Reset initiation
valueI
x|
->|
1
c|
->|
1
s|
Remove
context addedby
L
24
APPLY ACTORS
(A, PBEG, PEND,
Al):
operate on context-sensitiveinformation
in
the
token
tag,
making
it
possibleto
concurrently
execute severalinstantiations
of a procedure.The A instruction
adds a new contextto
the
token
tag
eachtime
a procedureis
invoked,
sendsits input
tokens
(procedure
arguments)
to
the
PBEG
instruction,
and sendsthe
Al
instruction
address(return
address)
to
the
PBEG
instruction.
The
PBEG
instruction
is
alwaysthe
first
instruction
of aprocedure,
it
collectsthe
procedure arguments and
distributes
them
to
the
statements ofthe
procedure,
and sendsthe
Al
address(return
address)
to
the
PEND
instruction.
The
PEND
instruction
is
alwaysthe
last
instrruction
of aprocedure,
it
collectsthe
procedure result
tokens
and sendsthem
to
the
Al
instruction.
The
Al
instruction
removesthe
context addedby
A
anddistributes
the
tokens
to
the
statements of
the
calling
procedure.args args +
A1
aI
I
A
PBEG
I
args
A1
addressI-STRUCTURE
ACTORS
(IREAD,
IWRITE):
manipulateI-structures.
xO
i
The IREAD
operation retrievesthe
data
value ofI-structure
xO at selectori.
xO
i
Ui
IWRITE
The IWRITE
operationappendsthe
value v
to
I-structure
xO at selectori.
It
also satisfies26
S.
Project Implementation
This
sectiondiscusses
the
simulatorimplementation.
It describes
the
inputs,
outputs, data
structures,
and algorithms ofthe
processesthat
constitutethe
system.It
endswith adiscussion
ofthe
monitors andprocess synchronization usedto
simulate parallelexecution.The
simulator was writtenin ModuLv2.
ModuLv2
was chosenbecause
it
supports realnumbers and provides coroutinesas avehicle
for
simulating
concurrentexecution.The
simulator will support a maximum offive hundred instructions
perprogram,
twenty
arguments per subroutine
call,
and onehundred i-structures
offifty
cells apiece.Any
ofthese
limits
may
be
changedby
modifying
the
DataFlowDecls.def file
andrecompiling
the
simulator.The
currentlimits
were chosento
achieve reasonable run-time performance.The
simulator operatesonly
on numericaldata
(with
the
exception of outputlabels).
Data
may
be
entered as eitherinteger
orreal; the
simulator converts all valuesto
real numbers.Control
values are represented
by
a1
for
true
and a0
for false.
The
simulator consists offive
functionally
different
processes(see
figure 11).
Build
token
setsimulates
the
matchunit,
build
operation packet simulatesthe
instruction
unit,
execute operationpacket simulates
the processor,
andthe
remaining
processes simulatethe
10
unit.The
simulatorbegins
by
executing
the
assembleinstruction
processto
convertthe
dataflow
assembler program
into
the
simulator's machine code.The
readdata
process readsthe
input file
and produces
input
tokens.
The
config
file
(see figure
12)
is
readto
determine
the
number of processors
that
areto
be
activatedfor
this
invocation;
a separate execute operation packet coroutineis
started
for
each active processor.Build
token
set andbuild
operation packet are started as coroutines
to
simulatethe
matchunit andinstruction unit,
respectively.Execution begins
whenthe
readdata
process producesinput
tokens.
Execution
ofthe
simulator
precedes asthe
token,
token set,
andoperation packet queues are produced and consumed.Exe
Assembler
Program
Instruction
Store
Token Set
Queue
Operation Packet
Queue
Token
Store
Token
Queue
[image:36.529.51.487.78.702.2]28
Figure
12.
The config file
20
2000000
2000000
2000000
20
is
the
number of processorsto
be
activated.2000000
is
the
working
set size ofthe
match unit coroutine.2000000
is
the
working
set size ofthe
instruction
unit coroutine.2000000
is
the
working
set size ofthe
processor coroutines.The
config
file
may
be
edited priorto
running
the
simulatorto
establishthe
number ofprocessors
that
areto
be
activatedduring
the
simulation.3.1.
Assemble
Instruction
Process
The
assembleinstruction
process readsthe
file
containing
the
dataflow
assembler
commands,
assemblesthe
commandsinto
the
simulator machinecode,
andstores
the
machine codein
the
instruction
storedata
structure.The
assembleinstruction
process also stores eachinstruction's
enable and constant countsin
the
token
store.The
simulatorinstruction
format
is
asfollows:
OP
EC DC CC
20{PORT}20 20{DEST}20
OP
EC DC CC
LABEL
20{PORT}
20{DEST}20
(OUTPUT
andDEBUG
instructions)
OP
Instruction
opcode.EC
Instruction
enable count.This
is
the
number of operands neededto
executethe
instruction.
