Rochester Institute of Technology
RIT Scholar Works
Theses
Thesis/Dissertation Collections
5-20-1986
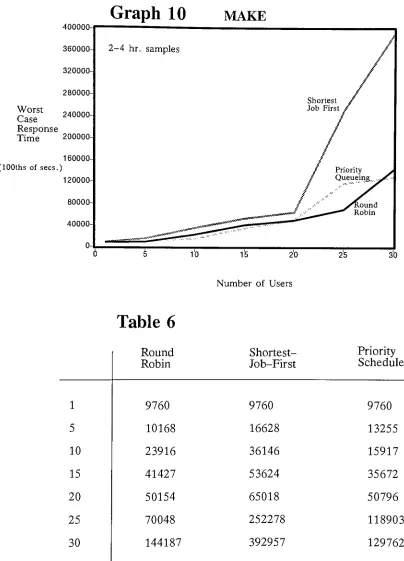
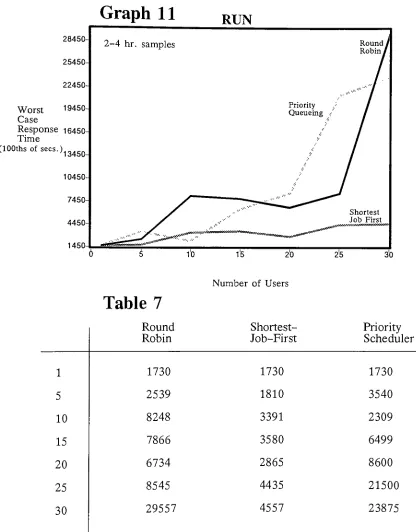
An analysis of variation in response time of CPU
scheduling algorithms as a function of load: a
simulation
John DeHority
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion
in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact
.
Recommended Citation
An Analysis of Variation in Response Time of
CPU Scheduling Algorithms as a Function of Load:
A Simulation
by: John W.B. DeHority
May 20, 1986
Rochester Institute of Technology
A thesis, submitted to
The Faculty of the School of Computer Science and Technology,
in partial fulfillment of the requirements for the degree of
Masters of Science
in
Computer Science.
Approved by:
And rew Kitchen
Prof. Andrew Kitchen
Warren R. Carithers
Prof. Warren Carithers
Walter Wolf
Title:
An Analysis of Variation in Response Time of CPU Scheduling
Algorithms as a Function of Load:
A Simulation
I, John W. B. DeHority, prefer to be contacted each time a request for
reproduction is made.
I
can be reached at the following address:
May 20, 1986
-This
thesis analyzes agroup
of cpuscheduling
algorithms on thebasis
ofthe variation
in
response time that resultsfrom
changesin
the systemload.
The
results ofthis
study quantify
thedifferential degradation
of performance acrossjob
categories.
The job
categoriesinclude
short-burstinteractive jobs
as well as cpuintensive jobs.
For
eachjob type,
measurements were made of averagejob
turnaround
time,
weighted average turn-aroundtime,
and worst case response time.Additional
statistics gatheredinclude:
ready-to-run queue size, cpu utilization andthroughput.
The
three cpuscheduling
algorithms compared are round-robin, shortest-job-first, and a multi-queue
priority
scheduler.The
analysis utilizes a modelencoded
in
'C
which simulates aninteractive
time-sharing
user community.The
model allows
scheduling
algorithms tobe
measured with a controlled workload.The
workloadis
variedby
selecting
the number of simulated users who aresharing
Computing
Review Subject Codes
The
following
subject classification codesfrom The
New
(1982)
Computing
Reviews
Classification
System,
publishedby
theACM apply
to this project:C.4
Performance
ofSystems
Measurement Techniques
Modeling
Techniques
Performance
attributesD.4
Operating
Systems
D.4.1
Process Management
Scheduling
MC68000
is
a trademark ofMotorola Inc.
Sun 2
andSun
2/120
are trademarks ofSun
Microsystems,
Inc.
Sun
Workstation
is
a registered trademark ofSun
Microsystems,
Inc.
UNIX
is
a registered trademark ofAT.
&
T. Bell Laboratories.
VAX,
PDP
11/23,
andProfessional 350
are registered trademarks ofDigital
Equipment Corporation
VENIX
is
a trademark ofVenturCom,
Inc.
Top billing
must go tomy
wife,Carolyn,
for her unfailing
support andencouragement,
as well asher keen
eyein
proof reading.I
oweher my
sincerestthanks
for seeing
me through the whole process.Thanks
are alsodue
to the three members ofmy
thesis committee,Andrew
Kitchen,
thechairperson;
Warren
Carithers
andWalter Wolf.
Their
analysis,guidance and support
has
been
valuablein giving
shape anddirection
to the project.
I
also want to thankmy
colleaguesin
theKEEPS department
atEastman
Kodak for contributing
their "histories" to thedata
gatheredfor
the calibration ofthe model.
Table
ofContents
Abstract
i
A.C.M.
Subject Codes
ii
Acknowledgments
iii
Table
ofContents
iv
Introduction
andBackground
1
1.1
The Problem
1
1.2
History
andTheory
2
Project
Description
16
2.1
General Considerations
16
2.2
The Advantages
andLimitations
of aModel
17
2.3
A
Functional Description
18
2.3.1
The Workload
19
2.3.2
The
"Simulation
Engine"22
2.3.3
Coming
toTerms
24
2.3.4
Statistics
System
andJob Related
2.4
Limitations
of theModel
28
2.5
Input
to theModel
29
2.6
Output From
theModel
30
2.7
Validation
andVerification
of theModel
33
System
Specifications
37
3.1
Two Perspectives To Consider
37
3.1.1
The
Modeled System
37
3.1.2
The Simulation
38
3.2
Organization
of theModel
40
3.3
Implementing
theModel
42
Validation and
Verification
of theModel
45
4.1
The Modeled
Commands
45
4.2
Validating
theInput
47
4.3
Validating
theOutput
48
4.4
Validating
theJob Mix
51
Results
andDiscussion
52
5.4
Priority
scheduler56
6.
Comparing
theAlgorithms
59
6.1
The Cost
ofScheduling
71
7.
Discrepancies
andShortcomings
of theModel
74
8.
Conclusions
76
9.
Bibliography
77
Appendix A
Qualifications
andPersonal Background
Appendix B
Model
Input
Appendix
C
Sample
Output
An
Analysis
of
Variation
In Response Time Of
CPU
Scheduling
Algorithms As A
Function
of
Load: A
Simulation
1.
Introduction
andBackground
1.1.
The Problem
Since
the advent oftime-sharing
in
computer systems, the topic ofscheduling
the centralprocessing
unit(cpu)
has
been
one ofcontinuing interest.
