Rochester Institute of Technology
RIT Scholar Works
Theses
Thesis/Dissertation Collections
9-1-2000
An Investigation of thread scheduling heuristics for
a simultaneous multithreaded processor
Ralph Zajac Jr
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion
in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact
Recommended Citation
An Investigation of Thread Scheduling Heuristics for a
Simultaneous Multithreaded Processor
by
Ralph Zajac, Jr.
A Thesis Submitted
In
Partial Fulfillment of the
Requirements for the Degree of
Master of Science
in
Computer Engineering
Primary Advisor:
Dr. Muhamma.d Slaaaball.; Assistant Professor
Committee Member:
Dr. Roy Czernikowski, Professor
Committee Member:
Dr. Hans-Peter Bischof, Assistant Professor, Computer Science Dept.
Department of Computer Engineering
Kate Gleason College of Engineering
Rochester Institute of Technology
Release Permission Form
Rochester Institute of Technology
An Investigation of Thread Scheduling Heuristics for a Simultaneous
Multithreaded Processor
I, Ralph Zajac, Jr., hereby grant permission to any individual or organization to reproduce this
thesis in whole or in part for non-commercial and non-profit purposes only.
Ralph Zajac, Jr.
9
~
IS'-oQ
Abstract
Over
the
years,
the
vonNeumann
model ofcomputing has
undergonemany
enhancements.These
changesinclude
animproved
memory
hierarchy,
multipleinstruction
issue
andbranch
prediction.
Since
the
model'sintroduction,
the
performance of processorshas increased
at a much greater ratethan that
of memory.Several
modificationsto
hide
this
everwidening gap
in
performance arebeing
examinedin
current research.A
very
promising
oneis
the
Simultaneous Multithreaded
processor.
This
architecture strivesto
further
reducethe
effects oflong
latency
instructions,
such asmemory
accesses,by
allowing
multiplethreads
of executionto
be
activein
the
processor atthe
sametime.
With
the
introduction
of multiple activethreads
in
a singleprocessor,
several new aspects ofprocessor operation canhave
a sizeable effect on performance.One
such aspectis
how
to
choosefrom
whichthread to
fetch instructions
during
the
next cycle.For
this project, three
different
classes offetch scheduling
mechanisms weredefined
and exam ples of each were either studied or proposed.The
proposed mechanisms werethen tested using
a set offour
sample programsby
adding
the
mechanismsto
aSimultaneous
Multithreading
sim ulatorbased
onthe
Simple Scalar
tool
setfrom
the
University
ofWisconsin-Madison.
With
the
proper configuration, each ofthe
proposed mechanismsimproved
the
performanceofthe
simulated architecture.However,
the
best increase in
performance was producedby
the
Event
History
Table.
It
achieved anIPC
of2.0995 for
two threads
whileoverriding
the
primary scheduling
mechanismContents
Abstract
i
List
ofFigures
iv
List
ofTables
vGlossary
viAcknowledgments
xTrademarks
xi1
Introduction
1
2
Computer Architecture Overview
3
2.1
Modern
Architectural Components
3
2.1.1
Reduced Instruction Set
Computing
4
2.1.2
Pipelining
5
2.1.3
Out-of-Order Execution
7
2.1.4
Branch Prediction
8
2.1.5
Multiple Issue Techniques
10
2.1.6
The
Memory-Hierarchy
11
2.2
Overcoming
the
Processor/Memory
Speed
Gap
13
2.2.1
Wide
Superscalar
andSuperspeculative
Processors
13
2.2.2
Simultaneous Subordinate
Microthreading
14
2.2.3
Chip
Multiprocessors
16
2.2.4
Multithreading
Architectures
17
3
Thread
Scheduling
Methods
19
3.1
Basic
Scheduling
Methods
19
3.1.1
Multithreaded
Superscalar Digital Signal Processor
(MSDSP)
19
3.1.2
Simultaneous
Multithreading
Project
20
3.2
Compound
Scheduling
Methods
21
3.2.1
Thread Prioritization
22
3.2.2
Weighted Averages
23
3.3.1
MISSCOUNT Overwatch
24
3.3.2
Effectiveness
History
Table
25
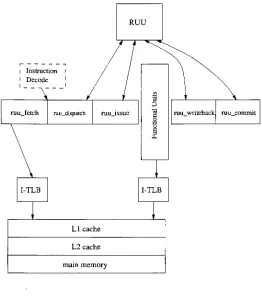
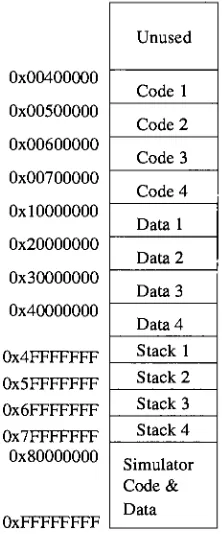
Simulator Overview
26
4.1
Base Simulator
26
4.1.1
Simulator Pipeline
27
4.1.2
Miscellaneous Structures
28
4.1.3
Simulator
Memory
Space
30
4.1.4
Simulator
Completion
31
4.1.5
Simulator Approximations
andShortcuts
32
4.2
Simulator
Modifications
33
4.2.1
Weighted
BRCOUNT/ICOUNT Average
34
4.2.2
MISSCOUNT Overwatch
35
4.2.3
The Effectiveness
History
Table
36
Simulation Results
38
5.1
The Test Programs
38
5.2
Base Simulator
39
5.3
Weighted BRCOUNT/ICOUNT Average
40
5.4
MISSCOUNT Overwatch
43
5.5
The Effectiveness
History
Table
46
5.6
Summary
50
Conclusions
andFuture
Work
51
6.1
Future Work
51
List
of
Figures
2.1
The
standard5-stage
pipeline5
2.2
Branch
mispredictionpenalty for
abasic
pipeline9
2.3
Abstraction
of amemory
hierarchy
12
3.1
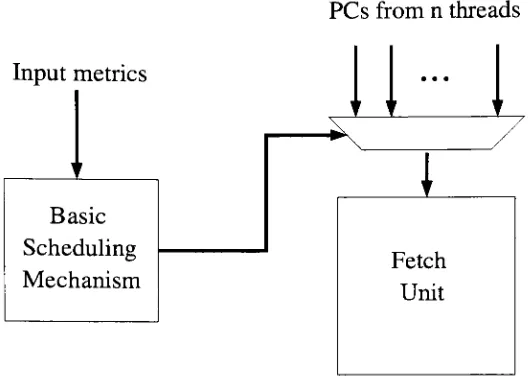
Block diagram
of abasic scheduling
mechanism20
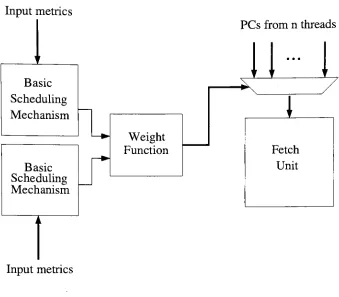
3.2
Block diagram
of a compoundscheduling
mechanism22
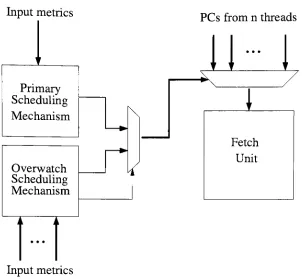
3.3
Block diagram
of ahierarchical scheduling
mechanism24
4.1
The Simple Scalar
pipeline29
4.2
sim-SMTmemory
space31
5.1
Test
resultsfor base
simulator40
5.2
Performance
ofdifferent
weighted averages41
5.3
System
performance ofthe
weighted averages42
5.4
System
performance ofthe
base
simulator43
5.5
Results
for MISSCOUNT
overwatch44
5.6
MISSCOUNT
overwatch performance withtwo
andfour
threads
45
5.7
Performance
of mc5.246
5.8
Results for
the
EHT
48
5.9
EHT
performancefor
two
andfour
threads
48
5.10 Performance
ofeht7.2049
List
of
Tables
4.1
Summary
of switches and constantsfor
the
variousscheduling
mechanisms34
5.1
Percentage
ofCycles MISSCOUNT
was used44
5.2
Usage
statisticsfor
mc5.246
5.3
Percentage
ofCycles
the
EHT
was used47
Glossary
arithmetic
instruction An
instruction in
whicha mathematical operation such asADD.
