© 2018 IJSRCSEIT | Volume 3 | Issue 3 | ISSN : 2456-3307
Analysis of Two Phase Scheduling Within Distributed System
for Enhancement of Makespan and Flowtime
Jasjit Singh, Anil Kumar
Computer Science & Engineering Department,Guru Nanak University, Amritsar, Punjab, India
ABSTRACT
The primary aim of task scheduling is to allocate tasks to accessible processors to deliver least schedule
length without compromising the priority limitations. In distributed system environment the load is
distributed among different servers because they have its own resources. Even though, number of
scheduling algorithms is available for solving task scheduling algorithms. In our proposed paper we
use two phase scheduling techniques for real time distributed systems. The first phase helps in
producing scheduling sequence and second phase aims to dispatch tasks to different nodes in network.
Our approach provides high flexibility so that developer can apply multiple policies in each phase.
Both the phases are independent so that changes in one phase did not impact the other phase. We
implement the first phase with three sorting techniques and second phase having two scheduling
techniques. our approach also uses EDF (Earliest Dead line first ) and AEAP ( As early as Possible)
leads to an optimized performance.
I.
INTRODUCTION
Cloud computing and service level agreement structures are driving a move toward distributed constant systems, where the achievement of utilizations to a great extent relies upon quality of-service (QoS) execution (i.e., due dates and accessibility).(Chronaki et al. 2016) A Service Level Agreement (SLA) is connected as an agreement between clients and specialist co-ops. In this investigation, we concentrate on planning methods that assign computing assets to errands in an approach to fulfil due date necessities to satisfy a predetermined SLA in distributed systems (Chwa et al. 2016)(e.g., Hadoop computing situations).
(Pavani & Tinini 2016)A distributed system comprises of approximately coupled computing hubs associated through Ethernet or different systems. Booking plans play an critical part in accomplishing superior of distributed systems. Planning calculations
are isolated into two classes, to be specific, dynamic booking and static planning. To fulfil a given SLA of continuous applications in distributed systems, planning instruments are dependable for guaranteeing that all assignments are finished before their due date. (Nasr 2015b)Existing continuous booking calculations found in the writing incorporate both pre-emptive and non-pre-emptive. A modest bunch of ongoing applications running in the administration arranged engineering worldview are contained autonomous undertakings (see, for instance, where there is no intercommunication among constant undertakings.
continuous undertakings having priority requirements. (He et al. 2015)A developing number of constant applications can be sensibly displayed in the type of a coordinated non-cyclic chart (DAG), in which hubs and edges speak to errands and correspondence, individually.
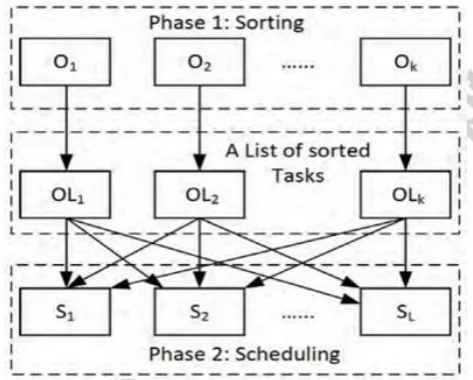
(Liang et al. n.d.)Third, breaking a planning instrument into two particular stages is engaging, in light of the fact that this approach enables us to research effects of arranging arrangements on planning strategies and the other way around. Accordingly, we address the previously mentioned three issues by building up a two-phase booking system, for distributed ongoing systems in this paper.(Hidri & Gharbi 2017) Dissimilar to customary booking calculations, TOPS flawlessly incorporates two unmistakable stages. The main stage is accountable for creating a booking arrangement, though the second stage intends to dispatch the undertakings to computing hubs of a distributed system. The second stage too sensibly decides the beginning time of each assignment. (Saha et al. 2016)TOPS empowers system designers to simultaneously apply different arrangements in two stages. As it were, a system overseer is permitted to change a approach in one stage without designing another stage. Given a distributed system where there are M strategies in stage one and N approaches in stage two, the aggregate number of booking calculations offered by the two-stage system is MN.
Figure 1. Decomposing an entire scheduling mechanism into two distinct phases.
A moment advantage of this approach is making it conceivable to freely what's more, simultaneously examine arranging strategies in stage one and booking arrangements in stage two. (Zahedani & Dastghaibyfard 2014)With TOPS set up, we can watch the effects of arranging arrangements on the execution of planning strategies. We actualize a model of TOPS, where the primary stage is included three arranging approaches and the second stage comprises of two booking arrangements. (Kim et al. 2015)
(Nadeem et al. n.d.)TOPS empower us to find that consolidating the EDF and AEAP arrangements prompts an enhanced execution among all the six applicant calculations. The fundamental commitments of this work include:
1. A propelled two-stage booking system. 2. The outline and usage of three arranging
strategies and two booking arrangements in TOPS.
