Rochester Institute of Technology
RIT Scholar Works
Theses
Thesis/Dissertation Collections
3-1-1998
Lempel Ziv Welch data compression using
associative processing as an enabling technology for
real time application
Manish Narang
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion
in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact
.
Recommended Citation
Lempel Ziv Welch Data Compression
using Associative Processing as an Enabling
Technology for Real Time Applications.
by
Manish Narang
A Thesis Submitted
m
Partial Fulfillment of the
Requirements for the Degree of
MASTER OF SCIENCE
in
Computer Engineering
Approved by:
_
Graduate Advisor - Tony H. Chang, Professor
Roy Czemikowski, Professor
Muhammad Shabaan, Assistant Professor
Department of Computer Engineering
College of Engineering
Rochester Institute of Technology
Rochester, New York
Thesis Release Permission Form
Rochester Institute of Technology
College of Engineering
Title: Lempel Ziv Welch Data Compression using Associative Processing as an Enabling
Technology for Real Time Applications.
I, Manish Narang, hereby grant pennission to the Wallace Memorial Library to reproduce
my thesis in whole or
in
part.
Signature:
_
---.L----=---Abstract
Data
compressionis
aterm that
refersto
thereductionofdata
representation requirementseither
in
storage and/orin
transmission.A commonly
used algorithmfor
compressionis
the
Lempel-Ziv-Welch
(LZW)
method proposedby Terry
A. Welch[l].
LZW
is
anadaptive,
dictionary
based,
lossless
algorithm.This
providesfor
a general compressionmechanism that
is
applicableto
abroad
range ofinputs.
Furthermore,
thelossless
natureof
LZW
implies
thatit is
a reversible process which resultsin
the originalfile/message
being fully
recoverablefrom
compression.A
variant ofthisalgorithmis
currently
thefoundation
oftheUNIX
"compress"program.
Additionally,
LZW
is
one ofthe compression schemesdefined in
the
TIFF
standard[12],
as well as
in
theCCITT V.42bis
standard.One
ofthe challengesin
designing
an efficient compressionmechanism,
such asLZW,
which can
be
usedin
real timeapplications,
is
the speed of the searchinto
thedata
dictionary.
In
this paper anAssociative
Processing
implementation
of theLZW
algorithm
is
presented.This
approachprovides an efficient solutiontothis requirement.Additionally,
it
is
shown thatAssociative
Processing
(ASP)
allowsfor
rapid and elegantdevelopment
ofthe
LZW
algorithmthatwillgenerally
outperform standard approachesin
Acknowledgment
I
wouldlike
to
acknowledgemy
family, Gurprasad,
Vimal
andVibhu
Narang,
for
theguidance and support
they
offeredthroughout the
implementation
ofthis
work.Also,
I
wouldlike
to
thanktheThesis
committeefor
theirinput
andtimein
reviewing my
Table
of
Contents
ABSTRACT Ill
ACKNOWLEDGMENT IV
TABLE OF CONTENTS V
LIST OF
FIGURES
VIILISTOF
TABLES
VIIIGLOSSARY IX
1. INTRODUCTION 1
1.1 General 1
1.2Information Sources 2
1.3 Deliverables 4
2. INFORMATION THEORY 5
2.1 Information 5
2.2 Redundancy 11
3. COMPRESSION .13
3.1 General Overview 13
3.2 Run LengthEncoding 18
3.3 Shannon-FanoCoding ., 19
3.4 Huffman Coding 23
3.5 Arithmetic Coding 28
3.6Lempel-Ziv-Welch 32
3.6.1 Basic Algorithms 34
3.6.2 An Example 36
3.6.3
Hashing
403.7 Considerations 43
3.8 The NeedforHardwareCompression 44
4. ASSOCIATIVE PROCESSING 48
4.1 general-cam 48
4.2 Integration Issues 54
4.2.1
Constituents
of a cell 544.2.2
Scalability
564.3 Coherent Processor 58
4.4 Alternatives 60
4.5
ArchitectureforCompressionusingAssociative Processing 624.6 avariable length12bit codeimplementationoflzwcompression using
associative
Processing
634.6.1 Data Structure
64
4.6.2 CP
Macros
66
4.6.3 Accomplishments
68
4.7 avariable length16bit code implementation oflzwcompression using
associative
Processing
714.7.2
CP
Macros 724.8
Results73
5. COMMERCIAL HARDWARE
COMPRESSORS
796. CONCLUSION 80
6.1 Summary 80
6.2 Significance
83
PREFERENCES 84
8. APPENDIX A: MAIN LZW 12 BIT
CODE
879. APPENDIX B: CP LZW 12 BIT CODE 94
10. APPENDIX C: MAIN LZW 16 BIT
CODE
96List
of
Figures
Figure
1.Generic Statistical Compression
15Figure 2.
Generic Adaptive Compression
17Figure
3.Generic Adaptive Decompression
18Figure 4.
Binary
TreeRepresentation
ofShannon-Fano Code
22Figure 5. Huffman Treeafter second iteration 25
Figure
6. Binary Treerepresentation ofHuffmancode 26Figure
7. IncomingStream
toLZWcompression 36Figure 8. Compressed
Stream
afterLZWcompression 37Figure 9. Mask
Functionality
inanASP 50Figure 10. Logicfor asingle bit ofCAM 51
Figure 11. Multiple
Response
Resolver , 52Figure 12. Static CAM Cell
Circuit
54Figure 13.
Dynamic
CAM Cell Circuit 55Figure 14. Proposed ASP Architecture
63
Figure 15. CAM Data
Structure
for12bitLZW 64Figure
16.Representation
ofTable 13inCAMusing12bitcodes 65Figure 17. User Data
Structure
forCAMinterface 66Figure 18.CAM Data
Structure
for16bitLZW 71 [image:8.561.77.494.70.324.2]List
of
Tables
Table
1.Entropies
ofEnglish
relative to order9
Table
2.Probability
ofasample alphabet 20Table
3. First
iteration ofShannon-Fano
21Table
4. Shannon-Fano Code
for the samplealphabetofTable 2 21Table
5.
ExampleofShannon-Fano
Coding 22Table
6.
Huffman CodeforTable
2 26Table 7. Huffmancoding example
27
Table 8. Rangeassignment for text string"ROCHESTER" 30
Table 9.
Arithmetic Coding
of text string"ROCHESTER" 30Table 10. Arithmeticdecoding oftextstring"ROCHESTER" 31
Table 1 1.
String
tableafter initialization 36Table 12. Buildingof
String
TableduringCompression
36Table 13.
String
Tableatcompletion 37Table 14.
Decompression
ofCompressed Stream
up to the seventhcode 37Table 15. Hashtable usingOpen
Chaining
- Linear Probe 41Table 16. Calgary Corpus
[33]
69Table
17. Compressionresultsfor12bit implementation 70Table 18.
Compression
results for16bitimplementation 74Table 19. Runtimeapproximationsfor16bitversion 77
[image:9.561.74.495.71.312.2]Glossary
Active-X ASIC ASP CAM CP CU Java-Beans GPLB LAN LFU LRU LZW MRRMRReg
MRROut OLAP PPM RLE SIMD SRUDS
VLSIWAN
wcsAsoftware component
interface
architecture proposedby
Microsoft.Application
Specific Integrated Circuit.Associative
Processor(s)
orProcessing.Content Addressable Memory.