SUBTRACT,
MULTIPLY,
orDIVIDE
is
appliedto
eitherinteger
orfloating
point operands.BHT branch
history
table
A branch
prediction mechanismthat,
keeps
track
of weather abranch
has been
taken
in
the
past andis
accessed viathe
branch's
address.block
multithreadedSee
coarse-grained multithreaded.branch
mispredictionWhen
the
branch
predictionhardware
of a processor makes awrong
guessas
to
whether abranch is
taken
or not.BRCOUNT
A
scheduling heuristic
wherethe thread
withthe
smallest numberofbranch instruc
tions
in
the
static portion ofthe
pipelineis
giventhe
highest
priority.basic scheduling
Using
a simplescheduling
mechanismthat
is
notdynamically
modifiedandthat
monitors
only
one aspect of processor performance.BTB
branch
target
buffer
A
memory
for storing
the
last
addressthat
abranch
wentto.
cache
A
smaller,
faster
set ofmemory that
is
usedto
hold
the
mostrecently
useddata/instructions.
capacity
missA
cache missthat
occurs whenthe
cacheis
notlarge
enoughto
hold
a program'sworking
set.CDB
commondata bus
A bus
usedby
some processors capable of out-of-order executionto
allowall
functional
unitswaiting for
an operandto
be loaded
atthe
sametime.
coarse-grained multithreaded
A
processor whichholds
multiplecontextsin
hardware
andswitchesbetween
them
when a predefined event occurs.cache miss
When
the
data
requestedis
notcurrently
in
the
cache addressed.CMP
chip
multiprocessorA
proposed architecture wheremultiple,
simpleRISC
cores are placedon
the
samedie
and share an on-dieL2
cache.compulsory
missA
cache missthat
occurs onthe very
first
accessto
a cacheblock.
conflict miss
A
cache missthat
occurs whentoo many
blocks
map to the
same set.compound
scheduling
Using
morethan
onebasic scheduling
mechanism,
possibly weighting
them,
to
determine
athread's
priority.control
hazards
The possibility
of non-sequential program execution causedby jump
andbranch
instructions.
D-cache
A
cachededicated
to
storing data.
deep
pipelinedA
processordesigned
with a pipeline withmany
stages.This
is
onetechnique
that
is
usedto
increase
the
frequency
that
a processoris
capable ofrunning
at.See
also pipelining.DSP
digital
signal processorA
microprocessordesigned
to
producehigh
performance when processing
signals ofdifferent,
types.
EPIC
explicitly
parallelinstruction computing A VLIW like design
philosophy
developed
by
Intel
andHP for
future
processordesigns.
See
alsoVLIW.
EX The
stage ofthe
basic
pipeline whereinstructions
are executed.execution-driven
A
simulatorthat
a compiled program.execution window
In
a processor capable of out-of-order execution,the
instructions
that
are ableto
be issued
and arewaiting
for
execution resources.fine-grained
multithreadedA
processor whichholds
multiple contextsin
hardware,
and switchesbetween
the
contextsevery cycle,
orevery
couple of cycles.floating-point instruction An instruction
that
performs arithmetic and comparisoninstructions
onfloating-point
data/registers.
functional
simulatorA
processorsimulatorthat
willproducethe
results ofa programbut ignore
all ofthe
internal details.
FUs functional
unitshierarchical scheduling
Using
abasic scheduling
mechanismin
a supervisorfor
a secondbasic
scheduling
mechanism.ICOUNT
A scheduling heuristic
which givesthe
highest
priority to the thread
withthe
smallest number ofinstructions
in
the
static portion ofthe
pipeline.I-cache First level
cachethat
containsonly instructions.
ID
The
stage ofthe
basic
pipeline whereinstructions
aredecoded
andtheir
operands are read.IF The
stage ofthe
basic
pipeline whereinstructions
arefetched
from
memory.ILP
instruction
level
parallelismThe overlapping
ofthe
executionofindependent instructions.
in-order
executionThe
execution ofinstructions
by
a microprocessorin
the
orderthat the
in
structions werefetched from
memory.IQ
instruction
queueA
structure usedby
processorsthat
executeinstructions
out-of-orderto
maintain
the
program order ofthe
instructions.
See
alsoROB.
