Web tools for introductory computational linguistics
D a f y d d G i b b o n
Fakultilt fllr Ling. 8z Lit. Pf. 100131, D - 3 3 5 0 1 Bielefeld
g i b b o n ~ s p e ct rum. u n i - b i e l e f eld. de
Julie Carson-Berndsen
D e p a r t m e n t of C o m p u t e r S c i e n c e
Belfield, D u b l i n 4, I r e l a n d
Julie. Berndsen@ucd. ie
A b s t r a c t
We introduce a notion of
training
methodology space
(TM space) for specifying training methodologies in tile different disciplines and teaching traditions associated with computa- tional linguistics and the human lan- guage technologies, and pin our ap- proach to the concept ofoperational
model;
we also discuss different gen- eral levels of interactivity. A num- ber of operational models are intro- duced, with web interfaces for lexical databases, DFSA matrices, finite- state phonotactics development, and DATR lexica.1 W h y
tools
f o r C Ltraining?
In computational linguistics, a number of teaching topics and traditions meet; for ex- ample:
• tbrmal mathematical training,
• linguistic argumentation using sources of independent evidence,
• theory development and testing with em- pirical models,
• corpus processing with tagging and sta- tistical classification.
Correspondingly, teachers' expectations and teaching styles vary widely, and, likewise, students' expectations and accustomed styles of learning are very varied. Teaching methods and philosophies fluctuate, too, between more behaviouristic styles which are more charac- teristic of practical subjects, and the more
rationalistic styles of traditional m a t h e m a t - ics training; none, needless to say, covers the special needs of all subjects.
Without specifying the dimensions in de- tail, let us call this complex field
training
method space (TM space).
The termtrain-
ing
is chosen because it is neutral betweenteaching
andlearning,
and implies the inten- sive acquisition of both theoretical and prac- tical abilities. Let us assume, based on the variations outlined above, that we will need to navigate this space in sophisticated ways, but as easily as possible. What could be at the centre of TM space? As the centre of TM space, let us postulate amodel-based
training method, with the following properties:1. The models in TM space are both formal, and with operational, empirical interpre- tations.
2. The empirical interpretations of models in TM space are in general operational models implemented in software.
3. The models in TM space may be under- stod by different users from several differ- ent perspectives: from the point of view of the mathematician, the programmer, the software user etc., like 'real life pro- grammes'.
4. Typical lingware and software models are grammars, lexica, annotated corpora, op- erationalised procedures, parsers, com- pilers; more traditional models are graphs, slides, blackboards, t h r e e - dimensional block or ball constructions, calculators.
i
space? There are several facets to the answer: First, the use of operational models permits
practice
without succumbing to the naiveti@s of stimulus-response models. Second, this no- tion of model isintegrative,
that is, they are on the one handmathematical,
in that they are structures which are involved in the in- terpretation of theories, and at the same time they areempirical,
in representing chunks of the world, andoperational,
in that they map temporal sequences of states on to real time sequences. But, third, working with opera- tional models is morefun.
Ask our kids.This paper describes and motivates a range of such models: fbr arithmetic, for manipu- lating databases, for experimenting with fi- nite state devices, for writing phonological (or, analogously, orthographic) descriptions, for developing sophisticated inheritance lex- ica.
2 W h a t k i n d o f
i n t e r a c t i v i t y ?
The second kind of question to be asked is: Why the Web? Interactive training tools are not limited to the Web; they have been dis- tributed on floppy disk for over two decades, and on CD-ROM for over a decade. In pho- netics, interactive operational models have a long history: audio I/O, visualisations as os- cillogrammes, spectrogrammes, pitch traces and so on, have been leading models for multi-media in teacher training and speech therapy education since the 1970s. So why the Web? The answers are relatively straight- fbrward:
• The Web makes software easy to dis- tribute.
• The Web is both a distributed user plat- form a n d a distributed archive.
• New forms of cooperative distance learn- ing become possible.
• Each software version is instantly avail- able.
