DAGALP, RUKIYE ESENER. Estimators For Generalized Linear Measurement Er-ror Models With Interaction Terms. (Under the direction of Professor Leonard A. Stefanski)
The primary objectives of this research are to develop and study estimators for generalized linear measurement error models when the mean function contains error-free predictors as well as predictors measured with error and interactions between error-free and error-prone predictors. Attention is restricted to generalized linear models in canonical form with independent additive Gaussian measurement error in the error-prone predictors.
Estimators appropriate for the functional (Fuller, 1987, Ch. 1) version of the mea-surement error model are derived and studied. The estimators are also appropriate in the structural version of the model and thus the methods developed in this research are functional in the sense of Carroll, Ruppert and Stefanski (1995, Ch. 6).
The primary approach to the development of estimators in this research is the
conditional-score method proposed by Stefanski and Carroll (1987) and described by Carroll et al. (1995, Ch. 6). Sufficient statistics for the unobserved predictors are obtained and the conditional distribution of the observed data given these sufficient statistics is derived. The latter admits unbiased score functions that are free of the nuisance parameters (the unobserved predictors) and are used to construct unbiased estimating equations for model parameters.
Estimators for the parameters of the model of interest are also derived using the corrected approach proposed by Nakamura (1990) and Stefanski (1989). These are also functional estimators in the sense of Carroll et al. (1995, Ch. 6) that are less dependent on the exponential-family model assumptions and thus provide a benchmark against which to compare the conditional-score estimators.
by
RUKIYE E. DAGALP
A dissertation submitted in partial satisfaction of the requirements for the degree of
Doctor of Philosophy
in STATISTICS
in the
GRADUATE SCHOOL at
NC STATE UNIVERSITY 2001
Professor Leonard A. Stefanski Professor William H. Swallow Chair of Advisory Committee
Biography
Acknowledgements
My sincere gratitude is given to those who supported me during my academic career. Without your help, friendship and advice I would not have succeeded. I would especially like to thank the following individuals:
• Dr. Leonard A. Stefanski, my advisor, mentor and friend. I cannot thank you enough for your patience, insight, encouragement, wonderful proofreading throughout this dissertation, and for introducing me to the area of measurement error models. It has been a great pleasure working with you.
• Drs. William H. Swallow, John F. Monahan, and Dennis D. Boos. Thank you for serving on my committee and providing useful comments on my dissertation. • Dr. Sastry Pantula, NCSU Director of Graduate Programs. Thank you for all
your support, help and advice.
• Dr. James Stapleton, MSU Director of Graduate Programs. Thank you for your encouragement and belief in me to complete the Ph.D. program.
• Drs. Bibhuti B. Bhattacharyya, Anastasios Tsiatis, Marie Davidian, Fikri Oz-turk, and Hamza Gamgam who have been the most influential instructors in my academic career.
• Dr. Harvey J. Charlton, NCSU Department of Mathematics. Thank you for your financial support and friendship throughout my study.
• Terry Byron, NCSU Department of Statistics Systems Administrator. Thank you for your help with my computer questions and for always being willing to lend a helping hand.
• Kath & Dave Williams, thank you for taking care of me during my pregnancy, for your friendship, and your delicious dinners.
• Fellow graduate students at NCSU: Josh Tebbs, Steve Novick, Jared Lunceford, Jimmy Doi, Ann Oberg, Elizabeth Johnson. Thanks to each of you for your kindness, support and friendship. A especial thanks to Jared for being the SAS/IML manual for me, and Jimmy for proofreading my thesis.
• Janice Gaddy, Sharon Patton, especially Brenda Currin. Thank you all for your sweet kindness, willingness to assist and friendship.
• Hatice & Adem C. Esener, my parents, who continually encouraged me through-out my Ph.D. program. Thank you for your never ending love and support. • Finally, to my husband Volkan and my son Alper. I cannot thank you enough for
Contents
List of Tables viii
List of Figures xiv
1 Introduction 1
1.1 Measurement Error Models . . . 1
1.1.1 Simple Linear Regression . . . 3
1.1.2 Simple Logistic Regression . . . 6
1.2 Statistical Inference in the Presence of Measurement Error . . . 8
1.2.1 The Conditional-Score . . . 8
1.2.2 The Corrected-Score . . . 10
1.3 Outline of Thesis . . . 12
2 Generalized Linear Measurement Error Models and Conditional-Scores 13 3 Normal Linear Regression 22 3.1 The Specific Form of the Conditional-Score . . . 22
3.2 Corrected-Score Estimator . . . 27
3.3 Large-Sample Inference for Conditional-Score and Corrected-Score Es-timates . . . 31
3.3.1 Empirical and Conditional Model Based Methods of Estimating the Asymptotic Covariance Matrix . . . 35
3.4 Simulation Study . . . 37
3.4.1 Results of the Monte Carlo Simulation . . . 38
3.4.2 Comparison of Two Methods of Estimating the Asymptotic Co-variance Matrix. . . 48
