City, University of London Institutional Repository
Citation
: Efthimiadis, E.N. (1992). Interactive query expansion and relevance feedback
for document retrieval systems. (Unpublished Doctoral thesis, City University London)This is the accepted version of the paper.
This version of the publication may differ from the final published
version.
Permanent repository link:
http://openaccess.city.ac.uk/7891/Link to published version
:
Copyright and reuse:
City Research Online aims to make research
outputs of City, University of London available to a wider audience.
Copyright and Moral Rights remain with the author(s) and/or copyright
holders. URLs from City Research Online may be freely distributed and
linked to.
City Research Online: http://openaccess.city.ac.uk/ [email protected]
and
Relevance Feedback
for
Document Retrieval Systems
Efthimis Nikolaos Efthimiadis
Thesis submitted for the degree of Doctor of Philosophy
Department of Information Science
The City University
London
July 1992
020220961-Acknowledgements
Abstract
1 Introduction
I Background information and literature reviews
2 Document Retrieval Systems
2.1 A brief overview of DRS
2.1.1 User-approach to the system
2.1.2 Query-document comparison
2.1.2.1 System comparison
2.1.2.2 User comparison
2.2 Retrieval mechanisms
2.2.1 Boolean searching
2.2.2 The probabilistic approach
2.2.2.1 Parameter estimation
2.2.3 Term Dependencies
2.3 Performance Evaluation
2.3.1 Recall and Precision
2.4 Information Retrieval Tests
2.4.1 Experiment and Investigation
5
6
6
8
8
8
9
9
10
13
15
19
19
21
23
24
3 Interaction in information retrieval 26
3.1 Intermediary mechanisms 26
3.2 User-system interaction 28
3.2.1 Interaction in Boolean systems 29
3.3 Search strategy: some definitions 29
3.3.1 Query expansion 30
3.4 Query formulation 31
3.5 Query reformulation 34
3.5.1 Simple relevance feedback 34
3.5.2 Interactive query definition & expansion 35
3.5.2.1 Based on a knowledge structure 36
3.5.2.2 Based on search results 37
4 Query expansion 40
4.1 The curse of dimensionality 41
4.2 Automatic Query Expansion 41
4.3 Semi-automatic query expansion 48
4.3.1 An overview of ZOOM and SuperZOOM 53
5 CIRT: a front-end for weighted searching 60
5.1 Introduction to front-ends for DRS 60
5.2 CIRT: background and introduction 61
5.3 Weighting, ranking, and relevance feedback in CIRT 63
5.4 The search algorithm 65
5.5 CIRT's user interface 70
5.6 A typical weighted search 73
5.7 The CIRT evaluation project 77
5.8 CIRT: Technical description 78
II
Interactive Query Expansion: pilot case studies
81
6
Introduction to the pilot case studies
82
6.1 Aims 82
6.2 Rationale 84
7
Pilot 1
87
7.1 Introduction 87
7.2 The INSPEC database 88
7.3 Methodology 89
7.3.1 Sample searches 89
7.3.2 Methodology for search reconstruction 89
7.3.3 Search reconstruction 93
7.3.3.1 INSPEC record fields 93
7.3.3.2 Processing and loading of INSPEC 94
7.3.3.3 Tape loading schedules 95
7.3.3.4 Search reconstruction in Data-Star 96
7.3.3.5 Search Reconstruction in ESA 97
7.3.3.6 Overall comments on limiting 99
7.3.4 Problems 99
7.3.4.1 The York Box and the LSI 11 size limitation 100
7.3.4.2 Speed of search 100
7.3.4.3 Term deletion 100
7.3.4.4 System crashes 101
7.3.4.5 Changes in Data-Star's transmission sequences 101
7.3.4.6 Problems Searching ESA 102
7.3.5 Source of query expansion terms and term selection 104
7.3.6 Relevance judgements 107
7.4.1 In search of a term ranking algorithm for query expansion 109
7.4.1.1 Selecting a ranking algorithm for query expansion 113
7.5 Results and discussion 119
7.5.1 Search r140 119
7.5.1.1 Analysis 123
7.5.2 Search r62 124
7.5.2.1 Analysis 129
7.5.3 Search r287 130
7.5.3.1 Analysis 134
7.6 Concluding remarks 136
8
Pilot 2
138
8.1 Introduction 138
8.2 Methodology 138
8.3 Results and Discussion 139
8.3.1 Search c68 139
8.3.2 Search c291 140
8.4 Concluding remarks 140
9
Pilot 3
142
9.1 Introduction 142
9.2 Methodology 143
9.3 Results 144
9.3.1 Search c60 144
9.3.2 Search c69 145
9.3.3 Search c70 146
9.4 Analysis and discussion 148
CONTENTS
vi
III Interactive Query Expansion: the experiment
153
10 The experiment
154
10.1 Introduction 154
10.2 Methodology 155
10.2.1 Experimental design 155
10.2.2 Sample and participants 155
10.2.3 Variables 156
10.2.3.1 Retrieval effectiveness (V1) 156
10.2.3.2 User effort (V2) 157
10.2.3.3 Subjective user reactions (V3) 158
10.2.3.4 User characteristics (V4) 158
10.2.3.5 Request characteristics (V5) 158
10.2.3.6 Search process characteristics (V6) 158
10.2.3.7 Term selection characteristics (V7) 158
10.2.4 Data collection instruments 159
10.2.4.1 Questionnaires 160
10.2.4.2 Evaluation of offline prints 161
10.2.4.3 The Logs 162
10.2.5 Procedure for data collection: summary 162
10.2.6 Procedure for data collection: discussion 163
10.2.6.1 Query Terms 164
10.2.6.2 Online Relevance Judgements 165
10.2.6.3 On which document representation should relevance
judgements be based on? 165
10.2.6.4 Relevance assessments 166
10.2.6.5 Sample size of relevant documents for relevance feedback 167
10.2.6.6 Identifying, weighting and ranking candidate terms . . . 168
10.2.6.8 Completing the search process 169
10.3 Results and discussion 170
10.3.1 Main results 170
10.3.1.1 Query expansion terms 170
10.3.1.2 Term selection characteristics 171
10.3.1.3 User selection of terms for query expansion 171
10.3.1.4 Evaluating the ranking algorithm 175
10.3.1.5 Retrieval effectiveness 178
10.3.1.6 Correspondence of online and offline relevance judgements 179
10.3.1.7 Retrieval effectiveness of the query expansion search . . . . 181
10.3.1.8 Discussion on retrieval effectiveness and online vs offline
judgements 183
10.3.2 Other findings 184
10.3.2.1 User status 184
10.3.2.2 Intended use of information 186
10.3.2.3 User's assessment of the nature of the enquiry 186
10.3.2.4 Work done on the problem 186
10.3.2.5 Clarity of the problem 187
10.3.2.6 Type of search required 187
10.3.2.7 Familiarity with the process of online searching 187
10.3.2.8 User's satisfaction with the search 187
10.3.2.9 User's assessment of the search 188
10.3.2.10 User's assessment of the results 188
10.3.2.11 Match of search to enquiry 188
10.3.2.12 Expected references 189
10.3.2.13 User's satisfaction with the results 189
11 Evaluation of the six ranking algorithms
197
11.1 Introduction
197
11.2 Methodology
197
11.3 Results and Discussion
199
11.3.1 Distribution of the terms chosen by the users
199
11.3.2 The 5 top ranked terms of each algorithm
202
11.3.3 Sum of ranks of the user designated five best terms
203
11.4 Concluding Remarks
203
12 Conclusions and Recommendations
208
12.1 Proposals for future research
210
12.1.1 Ranking algorithms
210
12.1.2 User Studies and Query Expansion
211
12.1.3 User studies and relevance feedback systems
212
12.1.4 A module for interactive query expansion: a proposal
212
12.1.5 Automatic vs Interactive Query Expansion: a research proposal. 213
Appendices
217