For my
masters thesis topicI
propose to model and analyze agroup
of cpuscheduling
algorithms on thebasis
of the variationin
response time as afunction
of system
load. Algorithms for scheduling
the cpuhave been
analyzedin many
different
ways,but
uponreviewing
theliterature
it
is
evident that variationin
response time
is
onedimension
of performance measurement thathas
notbeen
thoroughly
studied or quantified.Variation
in
response timeis
a relevantissue
in
atime-sharing
environment.I
amusing
responsetime to meanthe elapsed timefrom
thejob
submissiontime toits
completion time.Anyone
whohas
usedtheVAXes
atR.I.T.
nearthe end ofthequarter can attest to the
reality
of variationin
system performance and to therelevance ofthis
issue. The
questionhas
been
asked,but
notanswered,
elsewhere.It
has
alsobeen
suggested thatfor
interactive
systems(such
astime-sharing
systems),it is
moreimportant
to minimize the variancein
the response time than to minimize the average response time.A
system with reasonable and predictable response timemay
be
considered
better
than a system whichis faster
on theaverage,
but
highly
variable.There
has
been
little
workdone
on cpuscheduling
1.2.
History
andTheory
The
performance of the computer systems we useday
in
andday
outhas
been
a subject ofintense interest
for
computer programmers, engineers,buyers,
managers and users almost
from
thebeginning.
The
measurement andoptimization of computer system performance
has
consequently
received a greatdeal
of attention and analysis.Someone
from
each of the groupsjust listed
has
atone time or another set out to analyze the performance of their computer system.
Each
of these groupsis
likely
to offer adifferent
assessment of the same systembecause
they
eachhave different
requirements and aims.They
may
each choosedifferent
indices
of performancereflecting
their various perspectives on theproblem.
The
greatest concern of a computer engineermay be
the total throughput ofthe computer system that
is
being
designed.
Throughput
is
a measure of thenumber of
jobs
that are completed per unit of time.A
manager of alarge
computing
center, on the otherhand,
might voice concern about cpu utilization.Utilization
is
calculated as the percentage of the time that the cpuis actually
busy
processing job
requests.This
concern overmaximizing
utilization was morelikely
to
be
raisedin
an earlier period when cpu time wasvery expensive,
andit
washighly
desirable
to maximize cpu utilization.It
is
still a valid performancecriterion.
Many
abuyer,
for lack
of attentionto utilization,has
purchased a systemwhich either
fails
to meet thedemands
of the organization,causing
greatbacklogs
of work, or
has
purchased a system thatfar
exceeds the organization's needs.The
latter buyer
now owns ahigh
performance systemin
which the cpuis idle
alarge
part of the
time,
even when there are users on the system.The
response time of- 3
The
needfor,
andinterest
in,
short-termjob
scheduling
waslikely
born
theday
someone noted that a computer's centralprocessing
unit satidle
a goodportion of the time
if
it
wasonly
given a singlejob
to work onduring
any
timeinterval. The
processor would experiencefrequent
idle
periods while the currentjob
waswaiting
for input
or output.It became
immediately
apparent that totalsystem throughput could
be improved
and cpu utilization couldsimultaneously be
improved
by
overlapping jobs
in
such away
that onejob
couldbe running
whileanother was
waiting for
input
or output.Charles
Sauer
andMani
Chandy
describe
the consequences of this
discovery:
A
major aspect of most moderncomputing
systemsis
thesharing of
resources.
The
classicillustration
is
the multiprogrammedoperating
system.
Put
simply, the objective ofmultiprogramming
is
tohave
oneprogram's use of a processor
overlap
with otherprograms'
use of
I/O
devices
so that several programsmay
share the machine, with eachmaking
progress similar to the progressit
would makeif it had
soleuse of the machine.
This
sharing
of resources reduces the costattributed to each program,
i.e.,
if
a programhas
sole use of themachine,
it
mustbe
chargedfor
theidle
time of resources as well asthe
busy
time.In
theidealized multiprogramming
system, programsare
only
chargedfor
the time spentusing
resources.However,
thesharing
of resourcesinherently
causes contentionfor
resources;if
twoprograms need the processor, one must wait.
[
Sauer
andChandy
1981
]
The
advent ofinteractive
time-sharing
computer systemsfocused
attentionsharply
upon this contentionfor
resources as one or more of the users on a systemwere
forced
to waitfor
their results.The
daily
user of aninteractive
computersystem
is
likely
to choose minimal response time or uniform response time as themost
desirable
or significant performance criterion.The
needfor
predictableuniform response time
has been
recognized as animportant
performance criterionin
thedesign
ofinteractive
computer systems.Bill
Joy,
ofSun
Microcomputers,
in
primary
the need
for "predictable
responsetime."
The
interactive
user'sfirst
choice wouldbe
to achieve thatideal
conditionSauer
andChandy
[1981]
described,
where eachjob
makes progress as thoughit
had
sole use of the machine.Realizing
that thisis
unlikely, the second choicewould
be for
the system to respondin
a uniform manner across time to therepetition of similar requests.
This
uniformity
of responseis
anotherway
ofdescribing
a minimal variationin
response time.Minimizing
variationin
responsetime
has
been
noted as animportant
goalfor designers
ofinteractive
time-sharing
systems.
Consider
aMTVRS
[
multi-programmedinteractive
virtual-memory
reference system
]
in
which response times tolight
commandsvary
from 1
to15
seconds(
a totaldeviation
of14
seconds),
with ameanvalue of
4
seconds and a standarddeviation
of6
seconds.The high
variability
of response timein
thisinstallation
lowers
the usersatisfaction
level,
and the systemis
likely
tobe
usedineffectively.
When
the standarddeviation
appears toolarge
with respect to themean, a thorough analysis of the system's performance should
be
carried out, since the system
is
likely
tobe loaded in
an anomalousway
or tobe
inadequately
sized.[
Ferrari
et. al.1983
]
Algorithms for scheduling
the cpuhave
been
analyzed on thebasis
of mostof the criteria that
have already been
mentioned:throughput,
cpuutilization,
andaverage response time.
But
uponreviewing
theliterature it is
evident thatvariationin
response timeis
onedimension
of performance measurement thathas
notbeen
thoroughly
studied or quantified.Numerous scheduling
algorithmshave been
analyzed on thebasis
of these-5
-"shortest-remaining-time-first"
(S.R.T.)
scheduling
algorithm yields theminimum average
waiting
time.For
example consider the simple case ofjust
twoarriving jobs
tobe
scheduled.Moving
the shorterjob
ahead of thelonger
job
willdecrease
thewaiting
time of the shorterjob
more thanit
willincrease
thewaiting
time of the
longer job. Thus
the averagewaiting
timehas
been
reduced.At least in
terms of average
waiting
time,
scheduling
thejob
with the shortestremaining
needfirst is provably
optimal.How
toimplement
that algorithmis
another matterentirely.
In
the real world thejob
schedulerrarely
knows
in
advance the serviceneeds of an
arriving job.