Coherent
Processor,
an associative processordesignedby
CoherentResearch.Control Unit.
Asoftware component
interface
architecture proposedby
Sun Microsystems.General Purpose Logic Block.
Local Area Network.
Least
Frequently
Used.Least
Recently
Used.Lempel-Ziv-Welch.
Multiple Response Resolver.
Multiple Response Register.
OutputoftheMRR.
Online Analytical Processing.
Prediction
by
PartialMatching.Run Length Encoding.
Single Instruction Multiple Data.
Shift Register.
User Data Structure.
Very
Large
Scale Integration.Wide Area Network.
1.
Introduction
1.1 General
Today's
worldhas become
aninformation
society.Bob
Lucky
has
stated,
"The industrial
age
has
come andgone; the
information
ageis
here."
[17,
p.2]
This
is
in
sightofthe
fact
that more than
65%
percent ofthe
population ofthe
United States
is involved
in
information
relatedwork.Much like
theindustrial
age and otherturning
pointsin
the
history
ofman, this
agetoo
has
many
implications.
The
greatest of whichis
the
management ofdigital information.
There
aremany
aspectsrelating
to this challenge;
from
creating,
securing,
sharing,
storing,
anddistributing,
to
analyzing.In
this paper,
solutionsto
twoofthese
challengesare
being
examined.Namely,
storing,
anddistributing
information
willbe
presented.It
is
obvious thatasinformation
grows,
sodoes
the
needto
store anddistribute it.
Here,
when we speak of
storing
information,
we arereferring
to a means ofphysically writing
data into
a permanent storagedevice
such as magnetic or optical media.Although
the
density
ofsuchdevices is
everincreasing,
without an appreciableincrease in
cost, there
are
issues
thatthis
technology
changedoes
not address.One,
those thathave
already invested
in
the
purchase of storage media or networks willnot
be
easily
willing
to
spend additionalmoney
in
revamping
existing
systems.Unfortunately,
due
to the
fact
that
information
is
growing
at afaster
ratethan the
technology,
a"do
nothing"
new
hardware is
unavoidablebut
musthappen in
tandem withthe
utilization ofdata
compression
to
meetthe needs ofthe
user and society.Two,
there
is
the
issue
of physical space constraints.Unchallenged,
it
is
notdifficult
to
imagine
thetrend
in
computertechnology
going
towards
afuture,
whichlike
thedays
ofthe
ENIAC
willhave large
computer rooms.Unlike
those
days,
where this room wasused
for processing
hardware,
the space will nowbe
dedicated for data
storage.Again,
data
compressioncan provide a mechanismto
help
controlthisgrowthin information.
Moreover,
it is
quite commonto
seethe
interconnection
ofhigh
speedLANs
vialow
speed
WANs.
However,
this resultsin
frequent
queuing delays. A
prime example ofthis
is
theInternet.
A
solution to this wouldbe
the utilization ofdata
compression onthe
gateway from
thehigh
speedto
thelow
speedlink.
This
will providefor
better
channelutilization under a
statistically
multiplexed scenario[30,
p.45].In
fact,
it
is
in
thistype
ofpoint to point connection that the merits of
hardware based
compression are strongest.This
is
due
to
thefact
thatin
this type ofconnection thetraffic
is
usually
heavy,
but
nocontext
switching
is
required;
hence only
one compressor/decompressoris
needed oneach side.
1.2 Information Sources
The
sourcesfor digital
information
are many.Examples
cangenerally
be
categorizedinto
three groupings.One
is
throughthe
digitization
ofexisting
information.
Another
source
is
through the
creation of newinformation.
The
last category
ofinformation
Let
uslook
atdigital
imaging
as an examplefor
the
creationofstorage andtransmissionrequirements
that
willbecome
increasingly
necessary
asexisting information
is
digitized.
The Encyclopedia
Britanica,
which contains about25,000
pages,
if
scanned at300 dots
per
inch
requiresmorethan
25
Gigabytes
ofdata
to
representit
in
anbi-level
format.
To
be
accurate,
notonly
is
this
a storage requirementbut,
it becomes
abandwidth
constraintif
onetries
todigitally
transmit
thisdata
over a network.Some may
arguethat
in
this
example
it is
notprudentto
storeevery
page ofthe encyclopediaas animage.
It may
be
suggested that
only
picturesbe
stored asimages
and that theremaining
content canbe
storedmore
efficiently
asplainelectronic text.Ignoring
the
fact
thatthis
suggestionis
in
effect
alluding
to aform
ofcompression,
it
is
still aformidable
taskto
manage thecontent of
data in
thelibrary
ofcongress as plaintext,
whichtoday
contains over17739
Gigabytes
ofdata.
(This
incidentally
wouldtake
over3
years to transmitover aTI (1.54
Mbps)
link.) [14]
One only
needsto
look
atthe number of newtitles
being
publishedannually
to estimatethepervasivecreation ofnew
information. Over
thelast 20
yearsin
theUnited
States,
the
numberofnewtitles published
has
gonefrom
1 1,000
to
over41,000.
This
is
equivalentto a
5
percent annual compounded growth.Similar
growth alsoholds
true
for
thepublicationof
journals,
magazines and reports.[17]
Moreover,
theincrease in
information
is
seenin
the
creation and management ofdigital
creations.
If
one examinesthe trend
in
the
use ofthe
Internet
for
the
transmission
ofapplications and
multimedia,
such as those proposed withthe
advent ofthe
networkMulticasting,
it is
nothard
to
visualizethe
needto
transmit and storethisinformation
in
the
least
amount of space possible.In
the
aboveexamples, the term
information is
usedloosely.
In
fact,
not all ofthe
contents of
the
aboveinformation is
really
information.
Information generally
canbe
separated
into:
realinformation
and redundancy.Unfortunately
therealinformation
canbe
seen astrue
knowledge
andhence
it is
unpredictablelike
a random process.This
portion of
data
is
impossible
to
compress withoutloosing
someknowledge
content.However,
the redundant portionis
excess andhence
canbe
removed withoutloss
ofknowledge. It is
thispoint thatforms
thepremisefor lossless data
compressionthroughthe
reduction ofredundancy.These
andotherfacets
ofdata
compression are presentedlater in
this paper.For
theremainder ofthis paper,
referenceto
information implies
realinformation.
