Providing the Induction In Data Streams Based On
Misclassification Error And GINI Index
N. Gopal1, K. Somasekhar2
1Department of MCA, RCR Institutes of Management & Technology, Tirupati, AP, India
2Assisstant Professor, Department of MCA, RCR Institute of Management & Technology, Tirupati,
AP, India Abstract:-
The most prevalent devices for stream information mining depend on choice trees. In past 15 years, all composed techniques, headed by the quick choice tree calculation, transferred on Hoeffding's imbalance and many scientists took after this plan. As of late, we have exhibited that despite the fact that the Hoeffding choice trees are a viable instrument for managing stream information, they are a simply heuristic strategy; for instance, established choice trees, for example, ID3 or CART can't be embraced to information stream mining utilizing Hoeffding's disparity. Consequently, there is an earnest need to grow new calculations, which are both numerically defended and portrayed by great execution. In this paper, we address this issue by building up a group of new part criteria for order in stationary information streams also, exploring their probabilistic properties. The new criteria, inferred utilizing suitable measurable devices, depend on the misclassification blunder and the Gini record debasement measures. The general division of part criteria into two sorts is proposed. Characteristics picked in view of sort I part criteria ensure, with high likelihood, the most astounding expected estimation of split measure. Sort I criteria guarantee that the picked trait is the same, with high likelihood, as it would be picked in light of the entire limitless information stream. In addition, in this paper, two half and half part criteria are proposed, which are the mixes of single criteria based on the misclassification blunder and Gini record.
Keywords: - Classification, Data Stream, Decision Trees, Impurity Measure, Splitting Criterion.
Introduction:-
IN THIS paper, an issue of information stream characterization is considered. An information stream is a conceivably unending succession of
information components, which arrive
consistently to the framework, regularly with high rate. Because of these attributes,
conventional information grouping
prepared at most once due to memory or computational power impediments. Existing techniques ought to be adjusted or new calculations ought to be created considering the specified confinements. Information stream grouping calculations ought to be asset
mindful .Another issue related with
information streams is the event of idea float The appropriation of stream information components qualities may advance in time. Despite the fact that this issue isn't tended to in this paper, it ought to be noticed that the idea float too postures numerous troubles in planning proper arrangement calculations. In the writing, there is an assortment of techniques intended for information grouping. The most famous techniques are manufactured neural systems, k-closest neighbors, and choice trees. In this paper, the utilization of choice trees for information stream mining is considered. Models learned utilizing choice trees have numerous points of interest.
They are effortlessly interpretable for clients
and show generally low memory
unpredictability contrasting and different strategies. This paper centers on the most basic purpose of choice tree acceptance calculations, i.e., the decision of a part characteristic in a thought about hub. In static choice trees, the "best" quality is picked on the premise of the information test S accessible in the thought about hub. The decision is influenced in light of some split measure to work. The estimation of this capacity is figured for all properties and the characteristic that gives the most noteworthy estimation of split measure is picked as the part one. In the most mainstream
choice tree calculations, for example, ID3 or CART , the split measure work is proposed as a decrease of some contamination measure g(S). Give us a chance to accept that information components are portrayed by D ascribes and can have a place with one of K classes. Let n(S) mean the quantity of information components in S and let nk (S) signify the quantity of information components from the set S which have a place to the kth class. At that point, the most famous polluting influence measures, i.e., data entropy, Gini list, and misclassification
blunder, are communicated in the
accompanying way, separately:
Proposed system:-
NEW SPLITTING CRITERIA
distribution of data elements does not change in time, i.e., the data stream is stationary. Let gi(S) be some split measure function calculated for the ith attribute based on sample of data elements S. Then, E[gi(S)] is its expected value. Moreover, let gi denote the value of split measure, which will be obtained for the whole infinite data stream (i.e., if the cardinality of set S is infinite). It is important to note that if the estimator gi(S) is biased, then E[gi(S)] differs from gi. This difference determines that there are two types of splitting criteria.