A CIRT's search tree
217
A.1 Search tree for request Q123
217
B Pilot 1
221
B.1 CIRT searches in the INSPEC database
221
B.2 INSPEC record fields
222
B.2.1 Data-Star record fields for the INSPEC database
222
B.2.2 ESA/IRS record fields for the INSPEC database
223
B.3 INSPEC updates
224
B.3.1 INSPEC updates on Data-Star
224
B.4 Programs for processing log files 228
B.4.1 Shell scripts for processing ESA log files 228
B.4.2 Program for calculating the F4modified weights 231
B.5 Retrieved records for search 140 234
B.6 Overlap of retrieved documents in searches of case 140 235
B.7 Retrieved records for search 62 236
B.8 Overlap of retrieved documents in searches of case 62 238
B.9 Retrieved records for search 287 239
B.10 Overlap of retrieved documents in searches of case 287 240
C Pilot 2
241
C.1 Search c68 241
C.2 Search c291 242
D
The Experiment
244
E Evaluation of the six algorithms
259
List of Figures
2.1 A model of a document retrieval system 7
2.2 A classification of retrieval techniques. 10
2.3 Steps in the pre-search interview and the online search. 11
3.1 The two stage model. 27
5.1 CIRT's relevance feedback mechanism 64
5.2 Search tree for three terms 66
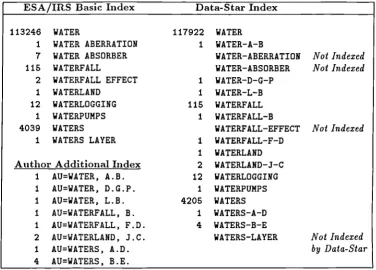
7.1 Index of the INSPEC database on ESA/IRS and Data-Star 95
10.1 Association of terms identified from the rank list to query 174
10.2 Relationship of the user selected 5 best terms to query terms 174
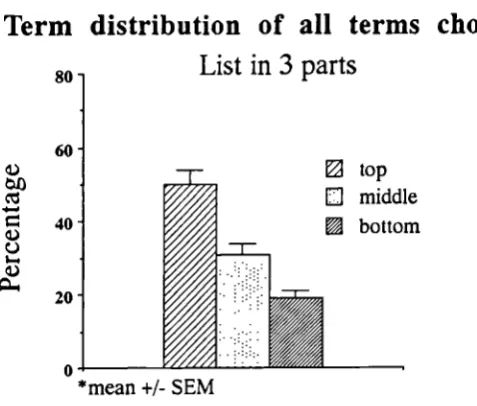
10.3 Term distribution of all terms chosen: list in 3 parts 177
10.4 Term distribution of all terms chosen: list in 2 parts 177
10.5 Term distribution of the 5 best terms: list in 3 parts 177
10.6 Relevance judgements 191
10.7 User's status 192
10.8 Intended use of information 192
10.9 User's assessment of the nature of the enquiry 192
10.10 Work done on the problem 193
10.11Clarity of the problem 193
10.12Type of search required 194
10.13User's satisfaction with the search 194
10.14User's assessment of the search 195
10.15User's assessment of the results 195
10.16Match of search to enquiry 196
10.17Expected references 196
11.1 Distribution of the terms chosen by the users for each algorithm 207
List of Tables
7.1 QE terms for r287 ranked by F4modified and F4point-5 110
7.2 QE terms for r287 ranked by the ZOOM and Porter algorithms. 116
7.3 QE terms for r287 ranked by the EMIM and
w(p — q)
algorithms. 1177.4 Rank position of terms using the 6 algorithms. 118
10.1 Totals for query expansion terms and single posted terms in the ranked lists 171
10.2 Totals and percentages of terms in the ranked-lists and of terms chosen by
the subjects 172
10.3 Results of the correspondence of the online to offline relevance judgements 180
10.4 Results of the query expansion searches 182
11.1 Summary statistics: Percentage distribution of all terms chosen by the users
Ranked lists divided into 2 parts 200
11.2 Summary statistics: Percentage distribution of all terms chosen by the users
Ranked lists divided into 3 parts 200
11.3 Summary statistics: Percentage distribution of the 5 best terms chosen by the users. Ranked lists divided into 3 parts 201
11.4 Sum of the ranks of the 5 best terms 204
11.5 Significance levels for the Wilcoxon test on pairs of the algorithms 205
11.6 Pearson's r correlation for pairs of algorithms 205
D.1 Term distribution of all terms chosen by the users as being potentially useful. Ranked-lists divided into 2 parts. List ranked with
w(p — q)
algorithm.. . 253D.2 Term distribution of all terms chosen by the users as being good terms to be included in the search. Ranked-lists divided into 3 parts. List ranked with
the
w(p — q)
algorithm. 254D.3 Term distribution of the 5 best terms. Ranked-lists divided into 3 parts. List
ranked with
w(p — q)
algorithm. 255D.4 Relevance assessments of offline prints 256
D.5 Relevance assessments and precision ratios for all searches 257
D.6 Correspondence of online to offline relevance jugdements 258
E.1 Term distribution of all terms chosen by the subjects as being potentially useful. Ranked-lists divided into 2 parts. List ranked with w(p — q) algorithm.260
E.2 Term distribution of all terms chosen by the subjects as being potentially useful. Ranked-lists divided into 2 parts. List ranked with the EMIM algorithm.261
E.3 Term distribution of all terms chosen by the subjects as being potentially useful. Ranked-lists divided into 2 parts. List ranked with the F4 formula 262
E.4 Term distribution of all terms chosen by the subjects as being potentially useful. Ranked-lists divided into 2 parts. List ranked with the F4-modified
formula 263
E.5 Term distribution of all terms chosen by the subjects as being potentially useful. Ranked-lists divided into 2 parts. List ranked using Porter's algorithm.264
E.6 Term distribution of all terms chosen by the subjects as being potentially useful. Ranked-lists divided into 2 parts. List as ranked by ZOOM 265
E.7 Term distribution of all terms chosen by the subjects as being good terms to be included in the search. Ranked-lists divided into 3 parts. List ranked
with the w(p — q) algorithm 266
E.8 Term distribution of all terms chosen by the subjects as being good terms to be included in the search. Ranked-lists divided into 3 parts. List ranked
using the EMIM algorithm. 267
E.9 Term distribution of all terms chosen by the subjects as being good terms to be included in the search. Ranked-lists divided into 3 parts. List ranked
with the F4 formula 268
E.10 Term distribution of all terms chosen by the subjects as being good terms to be included in the search. Ranked-lists divided into 3 parts. List ranked
with the F4-modified formula 269
E.11 Term distribution of all terms chosen by the subjects as being good terms to be included in the search. Ranked-lists divided into 3 parts. List ranked
with Porter's algorithm 270
E.12 Term distribution of all terms chosen by the subjects as being good terms to be included in the search. Ranked-lists divided into 3 parts. List as ranked
by ZOOM. 271
E.13 Term distribution of the 5 best terms. Ranked-lists divided into 3 parts. List
E.14 Term distribution of the 5 best terms. Ranked-lists divided into 3 parts. List
ranked with the EMIM algorithm 273
E.15 Term distribution of the 5 best terms. Ranked-lists divided into 3 parts. List
ranked with the F4 formula 274
E.16 Term distribution of the 5 best terms. Ranked-lists divided into 3 parts. List
ranked with the F4-modified formula. 275
E.17 Term distribution of the 5 best terms. Ranked-lists divided into 3 parts. List
ranked with Porter's algorithm 276
E.18 Term distribution of the 5 best terms. Ranked-lists divided into 3 parts. List
as ranked by ZOOM 277
E.19 Search 101: five top-ranked terms for each algorithm. 278
E.20 Search 102: five top-ranked terms for each algorithm. 279
E.21 Search 103: five top-ranked terms for each algorithm. 280
E.22 Search 105: five top-ranked terms for each algorithm. 281