Numerous heuristic
methods ofestimating
the serviceneeds of
arriving
jobs have
been
developed,
but
computershave
not yetbeen
taught omniscience.
The
shortest-remaining
-timefirst
algorithm remains abenchmark for
algorithms which seek to minimize average response time.Most
performance measures reported
in
theliterature
are"...
average values(
e.g.average response time
)
rather thandistributional
information
(e.g.
the90
th.percentile of response times).
Thus
the word average shouldbe
understood evenif
it
is
omitted."[
Peterson
andSilberschatz 1983
]
What
happens
to that averagewaiting
timein
atime-sharing
environment asthe
load
on the systemincreases?
This is
animportant,
yet unexamined question.The initial
answerto this questionis
intuitively
obvious.As
theload
on a systemis
increased
the averagewaiting
time willinevitably
increase
at some point.Again,
note the average
waiting
time willincrease. It
is
moredifficult
todetermine
whatwill
happen
to thedistribution
ofwaiting
times, particularly
by
job
type.Consider
avery
lightly
loaded
system, where the cpu utilizationis
solow
that the cpuis idle
alarge
percent of the time.To
keep
thisinitial
analysissimple,
let's further
assumethat we
have
ahomogeneous
job
mix thatis,
thejobs
have
very
similarthroughput to
increase,
and cpu utilization toincrease
also, with almost no changein
the response timefor
any
of thejobs.
However,
as soon as themulti-programming
level
reaches the threshold wherejobs
are simultaneouslycontending for
the use of the cpu, thenwaiting
timeis
introduced
and the averageresponse time will
inevitably
begin
toincrease.
The
function
that relates thechanges
in
response time to the systemload
(i.e.
the number ofjobs),
woulddescribe
the variationin
response timefor
thishomogeneous
population.Graph I
represents the change
in
response time we wouldtypically
find
in
this simple case.- 7
18
16
14
12
Turnaround *, 0
Time
Minutes
8
Response
Time
Programs/minute Load
[
Ferrari et. al. 1983]
Graph
1
This
simple case,involving
a singlejob type,
couldbe
analyzed through anapplication of
Little's Law.
[
Little 1961
]
If N
represents the average number of requestsin
the system,R
represents the average system residence time perrequest,
andX
representsthroughput,
thenLittle's
Law
stated thatN
=XR.
The
average number ofrequestsin
the systemis
equal to the product of thethroughput
and the average time spentin
the systemby
a request.In
the simpleillustration
givenmaximum
capacity
the average system residence time per request willincrease,
along
with aproportionalincrease
in
the average number ofrequestsin
the system.In
other words the system's queues will grow and response timealong
withit.
Little's
Law
has
given rise to a number of corollaries usefulin
the analysis ofsystem performance.
One
of these corollaries usefulin
the analysis ofinteractive
computer systems
is
theResponse
Time
Law,
[
Lazowska
et. al.1984
]
which saysthat the response time
(R)
is
equal to the number of users on the system(N)
divided
by
the system's throughput(X)
minus the average time that each userspends
thinking
between
job
requests(
appropriately
named'Z').
The Response Time Law
N
R
=X
-Z
Suppose
that weinitially
have
40
users on the system, which can complete2
jobs
per second, and that each user spends an average of15
secondsthinking
between jobs. The Response Time Law
tells us that the users willhave
to wait anaverage of
5
secondsfor
the system to respond and complete theirjob.
If
thenumber of users
is
doubled
thislaw
tells us that the response time willincrease
to25
seconds!This
analysis utilizes a time averaged valuefor
throughput,
thatrepresents some numberof completed
jobs
in
a period of time.The
analysis growsmore complex than these simple
illustrations
when welook
at examples that aremore representative of modern
time-sharing
systems.In
order toimprove
response-9
under
light
to moderateloads. In
Other words, the cpu andI/O
subsystem sitidle
asignificant portion ofthe time under these reduced
loads. This
allows the system torespond to the
initial
increase
in
workloadby
anincrease
in
facility
utilization and acorresponding increase
in
total system throughput.The
examplejust
givenheld
the throughput
constant,
whichled
to afive-fold increase
in
response time whenthe number of users
doubled.
If
job
throughput alsodoubled
then there wouldbe
no net change
in
average response time.As
processor timebecomes
less
andless
expensiveit
willbecome
increasingly
common to size systems sothat cpu utilizationis
low
underthe typicalexpected
operating
load.
Thus
thedramatic
increase
in
response time thataccompanies an
increase
in
the number of users willbe partially
offsetby
anincrease in
throughput.But it
is
notrealisticto assume thatthroughput will, or can,double
to matchevery
increase
in
the user population, orin
job
demands. At
somepoint
in every
system the addition of more users, or anincrease
in
servicedemands for
thejobs
submitted, willlead
tofull
utilization of onefacility
oranother within the system.
This
point offull
utilization of afacility
is
called thesaturation point.
When
that saturation pointis
reached, throughputlevels
off andresponse times
begin
toincrease rapidly
as the queuedbacklog
ofjobs
grows atthis critical
facility.
This
facility
is
thenlabeled
the "bottleneck"in
the system.Traditionally
system performance analysis and optimizationinvolves
a searchfor
this
"bottleneck"
and
its
abolition or reduction.Performance
analysishas been
described
as the abolition or reductionin backlogs
causedby
peakloads
and thepostponement of time when workload
increases
will saturate the systemforcing
its
expansion or replacement.
The
systems analyst attempts toidentify
these"bottlenecks"
and either
"widen"
them or eliminate them.
The
system will thenbe
bottleneck
willdefine
the newlimits
of system performance.[
Ferrari
et. al.1983
]
The
analysis thusfar has
treated alljobs
equally, withoutmaking
any
differentiations
ofjob
categories.It
should come as no surprise thatin many
systems thejobs
are not uniformin
thedemands
they
place upon the system.When
we make thedetermination
that variousjob
types shouldbe
treateddifferently
within the computer system on thebasis
of thedifferential demands for
service,
then wehave
drastically
increased
thecomplexity
of the analysis.We have
arelatively
goodunderstanding
of the performance of systemsdesigned
to meetspecifically described
loading
conditions,particularly
thoseloads
having
small variation.On
the otherhand,
those systems required to meet unspecified
loads,
withlarge
variations
in
theloading
conditions,have
proved tobe
difficult
tobuild. With
respect to theselatter
systems wefind
that we arein
a relative state ofignorance.
[
Lynch 1972
]
There have been many scheduling
algorithmsdeveloped
over the years to meetvarying
needs of thecomputing
community.They
have
rangedfrom
thevery
simplefirst-come-first-serve
algorithms tovery
sophisticated multi-levelfeedback
and
aging
algorithms.These
algorithmshave
allbeen
thoroughly
analyzed on thebasis
of cpu utilization, maximumthroughput,
average turn-around time andaverage response time.