• The browser client software used for accessing the Web is (all but) univer- sal (modulo minor implementation dif- ferences) in many ways: platform inde- pendent, exists in every office and many
h o u l e s , ...
The tools describe here embody three dif- ferent approaches to the
dependence
of stu- dents on teachers with regard to the provision of materials:1. Server-side applications, realised with standard CGI scripts: practically un- limited functionality, with arbitrary pro- gramming facilities in the background, but with inaccessible source code. 2. Compiled client-side applications, re-
alised with Java: practically unlimited functionality, particularly with respect to graphical user interfaces, typically with inaccessible source code.
3. Interpreted client-side applications, re- alised with JavaScript: limited func- tionality with respect to graphical user interfaces, functionality limited to text manipulation and manipulation of HTML attributes (including CGI pre- processing), typically with immediately accessible code.
There is another issue of interactivity at a very general level: in software development, perhaps less in the professional environment t h a n in the training of non-professionals to u n d e r s t a n d what is 'going on under the bon- net', or to produce small custom applications: the open software, shared code philosophy. In the world 'outside' salaries are obviously de- pendent on measurable product output, and intellectual property right (IPR) regulations for shareware, licences and purchase are there to enable people to make a legitimate living from software development, given the prevail- ing structures of our society.
As far as teaching is concerned, the de- bate mainly affects programmes with m e d i u m functionality such as basic speech editors or morphological analysers, often commercial, with products which can be produced in prin- ciple on a 'hidden' budget by a small group of advanced computer science or engineering students (hence the problem). Obviously, it is easy for those with in stable educational institutions to insist that software is common property; indeed it may be said to be their duty to provide such software, particularly in the small and m e d i u m functionality range.
Finally, it is essential to consider design is- sues for interactive teaching systems, an area which has a long history in teaching method- ology, going back to the p r o g r a m m e d learning and language lab concepts of the 1960s, and is very controversial (and beyond the scope of the present paper). We suggest that the dis- cussion can be generalised via the notion of T M space introduced above to conventional software engineering considerations:
require-
ments spec~ifieation
(e.g. specification of loca- tion in T M space by topic, course and student type),system design
(e.g. control structures, navigation, windowing, partition of material, use of graphics, audio etc.),implementation
(e.g. server-side vs. client side),verifica-
tion
(e.g. 'subjective', by users; 'objective', in course context).Only a small a m o u n t of literature is avail- able on teaching tools; however, cf. (HH1999) {br speech applications, and the following for applications in phonetics and phonology
(CB1998a), (CBG1999), English linguistics (CBG1997), and multimedia communication (G1997). The following sections will discuss a number of practical m o d e l - b a s e d applica- tions: a basic database environment; an in- terpreter for deterministic finite automata; a development environment for phonotactic and orthographic processing; a testbed and scratchpad for introducing the D A T R lexi-
cal representation language. T h e languages
used are JavaScript (JS) for client-side appli- cations, a n d Prolog (P) or C (C) for server-
side C G I applications.
3 D a t a b a s e q u e r y i n t e r f a c e
g e n e r a t o r
Database m e t h o d o l o g y is a n essential part of computational linguistic training; tradition- ally, U N I X A S C I I databases have b e e n at the core of m a n y N L P lexical databases, t h o u g h
large scale applications require a professional
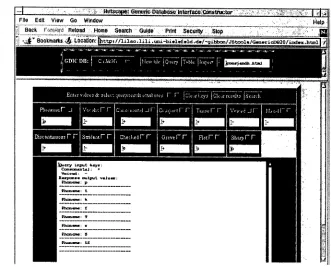
D B M S . T h e e x a m p l e s h o w n in Figure 1 s h o w s
a distinctive feature matrix (Jakobson a n d Halle consonant matrix) as a database rela- tion, with a query designed to access phono-
logical 'natural classes'; any lexical database relation can be implemented, of course. In this JavaScript application with on-the-fly
query interface generation the following func- tionality is provided:
i. Input a n d query of single database rela- tions.