1) Type-I splitting criterion guarantees that the imax-th attribute, chosen based on it, the imax-th attribute, chosen based on it, is the same, with probability at least (1 − δ)D−1, as it would be chosen based on the whole infinite data stream, that is
The distinction between the type-I and type-I I criteria can be understood as follows. Let S∞ be a data stream with an infinite number of data elements. If we could take all of them, calculate split measure function values for each attribute, and choose the one with the highest value, then with probability at least (1 − δ)D−1, it would be the attribute chosen based
on a data sample using the type-I I splitting criterion (if, obviously, the criterion was satisfied). Now let us partition the stream S∞ into an infinite number of subsets Si , each having exactly n data elements in it. Let us calculate for each attribute an arithmetic average of split measure values for all subsets Si and, as previously, choose the attribute with the highest obtained value.
Then, this attribute is with probability at least (1 − δ)D−1 the same as the attribute chosen based on the data sample of size n using the type-I splitting criterion (if, obviously, the criterion was satisfied). Since the estimator of split measure function calculated using a sample of n elements is biased (at least for the information gain, Gini gain, and accuracy gain), then these two types of criteria can result in choosing different attributes. Actually, in the literature so far, including the basic paper, but also the type-I splitting criteria were considered. Recently, Rosa and Cesa-Bianchi and Rosa introduced the bias term into the criteria and, although they did not call it in this way, for the first time proposed the type-I I splitting criteria.
GENERAL FORM OF THE ONLINE
DECISION TREE ALGORITHM:-
only difference between all versions of the algorithm considered in this paper lies in the applied splitting criterion. The block scheme of the ODT algorithm with the standard single splitting criteria, such as (22), (37), or (41), is shown in Fig. 2.
Let nk ij(S) denote the number of data elements (in set S) from the kth class, with the jth value of the ith attribute. The set of numbers nk ij(S), i = 1,..., D, j = 1,...,vi, k = 1,..., K is also called the sufficient statistics of set S. The algorithm starts with one single node— the root. The sufficient statistics in the root are all set to zero. Then, the tree is developed using subsequent data elements from the stream. Each data element s is sorted down the tree, according to the values of attributes and the current structure of the tree. An element s finally reaches a leaf L p. The sufficient statistics in leaf L p are updated. Let Sp denote the set of data elements collected so far in the leaf L p, ji,s denote the value of the ith attribute of data element s, and ks denote the class of element s. The update of sufficient statistics is made in the following manner:
Next, the values of the applied split measure function gi (Sp) are calculated for each attribute, i = 1... D.
The algorithm has a slightly different form if
hybrid splitting criteria are used.
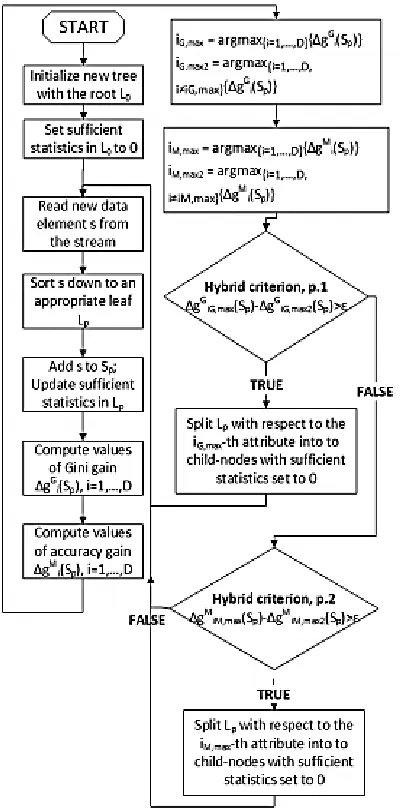
Corresponding block scheme is shown in Fig. 3. In this case, both split measures should be calculated for each attribute, i.e., gG i (Sp) and gM i (Sp). For each of the two split measures, attributes with the highest and the second highest values are chosen, i.e., iG,max and iG,max2 for Gini index and iM,max and
iM,max2 for misclassification error,
respectively. Then, the first part of hybrid splitting criterion is checked (denoted as ―Hybrid criterion, p.1‖ in Fig. 3). This part operates on the values of Gini gain. Type-I criterion (37) or type-I I criterion (41) can be used. If the criterion is met, the leaf L p is split into child nodes with respect to the iG,max-th attribute. Otherwise, the second part of hybrid splitting criterion is checked (denoted as ―Hybrid criterion, p.2‖ in Fig. 3). It is type-I criterion (22), i.e., the values of accuracy gain are compared. If it is satisfied, then the considered leaf is split with respect to the iM,max-th attribute.