Peterson
andSilberschatz
[
1983
]
stated"little
workhad
been
done
onscheduling
algorithms to minimizevariance."
A
review of thecomputer science
literature
revealed that this void observedby
Peterson
andSilberschatz has
not yetbeen filled. An
analysis ofscheduling
algorithms on thebasis
ofhow
response time changes as afunction
of systemload has
notbeen
reported
in
the literature.The
performance of a number of the simpler traditional algorithms canbe
11
first-come-first-serve
algorithm,
gives the use of the cpu overto thefirst job
thatarrives.
The
performance of this algorithmis
known
tobe widely
variable andentirely
dependent
upon the orderin
whichjobs
arrive.Smaller
jobs
will tend toform
a "convoy"behind
thelarger
jobs
in
the queue.Average
response timeis
certainly
notminimal,
and canvary
substantially
depending
upon the order ofarrival.
The
average response time of this algorithm varieswidely
evenbefore
variations
in
systemload
are takeninto
consideration.First-come-first-serve
scheduling,
whileit
may
be
the easiest algorithm to encode,is
probably
theleast
satisfactory.
The
excellent performance of the shortest-job-first algorithmhas
already
been
reported."It is
intuitively
optimal with respect to mean response time sinceit
maximizes the number of response times completed
in
a giveninterval
oftime."
[
Sauer
andChandy
1981
]
It
willconsistently
yield the minimum possible averageresponse time.
The
good newsis
that thisquality
wouldapply
under a wide rangeof
loading
conditions.The bad
newsis
that,
"at
the cpu(short-term)
scheduling
level
it is
unimplementable."There is
noway
toknow
thelength
of the next cpuburst.
One
approach
is
totry
to approximateSJF
scheduling.We may
notknow
the
length
of the next cpuburst,
but
wemay be
able to predictits
value.
We
would expect that the next cpuburst
willbe
similarin
length
to the previous ones.Thus
by
computing
an approximation ofthe
length
of the next cpuburst,
we can pickthejob
with the shortestpredicted cpu
burst.
[
Peterson
andSilberschatz
1983
]
In
abatch
environment, where thehistorical
timedemands
ofregularly
submitted
jobs
are wellknown,
it is
common practice to use a shortest-job-firstordering
of submittedjobs. At
thelevel
of short-term cpuscheduling
a number ofcpu
burst.
By
keeping
track of thelengths
of the most recent pastbursts for
aparticular
job
a reasonable prediction of the nextburst
canbe
madeby
taking
anexponential average of the previous
bursts.
In
the controlled world of a model we calculate eventsin
advance so thatwhen a
job
arrives at the schedulerits
needs arealready known. Thus
the modelerhas
theartificially
constructedopportunity
tostudy
the performance of a systemunder the
ideal
conditions ofknowing
the needs and nothaving
to predict them through someheuristic
mechanism.The
cpubursts
ofhighly
interactive
jobs,
suchas
file
editing, tend tobe
ofvery
shortduration consisting in
large
part ofprocessing
I/O interrupts.
Shortest-job-first
algorithms should yield adifferential
degradation
of performance acrossjob-types
as systemload
increases.
The
increase
in
response time shouldbe
greatestfor large
compute-boundjobs,
suchas compilation or
"number
crunching"
(like
running
computer models!), andsmaller
for
short-burstinteractive jobs like
editing.Since
weknow empirically from
theResponse Time 1-aw
andLittle's
Law
that the average response time
is
going
toincrease
as systemload increases
thewhole quest
for minimizing
variancein
response timemay
seem atfirst like
thesearch
for
theholy
grail.We know
that something, or someone,has
got to givewhen the system
load increases. No
algorithm can avoid thishard
reality.Different
scheduling
algorithms can change thedifferential
degradation
in
performanceacross
job
types.The operating
systemdesigner
canimplement
administrativepolicy
that will give preference to certainjob
categories over others when thereis
contention
for
the cpu.So
to some extent the question that this thesis raisesis
notpurely
a technical one,but
an administrativepolicy
one as well.Who
gets the- 13
-scheduling
algorithm.These
questions ofpolicy
arerarely
addressedin
theanalysis of
scheduling
algorithms.First-come-first-serve,
with the addition of time quantuminterrupts
becomes
round-robin scheduling.This
algorithmdoesn't
yield optimalperformance,
but it is fair. As
theload
increases,
everybody
is
penalizedequally
in
terms of the response time
they
experience.But
such a simple algorithmnaively
ignores
thehuman reality
ofhow
people respond to the machinesthey
use.Users
are more
likely
to tolerate(
maybe even reactfavorably
to)
a system thatthey
experience as
having
uniform and predictable responsetime,
evenif
thatpredictable
level
of responseis
not the optimum thatcouldbe
achievedunderideal
conditions with a
different
algorithm.An
interactive
computer systembuilds up
acertain pattern of responses that people come to expect.
As
performancedeviates
more
widely
from
that expectation, then theusers'
evaluation of the system
becomes
increasingly
negative.Users
of a system thatis
slower,but
predictable,may in
moments ofimpatience
wishfor
afaster
system,but
they
will notdevelop
the antagonism that
begins
when ajob
that"usually
takes afew
seconds",suddenly
takes"much
longer."What
algorithms mightbest satisfy
thesehuman engineering
factors?
The
most
likely
candidates willbe
algorithms that assign priorities tojob
types.Let
meventure
into
the realm ofpolicy for
afew
moments, and statemy
opinion.From
anexperiential perspective,
I
would assert thatnothing
is
morefrustrating
thanhaving
slow response to simple common actions.
Anyone
whohas
everbeen
typing
andfound
thatthey
weresuddenly
many
characters ahead of whatis displayed
on thescreen
knows
thisfrustration.
My
bias
wouldbe
towardscheduling
interactive
jobs,
and short, simple, common commands, ahead ofthe
larger
more"batch
like"jobs.
characteristics of the machines
they
use.Whether
its
theloosening
steering
of anaging
car or theresponse time curve of a computer system, we change our usage toadjust to the performance of these systems.
So
if larger
jobs
aregoing
to run at alower
priority,
we would expect users tofind
ways to make theirjobs
smaller.Making
one's programs moremodular,
so thatonly
small portions need tobe
recompiled,
rather thanrecompiling
entire segments of a program that arelargely
unchanged,
is
onedesirable
change that might resultin
these circumstances.There
areinherent
risksin
theimplementation
ofpriority
schedulers.The
most significant risk
is
starvation.Low
priority
jobs
may
be
totally
denied
access tothe processor
by
asteady
stream ofhigher priority jobs. If
it
appears thatstarvation of
lower
priority
jobs
is
occurring
then remedial actionsmay
be
necessary.
