ISSN(Online): 2320-9801
ISSN (Print): 2320-9798
I
nternational
J
ournal of
I
nnovative
R
esearch in
C
omputer
and
C
ommunication
E
ngineering
(An ISO 3297: 2007 Certified Organization)
Vol. 4, Issue 10, October 2016
Deep Web Interface Completely Harvested
and Reranked by Crawler
Amruta Pandit1, Prof.Manisha Naoghare2
Student, Dept. of Computer Engineering, SVIT, Chincholi, Nashik, Maharastra, India1
Assistant Professor, Dept. of Computer Engineering, SVIT, Chincholi, Nashik, Maharastra, India2
ABSTRACT
:
There are many undefined scaling challenges for general purpose crawler and search engines due to therapid growth of the deep web. Now a days there are increasing numbers of data sources which become available on the web, but often their contents are only accessible through query interface. For harvesting deep web interface problem proposed framework is used and the Parsing process takes place. To achieve more accurate result this proposed crawler calculate binary vector and page rank of pages and Count the given keywords from the URL which is mined from the crawler to accomplish more precise result for a focused crawler give relevant links with ranking. Here experimental result on a set of representative domain show the accuracy of this proposed crawler framework which can efficiently retrieves web interface from large scale sites.
KEYWORDS
:
Crawling, parsing, Page ranking, Binary VectorI. INTRODUCTION
The deep web means the data which is lie behind searchable web interfaces and which cannot be indexed by searching engines. There are many of Deep Web sources. A large fraction or a all fraction of deep web sources of given domain are able to automatically use the building system. There are recent studies which estimated that 1.9 zetta bytes were extended and 0.3 zetta bytes were disbursed universal in 2007. An IDC report estimates that the total all data created, replicated, and consumed will influence 6 zetta bytes in 2014 .There are vast amount of data is stored as structured or relational data in web databases. Deep web makes up about 96% of all the content on the Internet, this data 500 times larger than the surface web.
The deep web contain huge amount of data which is more usefull, because these entities which cannot access the proprietary web indices of search engines (e.g., Baidu and Google), because of this there is a necessity for an efficient crawler that is able to accurately and quickly explore the deep web databases. To locate deep web database it is challenging because they are not registered and keep constantly changing. For this problem, previous work has proposed two types of crawlers, generic and the focused crawlers. Generic crawlers which can retrive all searchable forms and cannot focus on a specific topic. Focused crawlers which Form Focused Crawler (FFC) and Adaptive Crawler for Hidden-web Entries (ACHE) can automatically search online databases on a topic. FFC is designed with link, page, and form classifiers for focused crawling of web forms, and is extended by ACHE with other components for form filtering and adaptive link learner. There are a pivotal role link classifier to play to achieve high efficiency than the best first crawler. However, to predict the distance to the containing searchable forms from page these link classifiers are used, which is very difficult to estimate for the delayed benefit links (links eventually lead to pages with forms).
ISSN(Online): 2320-9801
ISSN (Print): 2320-9798
I
nternational
J
ournal of
I
nnovative
R
esearch in
C
omputer
and
C
ommunication
E
ngineering
(An ISO 3297: 2007 Certified Organization)
Vol. 4, Issue 10, October 2016
crucial to develop smart crawling strategies which are able to quickly discover content sources from the deep web as much as possible.
II. RELATED WORK
A recent study which can shows that the harvest rate of deep web is low. There are many key reasons for why existing approaches don’t seem to be fitted to our purpose. The most previous work that aims to optimize coverage of individual sites, which is used to retrieve the maximum amount of deep web content retrieved.
There are Generic crawlers are mainly developed for deep webcharacterizing and directory construction of deep web resources, which do not limit search on a specific topic, but it try to fetch all searchable forms. The Database Crawler in the Meta Querier the Database Crawler is designed for discovering query interfacesautomatically. Database Crawler first finds root pages and then performs shallow crawling to crawl pages within a web server starting from a given root page. IP address may have some virtual hosts thus missing many web sites. For overcome the drawback of IP based sampling in the Database Crawler, Denis et al. propose a random sampling of hosts to characterize national deep web, using the Hostgraph provided by the Russian search engine Yandex. I Crawler combines pre query and post query methods for classification of searchable forms. Existing hidden web directories normaly have low coverage for relevant online databases access needs. The crawler is developed to visit links to pages of interest regions. But, a focused best 100,000 movie associated pages. An enhancement to the following all links in appropriate pages, the crawler most promising links in an appropriate page.