1.3 Deliverables
The
purpose ofthis
thesisis
twofold.One,
in
this
thesis anintroduction
to
associativeprocessing
is
presented.In
particular,
the goalis
to
demonstrate
variousfeatures
ofthe
associative
computing
paradigm.Two
main concepts that willbe focused
on are:1)
Associative
Processing
allowsfor
a performance enhancement of common algorithmssuch as
data
compression.2)
Associative
Processing
simplifies softwaredevelopment
by
eliminating
the needfor
explicit softwarehashing;
therefore
a reductionin
softwaredevelopment
costis
realized.These
two
concepts willbe
demonstrated
by
the
implementation
ofthe
Lempel-Ziv-Welch
(LZW)
data
compression algorithmfor
the
approaches will
be
examined.A
discussion
ofwhy LZW
waschosen,
along
with anoverviewof compression
theory,
will alsobe
presented.The
associativeprocessing
implementation
onthe
CP
also serves a secondpurpose;
thatis
todemonstrate
thehardware
extensibility
ofthe
concepts of a commongeneral purposeassociative
processing
architecture.This
is
done
by
extracting
thefeatures
of theCoherent Processor
that are neededfor
compression,
which would nolonger
makethe
processor general
purpose,
but
will makeit
compact andeasily
realizablefor
the
data
compression algorithm.
2.
Information
Theory
2.1 Information
Information
theory
providesfor
thelanguage
to
quantify
the abstract concepts ofdata
compression.
It originally
evolved out of a need to addressthe
issue
ofbandwidth
utilization and maximization.
Due
tothis,
researchersin
the area ofanalog
communications
have
been
studying
means ofefficiently coding data
sincethe
1940's.
Claude Shannon
was one ofthe
founding
fathers
ofinformation theory
anddata
compression.
[16]
Fundamental in Information
theory
is
the
conceptofinformation,
whichShannon defines
as
the
unpredictable portion of a message.It
is
quantified as:Average Information
=Here
the
base
ofthe
logarithm determines
the
unit usedto
measurethe
information.
Therefore,
for
abase
of2,
the
unit ofinformation is
calledabit.
Unless
otherwise notedthis
is
the
radixthat
willbe
usedin
all subsequent referencesto
log.
According
to this
definition,
a characterin
the
English
alphabetrequires-log (1/26)
=4.7
bits.
However,
we use8
bits
to
represent an alphabetic characterin
most computers.This
is
because,
in
most computers the extendedASCII
codeis
usedto
store theinformation. This
codehas 256
possibleoutcomesandhence
theinformation
content of asingle outcome
is
equal to-log
(1/256)
=8
bits.
This
does
not mean that
data
storedusing ASCII is
optimal with respectto size.This
is due
to
thefact
thatby
using ASCII
we are
assuming
that all symbols areindependent
andhave
an equalprobability
ofoccurring.
This is obviously
not truein
the
real world.Hence,
anopportunity
for
data
compression
is
created.To
extend the concept ofinformation
further,
to
include
realistic sourcesthat
generatesymbols whichare not all
equally
probable,
a quantifiable concept calledentropy,
H(S),
is
introduced.
It
canbe
seen asthe
probability
weighted average of theinformation
associated with a source of
information
that outputs a sequence ofsymbols,
from
analphabetofnpossible symbols.
For
azero-memory,
or orderzero, source,
meaning
that
theoutput of
any
symbolfrom
the
sourceis
statistically
independent
ofany
previous,
it is
quantified as:
H(S)
=The interpretation
ofentropy
is
the
same asthat
from
the
perspectiveofthermodynamics;the
higher
the
entropy
of amessage,
the
greaterits lack
of order orpredictability.Hence,
more
information is
conveyedin it.
Therefore,
the
relationship between
the
entropy
andlength
ofa message canbe
ascertained.A
formal
proof ofthe
relationship between
thelength
of a symbol andits
entropy showing
thatthe
averageLength
>H(S),
canbe found
in Adamek
[21,
p 33].
As
anexample,
let
uslook
at aloaded
three sideddie. Assume
that
theprobability that
aroll willresult
in 1 is
1.5/3,
theprobability
of a2
is
1/3,
andthe probability
of a3
is
0.5/3.
Therefore
theentropy for
thesourceis:
-1.5/3.0
log
(1.5/3.0)
- 1.0/3.0log
(1.0/3.0)
- 0.5/3.0log
(0.5/3.0)
=.5
log
(2)
+.33log
(3)
+.167log (6)
= 1.45 Bits
If
thedie is
notloaded
and all outcomes areequally
probable then theentropy
willbe
1
.58Bits. This
servestoillustrate
thatin
the case whereasideis
morelikely
to showup,
the amount of
information
conveyedis less
than
that when all outcomes areequally
likely,
hence
the
bit
requirementis less.
It
shouldbe
obvious thatthe
entropy
is
maximum
for
sourcesin
which theprobability
ofall symbolsis
equal.It
is
a minimumfor
sourcesthathave
asymbol ofprobability
of1
.The
previous equationfor
entropy
canbe
easily
extendedto
representthe
entropy
ofn-tuples
of zeromemory
finite
ensembles,
also referredto
asblock
random variables.The
entropy
of such a n-tuple canbe
shownto
be
equalto
nH(S).This
is derived from
the
fact
thatthe
probability
ofa n-tuplePfa)
=Pfa,) P(aj2)
...PfaJ.
Here
the
probabilitieson
the
right
side of the equation representthe
probability
of eachindividual
symbol.defined
equationfor
entropy
the
resultis
as stated above:H(Sk)
=k
H(S). As
anexamplefor
a2-tuple:
1=1 >i
H(S2)
=-XX piPj(log(pi)
+log(pj))
1=1 7=1n h
H(s2
)
=-X
P'los(/")X
pj-E
p'H
pj1b,(pj)
/=1 7=1 /=! >1
H(S2
)
=H(S)
+H(S)
=2H(S)
Using
the
fact
thatLength
>H(S)
andby
examining
the
results above alittle
morecarefully,
we see thatLmin(Sk)
>H(Sk)
=kH(S)
thereforeLmin(Sk)/k
>H(S).
Which
in
the
limiting
case ask
-> qoLmin(Sk)/k
->H(S).
This
says that as thelength
ofthe ensembletends to
infinity
the
averagelength
willreachthe theoretic entropy.This
fact is known
asShannon's Noiseless
Coding
theorem.For
agoodderivation
seeAdamek
[21
,p34].This
Theorem
servestocreate alower bound
onthecoding
ofensembles.Again
this
is
a simplistic view ofentropy,
sinceit
is only
an example of a zeromemory
source.
In
cases wherethe
sourceis
statistically
dependent
on previous outcomes such asthe
English
language,
aslightly
altered modelis
used.This
is done
withthe
use of aMarkov
model[15,
p.47]. A Markov
model of order nis defined
ashaving
aconditionalprobability P(mk/mk.,,mk.2,...,mk.n).
So for
an order oneMarkov model,
the
conditionalP(i
j)=P(i)P(j/i).
This
leads
to the
equation ofEntropy
for
an order oneMarkov
sourceto
be
equalto:
H{ylx)
=-XX^.-fllogW/O)
,=1 7=1
Here P(i
j)
is
the
joint
probability
andP(j/i)
is
the
conditional probability.A
good proofofthiscan
be found
in
Gonzalez
[14,
p327].Unfortunately,
whenstatistically
dependent
sourcesoccurthe extent ofthe
dependency
is
usually
severallayers
deep.