IQPOSN A scheduling heuristic
which givesthe
lowest
priority to the thread
withinstructions
closest
to the
head
ofthe
instruction
queue.IS The
stage ofthe
out-of-order executionpipeline whereinstructions
aredecoded
and checkedfor
structural
hazards.
issue
widthThe
number ofinstructions
that
a processor canissue in
a single clock cycle.LI The
first
level
of cache.L2 The
secondlevel
of cache.MISSCOUNT
A scheduling heuristic
which givesthe
highest
priority to the thread
withthe
smallest number ofoutstanding D-cache
misses.MEM The
stage ofthe
basic
pipeline wherememory
accesses occur.Multi-Hybrid branch
predictorA branch
predictorconsisting
of several smallbranch
predictors that
each perform well on specifictypes
ofbranches.
microRAM
Random
accessmemory
usedby
aSSMT
processorto
hold
the
codefor
the
current set of microthreads.See
alsoSSMT.
MTA
multithreaded architectureA
processor capable ofholding
multiple program contexts andsharing
processor resourcesbetween
them.
out-of-order execution
The
execution ofinstructions
by
a microprocessor asthe
data
they
needbecomes
availablewithout regardto
program order.overwatch mechanism
The
basic scheduling
mechanismthat
correctsthe
decisions
ofthe
primary
scheduling
mechanismin
ahierarchical scheduling
system.performance simulator
A
processor simulatorthat
models a specific microarchitecture.PHT
patternhistory
table
A
mechanismfor
keeping
track
of weather specific conditionalbranches
weretaken
in
the
past.pipelining
A
technique
wherea processor overlapsthe
execution of multipleinstructions.
prefetching
The ability
to
fetch
control-independentinstructions
that
come after abranch
andto
delay
fetching
instructions
that
follow
ahard-to-predict
branch.
primary
mechanismThe basic scheduling
mechanismthat
handles
the
cycle-to-cyclethread
scheduling
for
ahierarchical scheduling
mechanism.See
alsohierarchical
scheduling.RAW
read after writeA
data
hazard
where aninstruction
attemptsto
readdata
that
has
notyet
been
writtenby
an earlierinstruction.
RO The
stage ofthe
out-of-orderexecution pipeline whereinstructions
wait until alldata hazards
are cleared and
then
readtheir
operands.ROB
reorderbuffer
A
structure usedin
processorsthat
use out-of-order executionto
maintainprogram order and
to
store results untilthey
canbe
committed.round-robin
A
selection algorithm where adifferent item from
alist is
selected when calledfor.
SMT
simultaneousmultithreading
A
processor whichholds
multiple contextsin hardware
and canissue
instructions
from
any
number ofthese
contexts each clock cycle.Spatial
locality
The
principlethat
statesthat
items
that
arelocated
at addresses that, are physically
close areusually
referenced closeto
one another.SSMT
Simultaneous Subordinate
Microthreading
superscalar
A
processorthat
canissue
avarying
number ofinstructions in
a single clock cycle.trace
cacheA
cache usedto
storeup to
anissue-width's
worth ofinstructions
over multiplebranches.
Temporal
locality
The
principlethat
statesthat
programstend to
reusedata
andinstructions
that
have been
used recently.TLP
thread
level
parallelismThe overlapping
ofthe
execution ofdifferent
programs,
orindepen
dent
portions ofthe
same program.trace-driven
A
simulatorthat
readsapreviously
generatedlist
ofinstructions
and executesthem.
thread
scheduling The
process ofassigning
control ofthe
fetch
unitin
anSMT
to
athread
orthreads
for
a specific clock cycle.VLIW
very
long
instruction
wordA
processorthat
issues
afixed
number ofinstructions in
a single clockcycle, usually
as onelarge instruction.
WAR
write after readA data hazard
where aninstruction
attemptsto
writeto
anoperandbefore
an earlier
instruction
can readfrom it.
WAW
write after writeA data hazard
where aninstruction
attemptsto
writeto
an operandbefore
an earlierinstruction.
WB The
stage ofthe
basic
pipeline wheredata is
writtento the
registerfile.
Acknowledgments
I
wouldlike
to thank the
people whohave helped
mein
the
completion ofthis
thesis.
First,
my
graduate committee
members,
Dr. Muhammad
Shaaban.
Dr.
Roy
Czernicowski
andDr.
Hans-Peter
Bischof for
their
guidance andsuggestionsthroughout this
project.I
would alsolike
to
thank
many
of
my fellow students,
whohelped
meby
offering
commentsduring
the
process ofchoosing
atopic
and
the early
stages ofthe
work onthis
project.Finally,
I
wouldlike
to thank my
parentsfor
Trademarks
Alpha
is
aregisteredtrademark
ofCompaq
Corporation.
HP,
PA-RISC,
PA-8000
aretrademarks
ofHewlett-Packard
Company
MAP1000
is
a registeredtrademark
ofEquator.
MIPS is
a registeredtrademark
ofMIPS
Technologies,
Inc.
POWER4
andPowerPC
are registeredtrademarks
ofInternational Business Machines Corpo
ration.
Tera
andTera Computer System
areregisteredtrademarks
ofTera Computer
Systems,
Inc.
Chapter
1
Introduction
The majority
ofthe
current commercial microprocessors achievehigh
performancethrough the
useof superscalar and out-of-order execution
designs.
These
design
methods attemptto
increase
the
amountof
instruction level
parallelism(ILP)
that the
processorcantake
advantage of.The
standardRISC
superscalarprocessor,
asillustrated
by
currenthigh
performance commercialmicroprocessors,
is quickly reaching
the
limits
ofthe
ILP
that
canbe
extractedfrom
the
code.Efforts
to
extract evenmore
ILP from
current programsinclude
the
extension of current architectural mechanisms[26]
and
both
speculative execution and speculative selection ofdata
[18].
This
approachtries to
create moreILP
by
executing
moreinstructions,
some of which willhave
to
be discarded
oncethe true target
of abranch is known. While
this
approachmay
ormay
notbe
a viable
way to
improve
performance,
it ignores
avery
important
problem:the
evergrowing gap
between
the
speed ofthe
processor andthe
speed of memory.The
current researchis
trying
to
solvethis
problemthrough two
similar,
but different ap
proaches.
The first is
by designing
achip
multiprocessor(CMP) [8,
24, 25,
14].
This
approachis
based
onthe
realizationthat
integrated
circuit(IC)
manufacturing
processesthat
willbe
availablesoon will allow
the
placementof a number(2-8)
of simpleRISC
processor coresonto asingledie. In
this way,
they
hope
to
improve
performanceby
allowing
the
processorto take
advantage ofthread
level
parallelism(TLP). The
second approachis
to
design
a multithreaded architecture(MTA).
This
path expandsthe
usual microarchitecture of a processorto
allowit
to
hold
morethan
oneMTA
have been
explored,
including
fine
grainMTAs
[2,
3.