3. The execution assessment of individual calculations that incorporate arranging and booking strategies through broad tests.
System Model and problem Formulation
We show every application in type of an ongoing non-cyclic coordinated chart, where every ongoing undertaking is a major part that isn't detachable.(Lee et al. 2017) Comparative assignment models are generally utilized continuously Systems.
(Desai 2015)A parallel and distributed constant application is spoken to as a directed non-cyclic diagram characterized as RG={T, E}, where assignment set T contains a rundown of synergistic assignments (i.e., T={t1,t2, ..., tn}, and message set E represents messages. Note that set E also takes after priority requirements among continuous assignments in T. Task t is displayed as a tuple, t =(e, d, s, f, g, ρ), where e, d, s, and f speak to execution time, due date, begin time, and complete time of task t. G is t's in-degree showing the quantity of the undertaking's guardian errands in assignment chart RG, and ρ denotes a computing hub to which t is relegated.
(Zuo et al. 2015)Each message m in E is conveyed starting with one undertaking then onto the next. We characterize message m as a tuple, m=(ts, tr, s, f, c), where ts and tr are errands sending what's more, getting the message; s and f are the message's begin time and blade is h time; and c is message measure deciding the correspondence cost of the message. In this investigation, we concentrate on parallel and distributed systems that have no worldwide shared memory, implying that each computing hub freely deals with its neighbourhood principle memory. A parallel and distributed system is formally communicated as a set Ω ={P1,P2, ..., Pm}of computing hubs, which shape a completely interconnected computing condition.(Lin et al. 2016) Every hub in the system is displayed as Pi =(Δi, Mi), where undertakings in list Δi are appointed to Pi and assignments in Δi are arranged in a non-diminishing request of their begin times; message set Mi contains all messages conveyed from node Pi to alternate hubs in the system. (Hesabian et al. 2015)To encourage the introduction, we show message set Mi as a union of m disjoint sets. Along these lines, we have
Mi=Mi1∪...∪Mij∪...∪Mim, where j=i; all messages in set Mij are transmitted from node Pi to Pj. The messages put away in Mij are arranged in non-diminishing request of message begin times.(Mubarak et al. 2016) It is significant that a dominant part of parallel and distributed systems can be normally spoken to by this system display.
II.
OBJECTIVES OF SCHEDULING
An essential target of booking errands in a distributed continuous system is to dole out each errand to the most suitable computing hub and to choose the assignments begin time. (Zuo et al. 2015)The planning objective for continuous applications running on distributed systems is two creases. Initial, a scheduler needs to guarantee that each assignment's constant necessity is fulfilled. The primary target can be formally communicated as
∀ti ∈δj ,1≤i≤n,1≤j≤m: fi ≤di (1) Second, the system ought to limit the quantity of dynamic computing hubs to meet the due dates of assignments. Before displaying this goal in a formal way, we indicate a distributed system Ω as a union of two disjoint hub sets Ωactive and Ωidle.(Shi et al. 2016) Thus, wehaveΩ=Ω active ∪Ωidle. Ωactive is an arrangement of hubs to which there is no less than one doled out undertaking; Ωidle contains hubs where there are no doled out undertakings. Let |ωactive| speak to the quantity of computing hubs. At that point, the second goal can be composed as MP(RG,Ω) = min{|ωactive|} (2)
(Wahidah et al. 2015)The advantage of the second target is to enhance system use while making expansive scale distributed systems vitality productive. High vitality efficiency can be clearly accomplished by putting inert hubs in set Ωidle into the low-control mode.
III.