DC
Instruction
destination
count.CC
Instruction
constant count.PORT Slots in
the
instruction
whereincoming
operands are stored.
These
slotsinclude
a constant presence
bit.
The CONST
assemblerdirective
storesthe
constant valuein
the
port,
setsthe
constant presencebit,
andincrements
the
constantcountby
one.There
aretwenty
slots perinstruction.
DEST Destination
address and port.These
arethe
instruction
addresses and portswhere
the
resulttokens
(produced
by
executing
the
instruction)
areto
be delivered.
There
aretwenty
ofthese
perinstruction.
The
assembleinstruction
processbegins
by loading
the
commandtable.
The
commandTablefile
containsthe
syntacticalinformation
neededto
assemblethe
simulator'sdataflow
programs.The
table
has for
each assemblerinstruction,
the
instruction's
mneumonic, opcode,
enablecount,
anddestination
count(see figure
13).
The
instruction
storeis
anarray
offive hundred instruction
store records(see
figure
14)
.An
instruction's
addressis
its index
valueinto
the
array.The
zeroinstruction
addresshas
a specialmeaning
for
the
assembler;
it is
reservedfor
specifying
a nulldestination
address.3.2.
Read Data
Process
The
readdata
process readsthe
input
file,
builds
aninput
token
from
each recordin
the
file,
and sends
the
input
tokens
to the token
queue.This
is
the
process which putsthe
simulatorin
motion.
The input file
record consists of adata
value and adestination
(recall
that
adestination
consists of an
instruction
address and a port number).The input
file is further discussed in
the
Project
Application
section.3.2.1.
Token
Implementation
Tokens
consist of adata
value(data
values are notdistinguished from
controlvalues),
an [image:38.529.110.352.64.228.2]30
Figure
13.
The
commandTablefile
#
100
0
0
A
1
0
1
Al
2
0
0
ABS
31
1
ADD
3
2
AND
4
2
CONST
101
0
D
5
1
Dl
6
1
DEBUG
34
0
DIV
7
2
EQ
8
2
FGATE
9
2
GE
10
2
GT
11
2
HALT
32
1
IFREE
33
3
IREAD
12
2
IWRITE
13
3
L
14
2
LI
15
1
LE
16
2
LINK
17
1
LT
18
2
MUL
20
2
NE
21
2
NEG
22
1
NOT
23
1
OR
24
2
OUTPUT
19
0
PBEG
25
0
0
PEND
26
0
SQRT
27
1
SUB
28
2
SWITCH
29
2
2
TGATE
30
2
1
TRACE
102
0
0
Column
1
containsthe
instruction
mneumonic.Column
2
containsthe
instruction
opcode.Column
3
containsthe
instruction
enable count. [image:39.529.54.266.119.574.2]Figure
14.
Instruction
Store
Data
Structure
1
OP
EC DC CC L
Px
.P20D1-D20
500
OP
EC DC CC L
Px
.P20D1
D20
OP
instruction
opcode.EC
instruction
enable count(number
of operands neededto
executeinstruction).
DC instruction
destination
count.CC
instruction
constant count.L
characterstring
that
labels
outputdata.
P
slotsfor
receiving
instruction
operands.D
destination
address and port wherethe
instructions's
resulttokens
areto
be
sent.information
(see
figure
15).
3.3.
Build
Token
Set
Process
The
build
token set processforms
tokens
into
sets which aredestined
for
the
same
instruction
andhave
the
same context.A
token setis
complete when allthe
tokens
neededto
enable aninstruction
are gatheredtogether.
Completed
token
sets aresent
to
the
token set queue.Tokens
whichby
themselves enable aninstruction,
andtokens
which whencombined with an
instructions's
constants enable aninstruction,
are madeinto
atoken
set of one and queued.
The
tokenmatching
algorithm searchesthe
token store(see
figure
16)
for any
token sets whose
destination
is
that
ofthe
token.
If
amatching
setis found
then
the
[image:40.529.65.475.108.417.2]32
Figure
15.
Token Data Structure
Activity
Name
(Tag)
LIFO
queueDestination
Context
data
na >i
s >i
s/c >i
s/cdata
data
value or control value.na number of
activity
namesin
the
tag.
i
initiation
number(loop
iteration
counter).s
instruction
address and port.c
loop
codeblock
number.s/c
indicates
that
in
someinstances
the
addressis
part ofthe
activity
name,
while othertimes
it is
the
codeblock
number.When loops
are enteredit is
the
loop
codeblock
numberthat
is
neededto
matchtokens.