3.5 Asymptotic Relative Efficiencies of Conditional-Score and Corrected-Score Estimators . . . 53
4.2 An Approximate Corrected-Score . . . 62
4.3 Large-Sample Inference for Conditional-Score and Corrected-Score Es-timates . . . 66
4.3.1 Empirical and Conditional Model-Based Methods of Estimating the Asymptotic Covariance Matrix . . . 67
4.4 Simulation Study . . . 68
4.4.1 Results of the Monte Carlo Simulation . . . 69
4.4.2 Asymptotic Covariance Matrix Estimation . . . 79
4.5 Framingham Heart Study . . . 84
4.5.1 Model: CHD = ln(Cholest) Age ln(Cholest)*Age . . . 85
4.5.2 Model: CHD = ln(SBP) Smoke ln(SBP)*Smoke . . . 87
5 Conclusion and Discussion 94
List of Tables
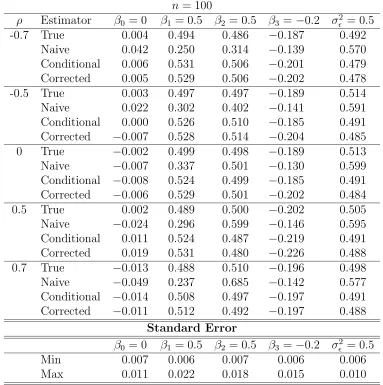
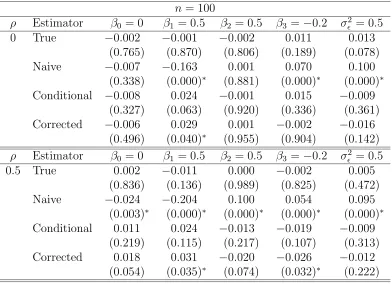
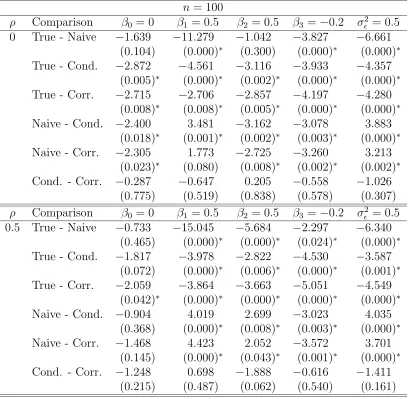
3.1 Simulation study results for the true, naive, conditional-score and corrected-score estimators for the normal linear model with parameters Θ= (β0, β1, β2, β3, σ²2)T = (0,0.5,0.5,−0.2,0.5)T and measurement er-ror variance σU2 = 0.5. Table entries are means of 100 Monte Carlo runs for sample size n = 100. The entries at the bottom of the table are minimum and maximum values of standard errors for the parameters. 40 3.2 Simulation study results for the true, naive, conditional-score and
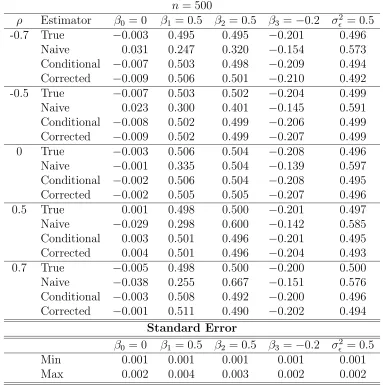
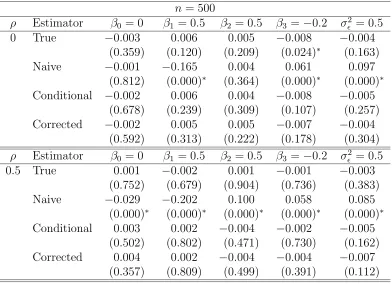
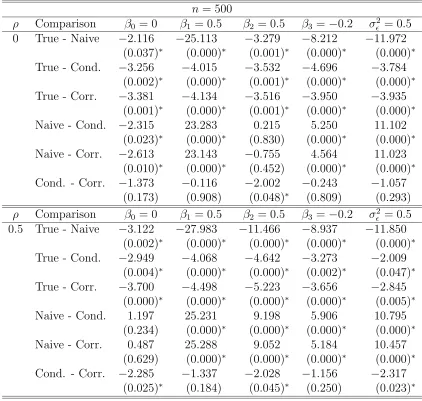
corrected-score estimators for the normal linear model with parameters Θ= (β0, β1, β2, β3, σ²2)T = (0,0.5,0.5,−0.2,0.5)T and measurement er-ror variance σU2 = 0.5. Table entries are means of 100 Monte Carlo runs for sample size n = 500. The entries at the bottom of the table are minimum and maximum values of standard errors for the parameters. 41 3.3 Simulation study results to analyze biases of the true, naive,
conditional-score and corrected-conditional-score estimators for the normal linear model with parameters Θ = (β0, β1, β2, β3, σ²2)T = (0,0.5,0.5,−0.2,0.5)T, mea-surement error variance σU2 = 0.5 and n = 100. Table entries are mean biases and p-values of t−tests for no-bias (in parentheses) for 100 Monte Carlo runs. . . 42 3.4 Simulation study results to analyze biases of the true, naive,
conditional-score and corrected-conditional-score estimators for the normal linear model with parameters Θ = (β0, β1, β2, β3, σ²2)T = (0,0.5,0.5,−0.2,0.5)T, mea-surement error variance σU2 = 0.5 and n = 500. Table entries are mean biases and p-values of t−tests for no-bias (in parentheses) for 100 Monte Carlo runs. . . 43 3.5 Simulation study results to compare differences in biases of the true,
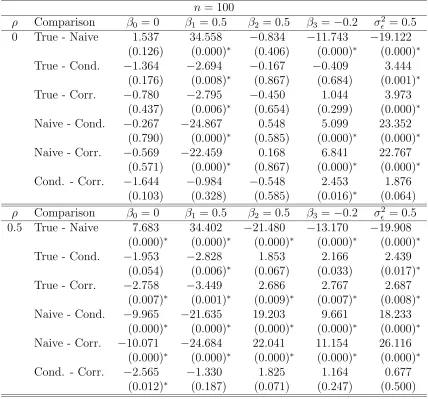
naive, conditional-score and corrected-score estimators for the normal
linear model with parametersΘ= (β0, β1, β2, β3, σ²2)T = (0,0.5,0.5,−0.2,0.5)T, measurement error variance σU2 = 0.5 and n = 100. Table entries are
3.6 Simulation study results to compare differences in biases of the true, naive, conditional-score and corrected-score estimators for the normal
linear model with parametersΘ= (β0, β1, β2, β3, σ²2)T = (0,0.5,0.5,−0.2,0.5)T,
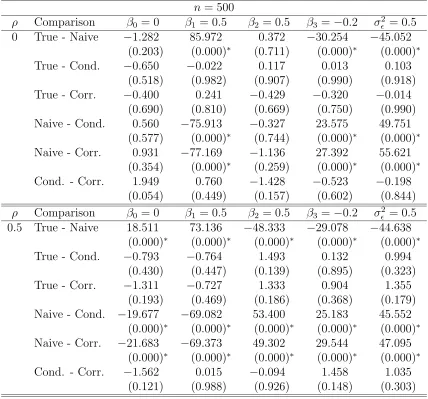
measurement error variance σU2 = 0.5 and n = 500. Table entries are paired t−test statistics and p−values (in parentheses) for 100 Monte Carlo runs. . . 45 3.7 Simulation study results to compare mean squared errors of the true,
naive, conditional-score and corrected-score estimators for the normal
linear model with parametersΘ= (β0, β1, β2, β3, σ²2)T = (0,0.5,0.5,−0.2,0.5)T,
measurement error variance σU2 = 0.5 and n = 100. Table entries are paired t−test statistics and p−values (in parentheses) for 100 Monte Carlo runs. . . 46 3.8 Simulation study results to compare mean squared errors of the true,
naive, conditional-score and corrected-score estimators for the normal
linear model with parametersΘ= (β0, β1, β2, β3, σ²2)T = (0,0.5,0.5,−0.2,0.5)T,
measurement error variance σU2 = 0.5 and n = 500. Table entries are paired t−test statistics and p−values (in parentheses) for 100 Monte Carlo runs. . . 47 3.9 Simulation study results to estimate the Monte Carlo, sandwich and
model-based variances for the true, naive, conditional-score and corrected-score estimators for the normal linear model with parameters Θ = (β0, β1, β2, β3, σ²2)T = (0,0.5,0.5,−0.2,0.5)T, measurement error vari-ance σ2U = 0, the correlation of X1 and X2, ρ= 0, and n= 100. Table entries (in last two columns) are the means and standard errors (in parentheses) of ratios of the mean of sandwich variance estimates to the mean of model-based variance estimates from five replicates each from 100 Monte Carlo runs. . . 49 3.10 Simulation study results to estimate the Monte Carlo, sandwich and
3.11 Simulation study results to estimate the Monte Carlo, sandwich and model-based variances for the true, naive, conditional-score and corrected-score estimators for the normal linear model with parameters Θ = (β0, β1, β2, β3, σ²2)T = (0,0.5,0.5,−0.2,0.5)T, measurement error vari-ance σ2U = 0.5, the correlation of X1 and X2, ρ = 0.5, and n = 100. Table entries (in last two columns) are the means and standard errors (in parentheses) of ratios of the mean of sandwich variance estimates to the mean of model-based variance estimates from five replicates each from 100 Monte Carlo runs. . . 51 3.12 Simulation study results to estimate the Monte Carlo, sandwich and