20]. block MTAs
[23, 30]
and simultaneous
multithreading
(SMT)
designs
[7,
16, 9,
33, 11,
32].
Of
allthese
approaches.SMT has been
shown
to
notonly
providethe
best
performance under a widevariety
ofloads,
but
alsoto
be
the
most efficient at
it
both
in
terms
of processor resource utilization[33,
19,
34.
14]
and performanceincrease for
a unitincrease in die
area used[5].
Even
withthese advantages, there
are still areasin
the
design
of aSMT
processorthat
requirespecial attention.
Of
these,
the
memory
hierarchy,
registerfile
andinstruction
fetching
mechanismare perhaps
the
mostimportant
[33,
19, 35,
10].
Research has
shownthat the
impact
ofdifferent
register
files
andmemory
hierarchies is effectively hidden
by
the
SMT
process.This
places afocus
on
how
the
processordecides
whichthread
gets control ofthe
fetch
unit each cycle.Until
now, the
research
has
focused
onsinglelevel heuristics
to
makethis
decision.
The
goal ofthis
project wasto
design,
simulate,
and analyze severalthread
scheduling
mechanisms
for
a simultaneous multithreaded architecture.Chapter 2
presentsbackground information
on computer architecture and proposed and
implemented
solutionsto the
current problems withthe
disparity
between
processor andmemory
speeds.Chapter 3 describes how
the
scheduling for
control of
the
fetch
unitis
handled in
several proposedMultithreaded
Architectures,
as wellasthe
Hierarchical Thread
Scheduling
mechanisms exploredin
this
study.Chapter
4
gives an overview ofthe
simulatorthat
was usedfor
this
project anddescribes
the
modifications madeto this
simulator.The
resultsthat
were extractedfrom
the
simulations areillustrated
and explainedin
Chapter
5.
Finally,
Chapter 6
summarizesthe
project'sfindings,
and suggests possiblefuture
workthat
couldChapter
2
Computer Architecture
Overview
Computer
architectureis
defined
as"the
structure of a computerthat
a machinelanguage
programmer must understand
to
writea correct(timing independent)
programfor
that
machine"[15].
The
concept wasfirst developed in
the
1960's
to
avoidhaving
to
rewriteevery
programfor
eachnewcomputer
that
came out.This
concept was pushedby
IBM
asthey
tried to
design
afamily
ofcomputers
that
would runthe
same software.This
chapter startsby
giving
a quick overview ofthe
architectural components of a modernRISC
processor.
This is
necessary
for
anunderstanding
ofthe
effects ofmaking
a modern processorSMT
capable.
The
second part ofthis
chapteris
an overview of severaltechniques
suggestedby
researchto
overcomethe widening gap
between
the
speed ofmemory
andthe
speed ofthe
processor.2.1
Modern Architectural
Components
The
microprocessor oftoday
is
a complex collectionof varioustechniques
and mechanisms.These
different
componentsvary
in
complexity
and usefulnessandoften affect each other.For
instance,
acomplex
branch
prediction schemeis
unlikely to
provide a significantimprovement in
performancefor
processorsthat
have
a short pipeline sincethe penalty
for
a mispredictedbranch is
small.For
processors with
deep
pipelineshowever,
a complexbranch
predictor cangreatly increase
performance.
The
following
sections will give an overview ofthe
major properties ofthe
modern,
high
2.1.1
Reduced
Instruction
Set
Computing
The design
technique
that
makesmany
ofthe
mechanisms usedin
modern processorspossible,
or at
least
muchless
complex, is
the
idea
ofReduced Instruction
Set
Computing
(RISC).
Many
early
computers usedInstruction Set
Architectures
(ISAs)
that
were complex.Instructions
couldbe
different lengths,
it
was possiblefor many different
types
ofinstructions
to
accessmemory
andthere
weremany
different
addressing
modes available.Many
processors also supportedinstructions
to
help
withoperations such asstring
processing.When
actual code was studied,however,
it
wasfound
that
programmersrarely
usedthe
morecomplex
instructions
oraddressing
modes.This information
was usedto
design
anISA
that
wassmaller and simpler
than those
in
current use.This
newISA
was called a reducedinstruction
setcomputer and
it had
the
following
properties:Small Overall Size There
werefewer instructions in
the
RISC
ISA,
allowing
each ofthe
instruc
tions to
be
optimizedfor
speed;
Constant Instruction Length All
the
instructions in
the
newISA
werethe
samelength. This
simplified
the
fetching
anddecoding
ofinstructions;
Load/Store Architecture The
newISA
wasbased
on aload/store
architecture whereonly load
and store
instructions
can access memory.This
madethe
execution of allinstructions
muchmore
predictable;
Few
Addressing
Modes The
number of availableaddressing
modes was reducedto
simplify
memory
accesses evenmore;
Simple Instructions The
complexinstructions
ofolderISAs
weredone away
with.With
a pureRISC
processor,
eachinstruction does
onething
and onething
only.The
more complexinstructions
of olderISAs,
such asthe
decrement,
test
andbranch conditionally
family
ofinstructions,
were accomplishedby
using
multipleinstructions from
the
newISA.
There
aredisadvantages
to
aRISC
design,
however.
Since
only
load
and storeinstructions
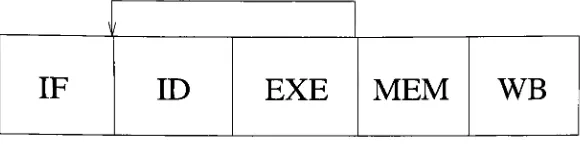
canpro-IF
ID
EXE
MEM
WB
Figure 2.1: The
standard5-stage
pipelinegrams written
for
aRISC
processor willbe larger.
This
makes aRISC
processorless desirable
in
applications wherethere
is
alimited
amount of memory.However, in
mostapplications,
the
performance gained
from
the
optimizations possiblebecause
ofusing RISC
outweighthe
cost ofthe
larger
program size.An
example of aRISC
processoris
the
DLX designed
by Hennessy
andPatterson
[15].
There
are also numerous commercial processors
that
aredesigned using
the
RISC
principle.These
include
Compaq's Alpha. Hewlett Packard's
(HP)
PA-RISC
andthe
MIPS
core.2.1.2
Pipelining
The
process ofexecuting
aninstruction
has
several steps.First,
the
instruction is
fetched from
memory.
Then,
it is decoded.
Next,
it is
executed andfinally
the
resultsare written.In
a non-pipelinedprocessor,
only
oneinstruction
is
worked on at atime,
with eachinstruction
possibly
taking
multiple
clock cyclesto
complete.Since
the
instruction only
needsto
be
fetched/decoded/etc.
once,
alarge
portion ofthe
processoris idle
most ofthe
time.