2. F r a m e structure, with a control frame
a n d a display/interaction frame w h i c h is allocated to on-the-fly or pre-stored database information.
3. T h e control frame permits selection of:
(a) a file containing a pre-compiled database in JavaScript notation, (b) on-the-fly generation of a query in-
terface from the first record of the database, w h i c h contains the n a m e s of the fields/attributes/flolumns, (c) on-the-fly generation of tabular rep-
resentation of the database,
(d) input of databases in tabular form.
Figure 1: Database interface generator (JavaScript).
5. C o m p i l a t i o n of database into a
JavaScript data structure: a o n e -
dimensional array, with a presentation
p a r a m e t e r for construction of the
on-the-fly query interface.
Typical applications include basic dictio- naries, simple multillingual dictionaries, rep- resentation of feature structures as a database relation with selection of n a t u r a l classes by means of an appropriate conjunction of query attributes and values.
Tasks range from user-oriented activities such as the construction of 'flat' databases, or of feature matrices, to the analysis of the code, and the addition of further input modal- ities. Advanced tasks include the analysis of the code, addition of character coding conven- tions, addition of further database features.
4
D F S A i n t e r p r e t e r
There are m a n y contexts in computational linguistics, n a t u r a l language processing and spoken language technology in which devices based on finite state a u t o m a t a are used; for example, tokenisation, morphological analy- sis and lemmatisation, shallow parsing, syl-
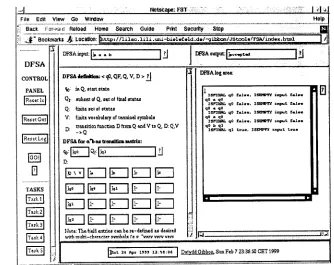
lable parsing, prosodic modelling, plain a n d hidden markov models. A s t a n d a r d compo- nent of courses in these disciplines is con- cerned with formal languages and a u t o m a t a theory. T h e basic form of finite state a u t o m a - ton is the deterministic finite state automa- ton (DFSA), whose vocabulary is epsilon-free and which has no more t h a n one transition with a given label from any state. T h e r e are several equivalent representation convert- tions for DFSAs, such as a full transition matrix (Vocabulary × StateSet) with target states as entries; or sparse m a t r i x represen- tation as a relation, i.e. a set of triples con- stituting a subset of the Cartesian p r o d u c t S t a t e S e t × Stateset x Vocabulary; or transi- tion network representation.
T h e interface currently uses the full m a t r i x representation, and permits the e n t r y of arbi- t r a r y a u t o m a t a into a fixed size matrix. T h e example shown illustrates the language a'b, but symbols consisting of an a r b i t r a r y n u m b e r
of characters, e.g. natural language examples,
[image:4.596.120.451.107.374.2]Fil~ l~clil Vlsw GO Wlrxlow Help I
D F S A i ~ p ~ t : I j ~ . .
I-~ I ~ ° ~ l - ~ ' ~
Q~. ~ a b s ~ ~ Q, set ot fia~l ~tatea
Q: finite s¢~ o| ~t~t~
D: u m s i ~ l+ancc+tion D Rom Q ~ d g to Q, D: Q,V D F S A ~cm ~ eu~ ~ e m R R m matrix:
+:[~-"~,+:1 ~'~
I~
D:t
IX~RA log mrs:
[
q O . qO
= . H
z s ~ . + qo r . ~ i . , xmaqp~,~, al~,.,r. • .l q O . qO
151rllf+tJ~ qO ~618e, 15mF'l~ i~pa~ =~11~
qo ~ qO qo b q)
F T1 i 7 - 1 F - ] F - - 1 1 7 - 1 F - 1 F - - I E ~ a - l g - 1 7 - - ] + +,
1 7 1 1 7 - 1 F - 1 1 7 - - 1 F - 1 t [] "~ , I
F - 1 7 - 1 F - 1 7 - - 1 F - ] ,~
, ,'~'~ m,,~-~h,,,?,~,,*~0~, ,,., -~,~, v,~,, ~,.~. ... ' . . . . , ,,,, ... i! [ ~ . . . I Dalydd Oi~bom Stm Feb 7 23:36:$0 ~ ' r 1999
Figure 2: Deterministic finite state automaton (DFSA) workpad (JavaScript).
provided.
