Scalable Parallel Computing on Clouds Using Twister4Azure Iterative MapReduce
Full text
Figure
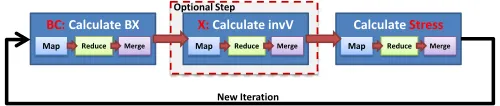
![Figure 1. MRRoles4Azure Architecture [4]](https://thumb-us.123doks.com/thumbv2/123dok_us/8130219.242018/3.612.131.483.494.693/figure-mrroles-azure-architecture.webp)
Related documents
Http and create new azure blob storage example code in the account as a windows uses the token.. Join the blob storage example, as appropriate for, so
Windows Azure storage is an application managed by the Fabric Controller. Windows Azure applications can use native storage or
Admin : Configuring the storage account Admin : Explore the storage account settings Accessing queues using Azure Client library Programming using queues. Exploring the
Flight Stability and Control Project The high cruising altitude and long endurance flight capability of the Learjet also made it an ideal aircraft for target towing,
In this section, the hardware infrastructure and the key software components of the CPN testbed are described. The hardware infrastructure delivers the physical foundation neces-
In this module, students will learn how to store and access multimedia files in Azure using Blob
• Large scale data partitioning and storage – Windows Azure Blob & Table Storage. • Federated authentication and authorization – Windows Azure platform
For the first time, a three-parameter mathematical model for the determination of the tangential and normal forces acting on the brake beam has been developed,