This
makes the mathematics abit
cumbersome.Although
the
independent
and order1 Markov
modellack
realism,
they
makeup for it
by
theirsimplicity in presenting
theimplications
ofcompression.An
example ofthe
effect ofdifferent
orders ofdependency
ontheEnglish language is
seenin
thefollowing
table
[17,
p.
111].
Table 1. Entropies ofEnglishrelativetoorder
Order
Zero
First
Second
Third
Fourth
Entropy
4.76
4.03
3.32
3.1
2.8
Up
tonow,
only
ensembles thathave been based
on a well-defined randomvariable,
whoseprobabilistic
behavior is
wellcharacterized,
have
been
discussed.
Therefore,
this
discussion
does
notcompletely hold
true
for
anarbitrary
source.Specifically,
theprevious theorem
does
nothold
true
for
afinite
sourcefor
which no a prioriinformation
is
available.Ziv
andLempel
help
the
situationby
providing
a systemfor encoding
whichalgorithm
for
coding
which achievessomething
analogousto the
H(S)
in
the
limiting
case.
They
use adictionary
based
technique
for individual
sequences,
which servesto
accommodate
the
issue
ofhigh
orderdependency.
The
basis for
theirworklies
in
the
fact
that
for
acompletely
randombinary
sequence oflength
n, the
number ofblocks
in
themessage grows as
n/log(n)
for
sufficiently
long
lengths.
They
termthis
type of sequenceas complex.
However,
they
believe
that
in
general,
input
sequences areinterrelated
andnot always complex.
Therefore,
in
the
case where symbols arefrom
a quasi-randomprocess,
but
are notindependent,
thebuildup
of avocabulary
for
long
sequencesapproaches
nH(S)/log(n),
whereH(S)
is
the
entropy
ofthe random source.It
is
due
tothisthat thespecialcase
arises,
whereif
thesequenceis
avery
long
one,
based
onrandomvariables,
thatthe
Lempel Ziv coding
canbe
relatedto
entropy.In
fact,
Ziv
andLempel
state,
"The
compression ratio achievedby
the proposed universal codeuniformly
approaches the
lower bound
on the compression ratio attainableby
block
to
variablecodes and variable
to
block
codesdesigned
to
match acompletely
specifiedsource."[2]
Moreover,
Ziv
andLempel
go on toindicate
that,
"For every
individual
<x> sequencex,
this
minimalbit/symbol
ratewas shownto
be
equalto
aquantity
H(x)
that,
in analog
withShannon's entropy (which
is
defined
for
probabilistic ensembles ratherthat
individual
sequences),
correspondsto
the smallestcoding
ratefor
x under whichthe
decoding
error-rate can
be
madearbitrarily
small."[3]
For
this
reasonthe
discussion
ofinformation
and2.2
Redundancy
Obviously,
information is
not always codedusing
the
theoretic entropy.This
raisesthe
question
for
the
purpose ofthe
excess,
whichhas
been
defined
as redundancy.Redundancy
does
not containinformation
andtherefore
does
not needto
be
encoded aspart of a message.
However,
generally,
information
withredundancy
is
easierto
understand and
is
moretolerant to
errorsif
it is
corrupted,
sinceredundancy
canbe
usedtocorrect
for
errors.From
apracticalpoint ofview,
sources ofredundancy
areinherent
in
theinformation
we exchange.In
theEnglish
language
theletter
"t"is
morelikely
to
occurthan
any
otherletter;
and theletter
"z"is
theleast likely.
From
ourdefinition
it
is
Obvious that the
letter
"t"has
alower entropy
andhence
providesless information.
To
makethis
point,
consider thefollowing
sentence"jack
andjill
wen?up ?he hill".
With
our
knowledge
oftheEnglish
language it
is
easy for
usto
determine
that
?
in
thesentencewas the
letter "t".
Therefore
the "t"is
redundantin
the
information
thatis
being
conveyed.
Without
the "t" we get noless information.
However,
understanding
whatis
being
communicatedbecomes
abit
more cumbersome.Also,
in
the
examplesentence,
if
due
to an error we wereonly
presented with"jack
andjill
wentup
ehill",
we wouldknow
torecoverfrom
theerrorby
filling
"th"
in
theblank
space.This
is
an example of ahigh
order redundancy.It
is
the same concept that allowsfor humans
to
have
conversations
in noisy
environments and stillbe
ableto
understand whatis
being
communicated
based
onthebits
and piecesthat
areactually
heard.
Forms
ofredundancy
are many.In
textanddatabase
files
they
can resultfrom
characterCharacter distribution
redundancy,
sometimes also referredto
ascoding
redundancy,arises
from
thefact
that
some characters are used morefrequently
than
others.It
is
seenin
theexample ofthe
ASCII
codebeing
usedto encodeEnglish
text.Here,
since75%
ofthe
256
characters willnotbe
used,
the additional3
bits
requiredto
encodeeach characterare considered redundant.
Character
repetitionredundancy
resultsfrom
thefact
that
arepetitionof characters canbe
better
encodedthanby
merely
repeating
theirsymbols.This
type ofredundancy
is
oftenfound in
images
anddatabase
files.
In
these
types ofsourcesit is
quite commonfor
chains of symbols
representing
ablank field
or a solid object to makeup
a significantamount ofthe
file's
content.Higher
order statistical correlationleads
toredundancy in
patterns.This
is
true sincecertain sequences ofsymbols tend to occur
in
afile
more often than others.Therefore
encoding
patterns such asthe
word "the"in
the same ways asany
other3
letter
combination
leads
to redundancy.The
is
also seenin
databases
if
advantageis
nottaken
in encoding
fields
thathave
a small cardinality.Positional redundancy
is
seen whensymbols appearin
a predictablefashion in blocks
ofdata
or whenthe value of a symbol canbe
predictedbased
onits
surroundings.This is
seen
in
the
exampleof a raster scan of animage,
in
which a verticalline is
placed.Here
it is
predictablewhatthe
value ofthe pixel,
whichis
afixed
offsetfrom
the
previous pixelAnother
type
ofredundancy
arisesfrom
the
human
ability
to
interpolate
vision; this type
of
redundancy
is
termed
psycho-visual redundancy.An
example ofthis
is
apparentwhenan
image is
passedthrough
alow
passfilter.
A
human is
generally
just
as ableto
perceive
the
contents ofthe
filtered image
as ofthe
original.This
is
sinceimages,
for
humans,
are understoodthrough
perception and not analytically.Unlike
the
othertypesof
redundancy, this type
is actually dependent
onthe
interpretation
ofthe
observer andtherefore,
is
sometimes not considered redundancy.This
is
so,
since theinformation
content
is
not1
00%
recoverable.More
thanjust
a philosophicalconcept,
redundancy
has
amathematicaldefinition. It
canbe
calculated as thedifference
between
theentropy
and theactual average numberofbits
per symbol.