Fig. 3. Block diagram of the ODT algorithm with hybrid splitting criteria.
Conclusion
with high likelihood (1 − δ)D−1, the most astounding expected estimation of the split measure. Sort I part criteria guarantee that the picked trait is the same as it would be in the event that the entire information stream was accessible. In this paper, new single part criteria were proposed, i.e., the sort I part criteria in light of the misclassification blunder and the Gini file also, the sort I part measure in view of the Gini record. Also, two half and half part criteria were proposed. These criteria blend the sort I measure in view of the misclassification blunder with one of the criteria in view of the Gini record. At last, the sort (I + I) and the sort (I + I) half breed proposed choice trees were contrasted and the Hoeffding choice tree and also with choice tree with part measure for which the bound is equivalent to the half of bound utilized as a part of the Hoeffding tree. The last one gave the most elevated precision among all choice trees considered in this paper. We empower scientists managing with stream information mining to perform reproductions with other estimations of steady C in recipe (5).
References
1. Aggarwal C., Xie Y., Yu P. (2011) On Dynamic Data-driven Selection of Sensor Streams, ACM KDD Conference. REED: robust, efficient filtering and online event detection in sensor networks, VLDB Conference.
4. Aggarwal C. (2007) Data Streams: Models and Algorithms, Springer.
5. Aggarwal C., Procopiuc C, Wolf J. Yu P., Park J.-S. (1999) Fast Algorithms for Projected Clustering. ACM SIGMOD Conference.
6. Aggarwal C. (2006) On Biased Reservoir Sampling in the presence of Stream Evolution. VLDB Conference.
7. Aggarwal C., Yu P. (2008) A Framework for Clustering Uncertain Data Streams. ICDE Conference.
8. Aggarwal C. (2003) A Framework for Diagnosing Changes in Evolving Data Streams. ACM SIGMOD Conference.
9. Aggarwal C. (2002) An Intuitive
Framework for understanding Changes in Evolving Data Streams. IEEE ICDE Conference.
10. Aggarwal C., Han J., Wang J., Yu P (2003). A Framework for Clustering Evolving Data Streams. VLDB Conference.
11. Aggarwal C., Han J., Wang J., Yu P (2004). A Framework for High Dimensional Projected Clustering of Data Streams. VLDB Conference.
12. Aggarwal C., Yu P. (2006) A Framework
for Clustering Massive Text and
13. Aggarwal C, Han J., Wang J., Yu P. (2004). On-Demand Classifi- cation of Data Streams. ACM KDD Conference.
14. Aggarwal C. (2009). Managing and Mining Sensor Data, Springer.
15. Aggarwal C., Yu P. (2007). On Density-based transforms for Uncertain Data Mining, ICDE Conference, 2007.
16. Agrawal R., Imielinski T., Swami A. (1993) Mining Association Rules between Sets of items in Large Databases. ACM SIGMOD Conference.
17. Alon N., Gibbons P., Matias Y., Szegedy M. (1999) Tracking Joins and Self-Joins in Limited Storage. ACM PODS Conference. 18. Alon N., Matias Y., Szegedy M. (1996) The
Space Complexity of Approximating
Frequency Moments. The Space
Complexity of Approximating Frequency Moments, pp. 20–29.