One
optionfor solving
the problem of starvationis
toblend
thepriority
scheduling
withjob
aging.Aging
algorithmsdynamically
change thepriority
ofjobs
so that asjobs
remainin
the system queuesfor
long
periods of time theirpriority gradually increases
with age.An
alternative response to the problem ofstarvation
is
a total reassessment of the utilization of the system, whichmay
wellconclude that the system
is
inadequately
sized to support the current number of users.The
requiredremedy
may be
to reduce the number ofavailableterminals on that system and transfer some of the workload to another system.Another
alternative might
be
todelay
the submission of theselow
priority
jobs
untillightly
loaded
periods, such as the middle of the night.This
alternativeis particularly
practical with
jobs
that require no userinteraction
to complete.Starvation
oflow priority
jobs
may
alsobe
anindication
that the categorieschosen
for
assigningjob
prioritiesmay
need reassessment.The blend
ofjobs
in
the workloadmay have
toomany
jobs
thatfall
into
thescheduling
algorithm'shigh
-15
-frequency
job
typesmay
cause users to alter their patterns of system use, so thatfewer
of thesejobs
are submittedin
thefuture.
The
workload placed on aninteractive
computer systemis
very dynamic. The
community
of usersis continually
finding
new ways to utilize their computers.Every
time we re-tune the performance characteristics of the computer systemin
response to the user community's new workload pattern, we set off another
reverberating
set of ripples through the utilizationhabits
of the user community.The
interactions between
the computer system and the usercommunity
arevery
dynamic
andconstantly
evolving.While
cpujob
scheduling may be
an old topicthat
has been
studied anddebated
many
times, it is
not a closed one.Algorithms
have
been
written, and will continue tobe
written, whichvery adequately
solve theneeds of a particular computer system, under a particular set of workload
characteristics.
But
systems and workloads continue to evolve.New
processor technologies are evolving, massive parallelprocessing
is
appearing in
new systems, andtightly
coupled networks aresharing
workloads.There
is
a continual need to re-evaluate the algorithms which parcel out the utilization of theseevolving
2. Project
Description
2.1.
General
Considerations
Central
processorjob scheduling in
a multi-user,multi-tasking
environmentis
theprimary
focus
of this project.There
are three criteria thatmustbe
satisfiedfor
an adequatetesting
environment.First,
thetesting
environment must alloweasy
modification of thejob scheduling
algorithmin
effect atany
given time.Second,
it
must allowfor
systematic control andvariation of the workloadimposed
upon the system.
And
thirdly, it
must providefor gathering
detailed,
accuratefeedback
of the system's performance under thesevarying
circumstances.It
mustbe
possible to obtain theselatter
measurements withoutaffecting
orcoloring
theperformance ofthe system under study.
It
is
oftenthe case that when performancemonitors are added to an
existing
systemthey
generate an additional workload onthat system which affects the
level
ofthe true workloadthat the monitoris seeking
to measure.
This
is
an undesirable side effect ofstudying
actualexisting
systemswhich
is
difficult
to avoid.The ideal
testing
environmentfor
such astudy
is
notreadily available, if
indeed
it
exists at all.Existing
multi-userinstallations
are not often accessiblefor
kernel
modifications, and were such modifications possiblethere would remain thedifficulties
ofcontrolling
the workload andmeasuring
the system's performance.The difficulties
ofcontrolling
these variables seem to outweigh thebenefits
ofconducting
thestudy
on an actualexisting
system.The
most viable alternativeis
the construction of a computer simulationmodel that satisfies these same criteria.
The
goal thenis
to arrive at acarefully
conceived and constructed qualitative model that will allow several
job
scheduling
17
the
gathering
ofdata
and the generation of statisticsmeasuring
the"system's"
performance without
affecting
thatperformance.A
model canisolate
the operationof the target system
from
the monitors which measureits
performance.This
is
rarely
possiblein
an actual system.2.2.
The
Advantages
andLimitations
ofA
Model
A
modelapproximates,
not replicates, thebehavior
of an actual system.The
modeler must
discern
the essential parameters and characteristics which affect a system's operation and capture those aspectsin
the model'sdesign. "A
modelis
an abstraction of a system: an attemptto
distill,
from
the mass ofdetails
thatis
thesystem
itself,
exactly
those aspects that are essential to the system's behavior."[
Lazowska
et. al.1984
]
It
is
thisvery
abstraction thatis
both
the strength and theweakness of the model.
Due
to this abstraction process the modeldoes
notexactly
replicate thebehavior
of the real systemit
is
derived from.
Instead
the model seeksto provide qualitative representation of the actual system.
The
essentialbehavior
characteristics of the original system must
be
presentin
the modelfor
it
tobe
avalid representation of the original system.
The
model should "reflect the generalbehavior
of a systembut
notnecessarily
specific values ofits
performancemeasures."
[
Lazowska
et. al.1984
]
The
model can provide an efficiency,flexibility
andadaptability
that were not possiblein
the original system.These
benefits
arederived
at the expense ofprecision.
While
a model should provide results that arequalitatively
correct,
they
may
be
quantitativelyimprecise.
These
qualitative results can providethe guidefor
further
investigations whichimplement
in
an actual system thefindings
of themodel.
The
role and purpose ofthe model willhave been
well metif it has
allowed a range of possibilities tohave been
checked withefficiency
and care.The
modelstudy is
scheduling
algorithms,any
computer system.
The
model should prove a valuable means ofgaining insight
into
the relative
behavior
and performance of variousscheduling
algorithms under awide range of
loading
conditions.2.3.
A Functional
Description
The
model mustsatisfy
the three criteria established above.It
should allowdifferent scheduling
algorithms tobe
exchangedeasily
and tested with similarworkloads.
The
model should generate and present thenecessary
statistics toassess the effects of workload on response time and system performance.
There
are several
discrete
functions
that mustbe
performedby
this model.The
implementation
of the model shouldideally
reflect the separation of thesefunctions.
For
example, thefunctions
having
todo
with the generation andreporting
of statistics shouldprobably
be
gathered togetherinto
one module ofcode.
Similarly,
those procedureswhich create and parameterize the user workloadshould
be
gathered together.Organization
of the code at thislevel
willgreatly
19
Project
Description
Input
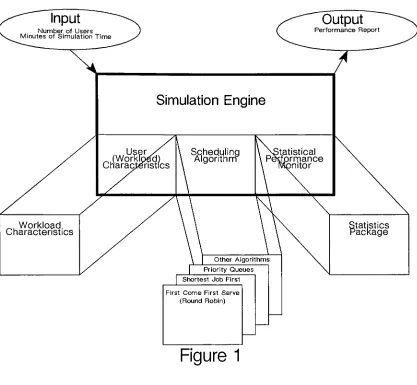
NumberofUsers MinutesofSimulation TimeOutput
Performance ReportSimulation
Engine
(Wortf>e._,
Characteristics^,
Workload.