E.23 Search 108: five top-ranked terms for each algorithm. 282
E.24 Search 110: five top-ranked terms for each algorithm. 283
E.25 Search 111: five top-ranked terms for each algorithm. 284
E.26 Search 112: five top-ranked terms for each algorithm. 285
E.27 Search 113: five top-ranked terms for each algorithm. 286
E.28 Search 114: five top-ranked terms for each algorithm. 287
E.29 Search 115: five top-ranked terms for each algorithm. 288
E.30 Search 116: five top-ranked terms for each algorithm. 289
E.31 Search 117: five top-ranked terms for each algorithm. 290
E.32 Search 118: five top-ranked terms for each algorithm. 291
E.33 Search 119: five top-ranked terms for each algorithm. 292
E.34 Search 120: five top-ranked terms for each algorithm. 293
E.35 Search 121: five top-ranked terms for each algorithm. 294
E.36 Search 122: five top-ranked terms for each algorithm. 295
E.37 Search 123: five top-ranked terms for each algorithm. 296
E.39 Search 125: five top-ranked terms for each algorithm 298
E.40 Search 126: five top-ranked terms for each algorithm 299
E.41 Search 127: five top-ranked terms for each algorithm 300
E.42 Search 128: five top-ranked terms for each algorithm 301
Acknowledgements
I would like to thank all those who have contributed to this work and helped make it possible. In particular I would like to thank:
Steve Robertson, whose ideas initiated this research, for his guidance, support, advice and patient supervision that saw me through this thesis.
The academic, administrative and research staff of the Department of Information Science.
My colleagues, at the Graduate School of Library and Information Science at the University of California, Los Angeles, for their encouragement to complete this work.
Data-Star, ESA/IRS and INSPEC for the free online time. P.G. Marchetti, Roy Kitley and Mike Everest of ESA were particularly helpful.
All the friends who variously discussed and commented.
Jean and Stathis for their support and more.
My parents, who have never failed to encourage, support and express enthusiasm for all my work,
Declaration of Copyright
Abstract
This thesis is aimed at investigating interactive query expansion within the context of a relevance feedback system that uses term weighting and ranking in searching online databases that are available through online vendors. Previous evaluations of relevance feedback systems have been made in laboratory conditions and not in a real operational environment.
The research presented in this thesis followed the idea of testing probabilistic retrieval techniques in an operational environment. The overall aim of this research was to investigate the process of interactive query expansion (IQE) from various points of view including effectiveness.
The INSPEC database, on both Data-Star and ESA-IRS, was searched online using CIRT, a front-end system that allows probabilistic term weighting, ranking and relevance feedback.
The thesis is divided into three parts.
Part I of the thesis covers background information and appropriate literature reviews with special emphasis on the relevance weighting theory (Binary Independence Model), the approaches to automatic and semi-automatic query expansion, the ZOOM facility of ESA/IRS and the CIRT front-end.
Part II is comprised of three Pilot case studies. It introduces the idea of interactive query expansion and places it within the context of the weighted environment of CIRT. Each Pilot study looked at different aspects of the query expansion process by using a front-end. The Pilot studies were used to answer methodological questions and also research questions about the query expansion terms. The knowledge and experience that was gained from the Pilots was then applied to the methodology of the study proper (Part III).
Part III discusses the Experiment and the evaluation of the six ranking algorithms. The Experiment was conducted under real operational conditions using a real system, real requests, and real interaction. Emphasis was placed on the characteristics of the interaction, especially on the selection of terms for query expansion.
Data were collected from 25 searches. The data collection mechanisms included questionnaires, transaction logs, and relevance evaluations.
The results of the Experiment are presented according to their treatment of query expansion as main results and other findings in Chapter 10. The main results discuss issues that relate directly to query expansion, retrieval effectiveness, the correspondence of the online-to-offline relevance judgements, and the performance of the w(p — q) ranking algorithm.
Finally, a comparative evaluation of six ranking algorithms was performed. The yardstick for the evaluation was provided by the user relevance judgements on the lists of the candidate terms for query expansion. The evaluation focused on whether there are any similarities in the performance of the algorithms and how those algorithms with similar performance treat terms.
This abstract refers only to the main conclusions drawn from the results of the Experiment:
(1) One third of the terms presented in the list of candidate terms was on average identified by the users as potentially useful for query expansion;
(2) These terms were mainly judged as either variant expression (synonyms) or alternative (related) terms to the initial query terms. However, a substantial portion of the selected terms were identified as representing new ideas.
(b) 66% of the query expansion terms have a relationship which makes the term: (bl) narrower term (70%), (b2) broader term (5%), (b3) related term (25%).
(4) The results provide some evidence for the effectiveness of interactive query expansion. The initial search produced on average 3 highly relevant documents at a precision of 34%; the query expansion search produced on average 9 further highly relevant documents at slightly higher precision.
(5) The results demonstrated the effectiveness of the w(p—q) algorithm, for the ranking of terms for query expansion, within the context of the Experiment.
(6) The main results of the comparative evaluation of the six ranking algorithms, i.e. w(p — q), EMIM, F4, F4modifed, Porter and ZOOM, are that: (a) w(p — q) and EMIM performed best; and (b) the performance between w(p — q) and EMIM and between F4 and F4modified is very similar;
(7) A new ranking algorithm is proposed as the result of the evaluation of the six algorithms.
Introduction
To date most information retrieval research experimentation on relevance feedback systems has been conducted in the laboratory. However, Sparck Jones (1988) and other researchers have called for more testing of probabilistic retrieval techniques in operational environments. There is therefore an apparent need for carrying out real, rather than simulated, interactive searching, in order to investigate the behaviour of relevance weighting under the constraints imposed by real users.