model-based variances for the true, naive, conditional-score and corrected-score estimators for the normal linear model with parameters Θ = (β0, β1, β2, β3, σ²2)T = (0,0.5,0.5,−0.2,0.5)T, measurement error vari-ance σ2U = 0.5, the correlation of X1 and X2, ρ = 0.5, and n = 500. Table entries (in last two columns) are the means and standard errors (in parentheses) of ratios of the mean of sandwich variance estimates to the mean of model-based variance estimates from five replicates each from 100 Monte Carlo runs. . . 52 3.13 The 95% confidence intervals for relative effiencies of the
conditional-score and the corrected-conditional-score estimators when (X1, X2)∼MVN(0,0, σ2X
1, σX22, ρ)
under the measurement error varianceσU2 = 0.5, and the true parame-ters Θ= (β0, β1, β2, β3, σ2²)T = (0,0.5,0.5,−0.2,0.5)T. The results are 102∗95% CI of the mean of four REs of 100,000 Monte Carlo runs. . 55 3.14 The 95% confidence intervals for relative effiencies of the conditional
score and the corrected-score estimators whenX2 is Binomial(1,π) and X1|X2 is Normal with mean µX2 = µ0I{X2 = 0} +µ1I{X2 = 1} and σX22 = σ02I{X2 = 0}+σ12I{X2 = 1} under measurement error variance σ2U = 0.5 and the true parameters Θ= (β0, β1, β2, β3, σ2²)T = (0,0.5,0.5,−0.2,0.5)T. The results are 102 ∗95% CI of the mean of
four REs of 100,000 Monte Carlo runs where µ0 = 0 and µ1 = 1. . . . 56 4.1 Simulation study results for the true, naive, conditional-score and
corrected-score estimators for the logistic regression model with pa-rameters Θ= (β0, β1, β2, β3,)T = (0,0.5,0.5,−0.2)T, measurement
4.2 Simulation study results for the true, naive, conditional-score and corrected-score estimators for the logistic regression model with pa-rameters Θ= (β0, β1, β2, β3,)T = (0,0.5,0.5,−0.2)T, measurement
er-ror variance σ2U = 0.5, and sample size n = 1000. Table entries are means of 100 Monte Carlo runs. The entries at the bottom of the table are minimum and maximum values of standard errors for the parameters. 72 4.3 Simulation study results to analyze biases of the true, naive,
conditional-score and corrected-conditional-score estimators for the logistic regression model with parameters Θ = (β0, β1, β2, β3)T = (0,0.5,0.5,−0.2)T,
measure-ment error variance σ2U = 0.5 andn = 500. Table entries are mean bi-ases and p-values oft−tests for no-bias (in parentheses) for 100 Monte Carlo runs. . . 73 4.4 Simulation study results to analyze biases of the true, naive,
conditional-score and corrected-conditional-score estimators for the logistic regression model with parameters Θ = (β0, β1, β2, β3)T = (0,0.5,0.5,−0.2)T,
measure-ment error varianceσ2U = 0.5 andn= 1000. Table entries are mean bi-ases and p-values oft−tests for no-bias (in parentheses) for 100 Monte Carlo runs. . . 74 4.5 Simulation study results to compare differences in biases of the true,
naive, conditional-score and corrected-score estimators for the logistic regression model with parametersΘ= (β0, β1, β2, β3)T = (0,0.5,0.5,−0.2)T,
measurement error variance σU2 = 0.5 and n = 500. Table entries are paired t−test statistics and p−values (in parentheses) for 100 Monte Carlo runs. . . 75 4.6 Simulation study results to compare differences in biases of the true,
naive, conditional-score and corrected-score estimators for the logistic regression model with parametersΘ= (β0, β1, β2, β3)T = (0,0.5,0.5,−0.2)T,
measurement error variance σ2U = 0.5 and n= 1000. Table entries are paired t−test statistics and p−values (in parentheses) for 100 Monte Carlo runs. . . 76 4.7 Simulation study results to compare mean squared errors of the true,
naive, conditional-score and corrected-score estimators for the logistic regression model with parametersΘ= (β0, β1, β2, β3)T = (0,0.5,0.5,−0.2)T,
measurement error variance σU2 = 0.5 and n = 500. Table entries are paired t−test statistics and p−values (in parentheses) for 100 Monte Carlo runs. . . 77 4.8 Simulation study results to compare mean squared errors of the true,
naive, conditional-score and corrected-score estimators for the logistic regression model with parametersΘ= (β0, β1, β2, β3)T = (0,0.5,0.5,−0.2)T,
4.9 Simulation study results to estimate the Monte Carlo, sandwich and model-based variances for the true, naive, conditional-score and corrected-score estimators for the logistic regression model with parametersΘ= (β0, β1, β2, β3)T = (0,0.5,0.5,−0.2)T, measurement error varianceσ2U = 0.5, the correlation of X1 and X2, ρ = 0, and n = 500. Table entries (in last two columns) are ratios of the mean of sandwich variance esti-mates to the mean of model-based variance estiesti-mates from 100 Monte Carlo runs. These ratios have standard error approximate equal to 0.14. 80 4.10 Simulation study results to estimate the Monte Carlo, sandwich and
model-based variances for the true, naive, conditional-score and corrected-score estimators for the logistic regression model with parametersΘ= (β0, β1, β2, β3)T = (0,0.5,0.5,−0.2)T, measurement error varianceσ2
U =