CharacteristicsScheduling
Algorithm
statistical
Performance ^nitor
Other Algorithms
PriorityQueues Shortest Job First
First Come First Serve (RoundRobin)
Figure
1
2.3.1.
The
Workload
Statistics Package
The
first
function
of the modelis
to generate an artificial workload thatsimulates the
activity
of a specified number of users.For
each user a series of "jobs"must
be
generated which simulate the cycle of commands that a typical usermight
issue
(
edit,list
files,
edit, compile, edit somemore, compile, run, print,
etc.).
The
workloadimposed
on the system willbe
controlledby
adding
andremoving
"users"
and
examining
the variationsin
response time that occur.Thus it
[image:27.529.46.463.93.478.2]particular measurement
interval.
One
of the assumptions that the model makesis
that user
behavior
is
homogeneous.
To
parameterize theworkload,
andfurther define
thebehavior
of a typicaluser,
data
was gatheredfrom
anexisting
time-sharing
user community.A group
ofprogrammers
working
together on a softwaredevelopment
project agreed to savetheir "history"
files
which record the sequence of commands whichthey
executedduring
their work session.These
programmers areworking
onSun
Workstations,
which are
Motorola MC-68010 based
UNIX
system.This
information
was gatheredby
having
each programmer provide a record of the systemload,
theirhistory
ofcommands,
and the timedemands
of their work session.This information
wasobtained
by
placing
several commandsin
the user's ".logout"file.
The
"uptime" commandindicates
the number of users onthe system and therelative
job
load.
This
command canbe
used to put atime-stamp
on thegrowing
master
history
file
and alsoindicate
the number of users on the system as well asthe relative
job
load.
The
"history" command appends thelast
onehundred
commands executed
by
each userbefore
logging
off of the system.The
"time"command records the total amount of user, system and real time utilized
by
thatuser since the creation of their
login
shell.From
this master collection of workhistory
files
adata
file
of typicalcommand execution sequences and relative
frequencies
was created.This
listing
ofexecuted commands was analyzedto
determine
the relativefrequency
of occurenceof each command.
This
wasfurther
analyzedto plot the relative order of commandexecution as atransition matrix.
If
the currentjob is
"A",
what percent ofthe timeis
the subsequentjob
"B",
"C"or
"D"? There
are typical sequences of commandsthat users
frequently
execute.For
example afterchanging working
directories,
21
(
"Is"in UNIX).
Similarly,
there are sequences of commands that are notcommon.
A
user whohas just
completed compilation of a programis
notlikely
torecompile
immediately
without anintervening
session offurther editing
or testing.From
this analysis adata file
was generated to represent these typical transitions.This data file is
usedby
thefunctions
which simulate"typical
users"to generate a
workload with a similar sequence and
frequency
of commands.The
module thatgenerates the user workload exhibits
behavior
similar to the actual userbehavior,
as
just described.
One
of theearly
limitations
ofusing
"history"files
was thatonly
thelast
twenty-five to
thirty
commands werebeing
saved.It
wasquickly
perceived thatthere was a gradual evolution
in
the sequence of commands that a programmerexecutes as the end of a work session
is
approached.The
true sequence ofcommands executed was not
being
capturedin
its
totality.To
correct this problemthe users
later
maintained and reported a muchlarger
personalhistory
of onehundred
commands.When
a user'sjob
is
createdby
the workload simulation module certainthings need to
be known
about thatjob besides its
arrival time.It
is
necessary
todetermine
the service requirements of thisjob
based
on thejob
type.To
parameterize this aspectof the simulated workload the
UNIX
"time"function
wasused to measure the service requirements of a
large
sample of each of thejob
types that were
included
in
thejob
sequence andfrequency
database.
The
UNIX
"time"
function
returns thefollowing
information:
the amount of usertime,
systemtime,
and real time usedin
the execution of the command; the amount ofmemory
used, the number of
I/O
interrupts;
and the amount ofpaging
andswapping
activity
associated with the timed process.This
data
was recordedfor many
values allows typical service
demands
tobe
generatedfor
each of the created userjobs.
2.3.2.
The
"Simulation
Engine"The
secondimportant
function
of the model couldbe
called the"simulation
engine".The
overall control of thesimulation,
theinitialization
of the model, andthe termination of the simulation are all controlled
by
this"simulation
engine".For
example,
the modelbegins
by determining
how
many
users are tobe
simulated
in
thisiteration
andhow
many
minutes of simulated timethe model will continue to executebefore
printing
out the accumulated statistics.The
simulation enginehas
to maintain a"system
clock"
so that events can
be
scheduled, timed and recorded.The
other majorresponsibility
ofthis portion ofthe modelis
maintaining
andmanipulating
theinternal
queues ofjobs
in
various states which constitute theinner
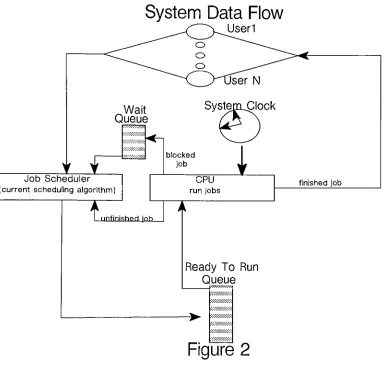
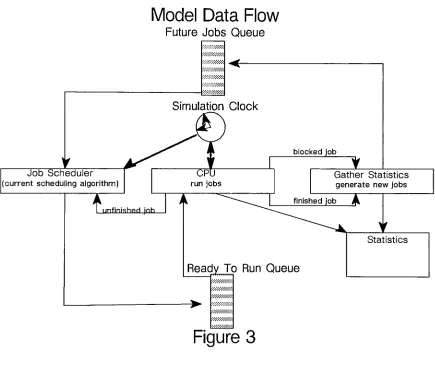
workings of the model.The
first
of theseinternal
queues contains the"arriving
jobs" that arebeing
submitted to our simulated processorfor
execution.The
model must maintain a queue of"future
events"that will represent the
jobs
being
generatedby
the simulated users of the system.The
module that simulates the user workloadis
responsiblefor generating
thejobs
that are enteredin
this queue.The
second oftheseinternal
queuesis
the "ready-to-run" queue ofjobs
thatare
ready
and waitingfor
cpu service.Jobs
are movedfrom
the queue of"future
events"
into
the ready-to-run queue when theirdesignated
"arrival
time"is
reached
by
theinner
clock of the model whichkeeps
track of simulated time.The
job
tobe
scheduledis
placedinto
the ready-to-run queueaccording
to the
-23
-component of the model that
is easily
changed or exchanged toimplement
adifferent
scheduling
algorithm.The
"simulation
engine"removes
jobs from
the ready-to-run queue and"runs"
them.