The research presented in this thesis follows this line of research thinking and is an investigation of interactive query expansion.' The overall aim of this research is to investigate the process of interactive query expansion (IQE) from various points of view including effectiveness. In other words, the aim was broader than just effectiveness. In order to investigate the process of query expansion as well as its effectiveness one needs to have a real system. I made use, therefore, of real users with their real requests in an operational environment, as opposed to searching a static test collection with fixed (artificial) queries, in order to study query expansion in a dynamic user centred environment.
For the research reported the INSPEC database, on both Data-Star and ESA-IRS, was searched online using CIRT, a front-end system that allows weighting, ranking and relevance feedback.
The thesis is divided into three parts.
Part I: background information
Part I of the thesis covers background information and appropriate literature reviews.
An overview of document retrieval systems highlights the major deficiencies of Boolean retrieval systems and discusses the probabilistic approaches to IR with special emphasis on the relevance weighting theory (Binary Independence Model) (Robertson & Sparck Jones, 1976). Chapter 2 also introduces what is experiment and what is investigation in the
1The terms interactive query expansion and semi-automatic query expansion are used interchangeably in the text.
context of information retrieval testing. This provides the reasons and the explanation for the adoption of the investigation approach in this research.
The chapter on 'interaction in IR' covers the interactional aspects between the user, the intermediary and the retrieval system. There is a discussion on search strategy, query formulation, query reformulation, simple relevance feedback, and the idea of 'interactive' query definition and expansion.
A more technical discussion on query expansion is given in chapter 4 which starts with the issue of the curse of dimensionality. Approaches to automatic and semi-automatic query expansion are reviewed and examples of how these have been implemented in various systems are given.
A detailed treatment of the ZOOM and SuperZOOM facilities of ESA/IRS is also presented here because of its importance for my experimental investigation. ZOOM was used for the analysis of the relevant document set that provided the terms for query expansion.
The last chapter of Part I introduces the idea of front-ends for document retrieval systems (DRS) and discusses in detail CIRT. CIRT, the front-end used for conducting this research, allows weighting ranking and relevance feedback while searching a Boolean vendor system. Chapter 5 provides a step-by-step discussion of the underlying theory of CIRT and its development. A technical description and a detailed discussion of how a weighted search is conducted through CIRT are given in order to provide the necessary background information to facilitate the discussion in the subsequent chapters.
Part II: Interactive query expansion: the pilot case studies
Part II starts by introducing the idea of interactive query expansion and how it relates to searching. It discusses why there is a need for a module for interactive query expansion. The emphasis is placed on a weighted environment especially one implemented in a front-end like CIRT.
A general description of the three Pilot case studies and the Experiment is given together with the overall methodology. Each Pilot study looked at different aspects of the query expansion process by using a front-end. The knowledge and experience that was gained from the Pilots was then applied to the methodology of the study proper (i.e., in the operational situation with real users) that is described in Part III.
Pilot 1
The aim of Pilot 1 (chapter 7) was to look at the process of query expansion as a whole and see what can be learned from it. It investigated the different sources for selecting query expansion terms for the front-end, e.g., using the relevant document set and ZOOM on certain fields of the record, such as descriptors, titles, abstract; selecting terms from the INSPEC thesaurus, etc.
terms, and on the six algorithms used in the experiments. The reasons for the selection of
w(p — q)
as the ranking formula for the query expansion terms are given as well as the reasons why this algorithm is good for term discrimination.Pilot 2
Pilot 2 looked at the process of adding new terms in the search. Its aim was to identify how searchers of a weighted system do query expansion without getting any help from the system.
CIRT did not offer any means of query expansion and the task was left entirely on the user. Searches from the CIRT evaluation project were analysed in order to see whether the users expanded their queries. If they did, then I investigated what was the source of the query expansion terms.
Pilot 3
Pilot 3 looked into the questions of 'what evidence is there to indicate that terms taken from relevance judgements of the first iteration search might subsequently be useful?', 'How predictive is the ranking of the first iteration (set) in retrieving the documents of the second set?' and 'Are the terms high-up on both lists?'
In summation, the Pilot studies presented in Part II were used to answer methodological questions as well as research questions about the query expansion terms. The main questions were: 'How useful are the query expansion terms?', 'Where to get them from for the proper experiment?', 'How to rank them?', 'Which ranking method to use in ranking query expansion terms?'.
Part III: Interactive query expansion: the experiment
Part III discusses the final full scale real-life experiment of this research and the evaluation of the six ranking algorithms.
The experiment
Having investigated query expansion under the controlled experimental conditions of the Pilot studies and having gained experience and learned from it I then proceeded with the Experiment under real conditions. I used an operational system, CIRT, to search a commercially available database, INSPEC on Data-Star, in order to study query expansion in a dynamic user centred environment.
characteristic, for example, is the selection of terms at a particular stage in the process. The results, therefore, have a quantitative as well as a qualitative component.
Data were collected from 25 searches. The data collection mechanisms included questionnaires, transaction logs, and relevance evaluations. The variables examined were divided into seven categories which include: retrieval effectiveness, user effort, subjective user reactions, user characteristics, request characteristics, search process characteristics and term selection characteristics.
Studies of operational systems produce a wide range of results and this study is no exception. However, the most important results with respect to query expansion are reported from the term selection characteristics and from the evaluation of the six ranking algorithms, which were the focus of this research.
The results of the Experiment are presented in two sections in Chapter 10, i.e. main results and other findings according to the treatment of query expansion. The main results relate directly to query expansion, e.g. what type of term relationships users identify between the initial query terms and the query expansion terms. In addition the main results discuss retrieval effectiveness, the correspondence of the online-to-offline relevance judgements, and the performance of the
w(p — q)
ranking algorithm. The other findings from the analysis of the results of the questionnaires and the searches that do not relate directly to query expansion cover the user characteristics, -subjective user reactions and search process characteristics.Evaluation of the six ranking algorithms
Chapter 11 presents a comparative evaluation of the six algorithms that were introduced in Pilot 1 and were considered for the ranking of the query expansion terms. These, i.e.
w(p — q),
EMIM, F4, F4modified, Porter and ZOOM were put to test. The yardstick for the evaluation was provided by the user relevance judgements on the lists of the candidate terms for query expansion. The evaluation focused on whether there are any similarities in the performance of the algorithms and how those algorithms with similar performance treat terms.The general conclusions drawn from this investigation of interactive query expansion in a weighted environment are presented in Chapter 12. An investigation is by definition an exploratory study which generates hypotheses for future research. Recommendations and proposals for future research follow the presentation of the general conclusions.
Background information and
literature reviews
Document
Retrieval Systems
2.1 A brief overview of DRS
As information systems, document retrieval systems (DRS), database management systems (DBMS) and expert systems try to satisfy one main function, i.e., to retrieve information from a store or database in response to a user's query (Croft, 1982). In addition the system should retrieve all and only that information which the enquirer wants or would want. In this sense information retrieval (IR) is studied by a wide range of disciplines in computer-based non-numeric processing. Topics such as automatic natural language processing, algorithms for searching, compression techniques, multi-media information systems and novel computer hardware are relevant to IR. There is therefore more to an information system than just retrieval. Historically IR has been taken to refer to techniques for the storage and retrieval of textual information. The discussion below is concentrated on DRS, leaving aside both DBMS and expert systems. (For an overview of information systems the reader is referred to Croft (1982)).