[15]
3.
Compression
3.1
General Overview
Compression
deals
withtaking
a message andtransforming
it using
acoding
scheme.Using
this techniqueit is
hoped
that theresulting
message,
ontheaverage,
willbe
smallerin
size than the original.At
the
highest
level,
compression canbe divided into
two
categories;
onebeing
lossy
andthe
otherbeing
lossless.
Lossy
compressiondeals
withentropy
reduction,
andtherefore
leads
to anencoding
schemein
whichinformation is
lost.
This
type
of compression schemeis
generally
well suitedfor
sources that aredigitizations
ofanalog
phenomenon,
such asimages
andsound,
whereunderstanding
is
compression
is
the
compression ratio.It
is defined
asthe
ratio ofthe size ofthe
originalmessage and
the
size ofthe
compressed message.It
shouldbe
obviousthat
thehigher
the
compression
ratio, the
better
the compression.Although
lossy
compressionis
highly
efficientfor
digitized
applications,many
otherapplications of
today
require that compressionbe completely
reversible.This is
especially
true
for
applicationsin
thehealth
andlegal
arena.Additionally,
thisrequirement
is
presentin digital
"data"storage andtransmission.
For
this
reason,lossless
compression
is
the
mainfocus
in
this
paper.The
goaloflossless
compressionis
limited
to
redundancy
reduction;
thereforeit
providesfor
acompletely
recoverableencoding
scheme.
Lossless data
compression canbe
achievedusing
two approaches.One,
using
azero
memory
model,
symbolprobabilitiescanbe
usedto encodedata
suchthatthe
length
of
its
symbolis
consistent withits
entropy.Two,
using
aMarkov
model,
the statisticaldependence property
canbe
usedto
predict or characterizethe type ofinformation
thatis
encoded.
This
allowsfor
thecreationof adictionary
ofcodesthatcorrespondstovariousinput
patterns;
therefore reoccurrence ofthe same pattern will resultin
the same outputcode.
[15,
p.50]
Hence,
it is implied
thatlossless
data
compressiondeals
with the representation ofinformation
in
theleast
amount of spacerequired,
whichoptimally
shouldbe
equalto the
Shannon
Entropy
ofthe
source.When
completeinformation
aboutthe
sourceis
available,
it is
often referredto
as minimalredundancy
coding.In
the
context ofredundancy,
the
goal of compressionbecomes
the removal ofapproach
is
goodin
some applicationsbut
canbe bad in
otherapplications.For
examplefrom
the
stand point of errorrecovery,
data
compression canbe
devastating.
Since
whenwe
have
removed allthe
redundancy
from
amessage,
any
errorin
theinformation
wouldresult
in data
being
lost. There
wouldbe
no statisticsavailableto
useto
be
abletocorrectthe error.
From
the
stand point ofdata
encryption,
data
compression canbe
abonus;
there are no statistics that can
be
ascertainedfrom
anideally
compressed message.Therefore,
it
is difficult
to predictthe
language
or content of the message withoutcomplete
knowledge
of thedecompression
algorithm.Considerations
thatrelatetoissues
such as
data
corruption anddata
encryptionusually
fall
underthe
category
of channelencoding
andthereforewill notbe
discussed beyond
thispoint.Compression
is
generally broken up into
atwo part problem.The
first
partinvolves
themodeling
ofthe
source andthe secondpartdeals
withthedevelopment
of a compressionmechanism
using
statistics/characteristics ofthe source.For
a statistical compressorit
would
look
like[ll,
p.14]:
Figure 1. GenericStatisticalCompression
Input
Stream
Symbols
s^^~^
\
Probabilities
Encoder
Output
Stream
XZ.
)
In
this
figure
the
modelis
a set of rulesthat
establishhow
to
code aninput
symbol.Furthermore,
this
figure
servesto
showthatfor
compressionto
occurthe
statistics needto
be
understoodfirst. For
an actualimplementation
ofthis
compressionprocess, the
modelalternatively, the
compressor needsto
do
two
passes onthe
source.In
the
first
passit
models
the
probabilities ofthe
source and communicatesthis
modelto the
decompressor.
The
modeling
leads
to
the
development
of acoding
table.The
secondpassis
wherethis
table
is
usedto
codethe
source.When
themodelis
createdonce,
and usedfor
allinput
symbols, the
compressionschemeis deemed
to
be
static.Static
compression,
althougheasy
toimplement,
has
somesignificant weaknesses.
Namely,
if
source statistics changesuddenly,
whenthe
modelhas
not,
it
canlead
topoor compression.A
solutionto this
problemmay
requireremodeling
thesourceevery
timeit
changes.This
solution,
however,
leads
to a considerable overheadin CPU
time.
Additionally,
if
the
model
is examining high
ordercorrelation,
then the amount ofinformation
to
be
communicated withthe
decompressor
becomes large.
For
this reason, adaptive compressionis generally
preferred over static compression.Adaptive
compression,
asits
nameimplies,
adaptstothe
characteristics ofthe
source.It
can
be implemented using
source statistics or adictionary
based
scheme.As
it has been
suggested,
statisticalmodeling generally
resultsin
thecoding
of a single symbol at atime
using its probability
ofoccurrence.Adaptive dictionary-based
approachestry
to achievebetter
compressionby
trying
to
accountfor
somehigher
ordercorrelations,
which canbe
seen as aspecial case of
the
Markov
model,
andby
using
single codesto
replace astring
of symbols.
The
assumptionhere is
that strings areinterrelated
andtherefore
will occurmany
times within a message.This
fact
then
leads
to
"good"
compression
being
stored
in
atable
(dictionary),
whichis
created onthe
fly
by
both
the
encoder andthe
decoder,
to
be
referenced asmany
times
as necessary.Additionally,
adaptive algorithmscan
generally
adjustquickly
to
a sourceby
resulting
in
"good"
compressionwithin a
few
thousand
bytesfl].
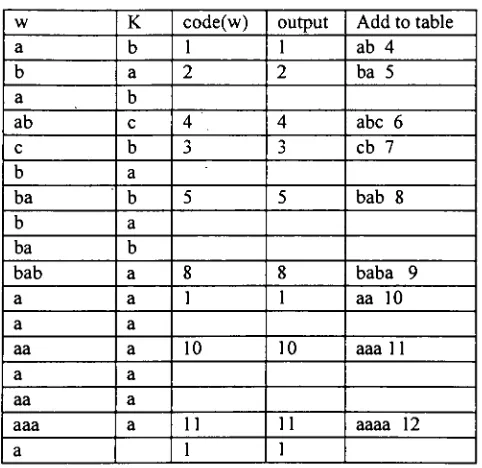
A
generic adaptive compressoris
shownin
Figure 2 [1
1,
p.21]:Figure 2. GenericAdaptive Compression
Symbols
Read input
Symbol
?1
Encode
Symbol
Update Output
Code Model
Model
Codes
Another
feature
of adaptive compression algorithmsis
that the
decompressor does
notneed
to
be
communicatedany
information
from
the
compressor.In
fact,
the
decompressor
uses asimilaralgorithm asthat
ofthe
compressorto
recreatethe
source.A
Figure 3. GenericAdaptiveDecompression
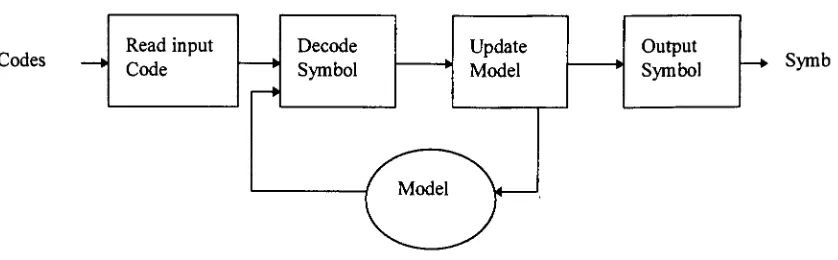
Codes
Read
input
Code ?