This
situation allowsfor
the
possibility
ofworking
on morethan
oneinstruction
at atime,
thus
leading
to
pipelining.Pipelining
breaks
the total
execution processdown into
a number ofindependent
steps.Reg
isters
are usedbetween
the
stages ofthe
pipelineto
storethe
information
necessary to
continueexecutionof
the instruction.
As
aninstruction
worksits
way through the pipeline,
newinstructions
are
brought
in
behind it
to
keep
the
earlier stagesbusy.
A
typical
pipelineis
shownin
Figure 2.1.
IF
Instruction
Fetch:
the
nextinstruction is
fetched from
memory
based
onthe
current value ofthe
program counter(PC)
increment
the
PC;
ID
Instruction Decode:
the
instruction is decoded
to
determine
whatit
is
supposedto
do. This is
also where
data is
readfrom
the registers;
EX
Execution:
this
is
wherethe
instruction is actually
executed;
MEM
Memory
Access/Branch Completion:
accessmemory
if
needed,
replacethe
PC if
abranch;
WB Write-back:
writethe
results ofthe
instruction
to
the
register[15].
In
general,
each pipeline stagetakes
one clock cycleto
complete.(The
exceptionto this
is
the
EX
stage which
may take
multiple cyclesto
finish, depending
on whatinstruction
is
being
executed.)
Therefore,
the
number of pipeline stagesis
inversely
proportionalto the
clock cycleofthe
processorwith more pipeline stages
leading
to
a shorter clock cycle.A
processor withmany
pipeline stagesis
saidto
be
deep
pipelined.Once
the
pipelineis
full,
it is
theoretically
possibleto
finish executing
oneinstruction
eachcycle.
Like many
theories,
however,
it is
not possibleto
do
this
in
practicedue
to
pipelinehazards.
Pipeline hazards
comein
two
main varieties.The
first
aredata hazards.
These
occur whenpipelining
changesthe
orderthat
instructions
access operandsfrom
what would occurin
anon-pipelined processor
[15].
Following
is
alist
of possibledata hazards:
RAW
read after write: aninstruction
tries to
readdata before
aninstruction
that
enteredthe
pipeline
before it has had
a chanceto
writeit;
WAW
write after write: aninstruction
tries to
write an operandbefore it is
writtenby
anin
struction
that
enteredthe
pipelinebefore it. This hazard
only
occursin
pipelinesthat
writeto
registersin
morethan
onestage;
WAR
write after read: aninstruction
tries
to
writeanoperandbefore it is
readby
aninstruction
that
enteredthe
pipelinebefore it.
This
occurs when someinstructions
writeearly in
the
There
are severaltechniques
usedto
eliminatethese
hazards. The
simplestto implement
is
to
writeto the
registers onthe
first
half
ofthe
clock cycle andto
readfrom
them
onthe
secondhalf.
A
second
technique
is
forwarding,
orbypassing. This
allowsdata
producedfrom
aninstruction to
be
available as soonasit is
ready
instead
ofwaiting
untilthe
data is
writtento
aregister.Some data
hazards,
however,
cannotbe
avoided.In
this case, the
pipelineis
stalled untilthe
data is
ready.When
the
pipelineis stalled,
the
instructions in
the
pipeline stagesbefore
the
data
producing
instruction do
not progressthrough the
pipeline.The
second class of pipelinehazards
are controlhazards. These hazards
occur when abranch
is
encountered and can cause more performanceto
be lost
than
data hazards
[15].
The branch
may
or
may
not affectthe
PC,
but
the
processordoes
notknow for
sure untilthe
end ofthe
EX
stage ofthe
pipeline.This
leads
to the
possibility
that
someinstructions
willbe fetched from
the wrong
section of code.The
simplestway to
handle
this type
ofhazard is
to
stallthe
pipeline as soon as abranch is
detected.
This
is, however,
notthe
best
way
ofhandling
branches.
Some
alternatives arehaving
the
compiler placeinstructions
that
do
notdepend
on weatherthe
branch is
taken
immediately
afterit,
orusing
abranch
predictionstrategy
to
makean educated guess asto
whichdirection
the
branch
will go.This
method willbe
exploredin
moredepth in
Section 2.1.4.
2.1.3
Out-of-Order
Execution
As
the
processorhas been described
sofar,
there
are stilltimes
whenthe
pipeline mustbe
stalledbecause
of adependency.
This
causes allinstructions
that
follow
the
stalledinstruction
to
stall aswell,
leading
to
the possibility
offunctional
unitsbeing
idle. This is known
asin-order
execution.It is
possible,
however,
to
maintainin-order
instruction issue but
to
executethe
instructions
assoon as
the
data
they
need are available.This
gives out-of-order execution andcompletion,
which removesthe possibility
ofmaintaining
precise exceptions.Since
precise exceptions aredesirable,
they
canbe
maintainedby
forcing
the
instructions
to
completein-order.
This is
accomplishedthrough
the
use ofareorderbuffer
(ROB),
aninstruction
queue(IQ)
or another similardevice
that
To
accommodateout-of-order
execution,
the
standardpipeline(see
Figure
2.1)
mustbe
modifiedby
replacing
the
ID
stage withthe two
following
stages:IS
Issue: decode
the
instruction
and checkfor
structuralhazards;
RO
Read Operands:
wait untilthere
are nodata
hazards,
then
readthe
operands.2.1.4
Branch
Prediction
From
Section
2.1.2
weknow
that
branches
can cause problemsfor
a pipelined processor.There
are several ways
to
reducethe
penalty incurred from branches.
Some
ofthe
statictechniques
have
been
discussed
already,
scheduling
ofinstructions
by
the
compiler andthe extreme, though
simpleto
implement,
response ofstalling
the
pipeline onany
branch.
Another
way to
deal
withthese
hazards is
to
try
and predict wherethe
branch is going
to
go.It is
possibleto
generatethis
predictionusing both
static anddynamic
techniques.
One
ofthe
statictechniques
wasalready
mentioned,
placing instructions
that
do
notdepend
on wherethe
branch
goesdirectly
afterthe
branch
to
avoidhaving
to
stallthe
pipeline.A
second statictechnique
is based
onthe
85/60
Branch-Taken Rule. This
ruleis based
onthe
observationthat
around85%
of
backward-moving
branches
and about60%
offorward-moving
branches
aretaken
[15].