The difference of DRS to the other information systems lies mainly in the nature of the information it stores and retrieves. The goal of a DRS is to retrieve information in response to human articulation of information needs by informing the enquirer which documents contain the needed information, i.e., reference retrieval l 2 . A wide range of issues have to be addressed in IR. These include, especially recently, user modelling, implementation of text databases for efficient access and the user interface. A core operation of a DRS is the comparison of user queries to document representations, and it is on this operation that my research is partly focused.
Figure 2.1 presents the traditional model of a DRS system in a simplified form (Robertson, 1978). The diagram contains the two most important elements of DRS, i.e., indexing and searching. At the left of the diagram is the 'indexing side' and at the right is the 'searching or query side'. For simplification both sides are presented as linear, but both involve feedback. This model is presented here, firstly, because it provides the 'standard view' of DR, and secondly, as a reminder of the co-existence of the indexing and
'Information retrieval, document retrieval and reference retrieval will be referred to as IR from now on. 'The terms document retrieval systems (DRS) and information retrieval systems (IRS) will also be used interchangeably from now on.
Iconcepts
Itranslate
final indexing
°normal text = entities
italicised text = activities
searching sides. The model contains entities and
activities
which may take different forms in different systems, e.g., online search, menu selection process (as determined by form of index language). Activities may be shifted from one part of the diagram to another. For example, an 'index language' may be highly constrained, therefore, 'translation' is very important to it; or, 'translation' may be trivial and consequently the`translation' of the 'information need' may be more important.Iother docs I other queries
document'
extract conceptsb
subject knowledge
compile
index language
info, need or (ASK)
express in words
Iquery I
Itranslate
Isearch formalities I
Isearch
[image:27.595.65.501.183.400.2]output
Figure 2.1: A model of a document retrieval system
In principle, a DRS has all the parts shown in the diagram. This is of particular importance to those interacting with a DRS because for most of the time they might have control over one part of the system only. For example, searchers do not have control of the indexing side but their searching effectiveness is determined of how well they have understood the indexing of the database they search. It is also useful to think of the different roles of people within the DRS, e.g., how indexers may have put information in, etc.
The term
document,
mentioned above, is being very loosely defined here, covering almost any type of representation of information across many possible format. This includes abstracts, journal articles, newspaper articles, technical papers, reports, descriptions of audiovisual material (films, records) and magnetic media, and so on. The text of documents is stored by the DRS as a structure that could be provided in some form oftext representation.
The most commonly used method is to represent the document by an unordered subset of words that appeared in it (uncontrolled keywords/terms — free-text indexing) or that appear in the indexing language used by the system (controlled keywords/terms). Index terms can be individual words or phrases and both controlled and uncontrolled terms have some semantic meaning. The retrieval process could be modelled as having the following form:• The DRS derives text representation of documents, as mentioned above.
• The DRS processes the query and for each document in the store compares the representation of the user query to the document representation it holds.
• This results in the retrieval of some documents from the store which are predicted by the system to be relevant to the users query and which are presented to the user for further consideration.
There may be several iterations of all but the first of the above steps during which the user and/or the system may modify the initial query.
2.1.1 User-
approach to the system
On the query side of Figure 2.1, one model of the user as part of the information system assumes that users approach the system because they recognise the existence of some anomaly in their state of knowledge (Belkin, Oddy & Brooks, 1982). This anomaly or information need which may take the form of a written statement of interest or in some cases is merely a vague idea has then to be described by the users.
This description, which will be referred to as the query, must be translated into a language that is acceptable to the system. For example, the query may be reduced to a number of search terms (keywords) that appropriately represent the contents of the query.
In order to satisfactorily achieve this transformation (query formulation) the user needs to have good knowledge of the database to be searched, the subject representation (controlled vocabulary), Boolean logic and so on. The query formulation can be performed by the user himself or it can be delegated to a search intermediary.
2.1.2 Query-
document comparison
2.1.2.1 System comparison
The process of comparing the query to the documents is said to be done by a matching
function (van Rijsbergen, 1979, p.97).
Simple matching or co-ordination level matching is an example of a matching function. It
assigns a score to a document equal to the number of terms that the document representation has in common with the query representation. Since simple matching assigns a numeric score to each document it is a kind of weighted matching. A score, like the above, obtained by some matching function can be used either for ranking a set of documents (ranked retrieval) or for retrieving a single set of documents scoring above a predefined threshold (set retrieval). In a Boolean system the binary-valued functions used (i.e., strict yes-no matching function) predetermines the use of set retrieval.
"... the system may present only one text, or an unordered set, or may rank the texts in some order. But any of these processes (or indeed, any act of retrieval)
is a ranking process (see Cooper (1968)). ... An explicit ranking beyond simple
set retrieval, is normally based on a matching process: it reflects the degree of
match, as measured by a matching function, between the texts and the request
as put to the system..."
Term-matching, i.e., the process of comparing the query to the documents is an inherent problem in traditional IR (this description does not apply to other types of IR systems, like menu-driven or hypertext systems). Whatever the retrieval mechanism and the retrieval technique used by the system (see above, Figure 2.2 and Belkin and Croft (1987)) terms from the user's query are matched at a symbolic, text-matching level against document representations. This form of matching is some distance removed from any semantic and contextual information in the document. Effective use of existing Boolean IR systems depends heavily on the users' perception of the data structure that their queries are addressing. The data structure (database view) is reflected in the query language, and vice versa. In other words, present query languages reflect the model of the logical structure of the databases. The IR situation is confined to set operations (creation and manipulation). Successful handling of these operations will result in a final set which to some degree will satisfy the user's expressed information need.
2.1.2.2 User comparison
The process of deciding upon the relationship that exists between a retrieved document and the query is called relevance judgement and plays a very important role in IR. What constitutes relevance and the distinction between relevance and usefulness has been extensively studied by many IR researchers and in many contexts. Saracevic (1975) and more recently Schamber, Eisenberg & Nilan (1990) provide an extensive review of the notion of relevance and its treatment in information science.
In
general, relevance is defined as the extent to which the subject matter of the document is about the query. Therefore, associated with each query is a variable whose value is the relevance of the document to the query. Robertson (1977a) describes a model for relevance in which relevance is assumed to be a continuous variable. Degrees of relevance, which relate to the process of judging relevance, are defined by dividing the continuous scale over which the variable ranges into as many divisions as there are degrees.In order to facilitate the discussion below I will make use of a rather simple definition of relevance, adopting a binary view of relevance. This assumes that relevance (or usefulness, or user satisfaction) is a basic dichotomous criterion variable, defined outside the retrieval system itself, so that a document is either relevant or not and there are no in-between states (Robertson, 1977b).
