Synthesis of Probabilistic Models for Quality-of-Service Software Engineering
Full text
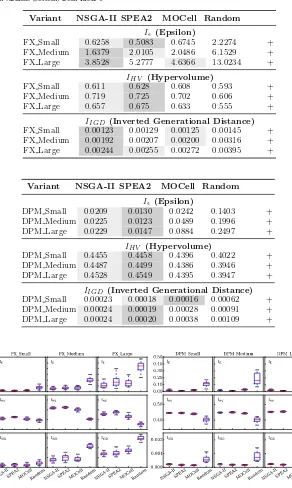
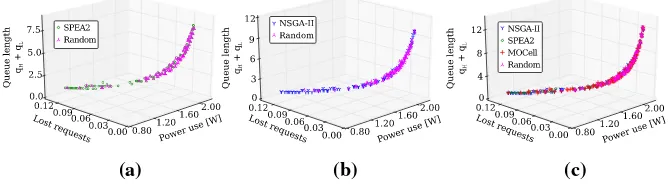
Figure




Related documents
We are constructing a new approach to software engineering education that integrates software process simulation, simulation games, and economic software engineering cost models
In the past five years there has been a dramatic increase in work on Search Based Software Engineering (SBSE), an approach to Software Engineering (SE) in which Search
Search Based Requirements Optimisation: Existing Work and Challenges, in: International Working Conference on Requirements Engineering: Foundation for Software Quality
Also differentiates traffic flow based on priority classes according to their QOS needs to meet the QOS requirements of diverse smart grid application attributing
software quality assurance & software Product line engineering written exam 2 software concept engineering (7) requirements engineering & software architectures for
• Component Component - - based software engineering (CBSE) is an approach to based software engineering (CBSE) is an approach to software development that relies on software
– (2) the application of a systematic, disciplined, quantifiable approach to the development, operation, and maintenance of software; that is, the application of engineering
Abstract: Software engineering is the establishment and application of sound engineering principals for obtaining economically feasible and reliable software that