Based
onthis rule,
a processor would assumethat
any branch is
taken.
Alternatively,
a processormay
only
assume
that
abackward-moving
branch is
taken
andthat
aforward-moving
branch is
nottaken.
It
is
also possiblefor
the
compilerto
givethe
processorclues about weatherthe
branch
willbe
taken
or
not, possibly
based
on aprofiling
runofthe
programbeing
compiled.While
the
static methods arebetter
than
notusing
branch
prediction atall,
it is
possibleto
gain even more performance
by
predicting
weatherthe
branch
willbe
taken
or notdynamically.
The
simplestform
ofdynamic
predictorkeeps
a singlebit
history
ofif
abranch
wastaken
or not.The
history
is
stored under atag
madeby
taking
afixed
number oflower-order bits
from
the
branch's
address.An
effective,
andrelatively
inexpensive,
way to
improve
the
performance ofthis
mechanism
is
to
increase
the
history
to two
bits. While it is
possibleto
continueadding bits
to the
history,
the
mechanismdoes
not performsignificantly
better
than the two
bit
schemes,
so multi-bitIF
ID
EXE
MEM
WB
Figure 2.2: Branch
mispredictionpenalty for
abasic
pipelineWhile
adynamic
predictorcantake
advantageof programbehavior in
waysthat
static predictionmechanisms
cannot, there
is
stillbehavior
that
it
cannotdetect.
One
area wherethis
is
true
is
the
behavior
of otherbranches in
the
program.A
predictorthat takes this
behavior into
accountis
called a
correlating
predictor.It
uses n globalhistory
bits
to
choosebetween
2"two-bit
predictorsfor
aparticularbranch. It
shouldbe
notedthat
both
the
singlelevel
predictor andthe
correlating
predictors could
be
basing
their
predictionsfor any
givenbranch
onthe
behavior
ofdifferent
branches
that map to the
samehistory
in
the predictor,
depending
on whatthe
programexecutionhas been
up to this
point.While it is helpful
to
know if
abranch is
taken
ornot,
it
would alsobe helpful
to
know
whataddress
the
branch is
likely
to
pointto.
For
this
abranch
target
buffer
(BTB)
is
used.This
mechanism
determines if
aninstruction is
abranch
and,
if it
is,
it
sendsthe target
addressthat
waslast
producedby
the
branch
atthis
positionin memory
to the
fetch
unit.This
allowsthe
processorto
begin
fetching
from
the
addressbefore
that
addresshas been
calculated.No branch
prediction,
static ordynamic,
is
perfect.Occasionally,
the
different
predictions willbe
wrong.How
oftenthis
occursdepends
onthe
size ofthe predictor, the
specific mechanismbeing
used andthe
behavior
ofthe
programcurrently
being
executed.When
these
mechanismsare
wrong,
abranch
mispredictionis
saidto
have
occurred.This
mispredictionincurs
apenalty
based
on wherein
the
pipelinethe
branch's behavior
andtarget
aredetermined. Figure 2.2
showsthe penalty
for
abranch
misprediction withthe
basic
pipelinefrom
[15].
It
shouldbe
obviousthat
the
length
ofthe
pipeline affectsthis penalty
andthat
deeper
pipelines wouldbenefit from
more2.1.5
Multiple Issue Techniques
Until
this
point,
the
mechanismslooked
athave been
trying
to
achievethe
theoretical
ideal
of oneinstructions
percycle(IPC).
In
orderto
improve
performancebeyond
this point, the
processor mustbe
ableto take
advantage ofthe
instruction level
parallelism(ILP)
in
programsby
issuing
morethan
oneinstruction
every
cycle.There
aretwo techniques that
allowthis:
superscalar processorsand
very
long
instruction
word(VLIW)
processors[15].
Superscalar
processorsaredesigned
to
allow a variable number ofinstructions
to
be issued
eachclock cycle.
These instructions
canbe
chosen eitherstatically
by
the
compilerordynamically
using
techniques
similarto those
usedfor
out-of-order execution(see Section 2.1.3). Modern
superscalarprocessors can
usually issue
a maximum ofthree to
four instructions
each cyclefrom
the
executionwindow,
or allinstructions
that
areready
to
be issued
and arewaiting for
execution resources.The
number of
instructions in
the
execution window each cycle variesbecause
ofdependencies,
andthe
number
actually issued
variesbased
onthe availability
ofthe
processor's execution resources.A
superscalar processoris usually implemented
by
allowing
certain classes ofinstructions
to
be
issued in
the
same clockcycle,
assuming
that there
are nodependencies between
them.
An
exampleof
this
wouldbe allowing
aninteger
arithmeticinstruction
and afloating-point instruction
to
be
issued in
the
same cycle.It is
also commonto
allow amemory
instruction,
aload
or astore, to
be
issued
eachcycle,
in
additionto the
otherinstructions
that
arebeing
issued.
Other
practices areto
have
morethan
onefunctional
unit ofa giventype to
allow moreinstructions
to
be issued in
asingle clock cycle and
to
pipelinethe
functional
units where possibleto
allowthe
issuing
oflong
latency
instructions
each clock cycle.The
complexity
addedto
adesign in making it
adynamically
issuing
superscalar processor canbe
substantial.VLIW
processorstry
to
offsetthis
hardware complexity
by
having
the
compilerstatically group
instructions
that
can execute atthe
sametime.
A
typical
instruction for
this type
of processor might
include
two
integer,
afloating-point,
amemory
referenceand abranch
operation.If
the
compiler cannotfind
an operationto
fill
one ofthese
slotsin
the
instruction,
aNOP
is
used.Both
techniques
allowing
multipleissue
ofinstructions
arein
usein
commercial processors.The
majority
ofthe currently
available general purpose processors are superscalardesigns.
These
include Compaq's
Alpha,
HP's PA-RISC
andthe
Motorola/IBM PowerPC. VLIW has found
ahome
in
special purpose processors.One
example ofthis
is
the
MAP 1000 digital
signal processor(DSP)
from
Equator.
In
the
general purposemarket,
Intel
andHP
arecurrently
developing
processorsbased
ontheir
explicitly
parallelinstruction computing
(EPIC)
technology,
whichis
basically
aVLIW
approach.2.1.6
The
Memory-Hierarchy
It
was recognizedearly
onthat,
if
giventhe
choice, programmers would want unlimited amountsof
fast
memory.This is impractical
for
most applicationsfor
many reasons,
notthe
least
of whichis
the
prohibitive costthis
wouldincur.