2.2 Retrieval mechanisms
Network
/\
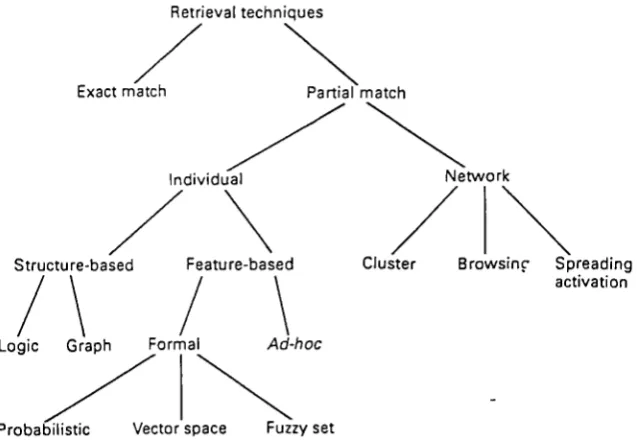
the query with the document representations. RTs are further classified according to the characteristics of the retrieved set of documents and the representations that are used. Some RTs fall into more than one category, and others are a mixture of techniques from different categories.
Retrieval techniques
/
Exact match Partial match
Individual /\
Structure-based Feature-based Cluster Browsing Spreading activation
/\
Logic Graph
Probabilistic
/\ Formal Ad-hoc
-N
[image:30.595.109.428.178.398.2]Vector space Fuzzy set
Figure 2.2: A classification of retrieval techniques.
The first distinction is between exact and partial match. In the former category are RTs that require any retrieved item to match the query exactly, which includes Boolean systems, those using the pseudo-Boolean free text operators, and string-searching systems. Partial match RTs, by which items may be ranked according to degree of match, are further divided into individual and network RTs. The former are based on matching queries against document representatives treated individually, whereas the latter make direct use of inter-document links of some kind.
Following this brief introduction to the RT I will concentrate in my discussion only on two RTs, Boolean from exact match and probabilistic from the partial match techniques.
2.2.1 Boolean searching
Most present day large operational DRS rely heavily on exact match techniques, i.e., Boolean logic. A variety of aids such as thesauri are needed to achieve reasonable performance. In the IR literature, therefore, the traditional Boolean searching has been the subject of many textbooks, including Henry et al (1980), Meadow and Cochrane (1981), Harter (1986), Hartley et al (1990), etc., and articles in journals such as Online Review,
Online, Database, and Database Searcher.
Steps
1. Clarifying and Negotiating the Information-Need and Search Objectives
• Interviewing the information requester clarifies the narrative form of the request and determines search objectives:
(a) retrieve all relevant items (high recall); (b) retrieve only relevant items (high precision);
(c) retrieve some relevant items.
• Identify constraints (e.g., books only as output or only in English, or only if published after 75)
2. Identifying Relevant Online System and Databases
• Determining which online system and data base to use first, which next, etc. 3. Formulating Basic Search Logic and Planning Search Strategies
• Analysing the search topic into parts called facets or concept groups. Planning approaches to search strategy for combining concepts of the topic.
4. Compiling the Search Terms
• Choosing indexing terms from the data base's thesaurus or other printed word lists. • Selecting terms for free text searching of the subject-conveying fields (title, abstract,
etc.).
• Deciding to use thesaurus and alphabetic word lists online.
5. Making Output Choices
• Choosing limits on, and printing of, output.
• Selecting an approach to search strategy that best satisfies the search objectives expressed by the requester.
6. Conceptualising the Search as Input to the Retrieval System
• Arranging the search terms into concepts or facets for search strategies using features of the retrieval system, for example, word proximity.
• Noting most important and less important concepts groups and deciding on sequence of input to access these concept groups efficiently.
• Restricting or limiting output based on search objectives. 7. Evaluating Preliminary Results
• Reviewing search results, step by step.
• Considering alternative search strategies to meet search objectives (recycling Steps 1-6).
8. Evaluating Final Results
• Determining requester's satisfaction with search results.
These steps will be examined and discussed. It is worth noting here that even if the end-user searches alone, i.e., without the help of an intermediary, there will still be a need to clarify and negotiate the request and to know enough about the language of the database being searched to match the request with the basic index provided. In other words the user would have to follow all the steps on her or his own.
In Figure 2.3 steps 1, 2 and 4 could be said to belong in the pre-search procedures. Steps 3, 5, 6 and 7 are activities used in both pre-search procedures and during the search and step 8 is a post-search action. The user-intermediary/intermediary-system interactions would determine the order of the steps and any possible repetitions of them. The steps, thus, are not in any fixed order, apart from the first one, which involves the user efforts to express and delegate her/his information need to the system (i.e., here the intermediary). The pre-search reference interview (Eichman, 1978; Knapp, 1978; Markey, 1981; Taylor, 1968) is the user's first interaction and the feedback from it creates and links the conceptual analysis of the request (query) and the manipulation of concepts to develop a search strategy.
Search intermediaries have their own stereotypes both about how to deal with users and the online services, and also of how to conduct searches. At this pre-search stage the intermediary and the user are involved in a cognitive exchange. The stages of this interaction (e.g., steps 1-6 but especially step 3) involve feedback that may change the searcher's (human intermediary's and/or end-user's) view of what is wanted - and consequently affect query formulation. A Boolean search system has nothing that could be described as a dynamic cognitive structure (Ingwersen, 1984). Hence any evolution in the interaction has to involve changes in the cognitive structures of the human beings.
Having dealt with steps 1-6 the searcher then goes online. At this interactive session the search formulation is being submitted to the database and feedback is involved as soon as the searcher receives messages that would alter her/his search strategy. As a general rule, it would be fair to assume that any online search will involve feedback and modifications to the search formulation - except perhaps in the case of a one concept one statement search for, say, an exhaustive literature search or for a known item search. Thus, the searcher would have to iterate some if not all of the steps 1-6. The work by Bates (1979a; 1979b; 1981; 1986; 1987), Fidel (1985), Harter and Peters (1985), etc., deals with this problem and suggests various tactics (or moves) to be made during the search. All these tactics in effect are suggestions for feedback to the database as responses to its messages (e.g., postings, error messages, etc.).
Boolean systems have disadvantages which are both well known and well documented (Belkin & Croft, 1987; Bookstein, 1985; Willett, 1988):
• they may miss many relevant records whose representations match the query only partially.
• they do not rank retrieved records. This is a consequence of the retrieval operations
which result in a simple partition of the database into discrete sub-sets, i.e., those
records that satisfy the query and are being retrieved and those which do not. All
records within the retrieved set are presumed of equal usefulness to the user and
therefore cannot be ranked in order of decreasing probability of relevance.
• they cannot take into account the relative importance of concepts either within the
query or within the document. There are no obvious means by which one can reflect
the relative importance of different components of the query, since Boolean searching
implicitly assumes that all terms have weights of either
1
or 0, depending upon whether
they happen to be present or absent in the query.
• retrieval depends on the two representations being compared having been drawn from
the same vocabulary.
• they require complicated query logic formulation. The logic associated with the
Boolean operators AND, OR, NOT has poorly understood consequences. Most users
are usually unable to make good query formulations and require the assistance of
trained intermediaries.
2.2.2 The probabilistic approach
IR researchers in their attempt to respond to the limitations of Boolean systems have
developed a number of alternative RT as seen in Figure 2.2 under partial match techniques
which are also known as best match techniques. These grew out of a number of
different theoretic models which, although they have been tested mostly under artificial
laboratory conditions, are promoted as having the potential for transforming the way
searches are implemented and for significantly improving system performance. The
most successful of these models are the probabilistic model (Maron & Kuhns, 1960;
Robertson & Sparck Jones, 1976; Croft & Harper, 1979; van Rijsbergen, 1979) and the
less formal vector space model (Salton, 1971).