*
Decode
Symbol
Update Output
Symbol Model
Model
Symb
Both
ofthe abovefigures
arefor
alossless
compression.For
Lossy
compression,
a stageneeds to
be
added to thefront
end of the compressionflow
above.Namely
atransformation/quantization
stageis
typically
performed priorto
modelsbeing
created.3.2 Run Length
Encoding
A
simple means to reducetheredundancy is known
asRun-Length-Encoding (RLE)
[18,
24]. It
tries to
encode runs ofthesame symbolby
using
a countfollowed
by
a symbolto
represent a chain of
the
same symbol.To
distinguish
count-symbol combinationfrom
astraight codethe use of a special escape
byte is
used.Therefore,
in
orderfor
RLE
tobe
effective, the
source shouldhave
runs greaterthan3
bytes.
Additionally
the encoding, ofruns
is
limited
to
255
with each escapebyte.
As
anexample,
if
we came across a streamthat
looked
as such:aaaaaaabbaaabbbbccccc,
we can represent
this
as<esc>7abb<esc>3a<esc>4b<esc>5c,
in
effectsaving 7
bytes.
This
type
oftechnique
is
usefulfor
"block"
type
drawings, i.e.,
line drawings
andfaxes.
Also,
this technique
has
moderate usein data
files;
but,
has
very
little
valuefor
problem with
RLE
type
techniques;
namely,
such techniques are notgenerically
applicable.
That
is
to say,
it
maybevery
efficient sometimes andvery inefficient
atothertimes.
3.3 Shannon-Fano
Coding
Claude Shannon
andR. M.
Fano developed
thistechnique
independently,
yet almostsimultaneously.[ll,
13]
Their
workis
the
first
well-known attempt to encodeinformation using
a minimumredundancy
code.Additionally
this workled
to thedevelopment
ofthe,
nowpopular,
Huffman coding
algorithmthatwillbe
discussed in
thefollowing
section.Fundamental
toShannon-Fano
codes aretwo
properties:The
number ofbits
required torepresenta code
is
proportionalto theprobability
ofthe code.Therefore,
codes withlow
probabilities
have
alarger bit
representation.This
is
consistent with the equation ofentropy,
whichwaspresented earlier.The
secondproperty
requiresthatthe
codesbe
ableto
be uniquely decoded.
Therefore,
they
mustobey
the
prefixproperty;
thatis
to say,
noone code can
be
a prefix ofanother.This
issue
canbe easily
solvedif
all codes are codedusing
the
leafs
of abinary
tree.Given this,
the symbolcoding
algorithm works asfollows[l
1,
p.31]
[13]:
Develop
aprobability
for
the
entirealphabet,
suchthat
each symbol's relativefrequency
of appearanceis known.
Sort
thesymbolsin
descending
frequency
order.Divide
thetablein two,
suchthat the
sumofthe probabilitiesin both
tables
is
Assign 0
asthefirst bit for
allthe symbolsin
the
top
half
ofthe
tableandassign a1
asthe
first bit for
allthe
symbolsin
the
lower half.
(Each
bit
assignmentforms
abifurcation in
the
binary
tree.)
Repeat
the
last
two
steps until each symbolis
uniquely
specified.The
above stepshave formed
abinary
tree
and canbe
usedto
encode anddecode
asource.
Note
that
fundamental
to this type
ofcoding
is
the
premise thatboth
thecompressor and
the
decompressor
have
aprioriknowledge
ofthe source.Alternatively,
for
thedecompressor,
the compressor cantransmit/store the
sourcedescription
as part ofthemessage.
However,
this
approachresultsin
the
performanceissues discussed
earlier.As
anexample,
let's
examine thefollowing
symbolalphabet:Table 2.
Probability
ofa sample alphabetProb
C
.05E
.3H
.10
.1R
.15S
.1T
.15Y
.05The
nextstep
is
to take
this alphabet and order anddivide it based
on thefrequency.
Table 3.Firstiteration ofShannon-Fano
Prob
E
.3T
.15R
.15H
.10
.1S
.1c
.05Y
.05Therefore,
weknow
thatthe
first bit
ofE
& T
willbe
0,
andthat
thefirst bit
ofR, H, O,
S,
C,
andY
willbe
1
.Continuing
the
procedure until completionresultsin
the
following
code.
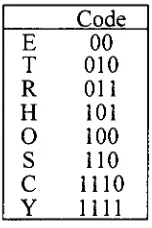
Table 4. Shannon-Fano Code forthesample alphabetof Table 2
Code
E
00
T
01
R
100
H
101
0
1100
S
1101
c
1110
Y
mi
The
different
iterations
ofthe
algorithm canbe
seenif
one examines thebinary
tree
Figure4.
Binary
Tree RepresentationofShannon-Fano CodeIt
shouldbe
obvious,
thatthe
algorithm guaranteesthat
no code willbe
a prefix ofanother.
If
we encode a message withthe
characteristic alphabet given aboveusing
theShannon-Fano
algorithm andthe
probabilitiesfrom
Table
2,
theefficiency
of this [image:32.561.114.384.95.286.2]algorithm
becomes
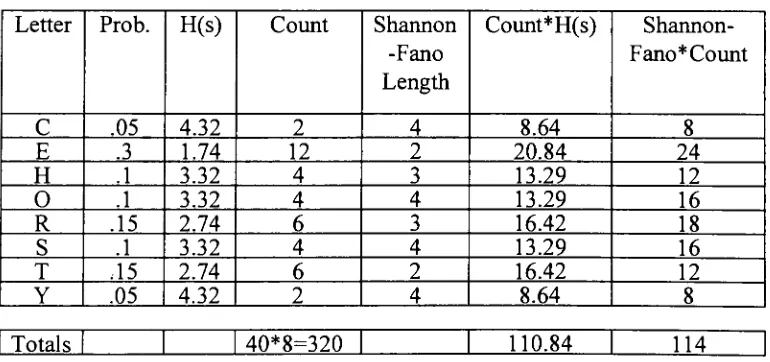
evident.Table 5. Example ofShannon-Fano
Coding
Letter
Prob.