0.5, the correlation of X1 and X2, ρ= 0, and n = 1000. Table entries (in last two columns) are ratios of the mean of sandwich variance esti-mates to the mean of model-based variance estiesti-mates from 100 Monte Carlo runs. These ratios have standard error approximate equal to 0.14. 81 4.11 Simulation study results to estimate the Monte Carlo, sandwich and
model-based variances for the true, naive, conditional-score and corrected-score estimators for the logistic regression model with parametersΘ= (β0, β1, β2, β3)T = (0,0.5,0.5,−0.2)T, measurement error varianceσ2
U =
0.5, the correlation of X1 and X2, ρ= 0.5, and n= 500. Table entries (in last two columns) are ratios of the mean of sandwich variance esti-mates to the mean of model-based variance estiesti-mates from 100 Monte Carlo runs. These ratios have standard error approximate equal to 0.14. 82 4.12 Simulation study results to estimate the Monte Carlo, sandwich and
model-based variances for the true, naive, conditional-score and corrected-score estimators for the logistic regression model with parametersΘ= (β0, β1, β2, β3)T = (0,0.5,0.5,−0.2)T, measurement error varianceσ2U = 0.5, the correlation ofX1 andX2,ρ= 0.5, andn= 1000. Table entries (in last two columns) are ratios of the mean of sandwich variance esti-mates to the mean of model-based variance estiesti-mates from 100 Monte Carlo runs. These ratios have standard error approximate equal to 0.14. 83 4.13 Framingham Heart study to estimate for naive, conditional-score and
Monte-Carlo corrected-score estimators with sample size, n = 1615, and their standard errors. ln(Cholest2) is the ln transformation of the single measurement of serum cholesterol at Exam 2 and the observed covariate is age. . . 85 4.14 Framingham Heart study to estimate for naive, conditional-score and
4.15 Framingham Heart study to estimate for naive, conditional-score and Monte-Carlo corrected-score estimators with sample size, n = 1615, and their standard errors. ln(SBP2−50) is ln transformation of (SBP2 − 50) and the observed covariate is smoke. . . 89 4.16 Framingham Heart study to estimate for naive, conditional-score and
List of Figures
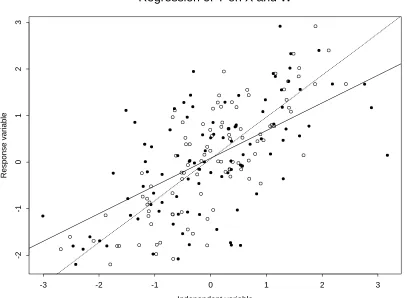
1.1 Illustration of the classical measurement error model in simple linear regression. The steeper line and the empty circles are the least squares fit and the plot of the true (Y, X) data, respectively. The attenuated line and the filled circles are the least squares fit and the plot of the observed (Y, W) data, respectively. For these data σX2 = σ2U = 1, (α, β) = (0,1) andσ²2 = 0.5. . . 5 1.2 Illustration of the classical measurement error model in logistic
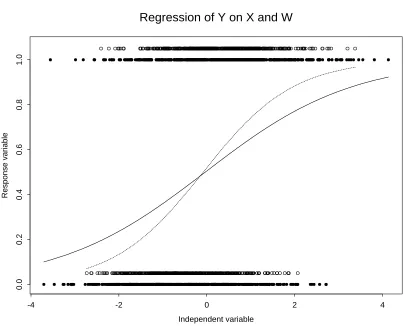
regres-sion. The empty circles are the true (X, Y) data and the filled circles are the observed (W, Y) data. The dotted and solid (attenuated) curves are (X, F(αbT rue+βbT rueX)) and (W, F(αbN aive+βbN aiveW)), respectively. For these dataσX2 =σU2 = 1 and (α, β) = (0,1). . . 7 4.1 The regression fits of CHD on single measurement of ln(Cholest2)
and Age for Naive, Conditional-score and Monte-Carlo Corrected-score methods. . . 86 4.2 The regression fits of CHD on average measurements of ln(Cholest) Age
for Naive, Conditional-score and Monte-Carlo Corrected-score methods. 88 4.3 The regression fits of CHD on measurements of ln(SBP2 - 50) and
Non-Smoke for Naive, Conditional-score and Monte-Carlo Corrected-score methods. . . 89 4.4 The regression fits of CHD on measurements of ln(SBP2 - 50) and
Smoke for Naive, Conditional-score and Monte-Carlo Corrected-score methods. . . 90 4.5 The regression fits of CHD on average measurements of ln(SBP) and
Non-Smoke for Naive, Conditional-score and Monte-Carlo Corrected-score methods. . . 92 4.6 The regression fits of CHD on average measurements of ln(SBP) and
Chapter 1
Introduction
1.1
Measurement Error Models
Regression analysis is a statistical methodology for studying the relationship be-tween two or more quantitative variables so that one variable can be explained from the other variables. The response variableY is a dependent variable whose variation can be explained by an explanatory variable or independent variable X which must be observable in traditional regression analysis. Sometimes the explanatory variable X cannot be observed, either because it is too expensive, unavailable, or mismea-sured. In this situation, a substitute variable W is observed instead of X, that is W = X +U, where U is measurement error. When the conditional distribution of Y given (X, W) is the same as the conditional distribution of Y given X, that is fY|X,W =fY|X, andW =X+U,W is said to be asurrogate forX. The substitution ofW for X creates problems in the analysis of the data, generally referred to as mea-surement error problems. The statistical models used to analyze such data are called
The purpose of regression analysis is to model the dependence of the conditional mean of Y given X mathematically via a regression function f, namely
E(Y|X) =f(X;θ), (1.1)
where θ is an unknown parameter to be estimated. In a measurement error problem there are two problems in modeling the regression of Y on X. One is with the unknown parameter θ and the other is that {(Yj, Wj), j = 1,2, . . . , n} are observed rather than {(Yj, Xj), j = 1,2, . . . , n}.