Before discussing the probabilistic approach it is worth commenting on some general
issues applicable to most best match systems. An essential feature of the partial match
techniques is term weighting and the weighting matching function used. Term weights
are precision devices and distinguish the better or more important terms from the less
important ones. Such discrimination helps to rank the output in decreasing order of
presumed importance, most relevant documents at the top and least relevant at the bottom.
This comes in contrast to Boolean set retrieval where a set is retrieved and all documents
in that set are being treated as having equal importance.
Aweighting function therefore
assigns measures of relative importance to the terms which have been selected to describe
a document or a query. In other words, weighting is a feature that can be associated
withany of the partial match techniques, but the importance lies on the way one arrives at a
weighting function, i.e., theoretically or empirically.
The work of Maron and Kuhns (1960) provides a good starting point to
overview
the
theory of probabilistic retrieval. They were primarily interested in
the probabilis. tic
on the retrieval of documents. A key concept in their theory was the notion of relevance and their work on this subject made substantial contributions in the field of IR.
In their 'probability of indexing' model the probability of relevance is computed relative to evidence consisting of the type of query(-ies) that the user(s) has(have) submitted. The probability is then interpreted in its frequency sense. For example, if a query consists of a single term
Q t,
the probability that a given documentDT,R
will be judged relevant, by the user who submitted the query termQ t,
is simply the ratio of the number of users who submit termQ t1
as their search term and judge documentDnR
relevant, to the number of users who submit termQ t,
as their search term. Because of lack of actual statistics, which can only be derived from user feedback, on which to base the estimation of the values of these probabilities, an indexer can only guesstimate the values of the probabilities. Hence, in probabilistic indexing the task of the indexer is precisely defined as that of the estimation of the values of the probabilities that a term Q t1 will be used in a query where the documentDnR
will be judged as relevant by that user, i.e.,P(Qt,IA,D„R),
and then to assign those terms Q t , to the corresponding documents D with the values of those estimates.In my discussion on the theories of probabilistic retrieval I will assume that document indexing is of the conventional non-probabilistic kind, i.e., it is binary subject indexing. This is because the ideas of probabilistic indexing have different assumptions to those of probabilistic retrieval as already explained. Nevertheless, it is worth mentioning here that some of the important research work on probabilistic indexing has been done by Bookstein and Swanson (1974; 1975), Harter (1975a; 1975b) and by Salton
et al.
(1981). A recent theoretical advance is the effort to combine these theories of indexing and retrieval into a unified theory of information retrieval (Robertson, Maron & Cooper, 1982; Robertson, Maxon & Cooper, 1983).The probabilistic theory of retrieval explicitly recognises the element of uncertainty involved in the retrieval process, i.e., that given a request (query) the retrieval mechanism would have to decide which documents to retrieve and in doing so there would be some inappropriately retrieved documents while some other more desirable documents would not be retrieved.
In probabilistic retrieval index terms form the basis of the retrieval decision. Thus, a probabilistic system may begin a search by assigning probabilities, i.e., numerical measures of uncertainty, to index terms. This indicates how likely it is that those terms will appear in a relevant or non-relevant document. These probabilities are further manipulated to derive the probability that a document is relevant to a query. Let's assume that in a collection of
N
documents each document is described by the presence or absence of a number of index terms n which correspond to the terms found in the collection's main index. A document in the collection can be represented as:D =
t2) • • •tn)
where ti = 0 indicates the absence of the term, and
We have also assumed that relevance is a dichotomous variable so that a document is either relevant or non-relevant to a query. The system needs first to estimate the probability of relevance P(relevantID) or non-relevance P(nonrelevantID) of the documents. The probability of relevance is computed relative to the set of document properties, i.e., index terms assigned to it. Then the documents are ranked in descending order of their estimated probability of relevance P(relevantID) and by using some cutoff point or threshold a top-ranked portion of the documents is presented to the user.
The formal basis about ranking in probabilistic retrieval is given by the Probability Ranking Principle (PRP) formulated by Cooper (1977) and quoted from Robertson (1977b):
"... If a reference retrieval system's response to each request is a ranking of the documents in the collection in order of decreasing probability of usefulness to the user who submitted the request, where the probabilities are estimated as accurately as possible on the basis of whatever data has been made available to the system for this purpose, then the overall effectiveness of the system to its users will be the best that is obtainable on the basis of that data...
2.2.2.1 Parameter estimation
One of the most difficult parts of the probabilistic approach is that it depends on parameters, not all of whose values are known. Thus parameter estimation has always been a stumbling block in the development of probabilistic models.
A weighting scheme is needed to start the search. For example, quorum searching (or co-ordination level matching) (Cleverdon, 1984) or inverse document frequency weighting (Sparck Jones, 1972) could be used for this purpose. The IDF, an empirical weighting rule as introduced by Sparck Jones, got a theoretical justification as being a limiting case of probabilistic relevance weights (Croft & Harper, 1979; Robertson, 1986) and is discussed on page 18.
After the initial search has been carried out a set of documents is retrieved and presented for evaluation to the user. The relevance feedback provided by the user at this stage forms the basis for estimating the parameters for subsequent retrievals. The theory of relevance weights (Robertson Sz Sparck Jones, 1976) considered the use of relevance information as the basis for the weighting of query terms. It makes use of two kinds of assumptions: term independence assumptions and document ordering assumptions. These are:
12 Independence assumption: The distribution of terms in relevant documents is independent and their distribution in non-relevant documents is independent.
02 Ordering principle: That probable relevance is based on both the presence of search terms in documents and the absence from documents.
By using the above assumptions they were able to provide a theoretical framework for term weighting. Because of these assumptions, especially of 12, the relevance weighting theory is also known as the binary independence retrieval model (BIM). The basic formula is:
wi = log Pt( 1 — qt)
Document Relevance Relevant Non-relevant
n — r
R — r
N— n — -F rN — n
N — R
where pt is the probability of term
t
occurring in a relevant document qt is the probability of termt
occurring in a non-relevant documentThe application of this formula requires some knowledge as to the relative occurrence of the term in relevant or non-relevant documents. The probability
p
andq
may be estimated from relevance feedback information. So, given a sample of some, but not all, of the relevant documents probability estimates can be made. In practice it is convenient to replace the probabilities by frequencies. Let us consider the estimate for a single term t and queryq
by assuming that:N
is the total number of documents in the collectionR
is the sample of relevant documents as defined by the user's feedbackn is the number of documents indexed by term
t
r is the number of relevant documents (from the sample R) assigned to term t
For each such term
t
we can construct a 2 x 2 'contingency' table as follows:Document t i = 1 Indexing ti = 0
From the above table four relevance weighting formulae can be derived. All four formulae use the same probability estimates, i.e.