5 P h o n o l o g i c a l N D F S A d e v e l o p m e n t e n v i r o n m e n t
Phonology and prosody were the first areas in which finite state technologies were shown to be linguistically adequate and computa- tionally efficient, in the 1970s; a close second was morphological alternations in the 1980s (CB1998a). The goal of this application is to demonstrate the use of finite state tech- niques in computational linguistics, partic- ularly in the area of phonotactic and allo- phonic description for computational phonol- ogy. However, the tool does not contain any level specific information and can therefore be used also to demonstrate finite state de- scriptions of orthographic information. In this CGI application, implemented in Prolog (see (CBG1999)), the following functionality is provided:
1. Display/Alter/Add to the current (non- deterministic) FSA descriptions.
2. Generate the combinations described in the FSA.
3. Compare two FSA descriptions.
4. Parse a string using an FSA description.
Typical applications of this tool include de- scriptions of phonological well-formedness of syllable models for various languages. Tasks range from testing and evaluating to parsing phonological (or orthographic) FSA descrip- tions. More advanced tasks include extension of the current toolbox functionality to cater for feature-based descriptions.
[image:5.596.122.456.105.370.2]File Edit View GO Window • " ] . : ( ,,° " Help.
, . . . ~ . . . . ~ - - . ~ , . : , _ _ ~ , ~ : , ~ ... ~. ... - . . . ~ . . . ~ . ~ .
Back ¢ o r ~ ¢ . : ~ Reload : Home ~;ea~ch Guide • Pdnt . Secuflty ~ l ~
ZI3A'FR HyprLex Scraud|pad
T H E O R Y
Q U E R Y
Dafydd Gibbon, B B i r d c i e l d , 2 2 M a r c h 19~7
( d r . : I h g g " ~ r E t
¢ o - g a l d m t . _ g m a p l e D ~ ~ t s ~ = i ~ ( . . . f 11 h ~ . ~ g l : i ~ l t = ~ t a a m t o t ~ l g ~ ( a l r z a . d t t - P i n i t a St, a t a ~ u t ~ a r ~ = ~ ~a= h z e q = ~ * c (31 r s l . d r = F ~ i n t e z p z e t ~ ~ir.l~ t y p e c c ~ e c 4 ~ f o = h = ~ - = b * c
(11 t m . d t z - I L ~ ( ' ~ a i c c m p ~ a l t i ~ l t : ~ t . ~ t o g i ~ t q l i E l ~
~ = ~ i g z :
o
M o ~ f e
( b u . * h o u • .
w o = d :
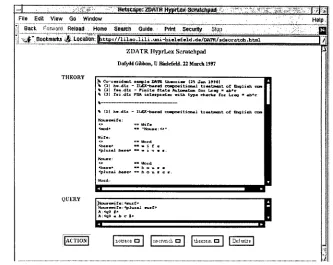
Figure 3: Zdatr scratchpad (CGI, UNIX shell, C).
was later replaced by Zdatr Vl.n, and will shortly be replaced by Zdatr V2.0 (imple- mented by Grigoriy Strokin, Moscow State University). The Zdatr software is widely used in the teaching of lexicography, lexicol- ogy, and lexicon theory (Ginpress).
Two interikces are driven by Zdatr: The testbed which permits interactions with pre- viously defined and integrated DATR theo- ries (CBG1999), and the scratchpad (shown in Figure 3), with which queries can be writ- ten and tested. The scratchpad permits the entry of short theories and queries, and the
testbed has the following functionality:
1. viewing of DATR theories;
2. selection of manual, declared (#show and # h i d e ) and pre-listed queries;
3. selection of o u t p u t properties (trace, atom spacing).