Often the relationship between X and W can be explained by a classical additive measurement error model
W =X+U, (1.2)
where U is a normally distributed measurement error with zero mean and variance σU2 and is independent of Y and X. The unobserved variable X is sometimes called the true regressor and can be either fixed or random. According to the characteristic of X, the measurement error models are called either functional models with fixedX orstructural models with random X (Fuller, 1987).
There are two important types of measurement error models depending on the distribution of X orW. The first one, the so-called classical error model, is given in (1.2). In this case W is an unbiased measure of X in the sense that E(W|X) = X and W is a surrogate forX in the sense that the conditional distribution of Y given X andW is the same as the conditional distribution ofY givenX. The latter implies that U is independent of Y and the residual isY −E(Y|X).
When E(X|W) = W, the measurement error model is called the Berkson error model, andW is called anunbiased Berkson predictor of X. That is,X varies around W and the measurement error model is
X =W +U, (1.3)
Y −E(Y|X) are uncorrelated and the residual is uncorrelated withX. For both mea-surement error models, the meamea-surement error U could be homoscedastic (constant variance) or heteroscedastic. In this thesis, we assume the classical measurement error model with known measurement error variance andW is a surrogate for X.
Parameter estimators obtained by ignoring the error in W as measurement of X and fitting the regression model to the observed data, are referred to asnaive estima-tors. These are generally biased and inconsistent estimators of the true parameters in the regression of Y given X. In simple linear regression, and in generalized linear regression models more generally, it is often the case that naive estimators of the regression coefficient of variables measured with error are biased toward zero. This type of bias called attenuation. It is well known and understood in the context of simple linear regression.
In simple linear regression, the amount of attenuation is called the reliability ra-tio (Fuller, 1987) and is commonly denoted by λ. The reliability ratio provides an approximate measure of attenuation in generalized linear measurement error models more generally and it will be referenced throughout this thesis in connection with both linear and nonlinear measurement error models.
We complete this subsection with an illustration and further discussion of mea-surement error-induced bias in the context of two simple regression models.
1.1.1
Simple Linear Regression
Consider the classical linear regression model with one independent variable that is unobservable
Y =α+βX +², with the classical measurement error model
where X is the true predictor, measured with error, U is the measurement error and W is a surrogate forX. Suppose{², U, X}is an independent triplet with distribution
² U X ∼N
0 0 µX ,
σ²2 0 0 0 σU2 0 0 0 σX2
.
Consistent estimating equations of intercept and slope based on the error-free data, given by the likelihood function, are
n
X
j=1
(Yj −α−βXj)
1 Xj = 0 0
. (1.4)
The equations in (1.4) yield the ordinary least squares estimate of slope given by
b
βT rue= SXY SXX =
(n−1)−1Pnj=1(Yj−Y)Xj (n−1)−1Pnj=1(Xj −X)2 .
Substituting W for X in (1.4) yields the so-called naive slope estimator,
b
βN aive = SW Y SW W =
(n−1)−1Pnj=1(Yj−Y)Wj (n−1)−1Pnj=1(Wj −W)2 = (n−1)
−1Pn
j=1(Yj−Y)(Xj +Uj)
(n−1)−1Pnj=1(Xj+Uj−X−U)2 = SY X+SY U
SXX+ 2SXU +SU U,
where SXX is the sample variance of X1, . . . , Xn, SU U is the sample variance of U1, . . . , Un, SXU is the sample covariance of (Xj, Uj), j = 1, . . . , n, and other com-ponents are defined similarly. By the Law of Large Numbers, both SY U and SXU converge to zero, SXX−→P σX2, and SU U−→P σU2, as n → ∞. Thus,
b
βN aive−→P λβ, as n → ∞
Independent variable
Response variable
-3 -2 -1 0 1 2 3
-2 -1 0 1 2 3
Regression of Y on X and W
Figure 1.1: Illustration of the classical measurement error model in simple linear regression. The steeper line and the empty circles are the least squares fit and the plot of the true (Y, X) data, respectively. The attenuated line and the filled circles are the least squares fit and the plot of the observed (Y, W) data, respectively. For these data σX2 =σ2U = 1, (α, β) = (0,1) and σ2² = 0.5.
Figure 1.1 illustrates the attenuation induced by measurement error. For this illustration, data were generated with α = 0, β = 1 and a sample size of 100. The true covariate X, the regression experimental error ², and the measurement error U were generated from the normal distribution
X U ² ∼N
0 0 0 ,
1 0 0 0 1 0 0 0 0.5
.
1.1.2
Simple Logistic Regression
Consider the logistic regression model with mean function E(Y|X) = Pr(Y = 1|X) = F(α+βX),
whereF(t) ={1 +e−t}−1 is the logistic function with the classical measurement error
model
W =X+U,
whereU is N(0, σU2), independent of all other variables, and the conditional distribu-tion ofW givenX is N(X, σU2). Defineθ = (α, β)T. Consistent estimating equations
for intercept and slope based on the error-free data, given by the likelihood function, are
n
X
j=1
{Yj −F(α+βXj)}
1 Xj = 0 0
. (1.5)
The estimator solving (1.5) will be called the true estimator and denoted by θbT rue. When the measurement error is ignored and W is substituted for X, the resulting estimating equations for intercept and slope are
n
X
j=1
{Yj −F(α+βWj)}
1 Wj = 0 0
. (1.6)
The estimator solving (1.6) will be called the naive estimator and designated by
b
θN aive.
Logistic regression estimators are nonlinear and have no closed-form expressions. Thus it is not possible to derive a mathematical expression for measurement error-induced bias in logistic regression. However, attenuation is easily demonstrated using simulated data sets. Figure 1.2 illustrates the attenuation induced by measurement error. For this graph, data were generated withα = 0 andβ = 1 and the sample size of 1000. The true covariateX and the measurement error U were generated from the standard bivariate normal distribution.
X
U
∼N
0 0 , 1 0
Regression of Y on X and W
Independent variable
Response variable
-4 -2 0 2 4
0.0
0.2
0.4
0.6
0.8
1.0
Figure 1.2: Illustration of the classical measurement error model in logistic regression. The empty circles are the true (X, Y) data and the filled circles are the observed (W, Y) data. The dotted and solid (attenuated) curves are (X, F(αbT rue+βbT rueX)) and (W, F(αbN aive+βbN aiveW)), respectively. For these dataσX2 =σU2 = 1 and (α, β) = (0,1).