As
jobs
movefrom
one state to the next, time-stamps aremaintained
for
eachjob
which allows thegathering
of statisticsfor
responsetime,
execution
time,
andwaiting
time.When
ajob finishes
running
these statistics aregathered
from
the time-stampsbefore
thejob
"leaves" the model.The
terminationof a
job
will trigger the generation ofthe"next
job"for
that particular user whichis
thenbe
placedin
the queue offuture
events.In
multi-processtime-sharing
computer systemsjobs
share the cpu withother
jobs. When
ajob begins
service at the cpuit does
notnecessarily finish
before
it
must giveup
use of the cpu to otherwaiting jobs. The
quantum of timeallocated
by
the systemmay
expirebefore
thejob is
completed,in
which case thejob
mustbe
placedback in
the ready-to-run queueaccording
to the currentscheduling
algorithm.The "simulation
engine"is
responsiblefor maintaining
thissharing
of the cputime,
removing
jobs
from
therunning
state thathave
exceededthe
designated
time quantum and are not yetfinished,
or areblocked
waiting for
interactive keyboard input.
Jobs
in
the "blocked"waiting
state are rescheduled asfuture
eventsdue
to arrive at the time of their next calculated"input".
The
first
scheduling
algorithmimplemented
is
a simple round-robinscheduler where the
jobs
are placedin
the ready-to-run queue on afirst-come-first-serve
basis. The
second cpuscheduling
algorithmimplemented
is
an optimal scheduler that can
be
representedin
a modelbut
notin
reality
thisbeing
the shortest-remaining-time-first scheduler.Since
time-stamps
arebeing
maintained on each
job
it
willbe known
at all times what thejob's
total needis,
would never
have in
a real computersystem,
it is
possible to schedule thejobs in
order of their total unmet need
in
other words the shortestjob
first. A
thirdalgorithm to
be
examined maintains two ready-to-runqueues,
onefor "interactive
jobs"
and a second
for
"background" or "batch"jobs. Interactive
jobs
willbe
runfirst,
and when that queueis empty jobs
willbe
runfrom
the queue ofbatch jobs.
The
flexibility
of the model allowsfor
additionalscheduling
algorithms tobe
implemented
and tested with relative ease,but
shortest-job-first,first-come-first-serve
andpriority
queues are the three algorithms that willbe
analyzed
here.
2.3.3.
Coming
To Terms
The
model attempts to represent a user's perspective on the world.Therefore
the performance parameter that this thesis
focuses
mostclosely
onis
systemresponse time.
I
amusing
response time to mean the elapsed timefrom
thejob
submission time to
its
completion time.I
believe
thisis
thebest
criterionfor
measuring
interactive
performance and mostclosely
represents the user'sperception of system performance.
There
is
anotherdefinition
of response time which measures the elapsed timefrom
the submission of thejob
until thefirst
appearance of response at theterminal.
Often
thefirst
appearance of a response will precede the completion ofthe
job
by
a significantinterval. The first
appearance of response canbe very
reassuring
to the user that the systemis indeed
working
on the submittedrequest,
particularly
when thefinal
completionmay
take significantfractions
of a minute orlonger. Some initial early
appearance of responseis reassuring
andhelps
preventimpatient
usersfrom
re-submitting thejob
orbanging
on thekeys
to seeif
thesystem
is
stillup
or responding.I have
chosen not to use this seconddefinition
of
-25
In
theinner
workings of themodel,
response timeis
measured as thedifference between
ajob's
arrival time andits
departure
time.A
job
is
assigned anarrival time as
it is
placedin
thefuture-events
queue.The
job
"arrives"
and
is
moved
into
the ready-to-run queue when the simulation clockis
equal to orgreaterthan
its
scheduled arrival time.If
ajob is
currently running
when the newjob is
scheduled toarrive,
thearriving
job
willhave
to wait until thecurrently
active
job
completesits
current cpuburst.
Departure
timeis
marked when thejob
leaves
the cpufor
thelast
time.Departure
should occur when the total servicereceived
is
equal to the total service need that wasdetermined
when thejob
wascreated
by
the"User
andJob
Demands
Module."The
model alsokeeps
track of cpu utilization and total throughput.Total
cpuutilization
is
the percentage of the total simulated time that the cpu wasactively
running
a user'sjob.
Since
the system overhead associated with a user'sjob is
combined with the usertime needed
for
ajob,
this cpu utilizationfigure
could alsobe
described
as the percentage of "non-idle" time.The
throughputis kept
as atally
of the total number ofjobs
completedduring
the period of simulation.This
total can
be
divided
by
the number of minutes of simulation to arrive at ajobs
completed per minute
figure. Throughput
and cpu utilization are good measures ofsystem performance,
however
response timeis
abetter indicator
ofhow
the userwould experience or evaluate the system's
interactive
performance.2.3.4.
Statistics
System
andJob
Related
The last function
of the modelis
to gather two categories of statistics.Processor
utilization statistics arekept
so that a system saturation workloadlevel
can
be
identified.Statistics for
the ready-to-run queue(or queues)
are maintained.Histograms
describing
the population sizes of the ready-to-run queueprovide a graphical representation of the size ofthe
waiting
queue overtime.The
model
has been
designed
to report thatfor
x amount of time there was onejob
waiting
to run, andfor
y
amount of time there were twojobs
waiting
to run,etcetera.
The
model reports system population statistics, so that a systempopulation of zero corresponds to the amount of time that the processor was
idle,
and a system population of one corresponds to those times when there was no
job
waiting
to run while a currentjob
wasbeing
processed.This
makesit
possible tocalculate and report an average system population.
This
additional average systempopulation statistic
is
printed outalong
withthedata
andhistogram
representationsof system population statistics.
The
secondcategory
of statistics arejob
related statistics.What
is
the user'sperceived responsetime?
This
user response timeis
further
subdividedby
job
type.One
of the specialinterests
of thisstudy
is
todetermine
how
response times ofcertain
job
types canbe
optimized(
namely interactive
jobs
such asediting
),
andwhat effect that optimization will
have
upon response timesfor
otherjob
types.It
is
alsoimportant
todetect
whetherany
job
types arebeing
starved out underhigh
loads
withany
of these algorithms.In
the area ofjob-related
statistics an additional measure ofjob-related
system performance
is
reported.Utilizing
average response times alonedoes
notallow meaningful comparisons to
be
madebetween
the changesin
response timeunder
increasing
loads
of twodifferent
job
categories whichhave
very
different
typical system demands.
For
example, anediting
job
has
an average response timeof .042 seconds when there
is
a single user and.261 seconds when there are
thirty
users on a system which utilizes round-robin scheduling.