There are many key reasons why existing approaches don’t be more well fitted to our purpose. First we will see most previous work aims to coverage optimize of individual sites which are used to retrieves the maximum amount of deep web data. Second things is that meanwhile we checkthe crawl entity oriented pages. In Existing system there are various crawler to solve this problem of crawling for hidden web resources. Our site locating technique employs a reverse searching technique and incremental two-level site prioritizing technique for unearthing relevant sites, achieving more data sources. During the in-site exploring stage, there are link tree design for balanced link prioritizing, eliminating bias toward web pages in popular directories.
III. PROPOSED MODEL
ISSN(Online): 2320-9801
ISSN (Print): 2320-9798
I
nternational
J
ournal of
I
nnovative
R
esearch in
C
omputer
and
C
ommunication
E
ngineering
(An ISO 3297: 2007 Certified Organization)
Vol. 4, Issue 10, October 2016
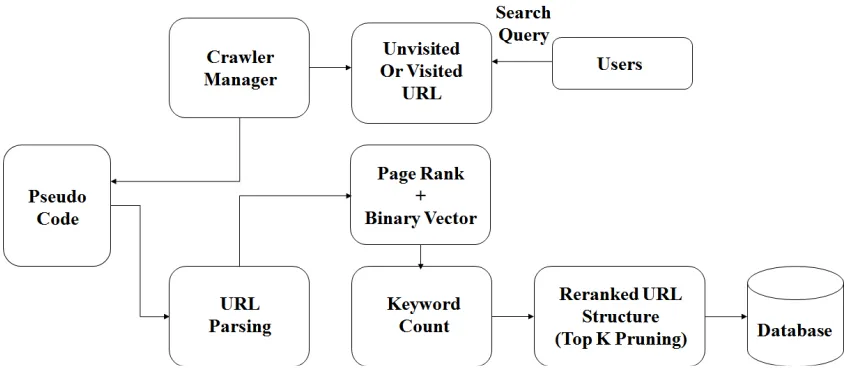
retrieve more accurate results search a query the crawler manager search the unvisited URL, In the framework there are HTML parsing takes place which can gives the result according to the page ranking clustering are takes place for clustering the pages which is stored in the Database. Using Ranked URL structure gives the accurate result of the users query. This proposed framework are used to achieving more accurate result compare to other search engine. For this when user ranking and binary vectors of the pages.
This proposed framework gives more accurate result according to calculating page rank and binary vector algorithm due to this framework gives the most accurate result to the user. Now a day’s deep web grows very fast, there has been many interest in techniques which are efficiently locate deep web interface. However, there are large amount of web resources and the dynamic nature of deep web, achieving wide coverage and high efficiency is a challenging issue. In this proposed framework of the crawler there are the following Modules.
B. PAGE RANK AND BINARY VECTOR CALCULATION:
In between the large amount of database hare calculating the page rank and binary vector of pages to achieve more accurate result.
C. RE-RANKING OF URL:
In between the vast amount of database there is need of re ranking of data is module are used for this task.
D. ALGORITHM: TOP K PRUNING
Input: ruleIr,input string s,candidate number k Output:top k output strings in Stopk
1 Begin
2 Find all rules applicable to s from Ir with Aho-corasick algorithm 3 Minscore=-infinity
4 Qpath=Stopk = fg 5 Add (1, 0) intoQpath 6 While Qpath is not empty do
7 Pickup a path (pos,string,score)from Qpath with heuristics 8 If score <= minscore then
9 Continue
10 If pos==| s | AND string reaches then 11If |Sk |_ k then
12 Remove candidate with minimum score from Stopk 13 Add candidate (string,score)into Stopk
14 Update minscore with minimum score in Stopk 15 Foreach next substring c atpos do
16 corresponding rule of c 17Pos = pos +
18 String=string+ 19 Score=score+
ISSN(Online): 2320-9801
ISSN (Print): 2320-9798
I
nternational
J
ournal of
I
nnovative
R
esearch in
C
omputer
and
C
ommunication
E
ngineering
(An ISO 3297: 2007 Certified Organization)
Vol. 4, Issue 10, October 2016
IV. RESULT AND DISCUSSION
The Experimental results are shown below.