When
subprograms areinvoked it is
the
invoking
instruction's
address(the
A
instruction)
that
is
neededto
matchtokens.
na
is
usedto
improve
the
simulator's run-time execution speed.It
speedsup
the
token
matching
algorithmby
allowing
it
to
immediately
discard
tokens
whoseactivity
name counts areunequal;
this
eliminates needlesstraversing
ofactivity
name queues whenmatching
token
activity
names.the
appropriatetoken
setport,
andthe
token
set countis
incremented.
If
the
instruction
enable count equalsthe
token
set countthen
the
setis
queued anddeleted
from
the
token
store.If
a tokenis
the
first
in
its
setto
arrive,
atoken
set recordis
created andinserted
into
the token store atthe
end ofthe
queuefor
that
token's
destination
address.
The
tokendata
is
inserted
into
the
appropriateport,
the
token
setactivity
In
the
event where atoken
is
destined
for
aninstruction
that
is
already
occupied,
the
simulator willissue
an error message and abort execution.Figure
16.
Token
Store
Data Structure
1
maxinstruction
ec cc ec cc
1
1
1
V
1
V
tc
>p..p
na
1
>|
i
s|
/ /
>|
i
s/c|
Token
Set
Activity
Name
tc
na
->
P-P
Token Set
Ports
I
>|
i
s|
/ /
>|
i
s/cToken
Set
Activity
Name
ec
cc
tc
P
na
i
s
c
instruction
enable count.instruction
constant count.number of
tokens
int
the
token set.port
containing
token
setvalues;
abit
is
setto
indicate
data
present.number of
activity
namesin
the
tag.loop
iteration
counter.instruction
address and port. [image:42.529.55.466.176.579.2]34
3.4.
Build
Operation
Packet
Process
The
build
operation packet processcombines
token
sets withtheir
destination
instruction's
opcode,
enablecount,
destination
count,
outputlabel
(if
there
is
one),
andconstant values
(if
there
are any).The
completed
packetis
sentto
the
operation packetqueue where
it
waitsto
be
executedby
the
next available processor.3.5.
Execute
Operation
Packet
Process
The
execute operation packetinvokes
the
appropriate procedureto
performthe
operation specified
by
the
operation packet's opcode.The
data
resulting
from
the
operation,
andthe
operation packet'sdestination
and context areformed
into
a resulttoken
and sentto
the
token
queue.The
simulatorinstruction
setis
completely
defined
in
the
Project
Description
section
(see
section2.1.5).
Each
instruction
is
implemented
as a separate procedure.The
instruction
set canbe
easily
extendedby
Figure
17.
Operation
Packet Data
Structure
|
op
ecdc 1 p..p
d..d
na|
>|
i
s|
/ /
>|
i
s/c|
op
instruction
opcode.ec
instruction
enable count.dc
instruction
destination
count.1
outputlabel.
p
portcontaining
operandvalue;
abit is
setto
indicate data
present.d
destination
address and port of resulttoken.
na number of
activity
namesin
the
tag.
i
loop
iteration
counter.s
instruction
address and port.writing the
instruction
procedure andlinking
it
withthe
rest ofthe
simulator modules.Placing
the
instruction's
command syntaxinto
the
commandTablefile
(see
figure
13)
willincorporate
the
instruction
into
the
simulator'sassemblerlanguage.
3.5.1. I-Structure
Implementation
The i-structure
store(figure
19)
is
anarray
of one-hundredby fifty
i-structure
cells.The
i-structure
is implemented
as an asynchronous(allows
readsto
occurbefore writes) data
structurethat
provides mostofthe
generalfunctionality
ofdata
structures.It is
constrained

![Figure 1.[AckermanData Flow 1982]](https://thumb-us.123doks.com/thumbv2/123dok_us/109933.10194/12.529.35.416.219.687/figure-ackermandata-flow.webp)
![Figure 3.[MisunasMIT Dennis Machine 1978] [Dennis.Boughton,Leung 1980]](https://thumb-us.123doks.com/thumbv2/123dok_us/109933.10194/15.529.54.452.90.321/figure-misunasmit-dennis-machine-dennis-boughton-leung.webp)
![Figure 5.[Gurd.Kirkham, Manchester MachineWatson 1985] [Gurd.Watson 1977] [Watson.Gurd 1979][Watson,Gurd 1982]](https://thumb-us.123doks.com/thumbv2/123dok_us/109933.10194/18.529.59.420.86.360/figure-gurd-kirkham-manchester-machinewatson-watson-watson-watson.webp)