1.2
Statistical Inference in the Presence of
Mea-surement Error
The study of measurement error problems in regression modeling is an active area of statistical research. The most comprehensive discussion of methods for linear measurement error models is the book by Fuller (1987). Statistical methods for nonlinear measurement error models are described in the book by Carroll, Ruppert and Stefanski (1995).
In this thesis two methods appropriate for functional measurement error models will be developed for a particular class of generalized linear measurement error models with interaction terms. The two methods, one based on conditional-scores, the other based on corrected-scores, are discussed in the following sections.
1.2.1
The Conditional-Score
In this section, the conditional-score estimators of Stefanski and Carroll (1987) are described for an important class of generalized linear measurement error mod-els. When measurement error is present, the naive estimating equations produce an estimator which is biased and inconsistent due to measurement error. The idea is to obtain an unbiased estimating equation for θ, that does not depend on the nuisance parameters and produces an asymptotically unbiased estimator. The con-ditional distribution of the response variable Y given a statistic that is sufficient for the unobserved covariate X, does not depend on X. Thus, it is possible to derive unbiased estimating equations for θ that do not depend on X. Conditional-scores are derived under the assumption of normally distributed measurement errors (the classical model) with known error variance.
for response variable Y, given explanatory variables X = (X1,X2)T, have density fY|X(y|x;θ) = exp
(
yη−b(η)
φ +c(y, φ)
)
, (1.7)
where η=α+βT1x1+βT2x2 is called the natural parameter and θ = (α,βT1,βT2, φ)T
is the unknown parameter. The mean and variance of Y are b0(η) and φb00(η), where b0 and b00 are the first and second derivatives of b(η) with respect to η. The class of models includes:
• Linear regression:
E(Y|X) = η, Var(Y|X) = φ, b(η) = η 2
2, c(y, φ) = − y2
2φ −log( √
2πφ) • Logistic regression:
E(Y|X) = H(η), Var(Y|X) =H0(η),φ = 1, b(η) = −log{1−H(η)}, c(y, φ) = 0, whereH(t) ={1 +e−t}−1
• Poisson log-linear regression:
E(Y|X) = Var(Y|X) = eη, φ = 1, b(η) = eη, c(y, φ) =−log(y!) • Gamma inverse regression:
E(Y|X) =−1
η, Var(Y|X) =− φ
η, b(η) =−log(−η), c(y, φ) = log(y/φ)
φ −log{yΓ(1/φ)}.
If both X1 and X2 were observed, the usual estimating equations forΘ have the form
n
X
j=1
{Yj −b0(ηj)}
1
X1j
X2j
= 0 0 0 , and n X j=1
(µn−p
n
¶
φ− {Yj −b 0(η
j)}2
b00(ηj)
)
= 0,
X1 is considered as an unknown parameter and α,β1,β2 and φ as fixed, then the statistic∆=W+YΩUβ1/φ is complete and sufficient for X1 (Stefanski & Carroll, 1987). Now, the conditional distribution of Y given ∆ and X2 is free of X1, so the unbiased estimating equations for Θ are independent ofX1. It is possible to derive the mean and variance ofY given∆andX2 by the density ofY|∆,X2 which is also a canonical generalized linear model in the same form as (1.7). The conditional-score function is derived in general for the exponential family in canonical form and is given in detail in Chapters 2, 3 and 4.
1.2.2
The Corrected-Score
The corrected-score method is a technique for eliminating asymptotic bias caused by measurement error by using unbiased estimating equations for the parameter of interest (Stefanski, 1989, and Nakamura, 1990). It assumes the existence of an unbi-ased score for the true data that is, when both X1 and X2 are error-free predictors, one would estimate the unknown parameter Θ in the absence of measurement error as the solutions of the equations
n
X
j=1
ψ(Yj,X1j,X2j;cΘ) =0, (1.8)
where ψ is a likelihood score function from the model for the true data. The data {Yj,X1j,X2j}n
j=1 are assumed to be independent random vectors such that
E{ψ(Y,X1,X2;Θ)}=0. (1.9) Estimators defined in (1.8) are called M-estimators.
When measurement error is normally distributed with known variance ΩU, a con-sistent estimator of the parameter of interest in nonlinear measurement error models is difficult to obtain (Stefanski, 1989) in general. However, suppose that there exists some score function, ψ∗(Y,W,X2;Θ) of the observed data having the property
for all Y,X1,X2 and Θ. It follows that
E{ψ∗(Y,W,X2;Θ)} = E{E{ψ∗(Y,W,X2;Θ)|Y,X1,X2}} = E{ψ(Y,X1,X2;Θ)}=0,
so thatψ∗(·,·,·,·) is a Fisher-consistent score function (Carroll, Ruppert & Stefanski, 1995). The M-estimator Θ∗ based on the observed data is defined as the solution to
n
X
j=1
ψ∗(Y
j,Wj,X2j;Θ∗) =0, (1.11)
and is then generally consistent forΘ. A score functionψ∗(·,·,·,·) satisfying (1.10) is called acorrected-score function and the parameter estimator,Θ∗ that satisfies (1.11) is called a corrected-score estimator.
The problem is that the corrected-score function satisfying (1.10) does not al-ways exist, and when it exists, it is not easy to find. For some common models, corrected-score functions have been studied and derived in detail by Stefanski (1989) and Nakamura (1990). Theorem 1 in Stefanski (1989) provides a means of deter-mining corrected-score functions for a large class of models. Let Z be independent standard normal errors independent of all other variables, and let i=√−1. If f(·) is an entire function of the complex variable and the indicated expectations exist, then Enf(W +iΩ1U/2Z)|Xo=f(X). (1.12) Examples of how to obtain an unbiased corrected-score function using this result are given in Stefanski (1989).
Application to the measurement error models problems results in the corrected-score
ψ∗(Y,W,X
2;Θ) = E
n
ψ(Y,W +iΩ1U/2Z,X2;Θ)|Y,W,X2o. (1.13)
1.3
Outline of Thesis
This thesis will focus on the classical measurement error model in (1.2) where the measurement error U is homoscedastic and normally distributed. The primary objective of this thesis is to study the effect of measurement error and to eliminate asymptotic bias when there exists an interaction between observed and unobserved true covariates of the form
E(Y|X1,X2) =b0(β0+βT1X1+βT2X2 +XT1β3X2),
for canonical generalized linear models, where β0,β1,β2 and β3 are unknown regres-sion coefficients. For eliminating bias due to measurement error, the conditional-score method (Stefanski & Carroll, 1987) and the corrected-score method (Stefanski, 1989, Nakamura, 1990) are studied for the regression models with interaction terms.