H(s)
Count
Shannon
-Fano
Length
Count*H(s)
Shannon-Fano*Count
C
.054.32
2
4
8.64
8
E
.31.74
12
2
20.84
24
H
.13.32
4
3
13.29
12
0
.13.32
4
4
13.29
16
R
.152.74
6
3
16.42
18
S
.13.32
4
4
13.29
16
T
.152.74
6
2
16.42
12
Y
.054.32
2
4
8.64
8
[image:32.561.62.447.446.627.2]It
is
apparentthat the
Shannon-Fano
algorithmperforms wellin
representing the
originalmessage when compared
to the
extendedASCII
representation,
which wouldtake
320
bits
to
storethe
same messagethat this
algorithm storesusing only 1 14
bits.
Although
the
Shannon-Fano
algorithm performswell, the
averageentropy
ofthemessage,
H(s),
shows
that
it is
possibleto
encodethis
messagein 1 10.84 bits.
The Huffman coding
algorithm
which,
onthe average,
performs evenbetter
is
presented next.3.4 Huffman
Coding
This
algorithm works similarto
theShannon-Fano
algorithmin
that
it
takes a messageand codes
it using
variablelength
symbolcodes,
which arebased
on symbol probabilities.This
algorithm alsohas
one ofthedisadvantages
ofthepreviously discussed
algorithm;
namely its behavior
is
generally
good,
but
optimalonly for
symbol probabilitiesthat
arenegative powers of
2
[15,
p55].Moreover,
sinceboth
ofthese algorithms arestatic,
thecoder/decoder must
have
aprioriknowledge
ofthe source statistics orrequiretwopassesto
analyze them.Also,
sinceboth
these
algorithms are order0
theirapplicability
as ageneral compression scheme
is
questionable.Furthermore,
althoughthey
work wellfor
character
distribution
redundancy,
they
are notapplicableto
othertypes
of redundancy.Some
ofthe
implementation
details
ofthis
algorithm are also common withthe
Shannon-Fano
algorithm.While
the prefix code rule applieshere
aswell, there
is
a significantdifference
in
the two
algorithms.The Huffman coding
schemetakes
abottom
up
approach,
whilethe
Shannon-Fano
algorithmis
atop
down
algorithm.Moreover,
the
Huffman coding
algorithmhas
been
shownto
always perform equal orbetter
than the
this
algorithmhas been
the
subject oflossless
data
compressionresearchfor
quite sometime.
The
algorithm canbe
summarized asfollows:
[13, 18,
23]
Develop
aprobability
for
the
entirealphabet,
suchthat
eachsymbol'srelativefrequency
of appearanceis
known.
Sort
thesymbols,
representing
nodes of abinary
tree,
in
probability
order.Combine
the
probabilities of thetwo
smallestnodesandcreate/addanewnode,
withits probability
equalto
thissum, to the
list
of availablenodes.Label
thetwo
leaf
nodes ofthosejust
combined as0
and1
respectively, andremovethem
from
thelist
of availablenodes.Repeat
this
process until abinary
treeis formed
by
utilizing
all ofthenodes.Utilizing
this algorithm onthe
above exampleleads
to the
following
possibleiterations.
In
thefirst iteration C
andY
canbe
combined and resultin
a node thathas
ajoint
probability
of0.1.
Since
this new nodehas
one ofthe
lowest
probabilities,
it
canbe
combined with
S,
which alsohas
aprobability
of0.1,
to
form
a newnodehaving
ajoint
Figure 5. Huffman Treeafter seconditeration.
_r
C Y
In
the nextiteration
H,
whichhas
the
lowest
probability,
canbe
combined withO
thatalso
has
aprobability
of0.1.
The
combination ofthe thesetwo
leaf
nodesforms
anodewith a
joint probability
of0.2.
This
leaves T
andR
withthelowest
probabilities.The
combination ofwhichresults
in
a newnodewithprobability 0.3.
Continuing
this
processuntil all
the
nodeshave
been
combined resultsin
abinary
tree thatlooks like
thefollowing. It
is
important
to
note thata given alphabetmay have
morethanoneHuffman
code.
However,
the total
compressedlength
of the message will remainthe same,
Figure6.
Binary
TreerepresentationofHuffmancodeThis
binary
tree resultsin
aHuffman coding
for
the alphabet givenin
the tablefor
the [image:36.561.112.399.126.322.2]Shannon-Fano
example andis
enumeratedin
thefollowing
table.Table 6. Huffman Code forTable2
Code
E
00
T
010
R
on
H
101
0
100
S
no
c
1110
Y
nn
[image:36.561.240.316.430.544.2]Table 7. Huffmancodingexample
Letter
Prob.
Count
Huffman
Length
Huffman
*
Count
C
.052
4
8
E
.312
2
24
H
.14
3
12
0
.14
3
12
R
.156
3
18
S
.14
3
12
T
.156
3
18
Y
.052
4
8
Totals
40*8=320
112
It
is
apparentthat theHuffman
Coding
Algorithm
has
out-performed theShannon-Fano
Algorithm,
although notby
much.In
both
cases,
these algorithmsdo
a muchbetter
job
coding
thanASCII.
But,
thefact
remainsthatthey do
notachievetheoptimalentropy
of110.84
bits.
As
statedearlier,
thisis due
to thefact
that the algorithmsjust discussed
result
in
optimal codesonly
whenthesourceprobabilitiesarenegative powersof2.
This
is
obvious sincetheHuffman
codes mustbe integral bits in length. Non-integral entropy
can
be
a majorissue
if
compressing something
thathas
ahigh probability
of occurring.This
is
so,
sinceby
rounding up
to
the nearestintegral bit length leads
to an errorthat
is
compounded with
every
occurrence ofthatcharacter.Therefore,
if
theprobability
is high
then
the
compounded effect ofrounding
will alsobe high.
The
effect ofthis
canbe
overcome
by
applying
the
Huffman coding
algorithmto groups ofsymbols,
but
thisleads
to
a solutionthat
is
not as general.The Arithmetic coding
algorithm,
whichtries to
overcomethis
limitation,
is
discussed
later.
Another
majorlimitation
of an algorithm such asHuffman
Coding
resultsfrom
the
has
to
know
when a complete codehas been
specifiedis
to
do
alookup
for
every
bit
received.
This
requirement of alogical
operationfor
eachbit
makesit
difficult
to
maintain
the
necessary
decompression
ratesin
real-time systemsoperating
at30 Mbps.
[l.p.10]
3.5 Arithmetic
Coding
As
statedearlier,
it is
not alwayspossible,
in
practice,
to achieve optimal compressionefficiency using Huffman coding due
the problem offractional Entropies.
This is
especially
truefor
symbols thathave
avery
unbalancedprobability
distribution.
Arithmetic coding
circumventsthis obstacleby
combining
a chain ofinput
symbolsinto
asingle
high-precision
floating
point numberbetween 1
and0.