How does
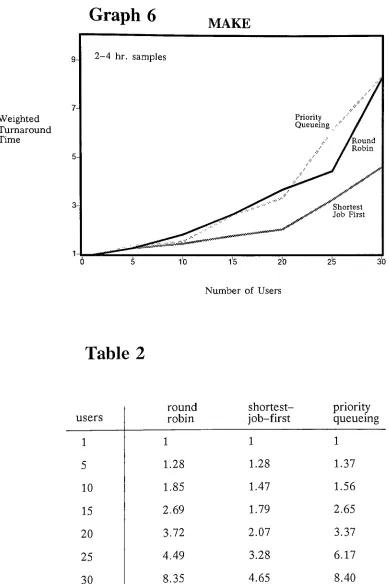
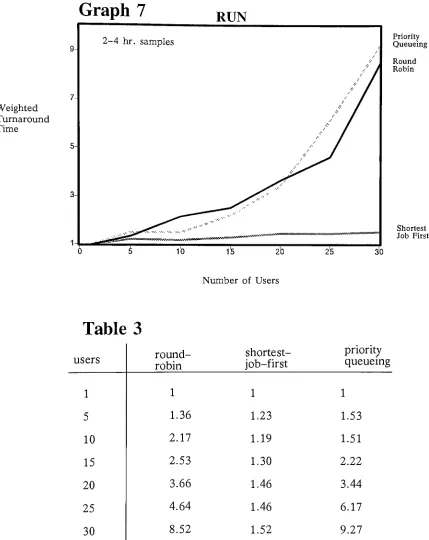
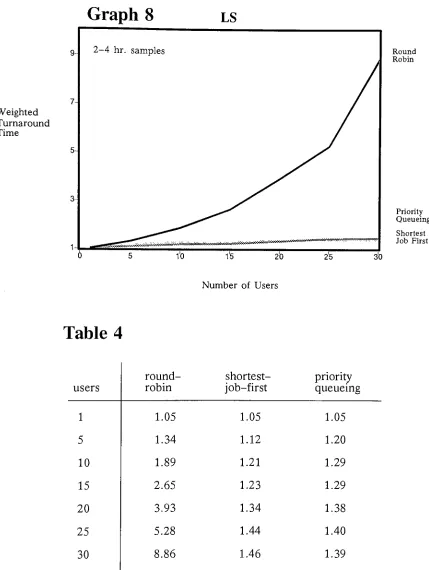
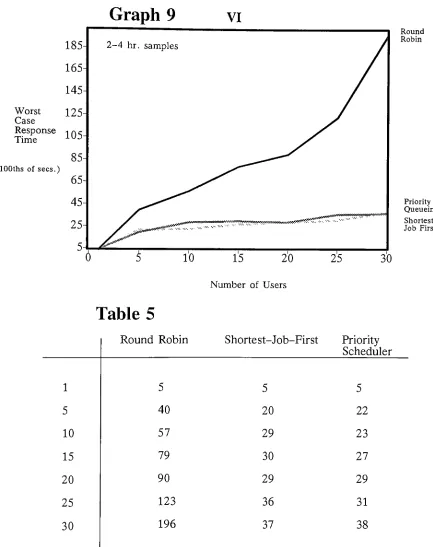
one compare27
-averages
36.68
secondsfor
a single user andincreases
to364.2
seconds whenthere are
thirty
userssharing
the system?The difference
between
the systemdemands
are sodifferent
for
thesejob
categories thatit is
difficult
and perhapseven meaningless to compare the
differential
changesin
response timebetween
these two
job
types on thebasis
of average response time.While
average response timeis
still aninteresting
statistic tolook
at,weighted turn-around time
is
the measure of choicefor comparing
how jobs
ofdifferent
typesfare
in
system performance.[
Ferrari,
et. al.1983
]
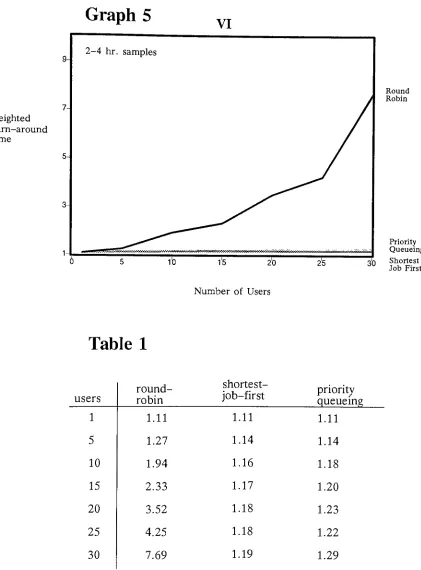
Weighted
turn-around time
is
the ratiobetween
turn-around time and actualprocessing
time.
On
a system with a single user this ratio shouldbe very nearly
equal to onefor
alljob
types.The
time requiredby
the system to process thejob is
divided into
the total turn-around time to yield a ratio that can
be
meaningfully
comparedacross
job
categories.These job
typesmay differ widely in
thedemands
they
typically
place upon the system.The
use of weighted turn-around timeis
offurther
help
in
diminishing
theimpact
of variationsin
systemdemands
within a singlejob
category.All
compilations
do
nothave
the sameprocessing demands.
Weighted
turn-aroundtime yields a measure of system performance which takes these variations
in
processing demands into
account.The
model reports statistics on weighted turn-around time.When
the modelis
running
in
the"verbose"
mode the weighted turn-around time
for
eachjob is
reported as
it
completes execution.The summary
job
statistics reportincludes
themean weighted turn-around time
for
eachjob
type.The
mean weightedturn-around time was
found
tobe
the most useful measure of system performancefor
the comparison of thedifferent scheduling
algorithms.This
measure of systemperformance of
scheduling
algorithms.It
shouldbe
noted that weightedturn-around time
is
particularly
sensitive to changesin
shorterduration
job
types.2.4.
Limitations
ofthe
Model
The
modelis
likely
tobe insensitive
to some of theinteractions
between
components of an actual computer system.
In
particular, the model will notreplicate some of the
thrashing
phenomena thathave
been
observedin
pagedvirtual
memory
computer systems asthey
approach saturation and thereis
adramatic increase
in
pagefaults. The
presentdesign
of the modeldoes
notdirectly
represent
memory
contention,swapping
or paging.The
cpu overhead associatedwith these activities
is
capturedin
the"system
time"component of the
UNIX
timecommand that
is
being
used to calibrate this model.So
while these activities arenot
directly
represented, theirimpact
upon system performanceis
takeninto
account.
The
modeldoes
notseparately
represent thequeuing
which occursfor
disk
I/O.
The
times associated with thisqueuing
are containedin
the user and systemtimes generated
by
theUNIX
time command.The
modelfactors
thesequeuing
delays into
the totaldelays
that the user perceives as response time.Questions
about the
interaction between
a given cpuscheduling
algorithm and theintensity
ofI/O activity
cannotbe
answeredby
this model.An
avenuefor future
explorationand enhancement of the model might
be
to takedisk
I/O queuing into
accountdirectly.
It
would thenbe
possible to examinequeuing
algorithms which givedifferential treatment to
I/O bound
and computebound
jobs.
It is
likely
possiblethat
further
control andtuning
of response time couldbe
obtainedby
differential
-29