LITERATURE REVIEW
through sharing hub points going from PCs to supercomputers appropriated the world over. As the grid circumstances energize appropriated figuring, the arranging of grid jobs has transformed into a basic issue. In this paper, an examination on realizing Two-Phase Variable Neighborhood Inquiry (TPVNS) count for arranging self-ruling occupations on computational grid is finished. The proposed estimation involves two modules with General Variable Neighborhood Search and Basic Variable Neighborhood Search calculation to find a decent mapping of grid jobs with grid hub points. The execution of the proposed figuring has been surveyed with deterministic heuristic and developmental calculations. Recreation comes about demonstrate that TPVNS calculation by and large performs superior to the current strategies.(Wu et al. 2014) (Nasr 2015b) The primary goal of undertaking booking is to relegate assignments onto accessible processors with the point of creating least plan length and without disregarding the priority requirements. A few calculations have been proposed for explaining assignment planning issue. The vast majority of them don’t take into account the normal correspondence of guardians and information prepared time. In this paper, another static planning calculation is proposed called Communication Levelled DAG with Duplication (CLDD) calculation to effectively plan assignments on the heterogeneous distributed computing frameworks. It understands most restrictions of existing calculations. The calculation not just concentrates on diminishing the Makespan, yet in addition gives better execution than alternate calculations as far as speedup, productivity and time intricacy. It comprises of three stages, level arranging stage, errand organizing stage and processor determination stage. We assess the execution of our calculation by applying it on irregular DAGs. As indicated by the advanced comes about, it has been discovered that our calculation outflank the others.
(Heuristics et al. 2016) The fundamental goal of undertaking planning is to allocate errands onto accessible processors with the point of delivering least plan length and without damaging the priority imperatives. A few calculations have been proposed for explaining undertaking planning issue. The vast majority of them don’t take into account the normal correspondence of guardians and information prepared time. In this paper, another static booking calculation is proposed called Communication Levelled DAG with Duplication (CLDD) calculation to productively plan errands other heterogeneous distributed computing frameworks. It illuminates most restrictions of existing calculations. The calculation not just concentrates on diminishing the Makespan, yet in addition gives better execution than alternate calculations as far as speedup, proficiency and time multifaceted nature. It comprises of three stages, level arranging stage, undertaking organizing stage and processor determination stage. We assess the execution of our calculation by applying it on irregular DAGs. As per the developed comes about, it has been discovered that our calculation beat the others.
procedures crosswise over processors. At long last, this paper will give some dialog among these booking instruments and their blends.
(Gupta et al. n.d.) We consider the issue of planning distributed planning calculations for remote systems. We display two calculations both of which accomplish throughput discretionarily close to that of maximal calendars, yet whose intricacy is low because of the way that they don't really endeavour to discover maximal timetables. The primary calculation requires each connect to gather nearby line length data in its neighbourhood, and its multifaceted nature is generally free of the size and topology of the system. The second calculation, introduced for the node exclusive obstruction display, does not expect hubs to gather line length data even in their nearby neighbourhoods, and its unpredictability depends just on the most extreme hub degree in the organize.
(Vasile et al. 2014) Today, practically everybody is associated with the Internet and utilizations distinctive Cloud answers for store convey and process information. Cloud computing amasses huge systems of virtualized administrations such as equipment and programming assets. The new period in which ICT entered all spaces (medicinal services, matured care, social help, and observation, training and so forth.) makes the need of new sight and sound substance driven applications. These applications produce immense measure of information, require
social occasion, preparing and after that conglomeration in a blame tolerant, solid and secure heterogeneous distributed framework made by a blend of Cloud frameworks (open/private), cell phones systems, desktop-based bunches, and so forth. In this setting dynamic asset provisioning for Big Information application planning progressed toward becoming is a test in present day frameworks. We proposed a resource aware half breed planning calculation for various sort of use: group employments and work processes. The proposed calculation considers various levelled bunching of the accessible assets into gatherings in the designation stage. Undertaking execution is performed in two stages: in the primary, errands are doled out to gatherings of assets and in the second stage; an established planning calculation is utilized for each gathering of assets. The proposed calculation is reasonable for Heterogeneous Distributed Computing, particularly for present day High-Performance Computing (HPC) frameworks in which applications are demonstrated with different necessities (both IO and computational escalated), with emphasize on information from sight and sound applications. We assess their execution in a sensible setting of CloudSim instrument concerning load-adjusting, cost funds, reliance confirmation for work processes and computational proficiency, and examine the computing strategies for these execution measurements at runtime.
Comparison table of literature review is given below: Table 1
Title Technique Parameters Merits Demerits
Task Scheduling Using Two-Phase Variable Neighborhood Search
Algorithm on
Heterogeneous Computing
and Grid
Environments(Manimegalai 2015)
Two-Phase Variable Neighborhood
Search (TPVNS)
Algorithms
General Variable Neighborhood Search and Basic Variable
Neighborhood Search
High
Performance
Evaluation of performance is tough
for High Performance
Heuristics(Heuristics et al. 2016) Scheduling in Distributed
Systems Algorithms for Wireless Networks(Gupta et al. n.d.) Scheduling Algorithm in Heterogeneous Distributed scheduling approach for parallel and distributed constant systems. TOPS decay a scheduler into two primary stages. The main stage is an arranging approach, though the second stage is a scheduling arrangement. With TOPS set up, one is permitted to contemplate the effect of an arranging approach on a scheduling strategy and the other way around. TOPS make it conceivable to adaptable make an extensive variety of schedulers via consistently integrating an arranging strategy in stage one with a scheduling approach in stage two. To show the quality of TOPS, we composed three arranging strategies in the primary stage and two scheduling strategies in the second stage. We quantitatively assess the execution
of the six schedulers, which join the arranging approaches and scheduling strategies in the TOPS structure. Our exploratory outcomes demonstrate that among the tried calculations, EDF/AEAP displays the best scheduling execution.