Fortunately,
the
principles of spatial andtemporal
locality
were
discovered. Temporal
locality
statesthat
programstend to
reusedata
andinstructions
that
have been
recently
used.Spatial
locality
statesthat
items
located
at addressesthat
arephysically
close
to
one another areusually
referenced closetogether
in
time
[15].
The
locality
principles were usedto
develop
the
idea
of amemory
hierarchy.
The
usefulness ofthe memory
hierarchy
is
that,
if
a small amount offast
memory
is
placed"close"
to the
processorand alarger
amount of slowermemory
is
place"further"
from
the processor,
the total memory
system ofthe
computer willhave
performance closeto that
ofthe
fast
memory
and a cost close
to that
ofthe
slow memory.The
faster
ofthese
memories are called caches.The
smallest,
and "closest"to the processor,
is
known
asthe
first
level,
orLI,
cache.Additional
levels
of cachebetween
the
processor andthe
mainmemory
are numberedsuccessively,
withthe
second
level,
orL2,
cachebeing
larger
than the
LI
cache and "farther"from
the
processor.This
pattern cancontinue
indefinitely,
though
few
processors use morethan
three
levels. The
hierarchy
is
accessedin
such away that the
contentsof eachlevel
ofthe memory
hierarchy
is
asuperset ofthe
next
level
up the
hierarchy.
(Using
this convention, the
registerfile
ofthe
processoris level 0
andis
considered atthe
"top" ofthe
hierarchy
andthe
mainmemory is
considered atthe
"bottom".See
Figure 2.3 for
a common representation of amemory
hierarchy.)
A
cacheis
addressedby
blocks.
A block is
several wordslong
andis
the
unit ofmemory
that
the
cache operates with whenaccessing
the
nextlevel
ofthe
memory hierarchy.
There
arethree
Register
File
Figure 2.3: Abstraction
of amemory
hierarchy
ways
that
blocks
canbe
placedin
a cache.The
easiestto
implement is direct
mapped.In
this
type
of cache each address canonly
map to
oneblock. The
secondtype
of placement schemeis full
associative.
This
allows an addressto
be
placedin any block in
the
cache.The
third
placementscheme,
setassociative,
is
the
generalform
ofthese two
specific methods.With
this
placementalgorithm,
amemory
address mapsto
a set and canbe
placedin any block in
that
set.When
a set contains nblocks,
the
cacheis
saidto
be n-way
set associative.The
vastmajority
of cachescurrently
in
use are eitherdirect
mapped,
2-way
set associative or4-way
setassociative; the
other alternativesdo
not producea significant performanceincrease
[15].
Since
the
locality
principlesonly describe
tendencies
ofprograms, the
information
that
is
neededis
not always availablein
a specificlevel
of cache.When
the
information
requestedis
not presentin
the
currentlevel
ofcache,
a cache misshas
occurred.The
following
list describes
the three types
of cache misses
[15]:
compulsory
missThese
misses occur onthe very
first
accessto
a cacheblock
sincethe
block
cannotbe in
the
cache yet.capacity
missThese
misses occur whenthe
cacheis
notlarge
enoughto
hold
allthe
blocks
neededduring
execution of a program.conflict miss
These
misses occurfor direct
mapped and set associative caches whentoo
many
blocks
map to the
same set.There is
noway to
removethe
Compulsory
misses.Capacity
andConflict
misses canbe
reducedby
increasing
the
size ofthe
cache.Conflict
misses canbe
reducedby increasing
the associativity
ofthe
cache.2.2
Overcoming
the
Processor/Memory
Speed
Gap
Advances
in
both
the
design
andthe
manufacture of microprocessorshas
created anever-growing
gap
between
the
performance ofthe
microprocessor andthe memory that the
processor needs.While
cache canhelp
to
economically hide
some ofthis gap
(see
Section
2.1.6),
the
differing
rates at which processors andmemory
areadvancing is causing
this gap to
widen at anincreasing
rate.This
trend
has
causedresearchinto
varioustechniques
ofhiding
that
gap.In
the
following
sections,
I
will give abrief
overview of some ofthese
techniques.
2.2.1
Wide Superscalar
andSuperspeculative Processors
Researchers
atboth
the
University
ofMichigan
(UM)
andCarnegie Mellon
University
(CMU)
areattempting
to
get more performance out ofthe
basic design
ofthe
current modernRISC
processorby
using
techniques
to
expose moreILP in
programs[26,
18].
The
team
atUM has
arguedthat
the
highest level
of performance willbe
attainedby
using
very
high
performance processorsin
a multiprocessor configuration andis
designing
a superscalar processor capable ofissuing
a maximum ofbetween 16
and32 instructions
each cyclefrom
a pool of closeto
2,000 instructions in
the
execution window.
Some
ofthe
mechanismsthat
they
proposeusing
to
effectively
use a processor ofthis
size are:a
trace cache,
whichis
a cacheto
storeup to
anissue-width's
worth ofinstructions
across multiplebranches;
a
Multi-Hybrid branch
predictorthat
uses several smallbranch
predictorsthat
perform wellon specific
types
ofbranches,
one of whichis
abuffer for
the target
addresses ofindirect
jumps;
the
ability
to
fetch
control-independentinstructions
that
come after abranch
andto
delay
the
fetching
ofinstructions
that
follow
ahard-to-predict
branch;
the
use ofdata
andinstruction
prefetching,
prediction ofdata
values anddependencies be
tween
loads
and stores;24
to
48 FUs
clusteredinto
groups ofthree to
five
unitsto
reducedelays
onthe
commondata
bus (CDB).
Simulations
ofthis
architecturehave
achieved anIPC
of closeto
13
[26].
The
CMU
project,
calledSuperflow,
is expanding
the
capabilities of current commercial processors while
adding
aggressivepredictive capabilities.Some
ofthe
characteristics ofthis
architectureinclude:
an
issue
widthof32;
a
128-entry
ROB;
64 KB data
andinstruction
caches with a10
cycle missdelay
to the
L2
cache;
a
128-entry,
fully
associative store queue.Added
to
this,
relatively,
conventional superscalararchitecture,
value anddependence
predictionmechanisms are used.
Alias
predictionis
also used.This
is
a mechanismto
predict aload
address.A
trace
cacheis
providedin
additionto the
standardinstruction,
data
and secondlevel
caches aswellasapattern
history
table
(PHT). Simulations
ofthe
Superflow
processorhave
shownsignificantimprovement
in
sustainedIPC.