pt =
and qt = in different ways. However, only one satisfies the assumptions as mentioned above. This has become known as the F4 formula.R-r =
wt =
log n-r log r(N n R r) (2.2)(n —
r)(R — r)
N -n- R+ r
The relevance weighting theory is based on the idea that both the presence and absence of query terms in a document are important. In other words, the user wants to accept documents with good terms, i.e., ones correlated with relevance, and reject documents with bad terms, correspondingly rejecting all those without good terms and accepting the ones without bad terms 3 . For a request and document with many terms, the final result would be the net balance for all good and bad terms (Sparck Jones, 1979a, p.38). The theory provides therefore an ordering mechanism which is quantified as the
'simple sum-of-weights'
over allof the terms in the query. If ti indicates the presence
(ti =
1) or absence (ti = 0) of a term in a documentD
(see page 14) the matching function is:D =
ti
log Pt(1 — qt) (2.3)qt( 1 Pt)
There are a number of problems with the estimation of the F4 parameters. At first this information is not available. After the relevance feedback of the first iteration some relevant documents may be known and the
pt , qt
and Wt may be estimated. Robertson and Sparck Jones (1976) have shown thatpt
should be estimated from the known relevant documents, but the base for estimating q t is not quite so obvious. Harper and van Rijsbergen (1978, p.204) argued that thecomplement method
should be used, i.e., instead of using the (very few) known non-relevant documents for the estimation of q t , the remainder of the collection (i.e., all those not known to be relevant) should be used.The second problem concerns the validity of the simple proportion estimates used in F4. If any of the four cells in F4 (equation 2.2) is zero then it yields infinite weights. This possibility arises when the sample of known relevant documents is very small or zero. To overcome this problem Robertson and Sparck Jones modified the formula by adding 0.5 to each of the four quantities in the F4. The result is known as the point-5 formula:
Wt
=
log (r .5)(N — n — R+ r + .5) (2.4) (n — r .5)(R — r + .5)This correction minimises bias and does not yield infinite weights. An account of the structure of relevance weights, the presence-absence components and the approaches to estimation are given by Sparck Jones (1979a, pp.38-41).
Harper and van Rijsbergen (1978) have suggested a different version of the F4 matching function (equation 2.4) which is thought to overcome the parameter estimation problems. This function is a modification of the expected mutual information measure (EMIM) (van Rijsbergen, 1977), and because it has no theoretical basis will not be discussed any further in this chapter. A detailed account of EMIM will be given in section 7.4 on page 111.
The relevance feedback techniques mentioned so far have assumed the use of some relevance information which in a retrieval situation are available on the second or subsequent iterations of the search. In the case where no relevance information is available, i.e., in the first iteration, it has been suggested by Croft and Harper (1979) that we could assume that all the query terms have equal probabilities of occurring in the relevant documents. We could also assume that the occurrence of a term in a non-relevant document may be estimated by its occurrence in the entire collection. The two assumptions correspond to setting all pt from equation 2.1 equal to a constant (k), where C = log = log and
qt = . So, they arrive at a weighting function:
cEti+Etilog
N —
nt ntwhere nt is the number of documents indexed by term t is the total number of documents in the collection
i =
0 or 1 indicates the absence or presence of the ith termThis expression is called the combination match because it is a weighted combination of a simple co-ordination level match (the first part of the expression) and the IDF weighting (the second part).
The inverse document frequency (IDF) weighting or the collection frequency weighting as introduced by Sparck Jones (1972) is determined by the function:
wt = — log = log N — log n (2.6)
where Wt is the weight for term t
is the number of documents indexed by term t is the total number of documents in the collection
The rationale behind this approach is that of the discriminating power of a term, i.e., a frequently occurring term would occur in many irrelevant documents whereas infrequent terms have a greater probability of occurring in relevant documents. Low frequency terms are thereby given the highest weight and are most influential in determining which documents will be retrieved. In practice this weight is implemented as (Sparck Jones, 1972; Robertson, 1974)
wt = log —N + 1
The IDF weight that is derived from the Croft and Harper weighting function (equation 2.5) is marginally different from Sparck Jones'.
Two special cases could occur with the combination match depending on the values of the constant C. If C = 0, i.e., all pt = 50%, then the weighting defaults to an IDF weighting. If C approaches infinity (C oo) the weighting is approximately equivalent to ranking the documents by IDF within co-ordination level matching. This means that if more than one document have the same co-ordination level weight (i.e., they are tied on the same rank) these will be further ranked by their IDF weight.
There are two final points to be made here. Firstly, that an analysis similar to the above that demonstrates the close relationship between IDF and the relevance weight theory is given by Robertson (1986). The second point also derives from the first and challenges the Croft and Harper claim that the relevance weight theory cannot be used in the initial search. This claim holds for F4 (equation 2.2) because when R = r = 0 it becomes undefined, but not for the point-5 formula (equation 2.4), which for an initial search, where R = r = 0, it becomes:
n+ .5
Thus, according to Robertson the point-5 formula behaves like a Bayesian estimator. It provides an estimate when there is no evidence available (i.e., initial search) and modifies the initial estimate as the evidence is obtained (i.e., second and subsequent iterations). This behaviour of the relevance weight function is useful because it demonstrates some learning properties and also because it opens itself to further modification as it will be discussed later 7.4.
N — n + .5
2.2.3 Term Dependencies
The probabilistic theory for retrieval discussed so far is based on the independence assumptions given on page 15. The term independence models assume that the probability of a term occurring in one of the sets of documents (relevant or non-relevant) is the product of the probabilities of all the individual terms of that document occurring in that set, thus
P(Direlevant) = P(tiIrelevant)P(t2Irelevant)...P(tnIrelevant)
This assumption, as mentioned in the previous section, simplifies the mathematical analysis and the modelling of the retrieval process and facilitates the development of any matching function based on it. Another area of research attempted to relax this assumption, by assuming that within a single relevance class of documents terms are not distributed independently of one another. If this assumption is true then the incorporation of dependency information into the models should yield better retrieval effectiveness in the retrieval based on such models.
Two ways have been identified so far that introduce term dependence. One is using general distribution function approximation techniques and the other is attempting to model the cause of term dependence. The latter has been suggested by Bookstein and Kraft (1977) but it is still untested and therefore it will not be discussed any further.
Van Rijsbergen (1977) applied the work of Chow and Liu (1968) on tree dependences to the IR situation. By using conditional probability distributions he developed a retrieval model which incorporates first order tree dependence between terms. This could be explained as ordering the terms so that:
(a) term ti is dependent on one of its preceding terms only, and
(b) in every such tree there is only one independent term (i.e., the root of the tree).
Of all the possible dependence trees van Rijsbergen defined the best dependence tree for the Chow expansion as being the Maximum Spanning Tree (MST). This theoretical tree dependence model has been developed into an algorithm (EMIM) (Harper & van Rijsbergen, 1978) which is discussed in section 7.4.
The second approximation technique is based on the Bahadur-Lazarfeld expansion (BLE) as described by Duda and Hart (1973) and it was introduced in IR by Clement Yu and co-workers (see Yu et al (1979; 1983). The BLE expansion involves the sum of a constant term, a set of terms with a single variable, another set with pairs of variables, then another set with triplets of variables and so on. The term dependence is calculated by correlation type coefficients which measure the times that terms t i co-occur in documents with a document collection. In general, parameter estimation is problematic as it is difficult to interpret the results in a satisfying way (Bookstein, 1985, p.132).