The below table shows that theProposed Crawler finds more relevant deep keywords than the existing crawler. To better understand the efficiency of these crawlers, table illustrates the number of relevant keywords harvested during the crawling process. We can observe that Proposed Crawler consistently harvest more relevant forms than existing, because our two-stage approach prioritizes more relevant sites, avoiding visiting many pages of irrelevant sites.
Table 1 Resultof total keywords found when query length is 3
Query ES_Keywords PS_Link Keywords
IPL 1390 4874
Earth 38185 41488
Samsung 12074 22759
Linux 16962 22299
Mozilla 12795 17305
V. CONCLUSIONAND FUTURE WORK
The fast growth of World Wide Web poses unique scaling challenges for general purpose crawler and search engines. As deep web grows a very fast speed, there has been improved interest in techniques that help efficiently locate deep web interface. In this Deep web there are vast amount of valuable information are present. And entities here propose an effective harvesting framework for deep web interfaces. Here have shown that this approach achieves both wide coverage for deep web interfaces and maintains highly efficient crawling. To achieve more accurate results here calculate the page rank and Binary Vector of the links. After calculating that links Re ranking of that links takes place using Ranked URL structure. Using this framework most accurate and quick result are retrieves. In future work, we plan to combine pre-query and post-query approaches for classifying deep-web forms to furtherimprove the accuracy of the form classifier.
REFERENCES
[1] Feng Zhao, Jingyu Zhou, Chang Nie,Heqing Huang, and Hai Jin. SmartCrawler: A Two-stage Crawler for E_ciently Harvesting Deep-web Interfaces. IEEE Transactions on Services Computing Volume: PP Year: 2015.
[2] BalakrishnanRaju, KambhampatiSubbarao, and JhaManishkumar. Assessing relevance and trust of the deep web sources and results based on inter-source agreement. ACM Transactions on the Web, 7(2):Article 11, 132, 2013.
[3] BalakrishnanRaju and KambhampatiSubbarao. Sourcerank: Relevance and trust assessment for deep web sources based on inter-source agreement. In Proceedings of the 20th international conference on World Wide Web, pages 227236,2011.
[4] NileshDalvi, Ravi Kumar, AshwinMachanavajjhala, and VibhorRastogi. Sampling hidden objects using nearest-neighbor oracles. In Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 13251333. ACM, 2011.
[5] Eduard C. Dragut, Thomas Kabisch, Clement Yu, and Ulf Leser. A hierarchical approach to model web query interfaces for web source integration. Proc. VLDB Endow., 2(1):325336, August 2009.
[6] Luciano Barbosa and Juliana Freire. An adaptive crawler for locating hidden- web entry points. In Proceedings of the 16th international conference on World Wide Web, pages 441450. ACM, 2007.
[7] Luciano Barbosa and Juliana Freire. Combining classi_ers to identify online databases. In Proceedings of the 16th international conference on World Wide Web, pages 431440. ACM, 2007.
ISSN(Online): 2320-9801
ISSN (Print): 2320-9798
I
nternational
J
ournal of
I
nnovative
R
esearch in
C
omputer
and
C
ommunication
E
ngineering
(An ISO 3297: 2007 Certified Organization)
Vol. 4, Issue 10, October 2016
[12] Jared Cope, Nick Craswell, and David Hawking. Automated discovery of search interfaces on the web. In Proceedings of the 14th Australasian database conference-Volume 17, pages 181189. Australian Computer Society, Inc., 2003.
[13] Panagiotis G Ipeirotis and Luis Gravano. Distributed search over the hidden web: Hierarchical database sampling and selection. In Proceedings of the 28th international conference on Very Large Data Bases, pages 394405. VLDB Endowment,2002.
[14] SriramRaghavan and Hector Garcia-Molina. Crawling the hidden web. In Proceedings of the 27th International Conference on Very Large Data Bases, pages 129138, 2000.