Chapter 2
Generalized Linear Measurement
Error Models and
Conditional-Scores
The statistical models studied in this dissertation have the exponential family form given in McCullagh & Nelder (1989, Chap. 2). Given a covariate p×1 vector
X =x, the response variable Y has density function as a generalized linear model in canonical form
fY|X(y|x,Θ) = exp
(
yη−b(η)
a(φ) +c(y, φ)
)
, (2.1)
with respect to aσ-finite measurem(·). Generalized linear models of this form include normal, Poisson, gamma, inverse Gaussian and logistic models. The normal linear and the logistic regression models are discussed in Chapters 3 and 4, respectively. In (2.1) functions a(·), b(·) and c(·,·) are known and η is called the natural parameter
and is a function of the predictor and unknown regression parameters. This thesis focuses exclusively on the case in which η has the form
η =η(X1,X2;Θ) =β0+βT1X1+βT2X2+XT1β3X2, (2.2) where Θ = (β0,βT1,βT2,βT31,βT32, . . . ,βT3p2, φ)T is a (p
β3k is a p1 ×1 vector, k = 1, . . . , p2. The predictor X1 is an unobservable p1 ×1 vector, butX2 is an observablep2×1 vector withX = (X1,X2)T. The novel feature
of this model is the interaction term between the predictor measured with error X1 and the error-free predictor X2. The mean and variance ofY given X are b0(η) and φb00(η), where b0 and b00 are the first and second derivatives of b(η) with respect to η, respectively. The measurement of the error-prone predictor is denoted by W and is assumed to satisfy
W =X1+U, (2.3)
where the measurement errorU is distributed as a normal random vector with mean zero and covariance matrix ΩU, independent of X1,X2 and Y. In this case the density of W given X1 =x1 is
fW|X1(w|x1,ΩU) = (2π)−p21 |ΩU |−12 exp
½
−1
2(w−x1)
TΩ−1
U (w−x1)
¾
. (2.4) The models in (2.1) and (2.4) together define a generalized linear measurement error model with interaction terms.
Combining (2.1) and (2.4) results in the joint density of (Y,W) given the unob-served predictor x1 and observed predictorx2,
fY,W|X1,X2(y,w|x1,x2;Θ) =fY|X1,X2(y|x1,x2;Θ)fW|X1,X2(w|x1,x2). (2.5) Functional maximum likelihood estimation maximizes the likelihood as a function of Θ and the unobserved predictors x11, . . . ,x1n, i.e.,
L(Θ;x11, . . . ,x1n|(Y1,W1), . . . ,(Yn,Wn)) =
n
X
j=1
log{fY,W|X1,X2(Yj,Wj|x1j,x2j;Θ)}(2.6).
approach is adapted here and used to derive conditional estimating equations for generalized linear models with interaction terms.
Consider the joint density in (2.5). Define Ωas Ω= ΩU
a(φ). (2.7)
Note that fW|X1(w|x1) = fW|X1,X2(w|x1,x2). Under (2.1), (2.4) and (2.7), the joint density of (Y,W) givenX1 =x1 and X2 =x2 is
fY,W|X1,X2(y,w|x1,x2;Θ) = fY|X1,X2(y|x1,x2;Θ)fW|X1(w|x1) (2.8)
= exp
(
yη−b(η)
a(φ) +c(y, φ)
)
(2π)−p21 |ΩU |−12 exp
½
−1
2(w−x1)
TΩ−1
U (w−x1)
¾
= exp
(
yβ0+yxT
1(β1+β3x2) +yxT2β2−b(η)
a(φ) +c(y, φ)− 1 2w
TΩ−1 U w
+xT1Ω−1U w− 1 2x
T
1Ω−1U x1−
1
2log [(2π)
p1 |Ω
U |]
)
= exp
(
xT
1Ω−1U
"
yΩU(β1+β3x2) a(φ) +w
#
+y(β0+x
T
2β2)−b(η)
a(φ) +c(y, φ) −1
2(w
TΩ−1
U w+xT1Ω−1U x1)−
1
2log [(2π)
p1 |Ω
U |]
)
=h1(δ,x1)h2(y,x2,w;Θ), where
h1(δ,x1) = exp
½
xT
1Ω−1U {yΩ(β1+β3x2) +w} −
1 2x
T
1Ω−1U x1
¾
,
h2(y,x2,w;Θ) = exp
(
y(β0+xT
2β2)−b(η)
a(φ) +c(y, φ)− 1 2w
TΩ−1 U w
−1
2log [(2π)
p1 |Ω
U |]
)
,
and
δ = w+yΩ(β1+β3x2).
Consider the density of (Y,W) when x1 is regarded as a parameter and all other parameters as known. In this case the statistic
is complete and sufficient for x1 by the Factorization Theorem (Casella & Berger 1990, p.250). Thus the distribution of Y given ∆ and X2 depends only on Y, W,
X2 and Θ, but not on the unobserved true regressor x1. To find the conditional distribution function ofY given ∆ and X2 consider the transformation
∆ = W +YΩ(β1+β3X2), T = Y.