4. a function for automatically integrating new theories sent by email (not docu- mented for external use).
Sample DATR theories which are avail- able include a detailed model of composition- ality in English c o m p o u n d nouns (Gibbon),
an application for developing alternative fea- ture or autosegmental phonological represen- tations (Carson-Berndsen), and a number of algorithm illustrations (bubble sort, shift reg- ister machine) for more theoretical purposes.
7 O u t l o o k
Tools like those introduced here are not ubiq- uitous, and there are many areas of computa- tional linguistics, in particular formal train- ing in computing and training in linguistic argumentation, which require intensive face- to-face teaching. Our tools are restricted to 'island' applications where we consider t h e m to be most effective. For many students (and teachers), such tools provide an additional level of motivation because of their easy ac- cessibility, portability, and the absence of in- stallation problems, and can be used with dif- ferent levels of student accomplishment, from the relatively casual user in a foreign language or speech therapy context, to the more ad- vanced linguistic programmer in courses on database or a u t o m a t a theory or software de- velopment.
[image:6.596.120.453.108.373.2]we favour client-side tools where possible. JavaScript is suitable in m a n y cases, provided t h a t minor browser incompatibilities are h a m dled. T h e database application, for exam- ple, still provided very fast access when eval- uated with a 2000 record, 10 attributes per record database. JavaScript has a n u m b e r of disadvantages (no mouse-graphics interac- tion, no library concept), but being an inter- preted language is very suitable for introduc- ing an 'open source code' policy in teaching. In contrast to CGI applications, where query and result transfer time can be considerable, client-side JavaScript (or Java) applications have a b a n d w i d t h d e p e n d e n t once-off down- load time for databases and scripts (or com- piled applets), but query and result transfer time are negligeable.
T h e applications presented here are fully integrated (with references to related appli- cations at other commercial a n d educational institutions, e.g. parsers, morphology pro- grammes, speech synthesis demonstrations) into the teaching programme. Obvious areas where further development is possible and de- sirable are:
• A u t o m a t i c tool interface generation based more explicitly on general princi- ples of training methodology, e.g. with a more explicit account of T M space and with more systematic control, help, error detection, query and result panel design. • A u t o m a t i c test generation for tool (and
student) validation.
• F u r t h e r tools for formal language, pars- ing and a u t o m a t a theoretic applications. • Extension of database tool to include
more database functionality.
We plan to e x t e n d our repertoire of appli- cations in these directions, and will inte- grate more applications from other institu- tions w h e n t h e y become available.
Essen (eds.) Language Teaching and Language Technology, Swets & Zeitlinger, Lisse.
Carson-Berndsen, J. 1998b. Time Map Phonol- ogy: Finite State Methods and Event Logics in Speech Recognition. Kluwer Acadmic Press, Dordrecht.
Carson-Berndsen J. & D. Gibbon 1997. In- teractive English, 2nd Bielefeld Multime- dia D a y D e m o , "coral. lili .uni-bielefeld. de/
MuMeT2", Universitit Bielefeld, November 1997. Carson-Berndsen J. & D. Gibbon 1999. Interac- tive Phonetics, Virtually! In: V. Hazan & M. Holland, eds., Method and Tool Innovations/or Speech Science Education. Proceedings off the MATISSE Workshop, University College, Lon- don, 16-17 April 1999, pp. 17-20.
Gibbon, D. 1 9 9 7 . Phonetics and
Multimedia Communication, Lecture
Notes, "coral. lili. uni-bielefeld, de/
Classes/Winter97", Universit~it Bielefeld.
Gibbon, D. in press. Computational lexicogra- phy. In: van Eynde, F. & D. Gibbon: Lexicon Development/or Speech and Language Process- ing. Kluwer Academic Press, Dordrecht. Hazan, V. & M. Holland, eds. 1999. Method and
Tool Innovations/or Speech Science Education. Proceedings o/ the MATISSE Workshop, Uni- versity College, London, 16-17 April 1999.
R e f e r e n c e s