Obviously,
the
amountofprecisionwill
depend
on the size ofthe original message.Fundamentally,
the approachis
to startwitharange thatrepresentsthefirst
character.To
thisrange,
the effect ofeachsubsequent character
is
added,
resulting in
the rangebecoming
a more precise range.Upon reaching
thepoint wherethecontribution of each symbolhas been
considered,
any
number
in
the range will allowfor
the uniquedecoding
ofthe original message.It
is
important
to notethat the
morelikely
symbolshave
theleast
effect onthe
narrowing
ofthe composite message
range,
andhence do
not contribute asmany
bits
to the
message.This
feature
ofArithmetic
Coding
fits
in
well withthe
earlierdiscussion
ofinformation
Init: Establish Prob. for the alphabet 0 ->
last;
For each symbol in alphabet:
sym, prob,
last,
last+prob -> table(sym,
prob,low,
high);
last + prob ->last;
Begin:
Read input > char; Low(table. sym
==
char) > msg_low_range; High(table. sym
==
char) > msg_high_range; msg_high_range
-msh_low_range > msg_range; Next:
Get next input > char; If no next input: Goto End; msg_range * High(table. sym
==
char) + msg_low_range
> msg_high_range; msg_range * Low(table
. sym ==
char) + msg_low_range > msg_low_range;
msg_high_range
-msh_low_range > msg_range; Goto Next;
End:
Select (value >= msg_low_range and <
msg_high_range) > Output.
Obviously
there are alot
ofimplementation
details
here.
The
mostbasic
issue is
that ofoverflow.
This
issue
canbe
resolvedby
shifting
out andtransmitting
parts oftherange asit
becomes
convergentin
the most significantdigits.
Therefore,
implementation
on astandard sized register
is
possible.Another
issue
ofArithmetic
Coding
deals
withinforming
thedecoder
whentostop decoding. This
canbe
accomplishedby
transmitting
the
length
ofthe
messagealong
with the composite numeric representation.Alternatively,
a special end ofmessage symbol canbe
encodedalong
withthe
originalmessage.
The
decoding
processis
very
similarto that
of encoding.Here,
instead
ofstarting
withthe range ofthe
first
character andadding
the
effects of subsequentcharacters,
we aregiven a rational
number,
andhave
to
determine
which characters createdit. This
processInit: Use Prob. from the compressor
0 ->
last;
For each symbol in alphabet:
sym, prob,
last,
last+prob> table
(sym,
prob,low,
high);
last + prob-last;
Begin:
Read input -> aNumber;
Extract:
Sym(table. low <= aNumber < table.
high)
- char;
char output;
aNumber - Low(table
. sym == char)
> aNumber;
aNumber
/
[High (table. sym ==char)
- Low(table . sym
==
char)]
> aNumber;
while not End of Message Goto Extract.
A
simple example ofencoding
the word"ROCHESTER"
using
this
techniqueis
given [image:40.561.75.396.48.250.2]below. The
symbol 'Y'is
used toindicate
theend ofmessage.Table 8. Rangeassignmentfortextstring "ROCHESTER"
Symbol
Probability
Low Range
High Range
C
0.1
0.0
0.1
E
0.2
0.1
0.3
H
0.1
0.3
0.4
0
0.1
0.4
0.5
R
0.2
0.5
0.7
S
0.1
0.7
0.8
T
0.1
0.8
0.9
Y
0.1
0.9
1.0
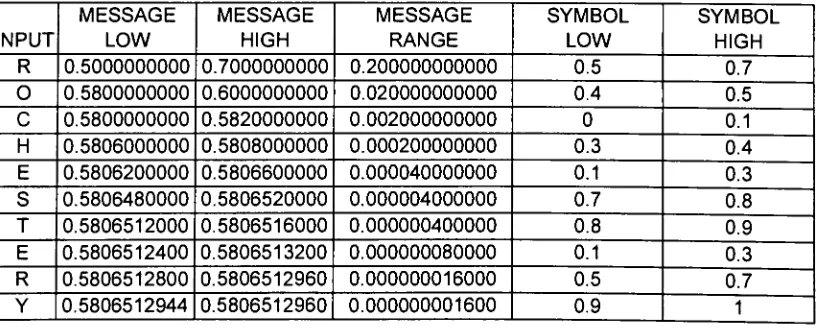
Table9. Arithmetic
Coding
oftextstring"ROCHESTER"
INPUT
MESSAGE
LOW
MESSAGE
HIGH
MESSAGE
RANGE
SYMBOL
LOW
SYMBOL
HIGH
R
0.5000000000 0.7000000000
0.200000000000
0.5
0.7
O
0.5800000000 0.6000000000
0.020000000000
0.4
0.5
C
0.5800000000 0.5820000000
0.002000000000
0
0.1
H
0.5806000000 0.5808000000
0.000200000000
0.3
0.4
E
0.5806200000 0.5806600000
0.000040000000
0.1
0.3
S
0.5806480000 0.5806520000
0.000004000000
0.7
0.8
T
0.5806512000 0.5806516000
0.000000400000
0.8
0.9
E
0.5806512400 0.5806513200
0.000000080000
0.1
0.3
R
0.5806512800
0.5806512960
0.000000016000
0.5
0.7
[image:40.561.71.480.521.685.2]Therefore,
the
message "ROCHESTERY" canbe
encodedto
be
uniquely
decodable
using
the value0.5806512944.
The
rangetells
how
precisethis
number needsto
be in
order
to
be
uniquely
decoded,
andhence
representsthe
probability
of the message.Therefore
the
number ofbits
requiredto
encodethis
message as abinary
fraction is
lg(0.0000000016)
+1,
approximately
equal tothe
Shannon
Entropy
of29.22
bits for
this
message.
Unfortunately,
due
tolack
of precisionin
mostprocessors,
larger
messagesrequire an extra
step in
encoding.Here
theencoding
is
achievedby
shifting
out tothe
channelthe most significant
bits
ofthecode asthey become
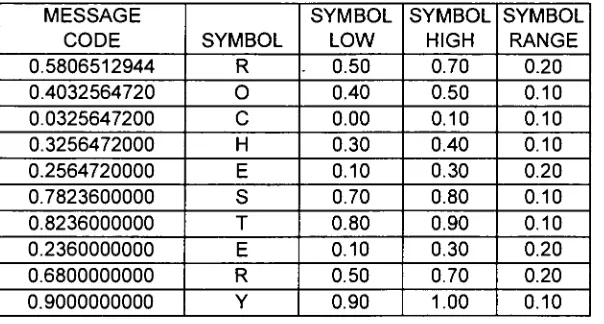
convergent. [image:41.561.67.369.368.530.2]Decoding
thismessagecanbe
seenin
thefollowing:
Table 10. Arithmetic
decoding
oftextstring "ROCHESTER"MESSAGE
CODE
SYMBOL
SYMBOL
LOW
SYMBOL
HIGH
SYMBOL
RANGE
0.5806512944
R
0.50
0.70
0.20
0.4032564720
O
0.40
0.50
0.10
0.0325647200
C
0.00
0.10
0.10
0.3256472000
H