V.
REFERENCES
[1]. Chronaki, K. et al., 2016. Task Scheduling Techniques for Asymmetric Multi-core Systems.,14(8).
[2]. Chwa, H.S. et al., 2016. Global EDF Schedulability Analysis for Parallel Tasks on Multi-core Platforms.,XX(X).
[4]. Gupta, A., Lin, X. & Srikant, R., Low-Complexity Distributed Scheduling Algorithms for Wireless Networks.,X(Xx), pp.1–14.
[5]. He, L., Zhu, H. & Jarvis, S.A., 2015. Developing Graph-based Co-scheduling Algorithms on Multicore Computers.,9219(c), pp.1–15.
[6]. Hesabian, N., Haj, H. & Javadi, S., 2015. Optimal Scheduling In Cloud Computing Environment Using the Bee Algorithm.,3(6), pp.253–258.
[7]. Heuristics, P.T.B. et al., 2016. Efficient Resource Constrained Scheduling using.,9219(c).
[8]. Hidri, L. & Gharbi, A., 2017. New efficient lower bound for the Hybrid Flow Shop
Scheduling Problem with
Multiprocessor.,XX(XX), pp.1–14.
[9]. Kim, D., Lee, T. & Kim, H., 2015. Optimal Scheduling of Transient Cycles for Single-Armed Cluster Tools With Parallel Chambers.,pp.1–11.
[10]. Lee, H. et al., 2017. GPU Architecture Aware Instruction Scheduling for Improving Soft-error Reliability.,XX(XX), pp.1–14.
[11]. Liang, D., Ho, P. & Liu, B., Scheduling in Distributed Systems.,pp.1–9.
[12]. Lin, B. et al., 2016. A Pretreatment Workflow Scheduling Approach for Big Data Applications in Multi-cloud Environments.,4537(1932). [13]. Manimegalai, S.S.D., 2015. Task Scheduling
Using Two-Phase Variable Neighborhood Search Algorithm on Heterogeneous Computing and Grid Environments.,pp.817– 818.
[14]. Mubarak, M. et al., 2016. Enabling Parallel Simulation of Large-Scale HPC Network Systems.,X(X).
[15]. Nadeem, Q. et al., Multi-Hop Routing Protocol for WSNs.
[16]. Nasr, A.A., 2015a. Performance Enhancement of Scheduling Algorithm in Heterogeneous Distributed Computing Systems.,6(5), pp.88– 96.
[17]. Nasr, A.A., 2015b. Task Scheduling Algorithm for High Performance Heterogeneous Distributed Computing Systems.,110(16), pp.23–29.
[18]. Pavani, G.S. & Tinini, R.I., 2016. Distributed meta-scheduling in lambda grids by means of Ant Colony Optimization. Future Generation Computer Systems, 63, pp.15–24.
[19]. Saha, S., Pal, S. & Pattnaik, P.K., 2016. A Novel Scheduling Algorithm for Cloud Computing Environment.,1.
[20]. Shi, L. et al., 2016. Energy-aware Scheduling of Embarrassingly Parallel Jobs and Resource Allocation in Cloud.,9219(c), pp.1–14.
[21]. Vasile, M. et al., 2014. Resource-Aware Hybrid Scheduling Algorithm in Heterogeneous Distributed Computing.,pp.1–22.
[22]. Wahidah, N. et al., 2015. Review On Cloud Computing Application In P2P Video Streaming. Procedia - Procedia Computer Science, 50, pp.185–190.
[23]. Wu, S. et al., 2014. Synchronization-Aware Scheduling for Virtual Clusters in Cloud.,9219(c), pp.1–14.
[24]. Zahedani, S.D. & Dastghaibyfard, G., 2014. A hybrid batch job scheduling algorithm for grid environment. Proceedings of the 4th International Conference on Computer and Knowledge Engineering, ICCKE 2014, pp.763– 768.