2.2.2
Simultaneous
Subordinate
Microthreading
Like
the
wide superscalar and superspeculativeefforts,
Simultaneous Subordinate
Microthreading
(SSMT)
focuses
onimproving
the
performance of a singlethread
[6].
It
attemptsto
do
this
by
executing
microcodethreads to improve
the
branch
prediction,
cachebehavior
and prefetcheffectiveness of
the
processor.Since
the
performance of modern processorsfalls
short ofthe
ideal
made possible
by
assuming
perfect operation ofthese
mechanisms,Chappell,
et. al. proposethat
executing
microcodethat
improves
the
effectiveness ofthese
mechanisms willimprove
the
overallperformanceof
the
processor.The
codefor
these
microthreadsis
storedin dedicated,
on-chip
random accessmemory
(RAM)
called microRAM.
A
microthread canbe
activatedthrough
eithera specialinstruction
addedto the
Instruction
Set Architecture
(ISA)
orthrough
pre-defined events.These
pre-defined events spawna microthread
in
muchthe
sameway
aninterrupt
spawns ahandler.
Some
ofthe
advantagesto
using
microthreads are:complex algorithms can
be
used withoutincreasing
hardware
complexity,
sincethe
microthreadsuse
the
existing
datapath;
the
optimizations arevery
flexible,
being
tuned to
specific applications and processorimple
mentations, or
disabled
when not needed;use of microRAM means
that the
microthreaddoes
not competefor fetch bandwidth
orI-cache
blocks;
the
microthreads are writtenin
aninternal
instruction
set,
allowing
the
ISA
to
remain untouched,
withthe
exception ofaSPAWN
instruction
to
launch
a microthread.This framework
allowsthe microthreading
mechanismto
be
very
flexible. The
use of microthreadsrequires support
from
the
compilerto
load
the
microRAM andto
spawnthe
microthreads.It is
assumed
that
someform
ofprofiling
willbe
usedas part ofthe
compilation process.Some
supportfrom
the
operating
system(OS)
is
also neededto
deal
withthe
addressing
ofthe
microRAM.The
only
modificationsto the
processorthat
are needed arethe
addition ofthe microRAM, the
ability
to
issue
instructions
from
that
microRAM and supportfor
the
context of atleast
one microthread.In
[6],
Chappell,
et. al.demonstrate
the
use ofSSMT
by
creating
a softwarePAg
branch
predictor
using
abranch
history
table
(BHT)
and aPHT. In
orderto
keep
the
microthreadfrom
interfering
withthe
mainthread
too much, this
predictor wasonly
used onbranches
that the
hardware branch
prediction mechanismdoes
nothandle
well.Simulations in
whichthe
SPECint95
benchmarks
were run showedthat the
microthread couldsignificantly
improve
the
performance ofsome of
the
programs.However,
on othersit
either produced noimprovement
or resultedin
a slightdecrease
in
performance.2.2.3
Chip
Multiprocessors
The techniques
that
have been
examined sofar
are allfocused
onimproving
the
performance of asingle
thread.
The
widesuperscalar/superspeculativeapproachtries to
do
this through
mechanismsthat
eitherfind
or create moreILP,
evenif
there
is
not much moreto
find,
orby
using
aggressivepredictive
techniques.
The
SSMT
technique
hopes
to
improve
performanceby
running
microthreadsaimed at
improving
the
performance of some ofthe
hardware
already
presentin
the
processorin
parallel with
the primary thread.
The
hope here is
that the
additionalload
onthe
processorresources will
be
compensatedfor
by
the
gainin
performance.On
the
otherhand,
chip
multiprocessors(CMPs)
attemptto
improve
the
performance ofthe
processor
by
exploiting
thread
level
parallelism(TLP)
[14,
25]. The idea is
to
place multiple copiesof a simple
RISC
core onthe
samedie. This
allowsthe
processorsto
share ahigh
speed connectionto the
sameL2
cache,
whichis
also placed onthe
die. In
mostcases,
better
performanceis
gainedby
each corehaving
its
ownLI
cacheinstead
of allthe
coressharing
aLI
cache[24].
There is
little
to
nodegradation
of performancefor
a singlethread
because
the
RISC
cores,
eventhough
they
areless
aggressive,
canbe
runat ahigher
frequency. Another
advantage ofCMPs is
that
they
are
inherently
divided into
relatively small, mostly
independent
components.This
characteristicleads
to the
elimination ofmany
ofthe
long-latency
interconnects
that
canbe found
on modernprocessors,
thus eliminating many
ofthe
timing
problems presentin
these
designs.
There
aredrawbacks
to this
architecturehowever. The
most obviousis
that
executionresources,
i.e. functional
units,
are not sharedbetween
the
cores.This
leads
to
large
portions ofthe
transistors
on
the
die
notbeing
used whenthere
is only
a singlethread
available.Another
resultofthis
inability
to
shareFUs
is
that
athread
couldbe
stalled on one corebecause
of alack
ofFUs,
eventhough
another core
has
a usableFU
free. There is
one processor resourcethat the
cores share:memory
bandwidth. Whether
this
willcausea problemdepends
onthe memory
access patternofthe threads
running
onthe
CMP
andthe
memory bandwidth
made availableto the
chip.2.2.4
Multithreading
Architectures
Designed
aroundthe
samebasic
set ofideals
that
CMPs
are. multithreaded architectures(MTAs)
create a processor
that
is
capable ofexecuting
andkeeping
track
of severalthreads
or programswith asingle
die,
thus
taking
advantage ofthe
TLP
available.There is
onefundamental
difference,
however:
MTAs
share processor resourcesamong
the threads
instead
ofhaving
several processorcores.
There
arethree
groups ofMTAs:
fine-grained,
coarse-grained and simultaneous, each willbe
described
below.
Fine-Grained
Multithreading
In
afine-grained
multithreadedarchitecture, the
processoris
capable ofholding
the
contextsfor
several
threads
or programs at atime.
Each
cycle, a newthread
gets control ofthe
processor[20.
2].
There
areusually
restrictionsto
whichthreads
are eligibleto take
control.For
instance,
in
the
Tera
computersystem,
eachthread
canonly
have
oneinstruction in
the
pipeline atthe
sametime
and an
outstanding
cache miss makes athread
ineligible
to
gain control[2].
The Tera
systemis
acommercial multiprocessor supercomputer meant
for
usein
a multi-user scientific environment.It
is
capable ofrunning
existing
scientificcode,
in
many
casesonly needing
a simple recompileto
do
so.
It has been
shownto
decrease
the
executiontime
for
several standard scientific workloads andto
be
much easierto
useas a platformto<