The Jacobian of this transformation has a determinant of one. Under the transfor-mation, the joint density function of (Y,∆) is
fY,∆(y,δ;Θ) =fY,W|X1,X2(y,δ −yΩ(β1 +β3x2);Θ) =fY|X1,X2(y;Θ)fW|X1(δ−yΩ(β1+β3x2);Θ) = exp
(
yη−b(η)
a(φ) +c(y, φ)
)
exp
(
−1
2[δ−yΩ(β1+β3x2)−x1]
T Ω−1
U
h
δ
−yΩ(β1+β3x2)−x1i− 1
2log [(2π)
p1 |Ω
U |]
)
= exp
(
yη−b(η)
a(φ) +c(y, φ)− 1
2(δ−x1)
TΩ−1
U (δ−x1) +y(δ−x1)TΩ−1U Ω(β1+β3x2)
−1
2y(β1+β3x2)
TΩΩ−1
U Ω(β1+β3x2)y−
1
2log [(2π)
p1 |Ω
U |]
) = exp ( y a(φ) h
η+ (δ−x1)T(β1 +β3x2)i−1
2(δ−x1)
TΩ−1
U (δ−x1)
−1 2y
2(β
1+β3x2)T Ω
a(φ)(β1+β3x2)− b(η)
a(φ) +c(y, φ)− 1
2log [(2π)
p1 |Ω
U |]
)
=g1(y,δ;Θ)g2(δ;Θ), where
g1(y,δ;Θ) = exp
(
y a(φ)
h
η+ (δ−x1)T(β1+β3x2)i− y 2
2a(φ)(β1+β3x2)
TΩ(β
1 +β3x2) +c(y, φ)
)
,
g2(δ;Θ) = exp
(
−1
2(δ−x1)
TΩ−1
U (δ−x1)−
b(η) a(φ) −
1
2log [(2π)
p1 |Ω
U |]
)
The marginal density function of the statistic∆ is f∆(δ;Θ) =
Z
fY,∆(y,δ;Θ)dy = g2(δ;Θ)
Z
g1(y,δ;Θ)dy, and the conditional density of Y given∆ is
fY|∆(y|δ;Θ) = fY,∆(y,δ;Θ) f∆(δ;Θ) =
g1(y,δ;Θ)g2(δ; Θ) g2(δ;Θ)R g1(y,δ;Θ)dy =
g1(y,δ;Θ)
R
g1(y,δ;Θ)dy
= exp
(
yϕ− 1 2
y2ξTΩξ
a(φ) +c(y, φ)−log{S(ϕ,ξ, φ)}
)
, (2.10)
where
ξ = (β1+β3x2), ϕ = η+ (δ−x1)
Tξ
a(φ) =
β0+βT1δ+β2TX2+δTβ3X2 a(φ) , and S(·,·,·) is defined as
S(ϕ,ξ, φ) =
Z
exp
(
yϕ− 1 2
y2ξTΩξ
a(φ) +c(y, φ)
)
dy.
The moments of Y given ∆ = δ can be computed from the partial derivatives of S(ϕ,ξ, φ) with respect to ϕ because (2.10) is an exponential family density inϕ and Y is the natural sufficient statistic. So,
EΘ{Y|∆=δ} =
"
∂
∂ϕlog{S(ϕ,ξ, φ)}
# ¯¯ ¯¯ ¯
ϕ=β0+βT1δ+βTa2(φX)2+δT β3X2
.
The conditional distribution ofY given ∆=δ is an exponential family with respect to the aσ-finite measure m(·) which does not depend on Θ. Thus
E{fY0 |∆(y|δ;Θ)}=
Z
fY0|∆(y|δ;Θ)dy=0, (2.11) where
fY0 |∆(y|δ;Θ) = ∂
From this expectation, consistent estimating equations for Θ are derived. We use an alternative derivation of the conditional-score as defined and derived by Stefanski and Carroll (1987).
From (2.1), ∂∂ΘlogfY|X1,X2(y|x1,x2;Θ) is equal to fY0|X
1,X2(y|x1,x2;Θ)
fY|X1,X2(y|x1,x2;Θ) = ∂ ∂Θ
(
yη−b(η)
a(φ) +c(y, φ)
) = ∂ ∂η (
yη−b(η)
a(φ) +c(y, φ)
) ∂η ∂β ∂ ∂φ (
yη−b(η)
a(φ) +c(y, φ)
) = 1 a(φ)
y−b0(η) {y−b0(η)}x1 {y−b0(η)}x2 {y−b0(η)}x1⊗x2 a0(φ)
a(φ) {yη−b(η)}+a(φ)c 0(y, φ)
,
whereβ = (β0,βT1,β2T,βT31,βT32, ...,β3Tp2)T,Θ= (βT, φ)T, andX1⊗X2 is the (p1p2)× 1 vector and equal to (x11XT2, x12XT2, . . . , x1p1XT2)T.
The conditional-score function given by Stefanski and Carroll (1987) is
ψC(Y,W,X2;Θ) = l0−E{l0|∆,X2}, (2.12) where
l0 = l0(Y,W,X
2;Θ) = E
(
fY0|X
1,X2(Y|X1,X2;Θ)
fY|X1,X2(Y|X1,X2;Θ)|Y,W,X2
) = 1 a(φ)
Y −E(b0(η)|Y,W,X2)
Y E(X1|Y,W,X2)−E(b0(η)X1|Y,W,X2) {Y −E(b0(η)|Y,W,X2)}X2
{Y E(X1|Y,W,X2)−E(b0(η)X1|Y,W,X2)} ⊗X2 −a0(φ)
a(φ) {Y E(η|Y,W,X2)−E[b(η)|Y,W,X2]}+a(φ)c 0(Y, φ)
.
The joint density of Y,W,X1 and X2 is
When W is surrogate forX1,fY|W,X1,X2 =fY|X1,X2 in which case fY,W,X1,X2 =fY|X1,X2fW|X1,X2fX1,X2.
By the Factorization Theorem,fY|X1,X2fW|X1,X2can be written ash1(∆,X1,X2)h2(Y,W,X2). Thus,
fY,W,X1,X2 =h1(∆,X1,X2)h2(Y,W,X2)fX1,X2. The marginal density of Y,W,X2 is equal to
fY,W,X2 =
Z
h1(∆,x1,X2)h2(Y,W,X2)fX1,X2dx1 = h2(Y,W,X2)
Z
h1(∆,x1,X2)fX1,X2dx1. The integral results in a function based only on∆ and X2. Thus,
fY,W,X2 =h2(Y,W,X2)f∆,X2.
Finally, the conditional distribution of X1 given Y,W and X2 is fX1|Y,W,X2 = fY,W,X1,X2
fY,W,X2
= h1(∆,X1,X2)h2(Y,W,X2)fX1,X2 h2(Y,W,X2)f∆,X2
= h1(∆,X1,X2)fX1,X2 f∆,X2 ,
which can be written as the conditional distribution ofX1 given∆ and X2. There-fore,
fX1|Y,W,X2 =fX1|∆,X2. (2.13) The result in (2.13) implies that l0 is equal to
l0 = 1
a(φ)
Y −E(b0(η)|∆,X2)
Y E(X1|∆,X2)−E(b0(η)X1|∆,X2) {Y −E(b0(η)|∆,X2)}X2
{Y E(X1|∆,X2)−E(b0(η)X1|∆,X2)} ⊗X2 −a0(φ)
a(φ) {Y E(η|∆,X2)−E(b(η)|∆,X2)}+a(φ)c 0(Y, φ)